
html_url
stringlengths 48
51
| title
stringlengths 1
290
| comments
sequencelengths 0
30
| body
stringlengths 0
228k
⌀ | number
int64 2
7.08k
|
|---|---|---|---|---|
https://github.com/huggingface/datasets/issues/1842 | Add AMI Corpus | [
"Available here: ~https://huggingface.co/datasets/ami~ https://huggingface.co/datasets/edinburghcstr/ami",
"@mariosasko actually the \"official\" AMI dataset can be found here: https://huggingface.co/datasets/edinburghcstr/ami -> the old one under `datasets/ami` doesn't work and should be deleted. \r\n\r\nThe new one was tested by fine-tuning a Wav2Vec2 model on it + we uploaded all the processed audio directly into it",
"@patrickvonplaten Thanks for correcting me! I've updated the link."
] | ## Adding a Dataset
- **Name:** *AMI*
- **Description:** *The AMI Meeting Corpus is a multi-modal data set consisting of 100 hours of meeting recordings. For a gentle introduction to the corpus, see the corpus overview. To access the data, follow the directions given there. Around two-thirds of the data has been elicited using a scenario in which the participants play different roles in a design team, taking a design project from kick-off to completion over the course of a day. The rest consists of naturally occurring meetings in a range of domains. Detailed information can be found in the documentation section.*
- **Paper:** *Homepage*: http://groups.inf.ed.ac.uk/ami/corpus/
- **Data:** *http://groups.inf.ed.ac.uk/ami/download/* - Select all cases in 1) and select "Individual Headsets" & "Microphone array" for 2)
- **Motivation:** Important speech dataset
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| 1,842 |
https://github.com/huggingface/datasets/issues/1841 | Add ljspeech | [] | ## Adding a Dataset
- **Name:** *ljspeech*
- **Description:** *This is a public domain speech dataset consisting of 13,100 short audio clips of a single speaker reading passages from 7 non-fiction books. A transcription is provided for each clip. Clips vary in length from 1 to 10 seconds and have a total length of approximately 24 hours.
The texts were published between 1884 and 1964, and are in the public domain. The audio was recorded in 2016-17 by the LibriVox project and is also in the public domain.)*
- **Paper:** *Homepage*: https://keithito.com/LJ-Speech-Dataset/
- **Data:** *https://keithito.com/LJ-Speech-Dataset/*
- **Motivation:** Important speech dataset
- **TFDatasets Implementation**: https://www.tensorflow.org/datasets/catalog/ljspeech
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| 1,841 |
https://github.com/huggingface/datasets/issues/1840 | Add common voice | [
"I have started working on adding this dataset.",
"Hey @BirgerMoell - awesome that you started working on Common Voice. Common Voice is a bit special since, there is no direct download link to download the data. In these cases we usually consider two options:\r\n\r\n1) Find a hacky solution to extract the download link somehow from the XLM tree of the website \r\n2) If this doesn't work we force the user to download the data himself and add a `\"data_dir\"` as an input parameter. E.g. you can take a look at how it is done for [this](https://github.com/huggingface/datasets/blob/66f2a7eece98d2778bd22bb5034cb7c2376032d4/datasets/arxiv_dataset/arxiv_dataset.py#L66) \r\n\r\nAlso the documentation here: https://huggingface.co/docs/datasets/add_dataset.html?highlight=data_dir#downloading-data-files-and-organizing-splits (especially the \"note\") might be helpful.",
"Let me know if you have any other questions",
"I added a Work in Progress pull request (hope that is ok). I've made a card for the dataset and filled out the common_voice.py file with information about the datset (not completely).\r\n\r\nI didn't manage to get the tagging tool working locally on my machine but will look into that later.\r\n\r\nLeft to do.\r\n\r\n- Tag the dataset\r\n- Add missing information and update common_voice.py\r\n\r\nhttps://github.com/huggingface/datasets/pull/1886",
"Awesome! I left a longer comment on the PR :-)",
"I saw that this current datasets package holds common voice version 6.1, how to add the new version 7.0 that is already available?",
"Will me merged next week - we're working on it :-)",
"Common voice still appears to be a 6.1. Is the plan still to upgrade to 7.0?",
"We actually already have the code and everything ready to add Common Voice 7.0 to `datasets` but are still waiting for the common voice authors to give us the green light :-) \r\n\r\nAlso gently pinging @phirework and @milupo here",
"Common Voice 7.0 is available here now: https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0",
"For anyone else stumbling upon this thread, the 8.0 version is also available now: https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0"
] | ## Adding a Dataset
- **Name:** *common voice*
- **Description:** *Mozilla Common Voice Dataset*
- **Paper:** Homepage: https://voice.mozilla.org/en/datasets
- **Data:** https://voice.mozilla.org/en/datasets
- **Motivation:** Important speech dataset
- **TFDatasets Implementation**: https://www.tensorflow.org/datasets/catalog/common_voice
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| 1,840 |
https://github.com/huggingface/datasets/issues/1839 | Add Voxforge | [] | ## Adding a Dataset
- **Name:** *voxforge*
- **Description:** *VoxForge is a language classification dataset. It consists of user submitted audio clips submitted to the website. In this release, data from 6 languages is collected - English, Spanish, French, German, Russian, and Italian. Since the website is constantly updated, and for the sake of reproducibility, this release contains only recordings submitted prior to 2020-01-01. The samples are splitted between train, validation and testing so that samples from each speaker belongs to exactly one split.*
- **Paper:** *Homepage*: http://www.voxforge.org/
- **Data:** *http://www.voxforge.org/home/downloads*
- **Motivation:** Important speech dataset
- **TFDatasets Implementation**: https://www.tensorflow.org/datasets/catalog/voxforge
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| 1,839 |
https://github.com/huggingface/datasets/issues/1838 | Add tedlium | [
"Hi @patrickvonplaten \r\nI can have a look to this dataset later since I am trying to add the OpenSLR dataset https://github.com/huggingface/datasets/pull/2173\r\nHopefully I have enough space since the compressed file is 21GB. The release 3 is even bigger: 54GB :-0",
"Resolved via https://github.com/huggingface/datasets/pull/4309"
] | ## Adding a Dataset
- **Name:** *tedlium*
- **Description:** *The TED-LIUM 1-3 corpus is English-language TED talks, with transcriptions, sampled at 16kHz. It contains about 118 hours of speech.*
- **Paper:** Homepage: http://www.openslr.org/7/, https://lium.univ-lemans.fr/en/ted-lium2/ &, https://www.openslr.org/51/
- **Data:** http://www.openslr.org/7/
- **Motivation:** Important speech dataset
- **TFDatasets Implementation**: https://www.tensorflow.org/datasets/catalog/tedlium
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| 1,838 |
https://github.com/huggingface/datasets/issues/1837 | Add VCTK | [
"@patrickvonplaten I'd like to take this, if nobody has already done it. I have added datasets before through the datasets sprint, but I feel rusty on the details, so I'll look at the guide as well as similar audio PRs (#1878 in particular comes to mind). If there is any detail I should be aware of please, let me know! Otherwise, I'll try to write up a PR in the coming days.",
"That sounds great @jaketae - let me know if you need any help i.e. feel free to ping me on a first PR :-)"
] | ## Adding a Dataset
- **Name:** *VCTK*
- **Description:** *This CSTR VCTK Corpus includes speech data uttered by 110 English speakers with various accents. Each speaker reads out about 400 sentences, which were selected from a newspaper, the rainbow passage and an elicitation paragraph used for the speech accent archive.*
- **Paper:** Homepage: https://datashare.ed.ac.uk/handle/10283/3443
- **Data:** https://datashare.ed.ac.uk/handle/10283/3443
- **Motivation:** Important speech dataset
- **TFDatasets Implementation**: https://www.tensorflow.org/datasets/catalog/vctk
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| 1,837 |
https://github.com/huggingface/datasets/issues/1836 | test.json has been removed from the limit dataset repo (breaks dataset) | [
"Thanks for the heads up ! I'm opening a PR to fix that"
] | https://github.com/huggingface/datasets/blob/16042b233dbff2a7585110134e969204c69322c3/datasets/limit/limit.py#L51
The URL is not valid anymore since test.json has been removed in master for some reason. Directly referencing the last commit works:
`https://raw.githubusercontent.com/ilmgut/limit_dataset/0707d3989cd8848f0f11527c77dcf168fefd2b23/data` | 1,836 |
https://github.com/huggingface/datasets/issues/1835 | Add CHiME4 dataset | [
"@patrickvonplaten not sure whether it is still needed, but willing to tackle this issue",
"Hey @patrickvonplaten, I have managed to download the zip on [here]( http://spandh.dcs.shef.ac.uk/chime_challenge/CHiME4/download.html) and successfully uploaded all the files on a hugging face dataset: \r\n\r\nhttps://huggingface.co/datasets/ksbai123/Chime4\r\n\r\nHowever I am getting this error when trying to use the dataset viewer:\r\n\r\n\r\n\r\nCan you take a look and let me know if I have missed any files please",
"@patrickvonplaten ?",
"Hi @KossaiSbai,\r\n\r\nThanks for your contribution.\r\n\r\nAs the issue is not strictly related to the `datasets` library, but to the specific implementation of the CHiME4 dataset, I have opened an issue in the Discussion tab of the dataset: https://huggingface.co/datasets/ksbai123/Chime4/discussions/2\r\nLet's continue the discussion there!"
] | ## Adding a Dataset
- **Name:** Chime4
- **Description:** Chime4 is a dataset for automatic speech recognition. It is especially useful for evaluating models in a noisy environment and for multi-channel ASR
- **Paper:** Dataset comes from a channel: http://spandh.dcs.shef.ac.uk/chime_challenge/CHiME4/ . Results paper:
- **Data:** http://spandh.dcs.shef.ac.uk/chime_challenge/CHiME4/download.html
- **Motivation:** So far there are very little datasets for speech in `datasets`. Only `lbirispeech_asr` so far.
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| 1,835 |
https://github.com/huggingface/datasets/issues/1832 | Looks like nokogumbo is up-to-date now, so this is no longer needed. | [] | Looks like nokogumbo is up-to-date now, so this is no longer needed.
__Originally posted by @dependabot in https://github.com/discourse/discourse/pull/11373#issuecomment-738993432__ | 1,832 |
https://github.com/huggingface/datasets/issues/1831 | Some question about raw dataset download info in the project . | [
"Hi ! The `dl_manager` is a `DownloadManager` object and is responsible for downloading the raw data files.\r\nIt is used by dataset builders in their `_split_generators` method to download the raw data files that are necessary to build the datasets splits.\r\n\r\nThe `Conll2003` class is a dataset builder, and so you can download all the raw data files by calling `_split_generators` with a download manager:\r\n```python\r\nfrom datasets import DownloadManager\r\nfrom datasets.load import import_main_class\r\n\r\nconll2003_builder = import_main_class(...)\r\n\r\ndl_manager = DownloadManager()\r\nsplis_generators = conll2003_builder._split_generators(dl_manager)\r\n```\r\n\r\nThen you can see what files have been downloaded with\r\n```python\r\ndl_manager.get_recorded_sizes_checksums()\r\n```\r\nIt returns a dictionary with the format {url: {num_bytes: int, checksum: str}}\r\n\r\nThen you can get the actual location of the downloaded files with\r\n```python\r\nfrom datasets import cached_path\r\n\r\nlocal_path_to_downloaded_file = cached_path(url)\r\n```\r\n\r\n------------------\r\n\r\nNote that you can also get the urls from the Dataset object:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nconll2003 = load_dataset(\"conll2003\")\r\nprint(conll2003[\"train\"].download_checksums)\r\n```\r\nIt returns the same dictionary with the format {url: {num_bytes: int, checksum: str}}",
"I am afraid that there is not a very straightforward way to get that location.\r\n\r\nAnother option, from _split_generators would be to use:\r\n- `dl_manager._download_config.cache_dir` to get the directory where all the raw downloaded files are:\r\n ```python\r\n download_dir = dl_manager._download_config.cache_dir\r\n ```\r\n- the function `datasets.utils.file_utils.hash_url_to_filename` to get the filenames of the raw downloaded files:\r\n ```python\r\n filenames = [hash_url_to_filename(url) for url in urls_to_download.values()]\r\n ```\r\nTherefore the complete path to the raw downloaded files would be the join of both:\r\n```python\r\ndownloaded_paths = [os.path.join(download_dir, filename) for filename in filenames]\r\n```\r\n\r\nMaybe it would be interesting to make these paths accessible more easily. I could work on this. What do you think, @lhoestq ?",
"Sure it would be nice to have an easier access to these paths !\r\nThe dataset builder could have a method to return those, what do you think ?\r\nFeel free to work on this @albertvillanova , it would be a nice addition :) \r\n\r\nYour suggestion does work as well @albertvillanova if you complete it by specifying `etag=` to `hash_url_to_filename`.\r\n\r\nThe ETag is obtained by a HEAD request and is used to know if the file on the remote host has changed. Therefore if a file is updated on the remote host, then the hash returned by `hash_url_to_filename` is different.",
"Once #1846 will be merged, the paths to the raw downloaded files will be accessible as:\r\n```python\r\nbuilder_instance.dl_manager.downloaded_paths\r\n``` "
] | Hi , i review the code in
https://github.com/huggingface/datasets/blob/master/datasets/conll2003/conll2003.py
in the _split_generators function is the truly logic of download raw datasets with dl_manager
and use Conll2003 cls by use import_main_class in load_dataset function
My question is that , with this logic it seems that i can not have the raw dataset download location
in variable in downloaded_files in _split_generators.
If someone also want use huggingface datasets as raw dataset downloader,
how can he retrieve the raw dataset download path from attributes in
datasets.dataset_dict.DatasetDict ? | 1,831 |
https://github.com/huggingface/datasets/issues/1830 | using map on loaded Tokenizer 10x - 100x slower than default Tokenizer? | [
"Hi @wumpusman \r\n`datasets` has a caching mechanism that allows to cache the results of `.map` so that when you want to re-run it later it doesn't recompute it again.\r\nSo when you do `.map`, what actually happens is:\r\n1. compute the hash used to identify your `map` for the cache\r\n2. apply your function on every batch\r\n\r\nThis can explain the time difference between your different experiments.\r\n\r\nThe hash computation time depends of how complex your function is. For a tokenizer, the hash computation scans the lists of the words in the tokenizer to identify this tokenizer. Usually it takes 2-3 seconds.\r\n\r\nAlso note that you can disable caching though using\r\n```python\r\nimport datasets\r\n\r\ndatasets.set_caching_enabled(False)\r\n```",
"Hi @lhoestq ,\r\n\r\nThanks for the reply. It's entirely possible that is the issue. Since it's a side project I won't be looking at it till later this week, but, I'll verify it by disabling caching and hopefully I'll see the same runtime. \r\n\r\nAppreciate the reference,\r\n\r\nMichael",
"I believe this is an actual issue, tokenizing a ~4GB txt file went from an hour and a half to ~10 minutes when I switched from my pre-trained tokenizer(on the same dataset) to the default gpt2 tokenizer.\r\nBoth were loaded using:\r\n```\r\nAutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)\r\n```\r\nI trained the tokenizer using ByteLevelBPETokenizer from the Tokenizers library and save it to a tokenizer.json file.\r\n\r\nI have tested the caching ideas above, changing the number of process, the TOKENIZERS_PARALLELISM env variable, keep_in_memory=True and batching with different sizes.\r\n\r\nApologies I can't really upload much code, but wanted to back up the finding and hopefully a fix/the problem can be found.\r\nI will comment back if I find a fix as well.",
"Hi @johncookds do you think this can come from one tokenizer being faster than the other one ? Can you try to compare their speed without using `datasets` just to make sure ?",
"Hi yes, I'm closing the loop here with some timings below. The issue seems to be at least somewhat/mainly with the tokenizer's themselves. Moreover legacy saves of the trainer tokenizer perform faster but differently than the new tokenizer.json saves(note nothing about the training process/adding of special tokens changed between the top two trained tokenizer tests, only the way it was saved). This is only a 3x slowdown vs like a 10x but I think the slowdown is most likely due to this.\r\n\r\n```\r\ntrained tokenizer - tokenizer.json save (same results for AutoTokenizer legacy_format=False):\r\nTokenizer time(seconds): 0.32767510414123535\r\nTokenized avg. length: 323.01\r\n\r\ntrained tokenizer - AutoTokenizer legacy_format=True:\r\nTokenizer time(seconds): 0.09258866310119629\r\nTokenized avg. length: 301.01\r\n\r\nGPT2 Tokenizer from huggingface\r\nTokenizer time(seconds): 0.1010282039642334\r\nTokenized avg. length: 461.21\r\n```",
"@lhoestq ,\r\n\r\nHi, which version of datasets has datasets.set_caching_enabled(False)? I get \r\nmodule 'datasets' has no attribute 'set_caching_enabled'. To hopefully get around this, I reran my code on a new set of data, and did so only once.\r\n\r\n@johncookds , thanks for chiming in, it looks this might be an issue of Tokenizer.\r\n\r\n**Tokenizer**: The runtime of GPT2TokenizerFast.from_pretrained(\"gpt2\") on 1000 chars is: **143 ms**\r\n**SlowTokenizer**: The runtime of a locally saved and loaded Tokenizer using the same vocab on 1000 chars is: **4.43 s**\r\n\r\nThat being said, I compared performance on the map function:\r\n\r\nRunning Tokenizer versus using it in the map function for 1000 chars goes from **141 ms** to **356 ms** \r\nRunning SlowTokenizer versus using it in the map function for 1000 chars with a single element goes from **4.43 s** to **9.76 s**\r\n\r\nI'm trying to figure out why the overhead of map would increase the time by double (figured it would be a fixed increase in time)? Though maybe this is expected behavior.\r\n\r\n@lhoestq, do you by chance know how I can redirect this issue to Tokenizer?\r\n\r\nRegards,\r\n\r\nMichael",
"Thanks for the experiments @johncookds and @wumpusman ! \r\n\r\n> Hi, which version of datasets has datasets.set_caching_enabled(False)?\r\n\r\nCurrently you have to install `datasets` from source to have this feature, but this will be available in the next release in a few days.\r\n\r\n> I'm trying to figure out why the overhead of map would increase the time by double (figured it would be a fixed increase in time)? Though maybe this is expected behavior.\r\n\r\nCould you also try with double the number of characters ? This should let us have an idea of the fixed cost (hashing) and the dynamic cost (actual tokenization, grows with the size of the input)\r\n\r\n> @lhoestq, do you by chance know how I can redirect this issue to Tokenizer?\r\n\r\nFeel free to post an issue on the `transformers` repo. Also I'm sure there should be related issues so you can also look for someone with the same concerns on the `transformers` repo.",
"@lhoestq,\r\n\r\nI just checked that previous run time was actually 3000 chars. I increased it to 6k chars, again, roughly double.\r\n\r\nSlowTokenizer **7.4 s** to **15.7 s**\r\nTokenizer: **276 ms** to **616 ms**\r\n\r\nI'll post this issue on Tokenizer, seems it hasn't quite been raised (albeit I noticed a similar issue that might relate).\r\n\r\nRegards,\r\n\r\nMichael",
"Hi, \r\nI'm following up here as I found my exact issue. It was with saving and re-loading the tokenizer. When I trained then processed the data without saving and reloading it, it was 10x-100x faster than when I saved and re-loaded it.\r\nBoth resulted in the exact same tokenized datasets as well. \r\nThere is additionally a bug where the older legacy tokenizer save does not preserve a learned tokenizing behavior if trained from scratch.\r\nUnderstand its not exactly Datasets related but hope it can help someone if they have the same issue.\r\nThanks!"
] | This could total relate to me misunderstanding particular call functions, but I added words to a GPT2Tokenizer, and saved it to disk (note I'm only showing snippets but I can share more) and the map function ran much slower:
````
def save_tokenizer(original_tokenizer,text,path="simpledata/tokenizer"):
words_unique = set(text.split(" "))
for i in words_unique:
original_tokenizer.add_tokens(i)
original_tokenizer.save_pretrained(path)
tokenizer2 = GPT2Tokenizer.from_pretrained(os.path.join(experiment_path,experiment_name,"tokenizer_squad"))
train_set_baby=Dataset.from_dict({"text":[train_set["text"][0][0:50]]})
````
I then applied the dataset map function on a fairly small set of text:
```
%%time
train_set_baby = train_set_baby.map(lambda d:tokenizer2(d["text"]),batched=True)
```
The run time for train_set_baby.map was 6 seconds, and the batch itself was 2.6 seconds
**100% 1/1 [00:02<00:00, 2.60s/ba] CPU times: user 5.96 s, sys: 36 ms, total: 5.99 s Wall time: 5.99 s**
In comparison using (even after adding additional tokens):
`
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")`
```
%%time
train_set_baby = train_set_baby.map(lambda d:tokenizer2(d["text"]),batched=True)
```
The time is
**100% 1/1 [00:00<00:00, 34.09ba/s] CPU times: user 68.1 ms, sys: 16 µs, total: 68.1 ms Wall time: 62.9 ms**
It seems this might relate to the tokenizer save or load function, however, the issue appears to come up when I apply the loaded tokenizer to the map function.
I should also add that playing around with the amount of words I add to the tokenizer before I save it to disk and load it into memory appears to impact the time it takes to run the map function.
| 1,830 |
https://github.com/huggingface/datasets/issues/1827 | Regarding On-the-fly Data Loading | [
"Possible duplicate\r\n\r\n#1776 https://github.com/huggingface/datasets/issues/\r\n\r\nreally looking PR for this feature",
"Hi @acul3 \r\n\r\nIssue #1776 talks about doing on-the-fly data pre-processing, which I think is solved in the next release as mentioned in the issue #1825. I also look forward to using this feature, though :)\r\n\r\nI wanted to ask about on-the-fly data loading from the cache (before pre-processing).",
"Hi ! Currently when you load a dataset via `load_dataset` for example, then the dataset is memory-mapped from an Arrow file on disk. Therefore there's almost no RAM usage even if your dataset contains TB of data.\r\nUsually at training time only one batch of data at a time is loaded in memory.\r\n\r\nDoes that answer your question or were you thinking about something else ?",
"Hi @lhoestq,\r\n\r\nI apologize for the late response. This answers my question. Thanks a lot."
] | Hi,
I was wondering if it is possible to load images/texts as a batch during the training process, without loading the entire dataset on the RAM at any given point.
Thanks,
Gunjan | 1,827 |
https://github.com/huggingface/datasets/issues/1825 | Datasets library not suitable for huge text datasets. | [
"Hi ! Looks related to #861 \r\n\r\nYou are right: tokenizing a dataset using map takes a lot of space since it can store `input_ids` but also `token_type_ids`, `attention_mask` and `special_tokens_mask`. Moreover if your tokenization function returns python integers then by default they'll be stored as int64 which can take a lot of space. Padding can also increase the size of the tokenized dataset.\r\n\r\nTo make things more convenient, we recently added a \"lazy map\" feature that allows to tokenize each batch at training time as you mentioned. For example you'll be able to do\r\n```python\r\nfrom transformers import BertTokenizer\r\n\r\ntokenizer = BertTokenizer.from_pretrained(\"bert-base-uncased\")\r\n\r\ndef encode(batch):\r\n return tokenizer(batch[\"text\"], padding=\"longest\", truncation=True, max_length=512, return_tensors=\"pt\")\r\n\r\ndataset.set_transform(encode)\r\nprint(dataset.format)\r\n# {'type': 'custom', 'format_kwargs': {'transform': <function __main__.encode(batch)>}, 'columns': ['idx', 'label', 'sentence1', 'sentence2'], 'output_all_columns': False}\r\nprint(dataset[:2])\r\n# {'input_ids': tensor([[ 101, 2572, 3217, ... 102]]), 'token_type_ids': tensor([[0, 0, 0, ... 0]]), 'attention_mask': tensor([[1, 1, 1, ... 1]])}\r\n\r\n```\r\nIn this example the `encode` transform is applied on-the-fly on the \"text\" column.\r\n\r\nThis feature will be available in the next release 2.0 which will happen in a few days.\r\nYou can already play with it by installing `datasets` from source if you want :)\r\n\r\nHope that helps !",
"How recently was `set_transform` added? I am actually trying to implement it and getting an error:\r\n\r\n`AttributeError: 'Dataset' object has no attribute 'set_transform'\r\n`\r\n\r\nI'm on v.1.2.1.\r\n\r\nEDIT: Oh, wait I see now it's in the v.2.0. Whoops! This should be really useful.",
"Yes indeed it was added a few days ago. The code is available on master\r\nWe'll do a release next week :)\r\n\r\nFeel free to install `datasets` from source to try it out though, I would love to have some feedbacks",
"For information: it's now available in `datasets` 1.3.0.\r\nThe 2.0 is reserved for even cooler features ;)",
"Hi @alexvaca0 , we have optimized Datasets' disk usage in the latest release v1.5.\r\n\r\nFeel free to update your Datasets version\r\n```shell\r\npip install -U datasets\r\n```\r\nand see if it better suits your needs."
] | Hi,
I'm trying to use datasets library to load a 187GB dataset of pure text, with the intention of building a Language Model. The problem is that from the 187GB it goes to some TB when processed by Datasets. First of all, I think the pre-tokenizing step (with tokenizer.map()) is not really thought for datasets this big, but for fine-tuning datasets, as this process alone takes so much time, usually in expensive machines (due to the need of tpus - gpus) which is not being used for training. It would possibly be more efficient in such cases to tokenize each batch at training time (receive batch - tokenize batch - train with batch), so that the whole time the machine is up it's being used for training.
Moreover, the pyarrow objects created from a 187 GB datasets are huge, I mean, we always receive OOM, or No Space left on device errors when only 10-12% of the dataset has been processed, and only that part occupies 2.1TB in disk, which is so many times the disk usage of the pure text (and this doesn't make sense, as tokenized texts should be lighter than pure texts).
Any suggestions?? | 1,825 |
https://github.com/huggingface/datasets/issues/1821 | Provide better exception message when one of many files results in an exception | [
"Hi!\r\n\r\nThank you for reporting this issue. I agree that the information about the exception should be more clear and explicit.\r\n\r\nI could take on this issue.\r\n\r\nOn the meantime, as you can see from the exception stack trace, HF Datasets uses pandas to read the CSV files. You can pass arguments to `pandas.read_csv` by passing additional keyword arguments to `load_dataset`. For example, you may find useful this argument:\r\n- `error_bad_lines` : bool, default True\r\n Lines with too many fields (e.g. a csv line with too many commas) will by default cause an exception to be raised, and no DataFrame will be returned. If False, then these “bad lines” will be dropped from the DataFrame that is returned.\r\n\r\nYou could try:\r\n```python\r\ndatasets = load_dataset(\"csv\", data_files=dict(train=train_files, validation=validation_files), error_bad_lines=False)\r\n```\r\n"
] | I find when I process many files, i.e.
```
train_files = glob.glob('rain*.csv')
validation_files = glob.glob(validation*.csv')
datasets = load_dataset("csv", data_files=dict(train=train_files, validation=validation_files))
```
I sometimes encounter an error due to one of the files being misformed (i.e. no data, or a comma in a field that isn't quoted, etc).
For example, this is the tail of an exception which I suspect is due to a stray comma.
> File "pandas/_libs/parsers.pyx", line 756, in pandas._libs.parsers.TextReader.read
> File "pandas/_libs/parsers.pyx", line 783, in pandas._libs.parsers.TextReader._read_low_memory
> File "pandas/_libs/parsers.pyx", line 827, in pandas._libs.parsers.TextReader._read_rows
> File "pandas/_libs/parsers.pyx", line 814, in pandas._libs.parsers.TextReader._tokenize_rows
> File "pandas/_libs/parsers.pyx", line 1951, in pandas._libs.parsers.raise_parser_error
> pandas.errors.ParserError: Error tokenizing data. C error: Expected 2 fields in line 559, saw 3
It would be nice if the exception trace contained the name of the file being processed (I have 250 separate files!) | 1,821 |
https://github.com/huggingface/datasets/issues/1818 | Loading local dataset raise requests.exceptions.ConnectTimeout | [
"Hi ! Thanks for reporting. This was indeed a bug introduced when we moved the `json` dataset loader inside the `datasets` package (before that, the `json` loader was fetched online, as all the other dataset scripts).\r\n\r\nThis should be fixed on master now. Feel free to install `datasets` from source to try it out.\r\nThe fix will be available in the next release of `datasets` in a few days"
] | Load local dataset:
```
dataset = load_dataset('json', data_files=["../../data/json.json"])
train = dataset["train"]
print(train.features)
train1 = train.map(lambda x: {"labels": 1})
print(train1[:2])
```
but it raised requests.exceptions.ConnectTimeout:
```
/Users/littlely/myvirtual/tf2/bin/python3.7 /Users/littlely/projects/python_projects/pytorch_learning/nlp/dataset/transformers_datasets.py
Traceback (most recent call last):
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/connection.py", line 160, in _new_conn
(self._dns_host, self.port), self.timeout, **extra_kw
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/util/connection.py", line 84, in create_connection
raise err
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/util/connection.py", line 74, in create_connection
sock.connect(sa)
socket.timeout: timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/connectionpool.py", line 677, in urlopen
chunked=chunked,
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/connectionpool.py", line 381, in _make_request
self._validate_conn(conn)
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/connectionpool.py", line 978, in _validate_conn
conn.connect()
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/connection.py", line 309, in connect
conn = self._new_conn()
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/connection.py", line 167, in _new_conn
% (self.host, self.timeout),
urllib3.exceptions.ConnectTimeoutError: (<urllib3.connection.HTTPSConnection object at 0x1181e9940>, 'Connection to s3.amazonaws.com timed out. (connect timeout=10)')
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/requests/adapters.py", line 449, in send
timeout=timeout
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/connectionpool.py", line 727, in urlopen
method, url, error=e, _pool=self, _stacktrace=sys.exc_info()[2]
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/urllib3/util/retry.py", line 439, in increment
raise MaxRetryError(_pool, url, error or ResponseError(cause))
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /datasets.huggingface.co/datasets/datasets/json/json.py (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x1181e9940>, 'Connection to s3.amazonaws.com timed out. (connect timeout=10)'))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/littlely/projects/python_projects/pytorch_learning/nlp/dataset/transformers_datasets.py", line 12, in <module>
dataset = load_dataset('json', data_files=["../../data/json.json"])
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/datasets/load.py", line 591, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/datasets/load.py", line 263, in prepare_module
head_hf_s3(path, filename=name, dataset=dataset, max_retries=download_config.max_retries)
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 232, in head_hf_s3
max_retries=max_retries,
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 523, in http_head
max_retries=max_retries,
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 458, in _request_with_retry
raise err
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 454, in _request_with_retry
response = requests.request(verb.upper(), url, **params)
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/requests/api.py", line 61, in request
return session.request(method=method, url=url, **kwargs)
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/requests/sessions.py", line 530, in request
resp = self.send(prep, **send_kwargs)
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/requests/sessions.py", line 643, in send
r = adapter.send(request, **kwargs)
File "/Users/littlely/myvirtual/tf2/lib/python3.7/site-packages/requests/adapters.py", line 504, in send
raise ConnectTimeout(e, request=request)
requests.exceptions.ConnectTimeout: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /datasets.huggingface.co/datasets/datasets/json/json.py (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x1181e9940>, 'Connection to s3.amazonaws.com timed out. (connect timeout=10)'))
Process finished with exit code 1
```
Why it want to connect a remote url when I load local datasets, and how can I fix it? | 1,818 |
https://github.com/huggingface/datasets/issues/1817 | pyarrow.lib.ArrowInvalid: Column 1 named input_ids expected length 599 but got length 1500 | [
"Hi !\r\nThe error you have is due to the `input_ids` column not having the same number of examples as the other columns.\r\nIndeed you're concatenating the `input_ids` at this line:\r\n\r\nhttps://github.com/LuCeHe/GenericTools/blob/431835d8e13ec24dceb5ee4dc4ae58f0e873b091/KerasTools/lm_preprocessing.py#L134\r\n\r\nHowever the other columns are kept unchanged, and therefore you end up with an `input_ids` column with 599 elements while the others columns like `attention_mask` have 1500.\r\n\r\nTo fix that you can instead concatenate them all using\r\n```python\r\nconcatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}\r\n```\r\n\r\nAlso you may need to drop the \"text\" column before applying `group_texts` since strings can't be concatenated with lists. You can drop it at the tokenization step:\r\n```python\r\ndset = dset.map(\r\n tokenize_function,\r\n batched=True,\r\n remove_columns=[\"text\"]\r\n)\r\n```",
"You saved my life."
] | I am trying to preprocess any dataset in this package with GPT-2 tokenizer, so I need to structure the datasets as long sequences of text without padding. I've been following a couple of your tutorials and here you can find the script that is failing right at the end
https://github.com/LuCeHe/GenericTools/blob/master/KerasTools/lm_preprocessing.py
In the last iteration of the last dset.map, it gives the error that I copied in the title. Another issue that I have, if I leave the batch_size set as 1000 in the last .map, I'm afraid it's going to lose most text, so I'm considering setting both writer_batch_size and batch_size to 300 K, but I'm not sure it's the best way to go.
Can you help me?
Thanks! | 1,817 |
https://github.com/huggingface/datasets/issues/1811 | Unable to add Multi-label Datasets | [
"Thanks for adding this dataset! As far as I know `supervised_keys` is mostly a holdover from TFDS, but isn't really used, so feel free to drop it (@lhoestq or @thomwolf correct me if I'm wrong). It definitely shouldn't be blocking :) ",
"I can confirm that it comes from TFDS and is not used at the moment.",
"Thanks @yjernite @lhoestq \r\n\r\nThe template for new dataset makes it slightly confusing. I suppose the comment suggesting its update can be removed.",
"Closing this issue since it was answered."
] | I am trying to add [CIFAR-100](https://www.cs.toronto.edu/~kriz/cifar.html) dataset. The dataset contains two labels per image - `fine label` and `coarse label`. Using just one label in supervised keys as
`supervised_keys=("img", "fine_label")` raises no issue. But trying `supervised_keys=("img", "fine_label","coarse_label")` leads to this error :
```python
Traceback (most recent call last):
File "test_script.py", line 2, in <module>
d = load_dataset('./datasets/cifar100')
File "~/datasets/src/datasets/load.py", line 668, in load_dataset
**config_kwargs,
File "~/datasets/src/datasets/builder.py", line 896, in __init__
super(GeneratorBasedBuilder, self).__init__(*args, **kwargs)
File "~/datasets/src/datasets/builder.py", line 247, in __init__
info.update(self._info())
File "~/.cache/huggingface/modules/datasets_modules/datasets/cifar100/61d2489b2d4a4abc34201432541b7380984ec714e290817d9a1ee318e4b74e0f/cifar100.py", line 79, in _info
citation=_CITATION,
File "<string>", line 19, in __init__
File "~/datasets/src/datasets/info.py", line 136, in __post_init__
self.supervised_keys = SupervisedKeysData(*self.supervised_keys)
TypeError: __init__() takes from 1 to 3 positional arguments but 4 were given
```
Is there a way I can fix this?
Also, what does adding `supervised_keys` do? Is it necessary? How would I specify `supervised_keys` for a multi-input, multi-label dataset?
Thanks,
Gunjan | 1,811 |
https://github.com/huggingface/datasets/issues/1810 | Add Hateful Memes Dataset | [
"I am not sure, but would `datasets.Sequence(datasets.Sequence(datasets.Sequence(datasets.Value(\"int\")))` work?",
"Also, I found the information for loading only subsets of the data [here](https://github.com/huggingface/datasets/blob/master/docs/source/splits.rst).",
"Hi @lhoestq,\r\n\r\nRequest you to check this once.\r\n\r\nThanks,\r\nGunjan",
"Hi @gchhablani since Array2D doesn't support images of different sizes, I would suggest to store in the dataset the paths to the image file instead of the image data. This has the advantage of not decompressing the data (images are often compressed using jpeg, png etc.). Users can still apply `.map` to load the images if they want to. Though it would en up being Sequences features.\r\n\r\nIn the future we'll add support for ragged tensors for this case and update the relevant dataset with this feature."
] | ## Add Hateful Memes Dataset
- **Name:** Hateful Memes
- **Description:** [https://ai.facebook.com/blog/hateful-memes-challenge-and-data-set]( https://ai.facebook.com/blog/hateful-memes-challenge-and-data-set)
- **Paper:** [https://arxiv.org/pdf/2005.04790.pdf](https://arxiv.org/pdf/2005.04790.pdf)
- **Data:** [This link](https://drivendata-competition-fb-hateful-memes-data.s3.amazonaws.com/XjiOc5ycDBRRNwbhRlgH.zip?AWSAccessKeyId=AKIARVBOBDCY4MWEDJKS&Signature=DaUuGgZWUgDHzEPPbyJ2PhSJ56Q%3D&Expires=1612816874)
- **Motivation:** Including multi-modal datasets to 🤗 datasets.
I will be adding this dataset. It requires the user to sign an agreement on DrivenData. So, it will be used with a manual download.
The issue with this dataset is that the images are of different sizes. The image datasets added so far (CIFAR-10 and MNIST) have a uniform shape throughout.
So something like
```python
datasets.Array2D(shape=(28, 28), dtype="uint8")
```
won't work for the images. How would I add image features then? I checked `datasets/features.py` but couldn't figure out the appropriate class for this. I'm assuming I would want to avoid re-sizing at all since we want the user to be able to access the original images.
Also, in case I want to load only a subset of the data, since the actual data is around 8.8GB, how would that be possible?
Thanks,
Gunjan | 1,810 |
https://github.com/huggingface/datasets/issues/1808 | writing Datasets in a human readable format | [
"AFAIK, there is currently no built-in method on the `Dataset` object to do this.\r\nHowever, a workaround is to directly use the Arrow table backing the dataset, **but it implies loading the whole dataset in memory** (correct me if I'm mistaken @lhoestq).\r\n\r\nYou can convert the Arrow table to a pandas dataframe to save the data as csv as follows:\r\n```python\r\narrow_table = dataset.data\r\ndataframe = arrow_table.to_pandas()\r\ndataframe.to_csv(\"/path/to/file.csv\")\r\n```\r\n\r\nSimilarly, you can convert the dataset to a Python dict and save it as JSON:\r\n```python\r\nimport json\r\narrow_table = dataset.data\r\npy_dict = arrow_table.to_pydict()\r\nwith open(\"/path/to/file.json\", \"w+\") as f:\r\n json.dump(py_dict, f)\r\n```",
"Indeed this works as long as you have enough memory.\r\nIt would be amazing to have export options like csv, json etc. !\r\n\r\nIt should be doable to implement something that iterates through the dataset batch by batch to write to csv for example.\r\nThere is already an `export` method but currently the only export type that is supported is `tfrecords`.",
"Hi! `datasets` now supports `Dataset.to_csv` and `Dataset.to_json` for saving data in a human readable format."
] | Hi
I see there is a save_to_disk function to save data, but this is not human readable format, is there a way I could save a Dataset object in a human readable format to a file like json? thanks @lhoestq | 1,808 |
https://github.com/huggingface/datasets/issues/1805 | can't pickle SwigPyObject objects when calling dataset.get_nearest_examples from FAISS index | [
"Hi ! Indeed we used to require mapping functions to be picklable with `pickle` or `dill` in order to cache the resulting datasets. And FAISS indexes are not picklable unfortunately.\r\n\r\nBut since #1703 this is no longer required (the caching will simply be disabled). This change will be available in the next release of `datasets`, or you can also install `datasets` from source.",
"I totally forgot to answer this issue, I'm so sorry. \r\n\r\nI was able to get it working by installing `datasets` from source. Huge thanks!"
] | So, I have the following instances in my dataset
```
{'question': 'An astronomer observes that a planet rotates faster after a meteorite impact. Which is the most likely effect of
this increase in rotation?',
'answer': 'C',
'example_id': 'ARCCH_Mercury_7175875',
'options':[{'option_context': 'One effect of increased amperage in the planetary world (..)', 'option_id': 'A', 'option_text': 'Planetary density will decrease.'},
(...)]}
```
The `options` value is always an list with 4 options, each one is a dict with `option_context`; `option_id` and `option_text`.
I would like to overwrite the `option_context` of each instance of my dataset for a dpr result that I am developing. Then, I trained a model already and save it in a FAISS index
```
dpr_dataset = load_dataset(
"text",
data_files=ARC_CORPUS_TEXT,
cache_dir=CACHE_DIR,
split="train[:100%]",
)
dpr_dataset.load_faiss_index("embeddings", f"{ARC_CORPUS_FAISS}")
torch.set_grad_enabled(False)
```
Then, as a processor of my dataset, I created a map function that calls the `dpr_dataset` for each _option_
```
def generate_context(example):
question_text = example['question']
for option in example['options']:
question_with_option = question_text + " " + option['option_text']
tokenize_text = question_tokenizer(question_with_option, return_tensors="pt").to(device)
question_embed = (
question_encoder(**tokenize_text)
)[0][0].cpu().numpy()
_, retrieved_examples = dpr_dataset.get_nearest_examples(
"embeddings", question_embed, k=10
)
# option["option_context"] = retrieved_examples["text"]
# option["option_context"] = " ".join(option["option_context"]).strip()
#result_dict = {
# 'example_id': example['example_id'],
# 'answer': example['answer'],
# 'question': question_text,
#options': example['options']
# }
return example
```
I intentionally commented on this portion of the code.
