|
--- |
|
license: mit |
|
datasets: |
|
- andythetechnerd03/Vietnamese-Poem-5words |
|
language: |
|
- vi |
|
tags: |
|
- art |
|
--- |
|
# Vietnamese Text Summarization with Poem |
|
Summarize a piece of text with poem. Doesn't it sound fun? </br> |
|
|
|
## Introduction |
|
|
|
Jokes aside, this is a fun project by my team at FPT University about fine-tuning a Large Language Model (LLM) at summarizing a piece of long Vietnamese text in the form of **poems**. We call the model **VistralPoem5**. </br> |
|
Here's a little example: |
|
 |
|
|
|
## HuggingFace 🤗 |
|
``` python |
|
from transformers import AutoTokenizer, AutoModelForCausalLM |
|
|
|
model_name = "andythetechnerd03/VistralPoem5" |
|
tokenizer = AutoTokenizer.from_pretrained(model_name, device_map="auto") |
|
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto") |
|
|
|
inputs = [ |
|
{"role": "system", "content": "Bạn là một nhà thơ chuyên nghiệp, nhiệm vụ của bạn là chuyển bài văn này thành 1 bài thơ 5 chữ từ khoảng 1 đến 3 khổ"}, |
|
{"role": "user", "content": "nhớ tới lời mẹ dặn\nsợ mẹ buồn con đau\nnên tự mình đứng dậy\nnhanh như có phép màu"} |
|
] |
|
|
|
input_ids = tokenizer.apply_chat_template(inputs, return_tensors="pt").to(model.device) |
|
outputs = model.generate( |
|
input_ids=input_ids, |
|
max_new_tokens=200, |
|
do_sample=True, |
|
top_p=0.95, |
|
top_k=20, |
|
temperature=0.1, |
|
repetition_penalty=1.05, |
|
) |
|
|
|
output_str = tokenizer.batch_decode(outputs[:, input_ids.size(1): ], skip_special_tokens=True)[0].strip() |
|
print(output_str) |
|
``` |
|
|
|
## Fine-tuning |
|
|
|
[](https://colab.research.google.com/github/andythetechnerd03/Vietnamese-Text-Summarization-Poem/blob/main/notebooks/fine_tune_with_axolotl.ipynb) |
|
|
|
This is not an easy task. The model we are using is a Vietnamese version of the popular [Mistral-7B](https://arxiv.org/abs/2310.06825) with 7 billion parameters. Obviously, it is very computationally expensive to fine-tune, therefore we applied various state-of-the-art optimization techniques: |
|
- [Flash Attention](https://github.com/Dao-AILab/flash-attention): helps reduce computation complexity of Attention from $O(n^2)$ to $O(n\log n)$ |
|
- [QLoRA (Quantized Low-Rank Adaptation)](https://arxiv.org/abs/2305.14314): train a smaller "adapter" which is a low-rank weight matrices, allowing for less computation. Furthermore, the base model is quantized to only `4-bit`, this is great for storing large models. |
|
- [Mixed Precision Training](https://arxiv.org/abs/1710.03740): here we combine `float32` with `bfloat16` data type for faster training. |
