KTO Trainer
Overview
Kahneman-Tversky Optimization (KTO) was introduced in KTO: Model Alignment as Prospect Theoretic Optimization by Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, Douwe Kiela.
The abstract from the paper is the following:
Kahneman & Tversky’s prospect theory tells us that humans perceive random variables in a biased but well-defined manner; for example, humans are famously loss-averse. We show that objectives for aligning LLMs with human feedback implicitly incorporate many of these biases — the success of these objectives (e.g., DPO) over cross-entropy minimization can partly be ascribed to them being human-aware loss functions (HALOs). However, the utility functions these methods attribute to humans still differ from those in the prospect theory literature. Using a Kahneman-Tversky model of human utility, we propose a HALO that directly maximizes the utility of generations instead of maximizing the log-likelihood of preferences, as current methods do. We call this approach Kahneman-Tversky Optimization (KTO), and it matches or exceeds the performance of preference-based methods at scales from 1B to 30B. Crucially, KTO does not need preferences — only a binary signal of whether an output is desirable or undesirable for a given input. This makes it far easier to use in the real world, where preference data is scarce and expensive.
The official code can be found in ContextualAI/HALOs.
This post-training method was contributed by Kashif Rasul, Younes Belkada, Lewis Tunstall and Pablo Vicente.
Quick start
This example demonstrates how to train a model using the KTO method. We use the Qwen 0.5B model as the base model. We use the preference data from the KTO Mix 14k. You can view the data in the dataset here:
Below is the script to train the model:
# train_kto.py
from datasets import load_dataset
from trl import KTOConfig, KTOTrainer
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
train_dataset = load_dataset("trl-lib/kto-mix-14k", split="train")
training_args = KTOConfig(output_dir="Qwen2-0.5B-KTO", logging_steps=10)
trainer = KTOTrainer(model=model, args=training_args, processing_class=tokenizer, train_dataset=train_dataset)
trainer.train()Execute the script using the following command:
accelerate launch train_kto.py
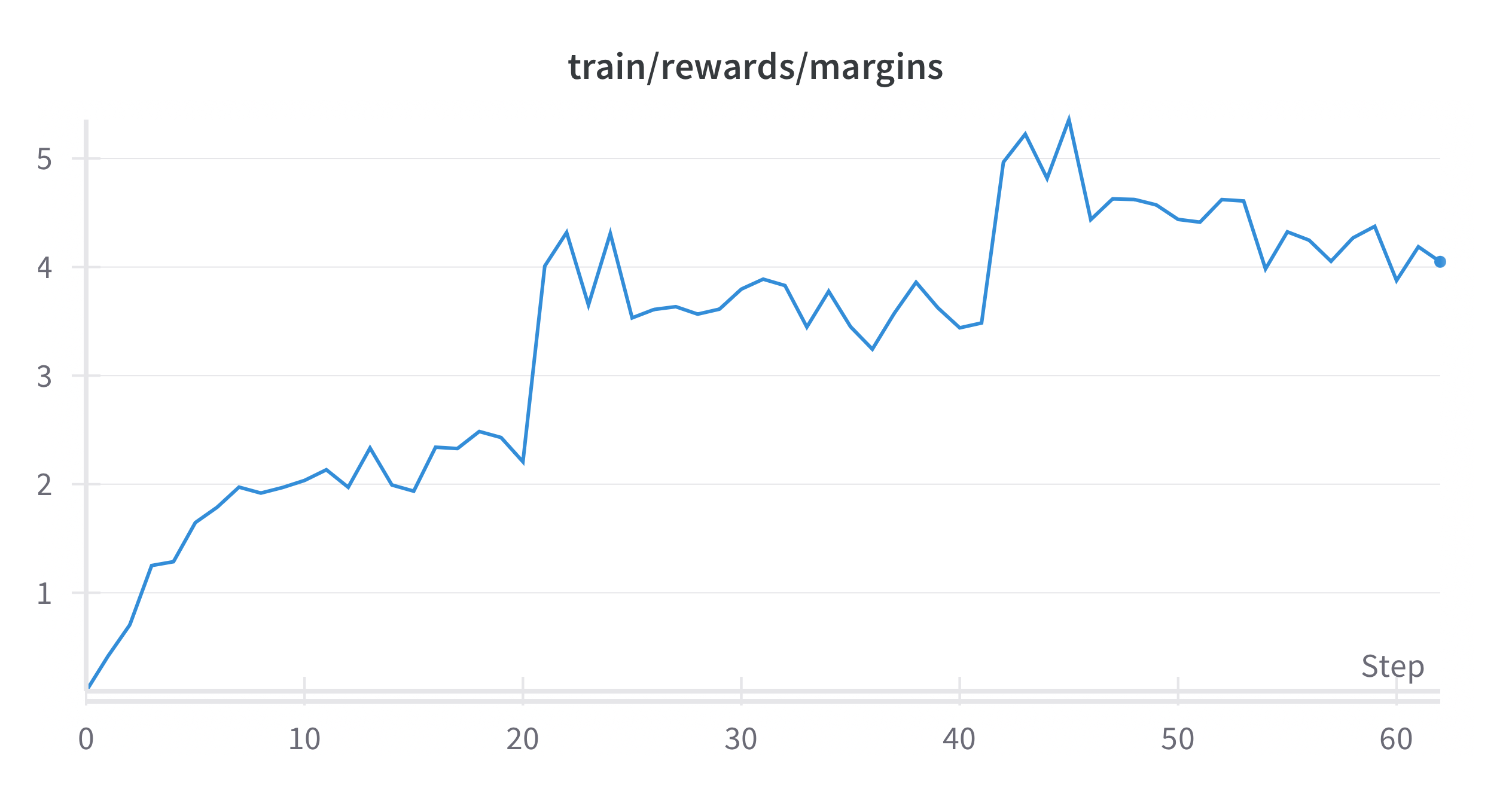
