
llava-hf/llava-onevision-qwen2-72b-ov-hf
Image-Text-to-Text
•
Updated
•
1.58k
•
6
Video-text-to-text models take in a video and a text prompt and output text. These models are also called video-language models.
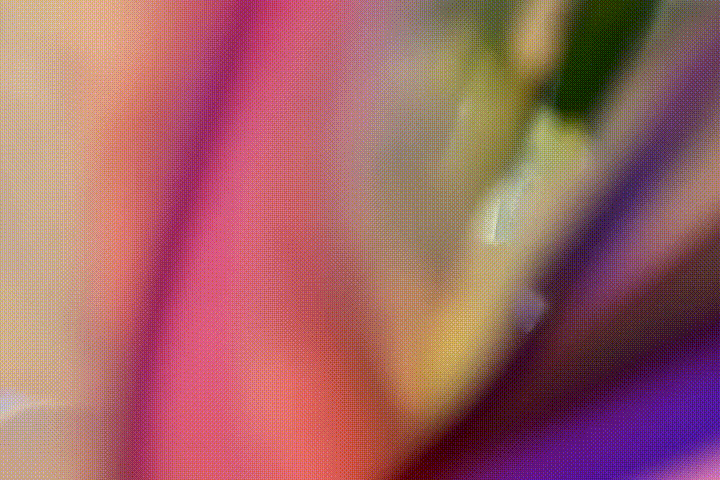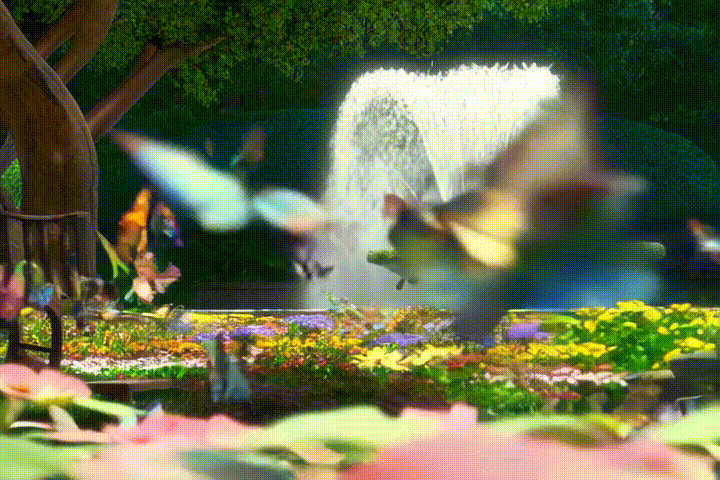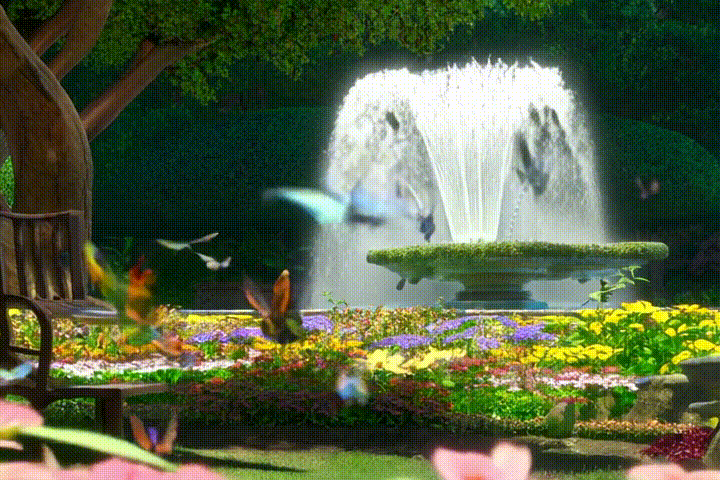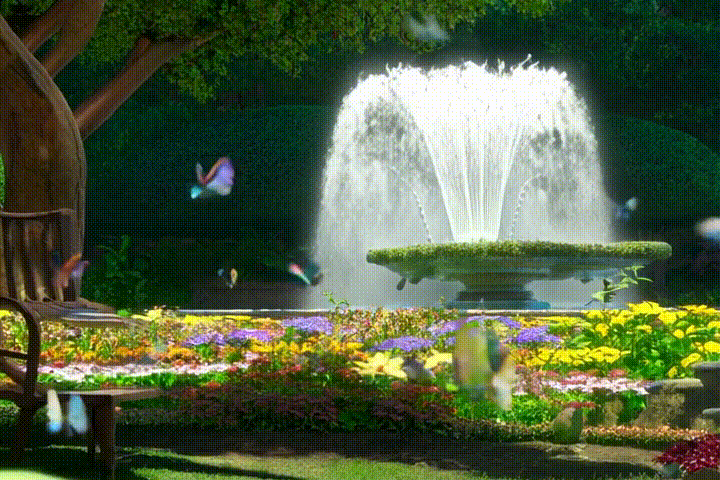
What is happening in this video?
