Using quantized models (dtypes)
Before Transformers.js v3, we used the quantized option to specify whether to use a quantized (q8) or full-precision (fp32) variant of the model by setting quantized to true or false, respectively. Now, we’ve added the ability to select from a much larger list with the dtype parameter.
The list of available quantizations depends on the model, but some common ones are: full-precision ("fp32"), half-precision ("fp16"), 8-bit ("q8", "int8", "uint8"), and 4-bit ("q4", "bnb4", "q4f16").

Basic usage
Example: Run Qwen2.5-0.5B-Instruct in 4-bit quantization (demo)
import { pipeline } from "@huggingface/transformers";
// Create a text generation pipeline
const generator = await pipeline(
"text-generation",
"onnx-community/Qwen2.5-0.5B-Instruct",
{ dtype: "q4", device: "webgpu" },
);
// Define the list of messages
const messages = [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Tell me a funny joke." },
];
// Generate a response
const output = await generator(messages, { max_new_tokens: 128 });
console.log(output[0].generated_text.at(-1).content);Per-module dtypes
Some encoder-decoder models, like Whisper or Florence-2, are extremely sensitive to quantization settings: especially of the encoder. For this reason, we added the ability to select per-module dtypes, which can be done by providing a mapping from module name to dtype.
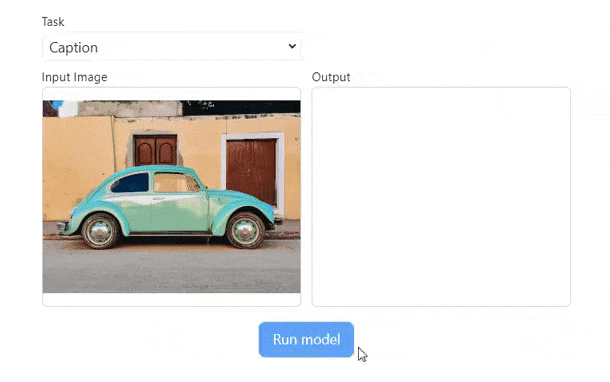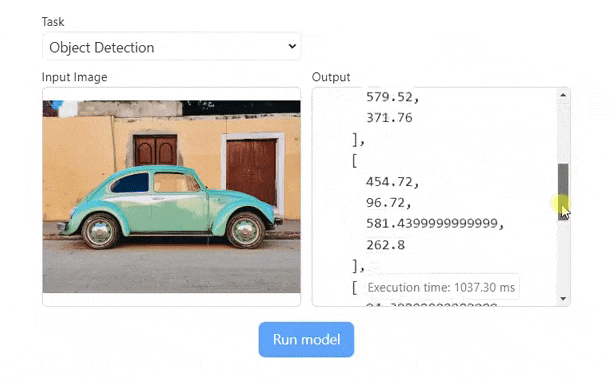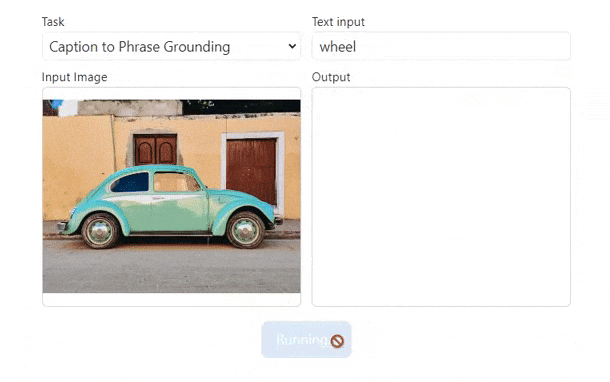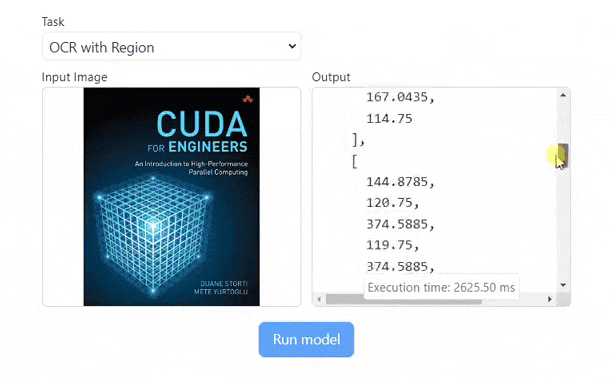
Example: Run Florence-2 on WebGPU (demo)
import { Florence2ForConditionalGeneration } from "@huggingface/transformers";
const model = await Florence2ForConditionalGeneration.from_pretrained(
"onnx-community/Florence-2-base-ft",
{
dtype: {
embed_tokens: "fp16",
vision_encoder: "fp16",
encoder_model: "q4",
decoder_model_merged: "q4",
},
device: "webgpu",
},
);
See full code example
import {
Florence2ForConditionalGeneration,
AutoProcessor,
AutoTokenizer,
RawImage,
} from "@huggingface/transformers";
// Load model, processor, and tokenizer
const model_id = "onnx-community/Florence-2-base-ft";
const model = await Florence2ForConditionalGeneration.from_pretrained(
model_id,
{
dtype: {
embed_tokens: "fp16",
vision_encoder: "fp16",
encoder_model: "q4",
decoder_model_merged: "q4",
},
device: "webgpu",
},
);
const processor = await AutoProcessor.from_pretrained(model_id);
const tokenizer = await AutoTokenizer.from_pretrained(model_id);
// Load image and prepare vision inputs
const url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg";
const image = await RawImage.fromURL(url);
const vision_inputs = await processor(image);
// Specify task and prepare text inputs
const task = "<MORE_DETAILED_CAPTION>";
const prompts = processor.construct_prompts(task);
const text_inputs = tokenizer(prompts);
// Generate text
const generated_ids = await model.generate({
...text_inputs,
...vision_inputs,
max_new_tokens: 100,
});
// Decode generated text
const generated_text = tokenizer.batch_decode(generated_ids, {
skip_special_tokens: false,
})[0];
// Post-process the generated text
const result = processor.post_process_generation(
generated_text,
task,
image.size,
);
console.log(result);
// { '<MORE_DETAILED_CAPTION>': 'A green car is parked in front of a tan building. The building has a brown door and two brown windows. The car is a two door and the door is closed. The green car has black tires.' }