

metadata
license: cc-by-nc-sa-4.0
task_categories:
- text-classification
language:
- ar
tags:
- Social Media
- News Media
- Sentiment
- Stance
- Emotion
pretty_name: >-
LlamaLens: Specialized Multilingual LLM for Analyzing News and Social Media
Content -- Arabic
size_categories:
- 10K<n<100K
dataset_info:
- config_name: SANADAkhbarona-news-categorization
splits:
- name: train
num_examples: 62210
- name: dev
num_examples: 7824
- name: test
num_examples: 7824
- config_name: CT22Harmful
splits:
- name: train
num_examples: 2484
- name: dev
num_examples: 1076
- name: test
num_examples: 1201
- config_name: Mawqif-Arabic-Stance-main
splits:
- name: train
num_examples: 3162
- name: dev
num_examples: 950
- name: test
num_examples: 560
- config_name: CT22Claim
splits:
- name: train
num_examples: 3513
- name: dev
num_examples: 339
- name: test
num_examples: 1248
- config_name: annotated-hatetweets-4-classes
splits:
- name: train
num_examples: 210525
- name: dev
num_examples: 90543
- name: test
num_examples: 100564
- config_name: ar_reviews_100k
splits:
- name: train
num_examples: 69998
- name: dev
num_examples: 10000
- name: test
num_examples: 20000
- config_name: Arafacts
splits:
- name: train
num_examples: 4354
- name: dev
num_examples: 623
- name: test
num_examples: 1245
- config_name: OSACT4SubtaskA
splits:
- name: train
num_examples: 4780
- name: dev
num_examples: 2047
- name: test
num_examples: 1827
- config_name: SANADAlArabiya-news-categorization
splits:
- name: train
num_examples: 56967
- name: dev
num_examples: 7120
- name: test
num_examples: 7123
- config_name: ArPro
splits:
- name: train
num_examples: 6002
- name: dev
num_examples: 672
- name: test
num_examples: 1326
- config_name: xlsum
splits:
- name: train
num_examples: 37425
- name: dev
num_examples: 4689
- name: test
num_examples: 4689
- config_name: ArSarcasm-v2
splits:
- name: train
num_examples: 8749
- name: dev
num_examples: 3761
- name: test
num_examples: 2996
- config_name: COVID19Factuality
splits:
- name: train
num_examples: 3513
- name: dev
num_examples: 339
- name: test
num_examples: 988
- config_name: Emotional-Tone
splits:
- name: train
num_examples: 7024
- name: dev
num_examples: 1005
- name: test
num_examples: 2009
- config_name: ans-claim
splits:
- name: train
num_examples: 3185
- name: dev
num_examples: 906
- name: test
num_examples: 456
- config_name: ArCyc_OFF
splits:
- name: train
num_examples: 3138
- name: dev
num_examples: 450
- name: test
num_examples: 900
- config_name: CT24_checkworthy
splits:
- name: train
num_examples: 7333
- name: dev
num_examples: 1093
- name: test
num_examples: 610
- config_name: stance
splits:
- name: train
num_examples: 2652
- name: dev
num_examples: 755
- name: test
num_examples: 379
- config_name: NewsHeadline
splits:
- name: train
num_examples: 939
- name: dev
num_examples: 160
- name: test
num_examples: 323
- config_name: NewsCredibilityDataset
splits:
- name: train
num_examples: 8671
- name: dev
num_examples: 1426
- name: test
num_examples: 2730
- config_name: UltimateDataset
splits:
- name: train
num_examples: 133036
- name: dev
num_examples: 19269
- name: test