|
|
|
To train the LLM seamlessly as possible, we used a popular open-source fine-tuning platform called [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl). This platform helps you declare the parameters and config and train quickly without much code. |
|
|
|
### Code for fine-tuning model |
|
To customize the configuration, you can modify the `create_file_config.py` file. After making your changes, run the script to generate a personalized configuration file. The following is an example of how to execute the model training: |
|
``` python |
|
cd src |
|
export PYTHONPATH="$PWD" |
|
accelerate launch -m axolotl.cli.train config.yaml |
|
``` |
|
|
|
## Data |
|
This is not easy. Such data that takes the input as a long text (newspaper article, story) and output a poem is very hard to find. So we created our own... by using *prompt engineering*. |
|
|
|
- The collection of poems is straightforward. There are many repositories and prior works that collected a handful of Vietnamese poems, as well as publicly available samples online. We collected from [FPT Software AI Lab](https://github.com/fsoft-ailab/Poem-Generator) and [HuggingFace](https://github.com/fsoft-ailab/Poem-Generator). |
|
- From the poems we use prompt engineering to ask our base model to generate a story from such poem. The prompt is in the form </br> |
|
``` Bạn là một nhà kể chuyện phiếm, nhiệm vụ của bạn là hãy kể 1 câu chuyện đơn giản và ngắn gọn từ một bài thơ, câu chuyện nên là 1 bài liền mạch, thực tế\n\n{insert poem here}``` |
|
- Speaking of prompt engineering, there is another prompt to generate poem from context. </br> |
|
```Bạn là một nhà thơ chuyên nghiệp, nhiệm vụ của bạn là chuyển bài văn này thành 1 bài thơ 5 chữ từ khoảng 1 đến 3 khổ: \n {insert context here}``` |
|
- The pre-processing step is faily simple. A bit of lowercase here, punctuation removal there, plus reducing poems to 1-3 random paragraphs, and we are done. |
|
|
|
After all, we have about 72,101 samples with a ratio of 0.05 (68495 on the train set and 3606 on the test set) |
|
|
|
We published the dataset at [here](https://huggingface.co/datasets/andythetechnerd03/Vietnamese-Poem-5words) |
|
|
|
### Custom Evaluation Data |
|
As part of the final evaluation for benchmark, we gathered around 27 Vietnamese children's stories and divided into many samples, accumulating to 118 samples. The dataset can be found [here](/data/eval_set.json) |
|
|
|
## Model |
|