But when I call the `map` method, `ds_with_context = dataset.map(generate_context,load_from_cache_file=False)`
It calls the following error:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-55-75a458ce205c> in <module>
----> 1 ds_with_context = dataset.map(generate_context,load_from_cache_file=False)
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/dataset_dict.py in map(self, function, with_indices, input_columns, batched, batch_size, remove_columns, keep_in_memory, load_from_cache_file, cache_file_names, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc)
301 num_proc=num_proc,
302 )
--> 303 for k, dataset in self.items()
304 }
305 )
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/dataset_dict.py in <dictcomp>(.0)
301 num_proc=num_proc,
302 )
--> 303 for k, dataset in self.items()
304 }
305 )
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/arrow_dataset.py in map(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint)
1257 fn_kwargs=fn_kwargs,
1258 new_fingerprint=new_fingerprint,
-> 1259 update_data=update_data,
1260 )
1261 else:
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
155 }
156 # apply actual function
--> 157 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
158 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
159 # re-apply format to the output
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
156 kwargs_for_fingerprint["fingerprint_name"] = fingerprint_name
157 kwargs[fingerprint_name] = update_fingerprint(
--> 158 self._fingerprint, transform, kwargs_for_fingerprint
159 )
160
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/fingerprint.py in update_fingerprint(fingerprint, transform, transform_args)
103 for key in sorted(transform_args):
104 hasher.update(key)
--> 105 hasher.update(transform_args[key])
106 return hasher.hexdigest()
107
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/fingerprint.py in update(self, value)
55 def update(self, value):
56 self.m.update(f"=={type(value)}==".encode("utf8"))
---> 57 self.m.update(self.hash(value).encode("utf-8"))
58
59 def hexdigest(self):
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/fingerprint.py in hash(cls, value)
51 return cls.dispatch[type(value)](cls, value)
52 else:
---> 53 return cls.hash_default(value)
54
55 def update(self, value):
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/fingerprint.py in hash_default(cls, value)
44 @classmethod
45 def hash_default(cls, value):
---> 46 return cls.hash_bytes(dumps(value))
47
48 @classmethod
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/utils/py_utils.py in dumps(obj)
387 file = StringIO()
388 with _no_cache_fields(obj):
--> 389 dump(obj, file)
390 return file.getvalue()
391
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/utils/py_utils.py in dump(obj, file)
359 def dump(obj, file):
360 """pickle an object to a file"""
--> 361 Pickler(file, recurse=True).dump(obj)
362 return
363
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/dill/_dill.py in dump(self, obj)
452 raise PicklingError(msg)
453 else:
--> 454 StockPickler.dump(self, obj)
455 stack.clear() # clear record of 'recursion-sensitive' pickled objects
456 return
/usr/lib/python3.7/pickle.py in dump(self, obj)
435 if self.proto >= 4:
436 self.framer.start_framing()
--> 437 self.save(obj)
438 self.write(STOP)
439 self.framer.end_framing()
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/utils/py_utils.py in save_function(pickler, obj)
554 dill._dill._create_function,
555 (obj.__code__, globs, obj.__name__, obj.__defaults__, obj.__closure__, obj.__dict__, fkwdefaults),
--> 556 obj=obj,
557 )
558 else:
/usr/lib/python3.7/pickle.py in save_reduce(self, func, args, state, listitems, dictitems, obj)
636 else:
637 save(func)
--> 638 save(args)
639 write(REDUCE)
640
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
/usr/lib/python3.7/pickle.py in save_tuple(self, obj)
784 write(MARK)
785 for element in obj:
--> 786 save(element)
787
788 if id(obj) in memo:
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/dill/_dill.py in save_module_dict(pickler, obj)
939 # we only care about session the first pass thru
940 pickler._session = False
--> 941 StockPickler.save_dict(pickler, obj)
942 log.info("# D2")
943 return
/usr/lib/python3.7/pickle.py in save_dict(self, obj)
854
855 self.memoize(obj)
--> 856 self._batch_setitems(obj.items())
857
858 dispatch[dict] = save_dict
/usr/lib/python3.7/pickle.py in _batch_setitems(self, items)
880 for k, v in tmp:
881 save(k)
--> 882 save(v)
883 write(SETITEMS)
884 elif n:
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
547
548 # Save the reduce() output and finally memoize the object
--> 549 self.save_reduce(obj=obj, *rv)
550
551 def persistent_id(self, obj):
/usr/lib/python3.7/pickle.py in save_reduce(self, func, args, state, listitems, dictitems, obj)
660
661 if state is not None:
--> 662 save(state)
663 write(BUILD)
664
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/dill/_dill.py in save_module_dict(pickler, obj)
939 # we only care about session the first pass thru
940 pickler._session = False
--> 941 StockPickler.save_dict(pickler, obj)
942 log.info("# D2")
943 return
/usr/lib/python3.7/pickle.py in save_dict(self, obj)
854
855 self.memoize(obj)
--> 856 self._batch_setitems(obj.items())
857
858 dispatch[dict] = save_dict
/usr/lib/python3.7/pickle.py in _batch_setitems(self, items)
880 for k, v in tmp:
881 save(k)
--> 882 save(v)
883 write(SETITEMS)
884 elif n:
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/dill/_dill.py in save_module_dict(pickler, obj)
939 # we only care about session the first pass thru
940 pickler._session = False
--> 941 StockPickler.save_dict(pickler, obj)
942 log.info("# D2")
943 return
/usr/lib/python3.7/pickle.py in save_dict(self, obj)
854
855 self.memoize(obj)
--> 856 self._batch_setitems(obj.items())
857
858 dispatch[dict] = save_dict
/usr/lib/python3.7/pickle.py in _batch_setitems(self, items)
885 k, v = tmp[0]
886 save(k)
--> 887 save(v)
888 write(SETITEM)
889 # else tmp is empty, and we're done
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
547
548 # Save the reduce() output and finally memoize the object
--> 549 self.save_reduce(obj=obj, *rv)
550
551 def persistent_id(self, obj):
/usr/lib/python3.7/pickle.py in save_reduce(self, func, args, state, listitems, dictitems, obj)
660
661 if state is not None:
--> 662 save(state)
663 write(BUILD)
664
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/dill/_dill.py in save_module_dict(pickler, obj)
939 # we only care about session the first pass thru
940 pickler._session = False
--> 941 StockPickler.save_dict(pickler, obj)
942 log.info("# D2")
943 return
/usr/lib/python3.7/pickle.py in save_dict(self, obj)
854
855 self.memoize(obj)
--> 856 self._batch_setitems(obj.items())
857
858 dispatch[dict] = save_dict
/usr/lib/python3.7/pickle.py in _batch_setitems(self, items)
880 for k, v in tmp:
881 save(k)
--> 882 save(v)
883 write(SETITEMS)
884 elif n:
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
547
548 # Save the reduce() output and finally memoize the object
--> 549 self.save_reduce(obj=obj, *rv)
550
551 def persistent_id(self, obj):
/usr/lib/python3.7/pickle.py in save_reduce(self, func, args, state, listitems, dictitems, obj)
660
661 if state is not None:
--> 662 save(state)
663 write(BUILD)
664
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
502 f = self.dispatch.get(t)
503 if f is not None:
--> 504 f(self, obj) # Call unbound method with explicit self
505 return
506
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/dill/_dill.py in save_module_dict(pickler, obj)
939 # we only care about session the first pass thru
940 pickler._session = False
--> 941 StockPickler.save_dict(pickler, obj)
942 log.info("# D2")
943 return
/usr/lib/python3.7/pickle.py in save_dict(self, obj)
854
855 self.memoize(obj)
--> 856 self._batch_setitems(obj.items())
857
858 dispatch[dict] = save_dict
/usr/lib/python3.7/pickle.py in _batch_setitems(self, items)
885 k, v = tmp[0]
886 save(k)
--> 887 save(v)
888 write(SETITEM)
889 # else tmp is empty, and we're done
/usr/lib/python3.7/pickle.py in save(self, obj, save_persistent_id)
522 reduce = getattr(obj, "__reduce_ex__", None)
523 if reduce is not None:
--> 524 rv = reduce(self.proto)
525 else:
526 reduce = getattr(obj, "__reduce__", None)
TypeError: can't pickle SwigPyObject objects
```
Which I have no idea how to solve/deal with it
| 1,805 |
https://github.com/huggingface/datasets/issues/1803 | Querying examples from big datasets is slower than small datasets | [
"Hello, @lhoestq / @gaceladri : We have been seeing similar behavior with bigger datasets, where querying time increases. Are you folks aware of any solution that fixes this problem yet? ",
"Hi ! I'm pretty sure that it can be fixed by using the Arrow IPC file format instead of the raw streaming format but I haven't tested yet.\r\nI'll take a look at it soon and let you know",
"My workaround is to shard the dataset into splits in my ssd disk and feed the data in different training sessions. But it is a bit of a pain when we need to reload the last training session with the rest of the split with the Trainer in transformers.\r\n\r\nI mean, when I split the training and then reloads the model and optimizer, it not gets the correct global_status of the optimizer, so I need to hardcode some things. I'm planning to open an issue in transformers and think about it.\r\n```\r\nfrom datasets import load_dataset\r\n\r\nbook_corpus = load_dataset(\"bookcorpus\", split=\"train[:25%]\")\r\nwikicorpus = load_dataset(\"wikicorpus\", split=\"train[:25%]\")\r\nopenwebtext = load_dataset(\"openwebtext\", split=\"train[:25%]\")\r\n\r\nbig_dataset = datasets.concatenate_datasets([wikicorpus, openwebtext, book_corpus])\r\nbig_dataset.shuffle(seed=42)\r\nbig_dataset = big_dataset.map(encode, batched=True, num_proc=20, load_from_cache_file=True, writer_batch_size=5000)\r\nbig_dataset.set_format(type='torch', columns=[\"text\", \"input_ids\", \"attention_mask\", \"token_type_ids\"])\r\n\r\n\r\ntraining_args = TrainingArguments(\r\n output_dir=\"./linear_bert\",\r\n overwrite_output_dir=True,\r\n per_device_train_batch_size=71,\r\n save_steps=500,\r\n save_total_limit=10,\r\n logging_first_step=True,\r\n logging_steps=100,\r\n gradient_accumulation_steps=9,\r\n fp16=True,\r\n dataloader_num_workers=20,\r\n warmup_steps=24000,\r\n learning_rate=0.000545205002870214,\r\n adam_epsilon=1e-6,\r\n adam_beta2=0.98,\r\n weight_decay=0.01,\r\n max_steps=138974, # the total number of steps after concatenating 100% datasets\r\n max_grad_norm=1.0,\r\n)\r\n\r\ntrainer = Trainer(\r\n model=model,\r\n args=training_args,\r\n data_collator=data_collator,\r\n train_dataset=big_dataset,\r\n tokenizer=tokenizer))\r\n```\r\n\r\nI do one training pass with the total steps of this shard and I use len(bbig)/batchsize to stop the training (hardcoded in the trainer.py) when I pass over all the examples in this split.\r\n\r\nNow Im working, I will edit the comment with a more elaborated answer when I left the work.",
"I just tested and using the Arrow File format doesn't improve the speed... This will need further investigation.\r\n\r\nMy guess is that it has to iterate over the record batches or chunks of a ChunkedArray in order to retrieve elements.\r\n\r\nHowever if we know in advance in which chunk the element is, and at what index it is, then we can access it instantaneously. But this requires dealing with the chunked arrays instead of the pyarrow Table directly which is not practical.",
"I have a dataset with about 2.7 million rows (which I'm loading via `load_from_disk`), and I need to fetch around 300k (particular) rows of it, by index. Currently this is taking a really long time (~8 hours). I tried sharding the large dataset but overall it doesn't change how long it takes to fetch the desired rows.\r\n\r\nI actually have enough RAM that I could fit the large dataset in memory. Would having the large dataset in memory speed up querying? To find out, I tried to load (a column of) the large dataset into memory like this:\r\n```\r\ncolumn_data = large_ds['column_name']\r\n```\r\nbut in itself this takes a really long time.\r\n\r\nI'm pretty stuck - do you have any ideas what I should do? ",
"Hi ! Feel free to post a message on the [forum](/static-proxy?url=https%3A%2F%2Fdiscuss.huggingface.co%2Fc%2Fdatasets%2F10). I'd be happy to help you with this.\r\n\r\nIn your post on the forum, feel free to add more details about your setup:\r\nWhat are column names and types of your dataset ?\r\nHow was the dataset constructed ?\r\nIs the dataset shuffled ?\r\nIs the dataset tokenized ?\r\nAre you on a SSD or an HDD ?\r\n\r\nI'm sure we can figure something out.\r\nFor example on my laptop I can access the 6 millions articles from wikipedia in less than a minute.",
"Thanks @lhoestq, I've [posted on the forum](/static-proxy?url=https%3A%2F%2Fdiscuss.huggingface.co%2Ft%2Ffetching-rows-of-a-large-dataset-by-index%2F4271%3Fu%3Dabisee).",
"Fixed by #2122."
] | After some experiments with bookcorpus I noticed that querying examples from big datasets is slower than small datasets.
For example
```python
from datasets import load_dataset
b1 = load_dataset("bookcorpus", split="train[:1%]")
b50 = load_dataset("bookcorpus", split="train[:50%]")
b100 = load_dataset("bookcorpus", split="train[:100%]")
%timeit _ = b1[-1]
# 12.2 µs ± 70.4 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
%timeit _ = b50[-1]
# 92.5 µs ± 1.24 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
%timeit _ = b100[-1]
# 177 µs ± 3.13 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
```
It looks like the time to fetch the example increases with the size of the dataset.
This is maybe due to the use of the Arrow streaming format to store the data on disk. I guess pyarrow needs to iterate through the file as a stream to find the queried sample.
Maybe switching to the Arrow IPC file format could help fixing this issue.
Indeed according to the [documentation](https://arrow.apache.org/docs/format/Columnar.html?highlight=arrow1#ipc-file-format), it's identical to the streaming format except that it contains the memory offsets of each sample, which could fix the issue:
> We define a “file format” supporting random access that is build with the stream format. The file starts and ends with a magic string ARROW1 (plus padding). What follows in the file is identical to the stream format. At the end of the file, we write a footer containing a redundant copy of the schema (which is a part of the streaming format) plus memory offsets and sizes for each of the data blocks in the file. This enables random access any record batch in the file. See File.fbs for the precise details of the file footer.
cc @gaceladri since it can help speed up your training when this one is fixed. | 1,803 |
https://github.com/huggingface/datasets/issues/1797 | Connection error | [
"Hi ! For future references let me add a link to our discussion here : https://github.com/huggingface/datasets/issues/759#issuecomment-770684693\r\n\r\nLet me know if you manage to fix your proxy issue or if we can do something on our end to help you :)"
] | Hi
I am hitting to the error, help me and thanks.
`train_data = datasets.load_dataset("xsum", split="train")`
`ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/xsum/xsum.py` | 1,797 |
https://github.com/huggingface/datasets/issues/1796 | Filter on dataset too much slowww | [
"When I use the filter on the arrow table directly, it works like butter. But I can't find a way to update the table in `Dataset` object.\r\n\r\n```\r\nds_table = dataset.data.filter(mask=dataset['flag'])\r\n```",
"@thomwolf @lhoestq can you guys please take a look and recommend some solution.",
"Hi ! Currently the filter method reads the dataset batch by batch to write a new, filtered, arrow file on disk. Therefore all the reading + writing can take some time.\r\nUsing a mask directly on the arrow table doesn't do any read or write operation therefore it's way quicker.\r\n\r\nReplacing the old table by the new one should do the job:\r\n```python\r\ndataset._data = dataset._data.filter(...)\r\n```\r\n\r\nNote: this is a **workaround** and in general users shouldn't have to do that. In particular if you did some `shuffle` or `select` before that then it would not work correctly since the indices mapping (index from `__getitem__` -> index in the table) would not be valid anymore. But if you haven't done any `shuffle`, `select`, `shard`, `train_test_split` etc. then it should work.\r\n\r\nIdeally it would be awesome to update the filter function to allow masking this way !\r\nIf you would like to give it a shot I will be happy to help :) ",
"Yes, would be happy to contribute. Thanks",
"Hi @lhoestq @ayubSubhaniya,\r\n\r\nIf there's no progress on this one, can I try working on it?\r\n\r\nThanks,\r\nGunjan",
"Sure @gchhablani feel free to start working on it, this would be very appreciated :)\r\nThis feature is would be really awesome, especially since arrow allows to mask really quickly and without having to rewrite the dataset on disk",
"Hi @lhoestq, any updates on this issue? The `filter` method is still veryyy slow 😕 ",
"No update so far, we haven't worked on this yet :/\r\n\r\nThough PyArrow is much more stable than 3 years ago so it would be a good time to dive into this",
"Hi @lhoestq, thanks a lot for the update! \r\n\r\nI would like to work on this(if possible). Could you please give me some steps regarding how should I approach this? Also any references would be great! ",
"I just played a bit with it to make sure using `table.filter()` is fine, but actually it seems to create a new table **in memory** :/\r\nThis is an issue since it can quickly fill the RAM, and `datasets`'s role is to make sure you can load bigger-than-memory datasets. Therefore I don't think it's a good idea in the end to use `table.filter()`\r\n\r\nAnyway I just ran OP's code an it runs in 20ms now on my side thanks to the I/O optimizations we did.\r\n\r\nAnother way to speed up `filter` is to add support pyarrow expressions though, using e.g. arrow formatting + dataset.filter (runs in 10ms on my side):\r\n\r\n```python\r\nimport pyarrow.dataset as pds\r\nimport pyarrow.compute as pc\r\n\r\nexpr = pc.field(\"flag\") == True\r\n\r\nfiltered = dataset.with_format(\"arrow\").filter(\r\n lambda t: pds.dataset(t).to_table(columns={\"mask\": expr})[0].to_numpy(),\r\n batched=True,\r\n).with_format(None)\r\n```"
] | I have a dataset with 50M rows.
For pre-processing, I need to tokenize this and filter rows with the large sequence.
My tokenization took roughly 12mins. I used `map()` with batch size 1024 and multi-process with 96 processes.
When I applied the `filter()` function it is taking too much time. I need to filter sequences based on a boolean column.
Below are the variants I tried.
1. filter() with batch size 1024, single process (takes roughly 3 hr)
2. filter() with batch size 1024, 96 processes (takes 5-6 hrs ¯\\\_(ツ)\_/¯)
3. filter() with loading all data in memory, only a single boolean column (never ends).
Can someone please help?
Below is a sample code for small dataset.
```
from datasets import load_dataset
dataset = load_dataset('glue', 'mrpc', split='train')
dataset = dataset.map(lambda x: {'flag': random.randint(0,1)==1})
def _amplify(data):
return data
dataset = dataset.filter(_amplify, batch_size=1024, keep_in_memory=False, input_columns=['flag'])
```
| 1,796 |
https://github.com/huggingface/datasets/issues/1790 | ModuleNotFoundError: No module named 'apache_beam', when specific languages. | [
"Hi !\r\n\r\nApache Beam is a framework used to define data transformation pipelines. These pipeline can then be run in many runtimes: DataFlow, Spark, Flink, etc. There also exist a local runner called the DirectRunner.\r\nWikipedia is a dataset that requires some parsing, so to allow the processing to be run on this kind of runtime we're using Apache Beam.\r\n\r\nAt Hugging Face we've already processed certain versions of wikipedia (the `20200501.en` one for example) so that users can directly download the processed version instead of using Apache Beam to process it.\r\nHowever for the japanese language we haven't processed it so you'll have to run the processing on your side.\r\nSo you do need Apache Beam to process `20200501.ja`.\r\n\r\nYou can install Apache Beam with\r\n```\r\npip install apache-beam\r\n```\r\n\r\nI think we can probably improve the error message to let users know of this subtlety.\r\nWhat #498 implied is that Apache Beam is not needed when you process a dataset that doesn't use Apache Beam.",
"Thanks for your reply! \r\nI understood.\r\n\r\nI tried again with installing apache-beam, add ` beam_runner=\"DirectRunner\"` and an anther `mwparserfromhell` is also required so I installed it.\r\nbut, it also failed. It exited 1 without error message.\r\n\r\n```py\r\nimport datasets\r\n# BTW, 20200501.ja doesn't exist at wikipedia, so I specified date argument\r\nwiki = datasets.load_dataset(\"wikipedia\", language=\"ja\", date=\"20210120\", cache_dir=\"./datasets\", beam_runner=\"DirectRunner\")\r\nprint(wiki)\r\n```\r\nand its log is below\r\n```\r\nUsing custom data configuration 20210120.ja\r\nDownloading and preparing dataset wikipedia/20210120.ja-date=20210120,language=ja (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to ./datasets/wikipedia/20210120.ja-date=20210120,language=ja/0.0.0/4021357e28509391eab2f8300d9b689e7e8f3a877ebb3d354b01577d497ebc63...\r\nKilled\r\n```\r\n\r\nI also tried on another machine because it may caused by insufficient resources.\r\n```\r\n$ python main.py\r\nUsing custom data configuration 20210120.ja\r\nDownloading and preparing dataset wikipedia/20210120.ja-date=20210120,language=ja (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to ./datasets/wikipedia/20210120.ja-date=20210120,language=ja/0.0.0/4021357e28509391eab2f8300d9b689e7e8f3a877ebb3d354b01577d497ebc63...\r\n\r\nTraceback (most recent call last):\r\n File \"main.py\", line 3, in <module>\r\n wiki = datasets.load_dataset(\"wikipedia\", language=\"ja\", date=\"20210120\", cache_dir=\"./datasets\", beam_runner=\"DirectRunner\")\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/datasets/load.py\", line 609, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/datasets/builder.py\", line 526, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/datasets/builder.py\", line 1069, in _download_and_prepare\r\n pipeline_results = pipeline.run()\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/pipeline.py\", line 561, in run\r\n return self.runner.run_pipeline(self, self._options)\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/direct/direct_runner.py\", line 126, in run_pipeline\r\n return runner.run_pipeline(pipeline, options)\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 182, in run_pipeline\r\n self._latest_run_result = self.run_via_runner_api(\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 193, in run_via_runner_api\r\n return self.run_stages(stage_context, stages)\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 358, in run_stages\r\n stage_results = self._run_stage(\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 549, in _run_stage\r\n last_result, deferred_inputs, fired_timers = self._run_bundle(\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 595, in _run_bundle\r\n result, splits = bundle_manager.process_bundle(\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 888, in process_bundle\r\n self._send_input_to_worker(process_bundle_id, transform_id, elements)\r\n File \"/home/miyamonz/.cache/pypoetry/virtualenvs/try-datasets-4t4JWXxu-py3.8/lib/python3.8/site-packages/apache_beam/runners/portability/fn_api_runner/fn_runner.py\", line 765, in _send_input_to_worker\r\n data_out.write(byte_stream)\r\n File \"apache_beam/coders/stream.pyx\", line 42, in apache_beam.coders.stream.OutputStream.write\r\n File \"apache_beam/coders/stream.pyx\", line 47, in apache_beam.coders.stream.OutputStream.write\r\n File \"apache_beam/coders/stream.pyx\", line 109, in apache_beam.coders.stream.OutputStream.extend\r\nAssertionError: OutputStream realloc failed.\r\n```\r\n\r\n",
"Hi @miyamonz,\r\n\r\nI tried replicating this issue using the same snippet used by you. I am able to download the dataset without any issues, although I stopped it in the middle because the dataset is huge.\r\n\r\nBased on a similar issue [here](https://github.com/google-research/fixmatch/issues/23), it could be related to your environment setup, although I am just guessing here. Can you share these details?",
"thanks for your reply and sorry for my late response.\r\n\r\n## environment\r\nmy local machine environment info\r\n- Ubuntu on WSL2\r\n\r\n`lsb_release -a`\r\n```\r\nNo LSB modules are available.\r\nDistributor ID: Ubuntu\r\nDescription: Ubuntu 20.04.2 LTS\r\nRelease: 20.04\r\nCodename: focal\r\n```\r\n\r\nRTX 2070 super\r\nInside WSL, there is no nvidia-msi command. I don't know why.\r\nBut, `torch.cuda.is_available()` is true and when I start something ML training code GPU usage is growing up, so I think it works.\r\n\r\nFrom PowerShell, there is nvidia-smi.exe and result is below.\r\n```\r\n+-----------------------------------------------------------------------------+\r\n| NVIDIA-SMI 470.05 Driver Version: 470.05 CUDA Version: 11.3 |\r\n|-------------------------------+----------------------+----------------------+\r\n| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |\r\n| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |\r\n| | | MIG M. |\r\n|===============================+======================+======================|\r\n| 0 NVIDIA GeForce ... WDDM | 00000000:09:00.0 On | N/A |\r\n| 0% 30C P8 19W / 175W | 523MiB / 8192MiB | 3% Default |\r\n| | | N/A |\r\n+-------------------------------+----------------------+----------------------+\r\n\r\n+-----------------------------------------------------------------------------+\r\n| Processes: |\r\n| GPU GI CI PID Type Process name GPU Memory |\r\n| ID ID Usage |\r\n|=============================================================================|\r\n| 0 N/A N/A 1728 C+G Insufficient Permissions N/A |\r\n| 0 N/A N/A 3672 C+G ...ekyb3d8bbwe\\YourPhone.exe N/A |\r\n| 0 N/A N/A 6304 C+G ...2txyewy\\TextInputHost.exe N/A |\r\n| 0 N/A N/A 8648 C+G C:\\Windows\\explorer.exe N/A |\r\n| 0 N/A N/A 9536 C+G ...y\\ShellExperienceHost.exe N/A |\r\n| 0 N/A N/A 10668 C+G ...5n1h2txyewy\\SearchApp.exe N/A |\r\n| 0 N/A N/A 10948 C+G ...artMenuExperienceHost.exe N/A |\r\n| 0 N/A N/A 11988 C+G ...8wekyb3d8bbwe\\Cortana.exe N/A |\r\n| 0 N/A N/A 12464 C+G ...cw5n1h2txyewy\\LockApp.exe N/A |\r\n| 0 N/A N/A 13280 C+G ...upport\\CEF\\Max Helper.exe N/A |\r\n| 0 N/A N/A 15948 C+G ...t\\GoogleIMEJaRenderer.exe N/A |\r\n| 0 N/A N/A 16128 C+G ...ram Files\\Slack\\Slack.exe N/A |\r\n| 0 N/A N/A 19096 C+G ...8bbwe\\WindowsTerminal.exe N/A |\r\n+-----------------------------------------------------------------------------+\r\n```\r\n\r\nI don't know what should I show in such a case. If it's not enough, please tell me some commands.\r\n\r\n---\r\n## what I did\r\nI surveyed more and I found 2 issues.\r\n\r\nAbout the first one, I wrote it as a new issue.\r\nhttps://github.com/huggingface/datasets/issues/2031\r\n\r\nThe error I mentioned in the previous comment above, which occurred on my local machine, is no longer occurring.\r\n\r\nBut, it still failed. In the previous comment, I wrote `AssertionError: OutputStream realloc failed.` happen on another machine. It also happens on my local machine.\r\n\r\nHere's what I've tried.\r\n\r\nthe wikipedia.py downloads these xml.bz2 files based on dumpstatus.json\r\nIn Japanese Wikipedia dataset that I specified, it will download these 6 files.\r\n\r\n\r\n`https://dumps.wikimedia.org/jawiki/20210120/dumpstatus.json`\r\nand filtered json based on wikipedia.py is below.\r\n```json\r\n {\r\n \"jobs\": {\r\n \"articlesmultistreamdump\": {\r\n \"files\": {\r\n \"jawiki-20210120-pages-articles-multistream1.xml-p1p114794.bz2\": {\r\n \"url\": \"/jawiki/20210120/jawiki-20210120-pages-articles-multistream1.xml-p1p114794.bz2\"\r\n },\r\n \"jawiki-20210120-pages-articles-multistream2.xml-p114795p390428.bz2\": {\r\n \"url\": \"/jawiki/20210120/jawiki-20210120-pages-articles-multistream2.xml-p114795p390428.bz2\"\r\n },\r\n \"jawiki-20210120-pages-articles-multistream3.xml-p390429p902407.bz2\": {\r\n \"url\": \"/jawiki/20210120/jawiki-20210120-pages-articles-multistream3.xml-p390429p902407.bz2\"\r\n },\r\n \"jawiki-20210120-pages-articles-multistream4.xml-p902408p1721646.bz2\": {\r\n \"url\": \"/jawiki/20210120/jawiki-20210120-pages-articles-multistream4.xml-p902408p1721646.bz2\"\r\n },\r\n \"jawiki-20210120-pages-articles-multistream5.xml-p1721647p2807947.bz2\": {\r\n \"url\": \"/jawiki/20210120/jawiki-20210120-pages-articles-multistream5.xml-p1721647p2807947.bz2\"\r\n },\r\n \"jawiki-20210120-pages-articles-multistream6.xml-p2807948p4290013.bz2\": {\r\n \"url\": \"/jawiki/20210120/jawiki-20210120-pages-articles-multistream6.xml-p2807948p4290013.bz2\"\r\n }\r\n }\r\n }\r\n }\r\n }\r\n```\r\n\r\nSo, I tried running with fewer resources by modifying this line.\r\nhttps://github.com/huggingface/datasets/blob/13a5b7db992ad5cf77895e4c0f76595314390418/datasets/wikipedia/wikipedia.py#L524\r\nI changed it like this. just change filepaths list.\r\n` | \"Initialize\" >> beam.Create(filepaths[:1])`\r\n\r\nand I added a print line inside for the loop of _extract_content.\r\nlike this `if(i % 100000 == 0): print(i)`\r\n\r\nfirst, without modification, it always stops after all _extract_content is done.\r\n\r\n- `filepaths[:1]` then it succeeded.\r\n- `filepaths[:2]` then it failed.\r\nI don't try all patterns because each pattern takes a long time.\r\n\r\n### my opinion\r\nIt seems it's successful when the entire file size is small.\r\n \r\nso, at least it doesn't file-specific issue.\r\n\r\n\r\nI don't know it's true but I think when beam_writter writes into a file, it consumes memory depends on its entire file.\r\nbut It's correct Apache Beam's behavior? I'm not familiar with this library.\r\n",
"I don't know if this is related, but there is this issue on the wikipedia processing that you reported at #2031 (open PR is at #2037 ) .\r\nDoes the fix your proposed at #2037 helps in your case ?\r\n\r\nAnd for information, the DirectRunner of Apache Beam is not optimized for memory intensive tasks, so you must be right when you say that it uses the memory for the entire file.",
"the #2037 doesn't solve my problem directly, but I found the point!\r\n\r\nhttps://github.com/huggingface/datasets/blob/349ac4398a3bcae6356f14c5754483383a60e8a4/datasets/wikipedia/wikipedia.py#L523\r\nthis `beam.transforms.Reshuffle()` cause the memory error.\r\n\r\nit makes sense if I consider the shuffle means. Beam's reshuffle seems need put all data in memory.\r\nPreviously I doubt that this line causes error, but at that time another bug showed in #2037 made error, so I can't found it.\r\n\r\nAnyway, I comment out this line, and run load_dataset, then it works!\r\n\r\n```python\r\nwiki = datasets.load_dataset(\r\n \"./wikipedia.py\",\r\n cache_dir=\"./datasets\",\r\n beam_runner=\"DirectRunner\",\r\n language=\"ja\",\r\n date=\"20210120\",\r\n)[\"train\"]\r\n```\r\n\r\n\r\nDataset has already shuffle function. https://github.com/huggingface/datasets/blob/349ac4398a3bcae6356f14c5754483383a60e8a4/src/datasets/arrow_dataset.py#L2069\r\nSo, though I don't know it's difference correctly, but I think Beam's reshuffle isn't be needed. How do you think?",
"The reshuffle is needed when you use parallelism.\r\nThe objective is to redistribute the articles evenly on the workers, since the `_extract_content` step generated many articles per file. By using reshuffle, we can split the processing of the articles of one file into several workers. Without reshuffle, all the articles of one file would be processed on the same worker that read the file, making the whole process take a very long time.",
"Maybe the reshuffle step can be added only if the runner is not a DirectRunner ?"
] | ```py
import datasets
wiki = datasets.load_dataset('wikipedia', '20200501.ja', cache_dir='./datasets')
```
then `ModuleNotFoundError: No module named 'apache_beam'` happend.
The error doesn't appear when it's '20200501.en'.
I don't know Apache Beam, but according to #498 it isn't necessary when it's saved to local. is it correct? | 1,790 |
https://github.com/huggingface/datasets/issues/1786 | How to use split dataset | [
"By default, all 3 splits will be loaded if you run the following:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\ndataset = load_dataset(\"lambada\")\r\nprint(dataset[\"train\"])\r\nprint(dataset[\"valid\"])\r\n\r\n```\r\n\r\nIf you wanted to do load this manually, you could do this:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\ndata_files = {\r\n \"train\": \"data/lambada/train.txt\",\r\n \"valid\": \"data/lambada/valid.txt\",\r\n \"test\": \"data/lambada/test.txt\",\r\n}\r\nds = load_dataset(\"text\", data_files=data_files)\r\n```",
"Thank you for the quick response! "
] | 
Hey,
I want to split the lambada dataset into corpus, test, train and valid txt files (like penn treebank) but I am not able to achieve this. What I am doing is, executing the lambada.py file in my project but its not giving desired results. Any help will be appreciated! | 1,786 |
https://github.com/huggingface/datasets/issues/1785 | Not enough disk space (Needed: Unknown size) when caching on a cluster | [
"Hi ! \r\n\r\nWhat do you mean by \"disk_usage(\".\").free` can't compute on the cluster's shared disk\" exactly ?\r\nDoes it return 0 ?",
"Yes, that's right. It shows 0 free space even though there is. I suspect it might have to do with permissions on the shared disk.\r\n\r\n```python\r\n>>> disk_usage(\".\")\r\nusage(total=999999, used=999999, free=0)\r\n```",
"That's an interesting behavior...\r\nDo you know any other way to get the free space that works in your case ?\r\nAlso if it's a permission issue could you try fix the permissions and let mus know if that helped ?",
"I think its an issue on the clusters end (unclear exactly why -- maybe something with docker containers?), will close the issue",
"Were you able to figure it out?",
"@philippnoah I had fixed it with a small hack where I patched `has_sufficient_disk_space` to always return `True`. you can do that with an import without having to modify the `datasets` package",
"@olinguyen Thanks for the suggestion, it works but I had to to edit builder.py in the installed package. Can you please explain how were you able to do this using import?",
"I was able to patch the builder code in my notebook before the load data call and it works. \r\n```\r\nimport datasets\r\ndatasets.builder.has_sufficient_disk_space = lambda needed_bytes, directory='.': True\r\n```"
] | I'm running some experiments where I'm caching datasets on a cluster and accessing it through multiple compute nodes. However, I get an error when loading the cached dataset from the shared disk.
The exact error thrown:
```bash
>>> load_dataset(dataset, cache_dir="/path/to/cluster/shared/path")
OSError: Not enough disk space. Needed: Unknown size (download: Unknown size, generated: Unknown size, post-processed: Unknown size)
```
[`utils.has_sufficient_disk_space`](https://github.com/huggingface/datasets/blob/8a03ab7d123a76ee744304f21ce868c75f411214/src/datasets/utils/py_utils.py#L332) fails on each job because of how the cluster system is designed (`disk_usage(".").free` can't compute on the cluster's shared disk).
This is exactly where the error gets thrown:
https://github.com/huggingface/datasets/blob/master/src/datasets/builder.py#L502
```python
if not utils.has_sufficient_disk_space(self.info.size_in_bytes or 0, directory=self._cache_dir_root):
raise IOError(
"Not enough disk space. Needed: {} (download: {}, generated: {}, post-processed: {})".format(
utils.size_str(self.info.size_in_bytes or 0),
utils.size_str(self.info.download_size or 0),
utils.size_str(self.info.dataset_size or 0),
utils.size_str(self.info.post_processing_size or 0),
)
)
```
What would be a good way to circumvent this? my current fix is to manually comment out that part, but that is not ideal.
Would it be possible to pass a flag to skip this check on disk space? | 1,785 |
https://github.com/huggingface/datasets/issues/1784 | JSONDecodeError on JSON with multiple lines | [
"Hi !\r\n\r\nThe `json` dataset script does support this format. For example loading a dataset with this format works on my side:\r\n```json\r\n{\"key1\":11, \"key2\":12, \"key3\":13}\r\n{\"key1\":21, \"key2\":22, \"key3\":23}\r\n```\r\n\r\nCan you show the full stacktrace please ? Also which version of datasets and pyarrow are you using ?\r\n\r\n",
"Hi Quentin!\r\n\r\nI apologize for bothering you. There was some issue with my pyarrow version as far as I understand. I don't remember the exact version I was using as I didn't check it.\r\n\r\nI repeated it with `datasets 1.2.1` and `pyarrow 2.0.0` and it worked.\r\n\r\nClosing this issue. Again, sorry for the bother.\r\n\r\nThanks,\r\nGunjan"
] | Hello :),
I have been trying to load data using a JSON file. Based on the [docs](https://huggingface.co/docs/datasets/loading_datasets.html#json-files), the following format is supported:
```json
{"key1":11, "key2":12, "key3":13}
{"key1":21, "key2":22, "key3":23}
```
But, when I try loading a dataset with the same format, I get a JSONDecodeError : `JSONDecodeError: Extra data: line 2 column 1 (char 7142)`. Now, this is expected when using `json` to load a JSON file. But I was wondering if there are any special arguments to pass when using `load_dataset` as the docs suggest that this format is supported.
When I convert the JSON file to a list of dictionaries format, I get AttributeError: `AttributeError: 'list' object has no attribute 'keys'`. So, I can't convert them to list of dictionaries either.
Please let me know :)
Thanks,
Gunjan | 1,784 |
https://github.com/huggingface/datasets/issues/1783 | Dataset Examples Explorer | [
"Hi @ChewKokWah,\r\n\r\nWe're working on it! In the meantime, you can still find the dataset explorer at the following URL: https://huggingface.co/datasets/viewer/",
"Glad to see that it still exist, this existing one is more than good enough for me, it is feature rich, simple to use and concise. \r\nHope similar feature can be retain in the future version."
] | In the Older version of the Dataset, there are a useful Dataset Explorer that allow user to visualize the examples (training, test and validation) of a particular dataset, it is no longer there in current version.
Hope HuggingFace can re-enable the feature that at least allow viewing of the first 20 examples of a particular dataset, or alternatively can extract 20 examples for each datasets and make those part of the Dataset Card Documentation. | 1,783 |
https://github.com/huggingface/datasets/issues/1781 | AttributeError: module 'pyarrow' has no attribute 'PyExtensionType' during import | [
"Hi ! I'm not able to reproduce the issue. Can you try restarting your runtime ?\r\n\r\nThe PyExtensionType is available in pyarrow starting 0.17.1 iirc. If restarting your runtime doesn't fix this, can you try updating pyarrow ?\r\n```\r\npip install pyarrow --upgrade\r\n```",
"We should bump up the version test of pyarrow maybe no?\r\n\r\nhttps://github.com/huggingface/datasets/blob/master/src/datasets/__init__.py#L60",
"Yes indeed.\r\n\r\nAlso it looks like Pyarrow 3.0.0 got released on pypi 10 hours ago. This might be related to the bug, I'll investigate\r\nEDIT: looks like the 3.0.0 release doesn't have unexpected breaking changes for us, so I don't think the issue comes from that",
"Maybe colab moved to pyarrow 0.16 by default (instead of 0.14 before)?",
"Installing datasets installs pyarrow>=0.17.1 so in theory it doesn't matter which version of pyarrow colab has by default (which is currently pyarrow 0.14.1).\r\n\r\nAlso now the colab runtime refresh the pyarrow version automatically after the update from pip (previously you needed to restart your runtime).\r\n\r\nI guess what happened is that Colab didn't refresh pyarrow for some reason, and the AttributeError was raised *before* the pyarrow version check from `datasets` at https://github.com/huggingface/datasets/blob/master/src/datasets/__init__.py#L60",
"Yes colab doesn’t reload preloaded library unless you restart the instance. Maybe we should move the check on top of the init ",
"Yes I'll do that :)",
"I updated the pyarrow version check in #1782",
"restarting worked for me\r\n> ```\r\n\r\nyes it worked for me"
] | I'm using Colab. And suddenly this morning, there is this error. Have a look below!

| 1,781 |
https://github.com/huggingface/datasets/issues/1777 | GPT2 MNLI training using run_glue.py | [] | Edit: I'm closing this because I actually meant to post this in `transformers `not `datasets`
Running this on Google Colab,
```
!python run_glue.py \
--model_name_or_path gpt2 \
--task_name mnli \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_gpu_train_batch_size 10 \
--gradient_accumulation_steps 32\
--learning_rate 2e-5 \
--num_train_epochs 3.0 \
--output_dir models/gpt2/mnli/
```
I get the following error,
```
"Asking to pad but the tokenizer does not have a padding token. "
ValueError: Asking to pad but the tokenizer does not have a padding token. Please select a token to use as `pad_token` `(tokenizer.pad_token = tokenizer.eos_token e.g.)` or add a new pad token via `tokenizer.add_special_tokens({'pad_token': '[PAD]'})`.
```
Do I need to modify the trainer to work with GPT2 ? | 1,777 |
https://github.com/huggingface/datasets/issues/1776 | [Question & Bug Report] Can we preprocess a dataset on the fly? | [
"We are very actively working on this. How does your dataset look like in practice (number/size/type of files)?",
"It's a text file with many lines (about 1B) of Chinese sentences. I use it to train language model using https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm_wwm.py",
"Indeed I will submit a PR in a fez days to enable processing on-the-fly :)\r\nThis can be useful in language modeling for tokenization, padding etc.\r\n",
"any update on this issue? ...really look forward to use it ",
"Hi @acul3,\r\n\r\nPlease look at the discussion on a related Issue #1825. I think using `set_transform` after building from source should do.",
"@gchhablani thank you so much\r\n\r\nwill try look at it"
] | I know we can use `Datasets.map` to preprocess a dataset, but I'm using it with very large corpus which generates huge cache file (several TB cache from a 400 GB text file). I have no disk large enough to save it. Can we preprocess a dataset on the fly without generating cache?
BTW, I tried raising `writer_batch_size`. Seems that argument doesn't have any effect when it's larger than `batch_size`, because you are saving all the batch instantly after it's processed. Please check the following code:
https://github.com/huggingface/datasets/blob/0281f9d881f3a55c89aeaa642f1ba23444b64083/src/datasets/arrow_dataset.py#L1532 | 1,776 |
https://github.com/huggingface/datasets/issues/1775 | Efficient ways to iterate the dataset | [
"It seems that selecting a subset of colums directly from the dataset, i.e., dataset[\"column\"], is slow.",
"I was wrong, ```dataset[\"column\"]``` is fast."