num_examples: 38456
- config_name: ThatiAR
splits:
- name: train
num_examples: 2446
- name: dev
num_examples: 467
- name: test
num_examples: 748
- config_name: ArSAS
splits:
- name: train
num_examples: 13883
- name: dev
num_examples: 1987
- name: test
num_examples: 3976
- config_name: CT22Attentionworthy
splits:
- name: train
num_examples: 2479
- name: dev
num_examples: 1071
- name: test
num_examples: 1186
- config_name: ASND
splits:
- name: train
num_examples: 74496
- name: dev
num_examples: 11136
- name: test
num_examples: 21942
- config_name: OSACT4SubtaskB
splits:
- name: train
num_examples: 4778
- name: dev
num_examples: 2048
- name: test
num_examples: 1827
- config_name: ArCyc_CB
splits:
- name: train
num_examples: 3145
- name: dev
num_examples: 451
- name: test
num_examples: 900
- config_name: SANADAlkhaleej-news-categorization
splits:
- name: train
num_examples: 36391
- name: dev
num_examples: 4550
- name: test
num_examples: 4550
configs:
- config_name: SANADAkhbarona-news-categorization
data_files:
- split: test
path: SANADAkhbarona-news-categorization/test.json
- split: dev
path: SANADAkhbarona-news-categorization/dev.json
- split: train
path: SANADAkhbarona-news-categorization/train.json
- config_name: CT22Harmful
data_files:
- split: test
path: CT22Harmful/test.json
- split: dev
path: CT22Harmful/dev.json
- split: train
path: CT22Harmful/train.json
- config_name: Mawqif-Arabic-Stance-main
data_files:
- split: test
path: Mawqif-Arabic-Stance-main/test.json
- split: dev
path: Mawqif-Arabic-Stance-main/dev.json
- split: train
path: Mawqif-Arabic-Stance-main/train.json
- config_name: CT22Claim
data_files:
- split: test
path: CT22Claim/test.json
- split: dev
path: CT22Claim/dev.json
- split: train
path: CT22Claim/train.json
- config_name: annotated-hatetweets-4-classes
data_files:
- split: test
path: annotated-hatetweets-4-classes/test.json
- split: dev
path: annotated-hatetweets-4-classes/dev.json
- split: train
path: annotated-hatetweets-4-classes/train.json
- config_name: ar_reviews_100k
data_files:
- split: test
path: ar_reviews_100k/test.json
- split: dev
path: ar_reviews_100k/dev.json
- split: train
path: ar_reviews_100k/train.json
- config_name: Arafacts
data_files:
- split: test
path: Arafacts/test.json
- split: dev
path: Arafacts/dev.json
- split: train
path: Arafacts/train.json
- config_name: OSACT4SubtaskA
data_files:
- split: test
path: OSACT4SubtaskA/test.json
- split: dev
path: OSACT4SubtaskA/dev.json
- split: train
path: OSACT4SubtaskA/train.json
- config_name: SANADAlArabiya-news-categorization
data_files:
- split: test
path: SANADAlArabiya-news-categorization/test.json
- split: dev
path: SANADAlArabiya-news-categorization/dev.json
- split: train
path: SANADAlArabiya-news-categorization/train.json
- config_name: ArPro
data_files:
- split: test
path: ArPro/test.json
- split: dev
path: ArPro/dev.json
- split: train
path: ArPro/train.json
- config_name: xlsum
data_files:
- split: test
path: xlsum/test.json
- split: dev
path: xlsum/dev.json
- split: train
path: xlsum/train.json
- config_name: ArSarcasm-v2
data_files:
- split: test
