Bamba: Inference-Efficient Hybrid Mamba2 Model 🐍






































TL;DR
We introduce Bamba-9B, an inference-efficient Hybrid Mamba2 model trained by IBM, Princeton, CMU, and UIUC on completely open data. At inference time, the model demonstrates 2.5x throughput improvement and 2x latency speedup compared to standard transformers in vLLM. To foster community experimentation, the model is immediately available to use in transformers, vLLM, TRL, and llama.cpp. We also release tuning, training, and extended pretraining recipes with a stateful data loader, and invite the community to further improve this model. Let's overcome the KV-cache bottleneck together!
Artifacts 📦
- Hugging Face Bamba collection
- GitHub repo with inference, training, and tuning scripts
- Data loader
- Quantization
- Auto-pilot for cluster monitoring
Motivation 🌟
Transformer models are increasingly used in real-world applications, but they face memory-bandwidth bottlenecks during inference, particularly during per-token decoding in longer context-length models. Techniques like lower precision, layer pruning, and compression can alleviate the problem, but do not address the root cause, which is the increasing amount of memory required by the KV-cache as the context length increases. Emerging architectures such as Mamba, Griffin, and DeltaNet eliminate this bottleneck by making the KV-cache size constant. The Mamba architecture has gained significant traction in the community in the recent past. For example, Jamba and Samba interleave Mamba layers with transformer layers and explore the resulting hybrid Mamba models. Codestral Mamba, a pure Mamba2 model, demonstrates state-of-the-art (SOTA) results on coding tasks, while NVIDIA's hybrid Mamba2 model achieves competitive performance across long-context and traditional LLM benchmarks. Recent innovations, like Falcon Mamba and Falcon 3 Mamba achieve SOTA rankings on Hugging Face leaderboards at the time of their releases.
We introduce Bamba-9B, a hybrid Mamba2 model trained on 2.2T tokens, further validating these emerging architectures. This collaboration between IBM, Princeton, CMU, and UIUC provides full training lineage, model checkpoints, and pretraining code to support reproducibility and experimentation. The training dataset of the released checkpoints does not contain any benchmark-aligned instruction data (except FLAN) to preserve extended pretraining and fine-tuning flexibility. Our aim is to showcase the hybrid Mamba2 architecture's potential by demonstrating strong performance at lower-mid size model scale (7B-10B) and to provide the community with checkpoints that are fully reproducible and trained with open datasets.
To foster community experimentation, we are also releasing a distributed stateless shuffle data loader and enabling hybrid Mamba2 architecture in open-source libraries like transformers, TRL, vLLM, and llama.cpp. We hope these efforts advance the adoption of Mamba architectures, alleviate KV-cache bottlenecks, and close the gap with SOTA open-source models.
Use in transformers 🤗
To use Bamba with transformers, you can use the familiar AutoModel classes and the generate API. For more details, please follow the instructions outlined in Bamba GitHub.
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("ibm-fms/Bamba-9B")
tokenizer = AutoTokenizer.from_pretrained("ibm-fms/Bamba-9B")
message = ["Mamba is a snake with following properties "]
inputs = tokenizer(message, return_tensors='pt', return_token_type_ids=False)
response = model.generate(**inputs, max_new_tokens=64)
print(tokenizer.batch_decode(response, skip_special_tokens=True)[0])
Evaluations 📊
We divide our evaluations into three parts:
- Comparison with SoTA transformer models
- Comparison with transformer models with similar token budget
- Comparison with other Mamba variants.
Evaluation setup ⚙️ 🖥️: We rerun all the benchmarks following the setup and scripts here for all models except the NVIDIA Mamba2 Hybrid model. We could not run benchmarking for the NVIDIA Mamba2 Hybrid model as the model weights are not in Hugging Face transformers compatible format. Therefore, we report the numbers from the original paper. For the v2 leaderboard results, we perform normalization and report the normalized results. In all the evaluations, higher is better except where indicated.
TL;DR Evals
Bamba-9B demonstrates the competitive performance of hybrid Mamba models compared to transformer models. While it has gaps in math benchmarks and MMLU scores (MMLU, GSM8K, MMLU-PRO, MATH Lvl 5), excluding these benchmarks places its average performance nearly on par with Meta Llama 3.1 8B (44.68 for Llama and 45.53 for Bamba), a model trained on 7x more data. These gaps can be addressed by (a) extending pretraining with more tokens (MMLU scores steadily improved during training), and (b) incorporating high-quality math data in the pretraining/annealing phases. Future plans include using updated datasets like Olmo2 mix and annealing with benchmark-aligned mixes such as Dolmino mix.
Bamba-9B’s results also alleviate concerns of relatively low scores of NVIDIA’s hybrid Mamba2 model in leaderboard benchmarks. The goal of NVIDIA’s study was to compare architectures under identical conditions. Consistent with their findings, Bamba-9B reaffirms that the hybrid Mamba2 architecture offers performance competitive to transformer models while providing up to 5x inference efficiency.
