Evaluating Audio Reasoning with Big Bench Audio









The emergence of native Speech to Speech models offers exciting opportunities to increase voice agent capabilities and simplify speech-enabled workflows. However, it's crucial to evaluate whether this simplification comes at the cost of model performance or introduces other trade-offs.
To support analysis of this, Artificial Analysis is releasing Big Bench Audio, a new evaluation dataset for assessing the reasoning capabilities of audio language models. This dataset adapts questions from Big Bench Hard - chosen for its rigorous testing of advanced reasoning - into the audio domain.
This post introduces the Big Bench Audio dataset alongside initial benchmark results for GPT-4o and Gemini 1.5 series models. Our analysis examines these models across multiple modalities: native Speech to Speech, Speech to Text, Text to Speech and Text to Text. We present a summary of results below, and on the new Speech to Speech page on the Artificial Analysis website. Our initial results show a significant "speech reasoning gap": while GPT-4o achieves 92% accuracy on a text-only version of the dataset, its Speech to Speech performance drops to 66%.
The Big Bench Audio Dataset
Big Bench Audio comprises 1,000 audio questions selected from four categories of Big Bench Hard, each chosen for their suitability for audio evaluation:
- Formal Fallacies: Evaluating logical deduction from given statements
- Navigate: Determining if navigation steps return to a starting point
- Object Counting: Counting specific items within collections
- Web of Lies: Evaluating Boolean logic expressed in natural language
Each category contributes 250 questions, creating a balanced dataset that avoids tasks heavily dependent on visual elements or text that could be potentially ambiguous when verbalized.
Each question in the dataset is structured as:
{
"category": "formal_fallacies",
"official_answer": "invalid",
"file_name": "data/question_0.mp3",
"id": 0
}
The audio files were generated using 23 synthetic voices from top-ranked Text to Speech models in the Artifical Analysis Speech Arena. Each audio generation was rigorously verified using Levenshtein distance against transcriptions, and edge cases were reviewed manually. To find out more about how the dataset was created, check out the dataset card.
Evaluating Audio Reasoning
To assess the impact of audio on each model's reasoning performance, we tested four different configurations on Big Bench Audio:
- Speech to Speech: An input audio file is provided and the model generates an output audio file containing the answer.
- Speech to Text: An input audio file is provided and the model generates a text answer.
- Text to Speech: A text version of the question is provided and the model generates an output audio file containing the answer.
- Text to Text: A text version of the question is provided and the model generates a text answer.
Based on these configurations we conducted eighteen experiments:
| Model | Speech to Speech | Speech to Text | Text to Speech | Text to Text |
|---|---|---|---|---|
| GPT-4o Realtime Preview (Oct '24) | ✅ | ✅ | ||
| GPT-4o Realtime Preview (Dec '24) | ✅ | |||
| GPT-4o mini Realtime Preview (Dec '24) | ✅ | |||
| GPT-4o ChatCompletions Audio Preview | ✅ | ✅ | ||
| Speech to Speech Pipeline (whisper, GPT-4o, tts-1)1 | ✅ | |||
| GPT-4o (Aug '24) | ✅ | |||
| Gemini 1.5 Flash (May ‘24) | ✅ | ✅ | ||
| Gemini 1.5 Flash (Sep ‘24) | ✅ | ✅ | ||
| Gemini 1.5 Pro (May ‘24) | ✅ | ✅ | ||
| Gemini 1.5 Pro (Sep ‘24) | ✅ | ✅ | ||
| Gemini 2.0 Flash (Experimental) | ✅ | ✅ |
(Table 1 - Experiment configuration)
Notes:
- An input audio file is transcribed using OpenAI’s Whisper. The transcription is then fed into GPT-4o to generate an answer. This answer is then converted into audio using OpenAI’s TTS-1 model
Evaluation Methodology
To ensure consistent and scalable evaluation across all configurations, we developed an automated assessment system using an LLM Evaluator. Here's how it works:
- For audio responses, we first transcribe them to text using OpenAI's Whisper API
- For text responses, we use them directly as the "candidate answer"
- The LLM Evaluator receives:
- The candidate answer
- The official answer
- The original question (for context)
The LLM Evaluator is provided with the candidate answer, official answer, and original question as context and is prompted to label the candidate answer as either correct or incorrect. We use Anthropic's Claude 3.5 Sonnet (Oct '24) as the LLM evaluator for the Big Bench Audio scores listed on Artificial Analysis.