path: ArSarcasm-v2/test.json
- split: dev
path: ArSarcasm-v2/dev.json
- split: train
path: ArSarcasm-v2/train.json
- config_name: COVID19Factuality
data_files:
- split: test
path: COVID19Factuality/test.json
- split: dev
path: COVID19Factuality/dev.json
- split: train
path: COVID19Factuality/train.json
- config_name: Emotional-Tone
data_files:
- split: test
path: Emotional-Tone/test.json
- split: dev
path: Emotional-Tone/dev.json
- split: train
path: Emotional-Tone/train.json
- config_name: ans-claim
data_files:
- split: test
path: ans-claim/test.json
- split: dev
path: ans-claim/dev.json
- split: train
path: ans-claim/train.json
- config_name: ArCyc_OFF
data_files:
- split: test
path: ArCyc_OFF/test.json
- split: dev
path: ArCyc_OFF/dev.json
- split: train
path: ArCyc_OFF/train.json
- config_name: CT24_checkworthy
data_files:
- split: test
path: CT24_checkworthy/test.json
- split: dev
path: CT24_checkworthy/dev.json
- split: train
path: CT24_checkworthy/train.json
- config_name: stance
data_files:
- split: test
path: stance/test.json
- split: dev
path: stance/dev.json
- split: train
path: stance/train.json
- config_name: NewsHeadline
data_files:
- split: test
path: NewsHeadline/test.json
- split: dev
path: NewsHeadline/dev.json
- split: train
path: NewsHeadline/train.json
- config_name: NewsCredibilityDataset
data_files:
- split: test
path: NewsCredibilityDataset/test.json
- split: dev
path: NewsCredibilityDataset/dev.json
- split: train
path: NewsCredibilityDataset/train.json
- config_name: UltimateDataset
data_files:
- split: test
path: UltimateDataset/test.json
- split: dev
path: UltimateDataset/dev.json
- split: train
path: UltimateDataset/train.json
- config_name: ThatiAR
data_files:
- split: test
path: ThatiAR/test.json
- split: dev
path: ThatiAR/dev.json
- split: train
path: ThatiAR/train.json
- config_name: ArSAS
data_files:
- split: test
path: ArSAS/test.json
- split: dev
path: ArSAS/dev.json
- split: train
path: ArSAS/train.json
- config_name: CT22Attentionworthy
data_files:
- split: test
path: CT22Attentionworthy/test.json
- split: dev
path: CT22Attentionworthy/dev.json
- split: train
path: CT22Attentionworthy/train.json
- config_name: ASND
data_files:
- split: test
path: ASND/test.json
- split: dev
path: ASND/dev.json
- split: train
path: ASND/train.json
- config_name: OSACT4SubtaskB
data_files:
- split: test
path: OSACT4SubtaskB/test.json
- split: dev
path: OSACT4SubtaskB/dev.json
- split: train
path: OSACT4SubtaskB/train.json
- config_name: ArCyc_CB
data_files:
- split: test
path: ArCyc_CB/test.json
- split: dev
path: ArCyc_CB/dev.json
- split: train
path: ArCyc_CB/train.json
- config_name: SANADAlkhaleej-news-categorization
data_files:
- split: test
path: SANADAlkhaleej-news-categorization/test.json
- split: dev
path: SANADAlkhaleej-news-categorization/dev.json
- split: train
path: SANADAlkhaleej-news-categorization/train.json
LlamaLens: Specialized Multilingual LLM Dataset
Overview
LlamaLens is a specialized multilingual LLM designed for analyzing news and social media content. It focuses on 19 NLP tasks, leveraging 52 datasets across Arabic, English, and Hindi.
