Spaces:
Running

Running

upload
Browse files- __pycache__/backend.cpython-37.pyc +0 -0
- app.py +48 -48
- download/20230719163556/20230719163556.zip +3 -0
- download/20230719163556/input/1512.03385.tar.gz +3 -0
- download/20230719163556/input/1706.03762.tar.gz +3 -0
- download/20230719163556/output/Attention-Is-All-You-Need/Figures/ModalNet-19.png +0 -0
- download/20230719163556/output/Attention-Is-All-You-Need/Figures/ModalNet-20.png +0 -0
- download/20230719163556/output/Attention-Is-All-You-Need/Figures/ModalNet-21.png +0 -0
- download/20230719163556/output/Attention-Is-All-You-Need/Figures/ModalNet-22.png +0 -0
- download/20230719163556/output/Attention-Is-All-You-Need/Figures/ModalNet-23.png +0 -0
- download/20230719163556/output/Attention-Is-All-You-Need/Figures/ModalNet-32.png +0 -0
- download/20230719163556/output/Attention-Is-All-You-Need/background.tex +58 -0
- download/20230719163556/output/Attention-Is-All-You-Need/introduction.tex +18 -0
- download/20230719163556/output/Attention-Is-All-You-Need/model_architecture.tex +155 -0
- download/20230719163556/output/Attention-Is-All-You-Need/ms.tex +413 -0
- download/20230719163556/output/Attention-Is-All-You-Need/nips_2017.sty +338 -0
- download/20230719163556/output/Attention-Is-All-You-Need/parameter_attention.tex +45 -0
- download/20230719163556/output/Attention-Is-All-You-Need/results.tex +166 -0
- download/20230719163556/output/Attention-Is-All-You-Need/sqrt_d_trick.tex +28 -0
- download/20230719163556/output/Attention-Is-All-You-Need/training.tex +42 -0
- download/20230719163556/output/Attention-Is-All-You-Need/vis/anaphora_resolution2_new.pdf +0 -0
- download/20230719163556/output/Attention-Is-All-You-Need/vis/anaphora_resolution_new.pdf +0 -0
- download/20230719163556/output/Attention-Is-All-You-Need/vis/attending_to_head2_new.pdf +0 -0
- download/20230719163556/output/Attention-Is-All-You-Need/vis/attending_to_head_new.pdf +0 -0
- download/20230719163556/output/Attention-Is-All-You-Need/vis/making_more_difficult5_new.pdf +0 -0
- download/20230719163556/output/Attention-Is-All-You-Need/vis/making_more_difficult_new.pdf +0 -0
- download/20230719163556/output/Attention-Is-All-You-Need/visualizations.tex +18 -0
- download/20230719163556/output/Attention-Is-All-You-Need/why_self_attention.tex +98 -0
- download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/cvpr.sty +249 -0
- download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/cvpr_eso.sty +109 -0
- download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eps/arch.pdf +0 -0
- download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eps/block.pdf +0 -0
- download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eps/block_deeper.pdf +0 -0
- download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eps/cifar.pdf +0 -0
- download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eps/imagenet.pdf +0 -0
- download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eps/std.pdf +0 -0
- download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eps/teaser.pdf +0 -0
- download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eso-pic.sty +267 -0
- download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/ieee.bst +1129 -0
- download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/residual_v1_arxiv_release.bbl +273 -0
- download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/residual_v1_arxiv_release.tex +909 -0
__pycache__/backend.cpython-37.pyc
ADDED
|
Binary file (2.61 kB). View file
|
|
|
app.py
CHANGED
|
@@ -1,4 +1,4 @@
|
|
| 1 |
-
import imp
|
| 2 |
import streamlit as st
|
| 3 |
import pandas as pd
|
| 4 |
import numpy as np
|
|
@@ -41,51 +41,51 @@ if crawling_or_not:
|
|
| 41 |
# cleaning the pdf lists
|
| 42 |
pdf_lists = [i.strip() for i in pdf_lists if len(i) > 0]
|
| 43 |
# TODO: limit the number of paper up to 10 since I am not sure that whether base64 support large file download
|
| 44 |
-
try:
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
# finish one paper
|
| 76 |
-
bar.progress((i+1)/N)
|
| 77 |
-
download_status.text(f"Iteration [{i+1}/{N}]: Finish Downloading of "+title)
|
| 78 |
-
|
| 79 |
-
with st.spinner("Archiving as Zip Files..."):
|
| 80 |
-
# save it as zip file
|
| 81 |
-
filepath = archive_dir(out,os.path.join(base,project_name))
|
| 82 |
-
|
| 83 |
-
# download
|
| 84 |
-
b64 = ToBase64(filepath).decode()
|
| 85 |
-
href = f"<a href='data:file/csv;base64,{b64}' download='arxiv2latex-output-{datetime.datetime.now()}.zip' color='red'>Click here to Download the Output Latex Zip Files</a>"
|
| 86 |
-
st.markdown(href, unsafe_allow_html=True)
|
| 87 |
|
| 88 |
-
|
| 89 |
-
|
| 90 |
-
|
| 91 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# import imp
|
| 2 |
import streamlit as st
|
| 3 |
import pandas as pd
|
| 4 |
import numpy as np
|
|
|
|
| 41 |
# cleaning the pdf lists
|
| 42 |
pdf_lists = [i.strip() for i in pdf_lists if len(i) > 0]
|
| 43 |
# TODO: limit the number of paper up to 10 since I am not sure that whether base64 support large file download
|
| 44 |
+
# try:
|
| 45 |
+
if len(pdf_lists) > predefined_limits:
|
| 46 |
+
st.warning(f"Currently only support up to {predefined_limits} papers. Please input less than {predefined_limits} papers.")
|
| 47 |
+
else:
|
| 48 |
+
# parsing
|
| 49 |
+
base='./download/'
|
| 50 |
+
project_name = get_timestamp().replace(" ","-")
|
| 51 |
+
base = os.path.join(base,project_name)
|
| 52 |
+
make_dir_if_not_exist(base)
|
| 53 |
+
|
| 54 |
+
# st.write(download_status)
|
| 55 |
+
with st.spinner("Downloading papers..."):
|
| 56 |
+
# progress bar
|
| 57 |
+
bar = st.progress(0)
|
| 58 |
+
download_status = st.empty()
|
| 59 |
+
N = len(pdf_lists)
|
| 60 |
+
for i, pdf_link in tqdm(enumerate(pdf_lists)):
|
| 61 |
+
title = get_name_from_arvix(pdf_link)
|
| 62 |
+
file_stamp = pdf_link.split("/")[-1]
|
| 63 |
+
source_link = "https://arxiv.org/e-print/"+file_stamp
|
| 64 |
+
inp = os.path.join(base,'input')
|
| 65 |
+
make_dir_if_not_exist(inp)
|
| 66 |
+
out = os.path.join(base,'output')
|
| 67 |
+
make_dir_if_not_exist(out)
|
| 68 |
+
response = requests.get(source_link)
|
| 69 |
+
filename = file_stamp+".tar.gz"
|
| 70 |
+
filepath = os.path.join(inp,filename)
|
| 71 |
+
open(filepath, "wb").write(response.content)
|
| 72 |
+
outpath = os.path.join(out,title)
|
| 73 |
+
untar(filepath,outpath)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 74 |
|
| 75 |
+
# finish one paper
|
| 76 |
+
bar.progress((i+1)/N)
|
| 77 |
+
download_status.text(f"Iteration [{i+1}/{N}]: Finish Downloading of "+title)
|
| 78 |
+
|
| 79 |
+
with st.spinner("Archiving as Zip Files..."):
|
| 80 |
+
# save it as zip file
|
| 81 |
+
filepath = archive_dir(out,os.path.join(base,project_name))
|
| 82 |
+
|
| 83 |
+
# download
|
| 84 |
+
b64 = ToBase64(filepath).decode()
|
| 85 |
+
href = f"<a href='data:file/csv;base64,{b64}' download='arxiv2latex-output-{datetime.datetime.now()}.zip' color='red'>Click here to Download the Output Latex Zip Files</a>"
|
| 86 |
+
st.markdown(href, unsafe_allow_html=True)
|
| 87 |
+
|
| 88 |
+
# 状态
|
| 89 |
+
st.success("Finished")
|
| 90 |
+
# except Exception as e:
|
| 91 |
+
# st.error("Something goes wrong. Please check the input or concat me to fix this bug. Error message: \n"+str(e))
|
download/20230719163556/20230719163556.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b8c08fed6381f25599036729607317c42b5c1a23ffc648cd0d43e3087819c4ef
|
| 3 |
+
size 1719685
|
download/20230719163556/input/1512.03385.tar.gz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a975e8b798fb4c447551bffd4e74a3abf169b151e4435390ab6d16bf88cef880
|
| 3 |
+
size 506177
|
download/20230719163556/input/1706.03762.tar.gz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2500348e730741b9a8eafcac0301f7e3f0b1c670f9e08ce62e6c45a36a64cf0a
|
| 3 |
+
size 1150961
|
download/20230719163556/output/Attention-Is-All-You-Need/Figures/ModalNet-19.png
ADDED

|
download/20230719163556/output/Attention-Is-All-You-Need/Figures/ModalNet-20.png
ADDED

|
download/20230719163556/output/Attention-Is-All-You-Need/Figures/ModalNet-21.png
ADDED
|
download/20230719163556/output/Attention-Is-All-You-Need/Figures/ModalNet-22.png
ADDED
|
download/20230719163556/output/Attention-Is-All-You-Need/Figures/ModalNet-23.png
ADDED
|
download/20230719163556/output/Attention-Is-All-You-Need/Figures/ModalNet-32.png
ADDED

|
download/20230719163556/output/Attention-Is-All-You-Need/background.tex
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU \citep{extendedngpu}, ByteNet \citep{NalBytenet2017} and ConvS2S \citep{JonasFaceNet2017}, all of which use convolutional neural networks as basic building block, computing hidden representations in parallel for all input and output positions. In these models, the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet. This makes it more difficult to learn dependencies between distant positions \citep{hochreiter2001gradient}. In the Transformer this is reduced to a constant number of operations, albeit at the cost of reduced effective resolution due to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as described in section~\ref{sec:attention}.
|
| 2 |
+
|
| 3 |
+
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. Self-attention has been used successfully in a variety of tasks including reading comprehension, abstractive summarization, textual entailment and learning task-independent sentence representations \citep{cheng2016long, decomposableAttnModel, paulus2017deep, lin2017structured}.
|
| 4 |
+
|
| 5 |
+
End-to-end memory networks are based on a recurrent attention mechanism instead of sequence-aligned recurrence and have been shown to perform well on simple-language question answering and language modeling tasks \citep{sukhbaatar2015}.
|
| 6 |
+
|
| 7 |
+
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution.
|
| 8 |
+
In the following sections, we will describe the Transformer, motivate self-attention and discuss its advantages over models such as \citep{neural_gpu, NalBytenet2017} and \citep{JonasFaceNet2017}.
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
%\citep{JonasFaceNet2017} report new SOTA on machine translation for English-to-German (EnDe), Enlish-to-French (EnFr) and English-to-Romanian language pairs.
|
| 12 |
+
|
| 13 |
+
%For example,! in MT, we must draw information from both input and previous output words to translate an output word accurately. An attention layer \citep{bahdanau2014neural} can connect a very large number of positions at low computation cost, making it an essential ingredient in competitive recurrent models for machine translation.
|
| 14 |
+
|
| 15 |
+
%A natural question to ask then is, "Could we replace recurrence with attention?". \marginpar{Don't know if it's the most natural question to ask given the previous statements. Also, need to say that the complexity table summarizes these statements} Such a model would be blessed with the computational efficiency of attention and the power of cross-positional communication. In this work, show that pure attention models work remarkably well for MT, achieving new SOTA results on EnDe and EnFr, and can be trained in under $2$ days on xyz architecture.
|
| 16 |
+
|
| 17 |
+
%After the seminal models introduced in \citep{sutskever14, bahdanau2014neural, cho2014learning}, recurrent models have become the dominant solution for both sequence modeling and sequence-to-sequence transduction. Many efforts such as \citep{wu2016google,luong2015effective,jozefowicz2016exploring} have pushed the boundaries of machine translation (MT) and language modeling with recurrent endoder-decoder and recurrent language models. Recent effort \citep{shazeer2017outrageously} has successfully combined the power of conditional computation with sequence models to train very large models for MT, pushing SOTA at lower computational cost.
|
| 18 |
+
|
| 19 |
+
%Recurrent models compute a vector of hidden states $h_t$, for each time step $t$ of computation. $h_t$ is a function of both the input at time $t$ and the previous hidden state $h_t$. This dependence on the previous hidden state precludes processing all timesteps at once, instead requiring long sequences of sequential operations. In practice, this results in greatly reduced computational efficiency, as on modern computing hardware, a single operation on a large batch is much faster than a large number of operations on small batches. The problem gets worse at longer sequence lengths. Although sequential computation is not a severe bottleneck at inference time, as autoregressively generating each output requires all previous outputs, the inability to compute scores at all output positions at once hinders us from rapidly training our models over large datasets. Although impressive work such as \citep{Kuchaiev2017Factorization} is able to significantly accelerate the training of LSTMs with factorization tricks, we are still bound by the linear dependence on sequence length.
|
| 20 |
+
|
| 21 |
+
%If the model could compute hidden states at each time step using only the inputs and outputs, it would be liberated from the dependence on results from previous time steps during training. This line of thought is the foundation of recent efforts such as the Markovian neural GPU \citep{neural_gpu}, ByteNet \citep{NalBytenet2017} and ConvS2S \citep{JonasFaceNet2017}, all of which use convolutional neural networks as a building block to compute hidden representations simultaneously for all timesteps, resulting in $O(1)$ sequential time complexity. \citep{JonasFaceNet2017} report new SOTA on machine translation for English-to-German (EnDe), Enlish-to-French (EnFr) and English-to-Romanian language pairs.
|
| 22 |
+
|
| 23 |
+
%A crucial component for accurate sequence prediction is modeling cross-positional communication. For example, in MT, we must draw information from both input and previous output words to translate an output word accurately. An attention layer \citep{bahdanau2014neural} can connect a very large number of positions at a low computation cost, also $O(1)$ sequential time complexity, making it an essential ingredient in recurrent encoder-decoder architectures for MT. A natural question to ask then is, "Could we replace recurrence with attention?". \marginpar{Don't know if it's the most natural question to ask given the previous statements. Also, need to say that the complexity table summarizes these statements} Such a model would be blessed with the computational efficiency of attention and the power of cross-positional communication. In this work, show that pure attention models work remarkably well for MT, achieving new SOTA results on EnDe and EnFr, and can be trained in under $2$ days on xyz architecture.
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
%Note: Facebook model is no better than RNNs in this regard, since it requires a number of layers proportional to the distance you want to communicate. Bytenet is more promising, since it requires a logarithmnic number of layers (does bytenet have SOTA results)?
|
| 28 |
+
|
| 29 |
+
%Note: An attention layer can connect a very large number of positions at a low computation cost in O(1) sequential operations. This is why encoder-decoder attention has been so successful in seq-to-seq models so far. It is only natural, then, to also use attention to connect the timesteps of the same sequence.
|
| 30 |
+
|
| 31 |
+
%Note: I wouldn't say that long sequences are not a problem during inference. It would be great if we could infer with no long sequences. We could just say later on that, while our training graph is constant-depth, our model still requires sequential operations in the decoder part during inference due to the autoregressive nature of the model.
|
| 32 |
+
|
| 33 |
+
%\begin{table}[h!]
|
| 34 |
+
%\caption{Attention models are quite efficient for cross-positional communications when sequence length is smaller than channel depth. $n$ represents the sequence length and $d$ represents the channel depth.}
|
| 35 |
+
%\label{tab:op_complexities}
|
| 36 |
+
%\begin{center}
|
| 37 |
+
%\vspace{-5pt}
|
| 38 |
+
%\scalebox{0.75}{
|
| 39 |
+
|
| 40 |
+
%\begin{tabular}{l|c|c|c}
|
| 41 |
+
%\hline \hline
|
| 42 |
+
%Layer Type & Receptive & Complexity & Sequential \\
|
| 43 |
+
% & Field & & Operations \\
|
| 44 |
+
%\hline
|
| 45 |
+
%Pointwise Feed-Forward & $1$ & $O(n \cdot d^2)$ & $O(1)$ \\
|
| 46 |
+
%\hline
|
| 47 |
+
%Recurrent & $n$ & $O(n \cdot d^2)$ & $O(n)$ \\
|
| 48 |
+
%\hline
|
| 49 |
+
%Convolutional & $r$ & $O(r \cdot n \cdot d^2)$ & $O(1)$ \\
|
| 50 |
+
%\hline
|
| 51 |
+
%Convolutional (separable) & $r$ & $O(r \cdot n \cdot d + n %\cdot d^2)$ & $O(1)$ \\
|
| 52 |
+
%\hline
|
| 53 |
+
%Attention & $r$ & $O(r \cdot n \cdot d)$ & $O(1)$ \\
|
| 54 |
+
%\hline \hline
|
| 55 |
+
%\end{tabular}
|
| 56 |
+
%}
|
| 57 |
+
%\end{center}
|
| 58 |
+
%\end{table}
|
download/20230719163556/output/Attention-Is-All-You-Need/introduction.tex
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Recurrent neural networks, long short-term memory \citep{hochreiter1997} and gated recurrent \citep{gruEval14} neural networks in particular, have been firmly established as state of the art approaches in sequence modeling and transduction problems such as language modeling and machine translation \citep{sutskever14, bahdanau2014neural, cho2014learning}. Numerous efforts have since continued to push the boundaries of recurrent language models and encoder-decoder architectures \citep{wu2016google,luong2015effective,jozefowicz2016exploring}.
|
| 2 |
+
|
| 3 |
+
Recurrent models typically factor computation along the symbol positions of the input and output sequences. Aligning the positions to steps in computation time, they generate a sequence of hidden states $h_t$, as a function of the previous hidden state $h_{t-1}$ and the input for position $t$. This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples.
|
| 4 |
+
%\marginpar{not sure if the memory constraints are understandable here}
|
| 5 |
+
Recent work has achieved significant improvements in computational efficiency through factorization tricks \citep{Kuchaiev2017Factorization} and conditional computation \citep{shazeer2017outrageously}, while also improving model performance in case of the latter. The fundamental constraint of sequential computation, however, remains.
|
| 6 |
+
|
| 7 |
+
%\marginpar{@all: there is work on analyzing what attention really does in seq2seq models, couldn't find it right away}
|
| 8 |
+
|
| 9 |
+
Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences \citep{bahdanau2014neural, structuredAttentionNetworks}. In all but a few cases \citep{decomposableAttnModel}, however, such attention mechanisms are used in conjunction with a recurrent network.
|
| 10 |
+
|
| 11 |
+
%\marginpar{not sure if "cross-positional communication" is understandable without explanation}
|
| 12 |
+
%\marginpar{insert exact training times and stats for the model that reaches sota earliest, maybe even a single GPU model?}
|
| 13 |
+
|
| 14 |
+
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.
|
| 15 |
+
%\marginpar{you removed the constant number of repetitions part. I wrote it because I wanted to make it clear that the model does not only perform attention once, while it's also not recurrent. I thought that might be important to get across early.}
|
| 16 |
+
|
| 17 |
+
% Just a standard paragraph with citations, rewrite.
|
| 18 |
+
%After the seminal papers of \citep{sutskever14}, \citep{bahdanau2014neural}, and \citep{cho2014learning}, recurrent models have become the dominant solution for both sequence modeling and sequence-to-sequence transduction. Many efforts such as \citep{wu2016google,luong2015effective,jozefowicz2016exploring} have pushed the boundaries of machine translation and language modeling with recurrent sequence models. Recent effort \citep{shazeer2017outrageously} has combined the power of conditional computation with sequence models to train very large models for machine translation, pushing SOTA at lower computational cost. Recurrent models compute a vector of hidden states $h_t$, for each time step $t$ of computation. $h_t$ is a function of both the input at time $t$ and the previous hidden state $h_t$. This dependence on the previous hidden state encumbers recurrnet models to process multiple inputs at once, and their time complexity is a linear function of the length of the input and output, both during training and inference. [What I want to say here is that although this is fine during decoding, at training time, we are given both input and output and this linear nature does not allow the RNN to process all inputs and outputs simultaneously and haven't been used on datasets that are the of the scale of the web. What's the largest dataset we have ? . Talk about Nividia and possibly other's effors to speed up things, and possibly other efforts that alleviate this, but are still limited by it's comptuational nature]. Rest of the intro: What if you could construct the state based on the actual inputs and outputs, then you could construct them all at once. This has been the foundation of many promising recent efforts, bytenet,facenet (Also talk about quasi rnn here). Now we talk about attention!! Along with cell architectures such as long short-term meory (LSTM) \citep{hochreiter1997}, and gated recurrent units (GRUs) \citep{cho2014learning}, attention has emerged as an essential ingredient in successful sequence models, in particular for machine translation. In recent years, many, if not all, state-of-the-art (SOTA) results in machine translation have been achieved with attention-based sequence models \citep{wu2016google,luong2015effective,jozefowicz2016exploring}. Talk about the neon work on how it played with attention to do self attention! Then talk about what we do.
|
download/20230719163556/output/Attention-Is-All-You-Need/model_architecture.tex
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
\begin{figure}
|
| 3 |
+
\centering
|
| 4 |
+
\includegraphics[scale=0.6]{Figures/ModalNet-21}
|
| 5 |
+
\caption{The Transformer - model architecture.}
|
| 6 |
+
\label{fig:model-arch}
|
| 7 |
+
\end{figure}
|
| 8 |
+
|
| 9 |
+
% Although the primary workhorse of our model is attention,
|
| 10 |
+
%Our model maintains the encoder-decoder structure that is common to many so-called sequence-to-sequence models \citep{bahdanau2014neural,sutskever14}. As in all such architectures, the encoder computes a representation of the input sequence, and the decoder consumes these representations along with the output tokens to autoregressively produce the output sequence. Where, traditionally, the encoder and decoder contain stacks of recurrent or convolutional layers, our encoder and decoder stacks are composed of attention layers and position-wise feed-forward layers (Figure~\ref{fig:model-arch}). The following sections describe the gross architecture and these particular components in detail.