] | For a large dataset that does not fits the memory, how can I select only a subset of features from each example?
If I iterate over the dataset and then select the subset of features one by one, the resulted memory usage will be huge. Any ways to solve this?
Thanks | 1,775 |
https://github.com/huggingface/datasets/issues/1774 | is it possible to make slice to be more compatible like python list and numpy? | [
"Hi ! Thanks for reporting.\r\nI am working on changes in the way data are sliced from arrow. I can probably fix your issue with the changes I'm doing.\r\nIf you have some code to reproduce the issue it would be nice so I can make sure that this case will be supported :)\r\nI'll make a PR in a few days ",
"Good if you can take care at your side.\r\nHere is the [colab notebook](https://colab.research.google.com/drive/19c-abm87RTRYgW9G1D8ktfwRW95zDYBZ?usp=sharing)"
] | Hi,
see below error:
```
AssertionError: Requested slice [:10000000000000000] incompatible with 20 examples.
``` | 1,774 |
https://github.com/huggingface/datasets/issues/1773 | bug in loading datasets | [
"Looks like an issue with your csv file. Did you use the right delimiter ?\r\nApparently at line 37 the CSV reader from pandas reads 2 fields instead of 1.",
"Note that you can pass any argument you would pass to `pandas.read_csv` as kwargs to `load_dataset`. For example you can do\r\n```python\r\nfrom datasets import load_dataset\r\ndataset = load_dataset('csv', data_files=data_files, sep=\"\\t\")\r\n```\r\n\r\nfor example to use a tab separator.\r\n\r\nYou can see the full list of arguments here: https://github.com/huggingface/datasets/blob/master/src/datasets/packaged_modules/csv/csv.py\r\n\r\n(I've not found the list in the documentation though, we definitely must add them !)",
"You can try to convert the file to (CSV UTF-8)"
] | Hi,
I need to load a dataset, I use these commands:
```
from datasets import load_dataset
dataset = load_dataset('csv', data_files={'train': 'sick/train.csv',
'test': 'sick/test.csv',
'validation': 'sick/validation.csv'})
print(dataset['validation'])
```
the dataset in sick/train.csv are simple csv files representing the data. I am getting this error, do you have an idea how I can solve this? thank you @lhoestq
```
Using custom data configuration default
Downloading and preparing dataset csv/default-61468fc71a743ec1 (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /julia/cache_home_2/datasets/csv/default-61468fc71a743ec1/0.0.0/2960f95a26e85d40ca41a230ac88787f715ee3003edaacb8b1f0891e9f04dda2...
Traceback (most recent call last):
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 485, in incomplete_dir
yield tmp_dir
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 527, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 604, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 959, in _prepare_split
for key, table in utils.tqdm(generator, unit=" tables", leave=False, disable=not_verbose):
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/tqdm-4.49.0-py3.7.egg/tqdm/std.py", line 1133, in __iter__
for obj in iterable:
File "/julia/cache_home_2/modules/datasets_modules/datasets/csv/2960f95a26e85d40ca41a230ac88787f715ee3003edaacb8b1f0891e9f04dda2/csv.py", line 129, in _generate_tables
for batch_idx, df in enumerate(csv_file_reader):
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/pandas-1.2.0-py3.7-linux-x86_64.egg/pandas/io/parsers.py", line 1029, in __next__
return self.get_chunk()
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/pandas-1.2.0-py3.7-linux-x86_64.egg/pandas/io/parsers.py", line 1079, in get_chunk
return self.read(nrows=size)
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/pandas-1.2.0-py3.7-linux-x86_64.egg/pandas/io/parsers.py", line 1052, in read
index, columns, col_dict = self._engine.read(nrows)
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/pandas-1.2.0-py3.7-linux-x86_64.egg/pandas/io/parsers.py", line 2056, in read
data = self._reader.read(nrows)
File "pandas/_libs/parsers.pyx", line 756, in pandas._libs.parsers.TextReader.read
File "pandas/_libs/parsers.pyx", line 783, in pandas._libs.parsers.TextReader._read_low_memory
File "pandas/_libs/parsers.pyx", line 827, in pandas._libs.parsers.TextReader._read_rows
File "pandas/_libs/parsers.pyx", line 814, in pandas._libs.parsers.TextReader._tokenize_rows
File "pandas/_libs/parsers.pyx", line 1951, in pandas._libs.parsers.raise_parser_error
pandas.errors.ParserError: Error tokenizing data. C error: Expected 1 fields in line 37, saw 2
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "write_sick.py", line 19, in <module>
'validation': 'sick/validation.csv'})
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/load.py", line 612, in load_dataset
ignore_verifications=ignore_verifications,
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 534, in download_and_prepare
self._save_info()
File "/julia/libs/anaconda3/envs/success/lib/python3.7/contextlib.py", line 130, in __exit__
self.gen.throw(type, value, traceback)
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 491, in incomplete_dir
shutil.rmtree(tmp_dir)
File "/julia/libs/anaconda3/envs/success/lib/python3.7/shutil.py", line 498, in rmtree
onerror(os.rmdir, path, sys.exc_info())
File "/julia/libs/anaconda3/envs/success/lib/python3.7/shutil.py", line 496, in rmtree
os.rmdir(path)
OSError: [Errno 39] Directory not empty: '/julia/cache_home_2/datasets/csv/default-61468fc71a743ec1/0.0.0/2960f95a26e85d40ca41a230ac88787f715ee3003edaacb8b1f0891e9f04dda2.incomplete'
```
| 1,773 |
https://github.com/huggingface/datasets/issues/1772 | Adding SICK dataset | [] | Hi
It would be great to include SICK dataset.
## Adding a Dataset
- **Name:** SICK
- **Description:** a well known entailment dataset
- **Paper:** http://marcobaroni.org/composes/sick.html
- **Data:** http://marcobaroni.org/composes/sick.html
- **Motivation:** this is an important NLI benchmark
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
thanks | 1,772 |
https://github.com/huggingface/datasets/issues/1771 | Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.2.1/datasets/csv/csv.py | [
"I temporary manually download csv.py as custom dataset loading script",
"Indeed in 1.2.1 the script to process csv file is downloaded. Starting from the next release though we include the csv processing directly in the library.\r\nSee PR #1726 \r\nWe'll do a new release soon :)",
"Thanks."
] | Hi,
When I load_dataset from local csv files, below error happened, looks raw.githubusercontent.com was blocked by the chinese government. But why it need to download csv.py? should it include when pip install the dataset?
```
Traceback (most recent call last):
File "/home/tom/pyenv/pystory/lib/python3.6/site-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/home/tom/pyenv/pystory/lib/python3.6/site-packages/datasets/utils/file_utils.py", line 343, in cached_path
max_retries=download_config.max_retries,
File "/home/tom/pyenv/pystory/lib/python3.6/site-packages/datasets/utils/file_utils.py", line 617, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.2.1/datasets/csv/csv.py
``` | 1,771 |
https://github.com/huggingface/datasets/issues/1770 | how can I combine 2 dataset with different/same features? | [
"Hi ! Currently we don't have a way to `zip` datasets but we plan to add this soon :)\r\nFor now you'll need to use `map` to add the fields from one dataset to the other. See the comment here for more info : https://github.com/huggingface/datasets/issues/853#issuecomment-727872188",
"Good to hear.\r\nCurrently I did not use map , just fetch src and tgt from the 2 dataset and merge them.\r\nIt will be a release if you can deal with it at the backend.\r\nThanks.",
"Hi! You can rename the columns and concatenate the datasets along `axis=1` to get the desired result as follows:\r\n```python\r\nds1 = ds1.rename_column(\"text\", \"src\")\r\nds2 = ds2.rename_column(\"text\", \"tgt\")\r\nds = datasets.concatenate_datasets([\"ds1\", \"ds2\"], axis=1)\r\n```"
] | to combine 2 dataset by one-one map like ds = zip(ds1, ds2):
ds1: {'text'}, ds2: {'text'}, combine ds:{'src', 'tgt'}
or different feature:
ds1: {'src'}, ds2: {'tgt'}, combine ds:{'src', 'tgt'} | 1,770 |
https://github.com/huggingface/datasets/issues/1769 | _pickle.PicklingError: Can't pickle typing.Union[str, NoneType]: it's not the same object as typing.Union when calling datasets.map with num_proc=2 | [
"More information: `run_mlm.py` will raise same error when `data_args.line_by_line==True`\r\n\r\nhttps://github.com/huggingface/transformers/blob/9152f16023b59d262b51573714b40325c8e49370/examples/language-modeling/run_mlm.py#L300\r\n",
"Hi ! What version of python and datasets do you have ? And also what version of dill and pickle ?",
"> Hi ! What version of python and datasets do you have ? And also what version of dill and pickle ?\r\n\r\npython==3.6.10\r\ndatasets==1.2.1\r\ndill==0.3.2\r\npickle.format_version==4.0",
"Multiprocessing in python require all the functions to be picklable. More specifically, functions need to be picklable with `dill`.\r\n\r\nHowever objects like `typing.Union[str, NoneType]` are not picklable in python <3.7.\r\nCan you try to update your python version to python>=3.7 ?\r\n"
] | It may be a bug of multiprocessing with Datasets, when I disable the multiprocessing by set num_proc to None, everything works fine.
The script I use is https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm_wwm.py
Script args:
```
--model_name_or_path
../../../model/chinese-roberta-wwm-ext
--train_file
/nfs/volume-377-2/bert/data/test/train.txt
--output_dir
test
--do_train
--per_device_train_batch_size
2
--gradient_accumulation_steps
2
--learning_rate
1e-4
--max_steps
1000
--warmup_steps
10
--save_steps
1000
--save_total_limit
1
--seed
23333
--max_seq_length
512
--preprocessing_num_workers
2
--cache_dir
/nfs/volume-377-2/bert/data/test/cache
```
Where the `/nfs/volume-377-2/bert/data/test/train.txt` is just a toy example with 10000 lines of random string, you should be able to reproduce this error esaily.
Full Traceback:
```
Traceback (most recent call last):
File "/nfs/volume-377-2/bert/transformers/examples/language-modeling/run_mlm_wwm.py", line 398, in <module>
main()
File "/nfs/volume-377-2/bert/transformers/examples/language-modeling/run_mlm_wwm.py", line 325, in main
load_from_cache_file=not data_args.overwrite_cache,
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/datasets/dataset_dict.py", line 303, in map
for k, dataset in self.items()
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/datasets/dataset_dict.py", line 303, in <dictcomp>
for k, dataset in self.items()
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/datasets/arrow_dataset.py", line 1318, in map
transformed_shards = [r.get() for r in results]
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/datasets/arrow_dataset.py", line 1318, in <listcomp>
transformed_shards = [r.get() for r in results]
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/multiprocess/pool.py", line 644, in get
raise self._value
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/multiprocess/pool.py", line 424, in _handle_tasks
put(task)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/multiprocess/connection.py", line 209, in send
self._send_bytes(_ForkingPickler.dumps(obj))
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/multiprocess/reduction.py", line 54, in dumps
cls(buf, protocol, *args, **kwds).dump(obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/dill/_dill.py", line 446, in dump
StockPickler.dump(self, obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 409, in dump
self.save(obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 751, in save_tuple
save(element)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/dill/_dill.py", line 933, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 821, in save_dict
self._batch_setitems(obj.items())
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 847, in _batch_setitems
save(v)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/dill/_dill.py", line 1438, in save_function
obj.__dict__, fkwdefaults), obj=obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 610, in save_reduce
save(args)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 751, in save_tuple
save(element)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 736, in save_tuple
save(element)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/dill/_dill.py", line 1170, in save_cell
pickler.save_reduce(_create_cell, (f,), obj=obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 610, in save_reduce
save(args)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 736, in save_tuple
save(element)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 521, in save
self.save_reduce(obj=obj, *rv)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 605, in save_reduce
save(cls)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/dill/_dill.py", line 1365, in save_type
obj.__bases__, _dict), obj=obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 610, in save_reduce
save(args)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 751, in save_tuple
save(element)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/dill/_dill.py", line 933, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 821, in save_dict
self._batch_setitems(obj.items())
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 847, in _batch_setitems
save(v)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File "/home/luban/miniconda3/envs/py36/lib/python3.6/site-packages/dill/_dill.py", line 933, in save_module_dict
StockPickler.save_dict(pickler, obj)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 821, in save_dict
self._batch_setitems(obj.items())
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 847, in _batch_setitems
save(v)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 507, in save
self.save_global(obj, rv)
File "/home/luban/miniconda3/envs/py36/lib/python3.6/pickle.py", line 927, in save_global
(obj, module_name, name))
_pickle.PicklingError: Can't pickle typing.Union[str, NoneType]: it's not the same object as typing.Union
```
| 1,769 |
https://github.com/huggingface/datasets/issues/1766 | Issues when run two programs compute the same metrics | [
"Hi ! To avoid collisions you can specify a `experiment_id` when instantiating your metric using `load_metric`. It will replace \"default_experiment\" with the experiment id that you provide in the arrow filename. \r\n\r\nAlso when two `experiment_id` collide we're supposed to detect it using our locking mechanism. Not sure why it didn't work in your case. Could you share some code that reproduces the issue ? This would help us investigate.",
"Thank you for your response. I fixed the issue by set \"keep_in_memory=True\" when load_metric. \r\nI cannot share the entire source code but below is the wrapper I wrote:\r\n\r\n```python\r\nclass Evaluation:\r\n def __init__(self, metric='sacrebleu'):\r\n # self.metric = load_metric(metric, keep_in_memory=True)\r\n self.metric = load_metric(metric)\r\n\r\n def add(self, predictions, references):\r\n self.metric.add_batch(predictions=predictions, references=references)\r\n\r\n def compute(self):\r\n return self.metric.compute()['score']\r\n```\r\n\r\nThen call the given wrapper as follows:\r\n\r\n```python\r\neval = Evaluation(metric='sacrebleu')\r\nfor query, candidates, labels in tqdm(dataset):\r\n predictions = net.generate(query)\r\n references = [[s] for s in labels]\r\n eval.add(predictions, references)\r\n if n % 100 == 0:\r\n bleu += eval.compute()\r\n eval = Evaluation(metric='sacrebleu')"
] | I got the following error when running two different programs that both compute sacreblue metrics. It seems that both read/and/write to the same location (.cache/huggingface/metrics/sacrebleu/default/default_experiment-1-0.arrow) where it caches the batches:
```
File "train_matching_min.py", line 160, in <module>ch_9_label
avg_loss = valid(epoch, args.batch, args.validation, args.with_label)
File "train_matching_min.py", line 93, in valid
bleu += eval.compute()
File "/u/tlhoang/projects/seal/match/models/eval.py", line 23, in compute
return self.metric.compute()['score']
File "/dccstor/know/anaconda3/lib/python3.7/site-packages/datasets/metric.py", line 387, in compute
self._finalize()
File "/dccstor/know/anaconda3/lib/python3.7/site-packages/datasets/metric.py", line 355, in _finalize
self.data = Dataset(**reader.read_files([{"filename": f} for f in file_paths]))
File "/dccstor/know/anaconda3/lib/python3.7/site-packages/datasets/arrow_reader.py", line 231, in read_files
pa_table = self._read_files(files)
File "/dccstor/know/anaconda3/lib/python3.7/site-packages/datasets/arrow_reader.py", line 170, in _read_files
pa_table: pa.Table = self._get_dataset_from_filename(f_dict)
File "/dccstor/know/anaconda3/lib/python3.7/site-packages/datasets/arrow_reader.py", line 299, in _get_dataset_from_filename
pa_table = f.read_all()
File "pyarrow/ipc.pxi", line 481, in pyarrow.lib.RecordBatchReader.read_all
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Expected to read 1819307375 metadata bytes, but only read 454396
``` | 1,766 |
https://github.com/huggingface/datasets/issues/1765 | Error iterating over Dataset with DataLoader | [
"Instead of:\r\n```python\r\ndataloader = torch.utils.data.DataLoader(encoded_dataset, batch_sampler=32)\r\n```\r\nIt should be:\r\n```python\r\ndataloader = torch.utils.data.DataLoader(encoded_dataset, batch_size=32)\r\n```\r\n\r\n`batch_sampler` accepts a Sampler object or an Iterable, so you get an error.",
"@mariosasko I thought that would fix it, but now I'm getting a different error:\r\n\r\n```\r\n/usr/local/lib/python3.6/dist-packages/datasets/arrow_dataset.py:851: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:141.)\r\n return torch.tensor(x, **format_kwargs)\r\n---------------------------------------------------------------------------\r\nRuntimeError Traceback (most recent call last)\r\n<ipython-input-20-3af1d82bf93a> in <module>()\r\n 1 dataloader = torch.utils.data.DataLoader(encoded_dataset, batch_size=32)\r\n----> 2 next(iter(dataloader))\r\n\r\n5 frames\r\n/usr/local/lib/python3.6/dist-packages/torch/utils/data/_utils/collate.py in default_collate(batch)\r\n 53 storage = elem.storage()._new_shared(numel)\r\n 54 out = elem.new(storage)\r\n---> 55 return torch.stack(batch, 0, out=out)\r\n 56 elif elem_type.__module__ == 'numpy' and elem_type.__name__ != 'str_' \\\r\n 57 and elem_type.__name__ != 'string_':\r\n\r\nRuntimeError: stack expects each tensor to be equal size, but got [7] at entry 0 and [10] at entry 1\r\n```\r\n\r\nAny thoughts what this means?I Do I need padding?",
"Yes, padding is an answer. \r\n\r\nThis can be solved easily by passing a callable to the collate_fn arg of DataLoader that adds padding. ",
"Padding was the fix, thanks!",
"dataloader = torch.utils.data.DataLoader(encoded_dataset, batch_size=4)\r\nbatch = next(iter(dataloader))\r\n\r\ngetting \r\nValueError: cannot reshape array of size 8192 into shape (1,512,4)\r\n\r\nI had put padding as 2048 for encoded_dataset\r\nkindly help",
"data_loader_val = torch.utils.data.DataLoader(val_dataset, batch_size=32, shuffle=True, drop_last=False, num_workers=0)\r\ndataiter = iter(data_loader_val)\r\nimages, _ = next(dataiter)\r\n\r\ngetting -> TypeError: 'list' object is not callable\r\n\r\nCannot iterate through the data. Kindly suggest."
] | I have a Dataset that I've mapped a tokenizer over:
```
encoded_dataset.set_format(type='torch',columns=['attention_mask','input_ids','token_type_ids'])
encoded_dataset[:1]
```
```
{'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]),
'input_ids': tensor([[ 101, 178, 1198, 1400, 1714, 22233, 21365, 4515, 8618, 1113,
102]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])}
```
When I try to iterate as in the docs, I get errors:
```
dataloader = torch.utils.data.DataLoader(encoded_dataset, batch_sampler=32)
next(iter(dataloader))
```
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-45-05180ba8aa35> in <module>()
1 dataloader = torch.utils.data.DataLoader(encoded_dataset, batch_sampler=32)
----> 2 next(iter(dataloader))
3 frames
/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py in __init__(self, loader)
411 self._timeout = loader.timeout
412 self._collate_fn = loader.collate_fn
--> 413 self._sampler_iter = iter(self._index_sampler)
414 self._base_seed = torch.empty((), dtype=torch.int64).random_(generator=loader.generator).item()
415 self._persistent_workers = loader.persistent_workers
TypeError: 'int' object is not iterable
``` | 1,765 |
https://github.com/huggingface/datasets/issues/1764 | Connection Issues | [
"Academic WIFI was blocking."
] | Today, I am getting connection issues while loading a dataset and the metric.
```
Traceback (most recent call last):
File "src/train.py", line 180, in <module>
train_dataset, dev_dataset, test_dataset = create_race_dataset()
File "src/train.py", line 130, in create_race_dataset
train_dataset = load_dataset("race", "all", split="train")
File "/Users/saeed/Desktop/codes/repos/dreamscape-qa/env/lib/python3.7/site-packages/datasets/load.py", line 591, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/Users/saeed/Desktop/codes/repos/dreamscape-qa/env/lib/python3.7/site-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/Users/saeed/Desktop/codes/repos/dreamscape-qa/env/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 343, in cached_path
max_retries=download_config.max_retries,
File "/Users/saeed/Desktop/codes/repos/dreamscape-qa/env/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 617, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.2.1/datasets/race/race.py
```
Or
```
Traceback (most recent call last):
File "src/train.py", line 105, in <module>
rouge = datasets.load_metric("rouge")
File "/Users/saeed/Desktop/codes/repos/dreamscape-qa/env/lib/python3.7/site-packages/datasets/load.py", line 500, in load_metric
dataset=False,
File "/Users/saeed/Desktop/codes/repos/dreamscape-qa/env/lib/python3.7/site-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/Users/saeed/Desktop/codes/repos/dreamscape-qa/env/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 343, in cached_path
max_retries=download_config.max_retries,
File "/Users/saeed/Desktop/codes/repos/dreamscape-qa/env/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 617, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.2.1/metrics/rouge/rouge.py
``` | 1,764 |
https://github.com/huggingface/datasets/issues/1762 | Unable to format dataset to CUDA Tensors | [
"Hi ! You can get CUDA tensors with\r\n\r\n```python\r\ndataset.set_format(\"torch\", columns=columns, device=\"cuda\")\r\n```\r\n\r\nIndeed `set_format` passes the `**kwargs` to `torch.tensor`",
"Hi @lhoestq,\r\n\r\nThanks a lot. Is this true for all format types?\r\n\r\nAs in, for 'torch', I can have `**kwargs` to `torch.tensor` and for 'tf' those args are passed to `tf.Tensor`, and the same for 'numpy' and 'pandas'?",
"Yes the keywords arguments are passed to the convert function like `np.array`, `torch.tensor` or `tensorflow.ragged.constant`.\r\nWe don't support the kwargs for pandas on the other hand.",
"Thanks @lhoestq,\r\nWould it be okay if I added this to the docs and made a PR?",
"Sure ! Feel free to open a PR to improve the documentation :) ",
"Closing this issue as it has been resolved."
] | Hi,
I came across this [link](https://huggingface.co/docs/datasets/torch_tensorflow.html) where the docs show show to convert a dataset to a particular format. I see that there is an option to convert it to tensors, but I don't see any option to convert it to CUDA tensors.
I tried this, but Dataset doesn't support assignment:
```
columns=['input_ids', 'token_type_ids', 'attention_mask', 'start_positions','end_positions']
samples.set_format(type='torch', columns = columns)
for column in columns:
samples[column].to(torch.device(self.config.device))
```
There should be an option to do so, or if there is already a way to do this, please let me know.
Thanks,
Gunjan | 1,762 |
https://github.com/huggingface/datasets/issues/1759 | wikipedia dataset incomplete | [
"Hi !\r\nFrom what pickle file fo you get this ?\r\nI guess you mean the dataset loaded using `load_dataset` ?",
"yes sorry, I used the `load_dataset`function and saved the data to a pickle file so I don't always have to reload it and are able to work offline. ",
"The wikipedia articles are processed using the `mwparserfromhell` library. Even if it works well in most cases, such issues can happen unfortunately. You can find the repo here: https://github.com/earwig/mwparserfromhell\r\n\r\nThere also exist other datasets based on wikipedia that were processed differently (and are often cleaner) such as `wiki40b`.\r\n\r\n",
"ok great. Thank you, @lhoestq. "
] | Hey guys,
I am using the https://github.com/huggingface/datasets/tree/master/datasets/wikipedia dataset.
Unfortunately, I found out that there is an incompleteness for the German dataset.
For reasons unknown to me, the number of inhabitants has been removed from many pages:
Thorey-sur-Ouche has 128 inhabitants according to the webpage (https://de.wikipedia.org/wiki/Thorey-sur-Ouche).
The pickle file however shows: französische Gemeinde mit Einwohnern (Stand).
Is it possible to fix this?
Best regards
Chris
| 1,759 |
https://github.com/huggingface/datasets/issues/1758 | dataset.search() (elastic) cannot reliably retrieve search results | [
"Hi !\r\nI tried your code on my side and I was able to workaround this issue by waiting a few seconds before querying the index.\r\nMaybe this is because the index is not updated yet on the ElasticSearch side ?",
"Thanks for the feedback! I added a 30 second \"sleep\" and that seemed to work well!"
] | I am trying to use elastic search to retrieve the indices of items in the dataset in their precise order, given shuffled training indices.
The problem I have is that I cannot retrieve reliable results with my data on my first search. I have to run the search **twice** to get the right answer.
I am indexing data that looks like the following from the HF SQuAD 2.0 data set:
```
['57318658e6313a140071d02b',
'56f7165e3d8e2e1400e3733a',
'570e2f6e0b85d914000d7d21',
'5727e58aff5b5019007d97d0',
'5a3b5a503ff257001ab8441f',
'57262fab271a42140099d725']
```
To reproduce the issue, try:
```
from datasets import load_dataset, load_metric
from transformers import BertTokenizerFast, BertForQuestionAnswering
from elasticsearch import Elasticsearch
import numpy as np
import collections
from tqdm.auto import tqdm
import torch
# from https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/question_answering.ipynb#scrollTo=941LPhDWeYv-
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')
max_length = 384 # The maximum length of a feature (question and context)
doc_stride = 128 # The authorized overlap between two part of the context when splitting it is needed.
pad_on_right = tokenizer.padding_side == "right"
squad_v2 = True
# from https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/question_answering.ipynb#scrollTo=941LPhDWeYv-
def prepare_validation_features(examples):
# Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
# in one example possible giving several features when a context is long, each of those features having a
# context that overlaps a bit the context of the previous feature.
tokenized_examples = tokenizer(
examples["question" if pad_on_right else "context"],
examples["context" if pad_on_right else "question"],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
# Since one example might give us several features if it has a long context, we need a map from a feature to
# its corresponding example. This key gives us just that.
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# We keep the example_id that gave us this feature and we will store the offset mappings.
tokenized_examples["example_id"] = []
for i in range(len(tokenized_examples["input_ids"])):
# Grab the sequence corresponding to that example (to know what is the context and what is the question).
sequence_ids = tokenized_examples.sequence_ids(i)
context_index = 1 if pad_on_right else 0
# One example can give several spans, this is the index of the example containing this span of text.
sample_index = sample_mapping[i]
tokenized_examples["example_id"].append(examples["id"][sample_index])
# Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
# position is part of the context or not.
tokenized_examples["offset_mapping"][i] = [
(list(o) if sequence_ids[k] == context_index else None)
for k, o in enumerate(tokenized_examples["offset_mapping"][i])
]
return tokenized_examples
# build base examples, features set of training data
shuffled_idx = pd.read_csv('https://raw.githubusercontent.com/afogarty85/temp/main/idx.csv')['idx'].to_list()
examples = load_dataset("squad_v2").shuffle(seed=1)['train']
features = load_dataset("squad_v2").shuffle(seed=1)['train'].map(
prepare_validation_features,
batched=True,
remove_columns=['answers', 'context', 'id', 'question', 'title'])
# reorder features by the training process
features = features.select(indices=shuffled_idx)
# get the example ids to match with the "example" data; get unique entries
id_list = list(dict.fromkeys(features['example_id']))
# now search for their index positions in the examples data set; load elastic search
es = Elasticsearch([{'host': 'localhost'}]).ping()
# add an index to the id column for the examples
examples.add_elasticsearch_index(column='id')
# retrieve the example index
example_idx_k1 = [examples.search(index_name='id', query=i, k=1).indices for i in id_list]
example_idx_k1 = [item for sublist in example_idx_k1 for item in sublist]
example_idx_k2 = [examples.search(index_name='id', query=i, k=3).indices for i in id_list]
example_idx_k2 = [item for sublist in example_idx_k2 for item in sublist]
len(example_idx_k1) # should be 130319
len(example_idx_k2) # should be 130319
#trial 1 lengths:
# k=1: 130314
# k=3: 130319
# trial 2:
# just run k=3 first: 130310
# try k=1 after k=3: 130319
```
| 1,758 |
https://github.com/huggingface/datasets/issues/1757 | FewRel | [
"+1",
"@dspoka Please check the following link : https://github.com/thunlp/FewRel\r\nThis link mentions two versions of the datasets. Also, this one seems to be the official link.\r\n\r\nI am assuming this is the correct link and implementing based on the same.",
"Hi @lhoestq,\r\n\r\nThis issue can be closed, I guess.",
"Yes :) closing\r\nThanks again for adding FewRel !",
"Thanks for adding this @gchhablani ! Sorry didn't see the email notifications sooner!"
] | ## Adding a Dataset
- **Name:** FewRel
- **Description:** Large-Scale Supervised Few-Shot Relation Classification Dataset
- **Paper:** @inproceedings{han2018fewrel,
title={FewRel:A Large-Scale Supervised Few-Shot Relation Classification Dataset with State-of-the-Art Evaluation},
author={Han, Xu and Zhu, Hao and Yu, Pengfei and Wang, Ziyun and Yao, Yuan and Liu, Zhiyuan and Sun, Maosong},
booktitle={EMNLP},
year={2018}}
- **Data:** https://github.com/ProKil/FewRel
- **Motivation:** relationship extraction dataset that's been used by some state of the art systems that should be incorporated.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| 1,757 |
https://github.com/huggingface/datasets/issues/1756 | Ccaligned multilingual translation dataset | [] | ## Adding a Dataset
- **Name:** *name of the dataset*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- CCAligned consists of parallel or comparable web-document pairs in 137 languages aligned with English. These web-document pairs were constructed by performing language identification on raw web-documents, and ensuring corresponding language codes were corresponding in the URLs of web documents. This pattern matching approach yielded more than 100 million aligned documents paired with English. Recognizing that each English document was often aligned to mulitple documents in different target language, we can join on English documents to obtain aligned documents that directly pair two non-English documents (e.g., Arabic-French).
- **Paper:** *link to the dataset paper if available*
- https://www.aclweb.org/anthology/2020.emnlp-main.480.pdf
- **Data:** *link to the Github repository or current dataset location*
- http://www.statmt.org/cc-aligned/
- **Motivation:** *what are some good reasons to have this dataset*
- The authors says it's an high quality dataset.
- it's pretty large and includes many language pairs. It could be interesting training mt5 on this task.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| 1,756 |
https://github.com/huggingface/datasets/issues/1755 | Using select/reordering datasets slows operations down immensely | [
"You can use `Dataset.flatten_indices()` to make it fast after a select or shuffle.",
"Thanks for the input! I gave that a try by adding this after my selection / reordering operations, but before the big computation task of `score_squad`\r\n\r\n```\r\nexamples = examples.flatten_indices()\r\nfeatures = features.flatten_indices()\r\n```\r\n\r\nThat helped quite a bit!"
] | I am using portions of HF's helpful work in preparing / scoring the SQuAD 2.0 data. The problem I have is that after using `select` to re-ordering the dataset, computations slow down immensely where the total scoring process on 131k training examples would take maybe 3 minutes, now take over an hour.
The below example should be reproducible and I have ran myself down this path because I want to use HF's scoring functions and helpful data preparation, but use my own trainer. The training process uses shuffle and therefore the order I trained on no longer matches the original data set order. So, to score my results correctly, the original data set needs to match the order of the training. This requires that I: (1) collect the index for each row of data emitted during training, and (2) use this index information to re-order the datasets correctly so the orders match when I go to score.
The problem is, the dataset class starts performing very poorly as soon as you start manipulating its order by immense magnitudes.
```
from datasets import load_dataset, load_metric
from transformers import BertTokenizerFast, BertForQuestionAnswering
from elasticsearch import Elasticsearch
import numpy as np
import collections
from tqdm.auto import tqdm
import torch
# from https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/question_answering.ipynb#scrollTo=941LPhDWeYv-
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')
max_length = 384 # The maximum length of a feature (question and context)
doc_stride = 128 # The authorized overlap between two part of the context when splitting it is needed.
pad_on_right = tokenizer.padding_side == "right"
squad_v2 = True
# from https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/question_answering.ipynb#scrollTo=941LPhDWeYv-
def prepare_validation_features(examples):
# Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
# in one example possible giving several features when a context is long, each of those features having a
# context that overlaps a bit the context of the previous feature.
tokenized_examples = tokenizer(
examples["question" if pad_on_right else "context"],
examples["context" if pad_on_right else "question"],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
# Since one example might give us several features if it has a long context, we need a map from a feature to
# its corresponding example. This key gives us just that.
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# We keep the example_id that gave us this feature and we will store the offset mappings.
tokenized_examples["example_id"] = []
for i in range(len(tokenized_examples["input_ids"])):
# Grab the sequence corresponding to that example (to know what is the context and what is the question).
sequence_ids = tokenized_examples.sequence_ids(i)
context_index = 1 if pad_on_right else 0
# One example can give several spans, this is the index of the example containing this span of text.
sample_index = sample_mapping[i]
tokenized_examples["example_id"].append(examples["id"][sample_index])
# Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
# position is part of the context or not.
tokenized_examples["offset_mapping"][i] = [
(list(o) if sequence_ids[k] == context_index else None)
for k, o in enumerate(tokenized_examples["offset_mapping"][i])
]
return tokenized_examples
# from https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/question_answering.ipynb#scrollTo=941LPhDWeYv-
def postprocess_qa_predictions(examples, features, starting_logits, ending_logits, n_best_size = 20, max_answer_length = 30):
all_start_logits, all_end_logits = starting_logits, ending_logits
# Build a map example to its corresponding features.
example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
features_per_example = collections.defaultdict(list)
for i, feature in enumerate(features):
features_per_example[example_id_to_index[feature["example_id"]]].append(i)
# The dictionaries we have to fill.
predictions = collections.OrderedDict()
# Logging.
print(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
# Let's loop over all the examples!
for example_index, example in enumerate(tqdm(examples)):
# Those are the indices of the features associated to the current example.
feature_indices = features_per_example[example_index]
min_null_score = None # Only used if squad_v2 is True.
valid_answers = []
context = example["context"]
# Looping through all the features associated to the current example.
for feature_index in feature_indices:
# We grab the predictions of the model for this feature.
start_logits = all_start_logits[feature_index]
end_logits = all_end_logits[feature_index]
# This is what will allow us to map some the positions in our logits to span of texts in the original
# context.
offset_mapping = features[feature_index]["offset_mapping"]
# Update minimum null prediction.
cls_index = features[feature_index]["input_ids"].index(tokenizer.cls_token_id)
feature_null_score = start_logits[cls_index] + end_logits[cls_index]
if min_null_score is None or min_null_score < feature_null_score:
min_null_score = feature_null_score
# Go through all possibilities for the `n_best_size` greater start and end logits.
start_indexes = np.argsort(start_logits)[-1 : -n_best_size - 1 : -1].tolist()
end_indexes = np.argsort(end_logits)[-1 : -n_best_size - 1 : -1].tolist()
for start_index in start_indexes:
for end_index in end_indexes:
# Don't consider out-of-scope answers, either because the indices are out of bounds or correspond
# to part of the input_ids that are not in the context.
if (
start_index >= len(offset_mapping)
or end_index >= len(offset_mapping)
or offset_mapping[start_index] is None
or offset_mapping[end_index] is None
):
continue
# Don't consider answers with a length that is either < 0 or > max_answer_length.
if end_index < start_index or end_index - start_index + 1 > max_answer_length:
continue
start_char = offset_mapping[start_index][0]
end_char = offset_mapping[end_index][1]
valid_answers.append(
{
"score": start_logits[start_index] + end_logits[end_index],
"text": context[start_char: end_char]
}
)
if len(valid_answers) > 0:
best_answer = sorted(valid_answers, key=lambda x: x["score"], reverse=True)[0]
else:
# In the very rare edge case we have not a single non-null prediction, we create a fake prediction to avoid
# failure.
best_answer = {"text": "", "score": 0.0}
# Let's pick our final answer: the best one or the null answer (only for squad_v2)
if not squad_v2:
predictions[example["id"]] = best_answer["text"]
else:
answer = best_answer["text"] if best_answer["score"] > min_null_score else ""
predictions[example["id"]] = answer
return predictions
# build base examples, features from training data
examples = load_dataset("squad_v2").shuffle(seed=5)['train']
features = load_dataset("squad_v2").shuffle(seed=5)['train'].map(
prepare_validation_features,
batched=True,
remove_columns=['answers', 'context', 'id', 'question', 'title'])
# sim some shuffled training indices that we want to use to re-order the data to compare how we did
shuffle_idx = np.arange(0, 131754)
np.random.shuffle(shuffle_idx)
# create a new dataset with rows selected following the training shuffle
features = features.select(indices=shuffle_idx)
# get unique example ids to match with the "example" data
id_list = list(dict.fromkeys(features['example_id']))
# now search for their index positions; load elastic search
es = Elasticsearch([{'host': 'localhost'}]).ping()
# add an index to the id column for the examples
examples.add_elasticsearch_index(column='id')
# search the examples for their index position
example_idx = [examples.search(index_name='id', query=i, k=1).indices for i in id_list]
# drop the elastic search
examples.drop_index(index_name='id')
# put examples in the right order
examples = examples.select(indices=example_idx)
# generate some fake data
logits = {'starting_logits': torch.randn(131754, 384), 'ending_logits': torch.randn(131754, 384)}
def score_squad(logits, n_best_size, max_answer):
# proceed with QA calculation
final_predictions = postprocess_qa_predictions(examples=examples,
features=features,
starting_logits=logits['starting_logits'],
ending_logits=logits['ending_logits'],
n_best_size=20,
max_answer_length=30)
metric = load_metric("squad_v2")
formatted_predictions = [{"id": k, "prediction_text": v, "no_answer_probability": 0.0} for k, v in final_predictions.items()]
references = [{"id": ex["id"], "answers": ex["answers"]} for ex in examples]
metrics = metric.compute(predictions=formatted_predictions, references=references)
return metrics
metrics = score_squad(logits, n_best_size=20, max_answer=30)
```
| 1,755 |
https://github.com/huggingface/datasets/issues/1747 | datasets slicing with seed | [
"Hi :) \r\nThe slicing API from https://huggingface.co/docs/datasets/splits.html doesn't shuffle the data.\r\nYou can shuffle and then take a subset of your dataset with\r\n```python\r\n# shuffle and take the first 100 examples\r\ndataset = dataset.shuffle(seed=42).select(range(100))\r\n```\r\n\r\nYou can find more information about shuffling and selecting rows in the documentation: https://huggingface.co/docs/datasets/processing.html#selecting-sorting-shuffling-splitting-rows",
"thank you so much\n\nOn Mon, Jan 18, 2021 at 3:17 PM Quentin Lhoest <[email protected]>\nwrote:\n\n> Hi :)\n> The slicing API doesn't shuffle the data.\n> You can shuffle and then take a subset of your dataset with\n>\n> # shuffle and take the first 100 examplesdataset = dataset.shuffle(seed=42).select(range(100))\n>\n> You can find more information about shuffling and selecting rows in the\n> documentation:\n> https://huggingface.co/docs/datasets/processing.html#selecting-sorting-shuffling-splitting-rows\n>\n> —\n> You are receiving this because you authored the thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/1747#issuecomment-762278134>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AM3GZM5D5MDPLJGI4IG3UADS2Q7GPANCNFSM4WHLOZJQ>\n> .\n>\n"
] | Hi
I need to slice a dataset with random seed, I looked into documentation here https://huggingface.co/docs/datasets/splits.html
I could not find a seed option, could you assist me please how I can get a slice for different seeds?
thank you.
@lhoestq | 1,747 |
https://github.com/huggingface/datasets/issues/1745 | difference between wsc and wsc.fixed for superglue | [
"From the description given in the dataset script for `wsc.fixed`:\r\n```\r\nThis version fixes issues where the spans are not actually substrings of the text.\r\n```"
] | Hi
I see two versions of wsc in superglue, and I am not sure what is the differences and which one is the original one. could you help to discuss the differences? thanks @lhoestq | 1,745 |
https://github.com/huggingface/datasets/issues/1743 | Issue while Creating Custom Metric | [
"Currently it's only possible to define the features for the two columns `references` and `predictions`.\r\nThe data for these columns can then be passed to `metric.add_batch` and `metric.compute`.\r\nInstead of defining more columns `text`, `offset_mapping` and `ground` you must include them in either references and predictions.\r\n\r\nFor example \r\n```python\r\nfeatures = datasets.Features({\r\n 'predictions':datasets.Sequence(datasets.Value(\"int32\")),\r\n \"references\": datasets.Sequence({\r\n \"references_ids\": datasets.Value(\"int32\"),\r\n \"offset_mapping\": datasets.Value(\"int32\"),\r\n 'text': datasets.Value('string'),\r\n \"ground\": datasets.Value(\"int32\")\r\n }),\r\n})\r\n```\r\n\r\nAnother option would be to simply have the two features like \r\n```python\r\nfeatures = datasets.Features({\r\n 'predictions':datasets.Sequence(datasets.Value(\"int32\")),\r\n \"references\": datasets.Sequence(datasets.Value(\"int32\")),\r\n})\r\n```\r\nand keep `offset_mapping`, `text` and `ground` as as parameters for the computation (i.e. kwargs when calling `metric.compute`).\r\n\r\n\r\nWhat is the metric you would like to implement ?\r\n\r\nI'm asking since we consider allowing additional fields as requested in the `Comet` metric (see PR and discussion [here](https://github.com/huggingface/datasets/pull/1577)) and I'd like to know if it's something that can be interesting for users.\r\n\r\nWhat do you think ?",
"Hi @lhoestq,\r\n\r\nI am doing text segmentation and the metric is effectively dice score on character offsets. So I need to pass the actual spans and I want to be able to get the spans based on predictions using offset_mapping.\r\n\r\nIncluding them in references seems like a good idea. I'll try it out and get back to you. If there's a better way to write a metric function for the same, please let me know.",
"Resolved via https://github.com/huggingface/datasets/pull/3824."