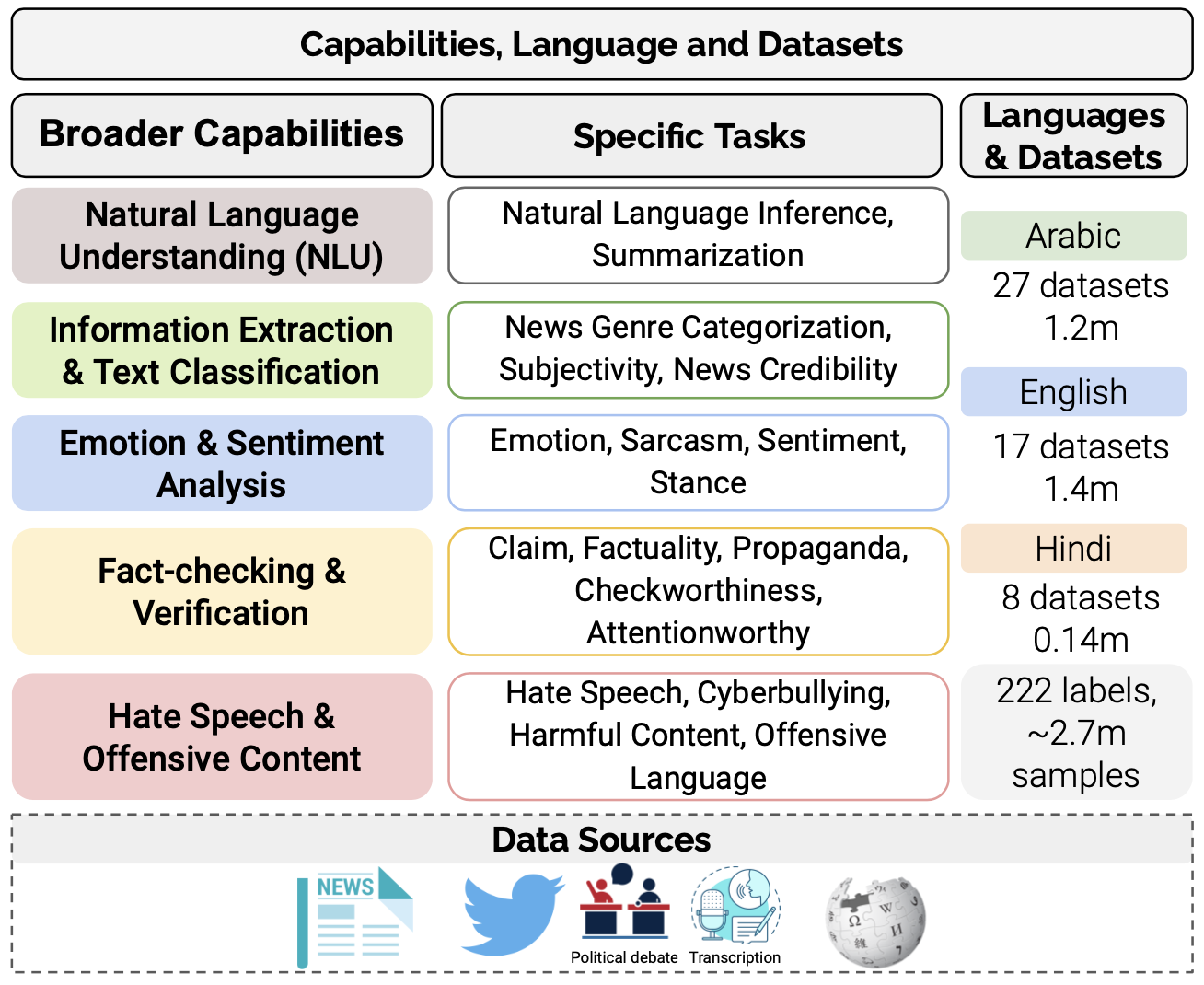
LlamaLens
This repo includes scripts needed to run our full pipeline, including data preprocessing and sampling, instruction dataset creation, model fine-tuning, inference and evaluation.
