|
--- |
|
title: Synthetic Data Generator |
|
short_description: Build datasets using natural language |
|
emoji: 🧬 |
|
colorFrom: yellow |
|
colorTo: pink |
|
sdk: gradio |
|
sdk_version: 4.44.1 |
|
app_file: app.py |
|
pinned: true |
|
license: apache-2.0 |
|
hf_oauth: true |
|
|
|
hf_oauth_scopes: |
|
- read-repos |
|
- write-repos |
|
- manage-repos |
|
- inference-api |
|
--- |
|
|
|
<h1 align="center"> |
|
<br> |
|
Synthetic Data Generator |
|
<br> |
|
</h1> |
|
<h3 align="center">Build datasets using natural language</h2> |
|
|
|
 |
|
|
|
<p align="center"> |
|
<a href="https://pypi.org/project/synthetic-dataset-generator/"> |
|
<img alt="CI" src="https://img.shields.io/pypi/v/synthetic-dataset-generator.svg?style=flat-round&logo=pypi&logoColor=white"> |
|
</a> |
|
<a href="https://pepy.tech/project/synthetic-dataset-generator"> |
|
<img alt="CI" src="https://static.pepy.tech/personalized-badge/synthetic-dataset-generator?period=month&units=international_system&left_color=grey&right_color=blue&left_text=pypi%20downloads/month"> |
|
</a> |
|
<a href="https://huggingface.co/spaces/argilla/synthetic-data-generator?duplicate=true"> |
|
<img src="https://huggingface.co/datasets/huggingface/badges/raw/main/duplicate-this-space-sm.svg"/> |
|
</a> |
|
</p> |
|
|
|
<p align="center"> |
|
<a href="https://twitter.com/argilla_io"> |
|
<img src="https://img.shields.io/badge/twitter-black?logo=x"/> |
|
</a> |
|
<a href="https://www.linkedin.com/company/argilla-io"> |
|
<img src="https://img.shields.io/badge/linkedin-blue?logo=linkedin"/> |
|
</a> |
|
<a href="http://hf.co/join/discord"> |
|
<img src="https://img.shields.io/badge/Discord-7289DA?&logo=discord&logoColor=white"/> |
|
</a> |
|
</p> |
|
|
|
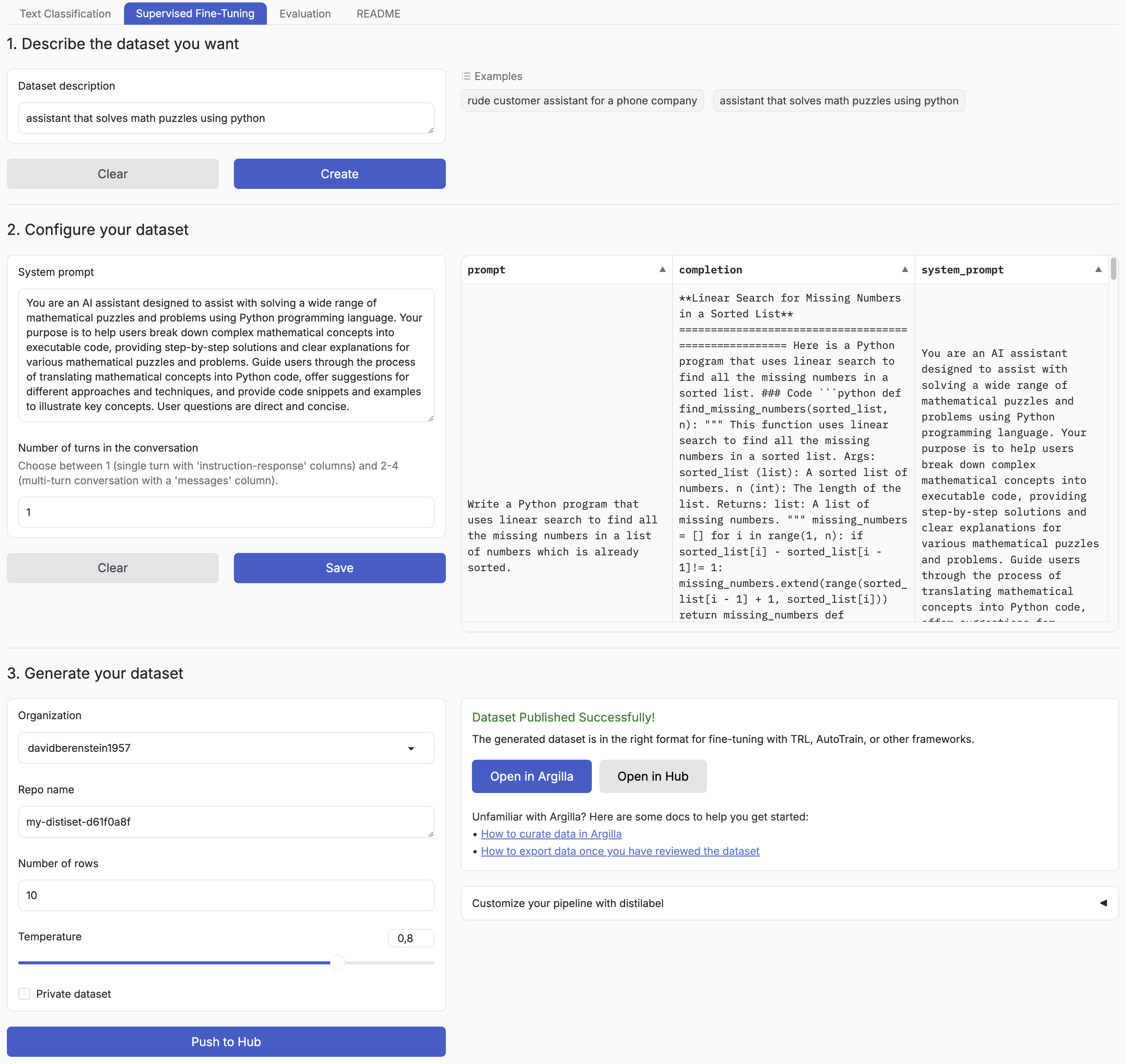
## Introduction |
|
|
|