The video shows a series of images showing a fountain with water jets and a variety of colorful flowers and butterflies in the background.
Most of the video language models can take in videos, multiple videos, images and multiple images. Some of these models can also take interleaved inputs, which can have images and videos inside the text, where you can refer to the input images and input videos within the text prompt.
Video language models come in three types:
Video language models trained on video-question-answer pairs can be used for video question answering and generating captions for videos.
Video language models can be used to have a dialogue about a video.
Video language models can recognize images through descriptions. When given detailed descriptions of specific entities, they can classify the entities in a video.
You can use the Transformers library to interact with video-language models.
Below we load a video language model, write a simple utility to sample videos, use chat template to format the text prompt, process the video and the text prompt and infer. To run the snippet below, please install OpenCV by running pip install opencv-python.
import uuid
import requests
import cv2
import torch
from transformers import LlavaNextVideoProcessor, LlavaNextVideoForConditionalGeneration
device = "cuda" if torch.cuda.is_available() else "cpu"
model_id = "llava-hf/LLaVA-NeXT-Video-7B-hf"
model = LlavaNextVideoForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
).to(device)
processor = LlavaNextVideoProcessor.from_pretrained(model_id)
def sample_frames(url, num_frames):
response = requests.get(url)
path_id = str(uuid.uuid4())
path = f"./{path_id}.mp4"
with open(path, "wb") as f:
f.write(response.content)
video = cv2.VideoCapture(path)
total_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
interval = total_frames // num_frames
frames = []
for i in range(total_frames):
ret, frame = video.read()
if not ret:
continue
if i % interval == 0:
pil_img = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
frames.append(pil_img)
video.release()
return frames
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": "Why is this video funny?"},
{"type": "video"},
],
},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
video_url = "https://huggingface.co/spaces/merve/llava-interleave/resolve/main/cats_1.mp4"
video = sample_frames(video, 8)
inputs = processor(text=prompt, videos=video, padding=True, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=100, do_sample=False)
print(processor.decode(output[0][2:], skip_special_tokens=True))
# Why is this video funny? ASSISTANT: The humor in this video comes from the cat's facial expression and body language. The cat appears to be making a funny face, with its eyes squinted and mouth open, which can be interpreted as a playful or mischievous expression. Cats often make such faces when they are in a good mood or are playful, and this can be amusing to people who are familiar with their behavior. The combination of the cat's expression and the close-
No example widget is defined for this task.
Note Contribute by proposing a widget for this task !
Note A robust video-text-to-text model that can take in image and video inputs.
Note Large and powerful video-text-to-text model that can take in image and video inputs.
Note Multiple-choice questions and answers about videos.
Note A dataset of instructions and question-answer pairs about videos.
Note Large video understanding dataset.
Note An application to chat with a video-text-to-text model.
Note A leaderboard for various video-text-to-text models.
No example metric is defined for this task.
Note Contribute by proposing a metric for this task !