

metadata
tags:
- text-to-image
- stable-diffusion
license: apache-2.0
language:
- en
library_name: diffusers
EasyRef Model Card
Project Page | Paper | Code | 🤗 Demo
Introduction
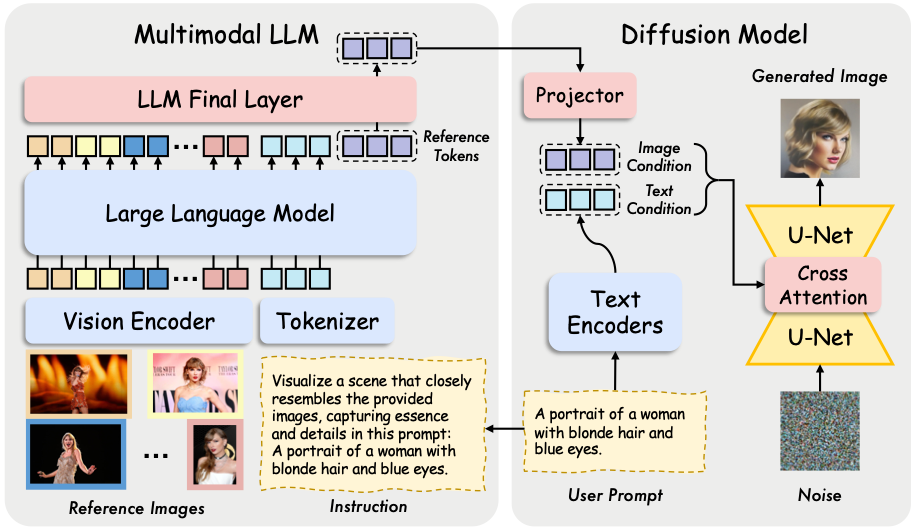
EasyRef is capable of modeling the consistent visual elements of various group image references with a single generalist multimodal LLM in a zero-shot setting.
Demos
More visualization examples are available in our project page.
Style, Identity, and Character Preservation

Comparison with IP-Adapter

Compatibility with ControlNet

Inference
We provide the inference code of EasyRef with SDXL in easyref_demo.
Usage Tips
- EasyRef performs best when provided with multiple reference images (more than 2).
- To ensure better identity preservation, we strongly recommend that users upload multiple square face images, ensuring the face occupies the majority of each image.
- Using multimodal prompts (both reference images and non-empty text prompt) can achieve better results.
- We set
scale=1.0by default. Lowering thescalevalue leads to more diverse but less consistent generation results.
Cite
If you find EasyRef useful for your research and applications, please cite us using this BibTeX:
@article{easyref,
title={EasyRef: Omni-Generalized Group Image Reference for Diffusion Models via Multimodal LLM},
author={Zong, Zhuofan and Jiang, Dongzhi and Ma, Bingqi and Song, Guanglu and Shao, Hao and Shen, Dazhong and Liu, Yu and Li, Hongsheng},
journal={arXiv preprint arXiv:2412.09618},
year={2024}
}