|
--- |
|
tags: |
|
- model_hub_mixin |
|
- pytorch_model_hub_mixin |
|
pipeline_tag: tabular-regression |
|
library_name: pytorch |
|
datasets: |
|
- gvlassis/california_housing |
|
metrics: |
|
- rmse |
|
--- |
|
|
|
# wide-and-deep-net-california-housing-v3 |
|
|
|
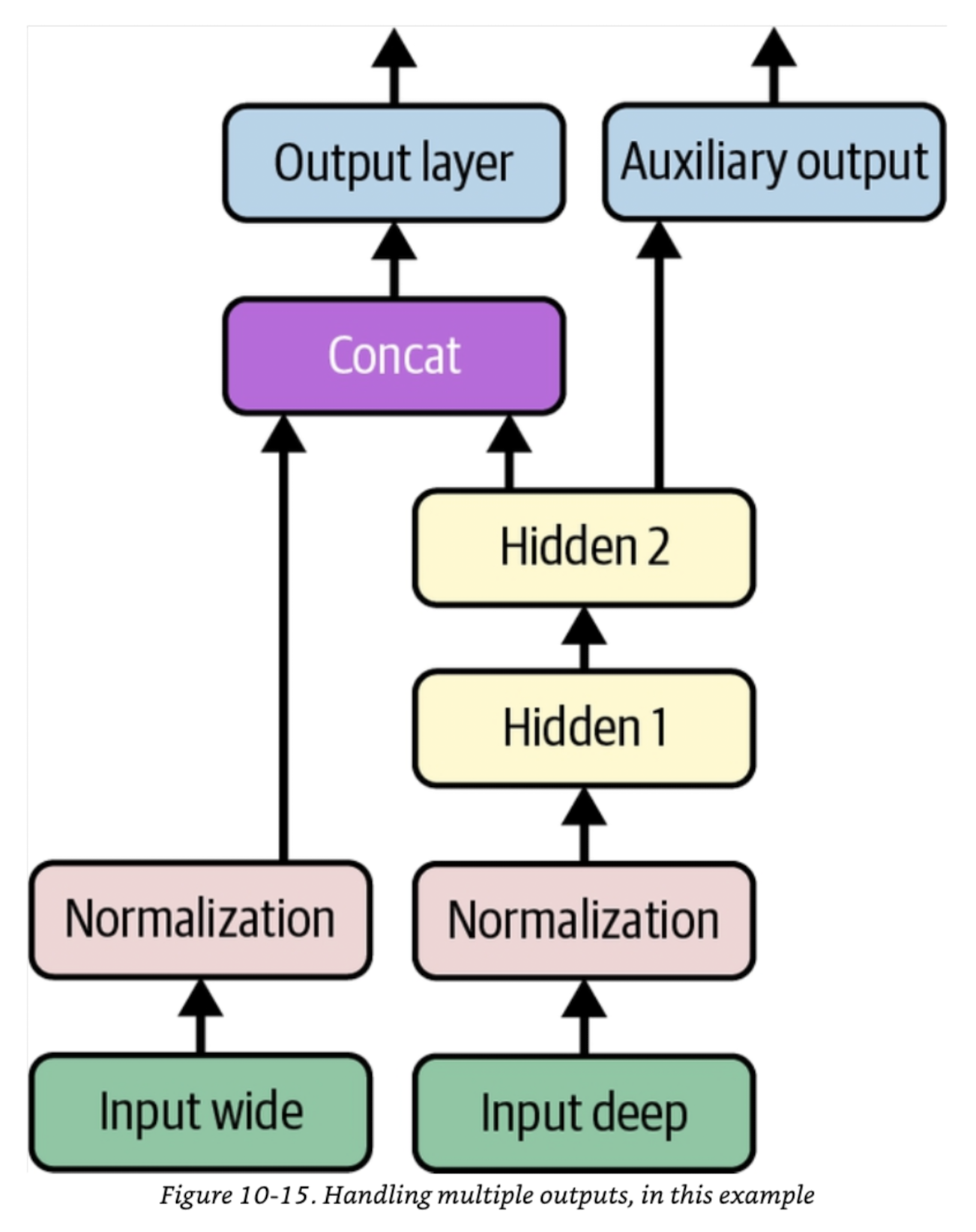
A wide & deep neural network trained on the California Housing dataset. It is a PyTorch adaptation of the TensorFlow model in Chapter 10 of Aurelien Geron's book 'Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow'. |
|
|
|
 |
|
|
|
The model takes eight features: `'MedInc'`, `'HouseAge'`, `'AveRooms'`, `'AveBedrms'`, `'Population'`, `'AveOccup'`, `'Latitude'` and `'Longitude'`. It predicts `'MedHouseVal'`. |
|
|
|
The first five features (`'MedInc'`, `'HouseAge'`, `'AveRooms'`, `'AveBedrms'` and `'Population'`) flow through the wide path. |
|
|
|
The last six features (`'AveRooms'`, `'AveBedrms'`, `'Population'`, `'AveOccup'`, `'Latitude'` and `'Longitude'`) flow through the deep path. |
|
|
|
Note: The features `'AveRooms'`, `'AveBedrms'` and `'Population'` flow through both the wide path and the deep path. |
|
|
|
The model also has an auxiliary head. The main head and the auxiliary head output the same thing (`'MedHouseVal'`). As mentioned in the book, this is a regularization technique, to try and ensure that the "underlying part of the network" (i.e., the deep path) learns something useful on its own, without relying on the rest of the network. |
|
|
|
Code: https://github.com/sambitmukherjee/handson-ml3-pytorch/blob/main/chapter10/wide_and_deep_net_california_housing_v3.ipynb |
|
|
|
Experiment tracking: https://wandb.ai/sadhaklal/wide-and-deep-net-california-housing |
|
|
|
## Usage |
|
|
|
``` |
|
from sklearn.datasets import fetch_california_housing |
|
|
|
housing = fetch_california_housing(as_frame=True) |
|
|
|
from sklearn.model_selection import train_test_split |
|
|
|
X_train_full, X_test, y_train_full, y_test = train_test_split(housing['data'], housing['target'], test_size=0.25, random_state=42) |
|
X_train, X_valid, y_train, y_valid = train_test_split(X_train_full, y_train_full, test_size=0.25, random_state=42) |
|
|
|
X_means, X_stds = X_train.mean(axis=0), X_train.std(axis=0) |
|
X_train = (X_train - X_means) / X_stds |
|
