
hawei_LinkedIn
commited on
Commit
·
8da1cd7
1
Parent(s):
851c617
upload model weights and model card
Browse files- .gitattributes +3 -0
- README.md +111 -0
- benchmark_results_code_instruct.json +3 -0
- benchmark_results_original_capability_instruct.json +3 -0
- config.json +3 -0
- evaluation_results.json +3 -0
- generation_config.json +3 -0
- model-00001-of-00005.safetensors +3 -0
- model-00002-of-00005.safetensors +3 -0
- model-00003-of-00005.safetensors +3 -0
- model-00004-of-00005.safetensors +3 -0
- model-00005-of-00005.safetensors +3 -0
- model.safetensors.index.json +3 -0
- plots/catastrophic_forgetting_opencoder.png +3 -0
- special_tokens_map.json +3 -0
- tokenizer.json +3 -0
- tokenizer_config.json +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
*.json filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,114 @@
|
|
| 1 |
---
|
| 2 |
license: llama3.1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: llama3.1
|
| 3 |
+
datasets:
|
| 4 |
+
- nvidia/OpenMathInstruct-2
|
| 5 |
+
language:
|
| 6 |
+
- en
|
| 7 |
+
base_model:
|
| 8 |
+
- meta-llama/Llama-3.1-8B-Instruct
|
| 9 |
+
model-index:
|
| 10 |
+
- name: Control-LLM-Llama3.1-8B-Math16
|
| 11 |
+
results:
|
| 12 |
+
- task:
|
| 13 |
+
type: code-evaluation
|
| 14 |
+
dataset:
|
| 15 |
+
type: mixed
|
| 16 |
+
name: Code Evaluation Dataset
|
| 17 |
+
metrics:
|
| 18 |
+
- name: pass_at_1,n=1 (code_instruct)
|
| 19 |
+
type: pass_at_1
|
| 20 |
+
value: 0.7840083073727934
|
| 21 |
+
stderr: 0.013257237506304915
|
| 22 |
+
verified: false
|
| 23 |
+
- name: pass_at_1,n=1 (humaneval_greedy_instruct)
|
| 24 |
+
type: pass_at_1
|
| 25 |
+
value: 0.8170731707317073
|
| 26 |
+
stderr: 0.03028135999593353
|
| 27 |
+
verified: false
|
| 28 |
+
- name: pass_at_1,n=1 (humaneval_plus_greedy_instruct)
|
| 29 |
+
type: pass_at_1
|
| 30 |
+
value: 0.7439024390243902
|
| 31 |
+
stderr: 0.03418746588364997
|
| 32 |
+
verified: false
|
| 33 |
+
- name: pass_at_1,n=1 (mbpp_plus_0shot_instruct)
|
| 34 |
+
type: pass_at_1
|
| 35 |
+
value: 0.8042328042328042
|
| 36 |
+
stderr: 0.0204357309715418
|
| 37 |
+
verified: false
|
| 38 |
+
- name: pass_at_1,n=1 (mbpp_sanitized_0shot_instruct)
|
| 39 |
+
type: pass_at_1
|
| 40 |
+
value: 0.7587548638132295
|
| 41 |
+
stderr: 0.02673991635681605
|
| 42 |
+
verified: false
|
| 43 |
+
- task:
|
| 44 |
+
type: original-capability
|
| 45 |
+
dataset:
|
| 46 |
+
type: meta/Llama-3.1-8B-Instruct-evals
|
| 47 |
+
name: Llama-3.1-8B-Instruct-evals Dataset
|
| 48 |
+
dataset_path: "meta-llama/llama-3.1-8_b-instruct-evals"
|
| 49 |
+
dataset_name: "Llama-3.1-8B-Instruct-evals__arc_challenge__details"
|
| 50 |
+
metrics:
|
| 51 |
+
- name: exact_match,strict-match (original_capability_instruct)
|
| 52 |
+
type: exact_match
|
| 53 |
+
value: 0.5630801459168563
|
| 54 |
+
stderr: 0.0028483348465514185
|
| 55 |
+
verified: false
|
| 56 |
+
- name: exact_match,strict-match (meta_arc_0shot_instruct)
|
| 57 |
+
type: exact_match
|
| 58 |
+
value: 0.8248927038626609
|
| 59 |
+
stderr: 0.01113972223585952
|
| 60 |
+
verified: false
|
| 61 |
+
- name: exact_match,strict-match (meta_gpqa_0shot_cot_instruct)
|
| 62 |
+
type: exact_match
|
| 63 |
+
value: 0.296875
|
| 64 |
+
stderr: 0.021609729061250887
|
| 65 |
+
verified: false
|
| 66 |
+
- name: exact_match,strict-match (meta_mmlu_0shot_instruct)
|
| 67 |
+
type: exact_match
|
| 68 |
+
value: 0.6815980629539952
|
| 69 |
+
stderr: 0.003931452244804845
|
| 70 |
+
verified: false
|
| 71 |
+
- name: exact_match,strict-match (meta_mmlu_pro_5shot_instruct)
|
| 72 |
+
type: exact_match
|
| 73 |
+
value: 0.4093251329787234
|
| 74 |
+
stderr: 0.004482884901882547
|
| 75 |
+
verified: false
|
| 76 |
---
|
| 77 |
+
# Control-LLM-Llama3.1-8B-Math16
|
| 78 |
+
This is a fine-tuned model of Llama-3.1-8B-Instruct for mathematical tasks on OpenCoder SFT dataset.