Comparison with SoTA transformer models
We compare Bamba-9B with SoTA transformer models of similar size (Meta Llama 3.1 8B, IBM Granite v3 8B, Olmo2 7B, and Gemma 2 9B). We observe that while there are obvious benchmark gaps, it is not clear that these gaps point to deficiencies in the Mamba/Mamba2 based models. In fact, a careful analysis shows that gaps are largely due to the amount of data used for training models and the inclusion of benchmark-aligned instruction datasets during the annealing phase. For example, we had one small scale run that added metamath and improved our GSM8k score from 36.77 to 60.0. We will publish detailed analysis and our findings in an upcoming paper.
HF OpenLLM v1 leaderboard
HF LLM-V1 + OpenbookQA and PIQA:
| Model | Average | MMLU | ARC-C | GSM8K | Hellaswag | OpenbookQA | Piqa | TruthfulQA | Winogrande |
|---|---|---|---|---|---|---|---|---|---|
| Bamba 9B | 62.31 | 60.77 | 63.23 | 36.77 | 81.8 | 47.6 | 82.26 | 49.21 | 76.87 |
| Meta Llama 3.1 8B | 63.51 | 66.26 | 57.85 | 49.96 | 81.98 | 46.8 | 82.54 | 45.16 | 77.51 |
| Olmo2 7B | 66.17 | 63.96 | 64.51 | 68.01 | 81.93 | 49.2 | 81.39 | 43.32 | 77.03 |
| IBM Granite v3 8B | 67.47 | 65.45 | 63.74 | 62.55 | 83.29 | 47.6 | 83.41 | 52.89 | 80.82 |
| Gemma2 9B | 68.38 | 72.29 | 68.26 | 67.4 | 82.56 | 47.8 | 83.24 | 45.39 | 80.11 |
| Qwen2.5 7B | 70.58 | 75.41 | 63.82 | 83.24 | 80.23 | 48.40 | 81.28 | 56.34 | 75.93 |
HF LLM-V2** :
| Model | Average | MMLU-PRO | BBH | GPQA | IFEval | MATH Lvl 5 | MuSR |
|---|---|---|---|---|---|---|---|
| Bamba 9B | 10.91 | 17.53 | 17.4 | 4.14 | 15.16 | 1.66 | 9.59 |
| Meta Llama 3.1 8B | 14.27 | 25.46 | 25.16 | 8.61 | 12.55 | 5.14 | 8.72 |
| Olmo2 7B | 13.36 | 22.79 | 21.69 | 4.92 | 16.35 | 4.38 | 10.02 |
| IBM Granite v3 8B | 21.14 | 25.83 | 28.02 | 9.06 | 44.79 | 9.82 | 9.32 |
| Gemma2 9B | 21.79 | 34.84 | 34.81 | 11.07 | 21.28 | 13.44 | 15.3 |
| Qwen2.5 7B | 25.13 | 37.62 | 35.62 | 9.96 | 34.77 | 18.35 | 14.6 |
Safety evals
Safety benchmarks are crucial for ensuring AI models generate content that is ethical, inclusive, and non-harmful. We evaluate our model on well known safety benchmarks such as Toxigen (5-shot, logits) (focused on detecting toxic language), BBQ (5-shot, generation), PopQA (5-shot, generation), and CrowS-Pairs (5-shot, logits) (measure bias and fairness). We intend to address these gaps in safety through comprehensive SFT and DPO approaches.
| Model | PopQA | Toxigen | BBQ | Crow-SPairs* |
|---|---|---|---|---|
| Bamba 9B | 20.5 | 57.4 | 44.2 | 70.8 |
| Meta Llama 3.1 8B | 28.77 | 67.02 | 59.97 | 70.84 |
| IBM Granite v3 8B | 27.5 | 79.9 | 82.1 | 75 |
| Olmo2 7B | 25.7 | 63.1 | 58.4 | 72 |
| Olmo1.5 7B | 20.4 | 56.7 | 53.3 | 72.2 |
| Gemma2 9B | 27.3 | 69.6 | 59.9 | 71.7 |
| Qwen2.5 7B | 18.2 | 64.1 | 78.1 | 70 |
*Lower is better
Comparison with transformer models with similar token budget
We pick a few prominent models: Olmo 7B trained on identical data (2024), Meta Llama 2 7B (2023), and IBM Granite 7B (2023), which have been trained to ~2T tokens. Among these transformer models, Olmo 7B has the highest average score across 8 key benchmarks. Bamba-9B outperforms Olmo 7B trained on identical number of tokens and datasets. Since the Bamba-9B model has 9B parameters, a direct comparison is again difficult, but the main takeaway is that hybrid Mamba2 models are competitive with the transformer models trained with similar token budget.