Features
- Multilingual support (Arabic, English, Hindi)
- 19 NLP tasks with 52 datasets
- Optimized for news and social media content analysis
📂 Dataset Overview
Arabic Datasets
| Task | Dataset | # Labels | # Train | # Test | # Dev |
|---|---|---|---|---|---|
| Attentionworthiness | CT22Attentionworthy | 9 | 2,470 | 1,186 | 1,071 |
| Checkworthiness | CT24_T1 | 2 | 22,403 | 500 | 1,093 |
| Claim | CT22Claim | 2 | 3,513 | 1,248 | 339 |
| Cyberbullying | ArCyc_CB | 2 | 3,145 | 900 | 451 |
| Emotion | Emotional-Tone | 8 | 7,024 | 2,009 | 1,005 |
| Emotion | NewsHeadline | 7 | 939 | 323 | 160 |
| Factuality | Arafacts | 5 | 4,354 | 1,245 | 623 |
| Factuality | COVID19Factuality | 2 | 3,513 | 988 | 339 |
| Harmful | CT22Harmful | 2 | 2,484 | 1,201 | 1,076 |
| Hate Speech | annotated-hatetweets-4-classes | 4 | 210,526 | 100,565 | 90,544 |
| Hate Speech | OSACT4SubtaskB | 2 | 4,778 | 1,827 | 2,048 |
| News Genre Categorization | ASND | 10 | 74,496 | 21,942 | 11,136 |
| News Genre Categorization | SANADAkhbarona | 7 | 62,210 | 7,824 | 7,824 |
| News Genre Categorization | SANADAlArabiya | 6 | 56,967 | 7,123 | 7,120 |
| News Genre Categorization | SANADAlkhaleej | 7 | 36,391 | 4,550 | 4,550 |
| News Genre Categorization | UltimateDataset | 10 | 133,036 | 38,456 | 19,269 |
| News Credibility | NewsCredibilityDataset | 2 | 8,671 | 2,730 | 1,426 |
| Summarization | xlsum | -- | 37,425 | 4,689 | 4,689 |
| Offensive Language | ArCyc_OFF | 2 | 3,138 | 900 | 450 |
| Offensive Language | OSACT4SubtaskA | 2 | 4,780 | 1,827 | 2,047 |
| Propaganda | ArPro | 2 | 6,002 | 1,326 | 672 |
| Sarcasm | ArSarcasm-v2 | 2 | 8,749 | 2,996 | 3,761 |
| Sentiment | ar_reviews_100k | 3 | 69,998 | 20,000 | 10,000 |
| Sentiment | ArSAS | 4 | 13,883 | 3,976 | 1,987 |
| Stance | Mawqif-Arabic-Stance-main | 2 | 3,162 | 560 | 950 |
| Stance | stance | 3 | 2,652 | 379 | 755 |
| Subjectivity | ThatiAR | 2 | 2,446 | 748 | 467 |
Results
Below, we present the performance of LlamaLens in Arabic compared to existing SOTA (if available) and the Llama-Instruct baseline, The “Δ” (Delta) column here is calculated as (LLamalens – SOTA).
| Task | Dataset | Metric | SOTA | Llama-instruct | LLamalens | Δ (LLamalens - SOTA) |
|---|---|---|---|---|---|---|
| News Summarization | xlsum | R-2 | 0.137 | 0.034 | 0.075 | -0.062 |
| News Genre | ASND | Ma-F1 | 0.770 | 0.587 | 0.938 | 0.168 |
| News Genre | SANADAkhbarona | Acc | 0.940 | 0.784 | 0.922 | -0.018 |
| News Genre | SANADAlArabiya | Acc | 0.974 | 0.893 | 0.986 | 0.012 |
| News Genre | SANADAlkhaleej | Acc | 0.986 | 0.865 | 0.967 | -0.019 |
| News Genre | UltimateDataset | Ma-F1 | 0.970 | 0.376 | 0.883 | -0.087 |
| News Credibility | NewsCredibility | Acc | 0.899 | 0.455 | 0.494 | -0.405 |
| Emotion | Emotional-Tone | W-F1 | 0.658 | 0.358 | 0.748 | 0.090 |
| Emotion | NewsHeadline | Acc | 1.000 | 0.406 | 0.551 | -0.449 |
| Sarcasm | ArSarcasm-v2 | F1_Pos | 0.584 | 0.477 | 0.307 | -0.277 |
| Sentiment | ar_reviews_100k | F1_Pos | – | 0.343 | 0.665 | – |
| Sentiment | ArSAS | Acc | 0.920 | 0.603 | 0.795 | -0.125 |
| Stance | stance | Ma-F1 | 0.767 | 0.608 | 0.936 | 0.169 |
| Stance | Mawqif-Arabic-Stance | Ma-F1 | 0.789 | 0.764 | 0.867 | 0.078 |
