
user
stringlengths 3
28
| created_at
timestamp[us] | body
stringlengths 1
173k
| issue_number
int64 1
2.57k
|
|---|---|---|---|
younesbelkada | 2023-02-22T10:59:52 | This solution makes a lot of sense yes! | 153 |
review-notebook-app[bot] | 2023-02-22T11:35:55 | Check out this pull request on <a href="https://app.reviewnb.com/lvwerra/trl/pull/153"><img align="absmiddle" alt="ReviewNB" height="28" class="BotMessageButtonImage" src="https://raw.githubusercontent.com/ReviewNB/support/master/images/button_reviewnb.png"/></a>
See visual diffs & provide feedback on Jupyter Notebooks.
---
<i>Powered by <a href='https://www.reviewnb.com/?utm_source=gh'>ReviewNB</a></i> | 153 |
lvwerra | 2023-02-22T11:36:46 | Deprecated `forward_batch_size`: feel free to have a look! | 153 |
HuggingFaceDocBuilderDev | 2023-02-16T10:55:22 | _The documentation is not available anymore as the PR was closed or merged._ | 152 |
younesbelkada | 2023-02-16T08:17:12 | Thanks a lot for your issue @koking0 !
Can you share with us more details about the environment you are using? Also how do you run your script?
I advice you to run the script with:
Step 1:
```
accelerate config
```
Then chose multi-gpu
Step 2:
```
accelerate launch your_script.py
``` | 151 |
koking0 | 2023-02-16T08:34:16 | thank you for your reply. I did it with the steps you provided.
This is the config file I generated via `accelerate config`:
```
$ cat /home/user/.cache/huggingface/accelerate/default_config.yaml
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: MULTI_GPU
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config: {}
gpu_ids: 0,2,4,5,6,7
machine_rank: 0
main_training_function: main
megatron_lm_config: {}
mixed_precision: 'no'
num_machines: 1
num_processes: 6
rdzv_backend: static
same_network: true
use_cpu: false
```
I think I have further positioned some problems, the `all_reduce` operation is initially stuck in `ppo/policy/advantages`, there may be other elements that will be stuck later, but the first one will be it.
I took a look at the dimensions and found that the dimensions are not consistent on each card, that could be a major reason, but why?
log:
```
0 start reduce process: ppo/policy/advantages, size: torch.Size([7744])
2 start reduce process: ppo/policy/advantages, size: torch.Size([7360])
3 start reduce process: ppo/policy/advantages, size: torch.Size([7712])
1 start reduce process: ppo/policy/advantages, size: torch.Size([7328])
5 start reduce process: ppo/policy/advantages, size: torch.Size([7552])
0 start reduce process: ppo/policy/advantages_mean, size: torch.Size([1])
4 start reduce process: ppo/policy/advantages, size: torch.Size([7776])
2 start reduce process: ppo/policy/advantages_mean, size: torch.Size([1])
3 start reduce process: ppo/policy/advantages_mean, size: torch.Size([1])
1 start reduce process: ppo/policy/advantages_mean, size: torch.Size([1])
5 start reduce process: ppo/policy/advantages_mean, size: torch.Size([1])
4 start reduce process: ppo/policy/advantages_mean, size: torch.Size([1])
``` | 151 |
younesbelkada | 2023-02-16T09:02:44 | Hi @koking0
Thanks for narrowing down the issue, I think that I have found the bug
The advantages are computed with respect to each token of the response.
In your case, your response are stored as such:
```
response_tensors.append(response.squeeze())
```
So each process will have a response that has a different length, thus resulting in a script that hangs. In gpt2-sentiment script we do:
```
response_tensors.append(response.squeeze()[-gen_len:])
```
And my understanding is that this leads for each process to have the same response length (after double checking on my side with 2xNVIDIA T4). Can you please double check that? | 151 |
koking0 | 2023-02-16T09:17:10 | Yes!
Thank you very very very much for your help in solving my problem.
I wish trl more and more perfect. | 151 |
shizhediao | 2023-02-23T06:13:46 | Update:
Seems that I got stuck at `stats_to_np`.
Hi, I encountered the same problem, where I got stuck at `gather_stats`. But I am using the official script as shown below. Could you help me take a look? Thanks!
```
########################################################################
# This is a fully working simple example to use trl with accelerate.
#
# This example fine-tunes a GPT2 model on the IMDB dataset using PPO
# (proximal policy optimization).
# in any of the following settings (with the same script):
# - single CPU or single GPU
# - multi GPUS (using PyTorch distributed mode)
# - multi GPUS (using DeepSpeed ZeRO-Offload stages 1 & 2)
# - fp16 (mixed-precision) or fp32 (normal precision)
#
# To run it in each of these various modes, first initialize the accelerate
# configuration with `accelerate config`
#
########################################################################
# 0. imports
import torch
import time
import argparse
from tqdm import tqdm
tqdm.pandas()
from transformers import pipeline, AutoTokenizer, set_seed
from datasets import load_dataset
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_model
from trl.core import respond_to_batch, LengthSampler
def arg_parser():
parser = argparse.ArgumentParser(description="LLM-RLHF")
parser.add_argument("--random_seed", type=int, default=1, help="random seed")
parser.add_argument(
"--dataset", type=str, default="gsm8k", choices=["gsm8k", "svamp", "aqua", "csqa", "asdiv", "last_letters", "addsub", "singleeq", "strategyqa"], help="dataset to inference"
)
parser.add_argument(
"--model_name", type=str, default="lvwerra/gpt2-imdb", help="base model used for training"
) # lvwerra/gpt2-imdb is a GPT2 model which was additionally fine-tuned on the IMDB dataset for 1 epoch with the huggingface script (no special settings). The other parameters are mostly taken from the original paper "Fine-Tuning Language Models from Human Preferences". This model as well as the BERT model is available in the Huggingface model zoo here. The following code should automatically download the models.
