通过文件系统 API 与 Hub 交互
除了 HfApi,huggingface_hub 库还提供了 HfFileSystem,这是一个符合 fsspec 规范的 Python 文件接口,用于与 Hugging Face Hub 交互。HfFileSystem 基于 HfApi 构建,提供了典型的文件系统操作,如 cp、mv、ls、du、glob、get_file 和 put_file。
HfFileSystem 提供了 fsspec 兼容性,这对于需要它的库(例如,直接使用 pandas 读取 Hugging Face 数据集)非常有用。然而,由于这种兼容性层,会引入额外的开销。为了更好的性能和可靠性,建议尽可能使用 HfApi 方法。
使用方法
>>> from huggingface_hub import HfFileSystem
>>> fs = HfFileSystem()
>>> # 列出目录中的所有文件
>>> fs.ls("datasets/my-username/my-dataset-repo/data", detail=False)
['datasets/my-username/my-dataset-repo/data/train.csv', 'datasets/my-username/my-dataset-repo/data/test.csv']
>>> # 列出仓库中的所有 ".csv" 文件
>>> fs.glob("datasets/my-username/my-dataset-repo/**/*.csv")
['datasets/my-username/my-dataset-repo/data/train.csv', 'datasets/my-username/my-dataset-repo/data/test.csv']
>>> # 读取远程文件
>>> with fs.open("datasets/my-username/my-dataset-repo/data/train.csv", "r") as f:
... train_data = f.readlines()
>>> # 远程文件内容读取为字符串
>>> train_data = fs.read_text("datasets/my-username/my-dataset-repo/data/train.csv", revision="dev")
>>> # 写入远程文件
>>> with fs.open("datasets/my-username/my-dataset-repo/data/validation.csv", "w") as f:
... f.write("text,label")
... f.write("Fantastic movie!,good")可以传递可选的 revision 参数,以从特定提交(如分支、标签名或提交哈希)运行操作。
与 Python 内置的 open 不同,fsspec 的 open 默认是二进制模式 "rb"。这意味着您必须明确设置模式为 "r" 以读取文本模式,或 "w" 以写入文本模式。目前不支持追加到文件(模式 "a" 和 "ab")
集成
HfFileSystem 可以与任何集成了 fsspec 的库一起使用,前提是 URL 遵循以下格式:
hf://[<repo_type_prefix>]<repo_id>[@<revision>]/<path/in/repo>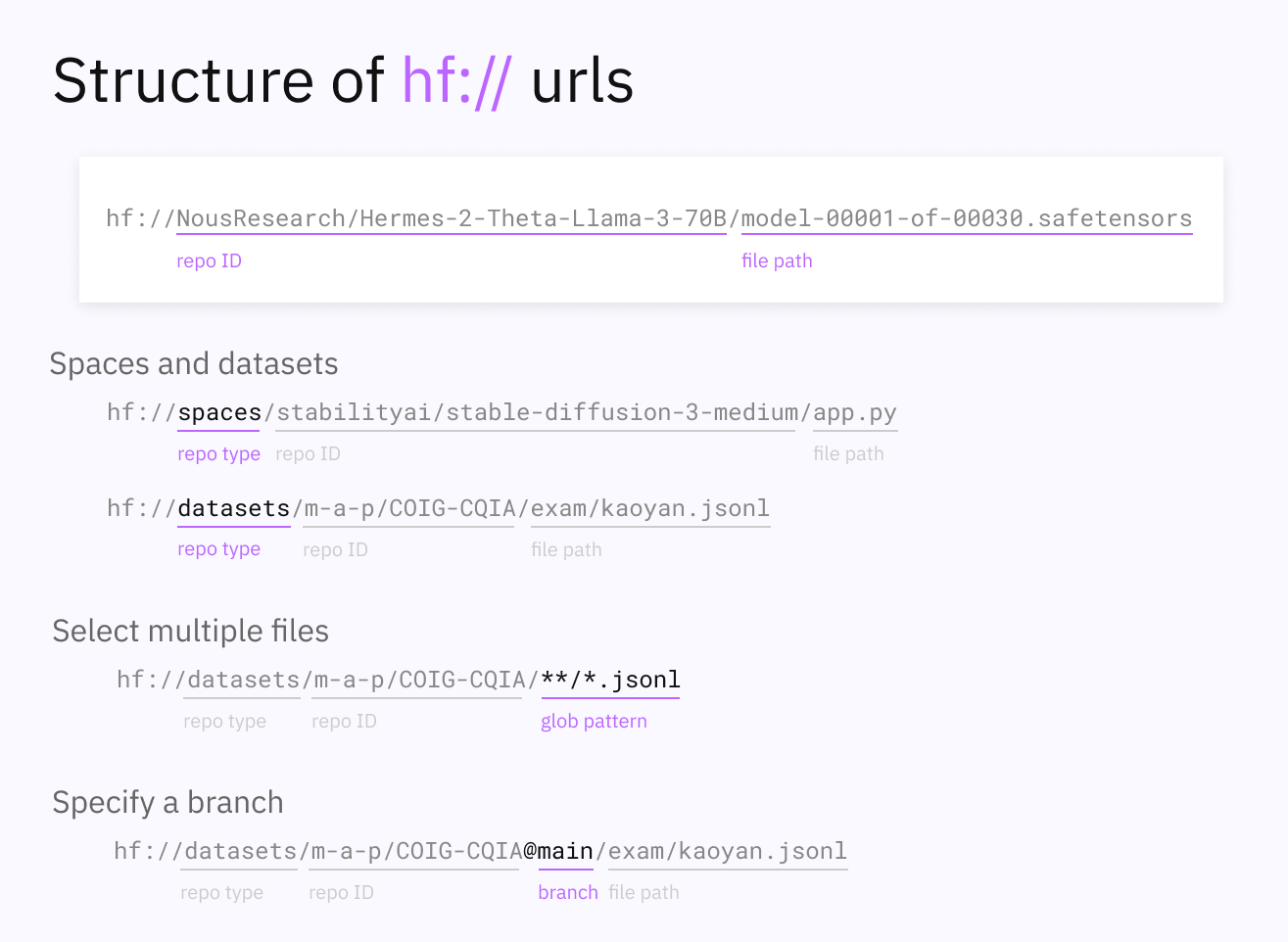