] | Hi Team,
I am trying to create a custom metric for my training as follows, where f1 is my own metric:
```python
def _info(self):
# TODO: Specifies the datasets.MetricInfo object
return datasets.MetricInfo(
# This is the description that will appear on the metrics page.
description=_DESCRIPTION,
citation=_CITATION,
inputs_description=_KWARGS_DESCRIPTION,
# This defines the format of each prediction and reference
features = datasets.Features({'predictions':datasets.Sequence(datasets.Value("int32")), "references": datasets.Sequence(datasets.Value("int32")),"offset_mapping":datasets.Sequence(datasets.Value("int32")),'text':datasets.Sequence(datasets.Value('string')),"ground":datasets.Sequence(datasets.Value("int32")),}),
# Homepage of the metric for documentation
homepage="http://metric.homepage",
# Additional links to the codebase or references
codebase_urls=["http://github.com/path/to/codebase/of/new_metric"],
reference_urls=["http://path.to.reference.url/new_metric"]
)
def _compute(self,predictions,references,text,offset_mapping,spans):
pred_spans = []
for i,preds in enumerate(predictions):
current_preds = []
for j,token_preds in enumerate(preds):
if (preds>0.5):
current_preds+=list(range(offset_mapping[i][j][0],offset_mapping[i][j][1]))
pred_spans.append(current_spans)
return {
"Token Wise F1": f1_score(references,predictions,labels=[0,1]),
"Offset Wise F1": np.mean([f1(preds,gold) for preds,fold in zip(pred_spans,ground)])
}
```
I believe this is not correct. But that's not the issue I am facing right now. I get this error :
```python
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-144-ed7349b50821> in <module>()
----> 1 new_metric.compute(predictions=inputs["labels"],references=inputs["labels"], text=inputs["text"], offset_mapping=inputs["offset_mapping"],ground=inputs["ground"] )
2 frames
/usr/local/lib/python3.6/dist-packages/datasets/features.py in encode_batch(self, batch)
802 encoded_batch = {}
803 if set(batch) != set(self):
--> 804 print(batch)
805 print(self)
806 raise ValueError("Column mismatch between batch {} and features {}".format(set(batch), set(self)))
ValueError: Column mismatch between batch {'references', 'predictions'} and features {'ground', 'predictions', 'offset_mapping', 'text', 'references'}
```
On checking the features.py file, I see the call is made from add_batch() in metrics.py which only takes in predictions and references.
How do I make my custom metric work? Will it work with a trainer even if I am able to make this metric work?
Thanks,
Gunjan | 1,743 |
https://github.com/huggingface/datasets/issues/1741 | error when run fine_tuning on text_classification | [
"none"
] | dataset:sem_eval_2014_task_1
pretrained_model:bert-base-uncased
error description:
when i use these resoruce to train fine_tuning a text_classification on sem_eval_2014_task_1,there always be some problem(when i use other dataset ,there exist the error too). And i followed the colab code (url:https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/text_classification.ipynb#scrollTo=TlqNaB8jIrJW).
the error is like this :
`File "train.py", line 69, in <module>
trainer.train()
File "/home/projects/anaconda3/envs/calibration/lib/python3.7/site-packages/transformers/trainer.py", line 784, in train
for step, inputs in enumerate(epoch_iterator):
File "/home/projects/anaconda3/envs/calibration/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 435, in __next__
data = self._next_data()
File "/home/projects/anaconda3/envs/calibration/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 475, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/home/projects/anaconda3/envs/calibration/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/projects/anaconda3/envs/calibration/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
KeyError: 2`
this is my code :
```dataset_name = 'sem_eval_2014_task_1'
num_labels_size = 3
batch_size = 4
model_checkpoint = 'bert-base-uncased'
number_train_epoch = 5
def tokenize(batch):
return tokenizer(batch['premise'], batch['hypothesis'], truncation=True, )
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='micro')
acc = accuracy_score(labels, preds)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}
model = BertForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels_size)
tokenizer = BertTokenizerFast.from_pretrained(model_checkpoint, use_fast=True)
train_dataset = load_dataset(dataset_name, split='train')
test_dataset = load_dataset(dataset_name, split='test')
train_encoded_dataset = train_dataset.map(tokenize, batched=True)
test_encoded_dataset = test_dataset.map(tokenize, batched=True)
args = TrainingArguments(
output_dir='./results',
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=number_train_epoch,
weight_decay=0.01,
do_predict=True,
)
trainer = Trainer(
model=model,
args=args,
compute_metrics=compute_metrics,
train_dataset=train_encoded_dataset,
eval_dataset=test_encoded_dataset,
tokenizer=tokenizer
)
trainer.train()
trainer.evaluate()
| 1,741 |
https://github.com/huggingface/datasets/issues/1733 | connection issue with glue, what is the data url for glue? | [
"Hello @juliahane, which config of GLUE causes you trouble?\r\nThe URLs are defined in the dataset script source code: https://github.com/huggingface/datasets/blob/master/datasets/glue/glue.py"
] | Hi
my codes sometimes fails due to connection issue with glue, could you tell me how I can have the URL datasets library is trying to read GLUE from to test the machines I am working on if there is an issue on my side or not
thanks | 1,733 |
https://github.com/huggingface/datasets/issues/1731 | Couldn't reach swda.py | [
"Hi @yangp725,\r\nThe SWDA has been added very recently and has not been released yet, thus it is not available in the `1.2.0` version of 🤗`datasets`.\r\nYou can still access it by installing the latest version of the library (master branch), by following instructions in [this issue](https://github.com/huggingface/datasets/issues/1641#issuecomment-751571471).\r\nLet me know if this helps !",
"Thanks @SBrandeis ,\r\nProblem solved by downloading and installing the latest version datasets."
] | ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.2.0/datasets/swda/swda.py
| 1,731 |
https://github.com/huggingface/datasets/issues/1729 | Is there support for Deep learning datasets? | [
"Hi @ZurMaD!\r\nThanks for your interest in 🤗 `datasets`. Support for image datasets is at an early stage, with CIFAR-10 added in #1617 \r\nMNIST is also on the way: #1730 \r\n\r\nIf you feel like adding another image dataset, I would advise starting by reading the [ADD_NEW_DATASET.md](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md) guide. New datasets are always very much appreciated 🚀\r\n"
] | I looked around this repository and looking the datasets I think that there's no support for images-datasets. Or am I missing something? For example to add a repo like this https://github.com/DZPeru/fish-datasets | 1,729 |
https://github.com/huggingface/datasets/issues/1728 | Add an entry to an arrow dataset | [
"Hi @ameet-1997,\r\nI think what you are looking for is the `concatenate_datasets` function: https://huggingface.co/docs/datasets/processing.html?highlight=concatenate#concatenate-several-datasets\r\n\r\nFor your use case, I would use the [`map` method](https://huggingface.co/docs/datasets/processing.html?highlight=concatenate#processing-data-with-map) to transform the SQuAD sentences and the `concatenate` the original and mapped dataset.\r\n\r\nLet me know If this helps!",
"That's a great idea! Thank you so much!\r\n\r\nWhen I try that solution, I get the following error when I try to concatenate `datasets` and `modified_dataset`. I have also attached the output I get when I print out those two variables. Am I missing something?\r\n\r\nCode:\r\n``` python\r\ncombined_dataset = concatenate_datasets([datasets, modified_dataset])\r\n```\r\n\r\nError:\r\n```\r\nAttributeError: 'DatasetDict' object has no attribute 'features'\r\n```\r\n\r\nOutput:\r\n```\r\n(Pdb) datasets\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['attention_mask', 'input_ids', 'special_tokens_mask'],\r\n num_rows: 493\r\n })\r\n})\r\n(Pdb) modified_dataset\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['attention_mask', 'input_ids', 'special_tokens_mask'],\r\n num_rows: 493\r\n })\r\n})\r\n```\r\n\r\nThe error is stemming from the fact that the attribute `datasets.features` does not exist. Would it not be possible to use `concatenate_datasets` in such a case? Is there an alternate solution?",
"You should do `combined_dataset = concatenate_datasets([datasets['train'], modified_dataset['train']])`\r\n\r\nDidn't we talk about returning a Dataset instead of a DatasetDict with load_dataset and no split provided @lhoestq? Not sure it's the way to go but I'm wondering if it's not simpler for some use-cases.",
"> Didn't we talk about returning a Dataset instead of a DatasetDict with load_dataset and no split provided @lhoestq? Not sure it's the way to go but I'm wondering if it's not simpler for some use-cases.\r\n\r\nMy opinion is that users should always know in advance what type of objects they're going to get. Otherwise the development workflow on their side is going to be pretty chaotic with sometimes unexpected behaviors.\r\nFor instance is `split=` is not specified it's currently always returning a DatasetDict. And if `split=\"train\"` is given for example it's always returning a Dataset.",
"Thanks @thomwolf. Your solution worked!"
] | Is it possible to add an entry to a dataset object?
**Motivation: I want to transform the sentences in the dataset and add them to the original dataset**
For example, say we have the following code:
``` python
from datasets import load_dataset
# Load a dataset and print the first examples in the training set
squad_dataset = load_dataset('squad')
print(squad_dataset['train'][0])
```
Is it possible to add an entry to `squad_dataset`? Something like the following?
``` python
squad_dataset.append({'text': "This is a new sentence"})
```
The motivation for doing this is that I want to transform the sentences in the squad dataset and add them to the original dataset.
If the above doesn't work, is there any other way of achieving the motivation mentioned above? Perhaps by creating a new arrow dataset by using the older one and the transformer sentences?
| 1,728 |
https://github.com/huggingface/datasets/issues/1727 | BLEURT score calculation raises UnrecognizedFlagError | [
"Upgrading tensorflow to version 2.4.0 solved the issue.",
"I still have the same error even with TF 2.4.0.",
"And I have the same error with TF 2.4.1. I believe this issue should be reopened. Any ideas?!",
"I'm seeing the same issue with TF 2.4.1 when running the following in https://colab.research.google.com/github/huggingface/datasets/blob/master/notebooks/Overview.ipynb:\r\n```\r\n!pip install git+https://github.com/google-research/bleurt.git\r\nreferences = [\"foo bar baz\", \"one two three\"]\r\nbleurt_metric = load_metric('bleurt')\r\npredictions = [\"foo bar\", \"four five six\"]\r\nbleurt_metric.compute(predictions=predictions, references=references)\r\n```",
"@aleSuglia @oscartackstrom - Are you getting the error when running your code in a Jupyter notebook ?\r\n\r\nI tried reproducing this error again, and was unable to do so from the python command line console in a virtual environment similar to the one I originally used (and unfortunately no longer have access to) when I first got the error. \r\nHowever, I've managed to reproduce the error by running the same code in a Jupyter notebook running a kernel from the same virtual environment.\r\nThis made me suspect that the problem is somehow related to the Jupyter notebook.\r\n\r\nMore environment details:\r\n```\r\nOS: Ubuntu Linux 18.04\r\nconda==4.8.3\r\npython==3.8.5\r\ndatasets==1.3.0\r\ntensorflow==2.4.0\r\nBLEURT==0.0.1\r\nnotebook==6.2.0\r\n```",
"This happens when running the notebook on colab. The issue seems to be that colab populates sys.argv with arguments not handled by bleurt.\r\n\r\nRunning this before calling bleurt fixes it:\r\n```\r\nimport sys\r\nsys.argv = sys.argv[:1]\r\n```\r\n\r\nNot the most elegant solution. Perhaps it needs to be fixed in the bleurt code itself rather than huggingface?\r\n\r\nThis is the output of `print(sys.argv)` when running on colab:\r\n```\r\n['/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py', '-f', '/root/.local/share/jupyter/runtime/kernel-a857a78c-44d6-4b9d-b18a-030b858ee327.json']\r\n```",
"I got the error when running it from the command line. It looks more like an error that should be fixed in the BLEURT codebase.",
"Seems to be a known issue in the bleurt codebase: https://github.com/google-research/bleurt/issues/24.",
"Hi, the problem should be solved now.",
"Hi @tsellam! I can verify that the issue is indeed fixed now. Thanks!"
] | Calling the `compute` method for **bleurt** metric fails with an `UnrecognizedFlagError` for `FLAGS.bleurt_batch_size`.
My environment:
```
python==3.8.5
datasets==1.2.0
tensorflow==2.3.1
cudatoolkit==11.0.221
```
Test code for reproducing the error:
```
from datasets import load_metric
bleurt = load_metric('bleurt')
gen_text = "I am walking on the promenade today"
ref_text = "I am walking along the promenade on this sunny day"
bleurt.compute(predictions=[test_text], references=[test_text])
```
Error Output:
```
Using default BLEURT-Base checkpoint for sequence maximum length 128. You can use a bigger model for better results with e.g.: datasets.load_metric('bleurt', 'bleurt-large-512').
INFO:tensorflow:Reading checkpoint /home/ubuntu/.cache/huggingface/metrics/bleurt/default/downloads/extracted/9aee35580225730ac5422599f35c4986e4c49cafd08082123342b1019720dac4/bleurt-base-128.
INFO:tensorflow:Config file found, reading.
INFO:tensorflow:Will load checkpoint bert_custom
INFO:tensorflow:Performs basic checks...
INFO:tensorflow:... name:bert_custom
INFO:tensorflow:... vocab_file:vocab.txt
INFO:tensorflow:... bert_config_file:bert_config.json
INFO:tensorflow:... do_lower_case:True
INFO:tensorflow:... max_seq_length:128
INFO:tensorflow:Creating BLEURT scorer.
INFO:tensorflow:Loading model...
INFO:tensorflow:BLEURT initialized.
---------------------------------------------------------------------------
UnrecognizedFlagError Traceback (most recent call last)
<ipython-input-12-8b3f4322318a> in <module>
2 gen_text = "I am walking on the promenade today"
3 ref_text = "I am walking along the promenade on this sunny day"
----> 4 bleurt.compute(predictions=[gen_text], references=[ref_text])
~/anaconda3/envs/noved/lib/python3.8/site-packages/datasets/metric.py in compute(self, *args, **kwargs)
396 references = self.data["references"]
397 with temp_seed(self.seed):
--> 398 output = self._compute(predictions=predictions, references=references, **kwargs)
399
400 if self.buf_writer is not None:
~/.cache/huggingface/modules/datasets_modules/metrics/bleurt/b1de33e1cbbcb1dbe276c887efa1fad68c6aff913885108078fa1ad408908778/bleurt.py in _compute(self, predictions, references)
103
104 def _compute(self, predictions, references):
--> 105 scores = self.scorer.score(references=references, candidates=predictions)
106 return {"scores": scores}
~/anaconda3/envs/noved/lib/python3.8/site-packages/bleurt/score.py in score(self, references, candidates, batch_size)
164 """
165 if not batch_size:
--> 166 batch_size = FLAGS.bleurt_batch_size
167
168 candidates, references = list(candidates), list(references)
~/anaconda3/envs/noved/lib/python3.8/site-packages/tensorflow/python/platform/flags.py in __getattr__(self, name)
83 # a flag.
84 if not wrapped.is_parsed():
---> 85 wrapped(_sys.argv)
86 return wrapped.__getattr__(name)
87
~/anaconda3/envs/noved/lib/python3.8/site-packages/absl/flags/_flagvalues.py in __call__(self, argv, known_only)
643 for name, value in unknown_flags:
644 suggestions = _helpers.get_flag_suggestions(name, list(self))
--> 645 raise _exceptions.UnrecognizedFlagError(
646 name, value, suggestions=suggestions)
647
UnrecognizedFlagError: Unknown command line flag 'f'
```
Possible Fix:
Modify `_compute` method https://github.com/huggingface/datasets/blob/7e64851a12263dc74d41c668167918484c8000ab/metrics/bleurt/bleurt.py#L104
to receive a `batch_size` argument, for example:
```
def _compute(self, predictions, references, batch_size=1):
scores = self.scorer.score(references=references, candidates=predictions, batch_size=batch_size)
return {"scores": scores}
``` | 1,727 |
https://github.com/huggingface/datasets/issues/1725 | load the local dataset | [
"You should rephrase your question or give more examples and details on what you want to do.\r\n\r\nit’s not possible to understand it and help you with only this information.",
"sorry for that.\r\ni want to know how could i load the train set and the test set from the local ,which api or function should i use .\r\n",
"Did you try to follow the instructions in the documentation?\r\nHere: https://huggingface.co/docs/datasets/loading_datasets.html#from-local-files",
"thanks a lot \r\ni find that the problem is i dont use vpn...\r\nso i have to keep my net work even if i want to load the local data ?",
"We will solve this soon (cf #1724)",
"thanks a lot",
"Hi! `json` is a packaged dataset now, which means its script comes with the library and doesn't require an internet connection."
] | your guidebook's example is like
>>>from datasets import load_dataset
>>> dataset = load_dataset('json', data_files='my_file.json')
but the first arg is path...
so how should i do if i want to load the local dataset for model training?
i will be grateful if you can help me handle this problem!
thanks a lot! | 1,725 |
https://github.com/huggingface/datasets/issues/1724 | could not run models on a offline server successfully | [
"Transferred to `datasets` based on the stack trace.",
"Hi @lkcao !\r\nYour issue is indeed related to `datasets`. In addition to installing the package manually, you will need to download the `text.py` script on your server. You'll find it (under `datasets/datasets/text`: https://github.com/huggingface/datasets/blob/master/datasets/text/text.py.\r\nThen you can change the line 221 of `run_mlm_new.py` into:\r\n```python\r\n datasets = load_dataset('/path/to/text.py', data_files=data_files)\r\n```\r\nWhere `/path/to/text.py` is the path on the server where you saved the `text.py` script.",
"We're working on including the local dataset builders (csv, text, json etc.) directly in the `datasets` package so that they can be used offline",
"The local dataset builders (csv, text , json and pandas) are now part of the `datasets` package since #1726 :)\r\nYou can now use them offline\r\n```python\r\ndatasets = load_dataset('text', data_files=data_files)\r\n```\r\n\r\nWe'll do a new release soon",
"> The local dataset builders (csv, text , json and pandas) are now part of the `datasets` package since #1726 :)\r\n> You can now use them offline\r\n> \r\n> ```python\r\n> datasets = load_dataset('text', data_files=data_files)\r\n> ```\r\n> \r\n> We'll do a new release soon\r\n\r\nso the new version release now?",
"Yes it's been available since datasets 1.3.0 !"
] | Hi, I really need your help about this.
I am trying to fine-tuning a RoBERTa on a remote server, which is strictly banning internet. I try to install all the packages by hand and try to run run_mlm.py on the server. It works well on colab, but when I try to run it on this offline server, it shows:

is there anything I can do? Is it possible to download all the things in cache and upload it to the server? Please help me out... | 1,724 |
https://github.com/huggingface/datasets/issues/1718 | Possible cache miss in datasets | [
"Thanks for reporting !\r\nI was able to reproduce thanks to your code and find the origin of the bug.\r\nThe cache was not reusing the same file because one object was not deterministic. It comes from a conversion from `set` to `list` in the `datasets.arrrow_dataset.transmit_format` function, where the resulting list would not always be in the same order and therefore the function that computes the hash used by the cache would not always return the same result.\r\nI'm opening a PR to fix this.\r\n\r\nAlso we plan to do a new release in the coming days so you can expect the fix to be available soon.\r\nNote that you can still specify `cache_file_name=` in the second `map()` call to name the cache file yourself if you want to.",
"Thanks for the fast reply, waiting for the fix :)\r\n\r\nI tried to use `cache_file_names` and wasn't sure how, I tried to give it the following:\r\n```\r\ntokenized_datasets = tokenized_datasets.map(\r\n group_texts,\r\n batched=True,\r\n num_proc=60,\r\n load_from_cache_file=True,\r\n cache_file_names={k: f'.cache/{str(k)}' for k in tokenized_datasets}\r\n)\r\n```\r\n\r\nand got an error:\r\n```\r\nmultiprocess.pool.RemoteTraceback:\r\n\"\"\"\r\nTraceback (most recent call last):\r\n File \"/venv/lib/python3.6/site-packages/multiprocess/pool.py\", line 119, in worker\r\n result = (True, func(*args, **kwds))\r\n File \"/venv/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 157, in wrapper\r\n out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n File \"/venv/lib/python3.6/site-packages/datasets/fingerprint.py\", line 163, in wrapper\r\n out = func(self, *args, **kwargs)\r\n File \"/venv/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1491, in _map_single\r\n tmp_file = tempfile.NamedTemporaryFile(\"wb\", dir=os.path.dirname(cache_file_name), delete=False)\r\n File \"/usr/lib/python3.6/tempfile.py\", line 690, in NamedTemporaryFile\r\n (fd, name) = _mkstemp_inner(dir, prefix, suffix, flags, output_type)\r\n File \"/usr/lib/python3.6/tempfile.py\", line 401, in _mkstemp_inner\r\n fd = _os.open(file, flags, 0o600)\r\nFileNotFoundError: [Errno 2] No such file or directory: '_00000_of_00060.cache/tmpsvszxtop'\r\n\"\"\"\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n File \"test.py\", line 48, in <module>\r\n cache_file_names={k: f'.cache/{str(k)}' for k in tokenized_datasets}\r\n File \"/venv/lib/python3.6/site-packages/datasets/dataset_dict.py\", line 303, in map\r\n for k, dataset in self.items()\r\n File \"/venv/lib/python3.6/site-packages/datasets/dataset_dict.py\", line 303, in <dictcomp>\r\n for k, dataset in self.items()\r\n File \"/venv/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1317, in map\r\n transformed_shards = [r.get() for r in results]\r\n File \"/venv/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1317, in <listcomp>\r\n transformed_shards = [r.get() for r in results]\r\n File \"/venv/lib/python3.6/site-packages/multiprocess/pool.py\", line 644, in get\r\n raise self._value\r\nFileNotFoundError: [Errno 2] No such file or directory: '_00000_of_00060.cache/tmpsvszxtop'\r\n```\r\n",
"The documentation says\r\n```\r\ncache_file_names (`Optional[Dict[str, str]]`, defaults to `None`): Provide the name of a cache file to use to store the\r\n results of the computation instead of the automatically generated cache file name.\r\n You have to provide one :obj:`cache_file_name` per dataset in the dataset dictionary.\r\n```\r\nWhat is expected is simply the name of a file, not a path. The file will be located in the cache directory of the `wikitext` dataset. You can try again with something like\r\n```python\r\ncache_file_names = {k: f'tokenized_and_grouped_{str(k)}' for k in tokenized_datasets}\r\n```",
"Managed to get `cache_file_names` working and caching works well with it\r\nHad to make a small modification for it to work:\r\n```\r\ncache_file_names = {k: f'tokenized_and_grouped_{str(k)}.arrow' for k in tokenized_datasets}\r\n```",
"Another comment on `cache_file_names`, it doesn't save the produced cached files in the dataset's cache folder, it requires to give a path to an existing directory for it to work.\r\nI can confirm that this is how it works in `datasets==1.1.3`",
"Oh yes indeed ! Maybe we need to update the docstring to mention that it is a path",
"I fixed the docstring. Hopefully this is less confusing now: https://github.com/huggingface/datasets/commit/42ccc0012ba8864e6db1392430100f350236183a",
"I upgraded to the latest version and I encountered some strange behaviour, the script I posted in the OP doesn't trigger recalculation, however, if I add the following change it does trigger partial recalculation, I am not sure if its something wrong on my machine or a bug:\r\n```\r\nfrom datasets import load_dataset\r\nfrom transformers import AutoTokenizer\r\n\r\ndatasets = load_dataset('wikitext', 'wikitext-103-raw-v1')\r\ntokenizer = AutoTokenizer.from_pretrained('bert-base-uncased', use_fast=True)\r\n\r\ncolumn_names = datasets[\"train\"].column_names\r\ntext_column_name = \"text\" if \"text\" in column_names else column_names[0]\r\ndef tokenize_function(examples):\r\n return tokenizer(examples[text_column_name], return_special_tokens_mask=True)\r\n# CHANGE\r\nprint('hello')\r\n# CHANGE\r\n\r\ntokenized_datasets = datasets.map(\r\n tokenize_function,\r\n batched=True,\r\n...\r\n```\r\nI am using datasets in the `run_mlm.py` script in the transformers examples and I found that if I change the script without touching any of the preprocessing. it still triggers recalculation which is very weird\r\n\r\nEdit: accidently clicked the close issue button ",
"This is because the `group_texts` line definition changes (it is defined 3 lines later than in the previous call). Currently if a function is moved elsewhere in a script we consider it to be different.\r\n\r\nNot sure this is actually a good idea to keep this behavior though. We had this as a security in the early development of the lib but now the recursive hashing of objects is robust so we can probably remove that.\r\nMoreover we're already ignoring the line definition for lambda functions.",
"I opened a PR to change this, let me know what you think.",
"Sounds great, thank you for your quick responses and help! Looking forward for the next release.",
"I am having a similar issue where only the grouped files are loaded from cache while the tokenized ones aren't. I can confirm both datasets are being stored to file, but only the grouped version is loaded from cache. Not sure what might be going on. But I've tried to remove all kinds of non deterministic behaviour, but still no luck. Thanks for the help!\r\n\r\n\r\n```python\r\n # Datasets\r\n train = sorted(glob(args.data_dir + '*.{}'.format(args.ext)))\r\n if args.dev_split >= len(train):\r\n raise ValueError(\"Not enough dev files\")\r\n dev = []\r\n state = random.Random(1001)\r\n for _ in range(args.dev_split):\r\n dev.append(train.pop(state.randint(0, len(train) - 1)))\r\n\r\n max_seq_length = min(args.max_seq_length, tokenizer.model_max_length)\r\n\r\n def tokenize_function(examples):\r\n return tokenizer(examples['text'], return_special_tokens_mask=True)\r\n\r\n def group_texts(examples):\r\n # Concatenate all texts from our dataset and generate chunks of max_seq_length\r\n concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}\r\n total_length = len(concatenated_examples[list(examples.keys())[0]])\r\n # Truncate (not implementing padding)\r\n total_length = (total_length // max_seq_length) * max_seq_length\r\n # Split by chunks of max_seq_length\r\n result = {\r\n k: [t[i : i + max_seq_length] for i in range(0, total_length, max_seq_length)]\r\n for k, t in concatenated_examples.items()\r\n }\r\n return result\r\n\r\n datasets = load_dataset(\r\n 'text', name='DBNL', data_files={'train': train[:10], 'dev': dev[:5]}, \r\n cache_dir=args.data_cache_dir)\r\n datasets = datasets.map(tokenize_function, \r\n batched=True, remove_columns=['text'], \r\n cache_file_names={k: os.path.join(args.data_cache_dir, f'{k}-tokenized') for k in datasets},\r\n load_from_cache_file=not args.overwrite_cache)\r\n datasets = datasets.map(group_texts, \r\n batched=True,\r\n cache_file_names={k: os.path.join(args.data_cache_dir, f'{k}-grouped') for k in datasets},\r\n load_from_cache_file=not args.overwrite_cache)\r\n```\r\n\r\nAnd this is the log\r\n\r\n```\r\n04/26/2021 10:26:59 - WARNING - datasets.builder - Using custom data configuration DBNL-f8d988ad33ccf2c1\r\n04/26/2021 10:26:59 - WARNING - datasets.builder - Reusing dataset text (/home/manjavacasema/data/.cache/text/DBNL-f8d988ad33ccf2c1/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5)\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:00<00:00, 21.07ba/s]\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 40/40 [00:01<00:00, 24.28ba/s]\r\n04/26/2021 10:27:01 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at /home/manjavacasema/data/.cache/train-grouped\r\n04/26/2021 10:27:01 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at /home/manjavacasema/data/.cache/dev-grouped\r\n```\r\n",
"Hi ! What tokenizer are you using ?",
"It's the ByteLevelBPETokenizer",
"This error happened to me too, when I tried to supply my own fingerprint to `map()` via the `new_fingerprint` arg.\r\n\r\nEdit: realized it was because my path was weird and had colons and brackets and slashes in it, since one of the variable values I included in the fingerprint was a dataset split like \"train[:10%]\". I fixed it with [this solution](https://stackoverflow.com/a/13593932/2287177) from StackOverflow to just remove those invalid characters from the fingerprint.",
"Good catch @jxmorris12, maybe we should do additional checks on the valid characters for fingerprints ! Would you like to contribute this ?\r\n\r\nI think this can be added here, when we set the fingerprint(s) that are passed `map`:\r\n\r\nhttps://github.com/huggingface/datasets/blob/25bb7c9cbf519fbbf9abf3898083b529e7762705/src/datasets/fingerprint.py#L449-L454\r\n\r\nmaybe something like\r\n```python\r\nif kwargs.get(fingerprint_name) is None:\r\n ...\r\nelse:\r\n # In this case, it's the user who specified the fingerprint manually:\r\n # we need to make sure it's a valid hash\r\n validate_fingerprint(kwargs[fingerprint_name])\r\n```\r\n\r\nOtherwise I can open a PR later",
"I opened a PR here to add the fingerprint validation: https://github.com/huggingface/datasets/pull/4587\r\n\r\nEDIT: merged :)",
"thank you!"
] | Hi,
I am using the datasets package and even though I run the same data processing functions, datasets always recomputes the function instead of using cache.
I have attached an example script that for me reproduces the problem.
In the attached example the second map function always recomputes instead of loading from cache.
Is this a bug or am I doing something wrong?
Is there a way for fix this and avoid all the recomputation?
Thanks
Edit:
transformers==3.5.1
datasets==1.2.0
```
from datasets import load_dataset
from transformers import AutoTokenizer
datasets = load_dataset('wikitext', 'wikitext-103-raw-v1')
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased', use_fast=True)
column_names = datasets["train"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
def tokenize_function(examples):
return tokenizer(examples[text_column_name], return_special_tokens_mask=True)
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
num_proc=60,
remove_columns=[text_column_name],
load_from_cache_file=True,
)
max_seq_length = tokenizer.model_max_length
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {
k: sum(examples[k], []) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs.
total_length = (total_length // max_seq_length) * max_seq_length
# Split by chunks of max_len.
result = {
k: [t[i: i + max_seq_length]
for i in range(0, total_length, max_seq_length)]
for k, t in concatenated_examples.items()
}
return result
tokenized_datasets = tokenized_datasets.map(
group_texts,
batched=True,
num_proc=60,
load_from_cache_file=True,
)
print(tokenized_datasets)
print('finished')
``` | 1,718 |
https://github.com/huggingface/datasets/issues/1717 | SciFact dataset - minor changes | [
"Hi Dave,\r\nYou are more than welcome to open a PR to make these changes! 🤗\r\nYou will find the relevant information about opening a PR in the [contributing guide](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md) and in the [dataset addition guide](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).\r\n\r\nPinging also @lhoestq for the Google cloud matter.",
"> I'd like to make a few minor changes, including the citation information and the `_URL` from which to download the dataset. Can I submit a PR for this?\r\n\r\nSure ! Also feel free to ping us for reviews or if we can help :)\r\n\r\n> It also looks like the dataset is being downloaded directly from Huggingface's Google cloud account rather than via the `_URL` in [scifact.py](https://github.com/huggingface/datasets/blob/master/datasets/scifact/scifact.py). Can you help me update the version on gcloud?\r\n\r\nWhat makes you think that ?\r\nAfaik there's no scifact on our google storage\r\n",
"\r\n\r\n> > I'd like to make a few minor changes, including the citation information and the `_URL` from which to download the dataset. Can I submit a PR for this?\r\n> \r\n> Sure ! Also feel free to ping us for reviews or if we can help :)\r\n> \r\nOK! We're organizing a [shared task](https://sdproc.org/2021/sharedtasks.html#sciver) based on the dataset, and I made some updates and changed the download URL - so the current code points to a dead URL. I'll update appropriately once the task is finalized and make a PR.\r\n\r\n> > It also looks like the dataset is being downloaded directly from Huggingface's Google cloud account rather than via the `_URL` in [scifact.py](https://github.com/huggingface/datasets/blob/master/datasets/scifact/scifact.py). Can you help me update the version on gcloud?\r\n> \r\n> What makes you think that ?\r\n> Afaik there's no scifact on our google storage\r\n\r\nYou're right, I had the data cached on my machine somewhere. \r\n\r\n",
"I opened a PR about this: https://github.com/huggingface/datasets/pull/1780. Closing this issue, will continue there."
] | Hi,
SciFact dataset creator here. First of all, thanks for adding the dataset to Huggingface, much appreciated!
I'd like to make a few minor changes, including the citation information and the `_URL` from which to download the dataset. Can I submit a PR for this?
It also looks like the dataset is being downloaded directly from Huggingface's Google cloud account rather than via the `_URL` in [scifact.py](https://github.com/huggingface/datasets/blob/master/datasets/scifact/scifact.py). Can you help me update the version on gcloud?
Thanks,
Dave | 1,717 |
https://github.com/huggingface/datasets/issues/1713 | Installation using conda | [
"Yes indeed the idea is to have the next release on conda cc @LysandreJik ",
"Great! Did you guys have a timeframe in mind for the next release?\r\n\r\nThank you for all the great work in developing this library.",
"I think we can have `datasets` on conda by next week. Will see what I can do!",
"Thank you. Looking forward to it.",
"`datasets` has been added to the huggingface channel thanks to @LysandreJik :)\r\nIt depends on conda-forge though\r\n\r\n```\r\nconda install -c huggingface -c conda-forge datasets\r\n```"
] | Will a conda package for installing datasets be added to the huggingface conda channel? I have installed transformers using conda and would like to use the datasets library to use some of the scripts in the transformers/examples folder but am unable to do so at the moment as datasets can only be installed using pip and using pip in a conda environment is generally a bad idea in my experience. | 1,713 |
https://github.com/huggingface/datasets/issues/1710 | IsADirectoryError when trying to download C4 | [
"I haven't tested C4 on my side so there so there may be a few bugs in the code/adjustments to make.\r\nHere it looks like in c4.py, line 190 one of the `files_to_download` is `'/'` which is invalid.\r\nValid files are paths to local files or URLs to remote files.",
"Fixed once processed data is used instead:\r\n- #2575"
] | **TLDR**:
I fail to download C4 and see a stacktrace originating in `IsADirectoryError` as an explanation for failure.
How can the problem be fixed?
**VERBOSE**:
I use Python version 3.7 and have the following dependencies listed in my project:
```
datasets==1.2.0
apache-beam==2.26.0
```
When running the following code, where `/data/huggingface/unpacked/` contains a single unzipped `wet.paths` file manually downloaded as per the instructions for C4:
```
from datasets import load_dataset
load_dataset("c4", "en", data_dir="/data/huggingface/unpacked", beam_runner='DirectRunner')
```
I get the following stacktrace:
```
/Users/fredriko/venv/misc/bin/python /Users/fredriko/source/misc/main.py
Downloading and preparing dataset c4/en (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /Users/fredriko/.cache/huggingface/datasets/c4/en/2.3.0/8304cf264cc42bdebcb13fca4b9cb36368a96f557d36f9dc969bebbe2568b283...
Traceback (most recent call last):
File "/Users/fredriko/source/misc/main.py", line 3, in <module>
load_dataset("c4", "en", data_dir="/data/huggingface/unpacked", beam_runner='DirectRunner')
File "/Users/fredriko/venv/misc/lib/python3.7/site-packages/datasets/load.py", line 612, in load_dataset
ignore_verifications=ignore_verifications,
File "/Users/fredriko/venv/misc/lib/python3.7/site-packages/datasets/builder.py", line 527, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/Users/fredriko/venv/misc/lib/python3.7/site-packages/datasets/builder.py", line 1066, in _download_and_prepare
pipeline=pipeline,
File "/Users/fredriko/venv/misc/lib/python3.7/site-packages/datasets/builder.py", line 582, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/Users/fredriko/.cache/huggingface/modules/datasets_modules/datasets/c4/8304cf264cc42bdebcb13fca4b9cb36368a96f557d36f9dc969bebbe2568b283/c4.py", line 190, in _split_generators
file_paths = dl_manager.download_and_extract(files_to_download)
File "/Users/fredriko/venv/misc/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 258, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/Users/fredriko/venv/misc/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 189, in download
self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)
File "/Users/fredriko/venv/misc/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 117, in _record_sizes_checksums
self._recorded_sizes_checksums[str(url)] = get_size_checksum_dict(path)
File "/Users/fredriko/venv/misc/lib/python3.7/site-packages/datasets/utils/info_utils.py", line 80, in get_size_checksum_dict
with open(path, "rb") as f:
IsADirectoryError: [Errno 21] Is a directory: '/'
Process finished with exit code 1
``` | 1,710 |
https://github.com/huggingface/datasets/issues/1709 | Databases | [] | ## Adding a Dataset
- **Name:** *name of the dataset*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** *what are some good reasons to have this dataset*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md). | 1,709 |
https://github.com/huggingface/datasets/issues/1708 | <html dir="ltr" lang="en" class="focus-outline-visible"><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> | [] | ## Adding a Dataset
- **Name:** *name of the dataset*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** *what are some good reasons to have this dataset*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md). | 1,708 |
https://github.com/huggingface/datasets/issues/1706 | Error when downloading a large dataset on slow connection. | [
"Hi ! Is this an issue you have with `openwebtext` specifically or also with other datasets ?\r\n\r\nIt looks like the downloaded file is corrupted and can't be extracted using `tarfile`.\r\nCould you try loading it again with \r\n```python\r\nimport datasets\r\ndatasets.load_dataset(\"openwebtext\", download_mode=\"force_redownload\")\r\n```"
] | I receive the following error after about an hour trying to download the `openwebtext` dataset.
The code used is:
```python
import datasets
datasets.load_dataset("openwebtext")
```
> Traceback (most recent call last): [4/28]
> File "<stdin>", line 1, in <module>
> File "/home/lucadiliello/anaconda3/envs/nlp/lib/python3.7/site-packages/datasets/load.py", line 610, in load_dataset
> ignore_verifications=ignore_verifications,
> File "/home/lucadiliello/anaconda3/envs/nlp/lib/python3.7/site-packages/datasets/builder.py", line 515, in download_and_prepare
> dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
> File "/home/lucadiliello/anaconda3/envs/nlp/lib/python3.7/site-packages/datasets/builder.py", line 570, in _download_and_prepare
> split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
> File "/home/lucadiliello/.cache/huggingface/modules/datasets_modules/datasets/openwebtext/5c636399c7155da97c982d0d70ecdce30fbca66a4eb4fc768ad91f8331edac02/openwebtext.py", line 62, in _split_generators
> dl_dir = dl_manager.download_and_extract(_URL)
> File "/home/lucadiliello/anaconda3/envs/nlp/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 254, in download_and_extract
> return self.extract(self.download(url_or_urls))
> File "/home/lucadiliello/anaconda3/envs/nlp/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 235, in extract
> num_proc=num_proc,
> File "/home/lucadiliello/anaconda3/envs/nlp/lib/python3.7/site-packages/datasets/utils/py_utils.py", line 225, in map_nested
> return function(data_struct)
> File "/home/lucadiliello/anaconda3/envs/nlp/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 343, in cached_path
> tar_file.extractall(output_path_extracted)
> File "/home/lucadiliello/anaconda3/envs/nlp/lib/python3.7/tarfile.py", line 2000, in extractall
> numeric_owner=numeric_owner)
> File "/home/lucadiliello/anaconda3/envs/nlp/lib/python3.7/tarfile.py", line 2042, in extract
> numeric_owner=numeric_owner)
> File "/home/lucadiliello/anaconda3/envs/nlp/lib/python3.7/tarfile.py", line 2112, in _extract_member
> self.makefile(tarinfo, targetpath)
> File "/home/lucadiliello/anaconda3/envs/nlp/lib/python3.7/tarfile.py", line 2161, in makefile
> copyfileobj(source, target, tarinfo.size, ReadError, bufsize)
> File "/home/lucadiliello/anaconda3/envs/nlp/lib/python3.7/tarfile.py", line 253, in copyfileobj
> buf = src.read(remainder)
> File "/home/lucadiliello/anaconda3/envs/nlp/lib/python3.7/lzma.py", line 200, in read
> return self._buffer.read(size)
> File "/home/lucadiliello/anaconda3/envs/nlp/lib/python3.7/_compression.py", line 68, in readinto
> data = self.read(len(byte_view))
> File "/home/lucadiliello/anaconda3/envs/nlp/lib/python3.7/_compression.py", line 99, in read
> raise EOFError("Compressed file ended before the "
> EOFError: Compressed file ended before the end-of-stream marker was reached
| 1,706 |
https://github.com/huggingface/datasets/issues/1701 | Some datasets miss dataset_infos.json or dummy_data.zip | [
"Thanks for reporting.\r\nWe should indeed add all the missing dummy_data.zip and also the dataset_infos.json at least for lm1b, reclor and wikihow.\r\n\r\nFor c4 I haven't tested the script and I think we'll require some optimizations regarding beam datasets before processing it.\r\n",
"Closing since the dummy data generation is deprecated now (and the issue with missing metadata seems to be addressed)."
] | While working on dataset REAME generation script at https://github.com/madlag/datasets_readme_generator , I noticed that some datasets miss a dataset_infos.json :
```
c4
lm1b
reclor
wikihow
```
And some does not have a dummy_data.zip :
```
kor_nli
math_dataset
mlqa
ms_marco
newsgroup
qa4mre
qangaroo
reddit_tifu
super_glue
trivia_qa
web_of_science
wmt14
wmt15
wmt16
wmt17
wmt18
wmt19
xtreme
```
But it seems that some of those last do have a "dummy" directory .
| 1,701 |
https://github.com/huggingface/datasets/issues/1696 | Unable to install datasets | [
"Maybe try to create a virtual env with python 3.8 or 3.7",
"Thanks, @thomwolf! I fixed the issue by downgrading python to 3.7. ",
"Damn sorry",
"Damn sorry"
] | ** Edit **
I believe there's a bug with the package when you're installing it with Python 3.9. I recommend sticking with previous versions. Thanks, @thomwolf for the insight!
**Short description**
I followed the instructions for installing datasets (https://huggingface.co/docs/datasets/installation.html). However, while I tried to download datasets using `pip install datasets` I got a massive error message after getting stuck at "Installing build dependencies..."
I was wondering if this problem can be fixed by creating a virtual environment, but it didn't help. Can anyone offer some advice on how to fix this issue?