parser.add_argument(
"--reward_model_name", type=str, default="lvwerra/distilbert-imdb", help="base model used for training"
)
parser.add_argument("--learning_rate", type=float, default=1.41e-5, help="learning rate")
parser.add_argument("--task_name", type=str, default="sentiment-analysis", help="task name for pipeline")
parser.add_argument("--batch_size", type=int, default=1, help="training batch size")
parser.add_argument("--inference_batch_size", type=int, default=1, help="inference batch size")
parser.add_argument("--forward_batch_size", type=int, default=1, help="forward batch size")
parser.add_argument("--output_dir", type=str, default="./output_dir", help="output directory")
parser.add_argument("--output_min_length", type=int, default=4, help="output_min_length")
parser.add_argument("--output_max_length", type=int, default=16, help="output_max_length")
parser.add_argument("--min_length", type=int, default=0, help="minimum length for generation")
parser.add_argument("--do_sample", type=bool, default=True, help="sampling or not")
parser.add_argument("--model_args", type=str, help="arguments for generator args")
parser.add_argument("--local_rank", type=int, help="local rank")
args = parser.parse_args()
return args
def build_dataset(config, dataset_name="imdb", input_min_text_length=2, input_max_text_length=8):
"""
Build dataset for training. This builds the dataset from `load_dataset`, one should
customize this function to train the model on its own dataset.
Args:
dataset_name (`str`):
The name of the dataset to be loaded.
Returns:
dataloader (`torch.utils.data.DataLoader`):
The dataloader for the dataset.
"""
tokenizer = AutoTokenizer.from_pretrained(config.model_name)
tokenizer.pad_token = tokenizer.eos_token
# load imdb with datasets
ds = load_dataset(dataset_name, split='train')
ds = ds.rename_columns({'text': 'review'})
ds = ds.filter(lambda x: len(x["review"])>200, batched=False)
input_size = LengthSampler(input_min_text_length, input_max_text_length)
def tokenize(sample):
sample["input_ids"] = tokenizer.encode(sample["review"])[:input_size()]
sample["query"] = tokenizer.decode(sample["input_ids"])
return sample
ds = ds.map(tokenize, batched=False)
ds.set_format(type='torch')
return ds
def main():
# 1. Set up configs
args = arg_parser()
ppo_config = PPOConfig(
batch_size=args.batch_size,
forward_batch_size=args.forward_batch_size,
model_name=args.model_name,
learning_rate=args.learning_rate,
log_with="wandb",
)
sent_kwargs = {
"return_all_scores": True,
"function_to_apply": "none",
"batch_size": ppo_config.forward_batch_size
}
# set seed before initializing value head for deterministic eval
set_seed(args.random_seed)
# 2. Load dataset
dataset = build_dataset(ppo_config)
def collator(data):
return dict((key, [d[key] for d in data]) for key in data[0])
# 3. load pretrained models
model = AutoModelForCausalLMWithValueHead.from_pretrained(ppo_config.model_name)
ref_model = AutoModelForCausalLMWithValueHead.from_pretrained(ppo_config.model_name)
tokenizer = AutoTokenizer.from_pretrained(ppo_config.model_name)
tokenizer.pad_token = tokenizer.eos_token
# 4. initialize trainer
ppo_trainer = PPOTrainer(ppo_config, model, ref_model, tokenizer, dataset=dataset, data_collator=collator)
# 5. load reward model
device = ppo_trainer.accelerator.device
if ppo_trainer.accelerator.num_processes == 1:
device = 0 if torch.cuda.is_available() else "cpu" # to avoid a `pipeline` bug
sentiment_pipe = pipeline(args.task_name, model=args.reward_model_name, device=device)
# 6. Training
output_length_sampler = LengthSampler(args.output_min_length, args.output_max_length)
# set up generation settings
generation_kwargs = {
"min_length":-1,
"top_k": 0.0,
"top_p": 1.0,
"do_sample": True,
"pad_token_id": tokenizer.eos_token_id
}
for batch_index, batch in enumerate(tqdm(ppo_trainer.dataloader, desc='Training')):
print("batch_index", batch_index)
query_tensors = batch['input_ids']
#### Get response from gpt2
response_tensors = []
for query in query_tensors:
gen_len = output_length_sampler()
generation_kwargs["max_new_tokens"] = gen_len
response = ppo_trainer.generate(query, **generation_kwargs)
response_tensors.append(response.squeeze()[-gen_len:])
batch['response'] = [tokenizer.decode(r.squeeze()) for r in response_tensors]
#### Compute sentiment score
texts = [q + r for q,r in zip(batch['query'], batch['response'])]
pipe_outputs = sentiment_pipe(texts, **sent_kwargs)
rewards = [torch.tensor(output[1]["score"]) for output in pipe_outputs]
print("query_tensors", query_tensors)
#### Run PPO step
stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
ppo_trainer.log_stats(stats, batch, rewards)
# 7. Model Inspectation
#### get a batch from the dataset
inference_batch_size = args.inference_batch_size
game_data = dict()
dataset.set_format("pandas")
df_batch = dataset[:].sample(inference_batch_size)
game_data['query'] = df_batch['query'].tolist()
query_tensors = df_batch['tokens'].tolist()
response_tensors_ref, response_tensors = [], []
#### get response from gpt2 and gpt2_ref
for i in range(inference_batch_size):
gen_len = output_length_sampler()
output = ref_model.generate(torch.tensor(query_tensors[i]).unsqueeze(dim=0).to(device),
max_new_tokens=gen_len, **gen_kwargs).squeeze()[-gen_len:]
response_tensors_ref.append(output)
output = model.generate(torch.tensor(query_tensors[i]).unsqueeze(dim=0).to(device),
max_new_tokens=gen_len, **gen_kwargs).squeeze()[-gen_len:]
response_tensors.append(output)
#### decode responses
game_data['response (before)'] = [tokenizer.decode(response_tensors_ref[i]) for i in range(inference_batch_size)]
game_data['response (after)'] = [tokenizer.decode(response_tensors[i]) for i in range(inference_batch_size)]
#### sentiment analysis of query/response pairs before/after
texts = [q + r for q,r in zip(game_data['query'], game_data['response (before)'])]
game_data['rewards (before)'] = [output[1]["score"] for output in sentiment_pipe(texts, **sent_kwargs)]
texts = [q + r for q,r in zip(game_data['query'], game_data['response (after)'])]
game_data['rewards (after)'] = [output[1]["score"] for output in sentiment_pipe(texts, **sent_kwargs)]
# store results in a dataframe
df_results = pd.DataFrame(game_data)
print(df_results)
# 8. Save model and tokenizer locally
model.save_pretrained(f'{args.output_dir}/rlhf-model-ppo', push_to_hub=True)
tokenizer.save_pretrained(f'{args.output_dir}/rlhf-model-ppo', push_to_hub=True)
if __name__ == "__main__":
main()
``` | 151 |
younesbelkada | 2023-03-16T08:20:54 | I also faced a similar issue with the latest `trl` that I fixed with https://github.com/lvwerra/trl/pull/222 | 151 |
younesbelkada | 2023-02-16T08:33:31 | Hi @BirgerMoell
Nice catch! These cells are missing indeed, would you mind opening a PR to fix this? it will be a nice contribution! | 150 |
BirgerMoell | 2023-02-16T16:23:47 | @younesbelkada made a PR. I noticed that some installs was added to the input (just the output of me running it). I'm not sure if these are shown when you load the notebook. If you want me to clean it up I'll fix that too.