对于数据集,repo_type_prefix 为 datasets/,对于Space,repo_type_prefix为 spaces/,模型不需要在 URL 中使用这样的前缀。
以下是一些 HfFileSystem 简化与 Hub 交互的有趣集成:
从 Hub 仓库读取/写入 Pandas DataFrame :
>>> import pandas as pd >>> # 将远程 CSV 文件读取到 DataFrame >>> df = pd.read_csv("hf://datasets/my-username/my-dataset-repo/train.csv") >>> # 将 DataFrame 写入远程 CSV 文件 >>> df.to_csv("hf://datasets/my-username/my-dataset-repo/test.csv")
同样的工作流程也适用于 Dask 和 Polars DataFrames.
使用 DuckDB 查询(远程)Hub文件:
>>> from huggingface_hub import HfFileSystem >>> import duckdb >>> fs = HfFileSystem() >>> duckdb.register_filesystem(fs) >>> # 查询远程文件并将结果返回为 DataFrame >>> fs_query_file = "hf://datasets/my-username/my-dataset-repo/data_dir/data.parquet" >>> df = duckdb.query(f"SELECT * FROM '{fs_query_file}' LIMIT 10").df()使用 Zarr 将 Hub 作为数组存储:
>>> import numpy as np >>> import zarr >>> embeddings = np.random.randn(50000, 1000).astype("float32") >>> # 将数组写入仓库 >>> with zarr.open_group("hf://my-username/my-model-repo/array-store", mode="w") as root: ... foo = root.create_group("embeddings") ... foobar = foo.zeros('experiment_0', shape=(50000, 1000), chunks=(10000, 1000), dtype='f4') ... foobar[:] = embeddings >>> # 从仓库读取数组 >>> with zarr.open_group("hf://my-username/my-model-repo/array-store", mode="r") as root: ... first_row = root["embeddings/experiment_0"][0]
认证
在许多情况下,您必须登录 Hugging Face 账户才能与 Hub 交互。请参阅文档的认证 部分,了解有关 Hub 上认证方法的更多信息。
也可以通过将您的 token 作为参数传递给 HfFileSystem 以编程方式登录:
>>> from huggingface_hub import HfFileSystem
>>> fs = HfFileSystem(token=token)如果您以这种方式登录,请注意在共享源代码时不要意外泄露令牌!
< > Update on GitHub