| Model | Average | MMLU | ARC-C | GSM8K | Hellaswag | OpenbookQA | Piqa | TruthfulQA | Winogrande |
|---|---|---|---|---|---|---|---|---|---|
| Bamba 9B (2.2T) | 62.31 | 60.77 | 63.23 | 36.77 | 81.8 | 47.6 | 82.26 | 49.21 | 76.87 |
| Olmo1.5 7B (2T) | 55.8 | 53.38 | 50.51 | 27.67 | 79.13 | 45.2 | 81.56 | 35.92 | 73.09 |
| Bamba 9B (2T) | 59.11 | 59.05 | 57.25 | 24.03 | 83.66 | 47.6 | 83.62 | 38.26 | 79.4 |
| Meta Llama2 7B (2T) | 53.78 | 46.64 | 52.65 | 13.57 | 78.95 | 45.2 | 80.03 | 38.96 | 74.27 |
| IBM Granite 7B (2T) | 52.07 | 49.02 | 49.91 | 10.84 | 77.0 | 40.8 | 80.14 | 38.7 | 70.17 |
Mamba/Mamba2 comparisons
Comparison with Mamba/Mamba2 architecture based language models
Multiple Mamba/Mamba2 architecture based models have started emerging in the last 6 months (e.g., NVIDIA hybrid Mamba2, Codestral Mamba, Falcon Mamba, and Zamba 7B v1) furthering the performance of these architectures and demonstrating their superior inference performance as well as closing the gaps in benchmark results with transformer models. We compare 8 key benchmarks across Bamba-9B, NVIDIA hybrid Mamba2, Zamba, and Falcon Mamba.
Falcon Mamba is a pure Mamba model, Zamba has shared attention layer for every 6 Mamba layers, and Bamba-9B and NVIDIA are both hybrid models with full attention layers interspersed with Mamba2 layers. Falcon Mamba was trained to 5.5T tokens and it performs the best overall but there are open questions on how well it will perform on long-context tasks where Mamba-based architectures truly shine in their inference performance. Zamba was trained on fewer tokens (1T), but with a different hybrid architecture and using benchmark-aligned instruction datasets including those generated from more powerful language models. Bamba-9B and NVIDIA hybrid Mamba2 are quite similar to each other (details on differences are summarized in the model architecture section), but Bamba-9B is trained to 2.2T tokens while NVIDIA Hybrid Mamba is trained to 3.5T tokens.
Note: As of writing this blog, Falcon3 Mamba 7B has landed with even better results than Falcon Mamba. We plan to leverages any learnings from Falcon3 Mamba and improve our next Bamba release.
| Model | Average | MMLU | ARC-C | GSM8K | Hellaswag | OpenbookQA | Piqa | TruthfulQA | Winogrande |
|---|---|---|---|---|---|---|---|---|---|
| Bamba 9B | 62.31 | 60.77 | 63.23 | 36.77 | 81.8 | 47.6 | 82.26 | 49.21 | 76.87 |
| NVIDIA Mamba2 Hybrid 8B* | 58.78 | 53.6 | 47.7 | 77.69 | -- | 42.8 | 79.65 | 38.72 | 71.27 |
| Zamba 7B | 64.36 | 57.85 | 55.38 | 61.33 | 82.27 | 46.8 | 82.21 | 49.69 | 79.32 |
| Falcon Mamba 7B | 65.31 | 63.19 | 63.4 | 52.08 | 80.82 | 47.8 | 83.62 | 53.46 | 78.14 |
* Results are taken from NVIDIA paper.
💡 Note: The differences in training datasets and the number of tokens seen during training make a direct comparison of these models difficult. The key takeaway from this table is that hybrid Mamba2 architectures can deliver competitive results while being nearly as efficient to train as transformer models. Furthermore, they can deliver significant improvement (theoretically up to 5x) in inference efficiency despite having full attention layers interspersed with Mamba2 layers. We are continuing to pretrain the Bamba-9B model with the latest datasets and plan to release future checkpoints as the model improves.
Inference efficiency ⚡🏎️
The KV-cache bottleneck is a major challenge for large language models, prompting solutions like quantization, pruning, and novel architectures such as Mamba2, Linear Transformers, and RetNets. Realizing inference efficiencies at scale, even with standard transformers, often requires custom kernels. Bamba-9B builds on the community momentum of kernel availability, with further improvements made through integration with the vLLM model-serving framework.
Our progress in vLLM integration, tracked via this PR, benchmarks Bamba-9B against Meta Llama 3.1 8B on an NVIDIA H100 80GB GPU. Using input sizes of 1K tokens and output sizes ranging from 2K to 64K across various batch sizes, we measured throughput (tokens/second) and latency. Results show that as batch size and sequence length increase, Bamba-9B achieves up to 2-2.5x better throughput and latency compared to transformer models. These gains enhance real-time applications and GPU utilization, with higher throughput ratios (>1) and lower latency ratios (<1) being beneficial.
 |
|---|
| Figure 1: Throughput improvements of Bamba |
 |
| Figure 2: Latency improvements of Bamba |
Our analysis indicates that on a H100 NVIDIA GPU, we expect 5x speedup when inference shifts to a memory bottleneck (which typically happens in production settings) - see the appendix on Arithmetic Intensity. However, we have not realized this speedup in vLLM yet because of three primary reasons:
- Chunked pre-fill is not supported for Bamba and any Mamba2-based architectures
- Memory allocation assumes standard transformer KV-cache
- Mamba2 kernels are not optimized for H100 GPUs
These issues are being tracked here.