As mentioned earlier, we use [Vistral-7B-Chat](https://huggingface.co/Viet-Mistral/Vistral-7B-Chat) as the base model and we fine-tune it on our curated dataset earlier. Here's a few configurations: |
|
- The model is based on Transformer’s decoder-only architechture: |
|
- Number of Attention Heads: 32 |
|
- Hidden Size: 4096 |
|
- Vocab size: 38369 |
|
- Data type: bfloat16 |
|
- Number of Hidden Layers (Nx): 32 |
|
- Loss function: Cross-entropy |
|
- Parameter-Efficient Finetuning: QLora |
|
- 4 bit |
|
- Alpha: 16 |
|
- Rank: 32 |
|
- Target: Linear |
|
- Gradient accumulation: 4 |
|
- Learning Rate: 0.0002 |
|
- Warmup Steps: 10 |
|
- LR Scheduler: Cosine |
|
- Max Steps: 400 |
|
- Batch size: 16 |
|
- Optimizer: Adamw bnb 8bit |
|
- Sequence Len: 1096 |
|
|
|
The weights can be found [here](https://huggingface.co/andythetechnerd03/VistralPoem5) |
|
|
|
The notebook for training can be found at `notebook/Fine_tune_LLMs_with_Axolotl.ipynb` |
|
|
|
## Benchmark |
|
We used the custom evaluation dataset to perform benchmark. Since popular metrics such as ROUGE is not applicable to poem format, we chose a simpler approach - counting the probability of 5-word poems in the result. </br> |
|
Here's the result: |
|
| Model | Number of Parameters | Hardware | Probability of 5-word(Higher is better) | Average inference time(Lower is better) | |
|
|----------------------------|----------------------|----------------------|-----------------------------------------|-----------------------------------------| |
|
| Vistral-7B-Chat (baseline) | 7B | 1x Nvidia Tesla A100 | 4.15% | 6.75s | |
|
| Google Gemini Pro* | > 100B | **Multi-TPU** | 18.3% | 3.4s | |
|
| **VistralPoem5 (Ours)** | **7B** | 1x Nvidia Tesla A100 | **61.4%** | **3.14s** | |
|
|
|
* API call, meaning inference time may be affected |
|
|
|
The benchmark code can be found at `notebook/infer_poem_model.ipynb` and `notebook/probability_5word.ipynb` |
|
|
|
|
|
## Deployment |
|
We used Gradio for fast deployment on Google Colab. It should be in `notebook/infer_poem_model.ipynb` as well. |
|
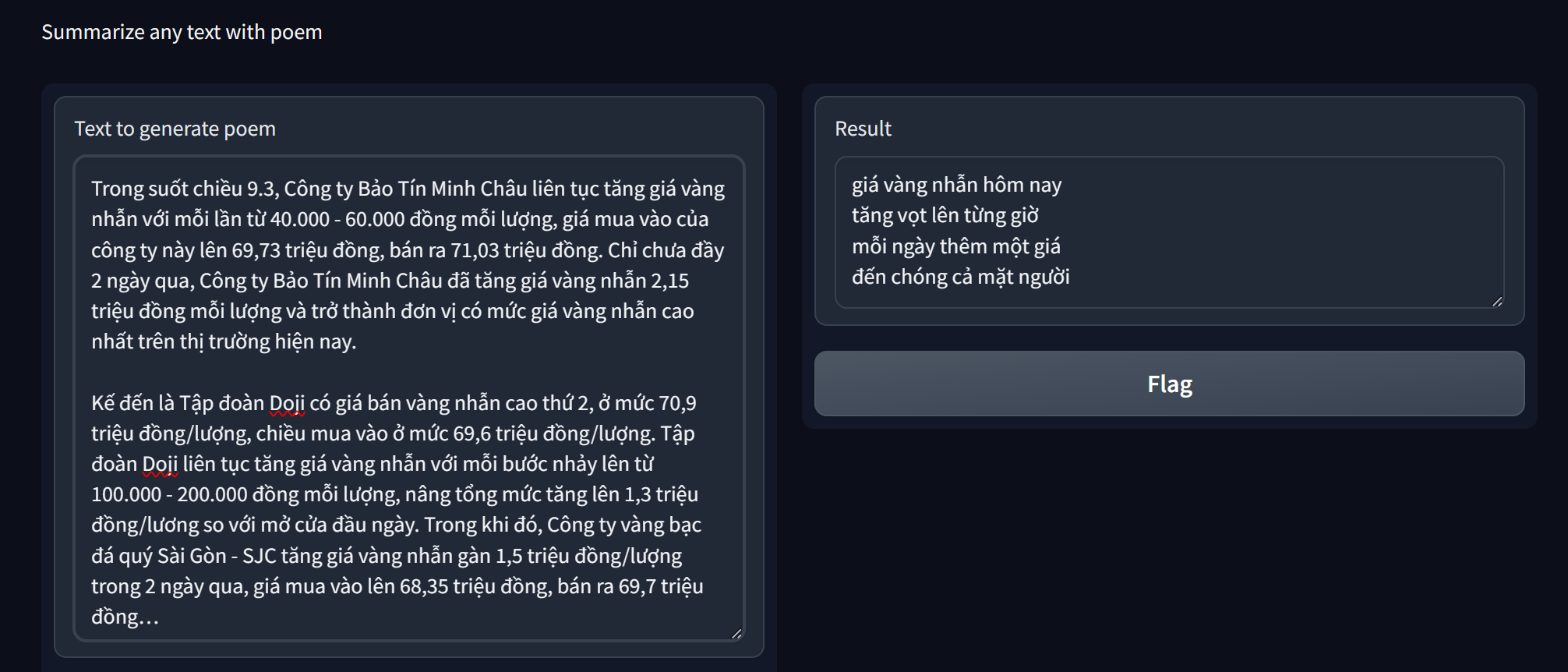 |
|
|
|
Docker Image, coming soon... |
|
## Future Work |
|
- [ ] Make a custom loss function to align rhythm and tones. |
|
- [ ] Use a better metric for evaluating poems (rhythm and content summarization) |
|
- [ ] Use RLHF to align poems with human values. |
|
- [ ] And more... |
|
|
|
## Credits |
|
- [Phan Phuc](https://github.com/pphuc25) for doing the fine-tuning. |
|
- [Me](https://github.com/andythetechnerd03) for designing the pipeline and testing the model. |
|
- [Truong Vo](https://github.com/justinvo277) for collecting the data. |