|
| 79 |
+
|
| 80 |
+
## Evaluation Results
|
| 81 |
+
Here is an overview of the evaluation results and findings:
|
| 82 |
+
|
| 83 |
+
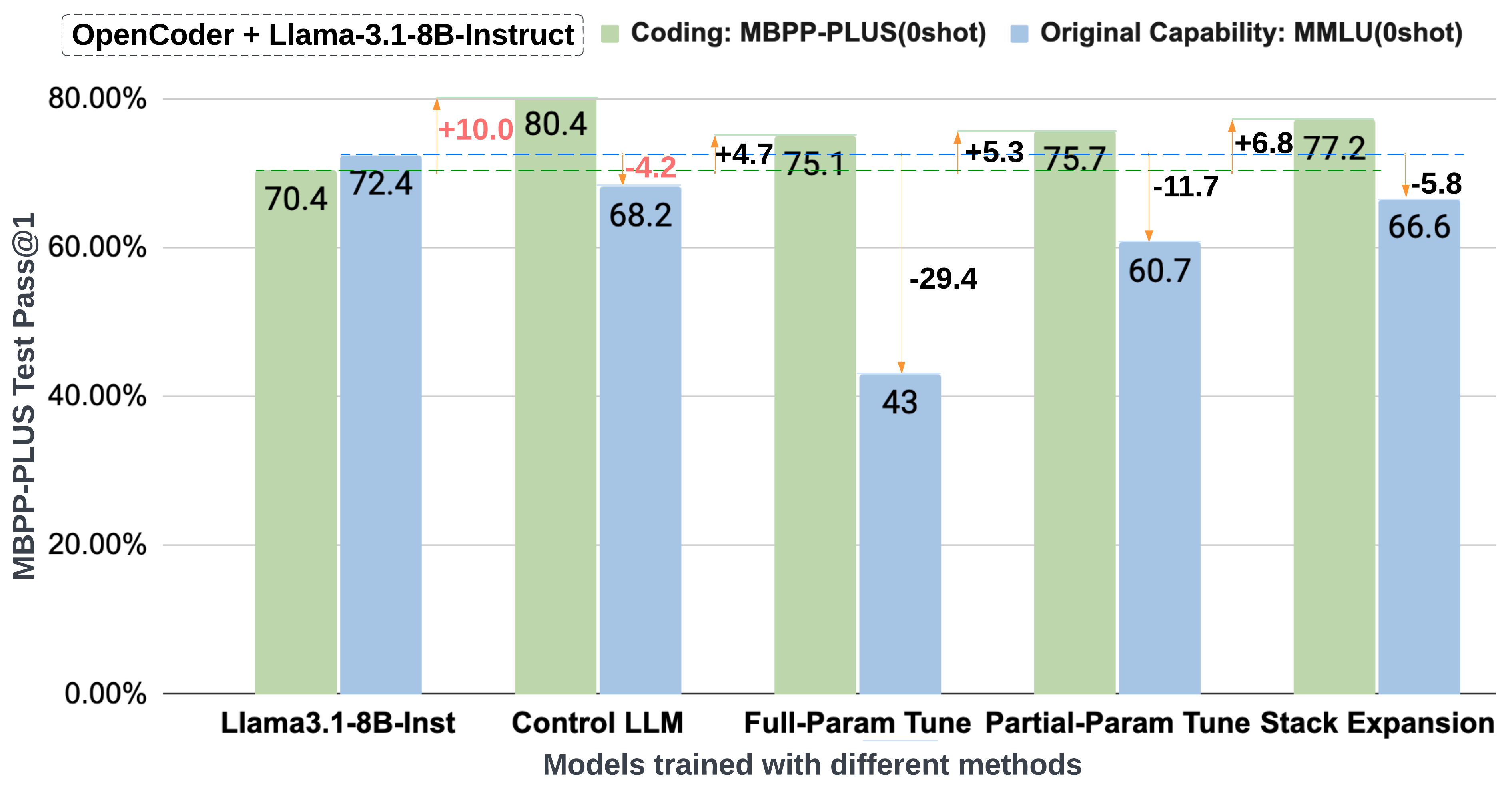
### Benchmark Result and Catastrophic Forgetting on OpenCoder
|
| 84 |
+
The following plot illustrates benchmark result and catastrophic forgetting mitigation on the OpenCoder SFT dataset.
|
| 85 |
+
|
| 86 |
+

|
| 87 |
+
|
| 88 |
+
### Benchmark Results Table
|
| 89 |
+
The table below summarizes evaluation results across coding tasks and original capabilities.