Model architecture
We base our model architecture on the NVIDIA hybrid Mamba2 with the following changes.
| Parameter | Bamba 9B | NVIDIA hybrid Mamba2 8B |
|---|---|---|
| Num layers | 32 | 29 |
| Num attention layers | 3 | 4 |
| Num Mamba2 layers | 29 | 25 |
| MLP expansion factor | 3.5 | 4 |
| Vocab size | 128k | 256k |
| Non-embedding parameters | 8.8B | 8.6B |
| RoPE | yes | no |
| Gated linear units | yes | no |
We have a total of 8B parameters in the Mamba2 layers, 800M in full attention layers, and 1B in embeddings. The hidden state is 4K, GQA for full attention with 8 KV-heads and 32 heads, Mamba2 layer head dimension is 64, and convolution filter size is 4. The most significant change between the two models is reducing the full attention layers from 4 in the NVIDIA hybrid Mamba2 model to 3 in Bamba-9B and introduction of the RoPE embeddings.
Data
Open-source data has come a long way since the inception of The Pile dataset. When we started training this model, the best open-source data was Dolma v1.7, which was shown to be quite performant through the Olmo models and ablations by the Hugging Face data team. Since then, several other higher quality open source datasets have been released, such as DCLM, FineWeb-2, and Olmo2 mix.
We use Dolma v1.7 for the first phase of training, and the chosen data mixes are illustrated below. For the second phase of training, we use Fineweb-edu and Cosmopedia. These datasets are downloaded in their raw form and we tokenize them using the Ray framework running on an internal large scale Red Hat Open Shift cluster. We plan to release the tokenized and formatted parquet data soon for reproducibility.
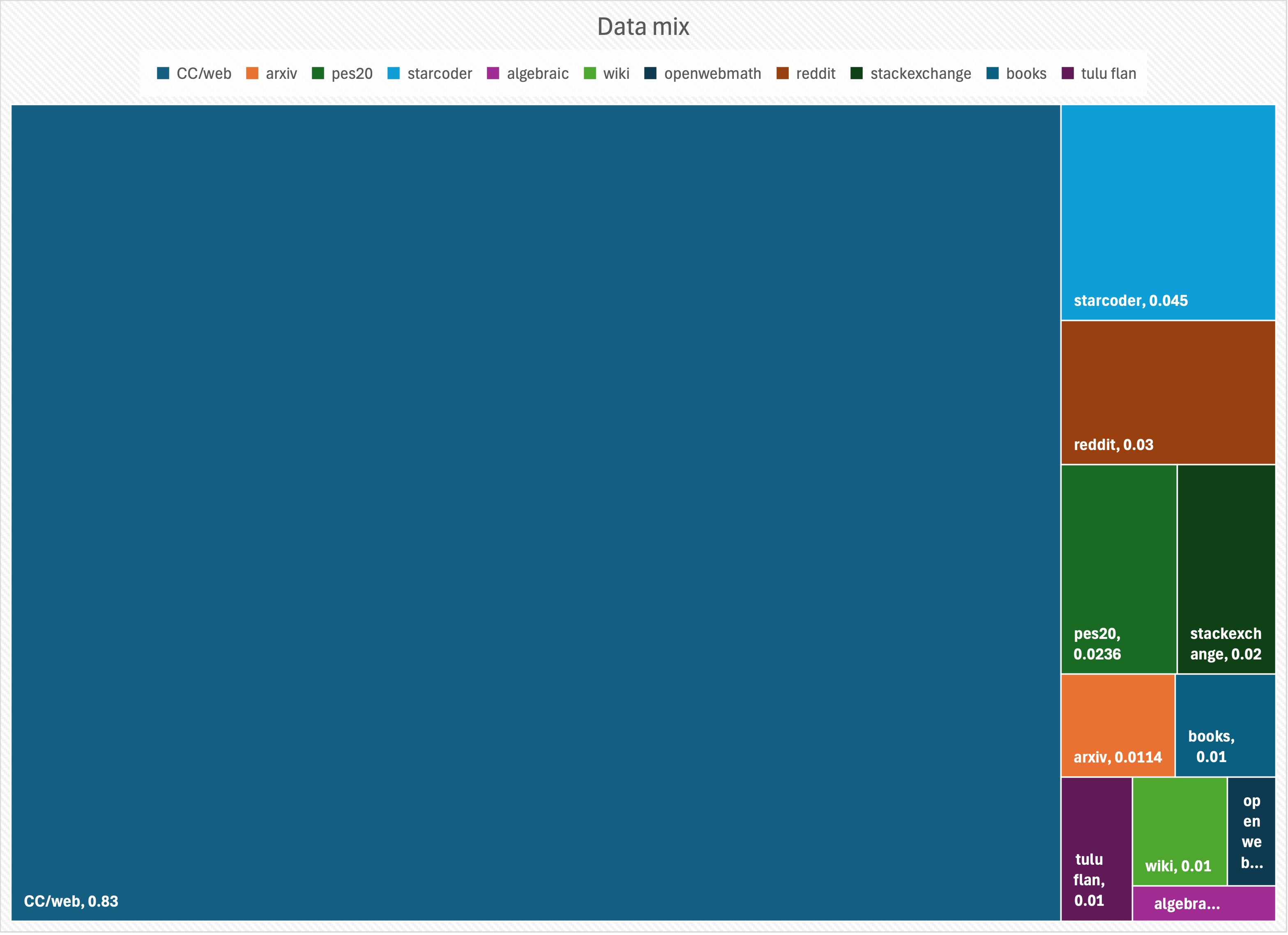
Data mix for pretraining phase one
Pre-Training
Pre-training Bamba was done in a phased manner, we performed several ablation experiments at 1.8B model size and 100B tokens to determine the right learning rates. Based on the promising results from this study, we trained a larger scale model - 3B to 2T tokens using Dolma mix. We also trained a 3B transformer model following Meta Llama architecture with the same data mix and observed similar or better performance for the Bamba model, which is inline with the conclusion reached by the NVIDIA study performed concurrently. Finally, we designed a 9B model architecture and retrained on the same mix. PyTorch FSDP was used to train all our models.
Training details: We used a cosine learning rate schedule, with a peak learning rate of
3e−4, a quadratic warmup over 2000 steps, decay factor of 0.033, and an ending learning rate of1e−5over 2T tokens. We used the AdamW optimizer withβ1of 0.9 andβ2of 0.95. We used a weight decay of 0.1, sequence length of 4096, and a global batch size of 1.5M tokens/batch. We used 192 A100 GPUs from the IBM Cloud Vela production cluster to train this model over a period of 2 months. This cluster is managed by Red Hat OpenShift. We experienced 3 job interruptions, which were attributed to an incorrect deployment of jobs and hardware failures. The hardware-related job failures were detected automatically using autopilot.We also performed a second phase training with high quality data from Hugging Face FineWeb-edu and Cosmopedia for an additional 200B tokens. We used a learning rate of 2e−5 and a cosine schedule to anneal the model, which helped improve our scores. We are currently experimenting with additional high quality data and will release any future checkpoints as part of our commitment to open source.