Distributed across 8 x H100 GPUs, the training takes approximately 30 minutes. You can verify the training progress by checking the reward graph. An increasing trend in the reward margin indicates that the model is improving and generating better responses over time.
To see how the trained model performs, you can use the TRL Chat CLI.
$ trl chat --model_name_or_path trl-lib/Qwen2-0.5B-KTO
<quentin_gallouedec>:
What is the best programming language?
<trl-lib/Qwen2-0.5B-KTO>:
The best programming language can vary depending on individual preferences, industry-specific requirements, technical skills, and familiarity with the specific use case or task. Here are some widely-used programming languages that have been noted as popular and widely used:
Here are some other factors to consider when choosing a programming language for a project:
1 JavaScript: JavaScript is at the heart of the web and can be used for building web applications, APIs, and interactive front-end applications like frameworks like React and Angular. It's similar to C, C++, and F# in syntax structure and is accessible and easy to learn, making it a popular choice for beginners and professionals alike.
2 Java: Known for its object-oriented programming (OOP) and support for Java 8 and .NET, Java is used for developing enterprise-level software applications, high-performance games, as well as mobile apps, game development, and desktop applications.
3 C++: Known for its flexibility and scalability, C++ offers comprehensive object-oriented programming and is a popular choice for high-performance computing and other technical fields. It's a powerful platform for building real-world applications and games at scale.
4 Python: Developed by Guido van Rossum in 1991, Python is a high-level, interpreted, and dynamically typed language known for its simplicity, readability, and versatility.
Expected dataset format
KTO requires an unpaired preference dataset. Alternatively, you can provide a paired preference dataset (also known simply as a preference dataset). In this case, the trainer will automatically convert it to an unpaired format by separating the chosen and rejected responses, assigning label = True to the chosen completions and label = False to the rejected ones.
The KTOTrainer supports both conversational and standard dataset format. When provided with a conversational dataset, the trainer will automatically apply the chat template to the dataset.