X_valid = (X_valid - X_means) / X_stds |
|
X_test = (X_test - X_means) / X_stds |
|
|
|
import torch |
|
|
|
device = torch.device("cpu") |
|
|
|
from dataclasses import dataclass |
|
from typing import Optional |
|
|
|
@dataclass |
|
class WideAndDeepNetOutput: |
|
main_output: torch.Tensor |
|
aux_output: torch.Tensor |
|
main_loss: Optional[torch.Tensor] = None |
|
aux_loss: Optional[torch.Tensor] = None |
|
loss: Optional[torch.Tensor] = None |
|
|
|
import torch.nn as nn |
|
from huggingface_hub import PyTorchModelHubMixin |
|
|
|
class WideAndDeepNet(nn.Module, PyTorchModelHubMixin): |
|
def __init__(self): |
|
super().__init__() |
|
self.hidden1 = nn.Linear(6, 30) |
|
self.hidden2 = nn.Linear(30, 30) |
|
self.main_head = nn.Linear(35, 1) |
|
self.aux_head = nn.Linear(30, 1) |
|
self.main_loss_fn = nn.MSELoss(reduction='sum') |
|
self.aux_loss_fn = nn.MSELoss(reduction='sum') |
|
|
|
def forward(self, input_wide, input_deep, label=None): |
|
act = torch.relu(self.hidden1(input_deep)) |
|
act = torch.relu(self.hidden2(act)) |
|
concat = torch.cat([input_wide, act], dim=1) |
|
main_output = self.main_head(concat) |
|
aux_output = self.aux_head(act) |
|
if label is not None: |
|
main_loss = self.main_loss_fn(main_output.squeeze(), label) |
|
aux_loss = self.aux_loss_fn(aux_output.squeeze(), label) |
|
loss = 0.9 * main_loss + 0.1 * aux_loss |
|
return WideAndDeepNetOutput(main_output, aux_output, main_loss, aux_loss, loss) |
|
else: |
|
return WideAndDeepNetOutput(main_output, aux_output) |
|
|
|
model = WideAndDeepNet.from_pretrained("sadhaklal/wide-and-deep-net-california-housing-v3") |
|
model.to(device) |
|
model.eval() |
|
|
|
# Let's predict on 3 unseen examples from the test set: |
|
print(f"Ground truth housing prices: {y_test.values[:3]}") |
|
new = { |
|
'input_wide': torch.tensor(X_test.values[:3, :5], dtype=torch.float32), |
|
'input_deep': torch.tensor(X_test.values[:3, 2:], dtype=torch.float32) |
|
} |
|
new = {k: v.to(device) for k, v in new.items()} |
|
with torch.no_grad(): |
|
output = model(**new) |
|
print(f"Predicted housing prices: {output.main_output.squeeze()}") |
|
``` |
|
|
|
## Metric |
|
|
|
RMSE on the test set: 0.574 |
|
|
|
--- |
|
|
|
This model has been pushed to the Hub using the [PyTorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration. |
