
Align-Anything
Collection
11 items
•
Updated
•
4
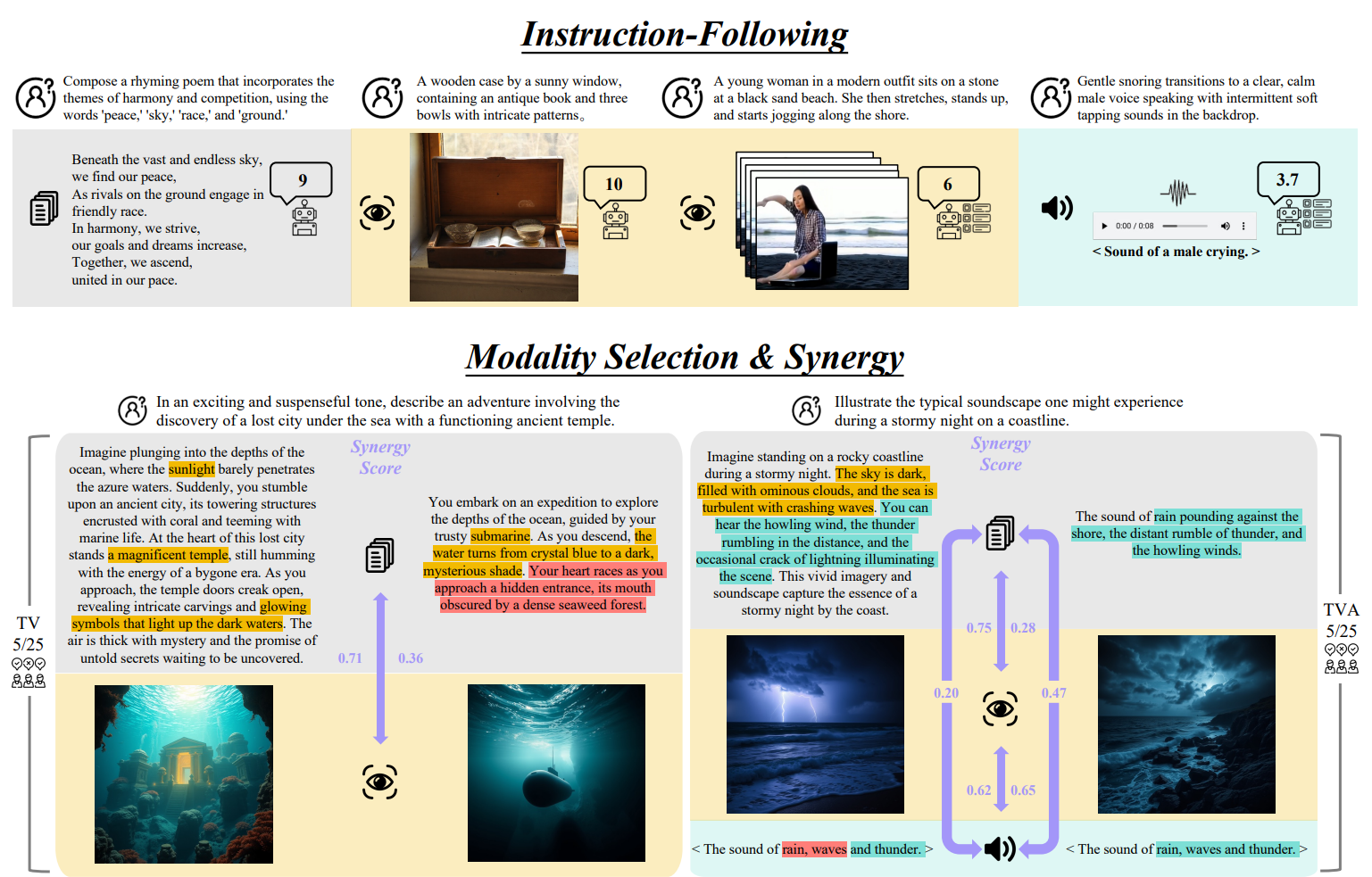
All-Modality Generation benchmark evaluates a model's ability to follow instructions, automatically select appropriate modalities, and create synergistic outputs across different modalities (text, visual, audio) while avoiding redundancy.