In theory, the dataset should contain at least one chosen and one rejected completion. However, some users have successfully run KTO using only chosen or only rejected data. If using only rejected data, it is advisable to adopt a conservative learning rate.
Example script
We provide an example script to train a model using the KTO method. The script is available in trl/scripts/kto.py
To test the KTO script with the Qwen2 0.5B model on the UltraFeedback dataset, run the following command:
accelerate launch trl/scripts/kto.py \
--model_name_or_path Qwen/Qwen2-0.5B-Instruct \
--dataset_name trl-lib/kto-mix-14k \
--num_train_epochs 1 \
--logging_steps 25 \
--output_dir Qwen2-0.5B-KTOUsage tips
For Mixture of Experts Models: Enabling the auxiliary loss
MOEs are the most efficient if the load is about equally distributed between experts.
To ensure that we train MOEs similarly during preference-tuning, it is beneficial to add the auxiliary loss from the load balancer to the final loss.
This option is enabled by setting output_router_logits=True in the model config (e.g. MixtralConfig).
To scale how much the auxiliary loss contributes to the total loss, use the hyperparameter router_aux_loss_coef=... (default: 0.001) in the model config.
Batch size recommendations
Use a per-step batch size that is at least 4, and an effective batch size between 16 and 128. Even if your effective batch size is large, if your per-step batch size is poor, then the KL estimate in KTO will be poor.
Learning rate recommendations
Each choice of beta has a maximum learning rate it can tolerate before learning performance degrades. For the default setting of beta = 0.1, the learning rate should typically not exceed 1e-6 for most models. As beta decreases, the learning rate should also be reduced accordingly. In general, we strongly recommend keeping the learning rate between 5e-7 and 5e-6. Even with small datasets, we advise against using a learning rate outside this range. Instead, opt for more epochs to achieve better results.
Imbalanced data
The desirable_weight and undesirable_weight of the KTOConfig refer to the weights placed on the losses for desirable/positive and undesirable/negative examples.
By default, they are both 1. However, if you have more of one or the other, then you should upweight the less common type such that the ratio of (desirable_weight number of positives) to (undesirable_weight number of negatives) is in the range 1:1 to 4:3.
Logged metrics
While training and evaluating we record the following reward metrics:
rewards/chosen: the mean log probabilities of the policy model for the chosen responses scaled by betarewards/rejected: the mean log probabilities of the policy model for the rejected responses scaled by betarewards/margins: the mean difference between the chosen and corresponding rejected rewardslogps/chosen: the mean log probabilities of the chosen completionslogps/rejected: the mean log probabilities of the rejected completionslogits/chosen: the mean logits of the chosen completionslogits/rejected: the mean logits of the rejected completionskl: the KL divergence between the policy model and the reference model
KTOTrainer
class trl.KTOTrainer
< source >( model: typing.Union[transformers.modeling_utils.PreTrainedModel, torch.nn.modules.module.Module, str] = None ref_model: typing.Union[transformers.modeling_utils.PreTrainedModel, torch.nn.modules.module.Module, str, NoneType] = None args: KTOConfig = None train_dataset: typing.Optional[datasets.arrow_dataset.Dataset] = None eval_dataset: typing.Union[datasets.arrow_dataset.Dataset, dict[str, datasets.arrow_dataset.Dataset], NoneType] = None processing_class: typing.Union[transformers.tokenization_utils_base.PreTrainedTokenizerBase, transformers.image_processing_utils.BaseImageProcessor, transformers.feature_extraction_utils.FeatureExtractionMixin, transformers.processing_utils.ProcessorMixin, NoneType] = None data_collator: typing.Optional[transformers.data.data_collator.DataCollator] = None model_init: typing.Optional[typing.Callable[[], transformers.modeling_utils.PreTrainedModel]] = None callbacks: typing.Optional[list[transformers.trainer_callback.TrainerCallback]] = None optimizers: tuple = (None, None) preprocess_logits_for_metrics: typing.Optional[typing.Callable[[torch.Tensor, torch.Tensor], torch.Tensor]] = None peft_config: typing.Optional[dict] = None compute_metrics: typing.Optional[typing.Callable[[transformers.trainer_utils.EvalLoopOutput], dict]] = None model_adapter_name: typing.Optional[str] = None ref_adapter_name: typing.Optional[str] = None )