|
| 11 |
+
|
| 12 |
+
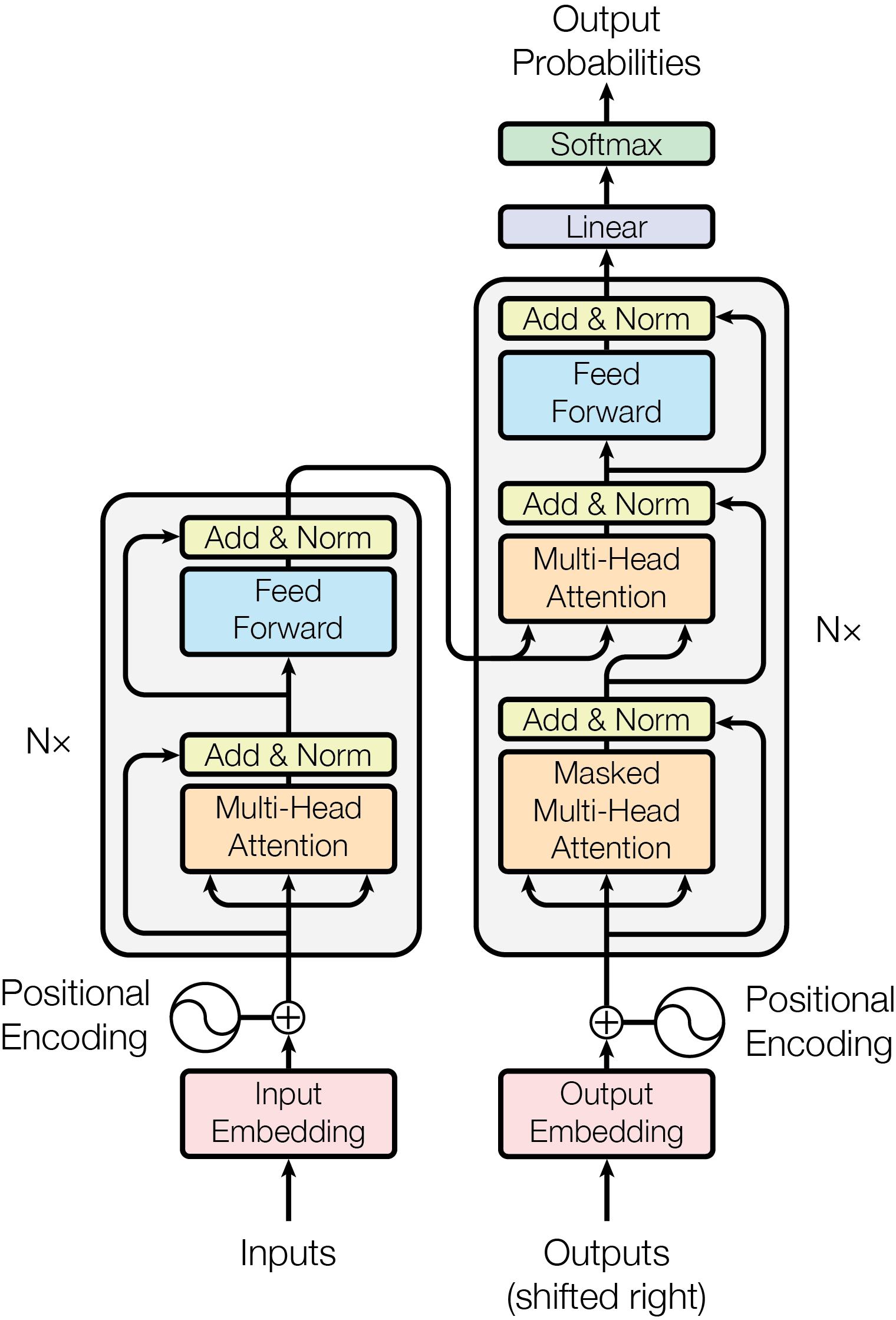
Most competitive neural sequence transduction models have an encoder-decoder structure \citep{cho2014learning,bahdanau2014neural,sutskever14}. Here, the encoder maps an input sequence of symbol representations $(x_1, ..., x_n)$ to a sequence of continuous representations $\mathbf{z} = (z_1, ..., z_n)$. Given $\mathbf{z}$, the decoder then generates an output sequence $(y_1,...,y_m)$ of symbols one element at a time. At each step the model is auto-regressive \citep{graves2013generating}, consuming the previously generated symbols as additional input when generating the next.
|
| 13 |
+
|
| 14 |
+
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure~\ref{fig:model-arch}, respectively.
|
| 15 |
+
|
| 16 |
+
\subsection{Encoder and Decoder Stacks}
|
| 17 |
+
|
| 18 |
+
\paragraph{Encoder:}The encoder is composed of a stack of $N=6$ identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network. We employ a residual connection \citep{he2016deep} around each of the two sub-layers, followed by layer normalization \cite{layernorm2016}. That is, the output of each sub-layer is $\mathrm{LayerNorm}(x + \mathrm{Sublayer}(x))$, where $\mathrm{Sublayer}(x)$ is the function implemented by the sub-layer itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension $\dmodel=512$.
|
| 19 |
+
|
| 20 |
+
\paragraph{Decoder:}The decoder is also composed of a stack of $N=6$ identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization. We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position $i$ can depend only on the known outputs at positions less than $i$.
|
| 21 |
+
|
| 22 |
+
% In our model (Figure~\ref{fig:model-arch}), the encoder and decoder are composed of stacks of alternating self-attention layers (for cross-positional communication) and position-wise feed-forward layers (for in-place computation). In addition, the decoder stack contains encoder-decoder attention layers. Since attention is agnostic to the distances between words, our model requires a "positional encoding" to be added to the encoder and decoder input. The following sections describe all of these components in detail.
|
| 23 |
+
|
| 24 |
+
\subsection{Attention} \label{sec:attention}
|
| 25 |
+
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
|
| 26 |
+
|
| 27 |
+
\subsubsection{Scaled Dot-Product Attention} \label{sec:scaled-dot-prod}
|
| 28 |
+
|
| 29 |
+
% \begin{figure}
|
| 30 |
+
% \centering
|
| 31 |
+
% \includegraphics[scale=0.6]{Figures/ModalNet-19}
|
| 32 |
+
% \caption{Scaled Dot-Product Attention.}
|
| 33 |
+
% \label{fig:multi-head-att}
|
| 34 |
+
% \end{figure}
|
| 35 |
+
|
| 36 |
+
We call our particular attention "Scaled Dot-Product Attention" (Figure~\ref{fig:multi-head-att}). The input consists of queries and keys of dimension $d_k$, and values of dimension $d_v$. We compute the dot products of the query with all keys, divide each by $\sqrt{d_k}$, and apply a softmax function to obtain the weights on the values.
|
| 37 |
+
|
| 38 |
+
In practice, we compute the attention function on a set of queries simultaneously, packed together into a matrix $Q$. The keys and values are also packed together into matrices $K$ and $V$. We compute the matrix of outputs as:
|
| 39 |
+
|
| 40 |
+
\begin{equation}
|
| 41 |
+
\mathrm{Attention}(Q, K, V) = \mathrm{softmax}(\frac{QK^T}{\sqrt{d_k}})V
|
| 42 |
+
\end{equation}
|
| 43 |
+
|
| 44 |
+
The two most commonly used attention functions are additive attention \citep{bahdanau2014neural}, and dot-product (multiplicative) attention. Dot-product attention is identical to our algorithm, except for the scaling factor of $\frac{1}{\sqrt{d_k}}$. Additive attention computes the compatibility function using a feed-forward network with a single hidden layer. While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.
|
| 45 |
+
|
| 46 |
+
%We scale the dot products by $1/\sqrt{d_k}$ to limit the magnitude of the dot products, which works well in practice. Otherwise, we found applying the softmax to often result in weights very close to 0 or 1, and hence minuscule gradients.
|
| 47 |
+
|
| 48 |
+
% Already described in the subsequent section
|
| 49 |
+
%When used as part of decoder self-attention, an optional mask function is applied just before the softmax to prevent positions from attending to subsequent positions. This mask simply sets the logits corresponding to all illegal connections (those outside of the lower triangle) to $-\infty$.
|
| 50 |
+
|
| 51 |
+
%\paragraph{Comparison to Additive Attention: } We choose dot product attention over additive attention \citep{bahdanau2014neural} since it can be computed using highly optimized matrix multiplication code. This optimization is particularly important to us, as we employ many attention layers in our model.
|
| 52 |
+
|
| 53 |
+
While for small values of $d_k$ the two mechanisms perform similarly, additive attention outperforms dot product attention without scaling for larger values of $d_k$ \citep{DBLP:journals/corr/BritzGLL17}. We suspect that for large values of $d_k$, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients \footnote{To illustrate why the dot products get large, assume that the components of $q$ and $k$ are independent random variables with mean $0$ and variance $1$. Then their dot product, $q \cdot k = \sum_{i=1}^{d_k} q_ik_i$, has mean $0$ and variance $d_k$.}. To counteract this effect, we scale the dot products by $\frac{1}{\sqrt{d_k}}$.
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
%We suspect this to be caused by the dot products growing too large in magnitude to result in useful gradients after applying the softmax function. To counteract this, we scale the dot product by $1/\sqrt{d_k}$.
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
\subsubsection{Multi-Head Attention} \label{sec:multihead}
|
| 60 |
+
|
| 61 |
+
\begin{figure}
|
| 62 |
+
\begin{minipage}[t]{0.5\textwidth}
|
| 63 |
+
\centering
|
| 64 |
+
Scaled Dot-Product Attention \\
|
| 65 |
+
\vspace{0.5cm}
|
| 66 |
+
\includegraphics[scale=0.6]{Figures/ModalNet-19}
|
| 67 |
+
\end{minipage}
|
| 68 |
+
\begin{minipage}[t]{0.5\textwidth}
|
| 69 |
+
\centering
|
| 70 |
+
Multi-Head Attention \\
|
| 71 |
+
\vspace{0.1cm}
|
| 72 |
+
\includegraphics[scale=0.6]{Figures/ModalNet-20}
|
| 73 |
+
\end{minipage}
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
% \centering
|
| 77 |
+
|
| 78 |
+
\caption{(left) Scaled Dot-Product Attention. (right) Multi-Head Attention consists of several attention layers running in parallel.}
|
| 79 |
+
\label{fig:multi-head-att}
|
| 80 |
+
\end{figure}
|
| 81 |
+
|
| 82 |
+
Instead of performing a single attention function with $\dmodel$-dimensional keys, values and queries, we found it beneficial to linearly project the queries, keys and values $h$ times with different, learned linear projections to $d_k$, $d_k$ and $d_v$ dimensions, respectively.
|
| 83 |
+
On each of these projected versions of queries, keys and values we then perform the attention function in parallel, yielding $d_v$-dimensional output values. These are concatenated and once again projected, resulting in the final values, as depicted in Figure~\ref{fig:multi-head-att}.
|
| 84 |
+
|
| 85 |
+
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
|
| 86 |
+
|
| 87 |
+
\begin{align*}
|
| 88 |
+
\mathrm{MultiHead}(Q, K, V) &= \mathrm{Concat}(\mathrm{head_1}, ..., \mathrm{head_h})W^O\\
|
| 89 |
+
% \mathrm{where} \mathrm{head_i} &= \mathrm{Attention}(QW_Q_i^{\dmodel \times d_q}, KW_K_i^{\dmodel \times d_k}, VW^V_i^{\dmodel \times d_v})\\
|
| 90 |
+
\text{where}~\mathrm{head_i} &= \mathrm{Attention}(QW^Q_i, KW^K_i, VW^V_i)\\
|
| 91 |
+
\end{align*}
|
| 92 |
+
|
| 93 |
+
Where the projections are parameter matrices $W^Q_i \in \mathbb{R}^{\dmodel \times d_k}$, $W^K_i \in \mathbb{R}^{\dmodel \times d_k}$, $W^V_i \in \mathbb{R}^{\dmodel \times d_v}$ and $W^O \in \mathbb{R}^{hd_v \times \dmodel}$.
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
%find it better (and no more expensive) to have multiple parallel attention layers (each over the full set of positions) with proportionally lower-dimensional keys, values and queries. We call this "Multi-Head Attention" (Figure~\ref{fig:multi-head-att}). The keys, values, and queries for each of these parallel attention layers are computed by learned linear transformations of the inputs to the multi-head attention. We use different linear transformations across different parallel attention layers. The output of the parallel attention layers are concatenated, and then passed through a final learned linear transformation.
|
| 97 |
+
|
| 98 |
+
In this work we employ $h=8$ parallel attention layers, or heads. For each of these we use $d_k=d_v=\dmodel/h=64$.
|
| 99 |
+
Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.
|
| 100 |
+
|
| 101 |
+
\subsubsection{Applications of Attention in our Model}
|
| 102 |
+
|
| 103 |
+
The Transformer uses multi-head attention in three different ways:
|
| 104 |
+
\begin{itemize}
|
| 105 |
+
\item In "encoder-decoder attention" layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence. This mimics the typical encoder-decoder attention mechanisms in sequence-to-sequence models such as \citep{wu2016google, bahdanau2014neural,JonasFaceNet2017}.
|
| 106 |
+
|
| 107 |
+
\item The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
|
| 108 |
+
|
| 109 |
+
\item Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. We need to prevent leftward information flow in the decoder to preserve the auto-regressive property. We implement this inside of scaled dot-product attention by masking out (setting to $-\infty$) all values in the input of the softmax which correspond to illegal connections. See Figure~\ref{fig:multi-head-att}.
|
| 110 |
+
|
| 111 |
+
\end{itemize}
|
| 112 |
+
|
| 113 |
+
\subsection{Position-wise Feed-Forward Networks}\label{sec:ffn}
|
| 114 |
+
|
| 115 |
+
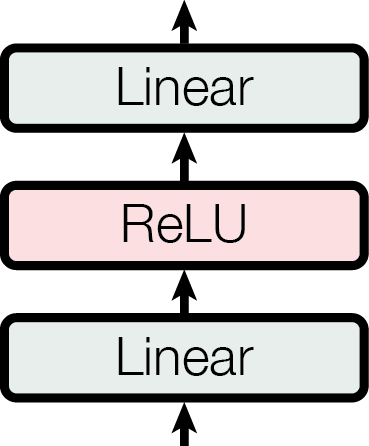
In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between.
|
| 116 |
+
|
| 117 |
+
\begin{equation}
|
| 118 |
+
\mathrm{FFN}(x)=\max(0, xW_1 + b_1) W_2 + b_2
|
| 119 |
+
\end{equation}
|
| 120 |
+
|
| 121 |
+
While the linear transformations are the same across different positions, they use different parameters from layer to layer. Another way of describing this is as two convolutions with kernel size 1. The dimensionality of input and output is $\dmodel=512$, and the inner-layer has dimensionality $d_{ff}=2048$.
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
%In the appendix, we describe how the position-wise feed-forward network can also be seen as a form of attention.
|
| 126 |
+
|
| 127 |
+
%from Jakob: The number of operations required for the model to relate signals from two arbitrary input or output positions grows in the distance between positions in input or output, linearly for ConvS2S and logarithmically for ByteNet, making it harder to learn dependencies between these positions \citep{hochreiter2001gradient}. In the transformer this is reduced to a constant number of operations, albeit at the cost of effective resolution caused by averaging attention-weighted positions, an effect we aim to counteract with multi-headed attention.
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
%Figure~\ref{fig:simple-att} presents a simple attention function, $A$, with a single head, that forms the basis of our multi-head attention. $A$ takes a query key vector $\kq$, matrices of memory keys $\km$ and memory values $\vm$ ,and produces a query value vector $\vq$ as
|
| 131 |
+
%\begin{equation*} \label{eq:attention}
|
| 132 |
+
% A(\kq, \km, \vm) = {\vm}^T (Softmax(\km \kq).
|
| 133 |
+
%\end{equation*}
|
| 134 |
+
%We linearly transform $\kq,\,\km$, and $\vm$ with learned matrices ${\Wkq \text{,} \, \Wkm}$, and ${\Wvm}$ before calling the attention function, and transform the output query with $\Wvq$ before handing it to the feed forward layer. Each attention layer has it's own set of transformation matrices, which are shared across all query positions. $A$ is applied in parallel for each query position, and is implemented very efficiently as a batch of matrix multiplies. The self-attention and encoder-decoder attention layers use $A$, but with different arguments. For example, in encdoder self-attention, queries in encoder layer $i$ attention to memories in encoder layer $i-1$. To ensure that decoder self-attention layers do not look at future words, we add $- \inf$ to the softmax logits in positions $j+1$ to query length for query position $l$.
|
| 135 |
+
|
| 136 |
+
%In simple attention, the query value is a weighted combination of the memory values where the attention weights sum to one. Although this function performs well in practice, the constraint on attention weights can restrict the amount of information that flows from memories to queries because the query cannot focus on multiple memory positions at once, which might be desirable when translating long sequences. \marginpar{@usz, could you think of an example of this ?} We remedy this by maintaining multiple attention heads at each query position that attend to all memory positions in parallel, with a different set of parameters per attention head $h$.
|
| 137 |
+
%\marginpar{}
|
| 138 |
+
|
| 139 |
+
\subsection{Embeddings and Softmax}
|
| 140 |
+
Similarly to other sequence transduction models, we use learned embeddings to convert the input tokens and output tokens to vectors of dimension $\dmodel$. We also use the usual learned linear transformation and softmax function to convert the decoder output to predicted next-token probabilities. In our model, we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation, similar to \citep{press2016using}. In the embedding layers, we multiply those weights by $\sqrt{\dmodel}$.
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
\subsection{Positional Encoding}
|
| 144 |
+
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. To this end, we add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension $\dmodel$ as the embeddings, so that the two can be summed. There are many choices of positional encodings, learned and fixed \citep{JonasFaceNet2017}.
|
| 145 |
+
|
| 146 |
+
In this work, we use sine and cosine functions of different frequencies:
|
| 147 |
+
|
| 148 |
+
\begin{align*}
|
| 149 |
+
PE_{(pos,2i)} = sin(pos / 10000^{2i/\dmodel}) \\
|
| 150 |
+
PE_{(pos,2i+1)} = cos(pos / 10000^{2i/\dmodel})
|
| 151 |
+
\end{align*}
|
| 152 |
+
|
| 153 |
+
where $pos$ is the position and $i$ is the dimension. That is, each dimension of the positional encoding corresponds to a sinusoid. The wavelengths form a geometric progression from $2\pi$ to $10000 \cdot 2\pi$. We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset $k$, $PE_{pos+k}$ can be represented as a linear function of $PE_{pos}$.
|
| 154 |
+
|
| 155 |
+
We also experimented with using learned positional embeddings \citep{JonasFaceNet2017} instead, and found that the two versions produced nearly identical results (see Table~\ref{tab:variations} row (E)). We chose the sinusoidal version because it may allow the model to extrapolate to sequence lengths longer than the ones encountered during training.
|
download/20230719163556/output/Attention-Is-All-You-Need/ms.tex
ADDED
|
@@ -0,0 +1,413 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
\documentclass{article}
|
| 2 |
+
|
| 3 |
+
% if you need to pass options to natbib, use, e.g.:
|
| 4 |
+
\PassOptionsToPackage{numbers, compress}{natbib}
|
| 5 |
+
% before loading nips_2017
|
| 6 |
+
%
|
| 7 |
+
% to avoid loading the natbib package, add option nonatbib:
|
| 8 |
+
% \usepackage[nonatbib]{nips_2017}
|
| 9 |
+
|
| 10 |
+
% Keep final for now to remove annoying line numbers.
|
| 11 |
+
%\usepackage[final]{nips_2017}
|
| 12 |
+
% Keep final for now to remove annoying line numbers.