Here's an error message:
`(env) Gas-MacBook-Pro:Downloads destiny$ pip install datasets
Collecting datasets
Using cached datasets-1.2.0-py3-none-any.whl (159 kB)
Collecting numpy>=1.17
Using cached numpy-1.19.5-cp39-cp39-macosx_10_9_x86_64.whl (15.6 MB)
Collecting pyarrow>=0.17.1
Using cached pyarrow-2.0.0.tar.gz (58.9 MB)
....
_configtest.c:9:5: warning: incompatible redeclaration of library function 'ceilf' [-Wincompatible-library-redeclaration]
int ceilf (void);
^
_configtest.c:9:5: note: 'ceilf' is a builtin with type 'float (float)'
_configtest.c:10:5: warning: incompatible redeclaration of library function 'rintf' [-Wincompatible-library-redeclaration]
int rintf (void);
^
_configtest.c:10:5: note: 'rintf' is a builtin with type 'float (float)'
_configtest.c:11:5: warning: incompatible redeclaration of library function 'truncf' [-Wincompatible-library-redeclaration]
int truncf (void);
^
_configtest.c:11:5: note: 'truncf' is a builtin with type 'float (float)'
_configtest.c:12:5: warning: incompatible redeclaration of library function 'sqrtf' [-Wincompatible-library-redeclaration]
int sqrtf (void);
^
_configtest.c:12:5: note: 'sqrtf' is a builtin with type 'float (float)'
_configtest.c:13:5: warning: incompatible redeclaration of library function 'log10f' [-Wincompatible-library-redeclaration]
int log10f (void);
^
_configtest.c:13:5: note: 'log10f' is a builtin with type 'float (float)'
_configtest.c:14:5: warning: incompatible redeclaration of library function 'logf' [-Wincompatible-library-redeclaration]
int logf (void);
^
_configtest.c:14:5: note: 'logf' is a builtin with type 'float (float)'
_configtest.c:15:5: warning: incompatible redeclaration of library function 'log1pf' [-Wincompatible-library-redeclaration]
int log1pf (void);
^
_configtest.c:15:5: note: 'log1pf' is a builtin with type 'float (float)'
_configtest.c:16:5: warning: incompatible redeclaration of library function 'expf' [-Wincompatible-library-redeclaration]
int expf (void);
^
_configtest.c:16:5: note: 'expf' is a builtin with type 'float (float)'
_configtest.c:17:5: warning: incompatible redeclaration of library function 'expm1f' [-Wincompatible-library-redeclaration]
int expm1f (void);
^
_configtest.c:17:5: note: 'expm1f' is a builtin with type 'float (float)'
_configtest.c:18:5: warning: incompatible redeclaration of library function 'asinf' [-Wincompatible-library-redeclaration]
int asinf (void);
^
_configtest.c:18:5: note: 'asinf' is a builtin with type 'float (float)'
_configtest.c:19:5: warning: incompatible redeclaration of library function 'acosf' [-Wincompatible-library-redeclaration]
int acosf (void);
^
_configtest.c:19:5: note: 'acosf' is a builtin with type 'float (float)'
_configtest.c:20:5: warning: incompatible redeclaration of library function 'atanf' [-Wincompatible-library-redeclaration]
int atanf (void);
^
_configtest.c:20:5: note: 'atanf' is a builtin with type 'float (float)'
_configtest.c:21:5: warning: incompatible redeclaration of library function 'asinhf' [-Wincompatible-library-redeclaration]
int asinhf (void);
^
_configtest.c:21:5: note: 'asinhf' is a builtin with type 'float (float)'
_configtest.c:22:5: warning: incompatible redeclaration of library function 'acoshf' [-Wincompatible-library-redeclaration]
int acoshf (void);
^
_configtest.c:22:5: note: 'acoshf' is a builtin with type 'float (float)'
_configtest.c:23:5: warning: incompatible redeclaration of library function 'atanhf' [-Wincompatible-library-redeclaration]
int atanhf (void);
^
_configtest.c:23:5: note: 'atanhf' is a builtin with type 'float (float)'
_configtest.c:24:5: warning: incompatible redeclaration of library function 'hypotf' [-Wincompatible-library-redeclaration]
int hypotf (void);
^
_configtest.c:24:5: note: 'hypotf' is a builtin with type 'float (float, float)'
_configtest.c:25:5: warning: incompatible redeclaration of library function 'atan2f' [-Wincompatible-library-redeclaration]
int atan2f (void);
^
_configtest.c:25:5: note: 'atan2f' is a builtin with type 'float (float, float)'
_configtest.c:26:5: warning: incompatible redeclaration of library function 'powf' [-Wincompatible-library-redeclaration]
int powf (void);
^
_configtest.c:26:5: note: 'powf' is a builtin with type 'float (float, float)'
_configtest.c:27:5: warning: incompatible redeclaration of library function 'fmodf' [-Wincompatible-library-redeclaration]
int fmodf (void);
^
_configtest.c:27:5: note: 'fmodf' is a builtin with type 'float (float, float)'
_configtest.c:28:5: warning: incompatible redeclaration of library function 'modff' [-Wincompatible-library-redeclaration]
int modff (void);
^
_configtest.c:28:5: note: 'modff' is a builtin with type 'float (float, float *)'
_configtest.c:29:5: warning: incompatible redeclaration of library function 'frexpf' [-Wincompatible-library-redeclaration]
int frexpf (void);
^
_configtest.c:29:5: note: 'frexpf' is a builtin with type 'float (float, int *)'
_configtest.c:30:5: warning: incompatible redeclaration of library function 'ldexpf' [-Wincompatible-library-redeclaration]
int ldexpf (void);
^
_configtest.c:30:5: note: 'ldexpf' is a builtin with type 'float (float, int)'
_configtest.c:31:5: warning: incompatible redeclaration of library function 'exp2f' [-Wincompatible-library-redeclaration]
int exp2f (void);
^
_configtest.c:31:5: note: 'exp2f' is a builtin with type 'float (float)'
_configtest.c:32:5: warning: incompatible redeclaration of library function 'log2f' [-Wincompatible-library-redeclaration]
int log2f (void);
^
_configtest.c:32:5: note: 'log2f' is a builtin with type 'float (float)'
_configtest.c:33:5: warning: incompatible redeclaration of library function 'copysignf' [-Wincompatible-library-redeclaration]
int copysignf (void);
^
_configtest.c:33:5: note: 'copysignf' is a builtin with type 'float (float, float)'
_configtest.c:34:5: warning: incompatible redeclaration of library function 'nextafterf' [-Wincompatible-library-redeclaration]
int nextafterf (void);
^
_configtest.c:34:5: note: 'nextafterf' is a builtin with type 'float (float, float)'
_configtest.c:35:5: warning: incompatible redeclaration of library function 'cbrtf' [-Wincompatible-library-redeclaration]
int cbrtf (void);
^
_configtest.c:35:5: note: 'cbrtf' is a builtin with type 'float (float)'
35 warnings generated.
clang _configtest.o -o _configtest
success!
removing: _configtest.c _configtest.o _configtest.o.d _configtest
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
_configtest.c:1:5: warning: incompatible redeclaration of library function 'sinl' [-Wincompatible-library-redeclaration]
int sinl (void);
^
_configtest.c:1:5: note: 'sinl' is a builtin with type 'long double (long double)'
_configtest.c:2:5: warning: incompatible redeclaration of library function 'cosl' [-Wincompatible-library-redeclaration]
int cosl (void);
^
_configtest.c:2:5: note: 'cosl' is a builtin with type 'long double (long double)'
_configtest.c:3:5: warning: incompatible redeclaration of library function 'tanl' [-Wincompatible-library-redeclaration]
int tanl (void);
^
_configtest.c:3:5: note: 'tanl' is a builtin with type 'long double (long double)'
_configtest.c:4:5: warning: incompatible redeclaration of library function 'sinhl' [-Wincompatible-library-redeclaration]
int sinhl (void);
^
_configtest.c:4:5: note: 'sinhl' is a builtin with type 'long double (long double)'
_configtest.c:5:5: warning: incompatible redeclaration of library function 'coshl' [-Wincompatible-library-redeclaration]
int coshl (void);
^
_configtest.c:5:5: note: 'coshl' is a builtin with type 'long double (long double)'
_configtest.c:6:5: warning: incompatible redeclaration of library function 'tanhl' [-Wincompatible-library-redeclaration]
int tanhl (void);
^
_configtest.c:6:5: note: 'tanhl' is a builtin with type 'long double (long double)'
_configtest.c:7:5: warning: incompatible redeclaration of library function 'fabsl' [-Wincompatible-library-redeclaration]
int fabsl (void);
^
_configtest.c:7:5: note: 'fabsl' is a builtin with type 'long double (long double)'
_configtest.c:8:5: warning: incompatible redeclaration of library function 'floorl' [-Wincompatible-library-redeclaration]
int floorl (void);
^
_configtest.c:8:5: note: 'floorl' is a builtin with type 'long double (long double)'
_configtest.c:9:5: warning: incompatible redeclaration of library function 'ceill' [-Wincompatible-library-redeclaration]
int ceill (void);
^
_configtest.c:9:5: note: 'ceill' is a builtin with type 'long double (long double)'
_configtest.c:10:5: warning: incompatible redeclaration of library function 'rintl' [-Wincompatible-library-redeclaration]
int rintl (void);
^
_configtest.c:10:5: note: 'rintl' is a builtin with type 'long double (long double)'
_configtest.c:11:5: warning: incompatible redeclaration of library function 'truncl' [-Wincompatible-library-redeclaration]
int truncl (void);
^
_configtest.c:11:5: note: 'truncl' is a builtin with type 'long double (long double)'
_configtest.c:12:5: warning: incompatible redeclaration of library function 'sqrtl' [-Wincompatible-library-redeclaration]
int sqrtl (void);
^
_configtest.c:12:5: note: 'sqrtl' is a builtin with type 'long double (long double)'
_configtest.c:13:5: warning: incompatible redeclaration of library function 'log10l' [-Wincompatible-library-redeclaration]
int log10l (void);
^
_configtest.c:13:5: note: 'log10l' is a builtin with type 'long double (long double)'
_configtest.c:14:5: warning: incompatible redeclaration of library function 'logl' [-Wincompatible-library-redeclaration]
int logl (void);
^
_configtest.c:14:5: note: 'logl' is a builtin with type 'long double (long double)'
_configtest.c:15:5: warning: incompatible redeclaration of library function 'log1pl' [-Wincompatible-library-redeclaration]
int log1pl (void);
^
_configtest.c:15:5: note: 'log1pl' is a builtin with type 'long double (long double)'
_configtest.c:16:5: warning: incompatible redeclaration of library function 'expl' [-Wincompatible-library-redeclaration]
int expl (void);
^
_configtest.c:16:5: note: 'expl' is a builtin with type 'long double (long double)'
_configtest.c:17:5: warning: incompatible redeclaration of library function 'expm1l' [-Wincompatible-library-redeclaration]
int expm1l (void);
^
_configtest.c:17:5: note: 'expm1l' is a builtin with type 'long double (long double)'
_configtest.c:18:5: warning: incompatible redeclaration of library function 'asinl' [-Wincompatible-library-redeclaration]
int asinl (void);
^
_configtest.c:18:5: note: 'asinl' is a builtin with type 'long double (long double)'
_configtest.c:19:5: warning: incompatible redeclaration of library function 'acosl' [-Wincompatible-library-redeclaration]
int acosl (void);
^
_configtest.c:19:5: note: 'acosl' is a builtin with type 'long double (long double)'
_configtest.c:20:5: warning: incompatible redeclaration of library function 'atanl' [-Wincompatible-library-redeclaration]
int atanl (void);
^
_configtest.c:20:5: note: 'atanl' is a builtin with type 'long double (long double)'
_configtest.c:21:5: warning: incompatible redeclaration of library function 'asinhl' [-Wincompatible-library-redeclaration]
int asinhl (void);
^
_configtest.c:21:5: note: 'asinhl' is a builtin with type 'long double (long double)'
_configtest.c:22:5: warning: incompatible redeclaration of library function 'acoshl' [-Wincompatible-library-redeclaration]
int acoshl (void);
^
_configtest.c:22:5: note: 'acoshl' is a builtin with type 'long double (long double)'
_configtest.c:23:5: warning: incompatible redeclaration of library function 'atanhl' [-Wincompatible-library-redeclaration]
int atanhl (void);
^
_configtest.c:23:5: note: 'atanhl' is a builtin with type 'long double (long double)'
_configtest.c:24:5: warning: incompatible redeclaration of library function 'hypotl' [-Wincompatible-library-redeclaration]
int hypotl (void);
^
_configtest.c:24:5: note: 'hypotl' is a builtin with type 'long double (long double, long double)'
_configtest.c:25:5: warning: incompatible redeclaration of library function 'atan2l' [-Wincompatible-library-redeclaration]
int atan2l (void);
^
_configtest.c:25:5: note: 'atan2l' is a builtin with type 'long double (long double, long double)'
_configtest.c:26:5: warning: incompatible redeclaration of library function 'powl' [-Wincompatible-library-redeclaration]
int powl (void);
^
_configtest.c:26:5: note: 'powl' is a builtin with type 'long double (long double, long double)'
_configtest.c:27:5: warning: incompatible redeclaration of library function 'fmodl' [-Wincompatible-library-redeclaration]
int fmodl (void);
^
_configtest.c:27:5: note: 'fmodl' is a builtin with type 'long double (long double, long double)'
_configtest.c:28:5: warning: incompatible redeclaration of library function 'modfl' [-Wincompatible-library-redeclaration]
int modfl (void);
^
_configtest.c:28:5: note: 'modfl' is a builtin with type 'long double (long double, long double *)'
_configtest.c:29:5: warning: incompatible redeclaration of library function 'frexpl' [-Wincompatible-library-redeclaration]
int frexpl (void);
^
_configtest.c:29:5: note: 'frexpl' is a builtin with type 'long double (long double, int *)'
_configtest.c:30:5: warning: incompatible redeclaration of library function 'ldexpl' [-Wincompatible-library-redeclaration]
int ldexpl (void);
^
_configtest.c:30:5: note: 'ldexpl' is a builtin with type 'long double (long double, int)'
_configtest.c:31:5: warning: incompatible redeclaration of library function 'exp2l' [-Wincompatible-library-redeclaration]
int exp2l (void);
^
_configtest.c:31:5: note: 'exp2l' is a builtin with type 'long double (long double)'
_configtest.c:32:5: warning: incompatible redeclaration of library function 'log2l' [-Wincompatible-library-redeclaration]
int log2l (void);
^
_configtest.c:32:5: note: 'log2l' is a builtin with type 'long double (long double)'
_configtest.c:33:5: warning: incompatible redeclaration of library function 'copysignl' [-Wincompatible-library-redeclaration]
int copysignl (void);
^
_configtest.c:33:5: note: 'copysignl' is a builtin with type 'long double (long double, long double)'
_configtest.c:34:5: warning: incompatible redeclaration of library function 'nextafterl' [-Wincompatible-library-redeclaration]
int nextafterl (void);
^
_configtest.c:34:5: note: 'nextafterl' is a builtin with type 'long double (long double, long double)'
_configtest.c:35:5: warning: incompatible redeclaration of library function 'cbrtl' [-Wincompatible-library-redeclaration]
int cbrtl (void);
^
_configtest.c:35:5: note: 'cbrtl' is a builtin with type 'long double (long double)'
35 warnings generated.
clang _configtest.o -o _configtest
success!
removing: _configtest.c _configtest.o _configtest.o.d _configtest
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
success!
removing: _configtest.c _configtest.o _configtest.o.d
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
success!
removing: _configtest.c _configtest.o _configtest.o.d
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
success!
removing: _configtest.c _configtest.o _configtest.o.d
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
success!
removing: _configtest.c _configtest.o _configtest.o.d
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
_configtest.c:8:12: error: use of undeclared identifier 'HAVE_DECL_SIGNBIT'
(void) HAVE_DECL_SIGNBIT;
^
1 error generated.
failure.
removing: _configtest.c _configtest.o
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
success!
removing: _configtest.c _configtest.o _configtest.o.d
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
success!
removing: _configtest.c _configtest.o _configtest.o.d
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
success!
removing: _configtest.c _configtest.o _configtest.o.d
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
success!
removing: _configtest.c _configtest.o _configtest.o.d
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
removing: _configtest.c _configtest.o _configtest.o.d
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
removing: _configtest.c _configtest.o _configtest.o.d
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
removing: _configtest.c _configtest.o _configtest.o.d
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
_configtest.c:1:5: warning: incompatible redeclaration of library function 'cabs' [-Wincompatible-library-redeclaration]
int cabs (void);
^
_configtest.c:1:5: note: 'cabs' is a builtin with type 'double (_Complex double)'
_configtest.c:2:5: warning: incompatible redeclaration of library function 'cacos' [-Wincompatible-library-redeclaration]
int cacos (void);
^
_configtest.c:2:5: note: 'cacos' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:3:5: warning: incompatible redeclaration of library function 'cacosh' [-Wincompatible-library-redeclaration]
int cacosh (void);
^
_configtest.c:3:5: note: 'cacosh' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:4:5: warning: incompatible redeclaration of library function 'carg' [-Wincompatible-library-redeclaration]
int carg (void);
^
_configtest.c:4:5: note: 'carg' is a builtin with type 'double (_Complex double)'
_configtest.c:5:5: warning: incompatible redeclaration of library function 'casin' [-Wincompatible-library-redeclaration]
int casin (void);
^
_configtest.c:5:5: note: 'casin' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:6:5: warning: incompatible redeclaration of library function 'casinh' [-Wincompatible-library-redeclaration]
int casinh (void);
^
_configtest.c:6:5: note: 'casinh' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:7:5: warning: incompatible redeclaration of library function 'catan' [-Wincompatible-library-redeclaration]
int catan (void);
^
_configtest.c:7:5: note: 'catan' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:8:5: warning: incompatible redeclaration of library function 'catanh' [-Wincompatible-library-redeclaration]
int catanh (void);
^
_configtest.c:8:5: note: 'catanh' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:9:5: warning: incompatible redeclaration of library function 'ccos' [-Wincompatible-library-redeclaration]
int ccos (void);
^
_configtest.c:9:5: note: 'ccos' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:10:5: warning: incompatible redeclaration of library function 'ccosh' [-Wincompatible-library-redeclaration]
int ccosh (void);
^
_configtest.c:10:5: note: 'ccosh' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:11:5: warning: incompatible redeclaration of library function 'cexp' [-Wincompatible-library-redeclaration]
int cexp (void);
^
_configtest.c:11:5: note: 'cexp' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:12:5: warning: incompatible redeclaration of library function 'cimag' [-Wincompatible-library-redeclaration]
int cimag (void);
^
_configtest.c:12:5: note: 'cimag' is a builtin with type 'double (_Complex double)'
_configtest.c:13:5: warning: incompatible redeclaration of library function 'clog' [-Wincompatible-library-redeclaration]
int clog (void);
^
_configtest.c:13:5: note: 'clog' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:14:5: warning: incompatible redeclaration of library function 'conj' [-Wincompatible-library-redeclaration]
int conj (void);
^
_configtest.c:14:5: note: 'conj' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:15:5: warning: incompatible redeclaration of library function 'cpow' [-Wincompatible-library-redeclaration]
int cpow (void);
^
_configtest.c:15:5: note: 'cpow' is a builtin with type '_Complex double (_Complex double, _Complex double)'
_configtest.c:16:5: warning: incompatible redeclaration of library function 'cproj' [-Wincompatible-library-redeclaration]
int cproj (void);
^
_configtest.c:16:5: note: 'cproj' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:17:5: warning: incompatible redeclaration of library function 'creal' [-Wincompatible-library-redeclaration]
int creal (void);
^
_configtest.c:17:5: note: 'creal' is a builtin with type 'double (_Complex double)'
_configtest.c:18:5: warning: incompatible redeclaration of library function 'csin' [-Wincompatible-library-redeclaration]
int csin (void);
^
_configtest.c:18:5: note: 'csin' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:19:5: warning: incompatible redeclaration of library function 'csinh' [-Wincompatible-library-redeclaration]
int csinh (void);
^
_configtest.c:19:5: note: 'csinh' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:20:5: warning: incompatible redeclaration of library function 'csqrt' [-Wincompatible-library-redeclaration]
int csqrt (void);
^
_configtest.c:20:5: note: 'csqrt' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:21:5: warning: incompatible redeclaration of library function 'ctan' [-Wincompatible-library-redeclaration]
int ctan (void);
^
_configtest.c:21:5: note: 'ctan' is a builtin with type '_Complex double (_Complex double)'
_configtest.c:22:5: warning: incompatible redeclaration of library function 'ctanh' [-Wincompatible-library-redeclaration]
int ctanh (void);
^
_configtest.c:22:5: note: 'ctanh' is a builtin with type '_Complex double (_Complex double)'
22 warnings generated.
clang _configtest.o -o _configtest
success!
removing: _configtest.c _configtest.o _configtest.o.d _configtest
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
_configtest.c:1:5: warning: incompatible redeclaration of library function 'cabsf' [-Wincompatible-library-redeclaration]
int cabsf (void);
^
_configtest.c:1:5: note: 'cabsf' is a builtin with type 'float (_Complex float)'
_configtest.c:2:5: warning: incompatible redeclaration of library function 'cacosf' [-Wincompatible-library-redeclaration]
int cacosf (void);
^
_configtest.c:2:5: note: 'cacosf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:3:5: warning: incompatible redeclaration of library function 'cacoshf' [-Wincompatible-library-redeclaration]
int cacoshf (void);
^
_configtest.c:3:5: note: 'cacoshf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:4:5: warning: incompatible redeclaration of library function 'cargf' [-Wincompatible-library-redeclaration]
int cargf (void);
^
_configtest.c:4:5: note: 'cargf' is a builtin with type 'float (_Complex float)'
_configtest.c:5:5: warning: incompatible redeclaration of library function 'casinf' [-Wincompatible-library-redeclaration]
int casinf (void);
^
_configtest.c:5:5: note: 'casinf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:6:5: warning: incompatible redeclaration of library function 'casinhf' [-Wincompatible-library-redeclaration]
int casinhf (void);
^
_configtest.c:6:5: note: 'casinhf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:7:5: warning: incompatible redeclaration of library function 'catanf' [-Wincompatible-library-redeclaration]
int catanf (void);
^
_configtest.c:7:5: note: 'catanf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:8:5: warning: incompatible redeclaration of library function 'catanhf' [-Wincompatible-library-redeclaration]
int catanhf (void);
^
_configtest.c:8:5: note: 'catanhf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:9:5: warning: incompatible redeclaration of library function 'ccosf' [-Wincompatible-library-redeclaration]
int ccosf (void);
^
_configtest.c:9:5: note: 'ccosf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:10:5: warning: incompatible redeclaration of library function 'ccoshf' [-Wincompatible-library-redeclaration]
int ccoshf (void);
^
_configtest.c:10:5: note: 'ccoshf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:11:5: warning: incompatible redeclaration of library function 'cexpf' [-Wincompatible-library-redeclaration]
int cexpf (void);
^
_configtest.c:11:5: note: 'cexpf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:12:5: warning: incompatible redeclaration of library function 'cimagf' [-Wincompatible-library-redeclaration]
int cimagf (void);
^
_configtest.c:12:5: note: 'cimagf' is a builtin with type 'float (_Complex float)'
_configtest.c:13:5: warning: incompatible redeclaration of library function 'clogf' [-Wincompatible-library-redeclaration]
int clogf (void);
^
_configtest.c:13:5: note: 'clogf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:14:5: warning: incompatible redeclaration of library function 'conjf' [-Wincompatible-library-redeclaration]
int conjf (void);
^
_configtest.c:14:5: note: 'conjf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:15:5: warning: incompatible redeclaration of library function 'cpowf' [-Wincompatible-library-redeclaration]
int cpowf (void);
^
_configtest.c:15:5: note: 'cpowf' is a builtin with type '_Complex float (_Complex float, _Complex float)'
_configtest.c:16:5: warning: incompatible redeclaration of library function 'cprojf' [-Wincompatible-library-redeclaration]
int cprojf (void);
^
_configtest.c:16:5: note: 'cprojf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:17:5: warning: incompatible redeclaration of library function 'crealf' [-Wincompatible-library-redeclaration]
int crealf (void);
^
_configtest.c:17:5: note: 'crealf' is a builtin with type 'float (_Complex float)'
_configtest.c:18:5: warning: incompatible redeclaration of library function 'csinf' [-Wincompatible-library-redeclaration]
int csinf (void);
^
_configtest.c:18:5: note: 'csinf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:19:5: warning: incompatible redeclaration of library function 'csinhf' [-Wincompatible-library-redeclaration]
int csinhf (void);
^
_configtest.c:19:5: note: 'csinhf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:20:5: warning: incompatible redeclaration of library function 'csqrtf' [-Wincompatible-library-redeclaration]
int csqrtf (void);
^
_configtest.c:20:5: note: 'csqrtf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:21:5: warning: incompatible redeclaration of library function 'ctanf' [-Wincompatible-library-redeclaration]
int ctanf (void);
^
_configtest.c:21:5: note: 'ctanf' is a builtin with type '_Complex float (_Complex float)'
_configtest.c:22:5: warning: incompatible redeclaration of library function 'ctanhf' [-Wincompatible-library-redeclaration]
int ctanhf (void);
^
_configtest.c:22:5: note: 'ctanhf' is a builtin with type '_Complex float (_Complex float)'
22 warnings generated.
clang _configtest.o -o _configtest
success!
removing: _configtest.c _configtest.o _configtest.o.d _configtest
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
_configtest.c:1:5: warning: incompatible redeclaration of library function 'cabsl' [-Wincompatible-library-redeclaration]
int cabsl (void);
^
_configtest.c:1:5: note: 'cabsl' is a builtin with type 'long double (_Complex long double)'
_configtest.c:2:5: warning: incompatible redeclaration of library function 'cacosl' [-Wincompatible-library-redeclaration]
int cacosl (void);
^
_configtest.c:2:5: note: 'cacosl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:3:5: warning: incompatible redeclaration of library function 'cacoshl' [-Wincompatible-library-redeclaration]
int cacoshl (void);
^
_configtest.c:3:5: note: 'cacoshl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:4:5: warning: incompatible redeclaration of library function 'cargl' [-Wincompatible-library-redeclaration]
int cargl (void);
^
_configtest.c:4:5: note: 'cargl' is a builtin with type 'long double (_Complex long double)'
_configtest.c:5:5: warning: incompatible redeclaration of library function 'casinl' [-Wincompatible-library-redeclaration]
int casinl (void);
^
_configtest.c:5:5: note: 'casinl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:6:5: warning: incompatible redeclaration of library function 'casinhl' [-Wincompatible-library-redeclaration]
int casinhl (void);
^
_configtest.c:6:5: note: 'casinhl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:7:5: warning: incompatible redeclaration of library function 'catanl' [-Wincompatible-library-redeclaration]
int catanl (void);
^
_configtest.c:7:5: note: 'catanl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:8:5: warning: incompatible redeclaration of library function 'catanhl' [-Wincompatible-library-redeclaration]
int catanhl (void);
^
_configtest.c:8:5: note: 'catanhl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:9:5: warning: incompatible redeclaration of library function 'ccosl' [-Wincompatible-library-redeclaration]
int ccosl (void);
^
_configtest.c:9:5: note: 'ccosl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:10:5: warning: incompatible redeclaration of library function 'ccoshl' [-Wincompatible-library-redeclaration]
int ccoshl (void);
^
_configtest.c:10:5: note: 'ccoshl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:11:5: warning: incompatible redeclaration of library function 'cexpl' [-Wincompatible-library-redeclaration]
int cexpl (void);
^
_configtest.c:11:5: note: 'cexpl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:12:5: warning: incompatible redeclaration of library function 'cimagl' [-Wincompatible-library-redeclaration]
int cimagl (void);
^
_configtest.c:12:5: note: 'cimagl' is a builtin with type 'long double (_Complex long double)'
_configtest.c:13:5: warning: incompatible redeclaration of library function 'clogl' [-Wincompatible-library-redeclaration]
int clogl (void);
^
_configtest.c:13:5: note: 'clogl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:14:5: warning: incompatible redeclaration of library function 'conjl' [-Wincompatible-library-redeclaration]
int conjl (void);
^
_configtest.c:14:5: note: 'conjl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:15:5: warning: incompatible redeclaration of library function 'cpowl' [-Wincompatible-library-redeclaration]
int cpowl (void);
^
_configtest.c:15:5: note: 'cpowl' is a builtin with type '_Complex long double (_Complex long double, _Complex long double)'
_configtest.c:16:5: warning: incompatible redeclaration of library function 'cprojl' [-Wincompatible-library-redeclaration]
int cprojl (void);
^
_configtest.c:16:5: note: 'cprojl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:17:5: warning: incompatible redeclaration of library function 'creall' [-Wincompatible-library-redeclaration]
int creall (void);
^
_configtest.c:17:5: note: 'creall' is a builtin with type 'long double (_Complex long double)'
_configtest.c:18:5: warning: incompatible redeclaration of library function 'csinl' [-Wincompatible-library-redeclaration]
int csinl (void);
^
_configtest.c:18:5: note: 'csinl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:19:5: warning: incompatible redeclaration of library function 'csinhl' [-Wincompatible-library-redeclaration]
int csinhl (void);
^
_configtest.c:19:5: note: 'csinhl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:20:5: warning: incompatible redeclaration of library function 'csqrtl' [-Wincompatible-library-redeclaration]
int csqrtl (void);
^
_configtest.c:20:5: note: 'csqrtl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:21:5: warning: incompatible redeclaration of library function 'ctanl' [-Wincompatible-library-redeclaration]
int ctanl (void);
^
_configtest.c:21:5: note: 'ctanl' is a builtin with type '_Complex long double (_Complex long double)'
_configtest.c:22:5: warning: incompatible redeclaration of library function 'ctanhl' [-Wincompatible-library-redeclaration]
int ctanhl (void);
^
_configtest.c:22:5: note: 'ctanhl' is a builtin with type '_Complex long double (_Complex long double)'
22 warnings generated.
clang _configtest.o -o _configtest
success!
removing: _configtest.c _configtest.o _configtest.o.d _configtest
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
_configtest.c:2:12: warning: unused function 'static_func' [-Wunused-function]
static int static_func (char * restrict a)
^
1 warning generated.
success!
removing: _configtest.c _configtest.o _configtest.o.d
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
_configtest.c:3:19: warning: unused function 'static_func' [-Wunused-function]
static inline int static_func (void)
^
1 warning generated.
success!
removing: _configtest.c _configtest.o _configtest.o.d
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
removing: _configtest.c _configtest.o _configtest.o.d
File: build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/config.h
#define SIZEOF_PY_INTPTR_T 8
#define SIZEOF_OFF_T 8
#define SIZEOF_PY_LONG_LONG 8
#define MATHLIB
#define HAVE_SIN 1
#define HAVE_COS 1
#define HAVE_TAN 1
#define HAVE_SINH 1
#define HAVE_COSH 1
#define HAVE_TANH 1
#define HAVE_FABS 1
#define HAVE_FLOOR 1
#define HAVE_CEIL 1
#define HAVE_SQRT 1
#define HAVE_LOG10 1
#define HAVE_LOG 1
#define HAVE_EXP 1
#define HAVE_ASIN 1
#define HAVE_ACOS 1
#define HAVE_ATAN 1
#define HAVE_FMOD 1
#define HAVE_MODF 1
#define HAVE_FREXP 1
#define HAVE_LDEXP 1
#define HAVE_RINT 1
#define HAVE_TRUNC 1
#define HAVE_EXP2 1
#define HAVE_LOG2 1
#define HAVE_ATAN2 1
#define HAVE_POW 1
#define HAVE_NEXTAFTER 1
#define HAVE_STRTOLL 1
#define HAVE_STRTOULL 1
#define HAVE_CBRT 1
#define HAVE_STRTOLD_L 1
#define HAVE_BACKTRACE 1
#define HAVE_MADVISE 1
#define HAVE_XMMINTRIN_H 1
#define HAVE_EMMINTRIN_H 1
#define HAVE_XLOCALE_H 1
#define HAVE_DLFCN_H 1
#define HAVE_SYS_MMAN_H 1
#define HAVE___BUILTIN_ISNAN 1
#define HAVE___BUILTIN_ISINF 1
#define HAVE___BUILTIN_ISFINITE 1
#define HAVE___BUILTIN_BSWAP32 1
#define HAVE___BUILTIN_BSWAP64 1
#define HAVE___BUILTIN_EXPECT 1
#define HAVE___BUILTIN_MUL_OVERFLOW 1
#define HAVE___BUILTIN_CPU_SUPPORTS 1
#define HAVE__M_FROM_INT64 1
#define HAVE__MM_LOAD_PS 1
#define HAVE__MM_PREFETCH 1
#define HAVE__MM_LOAD_PD 1
#define HAVE___BUILTIN_PREFETCH 1
#define HAVE_LINK_AVX 1
#define HAVE_LINK_AVX2 1
#define HAVE_XGETBV 1
#define HAVE_ATTRIBUTE_NONNULL 1
#define HAVE_ATTRIBUTE_TARGET_AVX 1
#define HAVE_ATTRIBUTE_TARGET_AVX2 1
#define HAVE___THREAD 1
#define HAVE_SINF 1
#define HAVE_COSF 1
#define HAVE_TANF 1
#define HAVE_SINHF 1
#define HAVE_COSHF 1
#define HAVE_TANHF 1
#define HAVE_FABSF 1
#define HAVE_FLOORF 1
#define HAVE_CEILF 1
#define HAVE_RINTF 1
#define HAVE_TRUNCF 1
#define HAVE_SQRTF 1
#define HAVE_LOG10F 1
#define HAVE_LOGF 1
#define HAVE_LOG1PF 1
#define HAVE_EXPF 1
#define HAVE_EXPM1F 1
#define HAVE_ASINF 1
#define HAVE_ACOSF 1
#define HAVE_ATANF 1
#define HAVE_ASINHF 1
#define HAVE_ACOSHF 1
#define HAVE_ATANHF 1
#define HAVE_HYPOTF 1
#define HAVE_ATAN2F 1
#define HAVE_POWF 1
#define HAVE_FMODF 1
#define HAVE_MODFF 1
#define HAVE_FREXPF 1
#define HAVE_LDEXPF 1
#define HAVE_EXP2F 1
#define HAVE_LOG2F 1
#define HAVE_COPYSIGNF 1
#define HAVE_NEXTAFTERF 1
#define HAVE_CBRTF 1
#define HAVE_SINL 1
#define HAVE_COSL 1
#define HAVE_TANL 1
#define HAVE_SINHL 1
#define HAVE_COSHL 1
#define HAVE_TANHL 1
#define HAVE_FABSL 1
#define HAVE_FLOORL 1
#define HAVE_CEILL 1
#define HAVE_RINTL 1
#define HAVE_TRUNCL 1
#define HAVE_SQRTL 1
#define HAVE_LOG10L 1
#define HAVE_LOGL 1
#define HAVE_LOG1PL 1
#define HAVE_EXPL 1
#define HAVE_EXPM1L 1
#define HAVE_ASINL 1
#define HAVE_ACOSL 1
#define HAVE_ATANL 1
#define HAVE_ASINHL 1
#define HAVE_ACOSHL 1
#define HAVE_ATANHL 1
#define HAVE_HYPOTL 1
#define HAVE_ATAN2L 1
#define HAVE_POWL 1
#define HAVE_FMODL 1
#define HAVE_MODFL 1
#define HAVE_FREXPL 1
#define HAVE_LDEXPL 1
#define HAVE_EXP2L 1
#define HAVE_LOG2L 1
#define HAVE_COPYSIGNL 1
#define HAVE_NEXTAFTERL 1
#define HAVE_CBRTL 1
#define HAVE_DECL_SIGNBIT
#define HAVE_COMPLEX_H 1
#define HAVE_CABS 1
#define HAVE_CACOS 1
#define HAVE_CACOSH 1
#define HAVE_CARG 1
#define HAVE_CASIN 1
#define HAVE_CASINH 1
#define HAVE_CATAN 1
#define HAVE_CATANH 1
#define HAVE_CCOS 1
#define HAVE_CCOSH 1
#define HAVE_CEXP 1
#define HAVE_CIMAG 1
#define HAVE_CLOG 1
#define HAVE_CONJ 1
#define HAVE_CPOW 1
#define HAVE_CPROJ 1
#define HAVE_CREAL 1
#define HAVE_CSIN 1
#define HAVE_CSINH 1
#define HAVE_CSQRT 1
#define HAVE_CTAN 1
#define HAVE_CTANH 1
#define HAVE_CABSF 1
#define HAVE_CACOSF 1
#define HAVE_CACOSHF 1
#define HAVE_CARGF 1
#define HAVE_CASINF 1
#define HAVE_CASINHF 1
#define HAVE_CATANF 1
#define HAVE_CATANHF 1
#define HAVE_CCOSF 1
#define HAVE_CCOSHF 1
#define HAVE_CEXPF 1
#define HAVE_CIMAGF 1
#define HAVE_CLOGF 1
#define HAVE_CONJF 1
#define HAVE_CPOWF 1
#define HAVE_CPROJF 1
#define HAVE_CREALF 1
#define HAVE_CSINF 1
#define HAVE_CSINHF 1
#define HAVE_CSQRTF 1
#define HAVE_CTANF 1
#define HAVE_CTANHF 1
#define HAVE_CABSL 1
#define HAVE_CACOSL 1
#define HAVE_CACOSHL 1
#define HAVE_CARGL 1
#define HAVE_CASINL 1
#define HAVE_CASINHL 1
#define HAVE_CATANL 1
#define HAVE_CATANHL 1
#define HAVE_CCOSL 1
#define HAVE_CCOSHL 1
#define HAVE_CEXPL 1
#define HAVE_CIMAGL 1
#define HAVE_CLOGL 1
#define HAVE_CONJL 1
#define HAVE_CPOWL 1
#define HAVE_CPROJL 1
#define HAVE_CREALL 1
#define HAVE_CSINL 1
#define HAVE_CSINHL 1
#define HAVE_CSQRTL 1
#define HAVE_CTANL 1
#define HAVE_CTANHL 1
#define NPY_RESTRICT restrict
#define NPY_RELAXED_STRIDES_CHECKING 1
#define HAVE_LDOUBLE_INTEL_EXTENDED_16_BYTES_LE 1
#define NPY_PY3K 1
#ifndef __cplusplus
/* #undef inline */
#endif
#ifndef _NPY_NPY_CONFIG_H_
#error config.h should never be included directly, include npy_config.h instead
#endif
EOF
adding 'build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/config.h' to sources.
Generating build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/_numpyconfig.h
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
_configtest.c:1:5: warning: incompatible redeclaration of library function 'exp' [-Wincompatible-library-redeclaration]
int exp (void);
^
_configtest.c:1:5: note: 'exp' is a builtin with type 'double (double)'
1 warning generated.
clang _configtest.o -o _configtest
success!
removing: _configtest.c _configtest.o _configtest.o.d _configtest
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
success!
removing: _configtest.c _configtest.o _configtest.o.d
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -c'
clang: _configtest.c
success!
removing: _configtest.c _configtest.o _configtest.o.d
File: build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/_numpyconfig.h
#define NPY_SIZEOF_SHORT SIZEOF_SHORT
#define NPY_SIZEOF_INT SIZEOF_INT
#define NPY_SIZEOF_LONG SIZEOF_LONG
#define NPY_SIZEOF_FLOAT 4
#define NPY_SIZEOF_COMPLEX_FLOAT 8
#define NPY_SIZEOF_DOUBLE 8
#define NPY_SIZEOF_COMPLEX_DOUBLE 16
#define NPY_SIZEOF_LONGDOUBLE 16
#define NPY_SIZEOF_COMPLEX_LONGDOUBLE 32
#define NPY_SIZEOF_PY_INTPTR_T 8
#define NPY_SIZEOF_OFF_T 8
#define NPY_SIZEOF_PY_LONG_LONG 8
#define NPY_SIZEOF_LONGLONG 8
#define NPY_NO_SMP 0
#define NPY_HAVE_DECL_ISNAN
#define NPY_HAVE_DECL_ISINF
#define NPY_HAVE_DECL_ISFINITE
#define NPY_HAVE_DECL_SIGNBIT
#define NPY_USE_C99_COMPLEX 1
#define NPY_HAVE_COMPLEX_DOUBLE 1
#define NPY_HAVE_COMPLEX_FLOAT 1
#define NPY_HAVE_COMPLEX_LONG_DOUBLE 1
#define NPY_RELAXED_STRIDES_CHECKING 1
#define NPY_USE_C99_FORMATS 1
#define NPY_VISIBILITY_HIDDEN __attribute__((visibility("hidden")))
#define NPY_ABI_VERSION 0x01000009
#define NPY_API_VERSION 0x0000000D
#ifndef __STDC_FORMAT_MACROS
#define __STDC_FORMAT_MACROS 1
#endif
EOF
adding 'build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/_numpyconfig.h' to sources.
executing numpy/core/code_generators/generate_numpy_api.py
adding 'build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/__multiarray_api.h' to sources.
numpy.core - nothing done with h_files = ['build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/config.h', 'build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/_numpyconfig.h', 'build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/__multiarray_api.h']
building extension "numpy.core._multiarray_tests" sources
creating build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/_multiarray_tests.c
building extension "numpy.core._multiarray_umath" sources
adding 'build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/config.h' to sources.
adding 'build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/_numpyconfig.h' to sources.
executing numpy/core/code_generators/generate_numpy_api.py
adding 'build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/__multiarray_api.h' to sources.
executing numpy/core/code_generators/generate_ufunc_api.py
adding 'build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/__ufunc_api.h' to sources.
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/arraytypes.c
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/einsum.c
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/lowlevel_strided_loops.c
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/nditer_templ.c
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/scalartypes.c
creating build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/funcs.inc
adding 'build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath' to include_dirs.
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/simd.inc
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/loops.h
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/loops.c
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/matmul.h
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/matmul.c
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/scalarmath.c
adding 'build/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath' to include_dirs.