Parameters
- model (
transformers.PreTrainedModel) — The model to train, preferably anAutoModelForSequenceClassification. - ref_model (
PreTrainedModelWrapper) — Hugging Face transformer model with a casual language modelling head. Used for implicit reward computation and loss. If no reference model is provided, the trainer will create a reference model with the same architecture as the model to be optimized. - args (
KTOConfig) — The arguments to use for training. - train_dataset (
datasets.Dataset) — The dataset to use for training. - eval_dataset (
datasets.Dataset) — The dataset to use for evaluation. - processing_class (
PreTrainedTokenizerBaseorBaseImageProcessororFeatureExtractionMixinorProcessorMixin, optional) — Processing class used to process the data. If provided, will be used to automatically process the inputs for the model, and it will be saved along the model to make it easier to rerun an interrupted training or reuse the fine-tuned model. - data_collator (
transformers.DataCollator, optional, defaults toNone) — The data collator to use for training. If None is specified, the default data collator (DPODataCollatorWithPadding) will be used which will pad the sequences to the maximum length of the sequences in the batch, given a dataset of paired sequences. - model_init (
Callable[[], transformers.PreTrainedModel]) — The model initializer to use for training. If None is specified, the default model initializer will be used. - callbacks (
list[transformers.TrainerCallback]) — The callbacks to use for training. - optimizers (
tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR]) — The optimizer and scheduler to use for training. - preprocess_logits_for_metrics (
Callable[[torch.Tensor, torch.Tensor], torch.Tensor]) — The function to use to preprocess the logits before computing the metrics. - peft_config (
dict, defaults toNone) — The PEFT configuration to use for training. If you pass a PEFT configuration, the model will be wrapped in a PEFT model. - disable_dropout (
bool, defaults toTrue) — Whether or not to disable dropouts inmodelandref_model. - compute_metrics (
Callable[[EvalPrediction], dict], optional) — The function to use to compute the metrics. Must take aEvalPredictionand return a dictionary string to metric values. - model_adapter_name (
str, defaults toNone) — Name of the train target PEFT adapter, when using LoRA with multiple adapters. - ref_adapter_name (
str, defaults toNone) — Name of the reference PEFT adapter, when using LoRA with multiple adapters.
Initialize KTOTrainer.
Computes log probabilities of the reference model for a single padded batch of a KTO specific dataset.
create_model_card
< source >( model_name: typing.Optional[str] = None dataset_name: typing.Optional[str] = None tags: typing.Union[str, list[str], NoneType] = None )
Creates a draft of a model card using the information available to the Trainer.
evaluation_loop
< source >( dataloader: DataLoader description: str prediction_loss_only: typing.Optional[bool] = None ignore_keys: typing.Optional[list[str]] = None metric_key_prefix: str = 'eval' )
Overriding built-in evaluation loop to store metrics for each batch.
Prediction/evaluation loop, shared by Trainer.evaluate() and Trainer.predict().
Works both with or without labels.
Generate samples from the model and reference model for the given batch of inputs.
get_batch_logps
< source >( logits: FloatTensor labels: LongTensor average_log_prob: bool = False label_pad_token_id: int = -100 is_encoder_decoder: bool = False )
Parameters
- logits — Logits of the model (unnormalized). Shape: (batch_size, sequence_length, vocab_size)
- labels — Labels for which to compute the log probabilities. Label tokens with a value of label_pad_token_id are ignored. Shape: (batch_size, sequence_length)
- average_log_prob — If True, return the average log probability per (non-masked) token. Otherwise, return the sum of the log probabilities of the (non-masked) tokens.
Compute the log probabilities of the given labels under the given logits.