| Att.worthiness | CT22Attentionworthy | W-F1 | 0.412 | 0.158 | 0.544 | 0.132 |
| Checkworthiness | CT24_T1 | F1_Pos | 0.569 | 0.404 | 0.877 | 0.308 |
| Claim | CT22Claim | Acc | 0.703 | 0.581 | 0.778 | 0.075 |
| Factuality | Arafacts | Mi-F1 | 0.850 | 0.210 | 0.534 | -0.316 |
| Factuality | COVID19Factuality | W-F1 | 0.831 | 0.492 | 0.781 | -0.050 |
| Propaganda | ArPro | Mi-F1 | 0.767 | 0.597 | 0.762 | -0.005 |
| Cyberbullying | ArCyc_CB | Acc | 0.863 | 0.766 | 0.753 | -0.110 |
| Harmfulness | CT22Harmful | F1_Pos | 0.557 | 0.507 | 0.508 | -0.049 |
| Hate Speech | annotated-hatetweets-4 | W-F1 | 0.630 | 0.257 | 0.549 | -0.081 |
| Hate Speech | OSACT4SubtaskB | Mi-F1 | 0.950 | 0.819 | 0.802 | -0.148 |
| Offensive | ArCyc_OFF | Ma-F1 | 0.878 | 0.489 | 0.652 | -0.226 |
| Offensive | OSACT4SubtaskA | Ma-F1 | 0.905 | 0.782 | 0.899 | -0.006 |
File Format
Each JSONL file in the dataset follows a structured format with the following fields:
id: Unique identifier for each data entry.original_id: Identifier from the original dataset, if available.input: The original text that needs to be analyzed.output: The label assigned to the text after analysis.dataset: Name of the dataset the entry belongs.task: The specific task type.lang: The language of the input text.instructions: A brief set of instructions describing how the text should be labeled.text: A formatted structure including instructions and response for the task in a conversation format between the system, user, and assistant, showing the decision process.
Example entry in JSONL file:
{
"id": "d1662e29-11cf-45cb-bf89-fa5cd993bc78",
"original_id": "nan",
"input": "الدفاع الجوي السوري يتصدى لهجوم صاروخي على قاعدة جوية في حمص",
"output": "not_claim",
"dataset": "ans-claim",
"task": "Claim detection",
"lang": "ar",
"instructions": "Analyze the given text and label it as 'claim' if it includes a factual statement that can be verified, or 'not_claim' if it's not a checkable assertion. Return only the label without any explanation, justification or additional text.",
"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>You are a social media expert providing accurate analysis and insights.<|eot_id|><|start_header_id|>user<|end_header_id|>Analyze the given text and label it as 'claim' if it includes a factual statement that can be verified, or 'not_claim' if it's not a checkable assertion. Return only the label without any explanation, justification or additional text.\ninput: الدفاع الجوي السوري يتصدى لهجوم صاروخي على قاعدة جوية في حمص\nlabel: <|eot_id|><|start_header_id|>assistant<|end_header_id|>not_claim<|eot_id|><|end_of_text|>"
}
Model
Replication Scripts
📢 Citation
If you use this dataset, please cite our paper:
@article{kmainasi2024llamalensspecializedmultilingualllm,
title={LlamaLens: Specialized Multilingual LLM for Analyzing News and Social Media Content},
author={Mohamed Bayan Kmainasi and Ali Ezzat Shahroor and Maram Hasanain and Sahinur Rahman Laskar and Naeemul Hassan and Firoj Alam},
year={2024},
journal={arXiv preprint arXiv:2410.15308},
volume={},
number={},
pages={},
url={https://arxiv.org/abs/2410.15308},
eprint={2410.15308},
archivePrefix={arXiv},
primaryClass={cs.CL}
}