Spaces:
Runtime error


Runtime error
Apply for community grant: Personal project
#1
by
deepdml
- opened

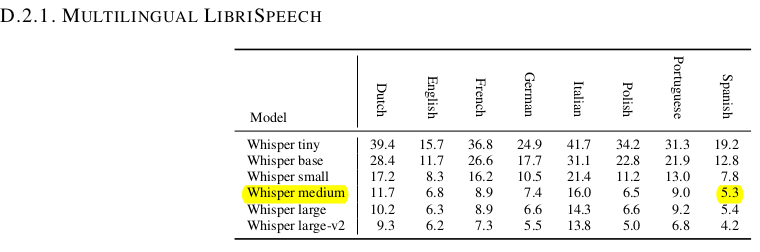
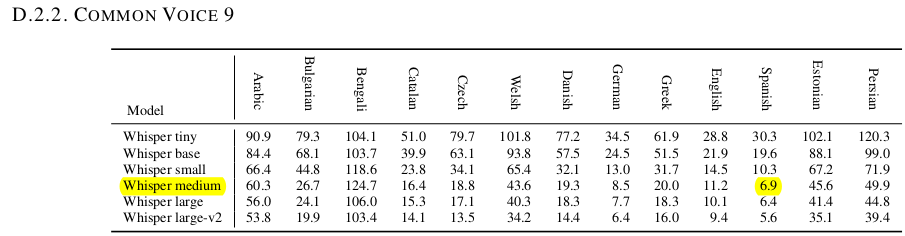
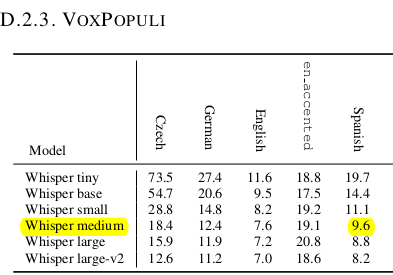
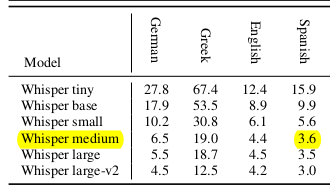
In all cases this fine tuned model WER is better than medium and large spanish version models, except for fleurs dataset (I'm analyzing now why in this case is worse):
- facebook/multilingual_librispeech: 4.66 % WER
- mozilla-foundation/common_voice_11_0: 6.34 %
- facebook/voxpopuli: 8.37 %
- google/fleurs: 4.03 %
I've been comparing the best medium spanish model on the leaderboard, whisper-medium-es, and it looks like having done fine tuning only with common-voice-11 produces an overfitting. Couldn't be the leaderboard the average WER over different test datasets?