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
% to compile a camera-ready version, add the [final] option, e.g.:
|
| 16 |
+
\usepackage[final]{nips_2017}
|
| 17 |
+
|
| 18 |
+
\usepackage[utf8]{inputenc} % allow utf-8 input
|
| 19 |
+
\usepackage[T1]{fontenc} % use 8-bit T1 fonts
|
| 20 |
+
\usepackage{hyperref} % hyperlinks
|
| 21 |
+
\usepackage{url} % simple URL typesetting
|
| 22 |
+
\usepackage{booktabs} % professional-quality tables
|
| 23 |
+
\usepackage{amsfonts} % blackboard math symbols
|
| 24 |
+
\usepackage{amsmath}
|
| 25 |
+
\usepackage{nicefrac} % compact symbols for 1/2, etc.
|
| 26 |
+
\usepackage{microtype} % microtypography
|
| 27 |
+
\usepackage{subfiles}
|
| 28 |
+
\usepackage{xcolor}
|
| 29 |
+
\usepackage{multirow}
|
| 30 |
+
\usepackage{enumerate}
|
| 31 |
+
\usepackage{subfiles}
|
| 32 |
+
\usepackage{multirow}
|
| 33 |
+
\usepackage{graphicx}
|
| 34 |
+
\usepackage{subfiles}
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
% % Custom Commands:
|
| 38 |
+
% \newcommand\blfootnote[1]{%
|
| 39 |
+
% \begingroup
|
| 40 |
+
% \renewcommand\thefootnote{}\footnote{#1}%
|
| 41 |
+
% \addtocounter{footnote}{-1}%
|
| 42 |
+
% \endgroup
|
| 43 |
+
% }
|
| 44 |
+
|
| 45 |
+
\newcommand\todo[1]{\textcolor{red}{[[#1]]}}
|
| 46 |
+
\newcommand\mc[1]{\mathcal{#1}}
|
| 47 |
+
\newcommand*\samethanks[1][\value{footnote}]{\footnotemark[#1]}
|
| 48 |
+
%keys for memory and values. Can be changed if needed
|
| 49 |
+
\newcommand{\kq}{q}
|
| 50 |
+
\newcommand{\km}{k}
|
| 51 |
+
\newcommand{\vq}{o}
|
| 52 |
+
\newcommand{\vm}{m}
|
| 53 |
+
\newcommand{\Wkq}{W_q}
|
| 54 |
+
\newcommand{\Wkm}{W_k}
|
| 55 |
+
\newcommand{\Wvq}{W_o}
|
| 56 |
+
\newcommand{\Wvm}{W_m}
|
| 57 |
+
\newcommand{\dmodel}{d_{\text{model}}}
|
| 58 |
+
\newcommand{\dffn}{d_{\text{ffn}}}
|
| 59 |
+
\newcommand{\dff}{d_{\text{ff}}}
|
| 60 |
+
\newcommand{\mbf}[1]{\mathbf{#1}}
|
| 61 |
+
%\newcommand{\kq}{{q}_k}
|
| 62 |
+
%\newcommand{\km}{{m}_k}
|
| 63 |
+
%\newcommand{\vq}{{q}_v}
|
| 64 |
+
%\newcommand{\vm}{{m}_v}
|
| 65 |
+
%\newcommand{\Wkq}{{W_q}_k}
|
| 66 |
+
%\newcommand{\Wkm}{{W_m}_k}
|
| 67 |
+
%\newcommand{\Wvq}{{W_q}_v}
|
| 68 |
+
%\newcommand{\Wvm}{{W_m}_v}
|
| 69 |
+
\newcommand\concat[3]{\left[#1 \parallel_#3 #2\right]}
|
| 70 |
+
|
| 71 |
+
\title{Attention Is All You Need}
|
| 72 |
+
|
| 73 |
+
% The \author macro works with any number of authors. There are two
|
| 74 |
+
% commands used to separate the names and addresses of multiple
|
| 75 |
+
% authors: \And and \AND.
|
| 76 |
+
%
|
| 77 |
+
% Using \And between authors leaves it to LaTeX to determine where to
|
| 78 |
+
% break the lines. Using \AND forces a line break at that point. So,
|
| 79 |
+
% if LaTeX puts 3 of 4 authors names on the first line, and the last
|
| 80 |
+
% on the second line, try using \AND instead of \And before the third
|
| 81 |
+
% author name.
|
| 82 |
+
\author{
|
| 83 |
+
\AND
|
| 84 |
+
Ashish Vaswani\thanks{Equal contribution. Listing order is random. Jakob proposed replacing RNNs with self-attention and started the effort to evaluate this idea.
|
| 85 |
+
Ashish, with Illia, designed and implemented the first Transformer models and has been crucially involved in every aspect of this work. Noam proposed scaled dot-product attention, multi-head attention and the parameter-free position representation and became the other person involved in nearly every detail. Niki designed, implemented, tuned and evaluated countless model variants in our original codebase and tensor2tensor. Llion also experimented with novel model variants, was responsible for our initial codebase, and efficient inference and visualizations. Lukasz and Aidan spent countless long days designing various parts of and implementing tensor2tensor, replacing our earlier codebase, greatly improving results and massively accelerating our research.
|
| 86 |
+
}\\
|
| 87 |
+
Google Brain\\
|
| 88 |
+
\texttt{[email protected]}\\
|
| 89 |
+
\And
|
| 90 |
+
Noam Shazeer\footnotemark[1]\\
|
| 91 |
+
Google Brain\\
|
| 92 |
+
\texttt{[email protected]}\\
|
| 93 |
+
\And
|
| 94 |
+
Niki Parmar\footnotemark[1]\\
|
| 95 |
+
Google Research\\
|
| 96 |
+
\texttt{[email protected]}\\
|
| 97 |
+
\And
|
| 98 |
+
Jakob Uszkoreit\footnotemark[1]\\
|
| 99 |
+
Google Research\\
|
| 100 |
+
\texttt{[email protected]}\\
|
| 101 |
+
\And
|
| 102 |
+
Llion Jones\footnotemark[1]\\
|
| 103 |
+
Google Research\\
|
| 104 |
+
\texttt{[email protected]}\\
|
| 105 |
+
\And
|
| 106 |
+
Aidan N. Gomez\footnotemark[1] \hspace{1.7mm}\thanks{Work performed while at Google Brain.}\\
|
| 107 |
+
University of Toronto\\
|
| 108 |
+
\texttt{[email protected]}
|
| 109 |
+
\And
|
| 110 |
+
{\L}ukasz Kaiser\footnotemark[1]\\
|
| 111 |
+
Google Brain\\
|
| 112 |
+
\texttt{[email protected]}\\
|
| 113 |
+
\And
|
| 114 |
+
Illia Polosukhin\footnotemark[1]\hspace{1.7mm} \thanks{Work performed while at Google Research.}\\
|
| 115 |
+
\texttt{[email protected]}\\
|
| 116 |
+
}
|
| 117 |
+
|
| 118 |
+
\begin{document}
|
| 119 |
+
|
| 120 |
+
\maketitle
|
| 121 |
+
|
| 122 |
+
\begin{abstract}
|
| 123 |
+
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
|
| 124 |
+
% \blfootnote{Code available at \url{https://github.com/tensorflow/tensor2tensor}}
|
| 125 |
+
|
| 126 |
+
%TODO(noam): update results for new models.
|
| 127 |
+
|
| 128 |
+
%llion@: FAIR's paper seems to concentrate solely on the convolutional aspect of their model and have the attention as an after thought almost, this gives us a good opportunity to differentiate ourselves from their paper.
|
| 129 |
+
|
| 130 |
+
%We are simpler in a number of ways and should have the simplicity as a big selling point:
|
| 131 |
+
%\begin{itemize}
|
| 132 |
+
%\item No convolutions
|
| 133 |
+
%\item No need for such careful initializations and %normalization.
|
| 134 |
+
%\item Simpler non-lineararities, they use the gated linear %units.
|
| 135 |
+
%\item Less layers?
|
| 136 |
+
%\end{itemize}
|
| 137 |
+
%One thing we do more is that we have self attention.
|
| 138 |
+
%Another selling point is the increased interpretability as %shown with the visualizations. Which comes from the %simplicity and use of only attentions.
|
| 139 |
+
\end{abstract}
|
| 140 |
+
|
| 141 |
+
\section{Introduction}
|
| 142 |
+
|
| 143 |
+
\input{introduction}
|
| 144 |
+
|
| 145 |
+
\section{Background}
|
| 146 |
+
|
| 147 |
+
\input{background}
|
| 148 |
+
|
| 149 |
+
\section{Model Architecture}
|
| 150 |
+
\input{model_architecture}
|
| 151 |
+
|
| 152 |
+
\section{Why Self-Attention}
|
| 153 |
+
\input{why_self_attention}
|
| 154 |
+
|
| 155 |
+
\section{Training}
|
| 156 |
+
\input{training}
|
| 157 |
+
|
| 158 |
+
\section{Results} \label{sec:results}
|
| 159 |
+
\input{results}
|
| 160 |
+
|
| 161 |
+
\section{Conclusion}
|
| 162 |
+
In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention.
|
| 163 |
+
|
| 164 |
+
For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles. %We also provide an indication of the broader applicability of our models through experiments on English constituency parsing.
|
| 165 |
+
|
| 166 |
+
We are excited about the future of attention-based models and plan to apply them to other tasks. We plan to extend the Transformer to problems involving input and output modalities other than text and to investigate local, restricted attention mechanisms to efficiently handle large inputs and outputs such as images, audio and video.
|
| 167 |
+
Making generation less sequential is another research goals of ours.
|
| 168 |
+
|
| 169 |
+
The code we used to train and evaluate our models is available at \url{https://github.com/tensorflow/tensor2tensor}.
|
| 170 |
+
|
| 171 |
+
\paragraph{Acknowledgements} We are grateful to Nal Kalchbrenner and Stephan Gouws for
|
| 172 |
+
their fruitful comments, corrections and inspiration.
|
| 173 |
+
|
| 174 |
+
\bibliographystyle{plain}
|
| 175 |
+
%\bibliography{deeplearn}
|
| 176 |
+
\begin{thebibliography}{10}
|
| 177 |
+
|
| 178 |
+
\bibitem{layernorm2016}
|
| 179 |
+
Jimmy~Lei Ba, Jamie~Ryan Kiros, and Geoffrey~E Hinton.
|
| 180 |
+
\newblock Layer normalization.
|
| 181 |
+
\newblock {\em arXiv preprint arXiv:1607.06450}, 2016.
|
| 182 |
+
|
| 183 |
+
\bibitem{bahdanau2014neural}
|
| 184 |
+
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio.
|
| 185 |
+
\newblock Neural machine translation by jointly learning to align and
|
| 186 |
+
translate.
|
| 187 |
+
\newblock {\em CoRR}, abs/1409.0473, 2014.
|
| 188 |
+
|
| 189 |
+
\bibitem{DBLP:journals/corr/BritzGLL17}
|
| 190 |
+
Denny Britz, Anna Goldie, Minh{-}Thang Luong, and Quoc~V. Le.
|
| 191 |
+
\newblock Massive exploration of neural machine translation architectures.
|
| 192 |
+
\newblock {\em CoRR}, abs/1703.03906, 2017.
|
| 193 |
+
|
| 194 |
+
\bibitem{cheng2016long}
|
| 195 |
+
Jianpeng Cheng, Li~Dong, and Mirella Lapata.
|
| 196 |
+
\newblock Long short-term memory-networks for machine reading.
|
| 197 |
+
\newblock {\em arXiv preprint arXiv:1601.06733}, 2016.
|
| 198 |
+
|
| 199 |
+
\bibitem{cho2014learning}
|
| 200 |
+
Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger
|
| 201 |
+
Schwenk, and Yoshua Bengio.
|
| 202 |
+
\newblock Learning phrase representations using rnn encoder-decoder for
|
| 203 |
+
statistical machine translation.
|
| 204 |
+
\newblock {\em CoRR}, abs/1406.1078, 2014.
|
| 205 |
+
|
| 206 |
+
\bibitem{xception2016}
|
| 207 |
+
Francois Chollet.
|
| 208 |
+
\newblock Xception: Deep learning with depthwise separable convolutions.
|
| 209 |
+
\newblock {\em arXiv preprint arXiv:1610.02357}, 2016.
|
| 210 |
+
|
| 211 |
+
\bibitem{gruEval14}
|
| 212 |
+
Junyoung Chung, {\c{C}}aglar G{\"{u}}l{\c{c}}ehre, Kyunghyun Cho, and Yoshua
|
| 213 |
+
Bengio.
|
| 214 |
+
\newblock Empirical evaluation of gated recurrent neural networks on sequence
|
| 215 |
+
modeling.
|
| 216 |
+
\newblock {\em CoRR}, abs/1412.3555, 2014.
|
| 217 |
+
|
| 218 |
+
\bibitem{dyer-rnng:16}
|
| 219 |
+
Chris Dyer, Adhiguna Kuncoro, Miguel Ballesteros, and Noah~A. Smith.
|
| 220 |
+
\newblock Recurrent neural network grammars.
|
| 221 |
+
\newblock In {\em Proc. of NAACL}, 2016.
|
| 222 |
+
|
| 223 |
+
\bibitem{JonasFaceNet2017}
|
| 224 |
+
Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann~N. Dauphin.
|
| 225 |
+
\newblock Convolutional sequence to sequence learning.
|
| 226 |
+
\newblock {\em arXiv preprint arXiv:1705.03122v2}, 2017.
|
| 227 |
+
|
| 228 |
+
\bibitem{graves2013generating}
|
| 229 |
+
Alex Graves.
|
| 230 |
+
\newblock Generating sequences with recurrent neural networks.
|
| 231 |
+
\newblock {\em arXiv preprint arXiv:1308.0850}, 2013.
|
| 232 |
+
|
| 233 |
+
\bibitem{he2016deep}
|
| 234 |
+
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
|
| 235 |
+
\newblock Deep residual learning for image recognition.
|
| 236 |
+
\newblock In {\em Proceedings of the IEEE Conference on Computer Vision and
|
| 237 |
+
Pattern Recognition}, pages 770--778, 2016.
|
| 238 |
+
|
| 239 |
+
\bibitem{hochreiter2001gradient}
|
| 240 |
+
Sepp Hochreiter, Yoshua Bengio, Paolo Frasconi, and J{\"u}rgen Schmidhuber.
|
| 241 |
+
\newblock Gradient flow in recurrent nets: the difficulty of learning long-term
|
| 242 |
+
dependencies, 2001.
|
| 243 |
+
|
| 244 |
+
\bibitem{hochreiter1997}
|
| 245 |
+
Sepp Hochreiter and J{\"u}rgen Schmidhuber.
|
| 246 |
+
\newblock Long short-term memory.
|
| 247 |
+
\newblock {\em Neural computation}, 9(8):1735--1780, 1997.
|
| 248 |
+
|
| 249 |
+
\bibitem{huang-harper:2009:EMNLP}
|
| 250 |
+
Zhongqiang Huang and Mary Harper.
|
| 251 |
+
\newblock Self-training {PCFG} grammars with latent annotations across
|
| 252 |
+
languages.
|
| 253 |
+
\newblock In {\em Proceedings of the 2009 Conference on Empirical Methods in
|
| 254 |
+
Natural Language Processing}, pages 832--841. ACL, August 2009.
|
| 255 |
+
|
| 256 |
+
\bibitem{jozefowicz2016exploring}
|
| 257 |
+
Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, and Yonghui Wu.
|
| 258 |
+
\newblock Exploring the limits of language modeling.
|
| 259 |
+
\newblock {\em arXiv preprint arXiv:1602.02410}, 2016.
|
| 260 |
+
|
| 261 |
+
\bibitem{extendedngpu}
|
| 262 |
+
{\L}ukasz Kaiser and Samy Bengio.
|
| 263 |
+
\newblock Can active memory replace attention?
|
| 264 |
+
\newblock In {\em Advances in Neural Information Processing Systems, ({NIPS})},
|
| 265 |
+
2016.
|
| 266 |
+
|
| 267 |
+
\bibitem{neural_gpu}
|
| 268 |
+
\L{}ukasz Kaiser and Ilya Sutskever.
|
| 269 |
+
\newblock Neural {GPU}s learn algorithms.
|
| 270 |
+
\newblock In {\em International Conference on Learning Representations
|
| 271 |
+
({ICLR})}, 2016.
|
| 272 |
+
|
| 273 |
+
\bibitem{NalBytenet2017}
|
| 274 |
+
Nal Kalchbrenner, Lasse Espeholt, Karen Simonyan, Aaron van~den Oord, Alex
|
| 275 |
+
Graves, and Koray Kavukcuoglu.
|
| 276 |
+
\newblock Neural machine translation in linear time.
|
| 277 |
+
\newblock {\em arXiv preprint arXiv:1610.10099v2}, 2017.
|
| 278 |
+
|
| 279 |
+
\bibitem{structuredAttentionNetworks}
|
| 280 |
+
Yoon Kim, Carl Denton, Luong Hoang, and Alexander~M. Rush.
|
| 281 |
+
\newblock Structured attention networks.
|
| 282 |
+
\newblock In {\em International Conference on Learning Representations}, 2017.
|
| 283 |
+
|
| 284 |
+
\bibitem{kingma2014adam}
|
| 285 |
+
Diederik Kingma and Jimmy Ba.
|
| 286 |
+
\newblock Adam: A method for stochastic optimization.
|
| 287 |
+
\newblock In {\em ICLR}, 2015.
|
| 288 |
+
|
| 289 |
+
\bibitem{Kuchaiev2017Factorization}
|
| 290 |
+
Oleksii Kuchaiev and Boris Ginsburg.
|
| 291 |
+
\newblock Factorization tricks for {LSTM} networks.
|
| 292 |
+
\newblock {\em arXiv preprint arXiv:1703.10722}, 2017.
|
| 293 |
+
|
| 294 |
+
\bibitem{lin2017structured}
|
| 295 |
+
Zhouhan Lin, Minwei Feng, Cicero Nogueira~dos Santos, Mo~Yu, Bing Xiang, Bowen
|
| 296 |
+
Zhou, and Yoshua Bengio.
|
| 297 |
+
\newblock A structured self-attentive sentence embedding.
|
| 298 |
+
\newblock {\em arXiv preprint arXiv:1703.03130}, 2017.
|
| 299 |
+
|
| 300 |
+
\bibitem{multiseq2seq}
|
| 301 |
+
Minh-Thang Luong, Quoc~V. Le, Ilya Sutskever, Oriol Vinyals, and Lukasz Kaiser.
|
| 302 |
+
\newblock Multi-task sequence to sequence learning.
|
| 303 |
+
\newblock {\em arXiv preprint arXiv:1511.06114}, 2015.
|
| 304 |
+
|
| 305 |
+
\bibitem{luong2015effective}
|
| 306 |
+
Minh-Thang Luong, Hieu Pham, and Christopher~D Manning.
|
| 307 |
+
\newblock Effective approaches to attention-based neural machine translation.
|
| 308 |
+
\newblock {\em arXiv preprint arXiv:1508.04025}, 2015.
|
| 309 |
+
|
| 310 |
+
\bibitem{marcus1993building}
|
| 311 |
+
Mitchell~P Marcus, Mary~Ann Marcinkiewicz, and Beatrice Santorini.
|
| 312 |
+
\newblock Building a large annotated corpus of english: The penn treebank.
|
| 313 |
+
\newblock {\em Computational linguistics}, 19(2):313--330, 1993.
|
| 314 |
+
|
| 315 |
+
\bibitem{mcclosky-etAl:2006:NAACL}
|
| 316 |
+
David McClosky, Eugene Charniak, and Mark Johnson.
|
| 317 |
+
\newblock Effective self-training for parsing.
|
| 318 |
+
\newblock In {\em Proceedings of the Human Language Technology Conference of
|
| 319 |
+
the NAACL, Main Conference}, pages 152--159. ACL, June 2006.
|
| 320 |
+
|
| 321 |
+
\bibitem{decomposableAttnModel}
|
| 322 |
+
Ankur Parikh, Oscar Täckström, Dipanjan Das, and Jakob Uszkoreit.
|
| 323 |
+
\newblock A decomposable attention model.
|
| 324 |
+
\newblock In {\em Empirical Methods in Natural Language Processing}, 2016.
|
| 325 |
+
|
| 326 |
+
\bibitem{paulus2017deep}
|
| 327 |
+
Romain Paulus, Caiming Xiong, and Richard Socher.
|
| 328 |
+
\newblock A deep reinforced model for abstractive summarization.
|
| 329 |
+
\newblock {\em arXiv preprint arXiv:1705.04304}, 2017.
|
| 330 |
+
|
| 331 |
+
\bibitem{petrov-EtAl:2006:ACL}
|
| 332 |
+
Slav Petrov, Leon Barrett, Romain Thibaux, and Dan Klein.
|
| 333 |
+
\newblock Learning accurate, compact, and interpretable tree annotation.
|
| 334 |
+
\newblock In {\em Proceedings of the 21st International Conference on
|
| 335 |
+
Computational Linguistics and 44th Annual Meeting of the ACL}, pages
|
| 336 |
+
433--440. ACL, July 2006.
|
| 337 |
+
|
| 338 |
+
\bibitem{press2016using}
|
| 339 |
+
Ofir Press and Lior Wolf.
|
| 340 |
+
\newblock Using the output embedding to improve language models.
|
| 341 |
+
\newblock {\em arXiv preprint arXiv:1608.05859}, 2016.
|
| 342 |
+
|
| 343 |
+
\bibitem{sennrich2015neural}
|
| 344 |
+
Rico Sennrich, Barry Haddow, and Alexandra Birch.
|
| 345 |
+
\newblock Neural machine translation of rare words with subword units.
|
| 346 |
+
\newblock {\em arXiv preprint arXiv:1508.07909}, 2015.
|
| 347 |
+
|
| 348 |
+
\bibitem{shazeer2017outrageously}
|
| 349 |
+
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le,
|
| 350 |
+
Geoffrey Hinton, and Jeff Dean.
|
| 351 |
+
\newblock Outrageously large neural networks: The sparsely-gated
|
| 352 |
+
mixture-of-experts layer.
|
| 353 |
+
\newblock {\em arXiv preprint arXiv:1701.06538}, 2017.
|
| 354 |
+
|
| 355 |
+
\bibitem{srivastava2014dropout}
|
| 356 |
+
Nitish Srivastava, Geoffrey~E Hinton, Alex Krizhevsky, Ilya Sutskever, and
|
| 357 |
+
Ruslan Salakhutdinov.
|
| 358 |
+
\newblock Dropout: a simple way to prevent neural networks from overfitting.
|
| 359 |
+
\newblock {\em Journal of Machine Learning Research}, 15(1):1929--1958, 2014.
|
| 360 |
+
|
| 361 |
+
\bibitem{sukhbaatar2015}
|
| 362 |
+
Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus.
|
| 363 |
+
\newblock End-to-end memory networks.
|
| 364 |
+
\newblock In C.~Cortes, N.~D. Lawrence, D.~D. Lee, M.~Sugiyama, and R.~Garnett,
|
| 365 |
+
editors, {\em Advances in Neural Information Processing Systems 28}, pages
|
| 366 |
+
2440--2448. Curran Associates, Inc., 2015.
|
| 367 |
+
|
| 368 |
+
\bibitem{sutskever14}
|
| 369 |
+
Ilya Sutskever, Oriol Vinyals, and Quoc~VV Le.
|
| 370 |
+
\newblock Sequence to sequence learning with neural networks.
|
| 371 |
+
\newblock In {\em Advances in Neural Information Processing Systems}, pages
|
| 372 |
+
3104--3112, 2014.
|
| 373 |
+
|
| 374 |
+
\bibitem{DBLP:journals/corr/SzegedyVISW15}
|
| 375 |
+
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and
|
| 376 |
+
Zbigniew Wojna.
|
| 377 |
+
\newblock Rethinking the inception architecture for computer vision.
|
| 378 |
+
\newblock {\em CoRR}, abs/1512.00567, 2015.
|
| 379 |
+
|
| 380 |
+
\bibitem{KVparse15}
|
| 381 |
+
{Vinyals {\&} Kaiser}, Koo, Petrov, Sutskever, and Hinton.
|
| 382 |
+
\newblock Grammar as a foreign language.