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/common/templ_common.h
adding 'build/src.macosx-10.15-x86_64-3.9/numpy/core/src/common' to include_dirs.
numpy.core - nothing done with h_files = ['build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/funcs.inc', 'build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/simd.inc', 'build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/loops.h', 'build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/matmul.h', 'build/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath/npy_math_internal.h', 'build/src.macosx-10.15-x86_64-3.9/numpy/core/src/common/templ_common.h', 'build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/config.h', 'build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/_numpyconfig.h', 'build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/__multiarray_api.h', 'build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/__ufunc_api.h']
building extension "numpy.core._umath_tests" sources
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/_umath_tests.c
building extension "numpy.core._rational_tests" sources
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/_rational_tests.c
building extension "numpy.core._struct_ufunc_tests" sources
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/_struct_ufunc_tests.c
building extension "numpy.core._operand_flag_tests" sources
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/_operand_flag_tests.c
building extension "numpy.fft.fftpack_lite" sources
building extension "numpy.linalg.lapack_lite" sources
creating build/src.macosx-10.15-x86_64-3.9/numpy/linalg
adding 'numpy/linalg/lapack_lite/python_xerbla.c' to sources.
building extension "numpy.linalg._umath_linalg" sources
adding 'numpy/linalg/lapack_lite/python_xerbla.c' to sources.
conv_template:> build/src.macosx-10.15-x86_64-3.9/numpy/linalg/umath_linalg.c
building extension "numpy.random.mtrand" sources
creating build/src.macosx-10.15-x86_64-3.9/numpy/random
building data_files sources
build_src: building npy-pkg config files
running build_py
creating build/lib.macosx-10.15-x86_64-3.9
creating build/lib.macosx-10.15-x86_64-3.9/numpy
copying numpy/conftest.py -> build/lib.macosx-10.15-x86_64-3.9/numpy
copying numpy/version.py -> build/lib.macosx-10.15-x86_64-3.9/numpy
copying numpy/_globals.py -> build/lib.macosx-10.15-x86_64-3.9/numpy
copying numpy/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy
copying numpy/dual.py -> build/lib.macosx-10.15-x86_64-3.9/numpy
copying numpy/_distributor_init.py -> build/lib.macosx-10.15-x86_64-3.9/numpy
copying numpy/setup.py -> build/lib.macosx-10.15-x86_64-3.9/numpy
copying numpy/ctypeslib.py -> build/lib.macosx-10.15-x86_64-3.9/numpy
copying numpy/matlib.py -> build/lib.macosx-10.15-x86_64-3.9/numpy
copying numpy/_pytesttester.py -> build/lib.macosx-10.15-x86_64-3.9/numpy
copying build/src.macosx-10.15-x86_64-3.9/numpy/__config__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy
creating build/lib.macosx-10.15-x86_64-3.9/numpy/compat
copying numpy/compat/py3k.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/compat
copying numpy/compat/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/compat
copying numpy/compat/setup.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/compat
copying numpy/compat/_inspect.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/compat
creating build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/umath.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/fromnumeric.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/_dtype.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/_add_newdocs.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/_methods.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/_internal.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/_string_helpers.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/multiarray.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/records.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/setup_common.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/_aliased_types.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/memmap.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/overrides.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/getlimits.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/_dtype_ctypes.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/defchararray.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/shape_base.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/machar.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/setup.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/numeric.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/function_base.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/einsumfunc.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/umath_tests.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/info.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/numerictypes.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/_type_aliases.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/cversions.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/arrayprint.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
copying numpy/core/code_generators/generate_numpy_api.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/core
creating build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/unixccompiler.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/numpy_distribution.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/conv_template.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/cpuinfo.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/ccompiler.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/msvc9compiler.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/npy_pkg_config.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/compat.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/misc_util.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/log.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/line_endings.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/lib2def.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/pathccompiler.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/system_info.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/core.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/__version__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/exec_command.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/from_template.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/mingw32ccompiler.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/setup.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/extension.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/msvccompiler.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/intelccompiler.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying numpy/distutils/info.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
copying build/src.macosx-10.15-x86_64-3.9/numpy/distutils/__config__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils
creating build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/build.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/config_compiler.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/build_ext.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/config.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/install_headers.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/build_py.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/build_src.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/sdist.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/build_scripts.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/bdist_rpm.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/install_clib.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/build_clib.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/autodist.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/egg_info.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/install.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/develop.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
copying numpy/distutils/command/install_data.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/command
creating build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/gnu.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/compaq.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/intel.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/none.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/nag.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/pg.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/ibm.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/sun.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/lahey.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/g95.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/mips.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/hpux.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/environment.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/pathf95.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/absoft.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
copying numpy/distutils/fcompiler/vast.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/distutils/fcompiler
creating build/lib.macosx-10.15-x86_64-3.9/numpy/doc
copying numpy/doc/misc.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/doc
copying numpy/doc/internals.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/doc
copying numpy/doc/creation.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/doc
copying numpy/doc/constants.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/doc
copying numpy/doc/ufuncs.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/doc
copying numpy/doc/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/doc
copying numpy/doc/broadcasting.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/doc
copying numpy/doc/basics.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/doc
copying numpy/doc/subclassing.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/doc
copying numpy/doc/indexing.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/doc
copying numpy/doc/byteswapping.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/doc
copying numpy/doc/structured_arrays.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/doc
copying numpy/doc/glossary.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/doc
creating build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/cfuncs.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/common_rules.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/crackfortran.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/cb_rules.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/rules.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/f2py2e.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/func2subr.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/__version__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/diagnose.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/setup.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/capi_maps.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/f90mod_rules.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/f2py_testing.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/use_rules.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/info.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/auxfuncs.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
copying numpy/f2py/__main__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/f2py
creating build/lib.macosx-10.15-x86_64-3.9/numpy/fft
copying numpy/fft/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/fft
copying numpy/fft/setup.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/fft
copying numpy/fft/helper.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/fft
copying numpy/fft/fftpack.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/fft
copying numpy/fft/info.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/fft
creating build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/_iotools.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/mixins.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/nanfunctions.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/recfunctions.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/histograms.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/scimath.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/_version.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/user_array.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/format.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/twodim_base.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/financial.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/index_tricks.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/npyio.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/shape_base.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/setup.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/stride_tricks.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/utils.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/arrayterator.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/function_base.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/arraysetops.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/arraypad.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/type_check.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/info.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/polynomial.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/_datasource.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
copying numpy/lib/ufunclike.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/lib
creating build/lib.macosx-10.15-x86_64-3.9/numpy/linalg
copying numpy/linalg/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/linalg
copying numpy/linalg/setup.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/linalg
copying numpy/linalg/linalg.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/linalg
copying numpy/linalg/info.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/linalg
creating build/lib.macosx-10.15-x86_64-3.9/numpy/ma
copying numpy/ma/extras.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/ma
copying numpy/ma/version.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/ma
copying numpy/ma/testutils.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/ma
copying numpy/ma/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/ma
copying numpy/ma/core.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/ma
copying numpy/ma/bench.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/ma
copying numpy/ma/setup.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/ma
copying numpy/ma/timer_comparison.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/ma
copying numpy/ma/mrecords.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/ma
creating build/lib.macosx-10.15-x86_64-3.9/numpy/matrixlib
copying numpy/matrixlib/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/matrixlib
copying numpy/matrixlib/setup.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/matrixlib
copying numpy/matrixlib/defmatrix.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/matrixlib
creating build/lib.macosx-10.15-x86_64-3.9/numpy/polynomial
copying numpy/polynomial/laguerre.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/polynomial
copying numpy/polynomial/_polybase.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/polynomial
copying numpy/polynomial/polyutils.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/polynomial
copying numpy/polynomial/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/polynomial
copying numpy/polynomial/setup.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/polynomial
copying numpy/polynomial/hermite_e.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/polynomial
copying numpy/polynomial/chebyshev.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/polynomial
copying numpy/polynomial/polynomial.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/polynomial
copying numpy/polynomial/legendre.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/polynomial
copying numpy/polynomial/hermite.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/polynomial
creating build/lib.macosx-10.15-x86_64-3.9/numpy/random
copying numpy/random/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/random
copying numpy/random/setup.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/random
copying numpy/random/info.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/random
creating build/lib.macosx-10.15-x86_64-3.9/numpy/testing
copying numpy/testing/nosetester.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/testing
copying numpy/testing/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/testing
copying numpy/testing/noseclasses.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/testing
copying numpy/testing/setup.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/testing
copying numpy/testing/utils.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/testing
copying numpy/testing/print_coercion_tables.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/testing
copying numpy/testing/decorators.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/testing
creating build/lib.macosx-10.15-x86_64-3.9/numpy/testing/_private
copying numpy/testing/_private/nosetester.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/testing/_private
copying numpy/testing/_private/__init__.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/testing/_private
copying numpy/testing/_private/noseclasses.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/testing/_private
copying numpy/testing/_private/utils.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/testing/_private
copying numpy/testing/_private/parameterized.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/testing/_private
copying numpy/testing/_private/decorators.py -> build/lib.macosx-10.15-x86_64-3.9/numpy/testing/_private
running build_clib
customize UnixCCompiler
customize UnixCCompiler using build_clib
building 'npymath' library
compiling C sources
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
creating build/temp.macosx-10.15-x86_64-3.9
creating build/temp.macosx-10.15-x86_64-3.9/numpy
creating build/temp.macosx-10.15-x86_64-3.9/numpy/core
creating build/temp.macosx-10.15-x86_64-3.9/numpy/core/src
creating build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/npymath
creating build/temp.macosx-10.15-x86_64-3.9/build
creating build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9
creating build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy
creating build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core
creating build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src
creating build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath
compile options: '-Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Inumpy/core/include -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy -Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -c'
clang: numpy/core/src/npymath/npy_math.c
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath/npy_math_complex.c
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath/ieee754.c
clang: numpy/core/src/npymath/halffloat.c
numpy/core/src/npymath/npy_math_complex.c.src:48:33: warning: unused variable 'tiny' [-Wunused-const-variable]
static const volatile npy_float tiny = 3.9443045e-31f;
^
numpy/core/src/npymath/npy_math_complex.c.src:67:25: warning: unused variable 'c_halff' [-Wunused-const-variable]
static const npy_cfloat c_halff = {0.5F, 0.0};
^
numpy/core/src/npymath/npy_math_complex.c.src:68:25: warning: unused variable 'c_if' [-Wunused-const-variable]
static const npy_cfloat c_if = {0.0, 1.0F};
^
numpy/core/src/npymath/npy_math_complex.c.src:69:25: warning: unused variable 'c_ihalff' [-Wunused-const-variable]
static const npy_cfloat c_ihalff = {0.0, 0.5F};
^
numpy/core/src/npymath/npy_math_complex.c.src:79:1: warning: unused function 'caddf' [-Wunused-function]
caddf(npy_cfloat a, npy_cfloat b)
^
numpy/core/src/npymath/npy_math_complex.c.src:87:1: warning: unused function 'csubf' [-Wunused-function]
csubf(npy_cfloat a, npy_cfloat b)
^
numpy/core/src/npymath/npy_math_complex.c.src:137:1: warning: unused function 'cnegf' [-Wunused-function]
cnegf(npy_cfloat a)
^
numpy/core/src/npymath/npy_math_complex.c.src:144:1: warning: unused function 'cmulif' [-Wunused-function]
cmulif(npy_cfloat a)
^
numpy/core/src/npymath/npy_math_complex.c.src:67:26: warning: unused variable 'c_half' [-Wunused-const-variable]
static const npy_cdouble c_half = {0.5, 0.0};
^
numpy/core/src/npymath/npy_math_complex.c.src:68:26: warning: unused variable 'c_i' [-Wunused-const-variable]
static const npy_cdouble c_i = {0.0, 1.0};
^
numpy/core/src/npymath/npy_math_complex.c.src:69:26: warning: unused variable 'c_ihalf' [-Wunused-const-variable]
static const npy_cdouble c_ihalf = {0.0, 0.5};
^
numpy/core/src/npymath/npy_math_complex.c.src:79:1: warning: unused function 'cadd' [-Wunused-function]
cadd(npy_cdouble a, npy_cdouble b)
^
numpy/core/src/npymath/npy_math_complex.c.src:87:1: warning: unused function 'csub' [-Wunused-function]
csub(npy_cdouble a, npy_cdouble b)
^
numpy/core/src/npymath/npy_math_complex.c.src:137:1: warning: unused function 'cneg' [-Wunused-function]
cneg(npy_cdouble a)
^
numpy/core/src/npymath/npy_math_complex.c.src:144:1: warning: unused function 'cmuli' [-Wunused-function]
cmuli(npy_cdouble a)
^
numpy/core/src/npymath/npy_math_complex.c.src:67:30: warning: unused variable 'c_halfl' [-Wunused-const-variable]
static const npy_clongdouble c_halfl = {0.5L, 0.0};
^
numpy/core/src/npymath/npy_math_complex.c.src:68:30: warning: unused variable 'c_il' [-Wunused-const-variable]
static const npy_clongdouble c_il = {0.0, 1.0L};
^
numpy/core/src/npymath/npy_math_complex.c.src:69:30: warning: unused variable 'c_ihalfl' [-Wunused-const-variable]
static const npy_clongdouble c_ihalfl = {0.0, 0.5L};
^
numpy/core/src/npymath/npy_math_complex.c.src:79:1: warning: unused function 'caddl' [-Wunused-function]
caddl(npy_clongdouble a, npy_clongdouble b)
^
numpy/core/src/npymath/npy_math_complex.c.src:87:1: warning: unused function 'csubl' [-Wunused-function]
csubl(npy_clongdouble a, npy_clongdouble b)
^
numpy/core/src/npymath/npy_math_complex.c.src:137:1: warning: unused function 'cnegl' [-Wunused-function]
cnegl(npy_clongdouble a)
^
numpy/core/src/npymath/npy_math_complex.c.src:144:1: warning: unused function 'cmulil' [-Wunused-function]
cmulil(npy_clongdouble a)
^
22 warnings generated.
ar: adding 4 object files to build/temp.macosx-10.15-x86_64-3.9/libnpymath.a
ranlib:@ build/temp.macosx-10.15-x86_64-3.9/libnpymath.a
building 'npysort' library
compiling C sources
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
creating build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/npysort
compile options: '-Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Inumpy/core/include -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy -Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -c'
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/npysort/quicksort.c
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/npysort/mergesort.c
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/npysort/heapsort.c
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/npysort/selection.c
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/npysort/binsearch.c
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
numpy/core/src/npysort/selection.c.src:328:9: warning: code will never be executed [-Wunreachable-code]
npy_intp k;
^~~~~~~~~~~
numpy/core/src/npysort/selection.c.src:326:14: note: silence by adding parentheses to mark code as explicitly dead
else if (0 && kth == num - 1) {
^
/* DISABLES CODE */ ( )
22 warnings generated.
ar: adding 5 object files to build/temp.macosx-10.15-x86_64-3.9/libnpysort.a
ranlib:@ build/temp.macosx-10.15-x86_64-3.9/libnpysort.a
running build_ext
customize UnixCCompiler
customize UnixCCompiler using build_ext
building 'numpy.core._dummy' extension
compiling C sources
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-DNPY_INTERNAL_BUILD=1 -DHAVE_NPY_CONFIG_H=1 -D_FILE_OFFSET_BITS=64 -D_LARGEFILE_SOURCE=1 -D_LARGEFILE64_SOURCE=1 -Inumpy/core/include -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy -Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -c'
clang: numpy/core/src/dummymodule.c
clang -bundle -undefined dynamic_lookup -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/dummymodule.o -L/usr/local/lib -L/usr/local/opt/[email protected]/lib -L/usr/local/opt/sqlite/lib -Lbuild/temp.macosx-10.15-x86_64-3.9 -o build/lib.macosx-10.15-x86_64-3.9/numpy/core/_dummy.cpython-39-darwin.so
building 'numpy.core._multiarray_tests' extension
compiling C sources
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
creating build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray
creating build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/common
compile options: '-DNPY_INTERNAL_BUILD=1 -DHAVE_NPY_CONFIG_H=1 -D_FILE_OFFSET_BITS=64 -D_LARGEFILE_SOURCE=1 -D_LARGEFILE64_SOURCE=1 -Inumpy/core/include -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy -Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -c'
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/_multiarray_tests.c
clang: numpy/core/src/common/mem_overlap.c
clang -bundle -undefined dynamic_lookup -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/_multiarray_tests.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/common/mem_overlap.o -L/usr/local/lib -L/usr/local/opt/[email protected]/lib -L/usr/local/opt/sqlite/lib -Lbuild/temp.macosx-10.15-x86_64-3.9 -lnpymath -o build/lib.macosx-10.15-x86_64-3.9/numpy/core/_multiarray_tests.cpython-39-darwin.so
building 'numpy.core._multiarray_umath' extension
compiling C sources
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
creating build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray
creating build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/umath
creating build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath
creating build/temp.macosx-10.15-x86_64-3.9/private
creating build/temp.macosx-10.15-x86_64-3.9/private/var
creating build/temp.macosx-10.15-x86_64-3.9/private/var/folders
creating build/temp.macosx-10.15-x86_64-3.9/private/var/folders/fz
creating build/temp.macosx-10.15-x86_64-3.9/private/var/folders/fz/0j719tys48x7jlnjnwc69smr0000gn
creating build/temp.macosx-10.15-x86_64-3.9/private/var/folders/fz/0j719tys48x7jlnjnwc69smr0000gn/T
creating build/temp.macosx-10.15-x86_64-3.9/private/var/folders/fz/0j719tys48x7jlnjnwc69smr0000gn/T/pip-install-ufzck51l
creating build/temp.macosx-10.15-x86_64-3.9/private/var/folders/fz/0j719tys48x7jlnjnwc69smr0000gn/T/pip-install-ufzck51l/numpy_b0e8a3953a1d4b46801f12bcea55536e
creating build/temp.macosx-10.15-x86_64-3.9/private/var/folders/fz/0j719tys48x7jlnjnwc69smr0000gn/T/pip-install-ufzck51l/numpy_b0e8a3953a1d4b46801f12bcea55536e/numpy
creating build/temp.macosx-10.15-x86_64-3.9/private/var/folders/fz/0j719tys48x7jlnjnwc69smr0000gn/T/pip-install-ufzck51l/numpy_b0e8a3953a1d4b46801f12bcea55536e/numpy/_build_utils
creating build/temp.macosx-10.15-x86_64-3.9/private/var/folders/fz/0j719tys48x7jlnjnwc69smr0000gn/T/pip-install-ufzck51l/numpy_b0e8a3953a1d4b46801f12bcea55536e/numpy/_build_utils/src
compile options: '-DNPY_INTERNAL_BUILD=1 -DHAVE_NPY_CONFIG_H=1 -D_FILE_OFFSET_BITS=64 -D_LARGEFILE_SOURCE=1 -D_LARGEFILE64_SOURCE=1 -DNO_ATLAS_INFO=3 -DHAVE_CBLAS -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Inumpy/core/include -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy -Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -c'
extra options: '-msse3 -I/System/Library/Frameworks/vecLib.framework/Headers'
clang: numpy/core/src/multiarray/alloc.c
clang: numpy/core/src/multiarray/calculation.cclang: numpy/core/src/multiarray/array_assign_scalar.c
clang: numpy/core/src/multiarray/convert.c
clang: numpy/core/src/multiarray/ctors.c
clang: numpy/core/src/multiarray/datetime_busday.c
clang: numpy/core/src/multiarray/dragon4.cclang: numpy/core/src/multiarray/flagsobject.c
numpy/core/src/multiarray/ctors.c:2261:36: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
if (!(PyUString_Check(name) && PyUString_GET_SIZE(name) == 0)) {
^
numpy/core/include/numpy/npy_3kcompat.h:110:28: note: expanded from macro 'PyUString_GET_SIZE'
#define PyUString_GET_SIZE PyUnicode_GET_SIZE
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:261:7: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op) : \
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/ctors.c:2261:36: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
if (!(PyUString_Check(name) && PyUString_GET_SIZE(name) == 0)) {
^
numpy/core/include/numpy/npy_3kcompat.h:110:28: note: expanded from macro 'PyUString_GET_SIZE'
#define PyUString_GET_SIZE PyUnicode_GET_SIZE
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:262:14: note: expanded from macro 'PyUnicode_GET_SIZE'
((void)PyUnicode_AsUnicode(_PyObject_CAST(op)),\
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/ctors.c:2261:36: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
if (!(PyUString_Check(name) && PyUString_GET_SIZE(name) == 0)) {
^
numpy/core/include/numpy/npy_3kcompat.h:110:28: note: expanded from macro 'PyUString_GET_SIZE'
#define PyUString_GET_SIZE PyUnicode_GET_SIZE
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:264:8: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
clang: numpy/core/src/multiarray/arrayobject.c
clang: numpy/core/src/multiarray/array_assign_array.c
clang: numpy/core/src/multiarray/convert_datatype.c
clang: numpy/core/src/multiarray/getset.c
clang: numpy/core/src/multiarray/datetime_busdaycal.c
clang: numpy/core/src/multiarray/buffer.c
clang: numpy/core/src/multiarray/compiled_base.c
clang: numpy/core/src/multiarray/hashdescr.c
clang: numpy/core/src/multiarray/descriptor.c
numpy/core/src/multiarray/descriptor.c:453:13: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
if (PyUString_GET_SIZE(name) == 0) {
^
numpy/core/include/numpy/npy_3kcompat.h:110:28: note: expanded from macro 'PyUString_GET_SIZE'
#define PyUString_GET_SIZE PyUnicode_GET_SIZE
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:261:7: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op) : \
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/descriptor.c:453:13: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
if (PyUString_GET_SIZE(name) == 0) {
^
numpy/core/include/numpy/npy_3kcompat.h:110:28: note: expanded from macro 'PyUString_GET_SIZE'
#define PyUString_GET_SIZE PyUnicode_GET_SIZE
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:262:14: note: expanded from macro 'PyUnicode_GET_SIZE'
((void)PyUnicode_AsUnicode(_PyObject_CAST(op)),\
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/descriptor.c:453:13: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
if (PyUString_GET_SIZE(name) == 0) {
^
numpy/core/include/numpy/npy_3kcompat.h:110:28: note: expanded from macro 'PyUString_GET_SIZE'
#define PyUString_GET_SIZE PyUnicode_GET_SIZE
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:264:8: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/descriptor.c:460:48: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
else if (PyUString_Check(title) && PyUString_GET_SIZE(title) > 0) {
^
numpy/core/include/numpy/npy_3kcompat.h:110:28: note: expanded from macro 'PyUString_GET_SIZE'
#define PyUString_GET_SIZE PyUnicode_GET_SIZE
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:261:7: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op) : \
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/descriptor.c:460:48: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
else if (PyUString_Check(title) && PyUString_GET_SIZE(title) > 0) {
^
numpy/core/include/numpy/npy_3kcompat.h:110:28: note: expanded from macro 'PyUString_GET_SIZE'
#define PyUString_GET_SIZE PyUnicode_GET_SIZE
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:262:14: note: expanded from macro 'PyUnicode_GET_SIZE'
((void)PyUnicode_AsUnicode(_PyObject_CAST(op)),\
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/descriptor.c:460:48: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
else if (PyUString_Check(title) && PyUString_GET_SIZE(title) > 0) {
^
numpy/core/include/numpy/npy_3kcompat.h:110:28: note: expanded from macro 'PyUString_GET_SIZE'
#define PyUString_GET_SIZE PyUnicode_GET_SIZE
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:264:8: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
clang: numpy/core/src/multiarray/conversion_utils.c
clang: numpy/core/src/multiarray/item_selection.c
clang: numpy/core/src/multiarray/dtype_transfer.c
clang: numpy/core/src/multiarray/mapping.c
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/arraytypes.c
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/nditer_templ.c
3 warnings generated.
clang: numpy/core/src/multiarray/datetime.c
numpy/core/src/multiarray/arraytypes.c.src:477:11: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
ptr = PyUnicode_AS_UNICODE(temp);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:279:7: note: expanded from macro 'PyUnicode_AS_UNICODE'
PyUnicode_AsUnicode(_PyObject_CAST(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/arraytypes.c.src:482:15: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
datalen = PyUnicode_GET_DATA_SIZE(temp);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:261:7: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op) : \
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/arraytypes.c.src:482:15: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
datalen = PyUnicode_GET_DATA_SIZE(temp);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:262:14: note: expanded from macro 'PyUnicode_GET_SIZE'
((void)PyUnicode_AsUnicode(_PyObject_CAST(op)),\
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/arraytypes.c.src:482:15: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
datalen = PyUnicode_GET_DATA_SIZE(temp);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:264:8: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
clang: numpy/core/src/multiarray/common.c
numpy/core/src/multiarray/common.c:187:28: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
itemsize = PyUnicode_GET_DATA_SIZE(temp);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:261:7: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op) : \
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/common.c:187:28: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
itemsize = PyUnicode_GET_DATA_SIZE(temp);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:262:14: note: expanded from macro 'PyUnicode_GET_SIZE'
((void)PyUnicode_AsUnicode(_PyObject_CAST(op)),\
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/common.c:187:28: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
itemsize = PyUnicode_GET_DATA_SIZE(temp);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:264:8: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/common.c:239:28: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
itemsize = PyUnicode_GET_DATA_SIZE(temp);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:261:7: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op) : \
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/common.c:239:28: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
itemsize = PyUnicode_GET_DATA_SIZE(temp);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:262:14: note: expanded from macro 'PyUnicode_GET_SIZE'
((void)PyUnicode_AsUnicode(_PyObject_CAST(op)),\
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/common.c:239:28: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
itemsize = PyUnicode_GET_DATA_SIZE(temp);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:264:8: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/common.c:282:24: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
int itemsize = PyUnicode_GET_DATA_SIZE(obj);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:261:7: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op) : \
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/common.c:282:24: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
int itemsize = PyUnicode_GET_DATA_SIZE(obj);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:262:14: note: expanded from macro 'PyUnicode_GET_SIZE'
((void)PyUnicode_AsUnicode(_PyObject_CAST(op)),\
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/common.c:282:24: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
int itemsize = PyUnicode_GET_DATA_SIZE(obj);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:264:8: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
6 warnings generated.
clang: numpy/core/src/multiarray/nditer_pywrap.c
9 warnings generated.
clang: numpy/core/src/multiarray/sequence.c
clang: numpy/core/src/multiarray/shape.c
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/einsum.c
clang: numpy/core/src/multiarray/methods.c
clang: numpy/core/src/multiarray/iterators.c
clang: numpy/core/src/multiarray/datetime_strings.c
clang: numpy/core/src/multiarray/number.c
clang: numpy/core/src/multiarray/scalarapi.c
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/scalartypes.c
numpy/core/src/multiarray/scalarapi.c:74:28: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
return (void *)PyUnicode_AS_DATA(scalar);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:283:21: note: expanded from macro 'PyUnicode_AS_DATA'
((const char *)(PyUnicode_AS_UNICODE(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:279:7: note: expanded from macro 'PyUnicode_AS_UNICODE'
PyUnicode_AsUnicode(_PyObject_CAST(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalarapi.c:135:28: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
return (void *)PyUnicode_AS_DATA(scalar);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:283:21: note: expanded from macro 'PyUnicode_AS_DATA'
((const char *)(PyUnicode_AS_UNICODE(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:279:7: note: expanded from macro 'PyUnicode_AS_UNICODE'
PyUnicode_AsUnicode(_PyObject_CAST(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalarapi.c:568:29: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
descr->elsize = PyUnicode_GET_DATA_SIZE(sc);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:261:7: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op) : \
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalarapi.c:568:29: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
descr->elsize = PyUnicode_GET_DATA_SIZE(sc);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:262:14: note: expanded from macro 'PyUnicode_GET_SIZE'
((void)PyUnicode_AsUnicode(_PyObject_CAST(op)),\
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalarapi.c:568:29: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
descr->elsize = PyUnicode_GET_DATA_SIZE(sc);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:264:8: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalartypes.c.src:475:17: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
ip = dptr = PyUnicode_AS_UNICODE(self);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:279:7: note: expanded from macro 'PyUnicode_AS_UNICODE'
PyUnicode_AsUnicode(_PyObject_CAST(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalartypes.c.src:476:11: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
len = PyUnicode_GET_SIZE(self);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:261:7: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op) : \
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalartypes.c.src:476:11: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
len = PyUnicode_GET_SIZE(self);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:262:14: note: expanded from macro 'PyUnicode_GET_SIZE'
((void)PyUnicode_AsUnicode(_PyObject_CAST(op)),\
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalartypes.c.src:476:11: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
len = PyUnicode_GET_SIZE(self);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:264:8: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalartypes.c.src:481:11: warning: 'PyUnicode_FromUnicode' is deprecated [-Wdeprecated-declarations]
new = PyUnicode_FromUnicode(ip, len);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:551:1: note: 'PyUnicode_FromUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(PyObject*) PyUnicode_FromUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalartypes.c.src:475:17: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
ip = dptr = PyUnicode_AS_UNICODE(self);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:279:7: note: expanded from macro 'PyUnicode_AS_UNICODE'
PyUnicode_AsUnicode(_PyObject_CAST(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalartypes.c.src:476:11: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
len = PyUnicode_GET_SIZE(self);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:261:7: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op) : \
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalartypes.c.src:476:11: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
len = PyUnicode_GET_SIZE(self);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:262:14: note: expanded from macro 'PyUnicode_GET_SIZE'
((void)PyUnicode_AsUnicode(_PyObject_CAST(op)),\
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalartypes.c.src:476:11: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
len = PyUnicode_GET_SIZE(self);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:264:8: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalartypes.c.src:481:11: warning: 'PyUnicode_FromUnicode' is deprecated [-Wdeprecated-declarations]
new = PyUnicode_FromUnicode(ip, len);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:551:1: note: 'PyUnicode_FromUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(PyObject*) PyUnicode_FromUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalartypes.c.src:1849:18: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
buffer = PyUnicode_AS_DATA(self);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:283:21: note: expanded from macro 'PyUnicode_AS_DATA'
((const char *)(PyUnicode_AS_UNICODE(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:279:7: note: expanded from macro 'PyUnicode_AS_UNICODE'
PyUnicode_AsUnicode(_PyObject_CAST(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalartypes.c.src:1850:18: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
buflen = PyUnicode_GET_DATA_SIZE(self);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:261:7: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op) : \
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalartypes.c.src:1850:18: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
buflen = PyUnicode_GET_DATA_SIZE(self);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:262:14: note: expanded from macro 'PyUnicode_GET_SIZE'
((void)PyUnicode_AsUnicode(_PyObject_CAST(op)),\
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/scalartypes.c.src:1850:18: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
buflen = PyUnicode_GET_DATA_SIZE(self);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:268:6: note: expanded from macro 'PyUnicode_GET_DATA_SIZE'
(PyUnicode_GET_SIZE(op) * Py_UNICODE_SIZE)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:264:8: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
5 warnings generated.
clang: numpy/core/src/multiarray/typeinfo.c
clang: numpy/core/src/multiarray/refcount.c
clang: numpy/core/src/multiarray/usertypes.c
clang: numpy/core/src/multiarray/multiarraymodule.c
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/lowlevel_strided_loops.c
clang: numpy/core/src/multiarray/vdot.c
clang: numpy/core/src/umath/umathmodule.c
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/matmul.c
clang: numpy/core/src/umath/reduction.c
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/loops.c
clang: numpy/core/src/multiarray/nditer_api.c
14 warnings generated.
clang: numpy/core/src/multiarray/strfuncs.c
numpy/core/src/umath/loops.c.src:655:18: warning: 'PyEval_CallObjectWithKeywords' is deprecated [-Wdeprecated-declarations]
result = PyEval_CallObject(tocall, arglist);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/ceval.h:24:5: note: expanded from macro 'PyEval_CallObject'
PyEval_CallObjectWithKeywords(callable, arg, (PyObject *)NULL)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/ceval.h:17:1: note: 'PyEval_CallObjectWithKeywords' has been explicitly marked deprecated here
Py_DEPRECATED(3.9) PyAPI_FUNC(PyObject *) PyEval_CallObjectWithKeywords(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/strfuncs.c:178:13: warning: 'PyEval_CallObjectWithKeywords' is deprecated [-Wdeprecated-declarations]
s = PyEval_CallObject(PyArray_ReprFunction, arglist);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/ceval.h:24:5: note: expanded from macro 'PyEval_CallObject'
PyEval_CallObjectWithKeywords(callable, arg, (PyObject *)NULL)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/ceval.h:17:1: note: 'PyEval_CallObjectWithKeywords' has been explicitly marked deprecated here
Py_DEPRECATED(3.9) PyAPI_FUNC(PyObject *) PyEval_CallObjectWithKeywords(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/core/src/multiarray/strfuncs.c:195:13: warning: 'PyEval_CallObjectWithKeywords' is deprecated [-Wdeprecated-declarations]
s = PyEval_CallObject(PyArray_StrFunction, arglist);
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/ceval.h:24:5: note: expanded from macro 'PyEval_CallObject'
PyEval_CallObjectWithKeywords(callable, arg, (PyObject *)NULL)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/ceval.h:17:1: note: 'PyEval_CallObjectWithKeywords' has been explicitly marked deprecated here
Py_DEPRECATED(3.9) PyAPI_FUNC(PyObject *) PyEval_CallObjectWithKeywords(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
2 warnings generated.
clang: numpy/core/src/multiarray/temp_elide.c
clang: numpy/core/src/umath/cpuid.c
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/scalarmath.c
clang: numpy/core/src/umath/ufunc_object.c
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'byte_long' [-Wunused-function]
byte_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'ubyte_long' [-Wunused-function]
ubyte_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'short_long' [-Wunused-function]
short_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'ushort_long' [-Wunused-function]
ushort_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'int_long' [-Wunused-function]
int_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'uint_long' [-Wunused-function]
uint_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'long_long' [-Wunused-function]
long_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'ulong_long' [-Wunused-function]
ulong_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'longlong_long' [-Wunused-function]
longlong_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'ulonglong_long' [-Wunused-function]
ulonglong_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'half_long' [-Wunused-function]
half_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'float_long' [-Wunused-function]
float_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'double_long' [-Wunused-function]
double_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'longdouble_long' [-Wunused-function]
longdouble_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'cfloat_long' [-Wunused-function]
cfloat_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'cdouble_long' [-Wunused-function]
cdouble_long(PyObject *obj)
^
numpy/core/src/umath/scalarmath.c.src:1449:1: warning: unused function 'clongdouble_long' [-Wunused-function]
clongdouble_long(PyObject *obj)
^
clang: numpy/core/src/multiarray/nditer_constr.c
numpy/core/src/umath/ufunc_object.c:657:19: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
for (i = 0; i < len; i++) {
~ ^ ~~~
clang: numpy/core/src/umath/override.c
clang: numpy/core/src/npymath/npy_math.c
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath/ieee754.c
numpy/core/src/umath/loops.c.src:2527:22: warning: code will never be executed [-Wunreachable-code]
npy_intp n = dimensions[0];
^~~~~~~~~~
numpy/core/src/umath/loops.c.src:2526:29: note: silence by adding parentheses to mark code as explicitly dead
if (IS_BINARY_REDUCE && 0) {
^
/* DISABLES CODE */ ( )
numpy/core/src/umath/loops.c.src:2527:22: warning: code will never be executed [-Wunreachable-code]
npy_intp n = dimensions[0];
^~~~~~~~~~
numpy/core/src/umath/loops.c.src:2526:29: note: silence by adding parentheses to mark code as explicitly dead
if (IS_BINARY_REDUCE && 0) {
^
/* DISABLES CODE */ ( )
numpy/core/src/umath/loops.c.src:2527:22: warning: code will never be executed [-Wunreachable-code]
npy_intp n = dimensions[0];
^~~~~~~~~~
numpy/core/src/umath/loops.c.src:2526:29: note: silence by adding parentheses to mark code as explicitly dead
if (IS_BINARY_REDUCE && 0) {
^
/* DISABLES CODE */ ( )
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath/npy_math_complex.c
numpy/core/src/npymath/npy_math_complex.c.src:48:33: warning: unused variable 'tiny' [-Wunused-const-variable]
static const volatile npy_float tiny = 3.9443045e-31f;
^
numpy/core/src/npymath/npy_math_complex.c.src:67:25: warning: unused variable 'c_halff' [-Wunused-const-variable]
static const npy_cfloat c_halff = {0.5F, 0.0};
^
numpy/core/src/npymath/npy_math_complex.c.src:68:25: warning: unused variable 'c_if' [-Wunused-const-variable]
static const npy_cfloat c_if = {0.0, 1.0F};
^
numpy/core/src/npymath/npy_math_complex.c.src:69:25: warning: unused variable 'c_ihalff' [-Wunused-const-variable]
static const npy_cfloat c_ihalff = {0.0, 0.5F};
^
numpy/core/src/npymath/npy_math_complex.c.src:79:1: warning: unused function 'caddf' [-Wunused-function]
caddf(npy_cfloat a, npy_cfloat b)
^
numpy/core/src/npymath/npy_math_complex.c.src:87:1: warning: unused function 'csubf' [-Wunused-function]
csubf(npy_cfloat a, npy_cfloat b)
^
numpy/core/src/npymath/npy_math_complex.c.src:137:1: warning: unused function 'cnegf' [-Wunused-function]
cnegf(npy_cfloat a)
^
numpy/core/src/npymath/npy_math_complex.c.src:144:1: warning: unused function 'cmulif' [-Wunused-function]
cmulif(npy_cfloat a)
^
numpy/core/src/npymath/npy_math_complex.c.src:67:26: warning: unused variable 'c_half' [-Wunused-const-variable]
static const npy_cdouble c_half = {0.5, 0.0};
^
numpy/core/src/npymath/npy_math_complex.c.src:68:26: warning: unused variable 'c_i' [-Wunused-const-variable]
static const npy_cdouble c_i = {0.0, 1.0};
^
numpy/core/src/npymath/npy_math_complex.c.src:69:26: warning: unused variable 'c_ihalf' [-Wunused-const-variable]
static const npy_cdouble c_ihalf = {0.0, 0.5};
^
numpy/core/src/npymath/npy_math_complex.c.src:79:1: warning: unused function 'cadd' [-Wunused-function]
cadd(npy_cdouble a, npy_cdouble b)
^
numpy/core/src/npymath/npy_math_complex.c.src:87:1: warning: unused function 'csub' [-Wunused-function]
csub(npy_cdouble a, npy_cdouble b)
^
numpy/core/src/npymath/npy_math_complex.c.src:137:1: warning: unused function 'cneg' [-Wunused-function]
cneg(npy_cdouble a)
^
numpy/core/src/npymath/npy_math_complex.c.src:144:1: warning: unused function 'cmuli' [-Wunused-function]
cmuli(npy_cdouble a)
^
numpy/core/src/npymath/npy_math_complex.c.src:67:30: warning: unused variable 'c_halfl' [-Wunused-const-variable]
static const npy_clongdouble c_halfl = {0.5L, 0.0};
^
numpy/core/src/npymath/npy_math_complex.c.src:68:30: warning: unused variable 'c_il' [-Wunused-const-variable]
static const npy_clongdouble c_il = {0.0, 1.0L};
^
numpy/core/src/npymath/npy_math_complex.c.src:69:30: warning: unused variable 'c_ihalfl' [-Wunused-const-variable]
static const npy_clongdouble c_ihalfl = {0.0, 0.5L};
^
numpy/core/src/npymath/npy_math_complex.c.src:79:1: warning: unused function 'caddl' [-Wunused-function]
caddl(npy_clongdouble a, npy_clongdouble b)
^
numpy/core/src/npymath/npy_math_complex.c.src:87:1: warning: unused function 'csubl' [-Wunused-function]
csubl(npy_clongdouble a, npy_clongdouble b)
^
numpy/core/src/npymath/npy_math_complex.c.src:137:1: warning: unused function 'cnegl' [-Wunused-function]
cnegl(npy_clongdouble a)
^
numpy/core/src/npymath/npy_math_complex.c.src:144:1: warning: unused function 'cmulil' [-Wunused-function]
cmulil(npy_clongdouble a)
^
22 warnings generated.
clang: numpy/core/src/common/mem_overlap.c
clang: numpy/core/src/npymath/halffloat.c
clang: numpy/core/src/common/array_assign.c
clang: numpy/core/src/common/ufunc_override.c
clang: numpy/core/src/common/npy_longdouble.c
clang: numpy/core/src/common/numpyos.c
clang: numpy/core/src/common/ucsnarrow.c
1 warning generated.
clang: numpy/core/src/umath/extobj.c
numpy/core/src/common/ucsnarrow.c:139:34: warning: 'PyUnicode_FromUnicode' is deprecated [-Wdeprecated-declarations]
ret = (PyUnicodeObject *)PyUnicode_FromUnicode((Py_UNICODE*)buf,
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:551:1: note: 'PyUnicode_FromUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(PyObject*) PyUnicode_FromUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
1 warning generated.
clang: numpy/core/src/common/python_xerbla.c
clang: numpy/core/src/common/cblasfuncs.c
clang: /private/var/folders/fz/0j719tys48x7jlnjnwc69smr0000gn/T/pip-install-ufzck51l/numpy_b0e8a3953a1d4b46801f12bcea55536e/numpy/_build_utils/src/apple_sgemv_fix.c
In file included from /private/var/folders/fz/0j719tys48x7jlnjnwc69smr0000gn/T/pip-install-ufzck51l/numpy_b0e8a3953a1d4b46801f12bcea55536e/numpy/_build_utils/src/apple_sgemv_fix.c:26:
In file included from numpy/core/include/numpy/arrayobject.h:4:
In file included from numpy/core/include/numpy/ndarrayobject.h:21:
build/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy/__multiarray_api.h:1463:1: warning: unused function '_import_array' [-Wunused-function]
_import_array(void)
^
1 warning generated.
17 warnings generated.
clang: numpy/core/src/umath/ufunc_type_resolution.c
4 warnings generated.