Data loader
There are several aspects to training a high-quality language model, data loader is an important one. Over the past 18 months we have been working on a data loader that satisfies the demands of large scale distributed training. We open source this data loader to enable others to use it in conjunction with their framework of choice. We have used it in the Bamba model training, and integrated it with Torch Titan. To date, we believe this is the only open source data loader that provides a rich set of features.
The data loader provides the following key features:
- Stateful and checkpointable to ensure seamless resumption mid-epoch
- Auto-rescales to changing workload and GPU allocations
- Data streaming with zero-overhead for shuffling
- Asynchronous distributed operation with no peer-to-peer communication
- Allows for dynamic data mixing and on-the-fly tokenization
- PyTorch native, modular, and extensible
We have battle tested this data loader over hundreds of training jobs and optimized it over months of continuous operation. The primary code base is located in our repo here and we have also worked with the Torch Titan team to make it available here. We are working with the Meta PyTorch team to contribute this data loader into core PyTorch.
Quantization
We recently open sourced a framework for quantization of models. Through this framework, we leverage the llm-compressor to quantize the Bamba checkpoints to fp8. We observed minimal loss in accuracy across all the benchmarks of the OpenLLM leaderboards. Specifically, for the Bamba 9B, a negligible difference of 0.1 between the average scores for V1 (from 62.31 to 61.5), and for V2 drop of 0.9 in the average (10.91 to 10.04). These quantized checkpoints are also released along with the bf16 counterparts. This also validates that Bamba models are amenable to quantization much like SoTA transformer models.
We are in the process of enabling fp8 inference for this model in vLLM, which will require updating the kernels. Linear layers and full attention will be easy to tackle, but the Mamba2 layers will require updates to the Triton/CUDA kernels to handle fp8.
Context length extension
We are currently exploring various approaches to long context length extensions beginning with applying LongRope to the full attention layers. Our preliminary findings using PhoneBook retrieval as the task indicate that LongRoPE can be applied to this model. We extend Bamba-9B's context length by 4x and 8x and compare the context-extended Bamba-9B against three variations of Meta Llama - LLama2, Llama3, LLama3.1, with training context lengths of 4K, 8K, and 128K. The results are plotted below.