|
| 90 |
+
|
| 91 |
+
| **Model** | **MB+** | **MS** | **HE+** | **HE** | **C-Avg** | **ARC** | **GP** | **MLU** | **MLUP** | **O-Avg** | **Overall** |
|
| 92 |
+
|--------------------|---------|---------|---------|---------|-----------|---------|---------|---------|----------|-----------|-------------|
|
| 93 |
+
| Llama3.1-8B-Ins | 70.4 | 67.7 | 66.5 | 70.7 | 69.1 | 83.4 | 29.9 | 72.4 | 46.7 | 60.5 | 64.8 |
|
| 94 |
+
| OpenCoder-8B-Ins | 81.2 | 76.3 | 78.0 | 82.3 | 79.5 | 8.2 | 25.4 | 37.4 | 11.3 | 24.6 | 52.1 |
|
| 95 |
+
| **Full Param Tune**| 75.1 | 69.6 | 71.3 | 76.8 | 73.3 | 24.4 | 21.9 | 43.0 | 19.2 | 31.5 | 52.4 |
|
| 96 |
+
| Partial Param Tune | 75.7 | 71.6 | 74.4 | 79.3 | 75.0 | 70.2 | 28.1 | 60.7 | 32.4 | 48.3 | 61.7 |
|
| 97 |
+
| Stack Expansion | 77.2 | 72.8 | 73.2 | 78.7 | 75.6 | 80.0 | 26.3 | 66.6 | 38.2 | 54.2 | 64.9 |
|
| 98 |
+
| Hybrid Expansion* | 77.5 | 73.5 | **76.2**| **82.3**| 77.1 | 80.9 | **32.6**| 68.1 | 40.3 | 56.0 | 66.6 |
|
| 99 |
+
| **Control LLM*** | **80.4**| **75.9**| 74.4 | 81.1 | **78.3** | **82.5**| 29.7 | **68.2**| **40.9** | **56.3** | **67.3** |
|
| 100 |
+
|
| 101 |
+
---
|
| 102 |
+
|
| 103 |
+
### Explanation:
|
| 104 |
+
- **MB+**: MBPP Plus
|
| 105 |
+
- **MS**: MBPP Sanitized
|
| 106 |
+
- **HE+**: HumanEval Plus
|
| 107 |
+
- **HE**: HumanEval
|
| 108 |
+
- **C-Avg**: Coding - Size Weighted Average across MB+, MS, HE+, and HE
|
| 109 |
+
- **ARC**: ARC benchmark
|
| 110 |
+
- **GP**: GPQA benchmark
|
| 111 |
+
- **MLU**: MMLU (Massive Multitask Language Understanding)
|
| 112 |
+
- **MLUP**: MMLU Pro
|
| 113 |
+
- **O-Avg**: Original Capability - Size Weighted Average across ARC, GPQA, MMLU, and MMLU Pro
|
| 114 |
+
- **Overall**: Combined average across all tasks
|
benchmark_results_code_instruct.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a6199e12ee08cddf074ddb4712b39440e8be166bd99d45eeec1e7050b3252aea
|
| 3 |
+
size 18321
|
benchmark_results_original_capability_instruct.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b236479e2183f37eae7caef1adce93f20147ac2be478c8ffc893a42583b6c699
|
| 3 |
+
size 17231
|
config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c3ac4fc4f51ac8ae6a23d7425533c9ce7a91c5b5a7eda80c2909f0b56336fc01
|
| 3 |
+
size 1747
|
evaluation_results.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4f4a88dc174e1604af1e83f0d6d13c71862a65e9bf646511270a3d9f141b2ee4
|
| 3 |
+
size 921
|
generation_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6e3dea9cdfa4a3e0edf1b52d9b1e9609aa22efcddce630060b748284663c8e67
|
| 3 |
+
size 177
|
model-00001-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:51f918e91dec283d291d864aaa45d69ffec7a757c4eb47e0b028d0034e6b9268
|
| 3 |
+
size 4976765742
|
model-00002-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:44f2bf1cf8eddf0c3b76952a4ec902ceffffe1fdad84766fee02acd585252dde
|
| 3 |
+
size 4999853582
|
model-00003-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:928b8ee9f7f26f1ab43be8e36f1bbcdb0b5b2c127bf94585180c2dd30cd11311
|
| 3 |
+
size 4915983640
|
model-00004-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4218fea139ca82ff487a993df7323a28c367c27f9920013753e420036e694b12
|
| 3 |
+
size 4999886888
|
model-00005-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6a1674c2c65e088709514f377d59d691c1454bcdfcfb875f820fadb2e9512009
|
| 3 |
+
size 3147970380
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:99a0746418bc2b35797d04c9fd6460fcf4e4de768b7aa9ab4b5f427b52099448
|
| 3 |
+
size 43015
|
plots/catastrophic_forgetting_opencoder.png
ADDED
|
Git LFS Details
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:453db79c09538b7953c4d9846d4bc0b46b86a296f285cdecc29f739f0b98f6a9
|
| 3 |
+
size 572
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a200d62d1a1177908f4310d7e367f0194d474db0038dc1f2f2434a3ef74af7d9
|
| 3 |
+
size 17210284
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e407a45cd60fbcdad88f1a22adab70157c47e858c0c94995de05e87b06205aa
|
| 3 |
+
size 55820
|