Compute the KTO loss and other metrics for the given batch of inputs for train or test.
get_eval_dataloader
< source >( eval_dataset: typing.Optional[datasets.arrow_dataset.Dataset] = None )
Parameters
- eval_dataset (
torch.utils.data.Dataset, optional) — If provided, will overrideself.eval_dataset. If it is a Dataset, columns not accepted by themodel.forward()method are automatically removed. It must implement__len__.
Returns the evaluation ~torch.utils.data.DataLoader.
Subclass of transformers.src.transformers.trainer.get_eval_dataloader to precompute ref_log_probs.
Returns the training ~torch.utils.data.DataLoader.
Subclass of transformers.src.transformers.trainer.get_train_dataloader to precompute ref_log_probs.
kto_loss
< source >( policy_chosen_logps: FloatTensor policy_rejected_logps: FloatTensor policy_KL_logps: FloatTensor reference_chosen_logps: FloatTensor reference_rejected_logps: FloatTensor reference_KL_logps: FloatTensor ) → A tuple of four tensors
Parameters
- policy_chosen_logps — Log probabilities of the policy model for the chosen responses. Shape: (num(chosen) in batch_size,)
- policy_rejected_logps — Log probabilities of the policy model for the rejected responses. Shape: (num(rejected) in batch_size,)
- policy_KL_logps — Log probabilities of the policy model for the KL responses. Shape: (batch_size,)
- reference_chosen_logps — Log probabilities of the reference model for the chosen responses. Shape: (num(chosen) in batch_size,)
- reference_rejected_logps — Log probabilities of the reference model for the rejected responses. Shape: (num(rejected) in batch_size,)
- reference_KL_logps — Log probabilities of the reference model for the KL responses. Shape: (batch_size,)
Returns
A tuple of four tensors
(losses, chosen_rewards, rejected_rewards, KL). The losses tensor contains the KTO loss for each example in the batch. The chosen_rewards and rejected_rewards tensors contain the rewards for the chosen and rejected responses, respectively. The KL tensor contains the detached KL divergence estimate between the policy and reference models.
Compute the KTO loss for a batch of policy and reference model log probabilities.
log
< source >( logs: dict start_time: typing.Optional[float] = None )
Log logs on the various objects watching training, including stored metrics.
Context manager for handling null reference model (that is, peft adapter manipulation).
KTOConfig
class trl.KTOConfig
< source >( output_dir: str overwrite_output_dir: bool = False do_train: bool = False do_eval: bool = False do_predict: bool = False eval_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = 'no' prediction_loss_only: bool = False per_device_train_batch_size: int = 8 per_device_eval_batch_size: int = 8 per_gpu_train_batch_size: typing.Optional[int] = None per_gpu_eval_batch_size: typing.Optional[int] = None gradient_accumulation_steps: int = 1 eval_accumulation_steps: typing.Optional[int] = None eval_delay: typing.Optional[float] = 0 torch_empty_cache_steps: typing.Optional[int] = None learning_rate: float = 1e-06 weight_decay: float = 0.0 adam_beta1: float = 0.9 adam_beta2: float = 0.999 adam_epsilon: float = 1e-08 max_grad_norm: float = 1.0 num_train_epochs: float = 3.0 max_steps: int = -1 lr_scheduler_type: typing.Union[transformers.trainer_utils.SchedulerType, str] = 'linear' lr_scheduler_kwargs: typing.Union[dict, str, NoneType] = <factory> warmup_ratio: float = 0.0 warmup_steps: int = 0 log_level: typing.Optional[str] = 'passive' log_level_replica: typing.Optional[str] = 'warning' log_on_each_node: bool = True logging_dir: typing.Optional[str] = None logging_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = 'steps' logging_first_step: bool = False logging_steps: float = 500 logging_nan_inf_filter: bool = True save_strategy: typing.Union[transformers.trainer_utils.SaveStrategy, str] = 'steps' save_steps: float = 500 save_total_limit: typing.Optional[int] = None save_safetensors: typing.Optional[bool] = True