|
| 383 |
+
\newblock In {\em Advances in Neural Information Processing Systems}, 2015.
|
| 384 |
+
|
| 385 |
+
\bibitem{wu2016google}
|
| 386 |
+
Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc~V Le, Mohammad Norouzi, Wolfgang
|
| 387 |
+
Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et~al.
|
| 388 |
+
\newblock Google's neural machine translation system: Bridging the gap between
|
| 389 |
+
human and machine translation.
|
| 390 |
+
\newblock {\em arXiv preprint arXiv:1609.08144}, 2016.
|
| 391 |
+
|
| 392 |
+
\bibitem{DBLP:journals/corr/ZhouCWLX16}
|
| 393 |
+
Jie Zhou, Ying Cao, Xuguang Wang, Peng Li, and Wei Xu.
|
| 394 |
+
\newblock Deep recurrent models with fast-forward connections for neural
|
| 395 |
+
machine translation.
|
| 396 |
+
\newblock {\em CoRR}, abs/1606.04199, 2016.
|
| 397 |
+
|
| 398 |
+
\bibitem{zhu-EtAl:2013:ACL}
|
| 399 |
+
Muhua Zhu, Yue Zhang, Wenliang Chen, Min Zhang, and Jingbo Zhu.
|
| 400 |
+
\newblock Fast and accurate shift-reduce constituent parsing.
|
| 401 |
+
\newblock In {\em Proceedings of the 51st Annual Meeting of the ACL (Volume 1:
|
| 402 |
+
Long Papers)}, pages 434--443. ACL, August 2013.
|
| 403 |
+
|
| 404 |
+
\end{thebibliography}
|
| 405 |
+
%\newpage
|
| 406 |
+
\input{visualizations}
|
| 407 |
+
%\appendix
|
| 408 |
+
%\newpage
|
| 409 |
+
%\input{parameter_attention}
|
| 410 |
+
|
| 411 |
+
%\input{sqrt_d_trick}
|
| 412 |
+
|
| 413 |
+
\end{document}
|
download/20230719163556/output/Attention-Is-All-You-Need/nips_2017.sty
ADDED
|
@@ -0,0 +1,338 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
% partial rewrite of the LaTeX2e package for submissions to the
|
| 2 |
+
% Conference on Neural Information Processing Systems (NIPS):
|
| 3 |
+
%
|
| 4 |
+
% - uses more LaTeX conventions
|
| 5 |
+
% - line numbers at submission time replaced with aligned numbers from
|
| 6 |
+
% lineno package
|
| 7 |
+
% - \nipsfinalcopy replaced with [final] package option
|
| 8 |
+
% - automatically loads times package for authors
|
| 9 |
+
% - loads natbib automatically; this can be suppressed with the
|
| 10 |
+
% [nonatbib] package option
|
| 11 |
+
% - adds foot line to first page identifying the conference
|
| 12 |
+
%
|
| 13 |
+
% Roman Garnett ([email protected]) and the many authors of
|
| 14 |
+
% nips15submit_e.sty, including MK and drstrip@sandia
|
| 15 |
+
%
|
| 16 |
+
% last revision: March 2017
|
| 17 |
+
|
| 18 |
+
\NeedsTeXFormat{LaTeX2e}
|
| 19 |
+
\ProvidesPackage{nips_2017}[2017/03/20 NIPS 2017 submission/camera-ready style file]
|
| 20 |
+
|
| 21 |
+
% declare final option, which creates camera-ready copy
|
| 22 |
+
\newif\if@nipsfinal\@nipsfinalfalse
|
| 23 |
+
\DeclareOption{final}{
|
| 24 |
+
\@nipsfinaltrue
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
% declare nonatbib option, which does not load natbib in case of
|
| 28 |
+
% package clash (users can pass options to natbib via
|
| 29 |
+
% \PassOptionsToPackage)
|
| 30 |
+
\newif\if@natbib\@natbibtrue
|
| 31 |
+
\DeclareOption{nonatbib}{
|
| 32 |
+
\@natbibfalse
|
| 33 |
+
}
|
| 34 |
+
|
| 35 |
+
\ProcessOptions\relax
|
| 36 |
+
|
| 37 |
+
% fonts
|
| 38 |
+
\renewcommand{\rmdefault}{ptm}
|
| 39 |
+
\renewcommand{\sfdefault}{phv}
|
| 40 |
+
|
| 41 |
+
% change this every year for notice string at bottom
|
| 42 |
+
\newcommand{\@nipsordinal}{31st}
|
| 43 |
+
\newcommand{\@nipsyear}{2017}
|
| 44 |
+
\newcommand{\@nipslocation}{Long Beach, CA, USA}
|
| 45 |
+
|
| 46 |
+
% handle tweaks for camera-ready copy vs. submission copy
|
| 47 |
+
\if@nipsfinal
|
| 48 |
+
\newcommand{\@noticestring}{%
|
| 49 |
+
\@nipsordinal\/ Conference on Neural Information Processing Systems
|
| 50 |
+
(NIPS \@nipsyear), \@nipslocation.%
|
| 51 |
+
}
|
| 52 |
+
\else
|
| 53 |
+
\newcommand{\@noticestring}{%
|
| 54 |
+
Submitted to \@nipsordinal\/ Conference on Neural Information
|
| 55 |
+
Processing Systems (NIPS \@nipsyear). Do not distribute.%
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
% line numbers for submission
|
| 59 |
+
\RequirePackage{lineno}
|
| 60 |
+
\linenumbers
|
| 61 |
+
|
| 62 |
+
% fix incompatibilities between lineno and amsmath, if required, by
|
| 63 |
+
% transparently wrapping linenomath environments around amsmath
|
| 64 |
+
% environments
|
| 65 |
+
\AtBeginDocument{%
|
| 66 |
+
\@ifpackageloaded{amsmath}{%
|
| 67 |
+
\newcommand*\patchAmsMathEnvironmentForLineno[1]{%
|
| 68 |
+
\expandafter\let\csname old#1\expandafter\endcsname\csname #1\endcsname
|
| 69 |
+
\expandafter\let\csname oldend#1\expandafter\endcsname\csname end#1\endcsname
|
| 70 |
+
\renewenvironment{#1}%
|
| 71 |
+
{\linenomath\csname old#1\endcsname}%
|
| 72 |
+
{\csname oldend#1\endcsname\endlinenomath}%
|
| 73 |
+
}%
|
| 74 |
+
\newcommand*\patchBothAmsMathEnvironmentsForLineno[1]{%
|
| 75 |
+
\patchAmsMathEnvironmentForLineno{#1}%
|
| 76 |
+
\patchAmsMathEnvironmentForLineno{#1*}%
|
| 77 |
+
}%
|
| 78 |
+
\patchBothAmsMathEnvironmentsForLineno{equation}%
|
| 79 |
+
\patchBothAmsMathEnvironmentsForLineno{align}%
|
| 80 |
+
\patchBothAmsMathEnvironmentsForLineno{flalign}%
|
| 81 |
+
\patchBothAmsMathEnvironmentsForLineno{alignat}%
|
| 82 |
+
\patchBothAmsMathEnvironmentsForLineno{gather}%
|
| 83 |
+
\patchBothAmsMathEnvironmentsForLineno{multline}%
|
| 84 |
+
}{}
|
| 85 |
+
}
|
| 86 |
+
\fi
|
| 87 |
+
|
| 88 |
+
% load natbib unless told otherwise
|
| 89 |
+
\if@natbib
|
| 90 |
+
\RequirePackage{natbib}
|
| 91 |
+
\fi
|
| 92 |
+
|
| 93 |
+
% set page geometry
|
| 94 |
+
\usepackage[verbose=true,letterpaper]{geometry}
|
| 95 |
+
\AtBeginDocument{
|
| 96 |
+
\newgeometry{
|
| 97 |
+
textheight=9in,
|
| 98 |
+
textwidth=5.5in,
|
| 99 |
+
top=1in,
|
| 100 |
+
headheight=12pt,
|
| 101 |
+
headsep=25pt,
|
| 102 |
+
footskip=30pt
|
| 103 |
+
}
|
| 104 |
+
\@ifpackageloaded{fullpage}
|
| 105 |
+
{\PackageWarning{nips_2016}{fullpage package not allowed! Overwriting formatting.}}
|
| 106 |
+
{}
|
| 107 |
+
}
|
| 108 |
+
|
| 109 |
+
\widowpenalty=10000
|
| 110 |
+
\clubpenalty=10000
|
| 111 |
+
\flushbottom
|
| 112 |
+
\sloppy
|
| 113 |
+
|
| 114 |
+
% font sizes with reduced leading
|
| 115 |
+
\renewcommand{\normalsize}{%
|
| 116 |
+
\@setfontsize\normalsize\@xpt\@xipt
|
| 117 |
+
\abovedisplayskip 7\p@ \@plus 2\p@ \@minus 5\p@
|
| 118 |
+
\abovedisplayshortskip \z@ \@plus 3\p@
|
| 119 |
+
\belowdisplayskip \abovedisplayskip
|
| 120 |
+
\belowdisplayshortskip 4\p@ \@plus 3\p@ \@minus 3\p@
|
| 121 |
+
}
|
| 122 |
+
\normalsize
|
| 123 |
+
\renewcommand{\small}{%
|
| 124 |
+
\@setfontsize\small\@ixpt\@xpt
|
| 125 |
+
\abovedisplayskip 6\p@ \@plus 1.5\p@ \@minus 4\p@
|
| 126 |
+
\abovedisplayshortskip \z@ \@plus 2\p@
|
| 127 |
+
\belowdisplayskip \abovedisplayskip
|
| 128 |
+
\belowdisplayshortskip 3\p@ \@plus 2\p@ \@minus 2\p@
|
| 129 |
+
}
|
| 130 |
+
\renewcommand{\footnotesize}{\@setfontsize\footnotesize\@ixpt\@xpt}
|
| 131 |
+
\renewcommand{\scriptsize}{\@setfontsize\scriptsize\@viipt\@viiipt}
|
| 132 |
+
\renewcommand{\tiny}{\@setfontsize\tiny\@vipt\@viipt}
|
| 133 |
+
\renewcommand{\large}{\@setfontsize\large\@xiipt{14}}
|
| 134 |
+
\renewcommand{\Large}{\@setfontsize\Large\@xivpt{16}}
|
| 135 |
+
\renewcommand{\LARGE}{\@setfontsize\LARGE\@xviipt{20}}
|
| 136 |
+
\renewcommand{\huge}{\@setfontsize\huge\@xxpt{23}}
|
| 137 |
+
\renewcommand{\Huge}{\@setfontsize\Huge\@xxvpt{28}}
|
| 138 |
+
|
| 139 |
+
% sections with less space
|
| 140 |
+
\providecommand{\section}{}
|
| 141 |
+
\renewcommand{\section}{%
|
| 142 |
+
\@startsection{section}{1}{\z@}%
|
| 143 |
+
{-2.0ex \@plus -0.5ex \@minus -0.2ex}%
|
| 144 |
+
{ 1.5ex \@plus 0.3ex \@minus 0.2ex}%
|
| 145 |
+
{\large\bf\raggedright}%
|
| 146 |
+
}
|
| 147 |
+
\providecommand{\subsection}{}
|
| 148 |
+
\renewcommand{\subsection}{%
|
| 149 |
+
\@startsection{subsection}{2}{\z@}%
|
| 150 |
+
{-1.8ex \@plus -0.5ex \@minus -0.2ex}%
|
| 151 |
+
{ 0.8ex \@plus 0.2ex}%
|
| 152 |
+
{\normalsize\bf\raggedright}%
|
| 153 |
+
}
|
| 154 |
+
\providecommand{\subsubsection}{}
|
| 155 |
+
\renewcommand{\subsubsection}{%
|
| 156 |
+
\@startsection{subsubsection}{3}{\z@}%
|
| 157 |
+
{-1.5ex \@plus -0.5ex \@minus -0.2ex}%
|
| 158 |
+
{ 0.5ex \@plus 0.2ex}%
|
| 159 |
+
{\normalsize\bf\raggedright}%
|
| 160 |
+
}
|
| 161 |
+
\providecommand{\paragraph}{}
|
| 162 |
+
\renewcommand{\paragraph}{%
|
| 163 |
+
\@startsection{paragraph}{4}{\z@}%
|
| 164 |
+
{1.5ex \@plus 0.5ex \@minus 0.2ex}%
|
| 165 |
+
{-1em}%
|
| 166 |
+
{\normalsize\bf}%
|
| 167 |
+
}
|
| 168 |
+
\providecommand{\subparagraph}{}
|
| 169 |
+
\renewcommand{\subparagraph}{%
|
| 170 |
+
\@startsection{subparagraph}{5}{\z@}%
|
| 171 |
+
{1.5ex \@plus 0.5ex \@minus 0.2ex}%
|
| 172 |
+
{-1em}%
|
| 173 |
+
{\normalsize\bf}%
|
| 174 |
+
}
|
| 175 |
+
\providecommand{\subsubsubsection}{}
|
| 176 |
+
\renewcommand{\subsubsubsection}{%
|
| 177 |
+
\vskip5pt{\noindent\normalsize\rm\raggedright}%
|
| 178 |
+
}
|
| 179 |
+
|
| 180 |
+
% float placement
|
| 181 |
+
\renewcommand{\topfraction }{0.85}
|
| 182 |
+
\renewcommand{\bottomfraction }{0.4}
|
| 183 |
+
\renewcommand{\textfraction }{0.1}
|
| 184 |
+
\renewcommand{\floatpagefraction}{0.7}
|
| 185 |
+
|
| 186 |
+
\newlength{\@nipsabovecaptionskip}\setlength{\@nipsabovecaptionskip}{7\p@}
|
| 187 |
+
\newlength{\@nipsbelowcaptionskip}\setlength{\@nipsbelowcaptionskip}{\z@}
|
| 188 |
+
|
| 189 |
+
\setlength{\abovecaptionskip}{\@nipsabovecaptionskip}
|
| 190 |
+
\setlength{\belowcaptionskip}{\@nipsbelowcaptionskip}
|
| 191 |
+
|
| 192 |
+
% swap above/belowcaptionskip lengths for tables
|
| 193 |
+
\renewenvironment{table}
|
| 194 |
+
{\setlength{\abovecaptionskip}{\@nipsbelowcaptionskip}%
|
| 195 |
+
\setlength{\belowcaptionskip}{\@nipsabovecaptionskip}%
|
| 196 |
+
\@float{table}}
|
| 197 |
+
{\end@float}
|
| 198 |
+
|
| 199 |
+
% footnote formatting
|
| 200 |
+
\setlength{\footnotesep }{6.65\p@}
|
| 201 |
+
\setlength{\skip\footins}{9\p@ \@plus 4\p@ \@minus 2\p@}
|
| 202 |
+
\renewcommand{\footnoterule}{\kern-3\p@ \hrule width 12pc \kern 2.6\p@}
|
| 203 |
+
\setcounter{footnote}{0}
|
| 204 |
+
|
| 205 |
+
% paragraph formatting
|
| 206 |
+
\setlength{\parindent}{\z@}
|
| 207 |
+
\setlength{\parskip }{5.5\p@}
|
| 208 |
+
|
| 209 |
+
% list formatting
|
| 210 |
+
\setlength{\topsep }{4\p@ \@plus 1\p@ \@minus 2\p@}
|
| 211 |
+
\setlength{\partopsep }{1\p@ \@plus 0.5\p@ \@minus 0.5\p@}
|
| 212 |
+
\setlength{\itemsep }{2\p@ \@plus 1\p@ \@minus 0.5\p@}
|
| 213 |
+
\setlength{\parsep }{2\p@ \@plus 1\p@ \@minus 0.5\p@}
|
| 214 |
+
\setlength{\leftmargin }{3pc}
|
| 215 |
+
\setlength{\leftmargini }{\leftmargin}
|
| 216 |
+
\setlength{\leftmarginii }{2em}
|
| 217 |
+
\setlength{\leftmarginiii}{1.5em}
|
| 218 |
+
\setlength{\leftmarginiv }{1.0em}
|
| 219 |
+
\setlength{\leftmarginv }{0.5em}
|
| 220 |
+
\def\@listi {\leftmargin\leftmargini}
|
| 221 |
+
\def\@listii {\leftmargin\leftmarginii
|
| 222 |
+
\labelwidth\leftmarginii
|
| 223 |
+
\advance\labelwidth-\labelsep
|
| 224 |
+
\topsep 2\p@ \@plus 1\p@ \@minus 0.5\p@
|
| 225 |
+
\parsep 1\p@ \@plus 0.5\p@ \@minus 0.5\p@
|
| 226 |
+
\itemsep \parsep}
|
| 227 |
+
\def\@listiii{\leftmargin\leftmarginiii
|
| 228 |
+
\labelwidth\leftmarginiii
|
| 229 |
+
\advance\labelwidth-\labelsep
|
| 230 |
+
\topsep 1\p@ \@plus 0.5\p@ \@minus 0.5\p@
|
| 231 |
+
\parsep \z@
|
| 232 |
+
\partopsep 0.5\p@ \@plus 0\p@ \@minus 0.5\p@
|
| 233 |
+
\itemsep \topsep}
|
| 234 |
+
\def\@listiv {\leftmargin\leftmarginiv
|
| 235 |
+
\labelwidth\leftmarginiv
|
| 236 |
+
\advance\labelwidth-\labelsep}
|
| 237 |
+
\def\@listv {\leftmargin\leftmarginv
|
| 238 |
+
\labelwidth\leftmarginv
|
| 239 |
+
\advance\labelwidth-\labelsep}
|
| 240 |
+
\def\@listvi {\leftmargin\leftmarginvi
|
| 241 |
+
\labelwidth\leftmarginvi
|
| 242 |
+
\advance\labelwidth-\labelsep}
|
| 243 |
+
|
| 244 |
+
% create title
|
| 245 |
+
\providecommand{\maketitle}{}
|
| 246 |
+
\renewcommand{\maketitle}{%
|
| 247 |
+
\par
|
| 248 |
+
\begingroup
|
| 249 |
+
\renewcommand{\thefootnote}{\fnsymbol{footnote}}
|
| 250 |
+
% for perfect author name centering
|
| 251 |
+
\renewcommand{\@makefnmark}{\hbox to \z@{$^{\@thefnmark}$\hss}}
|
| 252 |
+
% The footnote-mark was overlapping the footnote-text,
|
| 253 |
+
% added the following to fix this problem (MK)
|
| 254 |
+
\long\def\@makefntext##1{%
|
| 255 |
+
\parindent 1em\noindent
|
| 256 |
+
\hbox to 1.8em{\hss $\m@th ^{\@thefnmark}$}##1
|
| 257 |
+
}
|
| 258 |
+
\thispagestyle{empty}
|
| 259 |
+
\@maketitle
|
| 260 |
+
\@thanks
|
| 261 |
+
\@notice
|
| 262 |
+
\endgroup
|
| 263 |
+
\let\maketitle\relax
|
| 264 |
+
\let\thanks\relax
|
| 265 |
+
}
|
| 266 |
+
|
| 267 |
+
% rules for title box at top of first page
|
| 268 |
+
\newcommand{\@toptitlebar}{
|
| 269 |
+
\hrule height 4\p@
|
| 270 |
+
\vskip 0.25in
|
| 271 |
+
\vskip -\parskip%
|
| 272 |
+
}
|
| 273 |
+
\newcommand{\@bottomtitlebar}{
|
| 274 |
+
\vskip 0.29in
|
| 275 |
+
\vskip -\parskip
|
| 276 |
+
\hrule height 1\p@
|
| 277 |
+
\vskip 0.09in%
|
| 278 |
+
}
|
| 279 |
+
|
| 280 |
+
% create title (includes both anonymized and non-anonymized versions)
|
| 281 |
+
\providecommand{\@maketitle}{}
|
| 282 |
+
\renewcommand{\@maketitle}{%
|
| 283 |
+
\vbox{%
|
| 284 |
+
\hsize\textwidth
|
| 285 |
+
\linewidth\hsize
|
| 286 |
+
\vskip 0.1in
|
| 287 |
+
\@toptitlebar
|
| 288 |
+
\centering
|
| 289 |
+
{\LARGE\bf \@title\par}
|
| 290 |
+
\@bottomtitlebar
|
| 291 |
+
\if@nipsfinal
|
| 292 |
+
\def\And{%
|
| 293 |
+
\end{tabular}\hfil\linebreak[0]\hfil%
|
| 294 |
+
\begin{tabular}[t]{c}\bf\rule{\z@}{24\p@}\ignorespaces%
|
| 295 |
+
}
|
| 296 |
+
\def\AND{%
|
| 297 |
+
\end{tabular}\hfil\linebreak[4]\hfil%
|
| 298 |
+
\begin{tabular}[t]{c}\bf\rule{\z@}{24\p@}\ignorespaces%
|
| 299 |
+
}
|
| 300 |
+
\begin{tabular}[t]{c}\bf\rule{\z@}{24\p@}\@author\end{tabular}%
|
| 301 |
+
\else
|
| 302 |
+
\begin{tabular}[t]{c}\bf\rule{\z@}{24\p@}
|
| 303 |
+
Anonymous Author(s) \\
|
| 304 |
+
Affiliation \\
|
| 305 |
+
Address \\
|
| 306 |
+
\texttt{email} \\
|
| 307 |
+
\end{tabular}%
|
| 308 |
+
\fi
|
| 309 |
+
\vskip 0.3in \@minus 0.1in
|
| 310 |
+
}
|
| 311 |
+
}
|
| 312 |
+
|
| 313 |
+
% add conference notice to bottom of first page
|
| 314 |
+
\newcommand{\ftype@noticebox}{8}
|
| 315 |
+
\newcommand{\@notice}{%
|
| 316 |
+
% give a bit of extra room back to authors on first page
|
| 317 |
+
\enlargethispage{2\baselineskip}%
|
| 318 |
+
\@float{noticebox}[b]%
|
| 319 |
+
\footnotesize\@noticestring%
|
| 320 |
+
\end@float%
|
| 321 |
+
}
|
| 322 |
+
|
| 323 |
+
% abstract styling
|
| 324 |
+
\renewenvironment{abstract}%
|
| 325 |
+
{%
|
| 326 |
+
\vskip 0.075in%
|
| 327 |
+
\centerline%
|
| 328 |
+
{\large\bf Abstract}%
|
| 329 |
+
\vspace{0.5ex}%
|
| 330 |
+
\begin{quote}%
|
| 331 |
+
}
|
| 332 |
+
{
|
| 333 |
+
\par%
|
| 334 |
+
\end{quote}%
|
| 335 |
+
\vskip 1ex%
|
| 336 |
+
}
|
| 337 |
+
|
| 338 |
+
\endinput
|
download/20230719163556/output/Attention-Is-All-You-Need/parameter_attention.tex
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
\pagebreak
|
| 2 |
+
\section*{Two Feed-Forward Layers = Attention over Parameters}\label{sec:parameter_attention}
|
| 3 |
+
|
| 4 |
+
In addition to attention layers, our model contains position-wise feed-forward networks (Section \ref{sec:ffn}), which consist of two linear transformations with a ReLU activation in between. In fact, these networks too can be seen as a form of attention. Compare the formula for such a network with the formula for a simple dot-product attention layer (biases and scaling factors omitted):
|
| 5 |
+
|
| 6 |
+
\begin{align*}
|
| 7 |
+
FFN(x, W_1, W_2) = ReLU(xW_1)W_2 \\
|
| 8 |
+
A(q, K, V) = Softmax(qK^T)V
|
| 9 |
+
\end{align*}
|
| 10 |
+
|
| 11 |
+
Based on the similarity of these formulae, the two-layer feed-forward network can be seen as a kind of attention, where the keys and values are the rows of the trainable parameter matrices $W_1$ and $W_2$, and where we use ReLU instead of Softmax in the compatibility function.