🏠 Homepage | 👍 Our Official Code Repo
🤗 All-Modality Understanding Benchmark
🤗 All-Modality Generation Benchmark (Instruction Following Part)
🤗 All-Modality Generation Benchmark (Modality Selection and Synergy Part)
🤗 All-Modality Generation Reward Model
from transformers import AutoModel, AutoProcessor
model = AutoModel.from_pretrained("PKU-Alignment/AnyRewardModel", trust_remote_code=True)
processor = AutoProcessor.from_pretrained("PKU-Alignment/AnyRewardModel", trust_remote_code=True)
For Image-Audio Modality Synergy scoring:
user_prompt: str = 'USER: {input}'
assistant_prompt: str = '\nASSISTANT:\n{modality}{text_response}'
def sigmoid(x):
return 1 / (1 + math.exp(-x))
def process_ia(prompt, image_path, audio_path):
image_pixel_values = processor(data_paths = image_path, modality="image").pixel_values
audio_pixel_values = processor(data_paths = audio_path, modality="audio").pixel_values
text_input = processor(
text = user_prompt.format(input = prompt) + \
assistant_prompt.format(modality = "<image><audio>", text_response = ""),
modality="text"
)
return {
"input_ids": text_input.input_ids,
"attention_mask": text_input.attention_mask,
"pixel_values_1": image_pixel_values.unsqueeze(0),
"pixel_values_2": audio_pixel_values.unsqueeze(0),
"modality": [["image", "audio"]]
}
score = sigmoid(model(**process_ia(prompt, image_path, audio_path)).end_scores.squeeze(dim=-1).item())
For Text-Image Modality Synergy scoring:
user_prompt: str = 'USER: {input}'
assistant_prompt: str = '\nASSISTANT:\n{modality}{text_response}'
def sigmoid(x):
return 1 / (1 + math.exp(-x))
def process_ti(prompt, response, image_path):
image_pixel_values = processor(data_paths = image_path, modality="image").pixel_values
text_input = processor(
text = user_prompt.format(input = prompt) + \
assistant_prompt.format(modality = "<image>", text_response = response),
modality="text"
)
return {
"input_ids": text_input.input_ids,
"attention_mask": text_input.attention_mask,
"pixel_values_1": image_pixel_values.unsqueeze(0),
"modality": [["image", "text"]]
}
score = sigmoid(model(**process_ti(prompt, response, image_path)).end_scores.squeeze(dim=-1).item())
For Text-Audio Modality Synergy scoring:
user_prompt: str = 'USER: {input}'
assistant_prompt: str = '\nASSISTANT:\n{modality}{text_response}'
def sigmoid(x):
return 1 / (1 + math.exp(-x))
def process_ta(prompt, response, audio_path):
audio_pixel_values = processor(data_paths = audio_path, modality="audio").pixel_values
text_input = processor(
text = user_prompt.format(input = prompt) + \
assistant_prompt.format(modality = "<audio>", text_response = response),
modality="text"
)
return {
"input_ids": text_input.input_ids,
"attention_mask": text_input.attention_mask,
"pixel_values_1": audio_pixel_values.unsqueeze(0),
"modality": [["audio", "text"]]
}
score = sigmoid(model(**process_ta(prompt, response, audio_path)).end_scores.squeeze(dim=-1).item())
ftfy
timm
regex
einops
fvcore
decord
torchaudio
torchvision
pytorchvideo
ModuleNotFoundError: No module named 'torchvision.transforms.functional_tensor'
Please refer to guide at blog for detailed resolution steps.
Note: The current code is a sample script for the All-Modality Generation subtask of Eval Anything. In the future, we will integrate Eval Anything's evaluation into the framework to provide convenience for community use.
Please cite our work if you use our benchmark or model in your paper.
@inproceedings{ji2024align,
title={Align Anything: Training All-Modality Models to Follow Instructions with Language Feedback},
author={Jiaming Ji and Jiayi Zhou and Hantao Lou and Boyuan Chen and Donghai Hong and Xuyao Wang and Wenqi Chen and Kaile Wang and Rui Pan and Jiahao Li and Mohan Wang and Josef Dai and Tianyi Qiu and Hua Xu and Dong Li and Weipeng Chen and Jun Song and Bo Zheng and Yaodong Yang},
year={2024},
url={https://arxiv.org/abs/2412.15838}
}