4 warnings generated.
clang -bundle -undefined dynamic_lookup -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/alloc.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/arrayobject.o build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/arraytypes.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/array_assign_scalar.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/array_assign_array.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/buffer.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/calculation.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/compiled_base.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/common.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/convert.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/convert_datatype.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/conversion_utils.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/ctors.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/datetime.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/datetime_strings.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/datetime_busday.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/datetime_busdaycal.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/descriptor.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/dragon4.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/dtype_transfer.o build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/einsum.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/flagsobject.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/getset.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/hashdescr.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/item_selection.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/iterators.o build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/lowlevel_strided_loops.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/mapping.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/methods.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/multiarraymodule.o build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/nditer_templ.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/nditer_api.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/nditer_constr.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/nditer_pywrap.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/number.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/refcount.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/sequence.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/shape.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/scalarapi.o build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/scalartypes.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/strfuncs.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/temp_elide.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/typeinfo.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/usertypes.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/multiarray/vdot.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/umath/umathmodule.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/umath/reduction.o build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/loops.o build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/matmul.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/umath/ufunc_object.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/umath/extobj.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/umath/cpuid.o build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/scalarmath.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/umath/ufunc_type_resolution.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/umath/override.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/npymath/npy_math.o build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath/ieee754.o build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath/npy_math_complex.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/npymath/halffloat.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/common/array_assign.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/common/mem_overlap.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/common/npy_longdouble.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/common/ucsnarrow.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/common/ufunc_override.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/common/numpyos.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/common/cblasfuncs.o build/temp.macosx-10.15-x86_64-3.9/numpy/core/src/common/python_xerbla.o build/temp.macosx-10.15-x86_64-3.9/private/var/folders/fz/0j719tys48x7jlnjnwc69smr0000gn/T/pip-install-ufzck51l/numpy_b0e8a3953a1d4b46801f12bcea55536e/numpy/_build_utils/src/apple_sgemv_fix.o -L/usr/local/lib -L/usr/local/opt/[email protected]/lib -L/usr/local/opt/sqlite/lib -Lbuild/temp.macosx-10.15-x86_64-3.9 -lnpymath -lnpysort -o build/lib.macosx-10.15-x86_64-3.9/numpy/core/_multiarray_umath.cpython-39-darwin.so -Wl,-framework -Wl,Accelerate
building 'numpy.core._umath_tests' extension
compiling C sources
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-DNPY_INTERNAL_BUILD=1 -DHAVE_NPY_CONFIG_H=1 -D_FILE_OFFSET_BITS=64 -D_LARGEFILE_SOURCE=1 -D_LARGEFILE64_SOURCE=1 -Inumpy/core/include -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy -Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -c'
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/_umath_tests.c
clang -bundle -undefined dynamic_lookup -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/_umath_tests.o -L/usr/local/lib -L/usr/local/opt/[email protected]/lib -L/usr/local/opt/sqlite/lib -Lbuild/temp.macosx-10.15-x86_64-3.9 -o build/lib.macosx-10.15-x86_64-3.9/numpy/core/_umath_tests.cpython-39-darwin.so
building 'numpy.core._rational_tests' extension
compiling C sources
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-DNPY_INTERNAL_BUILD=1 -DHAVE_NPY_CONFIG_H=1 -D_FILE_OFFSET_BITS=64 -D_LARGEFILE_SOURCE=1 -D_LARGEFILE64_SOURCE=1 -Inumpy/core/include -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy -Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -c'
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/_rational_tests.c
clang -bundle -undefined dynamic_lookup -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/_rational_tests.o -L/usr/local/lib -L/usr/local/opt/[email protected]/lib -L/usr/local/opt/sqlite/lib -Lbuild/temp.macosx-10.15-x86_64-3.9 -o build/lib.macosx-10.15-x86_64-3.9/numpy/core/_rational_tests.cpython-39-darwin.so
building 'numpy.core._struct_ufunc_tests' extension
compiling C sources
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-DNPY_INTERNAL_BUILD=1 -DHAVE_NPY_CONFIG_H=1 -D_FILE_OFFSET_BITS=64 -D_LARGEFILE_SOURCE=1 -D_LARGEFILE64_SOURCE=1 -Inumpy/core/include -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy -Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -c'
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/_struct_ufunc_tests.c
clang -bundle -undefined dynamic_lookup -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/_struct_ufunc_tests.o -L/usr/local/lib -L/usr/local/opt/[email protected]/lib -L/usr/local/opt/sqlite/lib -Lbuild/temp.macosx-10.15-x86_64-3.9 -o build/lib.macosx-10.15-x86_64-3.9/numpy/core/_struct_ufunc_tests.cpython-39-darwin.so
building 'numpy.core._operand_flag_tests' extension
compiling C sources
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
compile options: '-DNPY_INTERNAL_BUILD=1 -DHAVE_NPY_CONFIG_H=1 -D_FILE_OFFSET_BITS=64 -D_LARGEFILE_SOURCE=1 -D_LARGEFILE64_SOURCE=1 -Inumpy/core/include -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy -Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -c'
clang: build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/_operand_flag_tests.c
clang -bundle -undefined dynamic_lookup -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/core/src/umath/_operand_flag_tests.o -L/usr/local/lib -L/usr/local/opt/[email protected]/lib -L/usr/local/opt/sqlite/lib -Lbuild/temp.macosx-10.15-x86_64-3.9 -o build/lib.macosx-10.15-x86_64-3.9/numpy/core/_operand_flag_tests.cpython-39-darwin.so
building 'numpy.fft.fftpack_lite' extension
compiling C sources
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
creating build/temp.macosx-10.15-x86_64-3.9/numpy/fft
compile options: '-Inumpy/core/include -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy -Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -c'
clang: numpy/fft/fftpack_litemodule.c
clang: numpy/fft/fftpack.c
clang -bundle -undefined dynamic_lookup -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk build/temp.macosx-10.15-x86_64-3.9/numpy/fft/fftpack_litemodule.o build/temp.macosx-10.15-x86_64-3.9/numpy/fft/fftpack.o -L/usr/local/lib -L/usr/local/opt/[email protected]/lib -L/usr/local/opt/sqlite/lib -Lbuild/temp.macosx-10.15-x86_64-3.9 -o build/lib.macosx-10.15-x86_64-3.9/numpy/fft/fftpack_lite.cpython-39-darwin.so
building 'numpy.linalg.lapack_lite' extension
compiling C sources
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
creating build/temp.macosx-10.15-x86_64-3.9/numpy/linalg
creating build/temp.macosx-10.15-x86_64-3.9/numpy/linalg/lapack_lite
compile options: '-DNO_ATLAS_INFO=3 -DHAVE_CBLAS -Inumpy/core/include -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy -Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -c'
extra options: '-msse3 -I/System/Library/Frameworks/vecLib.framework/Headers'
clang: numpy/linalg/lapack_litemodule.c
clang: numpy/linalg/lapack_lite/python_xerbla.c
clang -bundle -undefined dynamic_lookup -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk build/temp.macosx-10.15-x86_64-3.9/numpy/linalg/lapack_litemodule.o build/temp.macosx-10.15-x86_64-3.9/numpy/linalg/lapack_lite/python_xerbla.o -L/usr/local/lib -L/usr/local/opt/[email protected]/lib -L/usr/local/opt/sqlite/lib -Lbuild/temp.macosx-10.15-x86_64-3.9 -o build/lib.macosx-10.15-x86_64-3.9/numpy/linalg/lapack_lite.cpython-39-darwin.so -Wl,-framework -Wl,Accelerate
building 'numpy.linalg._umath_linalg' extension
compiling C sources
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
creating build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/linalg
compile options: '-DNO_ATLAS_INFO=3 -DHAVE_CBLAS -Inumpy/core/include -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy -Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -c'
extra options: '-msse3 -I/System/Library/Frameworks/vecLib.framework/Headers'
clang: build/src.macosx-10.15-x86_64-3.9/numpy/linalg/umath_linalg.c
numpy/linalg/umath_linalg.c.src:735:32: warning: unknown warning group '-Wmaybe-uninitialized', ignored [-Wunknown-warning-option]
#pragma GCC diagnostic ignored "-Wmaybe-uninitialized"
^
numpy/linalg/umath_linalg.c.src:541:1: warning: unused function 'dump_ufunc_object' [-Wunused-function]
dump_ufunc_object(PyUFuncObject* ufunc)
^
numpy/linalg/umath_linalg.c.src:566:1: warning: unused function 'dump_linearize_data' [-Wunused-function]
dump_linearize_data(const char* name, const LINEARIZE_DATA_t* params)
^
numpy/linalg/umath_linalg.c.src:602:1: warning: unused function 'dump_FLOAT_matrix' [-Wunused-function]
dump_FLOAT_matrix(const char* name,
^
numpy/linalg/umath_linalg.c.src:602:1: warning: unused function 'dump_DOUBLE_matrix' [-Wunused-function]
dump_DOUBLE_matrix(const char* name,
^
numpy/linalg/umath_linalg.c.src:602:1: warning: unused function 'dump_CFLOAT_matrix' [-Wunused-function]
dump_CFLOAT_matrix(const char* name,
^
numpy/linalg/umath_linalg.c.src:602:1: warning: unused function 'dump_CDOUBLE_matrix' [-Wunused-function]
dump_CDOUBLE_matrix(const char* name,
^
numpy/linalg/umath_linalg.c.src:865:1: warning: unused function 'zero_FLOAT_matrix' [-Wunused-function]
zero_FLOAT_matrix(void *dst_in, const LINEARIZE_DATA_t* data)
^
numpy/linalg/umath_linalg.c.src:865:1: warning: unused function 'zero_DOUBLE_matrix' [-Wunused-function]
zero_DOUBLE_matrix(void *dst_in, const LINEARIZE_DATA_t* data)
^
numpy/linalg/umath_linalg.c.src:865:1: warning: unused function 'zero_CFLOAT_matrix' [-Wunused-function]
zero_CFLOAT_matrix(void *dst_in, const LINEARIZE_DATA_t* data)
^
numpy/linalg/umath_linalg.c.src:865:1: warning: unused function 'zero_CDOUBLE_matrix' [-Wunused-function]
zero_CDOUBLE_matrix(void *dst_in, const LINEARIZE_DATA_t* data)
^
numpy/linalg/umath_linalg.c.src:1862:1: warning: unused function 'dump_geev_params' [-Wunused-function]
dump_geev_params(const char *name, GEEV_PARAMS_t* params)
^
numpy/linalg/umath_linalg.c.src:2132:1: warning: unused function 'init_cgeev' [-Wunused-function]
init_cgeev(GEEV_PARAMS_t* params,
^
numpy/linalg/umath_linalg.c.src:2213:1: warning: unused function 'process_cgeev_results' [-Wunused-function]
process_cgeev_results(GEEV_PARAMS_t *NPY_UNUSED(params))
^
numpy/linalg/umath_linalg.c.src:2376:1: warning: unused function 'dump_gesdd_params' [-Wunused-function]
dump_gesdd_params(const char *name,
^
numpy/linalg/umath_linalg.c.src:2864:1: warning: unused function 'dump_gelsd_params' [-Wunused-function]
dump_gelsd_params(const char *name,
^
16 warnings generated.
clang -bundle -undefined dynamic_lookup -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk build/temp.macosx-10.15-x86_64-3.9/build/src.macosx-10.15-x86_64-3.9/numpy/linalg/umath_linalg.o build/temp.macosx-10.15-x86_64-3.9/numpy/linalg/lapack_lite/python_xerbla.o -L/usr/local/lib -L/usr/local/opt/[email protected]/lib -L/usr/local/opt/sqlite/lib -Lbuild/temp.macosx-10.15-x86_64-3.9 -lnpymath -o build/lib.macosx-10.15-x86_64-3.9/numpy/linalg/_umath_linalg.cpython-39-darwin.so -Wl,-framework -Wl,Accelerate
building 'numpy.random.mtrand' extension
compiling C sources
C compiler: clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers
creating build/temp.macosx-10.15-x86_64-3.9/numpy/random
creating build/temp.macosx-10.15-x86_64-3.9/numpy/random/mtrand
compile options: '-D_FILE_OFFSET_BITS=64 -D_LARGEFILE_SOURCE=1 -D_LARGEFILE64_SOURCE=1 -Inumpy/core/include -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy -Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -c'
clang: numpy/random/mtrand/mtrand.c
clang: numpy/random/mtrand/initarray.cclang: numpy/random/mtrand/randomkit.c
clang: numpy/random/mtrand/distributions.c
numpy/random/mtrand/mtrand.c:40400:34: error: no member named 'tp_print' in 'struct _typeobject'
__pyx_type_6mtrand_RandomState.tp_print = 0;
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ ^
numpy/random/mtrand/mtrand.c:42673:22: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
(PyUnicode_GET_SIZE(**name) != PyUnicode_GET_SIZE(key)) ? 1 :
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:261:7: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op) : \
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/random/mtrand/mtrand.c:42673:22: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
(PyUnicode_GET_SIZE(**name) != PyUnicode_GET_SIZE(key)) ? 1 :
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:262:14: note: expanded from macro 'PyUnicode_GET_SIZE'
((void)PyUnicode_AsUnicode(_PyObject_CAST(op)),\
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/random/mtrand/mtrand.c:42673:22: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
(PyUnicode_GET_SIZE(**name) != PyUnicode_GET_SIZE(key)) ? 1 :
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:264:8: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/random/mtrand/mtrand.c:42673:52: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
(PyUnicode_GET_SIZE(**name) != PyUnicode_GET_SIZE(key)) ? 1 :
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:261:7: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op) : \
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/random/mtrand/mtrand.c:42673:52: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
(PyUnicode_GET_SIZE(**name) != PyUnicode_GET_SIZE(key)) ? 1 :
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:262:14: note: expanded from macro 'PyUnicode_GET_SIZE'
((void)PyUnicode_AsUnicode(_PyObject_CAST(op)),\
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/random/mtrand/mtrand.c:42673:52: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
(PyUnicode_GET_SIZE(**name) != PyUnicode_GET_SIZE(key)) ? 1 :
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:264:8: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/random/mtrand/mtrand.c:42689:26: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
(PyUnicode_GET_SIZE(**argname) != PyUnicode_GET_SIZE(key)) ? 1 :
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:261:7: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op) : \
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/random/mtrand/mtrand.c:42689:26: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
(PyUnicode_GET_SIZE(**argname) != PyUnicode_GET_SIZE(key)) ? 1 :
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:262:14: note: expanded from macro 'PyUnicode_GET_SIZE'
((void)PyUnicode_AsUnicode(_PyObject_CAST(op)),\
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/random/mtrand/mtrand.c:42689:26: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
(PyUnicode_GET_SIZE(**argname) != PyUnicode_GET_SIZE(key)) ? 1 :
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:264:8: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/random/mtrand/mtrand.c:42689:59: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
(PyUnicode_GET_SIZE(**argname) != PyUnicode_GET_SIZE(key)) ? 1 :
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:261:7: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op) : \
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/random/mtrand/mtrand.c:42689:59: warning: 'PyUnicode_AsUnicode' is deprecated [-Wdeprecated-declarations]
(PyUnicode_GET_SIZE(**argname) != PyUnicode_GET_SIZE(key)) ? 1 :
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:262:14: note: expanded from macro 'PyUnicode_GET_SIZE'
((void)PyUnicode_AsUnicode(_PyObject_CAST(op)),\
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:580:1: note: 'PyUnicode_AsUnicode' has been explicitly marked deprecated here
Py_DEPRECATED(3.3) PyAPI_FUNC(Py_UNICODE *) PyUnicode_AsUnicode(
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
numpy/random/mtrand/mtrand.c:42689:59: warning: '_PyUnicode_get_wstr_length' is deprecated [-Wdeprecated-declarations]
(PyUnicode_GET_SIZE(**argname) != PyUnicode_GET_SIZE(key)) ? 1 :
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:264:8: note: expanded from macro 'PyUnicode_GET_SIZE'
PyUnicode_WSTR_LENGTH(op)))
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:451:35: note: expanded from macro 'PyUnicode_WSTR_LENGTH'
#define PyUnicode_WSTR_LENGTH(op) _PyUnicode_get_wstr_length((PyObject*)op)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/cpython/unicodeobject.h:445:1: note: '_PyUnicode_get_wstr_length' has been explicitly marked deprecated here
Py_DEPRECATED(3.3)
^
/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9/pyport.h:508:54: note: expanded from macro 'Py_DEPRECATED'
#define Py_DEPRECATED(VERSION_UNUSED) __attribute__((__deprecated__))
^
12 warnings and 1 error generated.
error: Command "clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/usr/include -I/Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers -D_FILE_OFFSET_BITS=64 -D_LARGEFILE_SOURCE=1 -D_LARGEFILE64_SOURCE=1 -Inumpy/core/include -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/include/numpy -Inumpy/core/src/common -Inumpy/core/src -Inumpy/core -Inumpy/core/src/npymath -Inumpy/core/src/multiarray -Inumpy/core/src/umath -Inumpy/core/src/npysort -I/usr/local/include -I/usr/local/opt/[email protected]/include -I/usr/local/opt/sqlite/include -I/Users/destiny/Downloads/env/include -I/usr/local/Cellar/[email protected]/3.9.0_1/Frameworks/Python.framework/Versions/3.9/include/python3.9 -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/common -Ibuild/src.macosx-10.15-x86_64-3.9/numpy/core/src/npymath -c numpy/random/mtrand/mtrand.c -o build/temp.macosx-10.15-x86_64-3.9/numpy/random/mtrand/mtrand.o -MMD -MF build/temp.macosx-10.15-x86_64-3.9/numpy/random/mtrand/mtrand.o.d" failed with exit status 1 | 1,696 |
https://github.com/huggingface/datasets/issues/1687 | Question: Shouldn't .info be a part of DatasetDict? | [
"We could do something. There is a part of `.info` which is split specific (cache files, split instructions) but maybe if could be made to work.",
"Yes this was kinda the idea I was going for. DatasetDict.info would be the shared info amongs the datasets (maybe even some info on how they differ). "
] | Currently, only `Dataset` contains the .info or .features, but as many datasets contains standard splits (train, test) and thus the underlying information is the same (or at least should be) across the datasets.
For instance:
```
>>> ds = datasets.load_dataset("conll2002", "es")
>>> ds.info
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'DatasetDict' object has no attribute 'info'
```
I could imagine that this wouldn't work for datasets dicts which hold entirely different datasets (multimodal datasets), but it seems odd that splits of the same dataset is treated the same as what is essentially different datasets.
Intuitively it would also make sense that if a dataset is supplied via. the load_dataset that is have a common .info which covers the entire dataset.
It is entirely possible that I am missing another perspective | 1,687 |
https://github.com/huggingface/datasets/issues/1686 | Dataset Error: DaNE contains empty samples at the end | [
"Thanks for reporting, I opened a PR to fix that",
"One the PR is merged the fix will be available in the next release of `datasets`.\r\n\r\nIf you don't want to wait the next release you can still load the script from the master branch with\r\n\r\n```python\r\nload_dataset(\"dane\", script_version=\"master\")\r\n```",
"If you have other questions feel free to reopen :) "
] | The dataset DaNE, contains empty samples at the end. It is naturally easy to remove using a filter but should probably not be there, to begin with as it can cause errors.
```python
>>> import datasets
[...]
>>> dataset = datasets.load_dataset("dane")
[...]
>>> dataset["test"][-1]
{'dep_ids': [], 'dep_labels': [], 'lemmas': [], 'morph_tags': [], 'ner_tags': [], 'pos_tags': [], 'sent_id': '', 'text': '', 'tok_ids': [], 'tokens': []}
>>> dataset["train"][-1]
{'dep_ids': [], 'dep_labels': [], 'lemmas': [], 'morph_tags': [], 'ner_tags': [], 'pos_tags': [], 'sent_id': '', 'text': '', 'tok_ids': [], 'tokens': []}
```
Best,
Kenneth | 1,686 |
https://github.com/huggingface/datasets/issues/1683 | `ArrowInvalid` occurs while running `Dataset.map()` function for DPRContext | [
"Looks like the mapping function returns a dictionary with a 768-dim array in the `embeddings` field. Since the map is batched, we actually expect the `embeddings` field to be an array of shape (batch_size, 768) to have one embedding per example in the batch.\r\n\r\nTo fix that can you try to remove one of the `[0]` ? In my opinion you only need one of them, not two.",
"It makes sense :D\r\n\r\nIt seems to work! Thanks a lot :))\r\n\r\nClosing the issue"
] | It seems to fail the final batch ):
steps to reproduce:
```
from datasets import load_dataset
from elasticsearch import Elasticsearch
import torch
from transformers import file_utils, set_seed
from transformers import DPRContextEncoder, DPRContextEncoderTokenizerFast
MAX_SEQ_LENGTH = 256
ctx_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base", cache_dir="../datasets/")
ctx_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(
"facebook/dpr-ctx_encoder-single-nq-base",
cache_dir="..datasets/"
)
dataset = load_dataset('text',
data_files='data/raw/ARC_Corpus.txt',
cache_dir='../datasets')
torch.set_grad_enabled(False)
ds_with_embeddings = dataset.map(
lambda example: {
'embeddings': ctx_encoder(
**ctx_tokenizer(
example["text"],
padding='max_length',
truncation=True,
max_length=MAX_SEQ_LENGTH,
return_tensors="pt"
)
)[0][0].numpy(),
},
batched=True,
load_from_cache_file=False,
batch_size=1000
)
```
ARC Corpus can be obtained from [here](https://ai2-datasets.s3-us-west-2.amazonaws.com/arc/ARC-V1-Feb2018.zip)
And then the error:
```
---------------------------------------------------------------------------
ArrowInvalid Traceback (most recent call last)
<ipython-input-13-67d139bb2ed3> in <module>
14 batched=True,
15 load_from_cache_file=False,
---> 16 batch_size=1000
17 )
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/dataset_dict.py in map(self, function, with_indices, input_columns, batched, batch_size, remove_columns, keep_in_memory, load_from_cache_file, cache_file_names, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc)
301 num_proc=num_proc,
302 )
--> 303 for k, dataset in self.items()
304 }
305 )
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/dataset_dict.py in <dictcomp>(.0)
301 num_proc=num_proc,
302 )
--> 303 for k, dataset in self.items()
304 }
305 )
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/arrow_dataset.py in map(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint)
1257 fn_kwargs=fn_kwargs,
1258 new_fingerprint=new_fingerprint,
-> 1259 update_data=update_data,
1260 )
1261 else:
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
155 }
156 # apply actual function
--> 157 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
158 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
159 # re-apply format to the output
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
161 # Call actual function
162
--> 163 out = func(self, *args, **kwargs)
164
165 # Update fingerprint of in-place transforms + update in-place history of transforms
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/arrow_dataset.py in _map_single(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, new_fingerprint, rank, offset, update_data)
1526 if update_data:
1527 batch = cast_to_python_objects(batch)
-> 1528 writer.write_batch(batch)
1529 if update_data:
1530 writer.finalize() # close_stream=bool(buf_writer is None)) # We only close if we are writing in a file
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/arrow_writer.py in write_batch(self, batch_examples, writer_batch_size)
276 typed_sequence = TypedSequence(batch_examples[col], type=col_type, try_type=col_try_type)
277 typed_sequence_examples[col] = typed_sequence
--> 278 pa_table = pa.Table.from_pydict(typed_sequence_examples)
279 self.write_table(pa_table)
280
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.from_pydict()
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.from_arrays()
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.validate()
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowInvalid: Column 1 named text expected length 768 but got length 1000
``` | 1,683 |
https://github.com/huggingface/datasets/issues/1681 | Dataset "dane" missing | [
"Hi @KennethEnevoldsen ,\r\nI think the issue might be that this dataset was added during the community sprint and has not been released yet. It will be available with the v2 of datasets.\r\nFor now, you should be able to load the datasets after installing the latest (master) version of datasets using pip:\r\npip install git+https://github.com/huggingface/datasets.git@master",
"The `dane` dataset was added recently, that's why it wasn't available yet. We did an intermediate release today just before the v2.0.\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `dane` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"dane\")\r\n```",
"Thanks. Solved the problem."
] | the `dane` dataset appear to be missing in the latest version (1.1.3).
```python
>>> import datasets
>>> datasets.__version__
'1.1.3'
>>> "dane" in datasets.list_datasets()
True
```
As we can see it should be present, but doesn't seem to be findable when using `load_dataset`.
```python
>>> datasets.load_dataset("dane")
Traceback (most recent call last):
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 300, in cached_path
output_path = get_from_cache(
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/dane/dane.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/load.py", line 278, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 300, in cached_path
output_path = get_from_cache(
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/dane/dane.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/load.py", line 588, in load_dataset
module_path, hash = prepare_module(
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/load.py", line 280, in prepare_module
raise FileNotFoundError(
FileNotFoundError: Couldn't find file locally at dane/dane.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/dane/dane.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/dane/dane.py
```
This issue might be relevant to @ophelielacroix from the Alexandra Institut whom created the data. | 1,681 |
https://github.com/huggingface/datasets/issues/1679 | Can't import cc100 dataset | [
"cc100 was added recently, that's why it wasn't available yet.\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `cc100` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nlang = \"en\"\r\ndataset = load_dataset(\"cc100\", lang=lang, split=\"train\")\r\n```"
] | There is some issue to import cc100 dataset.
```
from datasets import load_dataset
dataset = load_dataset("cc100")
```
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/cc100/cc100.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/cc100/cc100.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/datasets/load.py in prepare_module(path, script_version, download_config, download_mode, dataset, force_local_path, **download_kwargs)
280 raise FileNotFoundError(
281 "Couldn't find file locally at {}, or remotely at {} or {}".format(
--> 282 combined_path, github_file_path, file_path
283 )
284 )
FileNotFoundError: Couldn't find file locally at cc100/cc100.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/cc100/cc100.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/cc100/cc100.py | 1,679 |
https://github.com/huggingface/datasets/issues/1675 | Add the 800GB Pile dataset? | [
"The pile dataset would be very nice.\r\nBenchmarks show that pile trained models achieve better results than most of actually trained models",
"The pile can very easily be added and adapted using this [tfds implementation](https://github.com/EleutherAI/The-Pile/blob/master/the_pile/tfds_pile.py) from the repo. \r\n\r\nHowever, the question is whether you'd be ok with 800GB+ cached in your local disk, since the tfds implementation was designed to offload the storage to Google Cloud Storage.",
"With the dataset streaming feature (see #2375) it will be more convenient to play with such big datasets :)\r\nI'm currently adding C4 (see #2511 ) but I can probably start working on this afterwards",
"Hi folks! Just wanted to follow up on this -- would be really nice to get the Pile on HF Datasets... unclear if it would be easy to also add partitions of the Pile subject to the original 22 datasets used, but that would be nice too!",
"Hi folks, thanks to some awesome work by @lhoestq and @albertvillanova you can now stream the Pile as follows:\r\n\r\n```python\r\n# Install master branch of `datasets`\r\npip install git+https://github.com/huggingface/datasets.git#egg=datasets[streaming]\r\npip install zstandard\r\n\r\nfrom datasets import load_dataset\r\n\r\ndset = load_dataset(\"json\", data_files=\"https://the-eye.eu/public/AI/pile/train/00.jsonl.zst\", streaming=True, split=\"train\")\r\nnext(iter(dset))\r\n# {'meta': {'pile_set_name': 'Pile-CC'},\r\n# 'text': 'It is done, and submitted. You can play “Survival of the Tastiest” on Android, and on the web ... '}\r\n```\r\n\r\nNext step is to add the Pile as a \"canonical\" dataset that can be streamed without specifying the file names explicitly :)",
"> Hi folks! Just wanted to follow up on this -- would be really nice to get the Pile on HF Datasets... unclear if it would be easy to also add partitions of the Pile subject to the original 22 datasets used, but that would be nice too!\r\n\r\nHi @siddk thanks to a tip from @richarddwang it seems we can access some of the partitions that EleutherAI created for the Pile [here](https://the-eye.eu/public/AI/pile_preliminary_components/). What's missing are links to the preprocessed versions of pre-existing datasets like DeepMind Mathematics and OpenSubtitles, but worst case we do the processing ourselves and host these components on the Hub.\r\n\r\nMy current idea is that we could provide 23 configs: one for each of the 22 datasets and an `all` config that links to the train / dev / test splits that EleutherAI released [here](https://the-eye.eu/public/AI/pile/), e.g.\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\n# Load a single component\r\nyoutube_subtitles = load_dataset(\"the_pile\", \"youtube_subtitles\")\r\n# Load the train / dev / test splits of the whole corpus\r\ndset = load_dataset(\"the_pile\", \"all\")\r\n```\r\n\r\nIdeally we'd like everything to be compatible with the streaming API and there's ongoing work by @albertvillanova to make this happen for the various compression algorithms.\r\n\r\ncc @lhoestq ",
"Ah I just saw that @lhoestq is already thinking about the specifying of one or more subsets in [this PR](https://github.com/huggingface/datasets/pull/2817#issuecomment-901874049) :)"
] | ## Adding a Dataset
- **Name:** The Pile
- **Description:** The Pile is a 825 GiB diverse, open source language modelling data set that consists of 22 smaller, high-quality datasets combined together. See [here](https://twitter.com/nabla_theta/status/1345130408170541056?s=20) for the Twitter announcement
- **Paper:** https://pile.eleuther.ai/paper.pdf
- **Data:** https://pile.eleuther.ai/
- **Motivation:** Enables hardcore (GPT-3 scale!) language modelling
## Remarks
Given the extreme size of this dataset, I'm not sure how feasible this will be to include in `datasets` 🤯 . I'm also unsure how many `datasets` users are pretraining LMs, so the usage of this dataset may not warrant the effort to integrate it.
| 1,675 |
https://github.com/huggingface/datasets/issues/1674 | dutch_social can't be loaded | [
"exactly the same issue in some other datasets.\r\nDid you find any solution??\r\n",
"Hi @koenvandenberge and @alighofrani95!\r\nThe datasets you're experiencing issues with were most likely added recently to the `datasets` library, meaning they have not been released yet. They will be released with the v2 of the library.\r\nMeanwhile, you can still load the datasets using one of the techniques described in this issue: #1641 \r\nLet me know if this helps!",
"Maybe we should do a small release on Monday in the meantime @lhoestq ?",
"Yes sure !",
"I just did the release :)\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `dutch_social` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"dutch_social\")\r\n```",
"@lhoestq could you also shed light on the Hindi Wikipedia Dataset for issue number #1673. Will this also be available in the new release that you committed recently?",
"The issue is different for this one, let me give more details in the issue",
"Okay. Could you comment on the #1673 thread? Actually @thomwolf had commented that if i use datasets library from source, it would allow me to download the Hindi Wikipedia Dataset but even the version 1.1.3 gave me the same issue. The details are there in the issue #1673 thread."
] | Hi all,
I'm trying to import the `dutch_social` dataset described [here](https://huggingface.co/datasets/dutch_social).
However, the code that should load the data doesn't seem to be working, in particular because the corresponding files can't be found at the provided links.
```
(base) Koens-MacBook-Pro:~ koenvandenberge$ python
Python 3.7.4 (default, Aug 13 2019, 15:17:50)
[Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from datasets import load_dataset
dataset = load_dataset(
'dutch_social')
>>> dataset = load_dataset(
... 'dutch_social')
Traceback (most recent call last):
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/dutch_social/dutch_social.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 278, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/dutch_social/dutch_social.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 589, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 282, in prepare_module
combined_path, github_file_path, file_path
FileNotFoundError: Couldn't find file locally at dutch_social/dutch_social.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/dutch_social/dutch_social.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/dutch_social/dutch_social.py
``` | 1,674 |
https://github.com/huggingface/datasets/issues/1673 | Unable to Download Hindi Wikipedia Dataset | [
"Currently this dataset is only available when the library is installed from source since it was added after the last release.\r\n\r\nWe pin the dataset version with the library version so that people can have a reproducible dataset and processing when pinning the library.\r\n\r\nWe'll see if we can provide access to newer datasets with a warning that they are newer than your library version, that would help in cases like yours.",
"So for now, should i try and install the library from source and then try out the same piece of code? Will it work then, considering both the versions will match then?",
"Yes",
"Hey, so i tried installing the library from source using the commands : **git clone https://github.com/huggingface/datasets**, **cd datasets** and then **pip3 install -e .**. But i still am facing the same error that file is not found. Please advise.\r\n\r\nThe Datasets library version now is 1.1.3 by installing from source as compared to the earlier 1.0.3 that i had loaded using pip command but I am still getting same error\r\n\r\n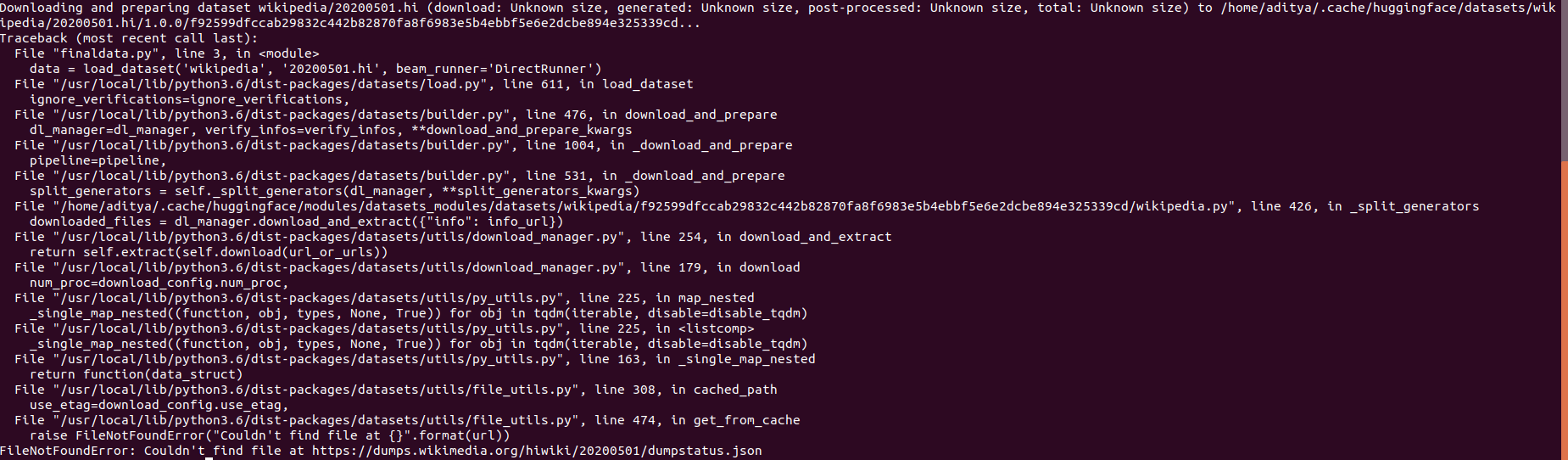\r\n",
"Looks like the wikipedia dump for hindi at the date of 05/05/2020 is not available anymore.\r\nYou can try to load a more recent version of wikipedia\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nd = load_dataset(\"wikipedia\", language=\"hi\", date=\"20210101\", split=\"train\", beam_runner=\"DirectRunner\")\r\n```",
"Okay, thank you so much"
] | I used the Dataset Library in Python to load the wikipedia dataset with the Hindi Config 20200501.hi along with something called beam_runner='DirectRunner' and it keeps giving me the error that the file is not found. I have attached the screenshot of the error and the code both. Please help me to understand how to resolve this issue.


| 1,673 |
https://github.com/huggingface/datasets/issues/1672 | load_dataset hang on file_lock | [
"Can you try to upgrade to a more recent version of datasets?",
"Thank, upgrading to 1.1.3 resolved the issue.",
"Having the same issue with `datasets 1.1.3` of `1.5.0` (both tracebacks look the same) and `kilt_wikipedia`, Ubuntu 20.04\r\n\r\n```py\r\nIn [1]: from datasets import load_dataset \r\n\r\nIn [2]: wikipedia = load_dataset('kilt_wikipedia')['full'] \r\nDownloading: 7.37kB [00:00, 2.74MB/s] \r\nDownloading: 3.33kB [00:00, 1.44MB/s] \r\n^C---------------------------------------------------------------------------\r\nOSError Traceback (most recent call last)\r\n~/anaconda3/envs/transformers2/lib/python3.7/site-packages/datasets/utils/filelock.py in _acquire(self)\r\n 380 try:\r\n--> 381 fcntl.flock(fd, fcntl.LOCK_EX | fcntl.LOCK_NB)\r\n 382 except (IOError, OSError):\r\n\r\nOSError: [Errno 37] No locks available\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nKeyboardInterrupt Traceback (most recent call last)\r\n<ipython-input-2-f412d3d46ec9> in <module>\r\n----> 1 wikipedia = load_dataset('kilt_wikipedia')['full']\r\n\r\n~/anaconda3/envs/transformers2/lib/python3.7/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, sav\r\ne_infos, script_version, **config_kwargs)\r\n 601 hash=hash,\r\n 602 features=features,\r\n--> 603 **config_kwargs,\r\n 604 )\r\n 605 \r\n\r\n~/anaconda3/envs/transformers2/lib/python3.7/site-packages/datasets/builder.py in __init__(self, *args, **kwargs)\r\n 841 def __init__(self, *args, **kwargs):\r\n 842 self._writer_batch_size = kwargs.pop(\"writer_batch_size\", self._writer_batch_size)\r\n--> 843 super(GeneratorBasedBuilder, self).__init__(*args, **kwargs)\r\n 844 \r\n 845 @abc.abstractmethod\r\n\r\n~/anaconda3/envs/transformers2/lib/python3.7/site-packages/datasets/builder.py in __init__(self, cache_dir, name, hash, features, **config_kwargs)\r\n 174 os.makedirs(self._cache_dir_root, exist_ok=True)\r\n 175 lock_path = os.path.join(self._cache_dir_root, self._cache_dir.replace(os.sep, \"_\") + \".lock\")\r\n--> 176 with FileLock(lock_path):\r\n 177 if os.path.exists(self._cache_dir): # check if data exist\r\n 178 if len(os.listdir(self._cache_dir)) > 0:\r\n\r\n~/anaconda3/envs/transformers2/lib/python3.7/site-packages/datasets/utils/filelock.py in __enter__(self)\r\n 312 \r\n 313 def __enter__(self):\r\n--> 314 self.acquire()\r\n 315 return self\r\n 316 \r\n\r\n~/anaconda3/envs/transformers2/lib/python3.7/site-packages/datasets/utils/filelock.py in acquire(self, timeout, poll_intervall)\r\n 261 if not self.is_locked:\r\n 262 logger().debug(\"Attempting to acquire lock %s on %s\", lock_id, lock_filename)\r\n--> 263 self._acquire()\r\n 264 \r\n 265 if self.is_locked:\r\n\r\n~/anaconda3/envs/transformers2/lib/python3.7/site-packages/datasets/utils/filelock.py in _acquire(self)\r\n 379 \r\n 380 try:\r\n--> 381 fcntl.flock(fd, fcntl.LOCK_EX | fcntl.LOCK_NB)\r\n 382 except (IOError, OSError):\r\n 383 os.close(fd)\r\n\r\nKeyboardInterrupt: \r\n\r\n```"
] | I am trying to load the squad dataset. Fails on Windows 10 but succeeds in Colab.
Transformers: 3.3.1
Datasets: 1.0.2
Windows 10 (also tested in WSL)
```
datasets.logging.set_verbosity_debug()
datasets.
train_dataset = load_dataset('squad', split='train')
valid_dataset = load_dataset('squad', split='validation')
train_dataset.features
```
```
https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad/squad.py not found in cache or force_download set to True, downloading to C:\Users\simpl\.cache\huggingface\datasets\tmpzj_o_6u7
Downloading:
5.24k/? [00:00<00:00, 134kB/s]
storing https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad/squad.py in cache at C:\Users\simpl\.cache\huggingface\datasets\f6877c8d2e01e8fcb60dc101be28b54a7522feac756deb9ac5c39c6d8ebef1ce.85f43de978b9b25921cb78d7a2f2b350c04acdbaedb9ecb5f7101cd7c0950e68.py
creating metadata file for C:\Users\simpl\.cache\huggingface\datasets\f6877c8d2e01e8fcb60dc101be28b54a7522feac756deb9ac5c39c6d8ebef1ce.85f43de978b9b25921cb78d7a2f2b350c04acdbaedb9ecb5f7101cd7c0950e68.py
Checking C:\Users\simpl\.cache\huggingface\datasets\f6877c8d2e01e8fcb60dc101be28b54a7522feac756deb9ac5c39c6d8ebef1ce.85f43de978b9b25921cb78d7a2f2b350c04acdbaedb9ecb5f7101cd7c0950e68.py for additional imports.
Found main folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad/squad.py at C:\Users\simpl\.cache\huggingface\modules\datasets_modules\datasets\squad
Found specific version folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad/squad.py at C:\Users\simpl\.cache\huggingface\modules\datasets_modules\datasets\squad\1244d044b266a5e4dbd4174d23cb995eead372fbca31a03edc3f8a132787af41
Found script file from https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad/squad.py to C:\Users\simpl\.cache\huggingface\modules\datasets_modules\datasets\squad\1244d044b266a5e4dbd4174d23cb995eead372fbca31a03edc3f8a132787af41\squad.py
Couldn't find dataset infos file at https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad\dataset_infos.json
Found metadata file for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad/squad.py at C:\Users\simpl\.cache\huggingface\modules\datasets_modules\datasets\squad\1244d044b266a5e4dbd4174d23cb995eead372fbca31a03edc3f8a132787af41\squad.json
No config specified, defaulting to first: squad/plain_text
```
Interrupting the jupyter kernel we are in a file lock.