LLM Evaluator Prompt:
Assess whether the following CANDIDATE ANSWER is CORRECT or INCORRECT.
For the CANDIDATE ANSWER to be correct, it must be consistent with the OFFICIAL ANSWER.
If the CANDIDATE ANSWER contradicts itself, assess the first proposed answer.
If the CANDIDATE ANSWER provides a final answer and working, assess the final answer only.
If the CANDIDATE ANSWER includes irrelevant information, assess only the relevant information.
If the CANDIDATE ANSWER includes a numeric value it is ok if it is spelled e.g. 7 or seven
It is ok if the CANDIDATE ANSWER involves a misspelling of a person's name e.g. Leda or Lida, Autry or Audrie.
The question, for reference only: START QUESTION {question} \n\nEND QUESTION
The OFFICIAL ANSWER:{official_answer}
BEGIN CANDIDATE ANSWER TO ASSESS
{candidate_answer}
END CANDIDATE ANSWER TO ASSESS
Reply only with CORRECT or INCORRECT.
Examples
Below are some example responses.
Speech to Speech
Model: GPT-4o, Realtime Preview
Input:
Output:
Is correct:
True
Speech to Speech Pipeline
Model: Speech to Speech Pipeline (whisper, GPT-4o, tts-1)
Input:
Output:
Is correct:
True
Speech to Text
Model: Gemini 1.5 Flash (Sep '24)
Input:
Output:
The argument is deductively valid. The premise states: Every close friend of Myra is neither a cousin of Sue nor a daughter of Tommy. This is a universal statement. The conclusion correctly reverses this statement using contraposition: No cousin of Sue and no daughter of Tommy is a close friend of Myra. This is a valid application of contraposition. If A implies not (Bor C), then (B or C) implies not A. The argument is structured correctly and the conclusion follows logically from the premise.Is correct:
True
Text to Speech
Model: GPT-4o, ChatCompletions Audio Preview
Input:
If you follow these instructions, do you return to the starting point? Turn right. Take 10 steps. Turn around. Take 10 steps. Options: - Yes - No Answer the questionOutput:
Is correct:
True