Synthetic Data Generator is a tool that allows you to create high-quality datasets for training and fine-tuning language models. It leverages the power of distilabel and LLMs to generate synthetic data tailored to your specific needs. |
|
|
|
Supported Tasks: |
|
|
|
- Text Classification |
|
- Supervised Fine-Tuning |
|
- Judging and rationale evaluation |
|
|
|
This tool simplifies the process of creating custom datasets, enabling you to: |
|
|
|
- Describe the characteristics of your desired application |
|
- Iterate on sample datasets |
|
- Produce full-scale datasets |
|
- Push your datasets to the [Hugging Face Hub](https://huggingface.co/datasets?other=datacraft) and/or Argilla |
|
|
|
By using the Synthetic Data Generator, you can rapidly prototype and create datasets for, accelerating your AI development process. |
|
|
|
## Installation |
|
|
|
You can simply install the package with: |
|
|
|
```bash |
|
pip install synthetic-dataset-generator |
|
``` |
|
|
|
### Environment Variables |
|
|
|
- `HF_TOKEN`: Your Hugging Face token to push your datasets to the Hugging Face Hub and run Inference Endpoints Requests. You can get one [here](https://huggingface.co/settings/tokens/new?ownUserPermissions=repo.content.read&ownUserPermissions=repo.write&globalPermissions=inference.serverless.write&tokenType=fineGrained). |
|
- `ARGILLA_API_KEY`: Your Argilla API key to push your datasets to Argilla. |
|
- `ARGILLA_API_URL`: Your Argilla API URL to push your datasets to Argilla. |
|
|
|
## Quickstart |
|
|
|
```bash |
|
python app.py |
|
``` |
|
|
|
## Custom synthetic data generation? |
|
|
|
Each pipeline is based on distilabel, so you can easily change the LLM or the pipeline steps. |
|
|
|
Check out the [distilabel library](https://github.com/argilla-io/distilabel) for more information. |
|
|

