

license: other
license_name: sspl
license_link: LICENSE
language:
- en
pipeline_tag: text-classification
tags:
- roberta
- generated_text_detection
- llm_content_detection
- AI_detection
datasets:
- Hello-SimpleAI/HC3
- tum-nlp/IDMGSP
- mlabonne/Evol-Instruct-Python-26k
library_name: transformers
![]()
SuperAnnotate
LLM Content Detector
Fine-Tuned RoBERTa Large
Description
The model designed to detect generated/synthetic text.
At the moment, such functionality is critical for check your training data and detecting fraud and cheating in scientific and educational areas.
Model Details
Model Description
- Model type: The custom architecture for binary sequence classification based on pre-trained RoBERTa, with a single output label.
- Language(s): Primarily English.
- License: Apache 2.0
- Finetuned from model: RoBERTa Large
Model Sources
- Repository: GitHub for HTTP service
Training data
The training data was sourced from three open datasets with different proportions and underwent filtering:
- HC3 | 50%
- IDMGSP | 30%
- Evol-Instruct-Python-26k | 20%
As a result, the training dataset contained approximately 25k pairs of text-label with an approximate balance of classes.
It's worth noting that the dataset's texts follow a logical structure:
Human-written and model-generated texts refer to a single prompt/instruction, though the prompts themselves were not used during training.
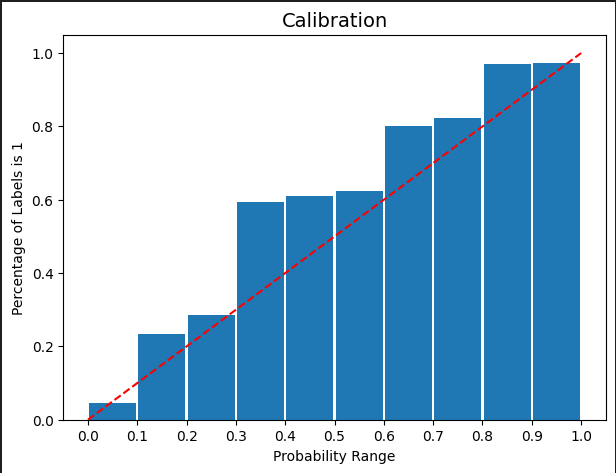
Peculiarity
During training, one of the priorities was not only maximizing the quality of predictions but also avoiding overfitting and obtaining an adequately confident predictor.
We are pleased to achieve the following state of model calibration:
Usage
TODO
Performance
The model was evaluated on a benchmark collected from the same datasets used for training, alongside a closed subset of SuperAnnotate.
However, there are no direct intersections of samples between the training data and the benchmark.
The benchmark comprises 1k samples, with 200 samples per category.
The model's performance is compared with open-source solutions and popular API detectors in the table below:
| Model/API | Wikipedia | Reddit QA | SA instruction | Papers | Code | Average |
|---|---|---|---|---|---|---|
| Hello-SimpleAI | 0.97 | 0.95 | 0.82 | 0.69 | 0.47 | 0.78 |
| RADAR | 0.47 | 0.84 | 0.59 | 0.82 | 0.65 | 0.68 |
| GPTZero | 0.72 | 0.79 | 0.90 | 0.67 | 0.74 | 0.76 |
| Originality.ai | 0.91 | 0.97 | 0.77 | 0.93 | 0.46 | 0.81 |
| LLM content detector | 0.88 | 0.95 | 0.84 | 0.81 | 0.96 | 0.89 |