https://github.com/lvwerra/trl/pull/158 | 150 |
lvwerra | 2023-02-20T10:51:19 | I think this was fixed in https://github.com/lvwerra/trl/pull/159. | 150 |
review-notebook-app[bot] | 2023-02-15T14:55:44 | Check out this pull request on <a href="https://app.reviewnb.com/lvwerra/trl/pull/149"><img align="absmiddle" alt="ReviewNB" height="28" class="BotMessageButtonImage" src="https://raw.githubusercontent.com/ReviewNB/support/master/images/button_reviewnb.png"/></a>
See visual diffs & provide feedback on Jupyter Notebooks.
---
<i>Powered by <a href='https://www.reviewnb.com/?utm_source=gh'>ReviewNB</a></i> | 149 |
HuggingFaceDocBuilderDev | 2023-02-15T15:01:48 | The docs for this PR live [here](/static-proxy?url=https%3A%2F%2Fmoon-ci-docs.huggingface.co%2Fdocs%2Ftrl%2Fpr_149). All of your documentation changes will be reflected on that endpoint. | 149 |
kashif | 2023-02-16T13:46:51 | @AlexWortega in your `sft` function I believe you are missing an `optimizer.zero_grad()` | 149 |
github-actions[bot] | 2023-06-20T15:05:03 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
| 149 |
lvwerra | 2023-06-23T13:04:46 | Closing for now since there is not a lot of activity right now. Feel free to reopen :) | 149 |
lvwerra | 2023-02-15T14:10:05 | hmm maybe we run out of data at this point. Maybe you could verify by just iterating over the dataset and not doing generation/training inside the loop. @younesbelkada maybe we can deal with this better inside TRL. | 148 |
edbeeching | 2023-02-15T20:40:37 | We could `drop_last=True` when we create the dataloader? | 148 |
younesbelkada | 2023-02-15T21:39:12 | Agreed with @edbeeching ! We can also have a stronger safety checker, happy to have a look! | 148 |
younesbelkada | 2023-02-16T15:28:23 | Hi @avacaondata
If you use the `main` branch the issue should be solved | 148 |
HuggingFaceDocBuilderDev | 2023-02-15T10:37:09 | _The documentation is not available anymore as the PR was closed or merged._ | 147 |
lvwerra | 2023-02-15T14:17:49 | Interesting idea! Indeed, TRL is not really setup for encoder models at this point, rather decoder models. In your setup each move would correspond to a forward pass in your model, right? With the decoder models we compute logits/logprobs in a single forward pass of the model for a series of actions (token generations). In your case you would do the same as a batch, right? | 146 |
jorahn | 2023-02-15T14:54:48 | Yes, exactly! A batch would usually be multiple games in parallel or leaves in a search tree. And a single example would be one position as input and a softmax over all moves (action space) as classification output.
The difference doesn't seem that big. Would it be worth trying directly or would I need to implement changes to the model classes or the trainer before even attempting? | 146 |
lvwerra | 2023-02-20T10:47:54 | I haven't thought it through completely but I think the main change necessary is to batch the connected forward passes together. So maybe overwriting the `batched_forward_pass` method would already be enough? Currently we pass inputs as `[bs, seq]` to the decoder model where in your case you probably want something along the lines of `[bs x seq, 1]` and then reshape the output logits back to something like `[bs, seq, tokens]`. Also not sure if the `data_collator` we use there works out of the box so worth double checking. | 146 |
jorahn | 2023-02-20T14:32:57 | Thanks for the helpful pointers! I’ll have a look into it 😊 | 146 |
lvwerra | 2023-03-21T10:15:22 | Closing this for now - feel free to reopen if there's an update :) | 146 |
younesbelkada | 2023-02-13T07:55:37 | Hi @thedarkzeno !
Thanks for your interest, yes this is on our roadmap and will be implemented very soon. We will keep you posted | 145 |
younesbelkada | 2023-03-07T14:12:25 | Hi @thedarkzeno !
You can now use `peft` and `trl`! Check out the docs here: https://huggingface.co/docs/trl/main/en/sentiment_tuning_peft to learn more about that! | 145 |
thedarkzeno | 2023-03-07T18:21:12 | Amazing work, could you make an example for T5?