save_on_each_node: bool = False save_only_model: bool = False restore_callback_states_from_checkpoint: bool = False no_cuda: bool = False use_cpu: bool = False use_mps_device: bool = False seed: int = 42 data_seed: typing.Optional[int] = None jit_mode_eval: bool = False use_ipex: bool = False bf16: bool = False fp16: bool = False fp16_opt_level: str = 'O1' half_precision_backend: str = 'auto' bf16_full_eval: bool = False fp16_full_eval: bool = False tf32: typing.Optional[bool] = None local_rank: int = -1 ddp_backend: typing.Optional[str] = None tpu_num_cores: typing.Optional[int] = None tpu_metrics_debug: bool = False debug: typing.Union[str, typing.List[transformers.debug_utils.DebugOption]] = '' dataloader_drop_last: bool = False eval_steps: typing.Optional[float] = None dataloader_num_workers: int = 0 dataloader_prefetch_factor: typing.Optional[int] = None past_index: int = -1 run_name: typing.Optional[str] = None disable_tqdm: typing.Optional[bool] = None remove_unused_columns: typing.Optional[bool] = True label_names: typing.Optional[typing.List[str]] = None load_best_model_at_end: typing.Optional[bool] = False metric_for_best_model: typing.Optional[str] = None greater_is_better: typing.Optional[bool] = None ignore_data_skip: bool = False fsdp: typing.Union[typing.List[transformers.trainer_utils.FSDPOption], str, NoneType] = '' fsdp_min_num_params: int = 0 fsdp_config: typing.Union[dict, str, NoneType] = None fsdp_transformer_layer_cls_to_wrap: typing.Optional[str] = None accelerator_config: typing.Union[dict, str, NoneType] = None deepspeed: typing.Union[dict, str, NoneType] = None label_smoothing_factor: float = 0.0 optim: typing.Union[transformers.training_args.OptimizerNames, str] = 'adamw_torch' optim_args: typing.Optional[str] = None adafactor: bool = False group_by_length: bool = False length_column_name: typing.Optional[str] = 'length' report_to: typing.Union[NoneType, str, typing.List[str]] = None ddp_find_unused_parameters: typing.Optional[bool] = None ddp_bucket_cap_mb: typing.Optional[int] = None ddp_broadcast_buffers: typing.Optional[bool] = None dataloader_pin_memory: bool = True dataloader_persistent_workers: bool = False skip_memory_metrics: bool = True use_legacy_prediction_loop: bool = False push_to_hub: bool = False resume_from_checkpoint: typing.Optional[str] = None hub_model_id: typing.Optional[str] = None hub_strategy: typing.Union[transformers.trainer_utils.HubStrategy, str] = 'every_save' hub_token: typing.Optional[str] = None hub_private_repo: typing.Optional[bool] = None hub_always_push: bool = False gradient_checkpointing: bool = False gradient_checkpointing_kwargs: typing.Union[dict, str, NoneType] = None include_inputs_for_metrics: bool = False include_for_metrics: typing.List[str] = <factory> eval_do_concat_batches: bool = True fp16_backend: str = 'auto' evaluation_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = None push_to_hub_model_id: typing.Optional[str] = None push_to_hub_organization: typing.Optional[str] = None push_to_hub_token: typing.Optional[str] = None mp_parameters: str = '' auto_find_batch_size: bool = False full_determinism: bool = False torchdynamo: typing.Optional[str] = None ray_scope: typing.Optional[str] = 'last' ddp_timeout: typing.Optional[int] = 1800 torch_compile: bool = False torch_compile_backend: typing.Optional[str] = None torch_compile_mode: typing.Optional[str] = None dispatch_batches: typing.Optional[bool] = None split_batches: typing.Optional[bool] = None include_tokens_per_second: typing.Optional[bool] = False include_num_input_tokens_seen: typing.Optional[bool] = False neftune_noise_alpha: typing.Optional[float] = None optim_target_modules: typing.Union[NoneType, str, typing.List[str]] = None batch_eval_metrics: bool = False eval_on_start: bool = False use_liger_kernel: typing.Optional[bool] = False eval_use_gather_object: typing.Optional[bool] = False average_tokens_across_devices: typing.Optional[bool] = False max_length: typing.Optional[int] = None max_prompt_length: typing.Optional[int] = None max_completion_length: typing.Optional[int] = None beta: float = 0.1 loss_type: typing.Literal['kto', 'apo_zero_unpaired'] = 'kto' desirable_weight: float = 1.0 undesirable_weight: float = 1.0 label_pad_token_id: int = -100 padding_value: typing.Optional[int] = None truncation_mode: str = 'keep_end' generate_during_eval: bool = False is_encoder_decoder: typing.Optional[bool] = None disable_dropout: bool = True precompute_ref_log_probs: bool = False model_init_kwargs: typing.Optional[dict[str, typing.Any]] = None ref_model_init_kwargs: typing.Optional[dict[str, typing.Any]] = None dataset_num_proc: typing.Optional[int] = None )
Parameters
- learning_rate (
float, optional, defaults to5e-7) — Initial learning rate forAdamWoptimizer. The default value replaces that of TrainingArguments. - max_length (
Optional[int], optional, defaults toNone) — Maximum length of the sequences (prompt + completion) in the batch. This argument is required if you want to use the default data collator. - max_prompt_length (
Optional[int], optional, defaults toNone) — Maximum length of the prompt. This argument is required if you want to use the default data collator. - max_completion_length (
Optional[int], optional, defaults toNone) — Maximum length of the completion. This argument is required if you want to use the default data collator and your model is an encoder-decoder. - beta (
float, optional, defaults to0.1) — Parameter controlling the deviation from the reference model. Higher β means less deviation from the reference model. - loss_type (
str, optional, defaults to"kto") — Type of loss to use. Possible values are: - desirable_weight (
float, optional, defaults to1.0) — Desirable losses are weighed by this factor to counter unequal number of desirable and undesirable paris. - undesirable_weight (
float, optional, defaults to1.0) — Undesirable losses are weighed by this factor to counter unequal number of desirable and undesirable pairs. - label_pad_token_id (
int, optional, defaults to-100) — Label pad token id. This argument is required if you want to use the default data collator. - padding_value (
Optional[int], optional, defaults toNone) — Padding value to use. IfNone, the padding value of the tokenizer is used. - truncation_mode (
str, optional, defaults to"keep_end") — Truncation mode to use when the prompt is too long. Possible values are"keep_end"or"keep_start". This argument is required if you want to use the default data collator. - generate_during_eval (
bool, optional, defaults toFalse) — IfTrue, generates and logs completions from both the model and the reference model to W&B during evaluation. - is_encoder_decoder (
Optional[bool], optional, defaults toNone) — When using themodel_initargument (callable) to instantiate the model instead of themodelargument, you need to specify if the model returned by the callable is an encoder-decoder model. - precompute_ref_log_probs (
bool, optional, defaults toFalse) — Whether to precompute reference model log probabilities for training and evaluation datasets. This is useful when training without the reference model to reduce the total GPU memory needed. - model_init_kwargs (
Optional[dict[str, Any]], optional, defaults toNone) — Keyword arguments to pass toAutoModelForCausalLM.from_pretrainedwhen instantiating the model from a string. - ref_model_init_kwargs (
Optional[dict[str, Any]], optional, defaults toNone) — Keyword arguments to pass toAutoModelForCausalLM.from_pretrainedwhen instantiating the reference model from a string. - dataset_num_proc — (
Optional[int], optional, defaults toNone): Number of processes to use for processing the dataset. - disable_dropout (
bool, optional, defaults toTrue) — Whether to disable dropout in the model.
Configuration class for the KTOTrainer.
Using HfArgumentParser we can turn this class into argparse arguments that can be specified on the command line.