|
| 12 |
+
|
| 13 |
+
%the compatablity function is $compat(q, k_i) = ReLU(q \cdot k_i)$ instead of $Softmax(qK_T)_i$.
|
| 14 |
+
|
| 15 |
+
Given this similarity, we experimented with replacing the position-wise feed-forward networks with attention layers similar to the ones we use everywhere else our model. The multi-head-attention-over-parameters sublayer is identical to the multi-head attention described in \ref{sec:multihead}, except that the "keys" and "values" inputs to each attention head are trainable model parameters, as opposed to being linear projections of a previous layer. These parameters are scaled up by a factor of $\sqrt{d_{model}}$ in order to be more similar to activations.
|
| 16 |
+
|
| 17 |
+
In our first experiment, we replaced each position-wise feed-forward network with a multi-head-attention-over-parameters sublayer with $h_p=8$ heads, key-dimensionality $d_{pk}=64$, and value-dimensionality $d_{pv}=64$, using $n_p=1536$ key-value pairs for each attention head. The sublayer has a total of $2097152$ parameters, including the parameters in the query projection and the output projection. This matches the number of parameters in the position-wise feed-forward network that we replaced. While the theoretical amount of computation is also the same, in practice, the attention version caused the step times to be about 30\% longer.
|
| 18 |
+
|
| 19 |
+
In our second experiment, we used $h_p=8$ heads, and $n_p=512$ key-value pairs for each attention head, again matching the total number of parameters in the base model.
|
| 20 |
+
|
| 21 |
+
Results for the first experiment were slightly worse than for the base model, and results for the second experiment were slightly better, see Table~\ref{tab:parameter_attention}.
|
| 22 |
+
|
| 23 |
+
\begin{table}[h]
|
| 24 |
+
\caption{Replacing the position-wise feed-forward networks with multihead-attention-over-parameters produces similar results to the base model. All metrics are on the English-to-German translation development set, newstest2013.}
|
| 25 |
+
\label{tab:parameter_attention}
|
| 26 |
+
\begin{center}
|
| 27 |
+
\vspace{-2mm}
|
| 28 |
+
%\scalebox{1.0}{
|
| 29 |
+
\begin{tabular}{c|cccccc|cccc}
|
| 30 |
+
\hline\rule{0pt}{2.0ex}
|
| 31 |
+
& \multirow{2}{*}{$\dmodel$} & \multirow{2}{*}{$\dff$} &
|
| 32 |
+
\multirow{2}{*}{$h_p$} & \multirow{2}{*}{$d_{pk}$} & \multirow{2}{*}{$d_{pv}$} &
|
| 33 |
+
\multirow{2}{*}{$n_p$} &
|
| 34 |
+
PPL & BLEU & params & training\\
|
| 35 |
+
& & & & & & & (dev) & (dev) & $\times10^6$ & time \\
|
| 36 |
+
\hline\rule{0pt}{2.0ex}
|
| 37 |
+
base & 512 & 2048 & & & & & 4.92 & 25.8 & 65 & 12 hours\\
|
| 38 |
+
\hline\rule{0pt}{2.0ex}
|
| 39 |
+
AOP$_1$ & 512 & & 8 & 64 & 64 & 1536 & 4.92& 25.5 & 65 & 16 hours\\
|
| 40 |
+
AOP$_2$ & 512 & & 16 & 64 & 64 & 512 & \textbf{4.86} & \textbf{25.9} & 65 & 16 hours \\
|
| 41 |
+
\hline
|
| 42 |
+
\end{tabular}
|
| 43 |
+
%}
|
| 44 |
+
\end{center}
|
| 45 |
+
\end{table}
|
download/20230719163556/output/Attention-Is-All-You-Need/results.tex
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
\subsection{Machine Translation}
|
| 2 |
+
\begin{table}[t]
|
| 3 |
+
\begin{center}
|
| 4 |
+
\caption{The Transformer achieves better BLEU scores than previous state-of-the-art models on the English-to-German and English-to-French newstest2014 tests at a fraction of the training cost. }
|
| 5 |
+
\label{tab:wmt-results}
|
| 6 |
+
\vspace{-2mm}
|
| 7 |
+
%\scalebox{1.0}{
|
| 8 |
+
\begin{tabular}{lccccc}
|
| 9 |
+
\toprule
|
| 10 |
+
\multirow{2}{*}{\vspace{-2mm}Model} & \multicolumn{2}{c}{BLEU} & & \multicolumn{2}{c}{Training Cost (FLOPs)} \\
|
| 11 |
+
\cmidrule{2-3} \cmidrule{5-6}
|
| 12 |
+
& EN-DE & EN-FR & & EN-DE & EN-FR \\
|
| 13 |
+
\hline
|
| 14 |
+
ByteNet \citep{NalBytenet2017} & 23.75 & & & &\\
|
| 15 |
+
Deep-Att + PosUnk \citep{DBLP:journals/corr/ZhouCWLX16} & & 39.2 & & & $1.0\cdot10^{20}$ \\
|
| 16 |
+
GNMT + RL \citep{wu2016google} & 24.6 & 39.92 & & $2.3\cdot10^{19}$ & $1.4\cdot10^{20}$\\
|
| 17 |
+
ConvS2S \citep{JonasFaceNet2017} & 25.16 & 40.46 & & $9.6\cdot10^{18}$ & $1.5\cdot10^{20}$\\
|
| 18 |
+
MoE \citep{shazeer2017outrageously} & 26.03 & 40.56 & & $2.0\cdot10^{19}$ & $1.2\cdot10^{20}$ \\
|
| 19 |
+
\hline
|
| 20 |
+
\rule{0pt}{2.0ex}Deep-Att + PosUnk Ensemble \citep{DBLP:journals/corr/ZhouCWLX16} & & 40.4 & & &
|
| 21 |
+
$8.0\cdot10^{20}$ \\
|
| 22 |
+
GNMT + RL Ensemble \citep{wu2016google} & 26.30 & 41.16 & & $1.8\cdot10^{20}$ & $1.1\cdot10^{21}$\\
|
| 23 |
+
ConvS2S Ensemble \citep{JonasFaceNet2017} & 26.36 & \textbf{41.29} & & $7.7\cdot10^{19}$ & $1.2\cdot10^{21}$\\
|
| 24 |
+
\specialrule{1pt}{-1pt}{0pt}
|
| 25 |
+
\rule{0pt}{2.2ex}Transformer (base model) & 27.3 & 38.1 & & \multicolumn{2}{c}{\boldmath$3.3\cdot10^{18}$}\\
|
| 26 |
+
Transformer (big) & \textbf{28.4} & \textbf{41.8} & & \multicolumn{2}{c}{$2.3\cdot10^{19}$} \\
|
| 27 |
+
%\hline
|
| 28 |
+
%\specialrule{1pt}{-1pt}{0pt}
|
| 29 |
+
%\rule{0pt}{2.0ex}
|
| 30 |
+
\bottomrule
|
| 31 |
+
\end{tabular}
|
| 32 |
+
%}
|
| 33 |
+
\end{center}
|
| 34 |
+
\end{table}
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
On the WMT 2014 English-to-German translation task, the big transformer model (Transformer (big) in Table~\ref{tab:wmt-results}) outperforms the best previously reported models (including ensembles) by more than $2.0$ BLEU, establishing a new state-of-the-art BLEU score of $28.4$. The configuration of this model is listed in the bottom line of Table~\ref{tab:variations}. Training took $3.5$ days on $8$ P100 GPUs. Even our base model surpasses all previously published models and ensembles, at a fraction of the training cost of any of the competitive models.
|
| 38 |
+
|
| 39 |
+
On the WMT 2014 English-to-French translation task, our big model achieves a BLEU score of $41.0$, outperforming all of the previously published single models, at less than $1/4$ the training cost of the previous state-of-the-art model. The Transformer (big) model trained for English-to-French used dropout rate $P_{drop}=0.1$, instead of $0.3$.
|
| 40 |
+
|
| 41 |
+
For the base models, we used a single model obtained by averaging the last 5 checkpoints, which were written at 10-minute intervals. For the big models, we averaged the last 20 checkpoints. We used beam search with a beam size of $4$ and length penalty $\alpha=0.6$ \citep{wu2016google}. These hyperparameters were chosen after experimentation on the development set. We set the maximum output length during inference to input length + $50$, but terminate early when possible \citep{wu2016google}.
|
| 42 |
+
|
| 43 |
+
Table \ref{tab:wmt-results} summarizes our results and compares our translation quality and training costs to other model architectures from the literature. We estimate the number of floating point operations used to train a model by multiplying the training time, the number of GPUs used, and an estimate of the sustained single-precision floating-point capacity of each GPU \footnote{We used values of 2.8, 3.7, 6.0 and 9.5 TFLOPS for K80, K40, M40 and P100, respectively.}.
|
| 44 |
+
%where we compare against the leading machine translation results in the literature. Even our smaller model, with number of parameters comparable to ConvS2S, outperforms all existing single models, and achieves results close to the best ensemble model.
|
| 45 |
+
|
| 46 |
+
\subsection{Model Variations}
|
| 47 |
+
|
| 48 |
+
\begin{table}[t]
|
| 49 |
+
\caption{Variations on the Transformer architecture. Unlisted values are identical to those of the base model. All metrics are on the English-to-German translation development set, newstest2013. Listed perplexities are per-wordpiece, according to our byte-pair encoding, and should not be compared to per-word perplexities.}
|
| 50 |
+
\label{tab:variations}
|
| 51 |
+
\begin{center}
|
| 52 |
+
\vspace{-2mm}
|
| 53 |
+
%\scalebox{1.0}{
|
| 54 |
+
\begin{tabular}{c|ccccccccc|ccc}
|
| 55 |
+
\hline\rule{0pt}{2.0ex}
|
| 56 |
+
& \multirow{2}{*}{$N$} & \multirow{2}{*}{$\dmodel$} &
|
| 57 |
+
\multirow{2}{*}{$\dff$} & \multirow{2}{*}{$h$} &
|
| 58 |
+
\multirow{2}{*}{$d_k$} & \multirow{2}{*}{$d_v$} &
|
| 59 |
+
\multirow{2}{*}{$P_{drop}$} & \multirow{2}{*}{$\epsilon_{ls}$} &
|
| 60 |
+
train & PPL & BLEU & params \\
|
| 61 |
+
& & & & & & & & & steps & (dev) & (dev) & $\times10^6$ \\
|
| 62 |
+
% & & & & & & & & & & & & \\
|
| 63 |
+
\hline\rule{0pt}{2.0ex}
|
| 64 |
+
base & 6 & 512 & 2048 & 8 & 64 & 64 & 0.1 & 0.1 & 100K & 4.92 & 25.8 & 65 \\
|
| 65 |
+
\hline\rule{0pt}{2.0ex}
|
| 66 |
+
\multirow{4}{*}{(A)}
|
| 67 |
+
& & & & 1 & 512 & 512 & & & & 5.29 & 24.9 & \\
|
| 68 |
+
& & & & 4 & 128 & 128 & & & & 5.00 & 25.5 & \\
|
| 69 |
+
& & & & 16 & 32 & 32 & & & & 4.91 & 25.8 & \\
|
| 70 |
+
& & & & 32 & 16 & 16 & & & & 5.01 & 25.4 & \\
|
| 71 |
+
\hline\rule{0pt}{2.0ex}
|
| 72 |
+
\multirow{2}{*}{(B)}
|
| 73 |
+
& & & & & 16 & & & & & 5.16 & 25.1 & 58 \\
|
| 74 |
+
& & & & & 32 & & & & & 5.01 & 25.4 & 60 \\
|
| 75 |
+
\hline\rule{0pt}{2.0ex}
|
| 76 |
+
\multirow{7}{*}{(C)}
|
| 77 |
+
& 2 & & & & & & & & & 6.11 & 23.7 & 36 \\
|
| 78 |
+
& 4 & & & & & & & & & 5.19 & 25.3 & 50 \\
|
| 79 |
+
& 8 & & & & & & & & & 4.88 & 25.5 & 80 \\
|
| 80 |
+
& & 256 & & & 32 & 32 & & & & 5.75 & 24.5 & 28 \\
|
| 81 |
+
& & 1024 & & & 128 & 128 & & & & 4.66 & 26.0 & 168 \\
|
| 82 |
+
& & & 1024 & & & & & & & 5.12 & 25.4 & 53 \\
|
| 83 |
+
& & & 4096 & & & & & & & 4.75 & 26.2 & 90 \\
|
| 84 |
+
\hline\rule{0pt}{2.0ex}
|
| 85 |
+
\multirow{4}{*}{(D)}
|
| 86 |
+
& & & & & & & 0.0 & & & 5.77 & 24.6 & \\
|
| 87 |
+
& & & & & & & 0.2 & & & 4.95 & 25.5 & \\
|
| 88 |
+
& & & & & & & & 0.0 & & 4.67 & 25.3 & \\
|
| 89 |
+
& & & & & & & & 0.2 & & 5.47 & 25.7 & \\
|
| 90 |
+
\hline\rule{0pt}{2.0ex}
|
| 91 |
+
(E) & & \multicolumn{7}{c}{positional embedding instead of sinusoids} & & 4.92 & 25.7 & \\
|
| 92 |
+
\hline\rule{0pt}{2.0ex}
|
| 93 |
+
big & 6 & 1024 & 4096 & 16 & & & 0.3 & & 300K & \textbf{4.33} & \textbf{26.4} & 213 \\
|
| 94 |
+
\hline
|
| 95 |
+
\end{tabular}
|
| 96 |
+
%}
|
| 97 |
+
\end{center}
|
| 98 |
+
\end{table}
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
%Table \ref{tab:ende-results}. Our base model for this task uses 6 attention layers, 512 hidden dim, 2048 filter dim, 8 attention heads with both attention and symbol dropout of 0.2 and 0.1 respectively. Increasing the filter size of our feed forward component to 8192 increases the BLEU score on En $\to$ De by $?$. For both the models, we use beam search decoding of size $?$ and length penalty with an alpha of $?$ \cite? \todo{Update results}
|
| 102 |
+
|
| 103 |
+
To evaluate the importance of different components of the Transformer, we varied our base model in different ways, measuring the change in performance on English-to-German translation on the development set, newstest2013. We used beam search as described in the previous section, but no checkpoint averaging. We present these results in Table~\ref{tab:variations}.
|
| 104 |
+
|
| 105 |
+
In Table~\ref{tab:variations} rows (A), we vary the number of attention heads and the attention key and value dimensions, keeping the amount of computation constant, as described in Section \ref{sec:multihead}. While single-head attention is 0.9 BLEU worse than the best setting, quality also drops off with too many heads.
|
| 106 |
+
|
| 107 |
+
In Table~\ref{tab:variations} rows (B), we observe that reducing the attention key size $d_k$ hurts model quality. This suggests that determining compatibility is not easy and that a more sophisticated compatibility function than dot product may be beneficial. We further observe in rows (C) and (D) that, as expected, bigger models are better, and dropout is very helpful in avoiding over-fitting. In row (E) we replace our sinusoidal positional encoding with learned positional embeddings \citep{JonasFaceNet2017}, and observe nearly identical results to the base model.
|
| 108 |
+
|
| 109 |
+
%To evaluate the importance of different components of the Transformer, we use our base model to ablate on a single hyperparameter at each time and measure the change in performance on English$\to$German translation. Our variations in Table~\ref{tab:variations} show that the number of attention layers and attention heads is the most important architecture hyperparamter However, the we do not see performance gains beyond 6 layers, suggesting that we either don't have enough data to train a large model or we need to turn up regularization. We leave this exploration for future work. Among our regularizers, attention dropout has the most significant impact on performance.
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
%Increasing the width of our feed forward component helps both on log ppl and Accuracy \marginpar{Intuition?}
|
| 113 |
+
%Using dropout to regularize our models helps to prevent overfitting
|
| 114 |
+
|
| 115 |
+
\subsection{English Constituency Parsing}
|
| 116 |
+
|
| 117 |
+
\begin{table}[t]
|
| 118 |
+
\begin{center}
|
| 119 |
+
\caption{The Transformer generalizes well to English constituency parsing (Results are on Section 23 of WSJ)}
|
| 120 |
+
\label{tab:parsing-results}
|
| 121 |
+
\vspace{-2mm}
|
| 122 |
+
%\scalebox{1.0}{
|
| 123 |
+
\begin{tabular}{c|c|c}
|
| 124 |
+
\hline
|
| 125 |
+
{\bf Parser} & {\bf Training} & {\bf WSJ 23 F1} \\ \hline
|
| 126 |
+
Vinyals \& Kaiser el al. (2014) \cite{KVparse15}
|
| 127 |
+
& WSJ only, discriminative & 88.3 \\
|
| 128 |
+
Petrov et al. (2006) \cite{petrov-EtAl:2006:ACL}
|
| 129 |
+
& WSJ only, discriminative & 90.4 \\
|
| 130 |
+
Zhu et al. (2013) \cite{zhu-EtAl:2013:ACL}
|
| 131 |
+
& WSJ only, discriminative & 90.4 \\
|
| 132 |
+
Dyer et al. (2016) \cite{dyer-rnng:16}
|
| 133 |
+
& WSJ only, discriminative & 91.7 \\
|
| 134 |
+
\specialrule{1pt}{-1pt}{0pt}
|
| 135 |
+
Transformer (4 layers) & WSJ only, discriminative & 91.3 \\
|
| 136 |
+
\specialrule{1pt}{-1pt}{0pt}
|
| 137 |
+
Zhu et al. (2013) \cite{zhu-EtAl:2013:ACL}
|
| 138 |
+
& semi-supervised & 91.3 \\
|
| 139 |
+
Huang \& Harper (2009) \cite{huang-harper:2009:EMNLP}
|
| 140 |
+
& semi-supervised & 91.3 \\
|
| 141 |
+
McClosky et al. (2006) \cite{mcclosky-etAl:2006:NAACL}
|
| 142 |
+
& semi-supervised & 92.1 \\
|
| 143 |
+
Vinyals \& Kaiser el al. (2014) \cite{KVparse15}
|
| 144 |
+
& semi-supervised & 92.1 \\
|
| 145 |
+
\specialrule{1pt}{-1pt}{0pt}
|
| 146 |
+
Transformer (4 layers) & semi-supervised & 92.7 \\
|
| 147 |
+
\specialrule{1pt}{-1pt}{0pt}
|
| 148 |
+
Luong et al. (2015) \cite{multiseq2seq}
|
| 149 |
+
& multi-task & 93.0 \\
|
| 150 |
+
Dyer et al. (2016) \cite{dyer-rnng:16}
|
| 151 |
+
& generative & 93.3 \\
|
| 152 |
+
\hline
|
| 153 |
+
\end{tabular}
|
| 154 |
+
\end{center}
|
| 155 |
+
\end{table}
|
| 156 |
+
|
| 157 |
+
To evaluate if the Transformer can generalize to other tasks we performed experiments on English constituency parsing. This task presents specific challenges: the output is subject to strong structural constraints and is significantly longer than the input.
|
| 158 |
+
Furthermore, RNN sequence-to-sequence models have not been able to attain state-of-the-art results in small-data regimes \cite{KVparse15}.
|
| 159 |
+
|
| 160 |
+
We trained a 4-layer transformer with $d_{model} = 1024$ on the Wall Street Journal (WSJ) portion of the Penn Treebank \citep{marcus1993building}, about 40K training sentences. We also trained it in a semi-supervised setting, using the larger high-confidence and BerkleyParser corpora from with approximately 17M sentences \citep{KVparse15}. We used a vocabulary of 16K tokens for the WSJ only setting and a vocabulary of 32K tokens for the semi-supervised setting.
|
| 161 |
+
|
| 162 |
+
We performed only a small number of experiments to select the dropout, both attention and residual (section~\ref{sec:reg}), learning rates and beam size on the Section 22 development set, all other parameters remained unchanged from the English-to-German base translation model. During inference, we increased the maximum output length to input length + $300$. We used a beam size of $21$ and $\alpha=0.3$ for both WSJ only and the semi-supervised setting.
|
| 163 |
+
|
| 164 |
+
Our results in Table~\ref{tab:parsing-results} show that despite the lack of task-specific tuning our model performs surprisingly well, yielding better results than all previously reported models with the exception of the Recurrent Neural Network Grammar \cite{dyer-rnng:16}.
|
| 165 |
+
|
| 166 |
+
In contrast to RNN sequence-to-sequence models \citep{KVparse15}, the Transformer outperforms the BerkeleyParser \cite{petrov-EtAl:2006:ACL} even when training only on the WSJ training set of 40K sentences.
|
download/20230719163556/output/Attention-Is-All-You-Need/sqrt_d_trick.tex
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
\section*{Justfication of the Scaling Factor in Dot-product Attention}
|
| 2 |
+
|
| 3 |
+
In Section~\ref{sec:scaled-dot-prod}, we introduced Scaled dot-product attention, where we scale down the dot products by $\sqrt{d_k}$. In this section, we will give a rough justification of this scaling factor. If we assume that $q$ and $k$ are $d_k$-dimensional vectors whose components are independent random variables with mean $0$ and variance $1$, then their dot product, $q \cdot k = \sum_{i=1}^{d_k} u_iv_i$, has mean $0$ and variance $d_k$. Since we would prefer these values to have variance $1$, we divide by $\sqrt{d_k}$.