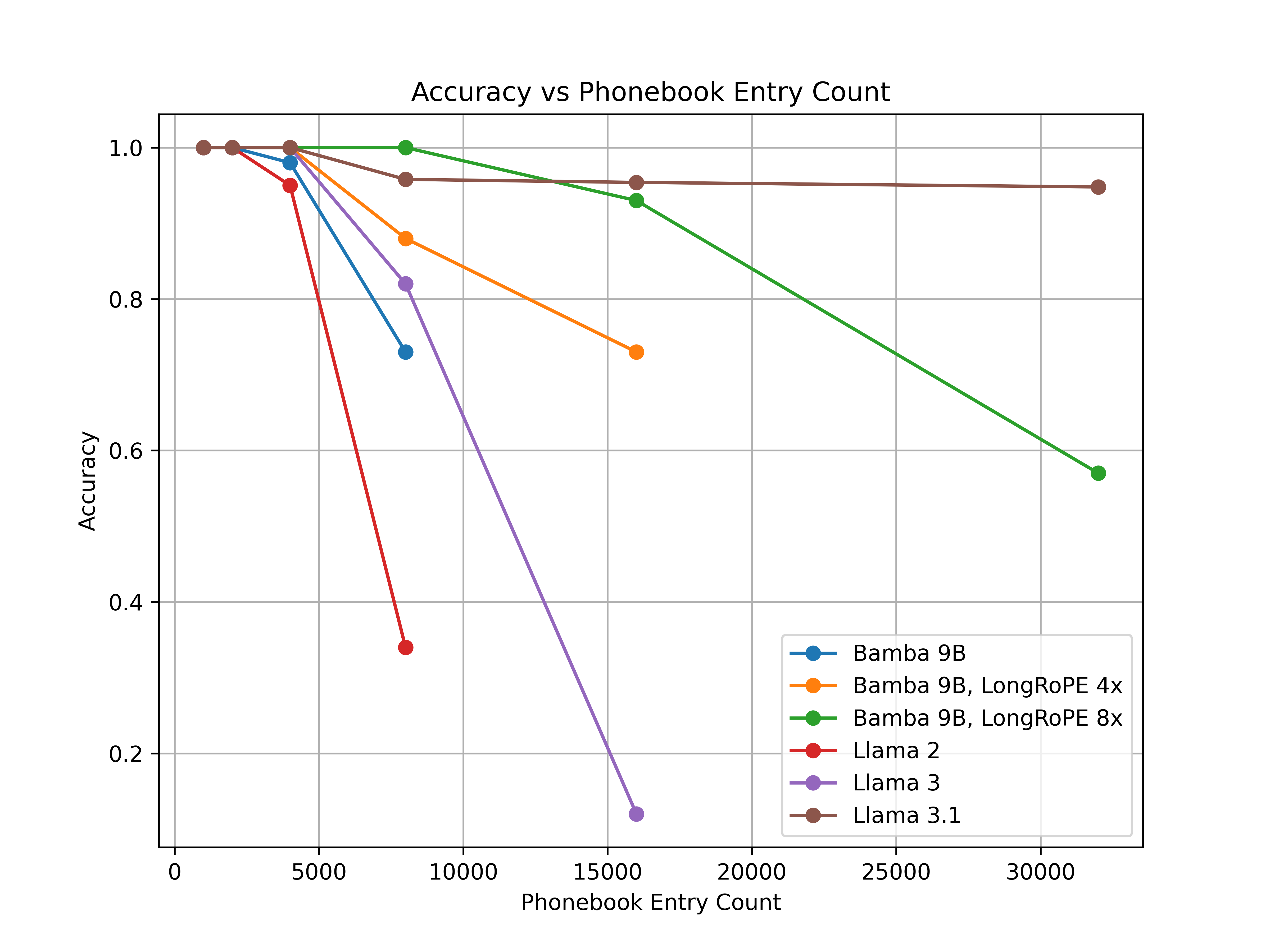
We observe that the context-extended Bamba-9B model performs exceptionally well up to a 16K context length without any tuning, outperforming the original Bamba-9B model, Llama2-7B, and Llama3-8B by a large margin and obtaining comparable performance as Llama3.1-8B. At sequence length 32K, LLama3.1 achieves the best performing result. We plan to release the long context length extended models when ready.
Summary 🎯
Bamba-9B, developed collaboratively by IBM, Princeton, CMU, and UIUC, is a strong performing hybrid Mamba2 model. The model is trained entirely on open datasets and we are releasing intermediate and final checkpoints. To foster community experimentation, the model is immediately available to use in transformers, vLLM, TRL, and llama.cpp. We also release tuning, training, and extended pretraining recipes with a stateful data loader, and invite the community to further improve this model.
Key Takeaways:
Inference Efficiency: Bamba-9B delivers substantial improvements in throughput and latency, enhancing real-time application performance. Benchmarking using vLLM against Llama 3.1 8B demonstrates 2.5x throughput and 2x latency improvements with more coming soon!
