
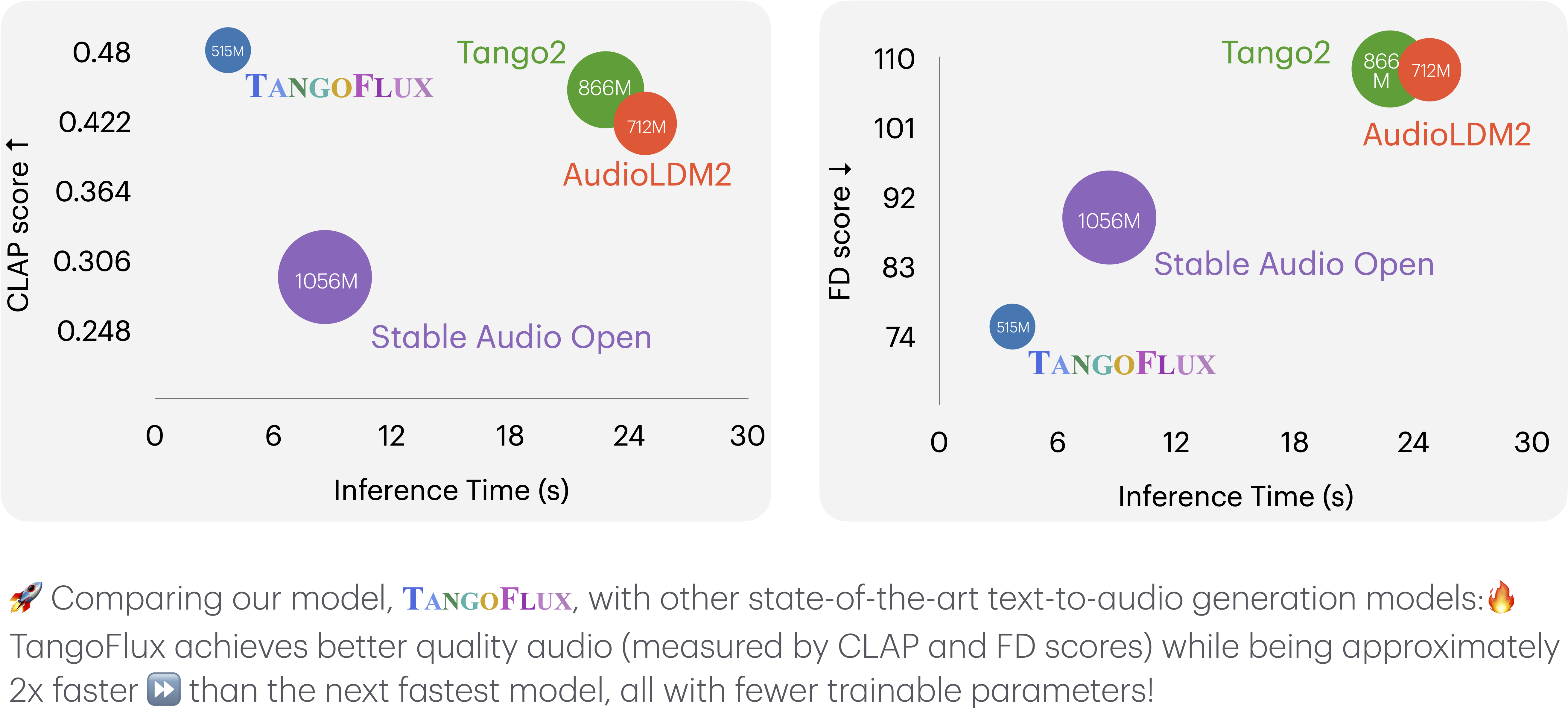
✨
TangoFlux: Super Fast and Faithful Text to Audio Generation with Flow Matching and Clap-Ranked Preference Optimization
✨✨✨
- Powered by Stability AI
Model Overview
TangoFlux consists of FluxTransformer blocks which are Diffusion Transformer (DiT) and Multimodal Diffusion Transformer (MMDiT), conditioned on textual prompt and duration embedding to generate audio at 44.1kHz up to 30 seconds. TangoFlux learns a rectified flow trajectory from audio latent representation encoded by a variational autoencoder (VAE). The TangoFlux training pipeline consists of three stages: pre-training, fine-tuning, and preference optimization. TangoFlux is aligned via CRPO which iteratively generates new synthetic data and constructs preference pairs to perform preference optimization.
Getting Started
Get TangoFlux from our GitHub repo https://github.com/declare-lab/TangoFlux with
pip install git+https://github.com/declare-lab/TangoFlux
The model will be automatically downloaded and saved in a cache. The subsequent runs will load the model directly from the cache.
The generate function uses 25 steps by default to sample from the flow model. We recommend using 50 steps for generating better quality audios. This comes at the cost of increased run-time.
import torchaudio
from tangoflux import TangoFluxInference
from IPython.display import Audio
model = TangoFluxInference(name='declare-lab/TangoFlux')
audio = model.generate('Hammer slowly hitting the wooden table', steps=50, duration=10)
Audio(data=audio, rate=44100)
License
The TangoFlux checkpoints are for non-commercial research use only. They are subject to the Stable Audio Open’s license, WavCap’s license, and the original licenses accompanying each training dataset.
This Stability AI Model is licensed under the Stability AI Community License, Copyright © Stability AI Ltd. All Rights Reserved
Citation
https://arxiv.org/abs/2412.21037
@misc{hung2024tangofluxsuperfastfaithful,
title={TangoFlux: Super Fast and Faithful Text to Audio Generation with Flow Matching and Clap-Ranked Preference Optimization},
author={Chia-Yu Hung and Navonil Majumder and Zhifeng Kong and Ambuj Mehrish and Rafael Valle and Bryan Catanzaro and Soujanya Poria},
year={2024},
eprint={2412.21037},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2412.21037},
}
- Downloads last month
- 321