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
%For any two $d_k$-dimension vectors $\vec{u}$ and $\vec{v}$, whose dimensions are independent, the mean and variance of the dot product will be the summation of the product of means and variances over the dimensions, that is, $E[<\vec{u},\vec{v}>] = \sum_{i=1}^{d_k} E[u_i]E[v_i]$, and $E[(<\vec{u},\vec{v}>-E[<\vec{u},\vec{v}>])^2] = \sum_{i=1}^{d_k} E[({u_i}-E[u_i])^2] E[({v_i}-E[v_i])^2]$. Layer norm encourages the mean and variance of each dimension to be $0$ and $1$ respectively, resultig in the dot product having mean $0$ and $d_k$ respectively. Therefore, scaling by $\sqrt{d_k}$ encourages the logits to be normalized as well.
|
| 8 |
+
|
| 9 |
+
\iffalse
|
| 10 |
+
|
| 11 |
+
In this section, we will give a rough justification of this scaling factor, that is, we will show that for any two vectors, $\vec{u}$ and $\vec{v}$, whose variance and mean are $1$ and $0$ respectively, the variance and the mean of the dot product are $d_k$ and $0$ respectively. Therefore, dividing by $\sqrt{d_k}$ ensures that each component of the attention logits are normalized. The repeated layer norms at each transformer layer encourage $\vec{u}$ and $\vec{v}$ to be normalized.
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
\begin{align*}
|
| 15 |
+
E[<\vec{u},\vec{v}>] & = \sum_k E[u_i v_i] &\text{By linearity of expectation} \\
|
| 16 |
+
& =\sum_k E[u_i]E[v_i] & \text{Assuming independence} \\
|
| 17 |
+
& = 0
|
| 18 |
+
\end{align*}
|
| 19 |
+
|
| 20 |
+
\begin{align*}
|
| 21 |
+
E[(<\vec{u},\vec{v}>-E[<\vec{u},\vec{v}>])^2] & = E[(<\vec{u},\vec{v}>)^2] - E[<\vec{u},\vec{v}>]^2 \\
|
| 22 |
+
& = E[(<\vec{u},\vec{v}>)^2] \\
|
| 23 |
+
& = \sum_k E[{u_i}^2] E[{v_i}^2] &\text{By linearity of expectation and indepedence} \\
|
| 24 |
+
& = d_k
|
| 25 |
+
\end{align*}
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
\fi
|
download/20230719163556/output/Attention-Is-All-You-Need/training.tex
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
This section describes the training regime for our models.
|
| 2 |
+
|
| 3 |
+
%In order to speed up experimentation, our ablations are performed relative to a smaller base model described in detail in Section \ref{sec:results}.
|
| 4 |
+
|
| 5 |
+
\subsection{Training Data and Batching}
|
| 6 |
+
We trained on the standard WMT 2014 English-German dataset consisting of about 4.5 million sentence pairs. Sentences were encoded using byte-pair encoding \citep{DBLP:journals/corr/BritzGLL17}, which has a shared source-target vocabulary of about 37000 tokens. For English-French, we used the significantly larger WMT 2014 English-French dataset consisting of 36M sentences and split tokens into a 32000 word-piece vocabulary \citep{wu2016google}. Sentence pairs were batched together by approximate sequence length. Each training batch contained a set of sentence pairs containing approximately 25000 source tokens and 25000 target tokens.
|
| 7 |
+
|
| 8 |
+
\subsection{Hardware and Schedule}
|
| 9 |
+
|
| 10 |
+
We trained our models on one machine with 8 NVIDIA P100 GPUs. For our base models using the hyperparameters described throughout the paper, each training step took about 0.4 seconds. We trained the base models for a total of 100,000 steps or 12 hours. For our big models,(described on the bottom line of table \ref{tab:variations}), step time was 1.0 seconds. The big models were trained for 300,000 steps (3.5 days).
|
| 11 |
+
|
| 12 |
+
\subsection{Optimizer} We used the Adam optimizer~\citep{kingma2014adam} with $\beta_1=0.9$, $\beta_2=0.98$ and $\epsilon=10^{-9}$. We varied the learning rate over the course of training, according to the formula:
|
| 13 |
+
|
| 14 |
+
\begin{equation}
|
| 15 |
+
lrate = \dmodel^{-0.5} \cdot
|
| 16 |
+
\min({step\_num}^{-0.5},
|
| 17 |
+
{step\_num} \cdot {warmup\_steps}^{-1.5})
|
| 18 |
+
\end{equation}
|
| 19 |
+
|
| 20 |
+
This corresponds to increasing the learning rate linearly for the first $warmup\_steps$ training steps, and decreasing it thereafter proportionally to the inverse square root of the step number. We used $warmup\_steps=4000$.
|
| 21 |
+
|
| 22 |
+
\subsection{Regularization} \label{sec:reg}
|
| 23 |
+
|
| 24 |
+
We employ three types of regularization during training:
|
| 25 |
+
\paragraph{Residual Dropout} We apply dropout \citep{srivastava2014dropout} to the output of each sub-layer, before it is added to the sub-layer input and normalized. In addition, we apply dropout to the sums of the embeddings and the positional encodings in both the encoder and decoder stacks. For the base model, we use a rate of $P_{drop}=0.1$.
|
| 26 |
+
|
| 27 |
+
% \paragraph{Attention Dropout} Query to key attentions are structurally similar to hidden-to-hidden weights in a feed-forward network, albeit across positions. The softmax activations yielding attention weights can then be seen as the analogue of hidden layer activations. A natural possibility is to extend dropout \citep{srivastava2014dropout} to attention. We implement attention dropout by dropping out attention weights as,
|
| 28 |
+
% \begin{equation*}
|
| 29 |
+
% \mathrm{Attention}(Q, K, V) = \mathrm{dropout}(\mathrm{softmax}(\frac{QK^T}{\sqrt{d}}))V
|
| 30 |
+
% \end{equation*}
|
| 31 |
+
% In addition to residual dropout, we found attention dropout to be beneficial for our parsing experiments.
|
| 32 |
+
|
| 33 |
+
%\paragraph{Symbol Dropout} In the source and target embedding layers, we replace a random subset of the token ids with a sentinel id. For the base model, we use a rate of $symbol\_dropout\_rate=0.1$. Note that this applies only to the auto-regressive use of the target ids - not their use in the cross-entropy loss.
|
| 34 |
+
|
| 35 |
+
%\paragraph{Attention Dropout} Query to memory attentions are structurally similar to hidden-to-hidden weights in a feed-forward network, albeit across positions. The softmax activations yielding attention weights can then be seen as the analogue of hidden layer activations. A natural possibility is to extend dropout \citep{srivastava2014dropout} to attentions. We implement attention dropout by dropping out attention weights as,
|
| 36 |
+
%\begin{equation*}
|
| 37 |
+
% A(Q, K, V) = \mathrm{dropout}(\mathrm{softmax}(\frac{QK^T}{\sqrt{d}}))V
|
| 38 |
+
%\end{equation*}
|
| 39 |
+
%As a result, the query will not be able to access the memory values at the dropped out position. In our experiments, we tried attention dropout rates of 0.2, and 0.3, and found it to work favorably for English-to-German translation.
|
| 40 |
+
%$attention\_dropout\_rate=0.2$.
|
| 41 |
+
|
| 42 |
+
\paragraph{Label Smoothing} During training, we employed label smoothing of value $\epsilon_{ls}=0.1$ \citep{DBLP:journals/corr/SzegedyVISW15}. This hurts perplexity, as the model learns to be more unsure, but improves accuracy and BLEU score.
|
download/20230719163556/output/Attention-Is-All-You-Need/vis/anaphora_resolution2_new.pdf
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
download/20230719163556/output/Attention-Is-All-You-Need/vis/anaphora_resolution_new.pdf
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
download/20230719163556/output/Attention-Is-All-You-Need/vis/attending_to_head2_new.pdf
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
download/20230719163556/output/Attention-Is-All-You-Need/vis/attending_to_head_new.pdf
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
download/20230719163556/output/Attention-Is-All-You-Need/vis/making_more_difficult5_new.pdf
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
download/20230719163556/output/Attention-Is-All-You-Need/vis/making_more_difficult_new.pdf
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
download/20230719163556/output/Attention-Is-All-You-Need/visualizations.tex
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
\pagebreak
|
| 2 |
+
\section*{Attention Visualizations}\label{sec:viz-att}
|
| 3 |
+
\begin{figure*}[h]
|
| 4 |
+
{\includegraphics[width=\textwidth, trim=0 0 0 36, clip]{./vis/making_more_difficult5_new.pdf}}
|
| 5 |
+
\caption{An example of the attention mechanism following long-distance dependencies in the encoder self-attention in layer 5 of 6. Many of the attention heads attend to a distant dependency of the verb `making', completing the phrase `making...more difficult'. Attentions here shown only for the word `making'. Different colors represent different heads. Best viewed in color.}
|
| 6 |
+
\end{figure*}
|
| 7 |
+
|
| 8 |
+
\begin{figure*}
|
| 9 |
+
{\includegraphics[width=\textwidth, trim=0 0 0 45, clip]{./vis/anaphora_resolution_new.pdf}}
|
| 10 |
+
{\includegraphics[width=\textwidth, trim=0 0 0 37, clip]{./vis/anaphora_resolution2_new.pdf}}
|
| 11 |
+
\caption{Two attention heads, also in layer 5 of 6, apparently involved in anaphora resolution. Top: Full attentions for head 5. Bottom: Isolated attentions from just the word `its' for attention heads 5 and 6. Note that the attentions are very sharp for this word.}
|
| 12 |
+
\end{figure*}
|
| 13 |
+
|
| 14 |
+
\begin{figure*}
|
| 15 |
+
{\includegraphics[width=\textwidth, trim=0 0 0 36, clip]{./vis/attending_to_head_new.pdf}}
|
| 16 |
+
{\includegraphics[width=\textwidth, trim=0 0 0 36, clip]{./vis/attending_to_head2_new.pdf}}
|
| 17 |
+
\caption{Many of the attention heads exhibit behaviour that seems related to the structure of the sentence. We give two such examples above, from two different heads from the encoder self-attention at layer 5 of 6. The heads clearly learned to perform different tasks.}
|
| 18 |
+
\end{figure*}
|
download/20230719163556/output/Attention-Is-All-You-Need/why_self_attention.tex
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
%We focus on the general task of mapping one variable-length sequence of symbol representations ${x_1, ..., x_n} \in \mathbb{R}^d$ to another sequence of the same length ${y_1, ..., y_n} \in \mathbb{R}^d$. \marginpar{should we use this notation? alternatively we can just say "d-dimensional vectors"}
|
| 2 |
+
|
| 3 |
+
In this section we compare various aspects of self-attention layers to the recurrent and convolutional layers commonly used for mapping one variable-length sequence of symbol representations $(x_1, ..., x_n)$ to another sequence of equal length $(z_1, ..., z_n)$, with $x_i, z_i \in \mathbb{R}^d$, such as a hidden layer in a typical sequence transduction encoder or decoder. Motivating our use of self-attention we consider three desiderata.
|
| 4 |
+
|
| 5 |
+
One is the total computational complexity per layer.
|
| 6 |
+
Another is the amount of computation that can be parallelized, as measured by the minimum number of sequential operations required.
|
| 7 |
+
|
| 8 |
+
The third is the path length between long-range dependencies in the network. Learning long-range dependencies is a key challenge in many sequence transduction tasks. One key factor affecting the ability to learn such dependencies is the length of the paths forward and backward signals have to traverse in the network. The shorter these paths between any combination of positions in the input and output sequences, the easier it is to learn long-range dependencies \citep{hochreiter2001gradient}. Hence we also compare the maximum path length between any two input and output positions in networks composed of the different layer types.
|
| 9 |
+
|
| 10 |
+
%\subsection{Computational Performance and Path Lengths}
|
| 11 |
+
|
| 12 |
+
\begin{table}[t]
|
| 13 |
+
\caption{
|
| 14 |
+
Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types. $n$ is the sequence length, $d$ is the representation dimension, $k$ is the kernel size of convolutions and $r$ the size of the neighborhood in restricted self-attention.}
|
| 15 |
+
%Attention models are quite efficient for cross-positional communications when sequence length is smaller than channel depth.
|
| 16 |
+
\label{tab:op_complexities}
|
| 17 |
+
\begin{center}
|
| 18 |
+
\vspace{-1mm}
|
| 19 |
+
%\scalebox{0.75}{
|
| 20 |
+
|
| 21 |
+
\begin{tabular}{lccc}
|
| 22 |
+
\toprule
|
| 23 |
+
Layer Type & Complexity per Layer & Sequential & Maximum Path Length \\
|
| 24 |
+
& & Operations & \\
|
| 25 |
+
\hline
|
| 26 |
+
\rule{0pt}{2.0ex}Self-Attention & $O(n^2 \cdot d)$ & $O(1)$ & $O(1)$ \\
|
| 27 |
+
Recurrent & $O(n \cdot d^2)$ & $O(n)$ & $O(n)$ \\
|
| 28 |
+
|
| 29 |
+
Convolutional & $O(k \cdot n \cdot d^2)$ & $O(1)$ & $O(log_k(n))$ \\
|
| 30 |
+
%\cmidrule
|
| 31 |
+
Self-Attention (restricted)& $O(r \cdot n \cdot d)$ & $O(1)$ & $O(n/r)$ \\
|
| 32 |
+
|
| 33 |
+
%Convolutional (separable) & $O(k \cdot n \cdot d + n \cdot d^2)$ & $O(1)$ & $O(log_k(n))$ \\
|
| 34 |
+
|
| 35 |
+
%Position-wise Feed-Forward & $O(n \cdot d^2)$ & $O(1)$ & $\infty$ \\
|
| 36 |
+
|
| 37 |
+
%Fully Connected & $O(n^2 \cdot d^2)$ & $O(1)$ & $O(1)$ \\
|
| 38 |
+
%Convolutional (separable) & $O(k \cdot n \cdot d + n \cdot d^2)$ & $O(1)$ & $O(log_k(n))$ \\
|
| 39 |
+
|
| 40 |
+
%Position-wise Feed-Forward & $O(n \cdot d^2)$ & $O(1)$ & $\infty$ \\
|
| 41 |
+
|
| 42 |
+
%Fully Connected & $O(n^2 \cdot d^2)$ & $O(1)$ & $O(1)$ \\
|
| 43 |
+
\bottomrule
|
| 44 |
+
\end{tabular}
|
| 45 |
+
%}
|
| 46 |
+
\end{center}
|
| 47 |
+
\end{table}
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
%\begin{table}[b]
|
| 51 |
+
%\caption{
|
| 52 |
+
% Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types. $n$ is the sequence length, $d$ is the representation dimensionality, $k$ is the kernel size of convolutions and $r$ the size of the neighborhood in localized self-attention.}
|
| 53 |
+
%Attention models are quite efficient for cross-positional communications when sequence length is smaller than channel depth.
|
| 54 |
+
%\label{tab:op_complexities}
|
| 55 |
+
%\begin{center}
|
| 56 |
+
%\vspace{-1mm}
|
| 57 |
+
%%\scalebox{0.75}{
|
| 58 |
+
%
|
| 59 |
+
%\begin{tabular}{lccc}
|
| 60 |
+
%\hline
|
| 61 |
+
%Layer Type & Receptive & Complexity per Layer & Sequential %\\
|
| 62 |
+
% & Field Size & & Operations \\
|
| 63 |
+
%\hline
|
| 64 |
+
%Self-Attention & $n$ & $O(n^2 \cdot d)$ & $O(1)$ \\
|
| 65 |
+
%Recurrent & $n$ & $O(n \cdot d^2)$ & $O(n)$ \\
|
| 66 |
+
|
| 67 |
+
%Convolutional & $k$ & $O(k \cdot n \cdot d^2)$ & %$O(log_k(n))$ \\
|
| 68 |
+
%\hline
|
| 69 |
+
%Self-Attention (localized)& $r$ & $O(r \cdot n \cdot d)$ & %$O(1)$ \\
|
| 70 |
+
|
| 71 |
+
%Convolutional (separable) & $k$ & $O(k \cdot n \cdot d + n %\cdot d^2)$ & $O(log_k(n))$ \\
|
| 72 |
+
|
| 73 |
+
%Position-wise Feed-Forward & $1$ & $O(n \cdot d^2)$ & $O(1)$ %\\
|
| 74 |
+
|
| 75 |
+
%Fully Connected & $n$ & $O(n^2 \cdot d^2)$ & $O(1)$ \\
|
| 76 |
+
|
| 77 |
+
%\end{tabular}
|
| 78 |
+
%%}
|
| 79 |
+
%\end{center}
|
| 80 |
+
%\end{table}
|
| 81 |
+
|
| 82 |
+
%The receptive field size of a layer is the number of different input representations that can influence any particular output representation. Recurrent layers and self-attention layers have a full receptive field equal to the sequence length $n$. Convolutional layers have a limited receptive field equal to their kernel width $k$, which is generally chosen to be small in order to limit computational cost.
|
| 83 |
+
|
| 84 |
+
As noted in Table \ref{tab:op_complexities}, a self-attention layer connects all positions with a constant number of sequentially executed operations, whereas a recurrent layer requires $O(n)$ sequential operations.
|
| 85 |
+
In terms of computational complexity, self-attention layers are faster than recurrent layers when the sequence length $n$ is smaller than the representation dimensionality $d$, which is most often the case with sentence representations used by state-of-the-art models in machine translations, such as word-piece \citep{wu2016google} and byte-pair \citep{sennrich2015neural} representations.
|
| 86 |
+
To improve computational performance for tasks involving very long sequences, self-attention could be restricted to considering only a neighborhood of size $r$ in the input sequence centered around the respective output position. This would increase the maximum path length to $O(n/r)$. We plan to investigate this approach further in future work.
|
| 87 |
+
|
| 88 |
+
A single convolutional layer with kernel width $k < n$ does not connect all pairs of input and output positions. Doing so requires a stack of $O(n/k)$ convolutional layers in the case of contiguous kernels, or $O(log_k(n))$ in the case of dilated convolutions \citep{NalBytenet2017}, increasing the length of the longest paths between any two positions in the network.
|
| 89 |
+
Convolutional layers are generally more expensive than recurrent layers, by a factor of $k$. Separable convolutions \citep{xception2016}, however, decrease the complexity considerably, to $O(k \cdot n \cdot d + n \cdot d^2)$. Even with $k=n$, however, the complexity of a separable convolution is equal to the combination of a self-attention layer and a point-wise feed-forward layer, the approach we take in our model.
|
| 90 |
+
|
| 91 |
+
%\subsection{Unfiltered Bottleneck Argument}
|
| 92 |
+
|
| 93 |
+
%An orthogonal argument can be made for self-attention layers based on when the layer imposes the bottleneck of mapping all of the information used to compute a given output position into a single, fixed-length vector. ...
|
| 94 |
+
|
| 95 |
+
%There is a second argument for self-attention layers which we call the unfiltered bottleneck argument. In both recurrent and the convolutional layers, the information that position $i$ receives from the other positions is compressed to a vector of dimension $d$ before it ever can be filtered by the content $x_i$. More precisely, we can express $y_i = F(i, x_i, G(i, \{x_{j \neq i}\}))$, where $G(i, \{x_{j \neq i}\})$ is a vector of dimension $d$. Intuitively, we would expect that this would cause a large amount of irrelevant information to crowd out the relevant information. Self-attention does not suffer from the unfiltered bottleneck problem, since the aggregation happens after filtering, and so, intuitively, we have the chance of transmitting lots of relevant information.
|
| 96 |
+
|
| 97 |
+
As side benefit, self-attention could yield more interpretable models. We inspect attention distributions from our models and present and discuss examples in the appendix. Not only do individual attention heads clearly learn to perform different tasks, many appear to exhibit behavior related to the syntactic and semantic structure of the sentences.
|
| 98 |
+
|
download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/cvpr.sty
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
% ---------------------------------------------------------------
|
| 2 |
+
%
|
| 3 |
+
% $Id: cvpr.sty,v 1.3 2005/10/24 19:56:15 awf Exp $
|
| 4 |
+
%
|
| 5 |
+
% by [email protected]
|
| 6 |
+
% some mods by [email protected]
|
| 7 |
+
%
|
| 8 |
+
% ---------------------------------------------------------------
|
| 9 |
+
%
|
| 10 |
+
% no guarantee is given that the format corresponds perfectly to
|
| 11 |
+
% IEEE 8.5" x 11" Proceedings, but most features should be ok.