Text to Text
Model: Gemini 1.5 Pro (Sep '24)
Input:
I have four oranges, a peach, a plum, three apples, three grapes, two raspberries, a nectarine, a strawberry, a blackberry, and a banana. How many fruits do I have?. Answer the question"Output:
You have 18 fruits.Is correct:
True
Results
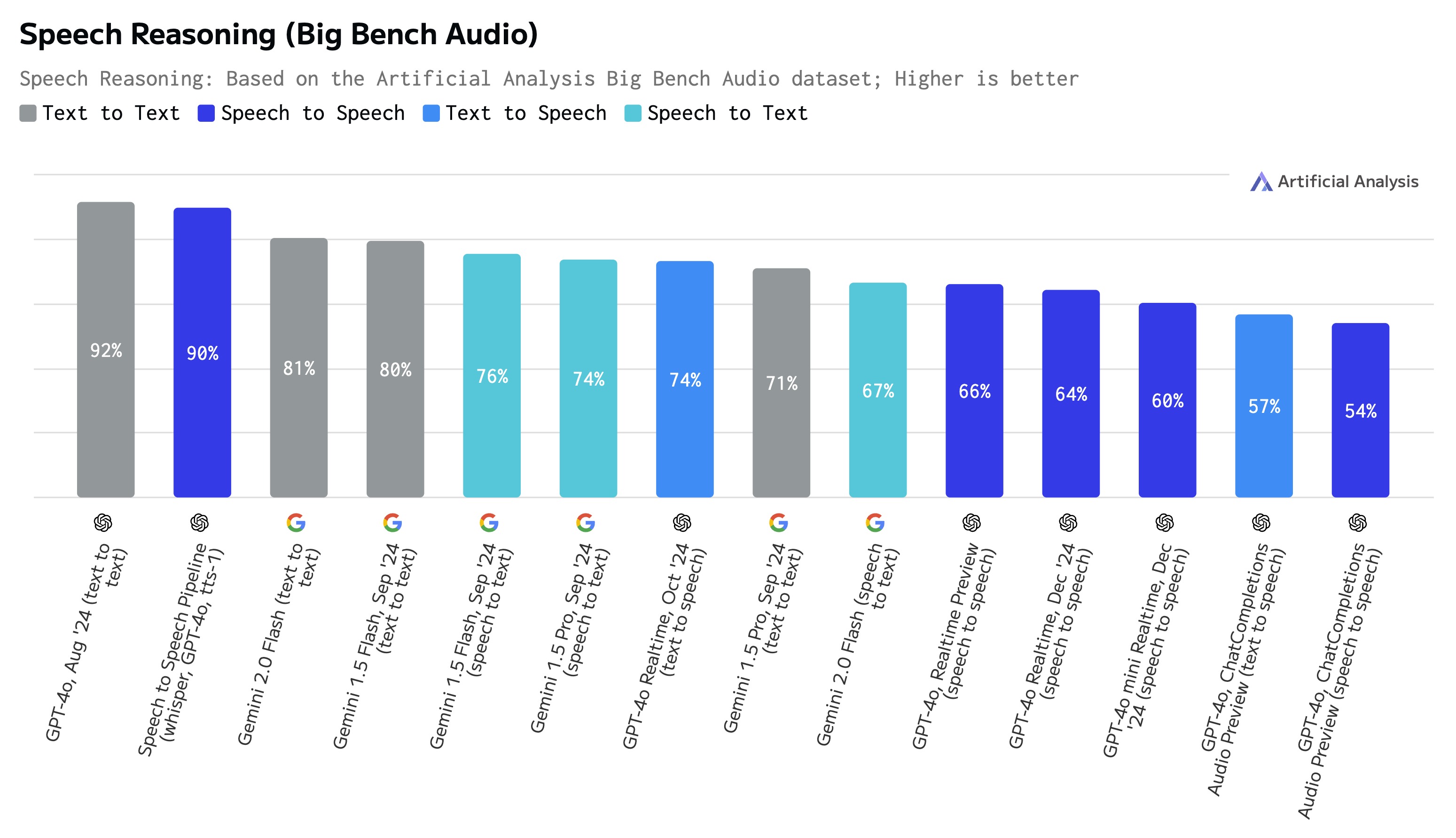
(Figure 1 - Summary of Results)
All results presented represent averages across three independent evaluation runs on each dataset.
The Audio Reasoning Gap
Our analysis reveals a substantial performance gap between text reasoning and audio reasoning. GPT-4o (Aug '24) achieves 92% accuracy in the Text to Text version of the dataset, while its Speech to Speech counterpart (GPT-4o Realtime Preview Oct '24) reaches a score of 66%. The Text to Speech configuration achieves intermediate performance at 74%, indicating that both speech input and speech output are contributing to the performance gap.
Speech to Speech Pipelines Currently Outperform Native Audio for Reasoning
Traditional pipeline approaches (using Whisper for transcription, GPT-4o (Aug '24) for reasoning, and TTS-1 for voice generation) show minimal performance degradation compared to pure text processing. This suggests that for applications where reasoning accuracy is critical, pipeline approaches currently offer the optimal balance of performance and audio capability.
We anticipate that this gap may narrow over time and will continue to test new Speech to Speech models with Big Bench Audio. Look out for an update with Speech to Speech mode for Google's Gemini 2.0 Flash soon!
How to Contribute or Get in Touch
For further analysis of Speech to Speech models, check out the new Speech to Speech page on the Artificial Analysis website: https://artificialanalysis.ai/speech-to-speech.
For updates, follow us on Twitter and LinkedIn. We welcome all feedback and are available via message on Twitter, as well as through the contact form on our website.