I've tried to make it work, but got this error:
C:\Users\Adalberto\miniconda3\lib\site-packages\transformers\models\t5\modeling_t5.py:970 in │
│ forward │
│ │
│ 967 │ │ batch_size, seq_length = input_shape │
│ 968 │ │ │
│ 969 │ │ # required mask seq length can be calculated via length of past │
│ ❱ 970 │ │ mask_seq_length = past_key_values[0][0].shape[2] + seq_length if past_key_values │
│ 971 │ │ │
│ 972 │ │ if use_cache is True: │
│ 973 │ │ │ assert self.is_decoder, f"`use_cache` can only be set to `True` if {self} is │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
IndexError: tuple index out of range | 145 |
younesbelkada | 2023-03-08T08:35:18 | @thedarkzeno you should disable `use_cache` when using `gradient_checkpointing`, check this issue: https://github.com/huggingface/transformers/issues/21737
I think your script should work with `use_cache=False`. If you managed to make a script with `t5` we'd be more than happy to add it on the lib, how does that sound to you?
Let us know if you need more help | 145 |
HuggingFaceDocBuilderDev | 2023-02-11T08:27:23 | _The documentation is not available anymore as the PR was closed or merged._ | 144 |
ArvinZhuang | 2023-02-11T10:43:47 | > Thanks for fixing! Could you revert your changes in all the scripts inside `examples/` after that we should be good to merge!
Hi
these changes are automatically generated by style && quality, but I reverted them anyway | 144 |
ArvinZhuang | 2023-02-11T10:59:31 | Also I notice this `"Forward batch size > 1 is not well supported yet for encoder-decoder models`.
Could you please give me more hits why this is the case? Looks like forward batch size =1 will greatly slow down the inference, I probably can give it a shot to fix this. | 144 |
Rebecca-Qian | 2023-02-14T05:41:01 | Had just prepared a PR to fix this 😄 thanks @ArvinZhuang | 144 |
ArvinZhuang | 2023-02-14T09:45:03 | > Had just prepared a PR to fix this 😄 thanks @ArvinZhuang
@Rebecca-Qian You are welcome :) Im glad to contribute as well
| 144 |
DaehanKim | 2023-02-10T11:20:04 | I found this because sentiment-control example ipynb didn't run in my environment.
I use A6000 GPU and only added `os.environ['CUDA_VISIBLE_DEVICES']='5'` at the start of the script. And got this stacktrace :
```
RuntimeError Traceback (most recent call last)
Cell In[15], line 24
22 #### Run PPO training
23 t = time.time()
---> 24 stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
26 for cs in ctrl_str:
27 key = 'env/reward_'+cs.strip('[]')
File /workspace/trl/trl/trainer/ppo_trainer.py:441, in PPOTrainer.step(self, queries, responses, scores)
437 t0 = time.time()
439 t = time.time()
--> 441 logprobs, ref_logprobs, values = self.batched_forward_pass(queries, responses)
442 timing["time/ppo/forward_pass"] = time.time() - t
444 t = time.time()
File /workspace/trl/trl/trainer/ppo_trainer.py:587, in PPOTrainer.batched_forward_pass(self, queries, responses)
584 response_batch = responses[i * fbs : (i + 1) * fbs]
586 with torch.no_grad():
--> 587 logits, _, v = self.model(**input_kwargs)
588 ref_logits, _, _ = self.ref_model(**input_kwargs)
590 if self.is_encoder_decoder:
File /opt/conda/envs/trl-tutorial/lib/python3.8/site-packages/torch/nn/modules/module.py:1212, in Module._call_impl(self, *input, **kwargs)
1209 bw_hook = hooks.BackwardHook(self, full_backward_hooks)
...
2208 # remove once script supports set_grad_enabled
2209 _no_grad_embedding_renorm_(weight, input, max_norm, norm_type)
-> 2210 return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument index in method wrapper__index_select)
```
I saw all inputs(query, responses) are properly in cuda devices. but in forward batching process, they seems to be mapped to CPU. Maybe it's related to recent forward batching update #139 (I'm not sure). I'll update when I figure out something. | 143 |
younesbelkada | 2023-02-10T11:25:29 | Hi @DaehanKim ,
Thanks for the report! I think this makes sense and should be replaced as suggested ;)
Do you know if adding your patch fixes your issue?
Also I would recommend to not add `CUDA_VISIBLE_DEVICES` as device assignement should be taken care by `accelerate` | 143 |
DaehanKim | 2023-02-10T11:47:01 | Unfortunately, fixing collator alone didn't solve the problem.
It gives another error stacktrace:
```
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[33], line 24
22 #### Run PPO training
23 t = time.time()
---> 24 stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
26 for cs in ctrl_str:
27 key = 'env/reward_'+cs.strip('[]')
File /workspace/trl/trl/trainer/ppo_trainer.py:441, in PPOTrainer.step(self, queries, responses, scores)
437 t0 = time.time()
439 t = time.time()
--> 441 logprobs, ref_logprobs, values = self.batched_forward_pass(queries, responses)
442 timing["time/ppo/forward_pass"] = time.time() - t
444 t = time.time()
File /workspace/trl/trl/trainer/ppo_trainer.py:587, in PPOTrainer.batched_forward_pass(self, queries, responses)
584 response_batch = responses[i * fbs : (i + 1) * fbs]
586 with torch.no_grad():
--> 587 logits, _, v = self.model(**input_kwargs)
588 ref_logits, _, _ = self.ref_model(**input_kwargs)
590 if self.is_encoder_decoder:
File /opt/conda/envs/trl-tutorial/lib/python3.8/site-packages/torch/nn/modules/module.py:1212, in Module._call_impl(self, *input, **kwargs)
1209 bw_hook = hooks.BackwardHook(self, full_backward_hooks)
...