|
| 12 |
+
%
|
| 13 |
+
% ---------------------------------------------------------------
|
| 14 |
+
% with LaTeX2e:
|
| 15 |
+
% =============
|
| 16 |
+
%
|
| 17 |
+
% use as
|
| 18 |
+
% \documentclass[times,10pt,twocolumn]{article}
|
| 19 |
+
% \usepackage{latex8}
|
| 20 |
+
% \usepackage{times}
|
| 21 |
+
%
|
| 22 |
+
% ---------------------------------------------------------------
|
| 23 |
+
|
| 24 |
+
% with LaTeX 2.09:
|
| 25 |
+
% ================
|
| 26 |
+
%
|
| 27 |
+
% use as
|
| 28 |
+
% \documentstyle[times,art10,twocolumn,latex8]{article}
|
| 29 |
+
%
|
| 30 |
+
% ---------------------------------------------------------------
|
| 31 |
+
% with both versions:
|
| 32 |
+
% ===================
|
| 33 |
+
%
|
| 34 |
+
% specify \cvprfinalcopy to emit the final camera-ready copy
|
| 35 |
+
%
|
| 36 |
+
% specify references as
|
| 37 |
+
% \bibliographystyle{ieee}
|
| 38 |
+
% \bibliography{...your files...}
|
| 39 |
+
%
|
| 40 |
+
% ---------------------------------------------------------------
|
| 41 |
+
|
| 42 |
+
\usepackage{eso-pic}
|
| 43 |
+
\usepackage{xspace}
|
| 44 |
+
|
| 45 |
+
\typeout{CVPR 8.5 x 11-Inch Proceedings Style `cvpr.sty'.}
|
| 46 |
+
|
| 47 |
+
% ten point helvetica bold required for captions
|
| 48 |
+
% eleven point times bold required for second-order headings
|
| 49 |
+
% in some sites the name of the fonts may differ,
|
| 50 |
+
% change the name here:
|
| 51 |
+
\font\cvprtenhv = phvb at 8pt % *** IF THIS FAILS, SEE cvpr.sty ***
|
| 52 |
+
\font\elvbf = ptmb scaled 1100
|
| 53 |
+
|
| 54 |
+
% If the above lines give an error message, try to comment them and
|
| 55 |
+
% uncomment these:
|
| 56 |
+
%\font\cvprtenhv = phvb7t at 8pt
|
| 57 |
+
%\font\elvbf = ptmb7t scaled 1100
|
| 58 |
+
|
| 59 |
+
% set dimensions of columns, gap between columns, and paragraph indent
|
| 60 |
+
\setlength{\textheight}{8.875in}
|
| 61 |
+
\setlength{\textwidth}{6.875in}
|
| 62 |
+
\setlength{\columnsep}{0.3125in}
|
| 63 |
+
\setlength{\topmargin}{0in}
|
| 64 |
+
\setlength{\headheight}{0in}
|
| 65 |
+
\setlength{\headsep}{0in}
|
| 66 |
+
\setlength{\parindent}{1pc}
|
| 67 |
+
\setlength{\oddsidemargin}{-.304in}
|
| 68 |
+
\setlength{\evensidemargin}{-.304in}
|
| 69 |
+
|
| 70 |
+
\newif\ifcvprfinal
|
| 71 |
+
\cvprfinalfalse
|
| 72 |
+
\def\cvprfinalcopy{\global\cvprfinaltrue}
|
| 73 |
+
|
| 74 |
+
% memento from size10.clo
|
| 75 |
+
% \normalsize{\@setfontsize\normalsize\@xpt\@xiipt}
|
| 76 |
+
% \small{\@setfontsize\small\@ixpt{11}}
|
| 77 |
+
% \footnotesize{\@setfontsize\footnotesize\@viiipt{9.5}}
|
| 78 |
+
% \scriptsize{\@setfontsize\scriptsize\@viipt\@viiipt}
|
| 79 |
+
% \tiny{\@setfontsize\tiny\@vpt\@vipt}
|
| 80 |
+
% \large{\@setfontsize\large\@xiipt{14}}
|
| 81 |
+
% \Large{\@setfontsize\Large\@xivpt{18}}
|
| 82 |
+
% \LARGE{\@setfontsize\LARGE\@xviipt{22}}
|
| 83 |
+
% \huge{\@setfontsize\huge\@xxpt{25}}
|
| 84 |
+
% \Huge{\@setfontsize\Huge\@xxvpt{30}}
|
| 85 |
+
|
| 86 |
+
\def\@maketitle
|
| 87 |
+
{
|
| 88 |
+
\newpage
|
| 89 |
+
\null
|
| 90 |
+
\vskip .375in
|
| 91 |
+
\begin{center}
|
| 92 |
+
{\Large \bf \@title \par}
|
| 93 |
+
% additional two empty lines at the end of the title
|
| 94 |
+
\vspace*{24pt}
|
| 95 |
+
{
|
| 96 |
+
\large
|
| 97 |
+
\lineskip .5em
|
| 98 |
+
\begin{tabular}[t]{c}
|
| 99 |
+
\ifcvprfinal\@author\else Anonymous CVPR submission\\
|
| 100 |
+
\vspace*{1pt}\\%This space will need to be here in the final copy, so don't squeeze it out for the review copy.
|
| 101 |
+
Paper ID \cvprPaperID \fi
|
| 102 |
+
\end{tabular}
|
| 103 |
+
\par
|
| 104 |
+
}
|
| 105 |
+
% additional small space at the end of the author name
|
| 106 |
+
\vskip .5em
|
| 107 |
+
% additional empty line at the end of the title block
|
| 108 |
+
\vspace*{12pt}
|
| 109 |
+
\end{center}
|
| 110 |
+
}
|
| 111 |
+
|
| 112 |
+
\def\abstract
|
| 113 |
+
{%
|
| 114 |
+
\centerline{\large\bf Abstract}%
|
| 115 |
+
\vspace*{12pt}%
|
| 116 |
+
\it%
|
| 117 |
+
}
|
| 118 |
+
|
| 119 |
+
\def\endabstract
|
| 120 |
+
{
|
| 121 |
+
% additional empty line at the end of the abstract
|
| 122 |
+
\vspace*{12pt}
|
| 123 |
+
}
|
| 124 |
+
|
| 125 |
+
\def\affiliation#1{\gdef\@affiliation{#1}} \gdef\@affiliation{}
|
| 126 |
+
|
| 127 |
+
\newlength{\@ctmp}
|
| 128 |
+
\newlength{\@figindent}
|
| 129 |
+
\setlength{\@figindent}{1pc}
|
| 130 |
+
|
| 131 |
+
\long\def\@makecaption#1#2{
|
| 132 |
+
\setbox\@tempboxa\hbox{\small \noindent #1.~#2}
|
| 133 |
+
\setlength{\@ctmp}{\hsize}
|
| 134 |
+
\addtolength{\@ctmp}{-\@figindent}\addtolength{\@ctmp}{-\@figindent}
|
| 135 |
+
% IF longer than one indented paragraph line
|
| 136 |
+
\ifdim \wd\@tempboxa >\@ctmp
|
| 137 |
+
% THEN DON'T set as an indented paragraph
|
| 138 |
+
{\small #1.~#2\par}
|
| 139 |
+
\else
|
| 140 |
+
% ELSE center
|
| 141 |
+
\hbox to\hsize{\hfil\box\@tempboxa\hfil}
|
| 142 |
+
\fi}
|
| 143 |
+
|
| 144 |
+
% correct heading spacing and type
|
| 145 |
+
\def\cvprsection{\@startsection {section}{1}{\z@}
|
| 146 |
+
{10pt plus 2pt minus 2pt}{7pt} {\large\bf}}
|
| 147 |
+
\def\cvprssect#1{\cvprsection*{#1}}
|
| 148 |
+
\def\cvprsect#1{\cvprsection{\hskip -1em.~#1}}
|
| 149 |
+
\def\section{\@ifstar\cvprssect\cvprsect}
|
| 150 |
+
|
| 151 |
+
\def\cvprsubsection{\@startsection {subsection}{2}{\z@}
|
| 152 |
+
{8pt plus 2pt minus 2pt}{6pt} {\elvbf}}
|
| 153 |
+
\def\cvprssubsect#1{\cvprsubsection*{#1}}
|
| 154 |
+
\def\cvprsubsect#1{\cvprsubsection{\hskip -1em.~#1}}
|
| 155 |
+
\def\subsection{\@ifstar\cvprssubsect\cvprsubsect}
|
| 156 |
+
|
| 157 |
+
%% --------- Page background marks: Ruler and confidentiality
|
| 158 |
+
|
| 159 |
+
% ----- define vruler
|
| 160 |
+
\makeatletter
|
| 161 |
+
\newbox\cvprrulerbox
|
| 162 |
+
\newcount\cvprrulercount
|
| 163 |
+
\newdimen\cvprruleroffset
|
| 164 |
+
\newdimen\cv@lineheight
|
| 165 |
+
\newdimen\cv@boxheight
|
| 166 |
+
\newbox\cv@tmpbox
|
| 167 |
+
\newcount\cv@refno
|
| 168 |
+
\newcount\cv@tot
|
| 169 |
+
% NUMBER with left flushed zeros \fillzeros[<WIDTH>]<NUMBER>
|
| 170 |
+
\newcount\cv@tmpc@ \newcount\cv@tmpc
|
| 171 |
+
\def\fillzeros[#1]#2{\cv@tmpc@=#2\relax\ifnum\cv@tmpc@<0\cv@tmpc@=-\cv@tmpc@\fi
|
| 172 |
+
\cv@tmpc=1 %
|
| 173 |
+
\loop\ifnum\cv@tmpc@<10 \else \divide\cv@tmpc@ by 10 \advance\cv@tmpc by 1 \fi
|
| 174 |
+
\ifnum\cv@tmpc@=10\relax\cv@tmpc@=11\relax\fi \ifnum\cv@tmpc@>10 \repeat
|
| 175 |
+
\ifnum#2<0\advance\cv@tmpc1\relax-\fi
|
| 176 |
+
\loop\ifnum\cv@tmpc<#1\relax0\advance\cv@tmpc1\relax\fi \ifnum\cv@tmpc<#1 \repeat
|
| 177 |
+
\cv@tmpc@=#2\relax\ifnum\cv@tmpc@<0\cv@tmpc@=-\cv@tmpc@\fi \relax\the\cv@tmpc@}%
|
| 178 |
+
% \makevruler[<SCALE>][<INITIAL_COUNT>][<STEP>][<DIGITS>][<HEIGHT>]
|
| 179 |
+
\def\makevruler[#1][#2][#3][#4][#5]{\begingroup\offinterlineskip
|
| 180 |
+
\textheight=#5\vbadness=10000\vfuzz=120ex\overfullrule=0pt%
|
| 181 |
+
\global\setbox\cvprrulerbox=\vbox to \textheight{%
|
| 182 |
+
{\parskip=0pt\hfuzz=150em\cv@boxheight=\textheight
|
| 183 |
+
\cv@lineheight=#1\global\cvprrulercount=#2%
|
| 184 |
+
\cv@tot\cv@boxheight\divide\cv@tot\cv@lineheight\advance\cv@tot2%
|
| 185 |
+
\cv@refno1\vskip-\cv@lineheight\vskip1ex%
|
| 186 |
+
\loop\setbox\cv@tmpbox=\hbox to0cm{{\cvprtenhv\hfil\fillzeros[#4]\cvprrulercount}}%
|
| 187 |
+
\ht\cv@tmpbox\cv@lineheight\dp\cv@tmpbox0pt\box\cv@tmpbox\break
|
| 188 |
+
\advance\cv@refno1\global\advance\cvprrulercount#3\relax
|
| 189 |
+
\ifnum\cv@refno<\cv@tot\repeat}}\endgroup}%
|
| 190 |
+
\makeatother
|
| 191 |
+
% ----- end of vruler
|
| 192 |
+
|
| 193 |
+
% \makevruler[<SCALE>][<INITIAL_COUNT>][<STEP>][<DIGITS>][<HEIGHT>]
|
| 194 |
+
\def\cvprruler#1{\makevruler[12pt][#1][1][3][0.993\textheight]\usebox{\cvprrulerbox}}
|
| 195 |
+
\AddToShipoutPicture{%
|
| 196 |
+
\ifcvprfinal\else
|
| 197 |
+
%\AtTextLowerLeft{%
|
| 198 |
+
% \color[gray]{.15}\framebox(\LenToUnit{\textwidth},\LenToUnit{\textheight}){}
|
| 199 |
+
%}
|
| 200 |
+
\cvprruleroffset=\textheight
|
| 201 |
+
\advance\cvprruleroffset by -3.7pt
|
| 202 |
+
\color[rgb]{.5,.5,1}
|
| 203 |
+
\AtTextUpperLeft{%
|
| 204 |
+
\put(\LenToUnit{-35pt},\LenToUnit{-\cvprruleroffset}){%left ruler
|
| 205 |
+
\cvprruler{\cvprrulercount}}
|
| 206 |
+
\put(\LenToUnit{\textwidth\kern 30pt},\LenToUnit{-\cvprruleroffset}){%right ruler
|
| 207 |
+
\cvprruler{\cvprrulercount}}
|
| 208 |
+
}
|
| 209 |
+
\def\pid{\parbox{1in}{\begin{center}\bf\sf{\small CVPR}\\\#\cvprPaperID\end{center}}}
|
| 210 |
+
\AtTextUpperLeft{%paperID in corners
|
| 211 |
+
\put(\LenToUnit{-65pt},\LenToUnit{45pt}){\pid}
|
| 212 |
+
\put(\LenToUnit{\textwidth\kern-8pt},\LenToUnit{45pt}){\pid}
|
| 213 |
+
}
|
| 214 |
+
\AtTextUpperLeft{%confidential
|
| 215 |
+
\put(0,\LenToUnit{1cm}){\parbox{\textwidth}{\centering\cvprtenhv
|
| 216 |
+
CVPR 2016 Submission \#\cvprPaperID. CONFIDENTIAL REVIEW COPY. DO NOT DISTRIBUTE.}}
|
| 217 |
+
}
|
| 218 |
+
\fi
|
| 219 |
+
}
|
| 220 |
+
|
| 221 |
+
%%% Make figure placement a little more predictable.
|
| 222 |
+
% We trust the user to move figures if this results
|
| 223 |
+
% in ugliness.
|
| 224 |
+
% Minimize bad page breaks at figures
|
| 225 |
+
\renewcommand{\textfraction}{0.01}
|
| 226 |
+
\renewcommand{\floatpagefraction}{0.99}
|
| 227 |
+
\renewcommand{\topfraction}{0.99}
|
| 228 |
+
\renewcommand{\bottomfraction}{0.99}
|
| 229 |
+
\renewcommand{\dblfloatpagefraction}{0.99}
|
| 230 |
+
\renewcommand{\dbltopfraction}{0.99}
|
| 231 |
+
\setcounter{totalnumber}{99}
|
| 232 |
+
\setcounter{topnumber}{99}
|
| 233 |
+
\setcounter{bottomnumber}{99}
|
| 234 |
+
|
| 235 |
+
% Add a period to the end of an abbreviation unless there's one
|
| 236 |
+
% already, then \xspace.
|
| 237 |
+
\makeatletter
|
| 238 |
+
\DeclareRobustCommand\onedot{\futurelet\@let@token\@onedot}
|
| 239 |
+
\def\@onedot{\ifx\@let@token.\else.\null\fi\xspace}
|
| 240 |
+
|
| 241 |
+
\def\eg{\emph{e.g}\onedot} \def\Eg{\emph{E.g}\onedot}
|
| 242 |
+
\def\ie{\emph{i.e}\onedot} \def\Ie{\emph{I.e}\onedot}
|
| 243 |
+
\def\cf{\emph{c.f}\onedot} \def\Cf{\emph{C.f}\onedot}
|
| 244 |
+
\def\etc{\emph{etc}\onedot} \def\vs{\emph{vs}\onedot}
|
| 245 |
+
\def\wrt{w.r.t\onedot} \def\dof{d.o.f\onedot}
|
| 246 |
+
\def\etal{\emph{et al}\onedot}
|
| 247 |
+
\makeatother
|
| 248 |
+
|
| 249 |
+
% ---------------------------------------------------------------
|
download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/cvpr_eso.sty
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
%%
|
| 2 |
+
%% This is file `everyshi.sty',
|
| 3 |
+
%% generated with the docstrip utility.
|
| 4 |
+
%%
|
| 5 |
+
%% The original source files were:
|
| 6 |
+
%%
|
| 7 |
+
%% everyshi.dtx (with options: `package')
|
| 8 |
+
%%
|
| 9 |
+
%% Copyright (C) [1994..1999] by Martin Schroeder. All rights reserved.
|
| 10 |
+
%%
|
| 11 |
+
%% This file is part of the EveryShi package
|
| 12 |
+
%%
|
| 13 |
+
%% This program may be redistributed and/or modified under the terms
|
| 14 |
+
%% of the LaTeX Project Public License, either version 1.0 of this
|
| 15 |
+
%% license, or (at your option) any later version.
|
| 16 |
+
%% The latest version of this license is in
|
| 17 |
+
%% CTAN:macros/latex/base/lppl.txt.
|
| 18 |
+
%%
|
| 19 |
+
%% Happy users are requested to send me a postcard. :-)
|
| 20 |
+
%%
|
| 21 |
+
%% The EveryShi package contains these files:
|
| 22 |
+
%%
|
| 23 |
+
%% everyshi.asc
|
| 24 |
+
%% everyshi.dtx
|
| 25 |
+
%% everyshi.dvi
|
| 26 |
+
%% everyshi.ins
|
| 27 |
+
%% everyshi.bug
|
| 28 |
+
%%
|
| 29 |
+
%% Error Reports in case of UNCHANGED versions to
|
| 30 |
+
%%
|
| 31 |
+
%% Martin Schr"oder
|
| 32 |
+
%% Cr"usemannallee 3
|
| 33 |
+
%% D-28213 Bremen
|
| 34 |
+
%% [email protected]
|
| 35 |
+
%%
|
| 36 |
+
%% File: everyshi.dtx Copyright (C) 2001 Martin Schr\"oder
|
| 37 |
+
\NeedsTeXFormat{LaTeX2e}
|
| 38 |
+
\ProvidesPackage{everyshi}
|
| 39 |
+
[2001/05/15 v3.00 EveryShipout Package (MS)]
|
| 40 |
+
%% \CharacterTable
|
| 41 |
+
%% {Upper-case \A\B\C\D\E\F\G\H\I\J\K\L\M\N\O\P\Q\R\S\T\U\V\W\X\Y\Z
|
| 42 |
+
%% Lower-case \a\b\c\d\e\f\g\h\i\j\k\l\m\n\o\p\q\r\s\t\u\v\w\x\y\z
|
| 43 |
+
%% Digits \0\1\2\3\4\5\6\7\8\9
|
| 44 |
+
%% Exclamation \! Double quote \" Hash (number) \#
|
| 45 |
+
%% Dollar \$ Percent \% Ampersand \&
|
| 46 |
+
%% Acute accent \' Left paren \( Right paren \)
|
| 47 |
+
%% Asterisk \* Plus \+ Comma \,
|
| 48 |
+
%% Minus \- Point \. Solidus \/
|
| 49 |
+
%% Colon \: Semicolon \; Less than \<
|
| 50 |
+
%% Equals \= Greater than \> Question mark \?
|
| 51 |
+
%% Commercial at \@ Left bracket \[ Backslash \\
|
| 52 |
+
%% Right bracket \] Circumflex \^ Underscore \_
|
| 53 |
+
%% Grave accent \` Left brace \{ Vertical bar \|
|
| 54 |
+
%% Right brace \} Tilde \~}
|
| 55 |
+
%%
|
| 56 |
+
%% \iffalse meta-comment
|
| 57 |
+
%% ===================================================================
|
| 58 |
+
%% @LaTeX-package-file{
|
| 59 |
+
%% author = {Martin Schr\"oder},
|
| 60 |
+
%% version = "3.00",
|
| 61 |
+
%% date = "15 May 2001",
|
| 62 |
+
%% filename = "everyshi.sty",
|
| 63 |
+
%% address = {Martin Schr\"oder
|
| 64 |
+
%% Cr\"usemannallee 3
|
| 65 |
+
%% 28213 Bremen
|
| 66 |
+
%% Germany},
|
| 67 |
+
%% telephone = "+49-421-2239425",
|
| 68 |
+
%% email = "[email protected]",
|
| 69 |
+
%% pgp-Key = "2048 bit / KeyID 292814E5",
|
| 70 |
+
%% pgp-fingerprint = "7E86 6EC8 97FA 2995 82C3 FEA5 2719 090E",
|
| 71 |
+
%% docstring = "LaTeX package which provides hooks into
|
| 72 |
+
%% \cs{shipout}.
|
| 73 |
+
%% }
|
| 74 |
+
%% ===================================================================
|
| 75 |
+
%% \fi
|
| 76 |
+
|
| 77 |
+
\newcommand{\@EveryShipout@Hook}{}
|
| 78 |
+
\newcommand{\@EveryShipout@AtNextHook}{}
|
| 79 |
+
\newcommand*{\EveryShipout}[1]
|
| 80 |
+
{\g@addto@macro\@EveryShipout@Hook{#1}}
|
| 81 |
+
\newcommand*{\AtNextShipout}[1]
|
| 82 |
+
{\g@addto@macro\@EveryShipout@AtNextHook{#1}}
|
| 83 |
+
\newcommand{\@EveryShipout@Shipout}{%
|
| 84 |
+
\afterassignment\@EveryShipout@Test
|
| 85 |
+
\global\setbox\@cclv= %
|
| 86 |
+
}
|
| 87 |
+
\newcommand{\@EveryShipout@Test}{%
|
| 88 |
+
\ifvoid\@cclv\relax
|
| 89 |
+
\aftergroup\@EveryShipout@Output
|
| 90 |
+
\else
|
| 91 |
+
\@EveryShipout@Output
|
| 92 |
+
\fi%
|
| 93 |
+
}
|
| 94 |
+
\newcommand{\@EveryShipout@Output}{%
|
| 95 |
+
\@EveryShipout@Hook%
|
| 96 |
+
\@EveryShipout@AtNextHook%
|
| 97 |
+
\gdef\@EveryShipout@AtNextHook{}%
|
| 98 |
+
\@EveryShipout@Org@Shipout\box\@cclv%
|
| 99 |
+
}
|
| 100 |
+
\newcommand{\@EveryShipout@Org@Shipout}{}
|
| 101 |
+
\newcommand*{\@EveryShipout@Init}{%
|
| 102 |
+
\message{ABD: EveryShipout initializing macros}%
|
| 103 |
+
\let\@EveryShipout@Org@Shipout\shipout
|
| 104 |
+
\let\shipout\@EveryShipout@Shipout
|
| 105 |
+
}
|
| 106 |
+
\AtBeginDocument{\@EveryShipout@Init}
|
| 107 |
+
\endinput
|
| 108 |
+
%%
|
| 109 |
+
%% End of file `everyshi.sty'.