In Google Colab the download is ok. In contrast to a local run in colab dataset_infos.json is downloaded
```
https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad/dataset_infos.json not found in cache or force_download set to True, downloading to /root/.cache/huggingface/datasets/tmptl9ha_ad
Downloading:
2.19k/? [00:00<00:00, 26.2kB/s]
``` | 1,672 |
https://github.com/huggingface/datasets/issues/1671 | connection issue | [
"Also, mayjor issue for me is the format issue, even if I go through changing the whole code to use load_from_disk, then if I do \r\n\r\nd = datasets.load_from_disk(\"imdb\")\r\nd = d[\"train\"][:10] => the format of this is no more in datasets format\r\nthis is different from you call load_datasets(\"train[10]\")\r\n\r\ncould you tell me how I can make the two datastes the same format @lhoestq \r\n\r\n",
"> `\r\nrequests.exceptions.ConnectTimeout: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /datasets.huggingface.co/datasets/datasets/glue/glue.py (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7ff6d6c60a20>, 'Connection to s3.amazonaws.com timed out. (connect timeout=10)'))`\r\n\r\nDo you have an internet connection on the machine ? Is there a proxy that might block requests to aws ?\r\n\r\n> I tried to do read the data, save it to a path and then set HF_HOME, which does not work and this is still not reading from the old set path, could you assist me how to save the datasets in a path, and let dataset library read from this path to avoid connection issue. thanks\r\n\r\nHF_HOME is used to specify the directory for the cache files of this library.\r\nYou can use save_to_disk and load_from_disk without changing the HF_HOME:\r\n```python\r\nimdb = datasets.load_dataset(\"imdb\")\r\nimdb.save_to_disk(\"/idiap/temp/rkarimi/hf_datasets/imdb\")\r\nimdb = datasets.load_from_disk(\"/idiap/temp/rkarimi/hf_datasets/imdb\")\r\n```\r\n\r\n> could you tell me how I can make the two datastes the same format\r\n\r\nIndeed they returns different things:\r\n- `load_dataset` returns a `Dataset` object if the split is specified, or a `DatasetDict` if no split is given. Therefore `load_datasets(\"imdb\", split=\"train[10]\")` returns a `Dataset` object containing 10 elements.\r\n- doing `d[\"train\"][:10]` on a DatasetDict \"d\" gets the train split `d[\"train\"]` as a `Dataset` object and then gets the first 10 elements as a dictionary"
] | Hi
I am getting this connection issue, resulting in large failure on cloud, @lhoestq I appreciate your help on this.
If I want to keep the codes the same, so not using save_to_disk, load_from_disk, but save the datastes in the way load_dataset reads from and copy the files in the same folder the datasets library reads from, could you assist me how this can be done, thanks
I tried to do read the data, save it to a path and then set HF_HOME, which does not work and this is still not reading from the old set path, could you assist me how to save the datasets in a path, and let dataset library read from this path to avoid connection issue. thanks
```
imdb = datasets.load_dataset("imdb")
imdb.save_to_disk("/idiap/temp/rkarimi/hf_datasets/imdb")
>>> os.environ["HF_HOME"]="/idiap/temp/rkarimi/hf_datasets/"
>>> imdb = datasets.load_dataset("imdb")
Reusing dataset imdb (/idiap/temp/rkarimi/cache_home_2/datasets/imdb/plain_text/1.0.0/90099cb476936b753383ba2ae6ab2eae419b2e87f71cd5189cb9c8e5814d12a3)
```
I tried afterwards to set HF_HOME in bash, this makes it read from it, but it cannot let dataset library load from the saved path and still downloading data. could you tell me how to fix this issue @lhoestq thanks
Also this is on cloud, so I save them in a path, copy it to "another machine" to load the data
### Error stack
```
Traceback (most recent call last):
File "./finetune_t5_trainer.py", line 344, in <module>
main()
File "./finetune_t5_trainer.py", line 232, in main
for task in data_args.eval_tasks} if training_args.do_test else None
File "./finetune_t5_trainer.py", line 232, in <dictcomp>
for task in data_args.eval_tasks} if training_args.do_test else None
File "/workdir/seq2seq/data/tasks.py", line 136, in get_dataset
split = self.get_sampled_split(split, n_obs)
File "/workdir/seq2seq/data/tasks.py", line 64, in get_sampled_split
dataset = self.load_dataset(split)
File "/workdir/seq2seq/data/tasks.py", line 454, in load_dataset
split=split, script_version="master")
File "/usr/local/lib/python3.6/dist-packages/datasets/load.py", line 589, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/usr/local/lib/python3.6/dist-packages/datasets/load.py", line 263, in prepare_module
head_hf_s3(path, filename=name, dataset=dataset)
File "/usr/local/lib/python3.6/dist-packages/datasets/utils/file_utils.py", line 200, in head_hf_s3
return http_head(hf_bucket_url(identifier=identifier, filename=filename, use_cdn=use_cdn, dataset=dataset))
File "/usr/local/lib/python3.6/dist-packages/datasets/utils/file_utils.py", line 403, in http_head
url, proxies=proxies, headers=headers, cookies=cookies, allow_redirects=allow_redirects, timeout=timeout
File "/usr/local/lib/python3.6/dist-packages/requests/api.py", line 104, in head
return request('head', url, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/requests/api.py", line 61, in request
return session.request(method=method, url=url, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/requests/sessions.py", line 542, in request
resp = self.send(prep, **send_kwargs)
File "/usr/local/lib/python3.6/dist-packages/requests/sessions.py", line 655, in send
r = adapter.send(request, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/requests/adapters.py", line 504, in send
raise ConnectTimeout(e, request=request)
requests.exceptions.ConnectTimeout: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /datasets.huggingface.co/datasets/datasets/glue/glue.py (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7ff6d6c60a20>, 'Connection to s3.amazonaws.com timed out. (connect timeout=10)'))
```
| 1,671 |
https://github.com/huggingface/datasets/issues/1670 | wiki_dpr pre-processing performance | [
"Hi ! And thanks for the tips :) \r\n\r\nIndeed currently `wiki_dpr` takes some time to be processed.\r\nMultiprocessing for dataset generation is definitely going to speed up things.\r\n\r\nRegarding the index note that for the default configurations, the index is downloaded instead of being built, which avoid spending time on constructing the index. However in other cases it would be awesome to make the construction faster.\r\n\r\nAny contribution that can help things faster are welcome. In particular in you have some code that can build a wiki_dpr IVF PQ index in a sharded GPU setup and would like to share it, we can add it to an `examples` folder. In particular since faiss is becoming the library of reference for dataset indexing for tasks like Open Domain Question Answering.\r\n\r\n",
"I'd be happy to contribute something when I get the time, probably adding multiprocessing and / or cython support to wiki_dpr. I've written cythonized apache beam code before as well.\r\n\r\nFor sharded index building, I used the FAISS example code for indexing 1 billion vectors as a start. I'm sure you're aware that the documentation isn't great, but the source code is fairly easy to follow.",
"Nice thanks ! That would be awesome to make its construction faster :) "
] | I've been working with wiki_dpr and noticed that the dataset processing is seriously impaired in performance [1]. It takes about 12h to process the entire dataset. Most of this time is simply loading and processing the data, but the actual indexing is also quite slow (3h).
I won't repeat the concerns around multiprocessing as they are addressed in other issues (#786), but this is the first obvious thing to do. Using cython to speed up the text manipulation may be also help. Loading and processing a dataset of this size in under 15 minutes does not seem unreasonable on a modern multi-core machine. I have hit such targets myself on similar tasks. Would love to see this improve.
The other issue is that it takes 3h to construct the FAISS index. If only we could use GPUs with HNSW, but we can't. My sharded GPU indexing code can build an IVF + PQ index in 10 minutes on 20 million vectors. Still, 3h seems slow even for the CPU.
It looks like HF is adding only 1000 vectors at a time by default [2], whereas the faiss benchmarks adds 1 million vectors at a time (effectively) [3]. It's possible the runtime could be reduced with a larger batch. Also, it looks like project dependencies ultimately use OpenBLAS, but this is known to have issues when combined with OpenMP, which HNSW does [3]. A workaround is to set the environment variable `OMP_WAIT_POLICY=PASSIVE` via `os.environ` or similar.
References:
[1] https://github.com/huggingface/datasets/blob/master/datasets/wiki_dpr/wiki_dpr.py
[2] https://github.com/huggingface/datasets/blob/master/src/datasets/search.py
[3] https://github.com/facebookresearch/faiss/blob/master/benchs/bench_hnsw.py
[4] https://github.com/facebookresearch/faiss/issues/422 | 1,670 |
https://github.com/huggingface/datasets/issues/1669 | wiki_dpr dataset pre-processesing performance | [
"Sorry, double posted."
] | I've been working with wiki_dpr and noticed that the dataset processing is seriously impaired in performance [1]. It takes about 12h to process the entire dataset. Most of this time is simply loading and processing the data, but the actual indexing is also quite slow (3h).
I won't repeat the concerns around multiprocessing as they are addressed in other issues (#786), but this is the first obvious thing to do. Using cython to speed up the text manipulation may be also help. Loading and processing a dataset of this size in under 15 minutes does not seem unreasonable on a modern multi-core machine. I have hit such targets myself on similar tasks. Would love to see this improve.
The other issue is that it takes 3h to construct the FAISS index. If only we could use GPUs with HNSW, but we can't. My sharded GPU indexing code can build an IVF + PQ index in 10 minutes on 20 million vectors. Still, 3h seems slow even for the CPU.
It looks like HF is adding only 1000 vectors at a time by default [2], whereas the faiss benchmarks adds 1 million vectors at a time (effectively) [3]. It's possible the runtime could be reduced with a larger batch. Also, it looks like project dependencies ultimately use OpenBLAS, but this is known to have issues when combined with OpenMP, which HNSW does [3]. A workaround is to set the environment variable `OMP_WAIT_POLICY=PASSIVE` via `os.environ` or similar.
References:
[1] https://github.com/huggingface/datasets/blob/master/datasets/wiki_dpr/wiki_dpr.py
[2] https://github.com/huggingface/datasets/blob/master/src/datasets/search.py
[3] https://github.com/facebookresearch/faiss/blob/master/benchs/bench_hnsw.py
[4] https://github.com/facebookresearch/faiss/issues/422 | 1,669 |
https://github.com/huggingface/datasets/issues/1662 | Arrow file is too large when saving vector data | [
"Hi !\r\nThe arrow file size is due to the embeddings. Indeed if they're stored as float32 then the total size of the embeddings is\r\n\r\n20 000 000 vectors * 768 dimensions * 4 bytes per dimension ~= 60GB\r\n\r\nIf you want to reduce the size you can consider using quantization for example, or maybe using dimension reduction techniques.\r\n",
"Thanks for your reply @lhoestq.\r\nI want to save original embedding for these sentences for subsequent calculations. So does arrow have a way to save in a compressed format to reduce the size of the file?",
"Arrow doesn't have compression since it is designed to have no serialization overhead",
"I see. Thank you."
] | I computed the sentence embedding of each sentence of bookcorpus data using bert base and saved them to disk. I used 20M sentences and the obtained arrow file is about 59GB while the original text file is only about 1.3GB. Are there any ways to reduce the size of the arrow file? | 1,662 |
https://github.com/huggingface/datasets/issues/1647 | NarrativeQA fails to load with `load_dataset` | [
"Hi @eric-mitchell,\r\nI think the issue might be that this dataset was added during the community sprint and has not been released yet. It will be available with the v2 of `datasets`.\r\nFor now, you should be able to load the datasets after installing the latest (master) version of `datasets` using pip:\r\n`pip install git+https://github.com/huggingface/datasets.git@master`",
"@bhavitvyamalik Great, thanks for this! Confirmed that the problem is resolved on master at [cbbda53](https://github.com/huggingface/datasets/commit/cbbda53ac1520b01f0f67ed6017003936c41ec59).",
"Update: HuggingFace did an intermediate release yesterday just before the v2.0.\r\n\r\nTo load it you can just update `datasets`\r\n\r\n`pip install --upgrade datasets`"
] | When loading the NarrativeQA dataset with `load_dataset('narrativeqa')` as given in the documentation [here](https://huggingface.co/datasets/narrativeqa), I receive a cascade of exceptions, ending with
FileNotFoundError: Couldn't find file locally at narrativeqa/narrativeqa.py, or remotely at
https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/narrativeqa/narrativeqa.py or
https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/narrativeqa/narrativeqa.py
Workaround: manually copy the `narrativeqa.py` builder into my local directory with
curl https://raw.githubusercontent.com/huggingface/datasets/master/datasets/narrativeqa/narrativeqa.py -o narrativeqa.py
and load the dataset as `load_dataset('narrativeqa.py')` everything works fine. I'm on datasets v1.1.3 using Python 3.6.10. | 1,647 |
https://github.com/huggingface/datasets/issues/1644 | HoVeR dataset fails to load | [
"Hover was added recently, that's why it wasn't available yet.\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `hover` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"hover\")\r\n```"
] | Hi! I'm getting an error when trying to load **HoVeR** dataset. Another one (**SQuAD**) does work for me. I'm using the latest (1.1.3) version of the library.
Steps to reproduce the error:
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("hover")
Traceback (most recent call last):
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/hover/hover.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/load.py", line 278, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/hover/hover.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/load.py", line 589, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/load.py", line 282, in prepare_module
combined_path, github_file_path, file_path
FileNotFoundError: Couldn't find file locally at hover/hover.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/hover/hover.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/hover/hover.py
``` | 1,644 |
https://github.com/huggingface/datasets/issues/1643 | Dataset social_bias_frames 404 | [
"I see, master is already fixed in https://github.com/huggingface/datasets/commit/9e058f098a0919efd03a136b9b9c3dec5076f626"
] | ```
>>> from datasets import load_dataset
>>> dataset = load_dataset("social_bias_frames")
...
Downloading and preparing dataset social_bias_frames/default
...
~/.pyenv/versions/3.7.6/lib/python3.7/site-packages/datasets/utils/file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, local_files_only, use_etag)
484 )
485 elif response is not None and response.status_code == 404:
--> 486 raise FileNotFoundError("Couldn't find file at {}".format(url))
487 raise ConnectionError("Couldn't reach {}".format(url))
488
FileNotFoundError: Couldn't find file at https://homes.cs.washington.edu/~msap/social-bias-frames/SocialBiasFrames_v2.tgz
```
[Here](https://homes.cs.washington.edu/~msap/social-bias-frames/) we find button `Download data` with the correct URL for the data: https://homes.cs.washington.edu/~msap/social-bias-frames/SBIC.v2.tgz | 1,643 |
https://github.com/huggingface/datasets/issues/1641 | muchocine dataset cannot be dowloaded | [
"I have encountered the same error with `v1.0.1` and `v1.0.2` on both Windows and Linux environments. However, cloning the repo and using the path to the dataset's root directory worked for me. Even after having the dataset cached - passing the path is the only way (for now) to load the dataset.\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"squad\") # Works\r\ndataset = load_dataset(\"code_search_net\", \"python\") # Error\r\ndataset = load_dataset(\"covid_qa_deepset\") # Error\r\n\r\npath = \"/huggingface/datasets/datasets/{}/\"\r\ndataset = load_dataset(path.format(\"code_search_net\"), \"python\") # Works\r\ndataset = load_dataset(path.format(\"covid_qa_deepset\")) # Works\r\n```\r\n\r\n",
"Hi @mrm8488 and @amoux!\r\n The datasets you are trying to load have been added to the library during the community sprint for v2 last month. They will be available with the v2 release!\r\nFor now, there are still a couple of solutions to load the datasets:\r\n1. As suggested by @amoux, you can clone the git repo and pass the local path to the script\r\n2. You can also install the latest (master) version of `datasets` using pip: `pip install git+https://github.com/huggingface/datasets.git@master`",
"If you don't want to clone entire `datasets` repo, just download the `muchocine` directory and pass the local path to the directory. Cheers!",
"Muchocine was added recently, that's why it wasn't available yet.\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `muchocine` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"muchocine\", split=\"train\")\r\n```",
"Thanks @lhoestq "
] | ```python
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/datasets/load.py in prepare_module(path, script_version, download_config, download_mode, dataset, force_local_path, **download_kwargs)
267 try:
--> 268 local_path = cached_path(file_path, download_config=download_config)
269 except FileNotFoundError:
7 frames
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/muchocine/muchocine.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/muchocine/muchocine.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/datasets/load.py in prepare_module(path, script_version, download_config, download_mode, dataset, force_local_path, **download_kwargs)
281 raise FileNotFoundError(
282 "Couldn't find file locally at {}, or remotely at {} or {}".format(
--> 283 combined_path, github_file_path, file_path
284 )
285 )
FileNotFoundError: Couldn't find file locally at muchocine/muchocine.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/muchocine/muchocine.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/muchocine/muchocine.py
``` | 1,641 |
https://github.com/huggingface/datasets/issues/1639 | bug with sst2 in glue | [
"Maybe you can use nltk's treebank detokenizer ?\r\n```python\r\nfrom nltk.tokenize.treebank import TreebankWordDetokenizer\r\n\r\nTreebankWordDetokenizer().detokenize(\"it 's a charming and often affecting journey . \".split())\r\n# \"it's a charming and often affecting journey.\"\r\n```",
"I am looking for alternative file URL here instead of adding extra processing code: https://github.com/huggingface/datasets/blob/171f2bba9dd8b92006b13cf076a5bf31d67d3e69/datasets/glue/glue.py#L174",
"I don't know if there exists a detokenized version somewhere. Even the version on kaggle is tokenized"
] | Hi
I am getting very low accuracy on SST2 I investigate this and observe that for this dataset sentences are tokenized, while this is correct for the other datasets in GLUE, please see below.
Is there any alternatives I could get untokenized sentences? I am unfortunately under time pressure to report some results on this dataset. thank you for your help. @lhoestq
```
>>> a = datasets.load_dataset('glue', 'sst2', split="validation", script_version="master")
Reusing dataset glue (/julia/datasets/glue/sst2/1.0.0/7c99657241149a24692c402a5c3f34d4c9f1df5ac2e4c3759fadea38f6cb29c4)
>>> a[:10]
{'idx': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], 'label': [1, 0, 1, 1, 0, 1, 0, 0, 1, 0], 'sentence': ["it 's a charming and often affecting journey . ", 'unflinchingly bleak and desperate ', 'allows us to hope that nolan is poised to embark a major career as a commercial yet inventive filmmaker . ', "the acting , costumes , music , cinematography and sound are all astounding given the production 's austere locales . ", "it 's slow -- very , very slow . ", 'although laced with humor and a few fanciful touches , the film is a refreshingly serious look at young women . ', 'a sometimes tedious film . ', "or doing last year 's taxes with your ex-wife . ", "you do n't have to know about music to appreciate the film 's easygoing blend of comedy and romance . ", "in exactly 89 minutes , most of which passed as slowly as if i 'd been sitting naked on an igloo , formula 51 sank from quirky to jerky to utter turkey . "]}
``` | 1,639 |
https://github.com/huggingface/datasets/issues/1636 | winogrande cannot be dowloaded | [
"I have same issue for other datasets (`myanmar_news` in my case).\r\n\r\nA version of `datasets` runs correctly on my local machine (**without GPU**) which looking for the dataset at \r\n```\r\nhttps://raw.githubusercontent.com/huggingface/datasets/master/datasets/myanmar_news/myanmar_news.py\r\n```\r\n\r\nMeanwhile, other version runs on Colab (**with GPU**) failed to download the dataset. It try to find the dataset at `1.1.3` instead of `master` . If I disable GPU on my Colab, the code can load the dataset without any problem.\r\n\r\nMaybe there is some version missmatch with the GPU and CPU version of code for these datasets?",
"It looks like they're two different issues\r\n\r\n----------\r\n\r\nFirst for `myanmar_news`: \r\n\r\nIt must come from the way you installed `datasets`.\r\nIf you install `datasets` from source, then the `myanmar_news` script will be loaded from `master`.\r\nHowever if you install from `pip` it will get it using the version of the lib (here `1.1.3`) and `myanmar_news` is not available in `1.1.3`.\r\n\r\nThe difference between your GPU and CPU executions must be the environment, one seems to have installed `datasets` from source and not the other.\r\n\r\n----------\r\n\r\nThen for `winogrande`:\r\n\r\nThe errors says that the url https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/winogrande/winogrande.py is not reachable.\r\nHowever it works fine on my side.\r\n\r\nDoes your machine have an internet connection ? Are connections to github blocked by some sort of proxy ?\r\nCan you also try again in case github had issues when you tried the first time ?\r\n"
] | Hi,
I am getting this error when trying to run the codes on the cloud. Thank you for any suggestion and help on this @lhoestq
```
File "./finetune_trainer.py", line 318, in <module>
main()
File "./finetune_trainer.py", line 148, in main
for task in data_args.tasks]
File "./finetune_trainer.py", line 148, in <listcomp>
for task in data_args.tasks]
File "/workdir/seq2seq/data/tasks.py", line 65, in get_dataset
dataset = self.load_dataset(split=split)
File "/workdir/seq2seq/data/tasks.py", line 466, in load_dataset
return datasets.load_dataset('winogrande', 'winogrande_l', split=split)
File "/usr/local/lib/python3.6/dist-packages/datasets/load.py", line 589, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/usr/local/lib/python3.6/dist-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/usr/local/lib/python3.6/dist-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/usr/local/lib/python3.6/dist-packages/datasets/utils/file_utils.py", line 487, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/winogrande/winogrande.py
yo/0 I1224 14:17:46.419031 31226 main shadow.py:122 > Traceback (most recent call last):
File "/usr/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/usr/local/lib/python3.6/dist-packages/torch/distributed/launch.py", line 260, in <module>
main()
File "/usr/local/lib/python3.6/dist-packages/torch/distributed/launch.py", line 256, in main
cmd=cmd)
``` | 1,636 |
https://github.com/huggingface/datasets/issues/1635 | Persian Abstractive/Extractive Text Summarization | [] | Assembling datasets tailored to different tasks and languages is a precious target. This would be great to have this dataset included.
## Adding a Dataset
- **Name:** *pn-summary*
- **Description:** *A well-structured summarization dataset for the Persian language consists of 93,207 records. It is prepared for Abstractive/Extractive tasks (like cnn_dailymail for English). It can also be used in other scopes like Text Generation, Title Generation, and News Category Classification.*
- **Paper:** *https://arxiv.org/abs/2012.11204*
- **Data:** *https://github.com/hooshvare/pn-summary/#download*
- **Motivation:** *It is the first Persian abstractive/extractive Text summarization dataset (like cnn_dailymail for English)!*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| 1,635 |
https://github.com/huggingface/datasets/issues/1634 | Inspecting datasets per category | [
"That's interesting, can you tell me what you think would be useful to access to inspect a dataset?\r\n\r\nYou can filter them in the hub with the search by the way: https://huggingface.co/datasets have you seen it?",
"Hi @thomwolf \r\nthank you, I was not aware of this, I was looking into the data viewer linked into readme page. \r\n\r\nThis is exactly what I was looking for, but this does not work currently, please see the attached \r\nI am selecting to see all nli datasets in english and it retrieves none. thanks\r\n\r\n\r\n\r\n\r\n\r\n",
"I see 4 results for NLI in English but indeed some are not tagged yet and missing (GLUE), we will focus on that in January (cc @yjernite): https://huggingface.co/datasets?filter=task_ids:natural-language-inference,languages:en",
"Hi! You can use `huggingface_hub`'s `list_datasets` for that now:\r\n```python\r\nimport huggingface_hub # pip install huggingface_hub\r\nhuggingface_hub.list_datasets(filter=\"task_categories:question-answering\")\r\n# or\r\nhuggingface_hub.list_datasets(filter=(\"task_categories:natural-language-inference\", \"languages:\"en\"))\r\n```"
] | Hi
Is there a way I could get all NLI datasets/all QA datasets to get some understanding of available datasets per category? this is hard for me to inspect the datasets one by one in the webpage, thanks for the suggestions @lhoestq | 1,634 |
https://github.com/huggingface/datasets/issues/1633 | social_i_qa wrong format of labels | [
"@lhoestq, should I raise a PR for this? Just a minor change while reading labels text file",
"Sure feel free to open a PR thanks !"
] | Hi,
there is extra "\n" in labels of social_i_qa datasets, no big deal, but I was wondering if you could remove it to make it consistent.
so label is 'label': '1\n', not '1'
thanks
```
>>> import datasets
>>> from datasets import load_dataset
>>> dataset = load_dataset(
... 'social_i_qa')
cahce dir /julia/cache/datasets
Downloading: 4.72kB [00:00, 3.52MB/s]
cahce dir /julia/cache/datasets
Downloading: 2.19kB [00:00, 1.81MB/s]
Using custom data configuration default
Reusing dataset social_i_qa (/julia/datasets/social_i_qa/default/0.1.0/4a4190cc2d2482d43416c2167c0c5dccdd769d4482e84893614bd069e5c3ba06)
>>> dataset['train'][0]
{'answerA': 'like attending', 'answerB': 'like staying home', 'answerC': 'a good friend to have', 'context': 'Cameron decided to have a barbecue and gathered her friends together.', 'label': '1\n', 'question': 'How would Others feel as a result?'}
```
| 1,633 |
https://github.com/huggingface/datasets/issues/1632 | SICK dataset | [] | Hi, this would be great to have this dataset included. I might be missing something, but I could not find it in the list of already included datasets. Thank you.
## Adding a Dataset
- **Name:** SICK
- **Description:** SICK consists of about 10,000 English sentence pairs that include many examples of the lexical, syntactic, and semantic phenomena.
- **Paper:** https://www.aclweb.org/anthology/L14-1314/
- **Data:** http://marcobaroni.org/composes/sick.html
- **Motivation:** This dataset is well-known in the NLP community used for recognizing entailment between sentences.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| 1,632 |
https://github.com/huggingface/datasets/issues/1630 | Adding UKP Argument Aspect Similarity Corpus | [
"Adding a link to the guide on adding a dataset if someone want to give it a try: https://github.com/huggingface/datasets#add-a-new-dataset-to-the-hub\r\n\r\nwe should add this guide to the issue template @lhoestq ",
"thanks @thomwolf , this is added now. The template is correct, sorry my mistake not to include it. ",
"Available here: https://huggingface.co/datasets/UKPLab/UKP_ASPECT"
] | Hi, this would be great to have this dataset included.
## Adding a Dataset
- **Name:** UKP Argument Aspect Similarity Corpus
- **Description:** The UKP Argument Aspect Similarity Corpus (UKP ASPECT) includes 3,595 sentence pairs over 28 controversial topics. Each sentence pair was annotated via crowdsourcing as either “high similarity”, “some similarity”, “no similarity” or “not related” with respect to the topic.
- **Paper:** https://www.aclweb.org/anthology/P19-1054/
- **Data:** https://tudatalib.ulb.tu-darmstadt.de/handle/tudatalib/1998
- **Motivation:** this is one of the datasets currently used frequently in recent adapter papers like https://arxiv.org/pdf/2005.00247.pdf
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
Thank you | 1,630 |
https://github.com/huggingface/datasets/issues/1627 | `Dataset.map` disable progress bar | [
"Progress bar can be disabled like this:\r\n```python\r\nfrom datasets.utils.logging import set_verbosity_error\r\nset_verbosity_error()\r\n```\r\n\r\nThere is this line in `Dataset.map`:\r\n```python\r\nnot_verbose = bool(logger.getEffectiveLevel() > WARNING)\r\n```\r\n\r\nSo any logging level higher than `WARNING` turns off the progress bar.",
"From the linked issues above, an up-to-date solution is:\r\n\r\n```python\r\nfrom datasets.utils.logging import disable_progress_bar\r\ndisable_progress_bar()\r\n```\r\n\r\nhttps://github.com/huggingface/datasets/blob/c6e08fcfc3a04e53430c26fa7c07da4cb18d977d/src/datasets/utils/logging.py#L233-L236",
"Why not have a parameter in the function such as `progress: bool = True`?"
] | I can't find anything to turn off the `tqdm` progress bars while running a preprocessing function using `Dataset.map`. I want to do akin to `disable_tqdm=True` in the case of `transformers`. Is there something like that? | 1,627 |
https://github.com/huggingface/datasets/issues/1624 | Cannot download ade_corpus_v2 | [
"Hi @him1411, the dataset you are trying to load has been added during the community sprint and has not been released yet. It will be available with the v2 of `datasets`.\r\nFor now, you should be able to load the datasets after installing the latest (master) version of `datasets` using pip:\r\n`pip install git+https://github.com/huggingface/datasets.git@master`",
"`ade_corpus_v2` was added recently, that's why it wasn't available yet.\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `ade_corpus_v2` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"ade_corpus_v2\", \"Ade_corpos_v2_drug_ade_relation\")\r\n```\r\n\r\n(looks like there is a typo in the configuration name, we'll fix it for the v2.0 release of `datasets` soon)"
] | I tried this to get the dataset following this url : https://huggingface.co/datasets/ade_corpus_v2
but received this error :
`Traceback (most recent call last):
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/ade_corpus_v2/ade_corpus_v2.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 278, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/ade_corpus_v2/ade_corpus_v2.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 589, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 282, in prepare_module
combined_path, github_file_path, file_path
FileNotFoundError: Couldn't find file locally at ade_corpus_v2/ade_corpus_v2.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/ade_corpus_v2/ade_corpus_v2.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/ade_corpus_v2/ade_corpus_v2.py`
| 1,624 |
https://github.com/huggingface/datasets/issues/1622 | Can't call shape on the output of select() | [
"Indeed that's a typo, do you want to open a PR to fix it?",
"Yes, created a PR"
] | I get the error `TypeError: tuple expected at most 1 argument, got 2` when calling `shape` on the output of `select()`.
It's line 531 in shape in arrow_dataset.py that causes the problem:
``return tuple(self._indices.num_rows, self._data.num_columns)``
This makes sense, since `tuple(num1, num2)` is not a valid call.
Full code to reproduce:
```python
dataset = load_dataset("cnn_dailymail", "3.0.0")
train_set = dataset["train"]
t = train_set.select(range(10))
print(t.shape) | 1,622 |
https://github.com/huggingface/datasets/issues/1618 | Can't filter language:EN on https://huggingface.co/datasets | [
"cc'ing @mapmeld ",
"Full language list is now deployed to https://huggingface.co/datasets ! Recommend close",
"Cool @mapmeld ! My 2 cents (for a next iteration), it would be cool to have a small search widget in the filter dropdown as you have a ton of languages now here! Closing this in the meantime."
] | When visiting https://huggingface.co/datasets, I don't see an obvious way to filter only English datasets. This is unexpected for me, am I missing something? I'd expect English to be selectable in the language widget. This problem reproduced on Mozilla Firefox and MS Edge:
| 1,618 |
https://github.com/huggingface/datasets/issues/1615 | Bug: Can't download TriviaQA with `load_dataset` - custom `cache_dir` | [
"Hi @SapirWeissbuch,\r\nWhen you are saying it freezes, at that time it is unzipping the file from the zip file it downloaded. Since it's a very heavy file it'll take some time. It was taking ~11GB after unzipping when it started reading examples for me. Hope that helps!\r\n\r\n",
"Hi @bhavitvyamalik \r\nThanks for the reply!\r\nActually I let it run for 30 minutes before I killed the process. In this time, 30GB were extracted (much more than 11GB), I checked the size of the destination directory.\r\n\r\nWhat version of Datasets are you using?\r\n",
"I'm using datasets version: 1.1.3. I think you should drop `cache_dir` and use only\r\n`dataset = datasets.load_dataset(\"trivia_qa\", \"rc\")`\r\n\r\nTried that on colab and it's working there too\r\n\r\n",
"Train, Validation, and Test splits contain 138384, 18669, and 17210 samples respectively. It takes some time to read the samples. Even in your colab notebook it was reading the samples before you killed the process. Let me know if it works now!",
"Hi, it works on colab but it still doesn't work on my computer, same problem as before - overly large and long extraction process.\r\nI have to use a custom 'cache_dir' because I don't have any space left in my home directory where it is defaulted, maybe this could be the issue?",
"I tried running this again - More details of the problem:\r\nCode:\r\n```\r\ndatasets.load_dataset(\"trivia_qa\", \"rc\", cache_dir=\"/path/to/cache\")\r\n```\r\n\r\nThe output:\r\n```\r\nDownloading and preparing dataset trivia_qa/rc (download: 2.48 GiB, generated: 14.92 GiB, post-processed: Unknown size, total: 17.40 GiB) to path/to/cache/trivia_qa/rc/1.1.0/e734e28133f4d9a353af322aa52b9f266f6f27cbf2f072690a1694e577546b0d... \r\nDownloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2.67G/2.67G [03:38<00:00, 12.2MB/s]\r\n\r\n```\r\nThe process continues (no progress bar is visible).\r\nI tried `du -sh .` in `path/to/cache`, and the size keeps increasing, reached 35G before I killed the process.\r\n\r\nGoogle Colab with custom `cache_dir` has same issue.\r\nhttps://colab.research.google.com/drive/1nn1Lw02GhfGFylzbS2j6yksGjPo7kkN-?usp=sharing#scrollTo=2G2O0AeNIXan",
"1) You can clear the huggingface folder in your `.cache` directory to use default directory for datasets. Speed of extraction and loading of samples depends a lot on your machine's configurations too.\r\n\r\n2) I tried on colab `dataset = datasets.load_dataset(\"trivia_qa\", \"rc\", cache_dir = \"./datasets\")`. After memory usage reached around 42GB (starting from 32GB used already), the dataset was loaded in the memory. Even Your colab notebook shows \r\n\r\nwhich means it's loaded now.",
"Facing the same issue.\r\nI am able to download datasets without `cache_dir`, however, when I specify the `cache_dir`, the process hangs indefinitely after partial download. \r\nTried for `data = load_dataset(\"cnn_dailymail\", \"3.0.0\")`",
"Hi @ashutoshml,\r\nI tried this and it worked for me:\r\n`data = load_dataset(\"cnn_dailymail\", \"3.0.0\", cache_dir=\"./dummy\")`\r\n\r\nI'm using datasets==1.8.0. It took around 3-4 mins for dataset to unpack and start loading examples.",
"Ok. I waited for 20-30 mins, and it still is stuck.\r\nI am using datasets==1.8.0.\r\n\r\nIs there anyway to check what is happening? like a` --verbose` flag?\r\n\r\n\r\n"
] | Hello,
I'm having issue downloading TriviaQA dataset with `load_dataset`.
## Environment info
- `datasets` version: 1.1.3
- Platform: Linux-4.19.129-aufs-1-x86_64-with-debian-10.1
- Python version: 3.7.3
## The code I'm running:
```python
import datasets
dataset = datasets.load_dataset("trivia_qa", "rc", cache_dir = "./datasets")
```
## The output:
1. Download begins:
```
Downloading and preparing dataset trivia_qa/rc (download: 2.48 GiB, generated: 14.92 GiB, post-processed: Unknown size, total: 17.40 GiB) to /cs/labs/gabis/sapirweissbuch/tr
ivia_qa/rc/1.1.0/e734e28133f4d9a353af322aa52b9f266f6f27cbf2f072690a1694e577546b0d...
Downloading: 17%|███████████████████▉ | 446M/2.67G [00:37<04:45, 7.77MB/s]
```
2. 100% is reached
3. It got stuck here for about an hour, and added additional 30G of data to "./datasets" directory. I killed the process eventually.
A similar issue can be observed in Google Colab:
https://colab.research.google.com/drive/1nn1Lw02GhfGFylzbS2j6yksGjPo7kkN-?usp=sharing
## Expected behaviour:
The dataset "TriviaQA" should be successfully downloaded.
| 1,615 |
https://github.com/huggingface/datasets/issues/1611 | shuffle with torch generator | [
"Is there a way one can convert the two generator? not sure overall what alternatives I could have to shuffle the datasets with a torch generator, thanks ",
"@lhoestq let me please expalin in more details, maybe you could help me suggesting an alternative to solve the issue for now, I have multiple large datasets using huggingface library, then I need to define a distributed sampler on top of it, for this I need to shard the datasets and give each shard to each core, but before sharding I need to shuffle the dataset, if you are familiar with distributed sampler in pytorch, this needs to be done based on seed+epoch generator to make it consistent across the cores they do it through defining a torch generator, I was wondering if you could tell me how I can shuffle the data for now, I am unfortunately blocked by this and have a limited time left, and I greatly appreciate your help on this. thanks ",
"@lhoestq Is there a way I could shuffle the datasets from this library with a custom defined shuffle function? thanks for your help on this. ",
"Right now the shuffle method only accepts the `seed` (optional int) or `generator` (optional `np.random.Generator`) parameters.\r\n\r\nHere is a suggestion to shuffle the data using your own shuffle method using `select`.\r\n`select` can be used to re-order the dataset samples or simply pick a few ones if you want.\r\nIt's what is used under the hood when you call `dataset.shuffle`.\r\n\r\nTo use `select` you must have the list of re-ordered indices of your samples.\r\n\r\nLet's say you have a `shuffle` methods that you want to use. Then you can first build your shuffled list of indices:\r\n```python\r\nshuffled_indices = shuffle(range(len(dataset)))\r\n```\r\n\r\nThen you can shuffle your dataset using the shuffled indices with \r\n```python\r\nshuffled_dataset = dataset.select(shuffled_indices)\r\n```\r\n\r\nHope that helps",
"thank you @lhoestq thank you very much for responding to my question, this greatly helped me and remove the blocking for continuing my work, thanks. ",
"@lhoestq could you confirm the method proposed does not bring the whole data into memory? thanks ",
"Yes the dataset is not loaded into memory",
"great. thanks a lot."
] | Hi
I need to shuffle mutliple large datasets with `generator = torch.Generator()` for a distributed sampler which needs to make sure datasets are consistent across different cores, for this, this is really necessary for me to use torch generator, based on documentation this generator is not supported with datasets, I really need to make shuffle work with this generator and I was wondering what I can do about this issue, thanks for your help
@lhoestq | 1,611 |
https://github.com/huggingface/datasets/issues/1610 | shuffle does not accept seed | [
"Hi, did you check the doc on `shuffle`?\r\nhttps://huggingface.co/docs/datasets/package_reference/main_classes.html?datasets.Dataset.shuffle#datasets.Dataset.shuffle",
"Hi Thomas\r\nthanks for reponse, yes, I did checked it, but this does not work for me please see \r\n\r\n```\r\n(internship) rkarimi@italix17:/idiap/user/rkarimi/dev$ python \r\nPython 3.7.9 (default, Aug 31 2020, 12:42:55) \r\n[GCC 7.3.0] :: Anaconda, Inc. on linux\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> import datasets \r\n2020-12-20 01:48:50.766004: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory\r\n2020-12-20 01:48:50.766029: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.\r\n>>> data = datasets.load_dataset(\"scitail\", \"snli_format\")\r\ncahce dir /idiap/temp/rkarimi/cache_home_1/datasets\r\ncahce dir /idiap/temp/rkarimi/cache_home_1/datasets\r\nReusing dataset scitail (/idiap/temp/rkarimi/cache_home_1/datasets/scitail/snli_format/1.1.0/fd8ccdfc3134ce86eb4ef10ba7f21ee2a125c946e26bb1dd3625fe74f48d3b90)\r\n>>> data.shuffle(seed=2)\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\nTypeError: shuffle() got an unexpected keyword argument 'seed'\r\n\r\n```\r\n\r\ndatasets version\r\n`datasets 1.1.2 <pip>\r\n`\r\n",
"Thanks for reporting ! \r\n\r\nIndeed it looks like an issue with `suffle` on `DatasetDict`. We're going to fix that.\r\nIn the meantime you can shuffle each split (train, validation, test) separately:\r\n```python\r\nshuffled_train_dataset = data[\"train\"].shuffle(seed=42)\r\n```\r\n"
] | Hi
I need to shuffle the dataset, but this needs to be based on epoch+seed to be consistent across the cores, when I pass seed to shuffle, this does not accept seed, could you assist me with this? thanks @lhoestq
| 1,610 |
https://github.com/huggingface/datasets/issues/1609 | Not able to use 'jigsaw_toxicity_pred' dataset | [
"Hi @jassimran,\r\nThe `jigsaw_toxicity_pred` dataset has not been released yet, it will be available with version 2 of `datasets`, coming soon.\r\nYou can still access it by installing the master (unreleased) version of datasets directly :\r\n`pip install git+https://github.com/huggingface/datasets.git@master`\r\nPlease let me know if this helps",
"Thanks.That works for now."
] | When trying to use jigsaw_toxicity_pred dataset, like this in a [colab](https://colab.research.google.com/drive/1LwO2A5M2X5dvhkAFYE4D2CUT3WUdWnkn?usp=sharing):
```
from datasets import list_datasets, list_metrics, load_dataset, load_metric
ds = load_dataset("jigsaw_toxicity_pred")
```
I see below error:
> FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/datasets/load.py in prepare_module(path, script_version, download_config, download_mode, dataset, force_local_path, **download_kwargs)
280 raise FileNotFoundError(
281 "Couldn't find file locally at {}, or remotely at {} or {}".format(
--> 282 combined_path, github_file_path, file_path
283 )
284 )
FileNotFoundError: Couldn't find file locally at jigsaw_toxicity_pred/jigsaw_toxicity_pred.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py | 1,609 |
https://github.com/huggingface/datasets/issues/1605 | Navigation version breaking | [
"Not relevant for our current docs :)."
] | Hi,
when navigating docs (Chrome, Ubuntu) (e.g. on this page: https://huggingface.co/docs/datasets/loading_metrics.html#using-a-custom-metric-script) the version control dropdown has the wrong string displayed as the current version:

**Edit:** this actually happens _only_ if you open a link to a concrete subsection.
IMO, the best way to fix this without getting too deep into the intricacies of retrieving version numbers from the URL would be to change [this](https://github.com/huggingface/datasets/blob/master/docs/source/_static/js/custom.js#L112) line to:
```
let label = (version in versionMapping) ? version : stableVersion
```
which delegates the check to the (already maintained) keys of the version mapping dictionary & should be more robust. There's a similar ternary expression [here](https://github.com/huggingface/datasets/blob/master/docs/source/_static/js/custom.js#L97) which should also fail in this case.
I'd also suggest swapping this [block](https://github.com/huggingface/datasets/blob/master/docs/source/_static/js/custom.js#L80-L90) to `string.contains(version) for version in versionMapping` which might be more robust. I'd add a PR myself but I'm by no means competent in JS :)
I also have a side question wrt. docs versioning: I'm trying to make docs for a project which are versioned alike to your dropdown versioning. I was wondering how do you handle storage of multiple doc versions on your server? Do you update what `https://huggingface.co/docs/datasets` points to for every stable release & manually create new folders for each released version?
So far I'm building & publishing (scping) the docs to the server with a github action which works well for a single version, but would ideally need to reorder the public files triggered on a new release. | 1,605 |