--> 767 input_shape = input_ids.size()
768 input_ids = input_ids.view(-1, input_shape[-1])
769 batch_size = input_ids.shape[0]
AttributeError: 'list' object has no attribute 'size'
```
This happens because `input_ids` becomes a list of individual input_id tensors. due to this part:
https://github.com/lvwerra/trl/blob/main/trl/trainer/ppo_trainer.py#L569-L576 | 143 |
DaehanKim | 2023-02-12T20:35:10 | I think #144 partially fix the problem, if we assume `self.data_collator` is always set to `DataCollatorForLanguageModeling(self.tokenizer, mlm=False)`. | 143 |
lvwerra | 2023-02-13T10:46:29 | Hi @DaehanKim I think there's some confusion in the `data_collator` since there are actually two :)
1. The `data_collator` passed to `PPOTrainer` will be used by `self.dataloader`. This is used to give you data in your training loop: https://github.com/lvwerra/trl/blob/ccd2641b51fb12424e46fff82b150e830f87800c/examples/sentiment/scripts/gpt2-sentiment.py#L136
2. The second collator (`self.data_collator`) is used internally only and is used to batch the inputs passed to `PPOTrainer.step` in `batched_forward_pass` here: https://github.com/lvwerra/trl/blob/ccd2641b51fb12424e46fff82b150e830f87800c/trl/trainer/ppo_trainer.py#L555-L557
Indeed for the second collator you have no way overwriting it and we always assume CLM objective but for the first one the one you pass will take effect.
For your latest error: is it possible that you pass list of lists rather than list of torch.tensors as queries/responses in `ppo_trainer.step(query_tensors, response_tensors, rewards)`? | 143 |
DaehanKim | 2023-02-13T11:33:52 | @lvwerra Thank you for correction! I didn't know these two are used in different ways.
My latest error occured since I forcefully overwrite `self.data_collator` to what was passed at`PPOTrainer` initialization. Everything works fine if I don't do that.
I think things are wrapped up : so closing the issue. | 143 |
HuggingFaceDocBuilderDev | 2023-02-09T18:10:59 | _The documentation is not available anymore as the PR was closed or merged._ | 142 |
younesbelkada | 2023-02-17T11:08:22 | Closing in favor of #162 | 142 |
lvwerra | 2023-02-09T18:02:54 | If you are running a decoder model I would look at `gpt2-sentiment.py`. Note that usually it is good to start with a smaller model. In general your format seems good, i guess you need to define a reward function as well. | 141 |
Sid22kiara | 2023-02-13T11:14:05 | ok | 141 |
lvwerra | 2023-02-13T11:26:03 | Closing for now, feel free to reopen if you run into any issues. | 141 |
lvwerra | 2023-02-09T17:01:56 | That would be something you would do after training right? So you would just take a model you want to evaluate, generate n candidates and sort them with the reward model? We can easily do that in a notebook/script in examples? Or do you think it requires custom functionality in the library? | 140 |
natolambert | 2023-02-10T03:24:28 | Yeah @lvwerra it would just be an example / documentation addition I bet.
Or, a more advanced option would be to explain the differences a bit for people too. | 140 |
lewtun | 2023-02-10T08:48:02 | Indeed, no additional training is required from this method, but you still need an optimization loop. One idea would be to wrap that logic in a helper class like `BestOfNSampler`, but starting with a notebook sounds like a good way to go!
Personally, I find the simplicity of the approach really appealing for setting non-PPO baselines :) | 140 |
metric-space | 2023-04-25T05:00:21 | @natolambert was wondering if this up for grabs? | 140 |
natolambert | 2023-04-25T17:00:33 | Haven't done it, happy to review your PR if you make one.
Generally, I had written out psuedo code here
```
query_tensors = [query_tensor]*batch_size
model.generate(query_tensors,
return_prompt=training_args.return_prompt,
generation_config=generation_config,
)
batch["response"] = tokenizer.batch_decode(
response_tensors, skip_special_tokens=training_args.decode_skip_special_tokens # default to True
)
texts = [q + "\n" + r for q, r in zip(batch["query"], batch["response"])]
pipe_outputs = reward_pipe(texts, **reward_pipeline_kwargs)
# Collate the rewards minus the baseline (for zero mean)
rewards = [torch.tensor(output[0]["score"]) for output in pipe_outputs]
best_output_idx = torch.argmax(rewards)
output = batch["response"][best_output_idx]
``` | 140 |
metric-space | 2023-04-27T03:01:29 | @natolambert I have something up as a draft PR https://github.com/lvwerra/trl/pull/326 that implements your pseudo code
I haven't trained anything but pulled down models from huggingface_hub that most likely are models trained from the sentiment notebook (in the examples folder). I may be misunderstanding things but despite implementing I have no clue what the zero mean stuff is showcasing but that could probably be the aftermath of having implemented the general `best-of-n` idea wrong
FYI haven't trained anything as I'm not sure if I'm on the right track and putting training code in the PR is just a matter of copy pasting stuff in from the notebook present in the `examples` folder
As an aside and maybe I'm looking too much into this:
context: from the above conversation
> That would be something you would do after training right?
> Indeed, no additional training is required from this method, but you still need an optimization loop
Aren't both of these contradicting each other or merely two different uses cases of the `best-of-n` idea?