Competitive Benchmarks: Bamba-9B performs competitively against state-of-the-art (SoTA) transformer models like Meta Llama 3.1 8B. It matches their average benchmark performance when excluding math and MMLU tasks, with opportunities to close these gaps through extended training and math-focused datasets.
Open Collaboration: The model's development utilized open data, promoting transparency and reproducibility within the AI community.
For more details and access to the model and associated resources, visit the Bamba GitHub repository.
Future work
There are several directions that we intend to explore and further inference-efficient mamab2 hybrid architectures:
- Continue to improve the models through continued pretraining on additional data; We welcome any feedback from the community so we can collectively create a kick-ass Mamba2 hybrid model.
- Perform SFT of base models using SFT datasets such as Tuluv3, agent instruct, and Anteater and compare the resulting model to other state-of-the-art instruction-tuned models.
- vLLM enablement of the model working with the community. The issues on chunked prefill and managing the memory allocation for this architecture will be key.
- Enabling
fp8kernels to make inference even faster. - Training time improvements and applying
torch.compileas well asfp8training, both of which our team has demonstrated on transformer architectures working with Meta. - Long context length extensions up to 1M+
Contributors
- Data collection and curation: We acknowledge and thank AllenAI team for making a high quality open source dataset Dolma as well as Hugging Face data team for making FineWeb-edu and Cosmopedia available. These are tremendous contributions which enabled us to create the model.
- Data preprocessing: We thank IBM's internal data preprocessing team, specifically Tuan Hoang Trong, Syed Zawad, Jay Gala, and Ryan Gordon for helping tokenize the data at scale. The code for tokenization is available here.
- Model architecture: The model architecture design was jointly done by Princeton, CMU, IBM, and UIUC and involved the following folks: Tri Dao (Princeton), Albert Gu (CMU), Linsong Chu (IBM), Davis Wertheimer (IBM), Minjia Zhang (UIUC), Mudhakar Srivatsa (IBM), and Raghu Ganti (IBM).
- Model training: Model training was performed primarily by the IBM team using the Mamba2 kernels and layer implementation from Tri Dao and Albert Gu. The following folks from IBM were primarily involved: Linsong Chu, Divya Kumari, Davis Wertheimer, Raghu Ganti, and Dakshi Agrawal.
- Model tuning: Tuning of the model was enabled and verified in TRL by the IBM team, involving Sukriti Sharma and Anh Uong.
- Model inference: Model inference in
transformers,vLLM, andllama.cppbuilds on the kernels written by Princeton and CMU. The IBM team is working with the community to enable it in various ecosystems. The team includes Fabian Lim, Antoni viros i Martin, Adnan Hoque, Jamie Yang, Nelson Nimura Gonzalez, Joshua Rosenkranz, Nick Hill, and Gabe Goodhart. - Quantization: Quantization is led by the IBM team - Naigang Wang and Charlie Liu.
- Evaluations: Evaluations are led by a team in IBM with long context evaluations being performed by UIUC, involving the following folks: Yotam Perlitz, Ofir Arviv, Michal Shmueli-Scheuer (IBM), Haoechen Shen, and Minjia Zhang (UIUC).
Finally, we would like to thank our leadership for their support in this effort - Priya Nagpurkar, David Cox, Sriram Raghavan, Aya Soffer, Ruchir Puri, and Mukesh Khare.
We would also like to thank the community, in particular Pablo Montalvo-Leroux, Aritra Roy Gosthipaty, and Vaibhav Srivastav from Hugging Face and Stas Bekman from Contextual AI who provided valuable feedback to this blog and the PRs into transformers. Further, we would like to thank Tyler Michael Smith from Neural Magic, who is shepherding the integration with vLLM.
A huge shoutout to Meta PyTorch, AllenAI, and Hugging Face teams for their contributions to the open initative, PyTorch FSDP allowed us to smoothly train this model and the data from Dolma and Fineweb/Cosmopedia made this model today!