| 140 |
metric-space | 2023-05-02T03:26:34 | Ah, I just realized something. I guess I wasn't sure where exactly in the pipeline I was supposed to be placing the `best-of-n-sampling` and I placed it after the RL part
from the WebGPT paper
> We sampled a fixed number of answers (4, 16 or 64) from
either the BC model or the RL model (if left unspecified, we used the BC model),
I could be mistaken but based off
> I find the simplicity of the approach really appealing for setting non-PPO baselines :)
I think it makes sense to make my PR a ref vs ppo vs non-ppo (best-of) | 140 |
HuggingFaceDocBuilderDev | 2023-02-08T15:26:56 | _The documentation is not available anymore as the PR was closed or merged._ | 139 |
lvwerra | 2023-02-09T14:05:47 | Both runs seem to be converging normally:
GPT2: https://wandb.ai/lvwerra/trl/runs/9ufqpv3w
T5: https://wandb.ai/lvwerra/trl/runs/4rphjty6 | 139 |
HuggingFaceDocBuilderDev | 2023-02-08T15:19:55 | _The documentation is not available anymore as the PR was closed or merged._ | 138 |
HuggingFaceDocBuilderDev | 2023-02-07T13:57:03 | _The documentation is not available anymore as the PR was closed or merged._ | 137 |
HuggingFaceDocBuilderDev | 2023-02-07T13:26:10 | _The documentation is not available anymore as the PR was closed or merged._ | 136 |
younesbelkada | 2023-02-08T10:50:00 | Final runs:
T5: https://wandb.ai/distill-bloom/trl/runs/7bxai1m5?workspace=user-younesbelkada
gpt2: https://wandb.ai/distill-bloom/trl/runs/2453mt4s?workspace=user-younesbelkada | 136 |
lvwerra | 2023-02-07T09:40:30 | Hi @sainathpawar, you should be able to use the saved models directly in `transformers`. See this section in the docs: https://huggingface.co/docs/trl/quickstart#how-to-use-a-trained-model | 135 |
lvwerra | 2023-02-09T15:16:56 | Closing this for now, feel free to re-open if there are any follow-up questions! | 135 |
HuggingFaceDocBuilderDev | 2023-02-07T01:28:25 | _The documentation is not available anymore as the PR was closed or merged._ | 134 |
lvwerra | 2023-02-07T09:11:04 | Thanks for the fixes @natolambert! Happy to integrate all the typo changes. However, for the variable renaming I would suggest leaving that for a major release. It is a breaking change which doesn't benefit the user much. Happy to clarify the docstrings though where necessary! | 134 |
natolambert | 2023-02-07T17:45:01 | Ah, great point. Thanks for teaching me open-source. | 134 |
HuggingFaceDocBuilderDev | 2023-02-06T20:31:41 | The docs for this PR live [here](/static-proxy?url=https%3A%2F%2Fmoon-ci-docs.huggingface.co%2Fdocs%2Ftrl%2Fpr_133). All of your documentation changes will be reflected on that endpoint. | 133 |
younesbelkada | 2023-02-08T10:49:16 | closing the PR in favor of breaking down this in smaller PRs | 133 |
HuggingFaceDocBuilderDev | 2023-02-06T14:37:32 | _The documentation is not available anymore as the PR was closed or merged._ | 132 |
lvwerra | 2023-02-06T18:36:25 | It's actually the same in the T5 script - mind fixing it too? | 132 |
younesbelkada | 2023-02-06T20:26:56 | Thanks! Added it on t5 script and checked that this was not used on the notebooks | 132 |
natolambert | 2023-02-06T21:56:30 | Most of these things are really poorly documented in the RLHF space. If I clean up #119 , could we track all of them there with experiment logs on performance?
A bug fix in the control notebook is being integrated soon #126, so maybe evaluation will get more interesting. | 131 |
lvwerra | 2023-02-07T09:42:53 | Restricting top-p/k can help generating better sequences. We can also play with temperature to force more exotic generations. Beware that if you change the generation temperature you would also need to take this into account when computing the log-probs for the KL-divergence penalty (made that mistake once before 😄). | 131 |
DaehanKim | 2023-02-10T07:37:25 | Thank you guys for the specific comments!
@lvwerra By retricting action space to top-p or top-k, I meant giving entropy loss only considering those vocabs of interests!
i.e. we have 50k vocabs for softmax output. but letting the model explore with naive entropy loss through all those 50k vocabs might cause degeneration of texts by accidentally picking up a low-probability token. So Computing entropy with masked softmax output(that masks out logits not included in top-k or top-p) would help explore only in meaningful vocab spaces.
Also since you mentioned, I was curious why all examples use simple categorical sampling for generation. As I see it, there are kinda standard decoding methods for open-ended generation and short text generations (with reference). These might be p-sampling (or momentum sampling, contrastive search if these can be integrated), and beam search or greedy search with repetition penalty. It would be beneficial to explore how these decoding methods affect RL training dynamics. | 131 |
lvwerra | 2023-02-10T09:37:46 | Main reason I have become quite conservative with sampling during generation is that I got burnt a few times. The main issue is that if you don't sample from the natural distribution of tokens is that there is no guarantee that KL-div term is positive. Since you use it as a penalty the model can exploit negative KL-div (since it effectively becomes a positive reward).
One example where this happened: if you constrain the minimum sequence length the EOS token is excluded from sampling until you reach the minimum length. What happened is that the model learned to assign very high probabilities to that token making the probabilities for all other tokens (including the sampled ones) very low which led to a negative reward. I could imagine similar subtle scenarios for top-p/k sampling but it's worth exploring. | 131 |
DaehanKim | 2023-02-13T12:12:48 | Thank you for sharing your experience. @lvwerra
I think negative KL can be avoided by masking out and then renormalizing each distribution so that they become valid probability distribution again. For instance, `ppo_policy = [0.1,0.1,0.8]` and `ref_policy = [0.05, 0.15, 0.8]` and `word_2` is masked out (for ease of computation). `ppo_policy = [0.1, 0.1] -> [0.5, 0.5]` and `ref_policy = [0.25, 0.75]` can be renormalized to form valid probability distributions. Hopefully this scheme can work in top-k or top-p scenario.
In case of min-length restriction, EOS logit in reference_distribution can also be masked out when comparing KL-div to prevent illegal inflation of EOS probability in ppo agent. (Though this needs subtle implementation and adds complication to the library for sure)
So what I'm thinking for top-p implementation( and anologously to top-k) is to generate responses with top-p scheme first, and logits are masked out with same top-p scheme before computing log probability. I can slightly change topPLogitWarper in transformer library to return logit masks that is applied to ppo agent logits. This same mask can be applied to ref_logits to generate same masked distribution and do log probabilty and kl-div computation. Do you think this is worth trying? | 131 |
DaehanKim | 2023-02-13T12:18:40 | I added entropy regularization in PPOTrainer and ran experiments with `sentiment-control.ipynb` script.
I didn't use any sampling scheme but pure categorical sampling.
Seems like it's not dramatic in this example 😁 but makes agent to explore more (when looking at the lm-head entropy).

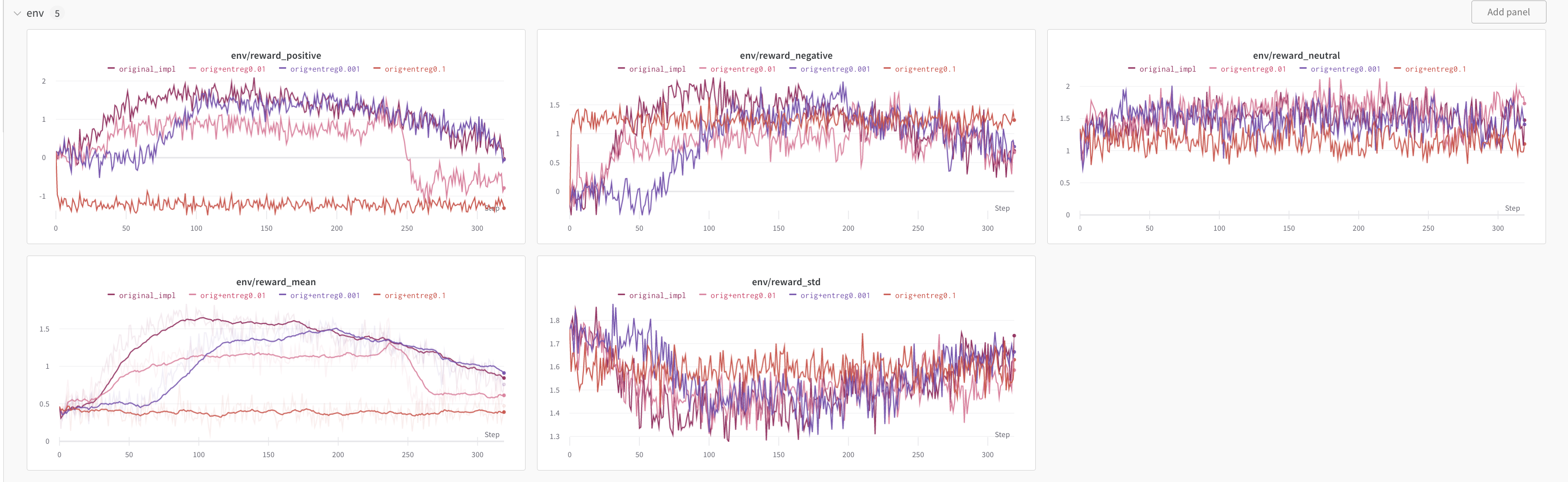
[full wandb chart here](https://wandb.ai/lucas01/trl?workspace=user-lucas01)
| 131 |
lvwerra | 2023-02-14T10:06:44 | Nice set of experiments :) I guess it doesn't help much in that case but it's cool that you managed get it to work! Would you mind sharing the code change necessary? I don't think we want to integrate it into TRL at this point unless there is a sign of improvement but it would be useful to have the code somewhere in case someone wants to run another experiment. | 131 |
DaehanKim | 2023-02-14T12:12:33 | Sure it's a really simple change.
First, you can add `entreg_coef` argument in PPOConfig initializer. [full code](https://github.com/DaehanKim/trl/blob/4f742f9d9a0f931600e5da8d0b5c886d5eb1a7c3/trl/trainer/ppo_config.py#L75-L99
)
```
@dataclass
class PPOConfig(object):
def __init__(
self,
...
entreg_coef: Optional[float] = 0.0, # no entropy regularization by default
...
):
...
self.entreg_coef = entreg_coef
...
```
Second, define your loss as follow : [full code](https://github.com/DaehanKim/trl/blob/4f742f9d9a0f931600e5da8d0b5c886d5eb1a7c3/trl/trainer/ppo_trainer_custom.py#L651-L652)
```
def train_minibatch(
self,
old_logprobs: torch.FloatTensor,
values: torch.FloatTensor,
rewards: torch.FloatTensor,
query: torch.LongTensor,
response: torch.LongTensor,
model_input: torch.LongTensor,
):
...
loss_p, loss_v, loss_ent, train_stats = self.loss(old_logprobs, values, rewards, logits, vpred, logprobs)
loss = loss_p + loss_v + loss_ent
...
```
```
def loss(
self,
old_logprobs: torch.FloatTensor,
values: torch.FloatTensor,
rewards: torch.FloatTensor,
logits: torch.FloatTensor,
vpred: torch.FloatTensor,
logprob: torch.FloatTensor,
):
...
# simply change the order of entropy computation to use it as a loss
# and ent_loss is defined as negative entropy
# it is multiplied with some coefficient and is added to the loss
entropy = torch.mean(entropy_from_logits(logits))
ent_loss = - entropy # negative entropy to be minimised
loss = pg_loss + self.config.vf_coef * vf_loss + self.config.entreg_coef * ent_loss
approxkl = 0.5 * torch.mean((logprob - old_logprobs) ** 2)
policykl = torch.mean(logprob - old_logprobs)
return_mean, return_var = torch.mean(returns), torch.var(returns)
value_mean, value_var = torch.mean(values), torch.var(values)
# and ent_loss is added to the stat dict to plot it in wandb dashboard
stats = dict(
loss=dict(policy=pg_loss, value=vf_loss, ent_loss=ent_loss, total=loss),
...)
```
| 131 |
lvwerra | 2023-02-15T14:32:26 | Thank you! Closing this issue for now, feel free to reopen if you find something new and interesting! | 131 |
leonardtang | 2023-11-17T23:05:12 | Can we add @DaehanKim's change as an official PR? Seems like a critical part of getting PPO to work? | 131 |
RylanSchaeffer | 2024-08-28T13:52:45 | @lvwerra @leonardtang I found this issue because my PPO runs constantly exhibit collapsing entropy:
- In general, is there a standard and generally successful solution to this problem?