Appendix: Arithmetic Intensity
Using the following notation:
$b$: batch size
$s$: sequence length
$h$: hidden state size (4096)
$d$: head dimension (128)
$l$: total number of layers (32)
$l_{attn}$: number of attention layers (3)
$l_{ssd}$: number of SSD layers (29)
Both the attention and Bamba models are configured with GQA of 4:1 (in the attention layers), MLP expansion ratio of 3.5 and use GLU in MLP block. The SSD layer in Bamba is configured with state dimension of $d$, head dimension of $d/2$ and number of heads = $4h/d$. Model size excluding the embedding layer is:
| Model Type | Model Size |
|---|---|
| attention | $13h^2l$ |
| Bamba | $15.5h^2l$ |
At prefill stage the compute and memory (read + write) requirements imposed by the model are:
| Model Type | Compute Prefill | Memory Prefill |
|---|---|---|
| attention | $26bsh^2l + 4bs^2hl$ | $13h^2l + 0.5bshl$ |
| Bamba | $31bsh^2l + 4bs^2hl_{attn} + 4bsdhl_{ssd}$ | $15.5h^2l + 0.5bshl_{attn} + 4bdhl_{ssd}$ |
At decode stage the compute and memory (read + write) requirements imposed by the model are:
| Model Type | Compute Decode | Memory Decode |
|---|---|---|
| attention | $26bh^2l + 4bshl$ | $13h^2l + 0.5bshl$ |
| Bamba | $31bh^2l + 4bshl_{attn} + 4bdhl_{ssd}$ | $15.5h^2l + 0.5bshl_{attn} + 4bdhl_{ssd}$ |
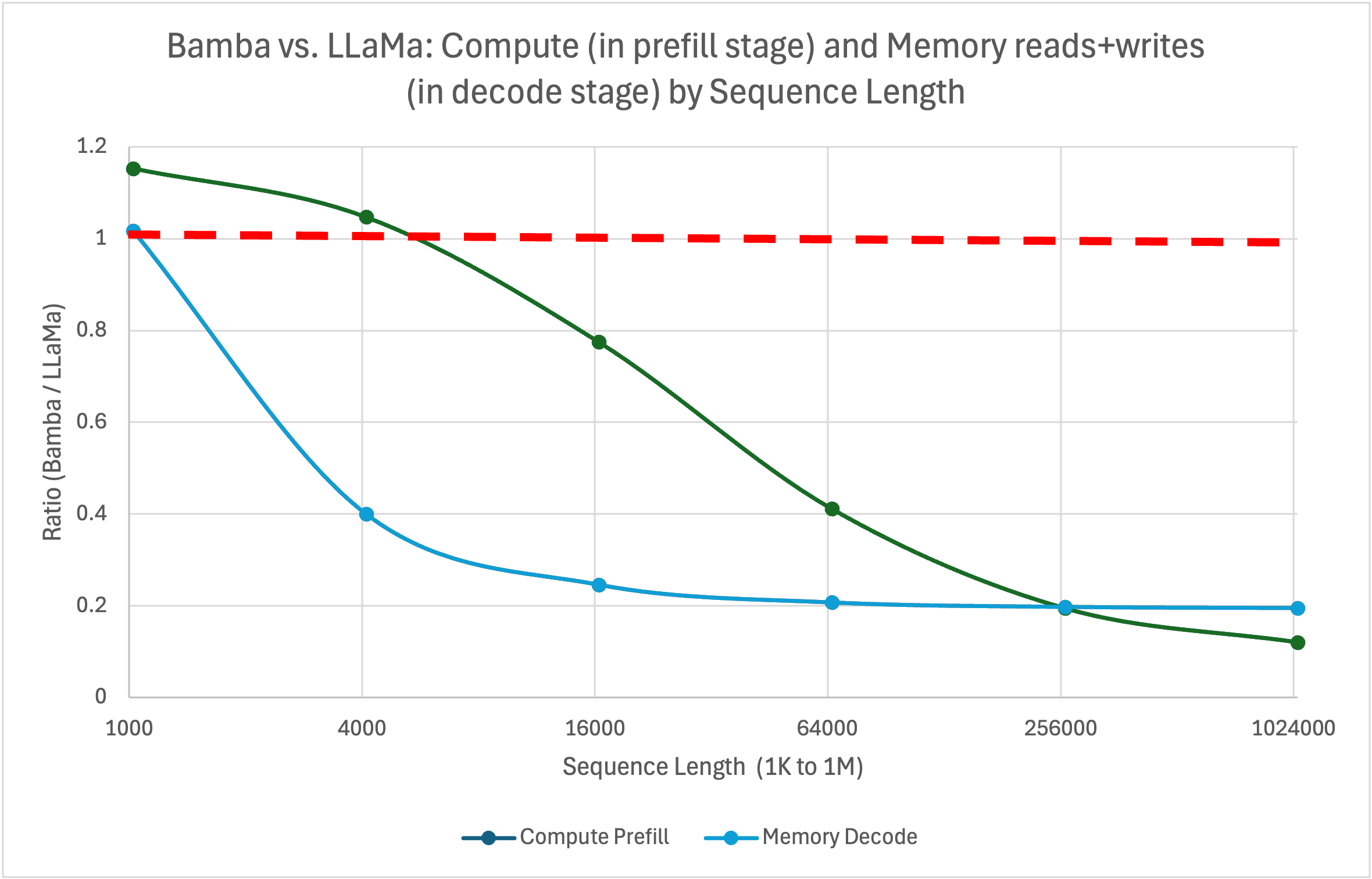
A comparison of compute flops during prefill stage and memory (read+write) sizes during decode stage between Bamba and LLaMa models is shown below. Note that ratios lesser than 1 are beneficial. With inference throughput primarily bottlenecked by decode stage, the potential speedup for Bamba (over LLaMa) is 5x for large sequence lengths (> 16K). Current measurements (on vLLM) hover at 2.5x, which we expect to improve in the near future.