- If so, is it already implemented in `TRL`? | 131 |
younesbelkada | 2023-02-02T07:47:26 | Hi @cdxzyc
Thanks for the issue! I suspect there is something wrong with your training loop
Can you share with us how you are training your model using the Trainer?
Thanks | 130 |
lvwerra | 2023-02-03T10:23:35 | So in the PPO setup there are two loops:
- run generation on a batch of prompts in your data. one epoch is one pass through the dataset
- for that batch we run PPO optimization. the `ppo_epochs` specify how many times we optimize on that batch
since generation is expensive you want to get as much out of it as possible so optimizing a batch multiple times helps.
hope this clarifies things! | 129 |
lvwerra | 2023-02-08T10:05:19 | Closing this for now - feel free to reopen if there are more questions! | 129 |
HuggingFaceDocBuilderDev | 2023-02-01T14:33:43 | _The documentation is not available anymore as the PR was closed or merged._ | 128 |
HuggingFaceDocBuilderDev | 2023-02-01T13:40:23 | _The documentation is not available anymore as the PR was closed or merged._ | 127 |
natolambert | 2023-02-01T20:15:42 | Yep, sorry I missed the point on the main init. I see now :). | 127 |
HuggingFaceDocBuilderDev | 2023-01-31T15:53:31 | _The documentation is not available anymore as the PR was closed or merged._ | 126 |
lvwerra | 2023-02-07T09:03:10 | Thanks @natolambert - I actually installed NB Review yesterday but I think we need to open a new PR for it to show the link :) https://app.reviewnb.com/lvwerra/trl/pull/126/ | 126 |
leoribeiro | 2023-03-22T21:15:21 | @lvwerra it seems that if we don't set `"eos_token_id": -1` the model learn gradually to generate shorter outputs. I think setting `"eos_token_id": -1` is not desirable because it makes the model to generate non grammatical text because it forces the generation until the max new tokens is reached. In that way, the model is not useful.
For example, this is a output generated by a RL-trained T5 model with `"eos_token_id": -1` for sampling:
`Three diaspora-based, prominent African activists discuss the current state of women's rights in the continent. In 2010, the African Union launched a decade-long initiative to promote women's empowerment. In 2010, the African Union launched a decade-long initiative to promote women's capabilities. Organizer Paul Valdais has been named "Inspirational Woman of 2012" by the UK group "Women 4 Africa"TIME: MK:'We really hope to be getting focus on justice at the bottom of the media., despite the`
This is the output for the same input example by a T5 model RL-trained without `"eos_token_id": -1` for sampling:
`African Voices talks with three diaspora-based African activist.`
Did you figure it out why T5 model learns to generate shorter inputs with PPO?
| 126 |
aliwalker | 2023-10-13T10:53:10 | > @lvwerra it seems that if we don't set `"eos_token_id": -1` the model learn gradually to generate shorter outputs. I think setting `"eos_token_id": -1` is not desirable because it makes the model to generate non grammatical text because it forces the generation until the max new tokens is reached. In that way, the model is not useful.
>
> For example, this is a output generated by a RL-trained T5 model with `"eos_token_id": -1` for sampling: `Three diaspora-based, prominent African activists discuss the current state of women's rights in the continent. In 2010, the African Union launched a decade-long initiative to promote women's empowerment. In 2010, the African Union launched a decade-long initiative to promote women's capabilities. Organizer Paul Valdais has been named "Inspirational Woman of 2012" by the UK group "Women 4 Africa"TIME: MK:'We really hope to be getting focus on justice at the bottom of the media., despite the`
>
> This is the output for the same input example by a T5 model RL-trained without `"eos_token_id": -1` for sampling: `African Voices talks with three diaspora-based African activist.`
>
> Did you figure it out why T5 model learns to generate shorter inputs with PPO?
Hi @leoribeiro ! I'm struggling with this issue when training on a very long context summarization task. Did you find any workarounds? | 126 |
lvwerra | 2023-02-03T10:28:17 | Unfortunately, I have not much experience with DS. Maybe opening an issue on this in `accelerate` would help. Since this happens at initialization you can write a minimal example:
```python
accelerator = Accelerator()
accelerator.prepare(model, ref_model, optimizer, data_collator, dataloader)
```
I suspect it's the models causing the issue so maybe you can drop the rest:
```python
accelerator.prepare(model)
accelerator.prepare(model, ref_model)
```
to see where the issue is occurring. | 125 |
avacaondata | 2023-02-12T01:59:56 | I think the issue can be closed, it was related with accelerate+deepspeed integration; we cannot use 2 models in the accelerator prepare call with that integration. | 125 |
lvwerra | 2023-02-13T11:33:21 | Ok, that is good to know! @younesbelkada maybe we can fix that in the way we setup models if a DS config was passed. | 125 |
HuggingFaceDocBuilderDev | 2023-01-30T19:38:46 | _The documentation is not available anymore as the PR was closed or merged._ | 124 |
HuggingFaceDocBuilderDev | 2023-01-30T19:33:52 | The docs for this PR live [here](/static-proxy?url=https%3A%2F%2Fmoon-ci-docs.huggingface.co%2Fdocs%2Ftrl%2Fpr_123). All of your documentation changes will be reflected on that endpoint. | 123 |
lvwerra | 2023-02-08T10:15:25 | Closing this for now as we decided not to rename for now :) | 122 |
natolambert | 2023-01-30T19:11:43 | I would guess most of these questions are answered by the fact that the repo was built to closely mirror the "learning to summarize" work. Which of these do you think is more impactful in investigating?
- for 1) you can see the original implementation [here](https://github.com/openai/lm-human-preferences/blob/bd3775f200676e7c9ed438c50727e7452b1a52c1/lm_human_preferences/train_policy.py#LL332C17-L333C96) -- I agree it's worth investigating. | 121 |
DaehanKim | 2023-02-01T16:02:07 | Thank you for answering! I'll check out the original implementation.
[this post](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/) contains answers to many of my question on their implementations!
btw I was not suggesting sth but just curious of implementation details. | 121 |