|
download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eps/arch.pdf
ADDED
|
Binary file (35.1 kB). View file
|
|
|
download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eps/block.pdf
ADDED
|
Binary file (409 kB). View file
|
|
|
download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eps/block_deeper.pdf
ADDED
|
Binary file (22.4 kB). View file
|
|
|
download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eps/cifar.pdf
ADDED
|
Binary file (27 kB). View file
|
|
|
download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eps/imagenet.pdf
ADDED
|
Binary file (23.9 kB). View file
|
|
|
download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eps/std.pdf
ADDED
|
Binary file (20.5 kB). View file
|
|
|
download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eps/teaser.pdf
ADDED
|
Binary file (20.8 kB). View file
|
|
|
download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/eso-pic.sty
ADDED
|
@@ -0,0 +1,267 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
%%
|
| 2 |
+
%% This is file `eso-pic.sty',
|
| 3 |
+
%% generated with the docstrip utility.
|
| 4 |
+
%%
|
| 5 |
+
%% The original source files were:
|
| 6 |
+
%%
|
| 7 |
+
%% eso-pic.dtx (with options: `package')
|
| 8 |
+
%%
|
| 9 |
+
%% This is a generated file.
|
| 10 |
+
%%
|
| 11 |
+
%% Copyright (C) 1998-2002 by Rolf Niepraschk <[email protected]>
|
| 12 |
+
%%
|
| 13 |
+
%% This file may be distributed and/or modified under the conditions of
|
| 14 |
+
%% the LaTeX Project Public License, either version 1.2 of this license
|
| 15 |
+
%% or (at your option) any later version. The latest version of this
|
| 16 |
+
%% license is in:
|
| 17 |
+
%%
|
| 18 |
+
%% http://www.latex-project.org/lppl.txt
|
| 19 |
+
%%
|
| 20 |
+
%% and version 1.2 or later is part of all distributions of LaTeX version
|
| 21 |
+
%% 1999/12/01 or later.
|
| 22 |
+
%%
|
| 23 |
+
\NeedsTeXFormat{LaTeX2e}[1999/12/01]
|
| 24 |
+
\ProvidesPackage{eso-pic}
|
| 25 |
+
[2002/11/16 v1.1b eso-pic (RN)]
|
| 26 |
+
\input{cvpr_eso.sty}
|
| 27 |
+
\newcommand\LenToUnit[1]{#1\@gobble}
|
| 28 |
+
|
| 29 |
+
\newcommand\AtPageUpperLeft[1]{%
|
| 30 |
+
\begingroup
|
| 31 |
+
\@tempdima=0pt\relax\@tempdimb=\ESO@yoffsetI\relax
|
| 32 |
+
\put(\LenToUnit{\@tempdima},\LenToUnit{\@tempdimb}){#1}%
|
| 33 |
+
\endgroup
|
| 34 |
+
}
|
| 35 |
+
\newcommand\AtPageLowerLeft[1]{\AtPageUpperLeft{%
|
| 36 |
+
\put(0,\LenToUnit{-\paperheight}){#1}}}
|
| 37 |
+
\newcommand\AtPageCenter[1]{\AtPageUpperLeft{%
|
| 38 |
+
\put(\LenToUnit{.5\paperwidth},\LenToUnit{-.5\paperheight}){#1}}%
|
| 39 |
+
}
|
| 40 |
+
\newcommand\AtTextUpperLeft[1]{%
|
| 41 |
+
\begingroup
|
| 42 |
+
\setlength\@tempdima{1in}%
|
| 43 |
+
\ifodd\c@page%
|
| 44 |
+
\advance\@tempdima\oddsidemargin%
|
| 45 |
+
\else%
|
| 46 |
+
\advance\@tempdima\evensidemargin%
|
| 47 |
+
\fi%
|
| 48 |
+
\@tempdimb=\ESO@yoffsetI\relax\advance\@tempdimb-1in\relax%
|
| 49 |
+
\advance\@tempdimb-\topmargin%
|
| 50 |
+
\advance\@tempdimb-\headheight\advance\@tempdimb-\headsep%
|
| 51 |
+
\put(\LenToUnit{\@tempdima},\LenToUnit{\@tempdimb}){#1}%
|
| 52 |
+
\endgroup
|
| 53 |
+
}
|
| 54 |
+
\newcommand\AtTextLowerLeft[1]{\AtTextUpperLeft{%
|
| 55 |
+
\put(0,\LenToUnit{-\textheight}){#1}}}
|
| 56 |
+
\newcommand\AtTextCenter[1]{\AtTextUpperLeft{%
|
| 57 |
+
\put(\LenToUnit{.5\textwidth},\LenToUnit{-.5\textheight}){#1}}}
|
| 58 |
+
\newcommand{\ESO@HookI}{} \newcommand{\ESO@HookII}{}
|
| 59 |
+
\newcommand{\ESO@HookIII}{}
|
| 60 |
+
\newcommand{\AddToShipoutPicture}{%
|
| 61 |
+
\@ifstar{\g@addto@macro\ESO@HookII}{\g@addto@macro\ESO@HookI}}
|
| 62 |
+
\newcommand{\ClearShipoutPicture}{\global\let\ESO@HookI\@empty}
|
| 63 |
+
\newcommand\ESO@isMEMOIR[1]{}
|
| 64 |
+
\@ifclassloaded{memoir}{\renewcommand\ESO@isMEMOIR[1]{#1}}{}
|
| 65 |
+
\newcommand{\@ShipoutPicture}{%
|
| 66 |
+
\bgroup
|
| 67 |
+
\@tempswafalse%
|
| 68 |
+
\ifx\ESO@HookI\@empty\else\@tempswatrue\fi%
|
| 69 |
+
\ifx\ESO@HookII\@empty\else\@tempswatrue\fi%
|
| 70 |
+
\ifx\ESO@HookIII\@empty\else\@tempswatrue\fi%
|
| 71 |
+
\if@tempswa%
|
| 72 |
+
\@tempdima=1in\@tempdimb=-\@tempdima%
|
| 73 |
+
\advance\@tempdimb\ESO@yoffsetI%
|
| 74 |
+
\ESO@isMEMOIR{%
|
| 75 |
+
\advance\@tempdima\trimedge%
|
| 76 |
+
\advance\@tempdima\paperwidth%
|
| 77 |
+
\advance\@tempdima-\stockwidth%
|
| 78 |
+
\if@twoside\ifodd\c@page\else%
|
| 79 |
+
\advance\@tempdima-2\trimedge%
|
| 80 |
+
\advance\@tempdima-\paperwidth%
|
| 81 |
+
\advance\@tempdima\stockwidth%
|
| 82 |
+
\fi\fi%
|
| 83 |
+
\advance\@tempdimb\trimtop}%
|
| 84 |
+
\unitlength=1pt%
|
| 85 |
+
\global\setbox\@cclv\vbox{%
|
| 86 |
+
\vbox{\let\protect\relax
|
| 87 |
+
\pictur@(0,0)(\strip@pt\@tempdima,\strip@pt\@tempdimb)%
|
| 88 |
+
\ESO@HookIII\ESO@HookI\ESO@HookII%
|
| 89 |
+
\global\let\ESO@HookII\@empty%
|
| 90 |
+
\endpicture}%
|
| 91 |
+
\nointerlineskip%
|
| 92 |
+
\box\@cclv}%
|
| 93 |
+
\fi
|
| 94 |
+
\egroup
|
| 95 |
+
}
|
| 96 |
+
\EveryShipout{\@ShipoutPicture}
|
| 97 |
+
\RequirePackage{keyval}
|
| 98 |
+
\newif\ifESO@dvips\ESO@dvipsfalse \newif\ifESO@grid\ESO@gridfalse
|
| 99 |
+
\newif\ifESO@texcoord\ESO@texcoordfalse
|
| 100 |
+
\newcommand*\ESO@gridunitname{}
|
| 101 |
+
\newcommand*\ESO@gridunit{}
|
| 102 |
+
\newcommand*\ESO@labelfactor{}
|
| 103 |
+
\newcommand*\ESO@griddelta{}\newcommand*\ESO@griddeltaY{}
|
| 104 |
+
\newcommand*\ESO@gridDelta{}\newcommand*\ESO@gridDeltaY{}
|
| 105 |
+
\newcommand*\ESO@gridcolor{}
|
| 106 |
+
\newcommand*\ESO@subgridcolor{}
|
| 107 |
+
\newcommand*\ESO@subgridstyle{dotted}% ???
|
| 108 |
+
\newcommand*\ESO@gap{}
|
| 109 |
+
\newcommand*\ESO@yoffsetI{}\newcommand*\ESO@yoffsetII{}
|
| 110 |
+
\newcommand*\ESO@gridlines{\thinlines}
|
| 111 |
+
\newcommand*\ESO@subgridlines{\thinlines}
|
| 112 |
+
\newcommand*\ESO@hline[1]{\ESO@subgridlines\line(1,0){#1}}
|
| 113 |
+
\newcommand*\ESO@vline[1]{\ESO@subgridlines\line(0,1){#1}}
|
| 114 |
+
\newcommand*\ESO@Hline[1]{\ESO@gridlines\line(1,0){#1}}
|
| 115 |
+
\newcommand*\ESO@Vline[1]{\ESO@gridlines\line(0,1){#1}}
|
| 116 |
+
\newcommand\ESO@fcolorbox[4][]{\fbox{#4}}
|
| 117 |
+
\newcommand\ESO@color[1]{}
|
| 118 |
+
\newcommand\ESO@colorbox[3][]{%
|
| 119 |
+
\begingroup
|
| 120 |
+
\fboxrule=0pt\fbox{#3}%
|
| 121 |
+
\endgroup
|
| 122 |
+
}
|
| 123 |
+
\newcommand\gridSetup[6][]{%
|
| 124 |
+
\edef\ESO@gridunitname{#1}\edef\ESO@gridunit{#2}
|
| 125 |
+
\edef\ESO@labelfactor{#3}\edef\ESO@griddelta{#4}
|
| 126 |
+
\edef\ESO@gridDelta{#5}\edef\ESO@gap{#6}}
|
| 127 |
+
\define@key{ESO}{texcoord}[true]{\csname ESO@texcoord#1\endcsname}
|
| 128 |
+
\define@key{ESO}{pscoord}[true]{\csname @tempswa#1\endcsname
|
| 129 |
+
\if@tempswa\ESO@texcoordfalse\else\ESO@texcoordtrue\fi}
|
| 130 |
+
\define@key{ESO}{dvips}[true]{\csname ESO@dvips#1\endcsname}
|
| 131 |
+
\define@key{ESO}{grid}[true]{\csname ESO@grid#1\endcsname
|
| 132 |
+
\setkeys{ESO}{gridcolor=black,subgridcolor=black}}
|
| 133 |
+
\define@key{ESO}{colorgrid}[true]{\csname ESO@grid#1\endcsname
|
| 134 |
+
\setkeys{ESO}{gridcolor=red,subgridcolor=green}}
|
| 135 |
+
\define@key{ESO}{gridcolor}{\def\ESO@gridcolor{#1}}
|
| 136 |
+
\define@key{ESO}{subgridcolor}{\def\ESO@subgridcolor{#1}}
|
| 137 |
+
\define@key{ESO}{subgridstyle}{\def\ESO@subgridstyle{#1}}%
|
| 138 |
+
\define@key{ESO}{gridunit}{%
|
| 139 |
+
\def\@tempa{#1}
|
| 140 |
+
\def\@tempb{bp}
|
| 141 |
+
\ifx\@tempa\@tempb
|
| 142 |
+
\gridSetup[\@tempa]{1bp}{1}{10}{50}{2}
|
| 143 |
+
\else
|
| 144 |
+
\def\@tempb{pt}
|
| 145 |
+
\ifx\@tempa\@tempb
|
| 146 |
+
\gridSetup[\@tempa]{1pt}{1}{10}{50}{2}
|
| 147 |
+
\else
|
| 148 |
+
\def\@tempb{in}
|
| 149 |
+
\ifx\@tempa\@tempb
|
| 150 |
+
\gridSetup[\@tempa]{.1in}{.1}{2}{10}{.5}
|
| 151 |
+
\else
|
| 152 |
+
\gridSetup[mm]{1mm}{1}{5}{20}{1}
|
| 153 |
+
\fi
|
| 154 |
+
\fi
|
| 155 |
+
\fi
|
| 156 |
+
}
|
| 157 |
+
\setkeys{ESO}{subgridstyle=solid,pscoord=true,gridunit=mm}
|
| 158 |
+
\def\ProcessOptionsWithKV#1{%
|
| 159 |
+
\let\@tempc\@empty
|
| 160 |
+
\@for\CurrentOption:=\@classoptionslist\do{%
|
| 161 |
+
\@ifundefined{KV@#1@\CurrentOption}%
|
| 162 |
+
{}{\edef\@tempc{\@tempc,\CurrentOption,}}}%
|
| 163 |
+
\edef\@tempc{%
|
| 164 |
+
\noexpand\setkeys{#1}{\@tempc\@ptionlist{\@currname.\@currext}}}%
|
| 165 |
+
\@tempc
|
| 166 |
+
\AtEndOfPackage{\let\@unprocessedoptions\relax}}%
|
| 167 |
+
\ProcessOptionsWithKV{ESO}%
|
| 168 |
+
\newcommand\ESO@div[2]{%
|
| 169 |
+
\@tempdima=#1\relax\@tempdimb=\ESO@gridunit\relax
|
| 170 |
+
\@tempdimb=#2\@tempdimb\divide\@tempdima by \@tempdimb%
|
| 171 |
+
\@tempcnta\@tempdima\advance\@tempcnta\@ne}
|
| 172 |
+
\AtBeginDocument{%
|
| 173 |
+
\IfFileExists{color.sty}
|
| 174 |
+
{%
|
| 175 |
+
\RequirePackage{color}
|
| 176 |
+
\let\ESO@color=\color\let\ESO@colorbox=\colorbox
|
| 177 |
+
\let\ESO@fcolorbox=\fcolorbox
|
| 178 |
+
}{}
|
| 179 |
+
\@ifundefined{Gin@driver}{}%
|
| 180 |
+
{%
|
| 181 |
+
\ifx\Gin@driver\@empty\else%
|
| 182 |
+
\filename@parse{\Gin@driver}\def\reserved@a{dvips}%
|
| 183 |
+
\ifx\filename@base\reserved@a\ESO@dvipstrue\fi%
|
| 184 |
+
\fi
|
| 185 |
+
}%
|
| 186 |
+
\ifx\pdfoutput\undefined\else
|
| 187 |
+
\ifx\pdfoutput\relax\else
|
| 188 |
+
\ifcase\pdfoutput\else
|
| 189 |
+
\ESO@dvipsfalse%
|
| 190 |
+
\fi
|
| 191 |
+
\fi
|
| 192 |
+
\fi
|
| 193 |
+
\ifESO@dvips\def\@tempb{eepic}\else\def\@tempb{epic}\fi
|
| 194 |
+
\def\@tempa{dotted}%\def\ESO@gap{\LenToUnit{6\@wholewidth}}%
|
| 195 |
+
\ifx\@tempa\ESO@subgridstyle
|
| 196 |
+
\IfFileExists{\@tempb.sty}%
|
| 197 |
+
{%
|
| 198 |
+
\RequirePackage{\@tempb}
|
| 199 |
+
\renewcommand*\ESO@hline[1]{\ESO@subgridlines\dottedline{\ESO@gap}%
|
| 200 |
+
(0,0)(##1,0)}
|
| 201 |
+
\renewcommand*\ESO@vline[1]{\ESO@subgridlines\dottedline{\ESO@gap}%
|
| 202 |
+
(0,0)(0,##1)}
|
| 203 |
+
}{}
|
| 204 |
+
\else
|
| 205 |
+
\ifx\ESO@gridcolor\ESO@subgridcolor%
|
| 206 |
+
\renewcommand*\ESO@gridlines{\thicklines}
|
| 207 |
+
\fi
|
| 208 |
+
\fi
|
| 209 |
+
}
|
| 210 |
+
\ifESO@texcoord
|
| 211 |
+
\def\ESO@yoffsetI{0pt}\def\ESO@yoffsetII{-\paperheight}
|
| 212 |
+
\edef\ESO@griddeltaY{-\ESO@griddelta}\edef\ESO@gridDeltaY{-\ESO@gridDelta}
|
| 213 |
+
\else
|
| 214 |
+
\def\ESO@yoffsetI{\paperheight}\def\ESO@yoffsetII{0pt}
|
| 215 |
+
\edef\ESO@griddeltaY{\ESO@griddelta}\edef\ESO@gridDeltaY{\ESO@gridDelta}
|
| 216 |
+
\fi
|
| 217 |
+
\newcommand\ESO@gridpicture{%
|
| 218 |
+
\begingroup
|
| 219 |
+
\setlength\unitlength{\ESO@gridunit}%
|
| 220 |
+
\ESO@color{\ESO@subgridcolor}%
|
| 221 |
+
\ESO@div{\paperheight}{\ESO@griddelta}%
|
| 222 |
+
\multiput(0,0)(0,\ESO@griddeltaY){\@tempcnta}%
|
| 223 |
+
{\ESO@hline{\LenToUnit{\paperwidth}}}%
|
| 224 |
+
\ESO@div{\paperwidth}{\ESO@griddelta}%
|
| 225 |
+
\multiput(0,\LenToUnit{\ESO@yoffsetII})(\ESO@griddelta,0){\@tempcnta}%
|
| 226 |
+
{\ESO@vline{\LenToUnit{\paperheight}}}%
|
| 227 |
+
\ESO@color{\ESO@gridcolor}%
|
| 228 |
+
\ESO@div{\paperheight}{\ESO@gridDelta}%
|
| 229 |
+
\multiput(0,0)(0,\ESO@gridDeltaY){\@tempcnta}%
|
| 230 |
+
{\ESO@Hline{\LenToUnit{\paperwidth}}}%
|
| 231 |
+
\ESO@div{\paperwidth}{\ESO@gridDelta}%
|
| 232 |
+
\multiput(0,\LenToUnit{\ESO@yoffsetII})(\ESO@gridDelta,0){\@tempcnta}%
|
| 233 |
+
{\ESO@Vline{\LenToUnit{\paperheight}}}%
|
| 234 |
+
\fontsize{10}{12}\normalfont%
|
| 235 |
+
\ESO@div{\paperwidth}{\ESO@gridDelta}%
|
| 236 |
+
\multiput(0,\ESO@gridDeltaY)(\ESO@gridDelta,0){\@tempcnta}{%
|
| 237 |
+
\@tempcntb=\@tempcnta\advance\@tempcntb-\@multicnt%
|
| 238 |
+
\ifnum\@tempcntb>1\relax
|
| 239 |
+
\multiply\@tempcntb by \ESO@gridDelta\relax%
|
| 240 |
+
\@tempdima=\@tempcntb sp\@tempdima=\ESO@labelfactor\@tempdima%
|
| 241 |
+
\@tempcntb=\@tempdima%
|
| 242 |
+
\makebox(0,0)[c]{\ESO@colorbox{white}{\the\@tempcntb}}%
|
| 243 |
+
\fi}%
|
| 244 |
+
\ifx\ESO@gridunitname\@empty\def\@tempa{0}\else\def\@tempa{1}\fi%
|
| 245 |
+
\ESO@div{\paperheight}{\ESO@gridDelta}%
|
| 246 |
+
\multiput(\ESO@gridDelta,0)(0,\ESO@gridDeltaY){\@tempcnta}{%
|
| 247 |
+
\@tempcntb=\@tempcnta\advance\@tempcntb-\@multicnt%
|
| 248 |
+
\ifnum\@tempcntb>\@tempa\relax
|
| 249 |
+
\multiply\@tempcntb by \ESO@gridDelta\relax%
|
| 250 |
+
\@tempdima=\@tempcntb sp\@tempdima=\ESO@labelfactor\@tempdima%
|
| 251 |
+
\@tempcntb=\@tempdima%
|
| 252 |
+
\makebox(0,0)[c]{\ESO@colorbox{white}{\the\@tempcntb}}%
|
| 253 |
+
\fi
|
| 254 |
+
}%
|
| 255 |
+
\ifx\ESO@gridunitname\@empty\else%
|
| 256 |
+
\thicklines\fboxrule=\@wholewidth%
|
| 257 |
+
\put(\ESO@gridDelta,\ESO@gridDeltaY){\makebox(0,0)[c]{%
|
| 258 |
+
\ESO@fcolorbox{\ESO@gridcolor}{white}{%
|
| 259 |
+
\textbf{\ESO@gridunitname}}}}%
|
| 260 |
+
\fi
|
| 261 |
+
\normalcolor%
|
| 262 |
+
\endgroup
|
| 263 |
+
}
|
| 264 |
+
\ifESO@grid\g@addto@macro\ESO@HookIII{\ESO@gridpicture}\fi
|
| 265 |
+
\endinput
|
| 266 |
+
%%
|
| 267 |
+
%% End of file `eso-pic.sty'.
|
download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/ieee.bst
ADDED
|
@@ -0,0 +1,1129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
% ---------------------------------------------------------------
|
| 3 |
+
%
|
| 4 |
+
% ieee.bst,v 1.0 2002/04/16
|
| 5 |
+
%
|
| 6 |
+
% by Glenn Paulley ([email protected])
|
| 7 |
+
%
|
| 8 |
+
% Modified from latex8.bst 1995/09/15 15:13:49 ienne Exp $
|
| 9 |
+
%
|
| 10 |
+
% by [email protected]
|
| 11 |
+
%
|
| 12 |
+
%
|
| 13 |
+
% ---------------------------------------------------------------
|
| 14 |
+
%
|
| 15 |
+
% no guarantee is given that the format corresponds perfectly to
|
| 16 |
+
% IEEE 8.5" x 11" Proceedings, but most features should be ok.
|
| 17 |
+
%
|
| 18 |
+
% ---------------------------------------------------------------
|
| 19 |
+
%
|
| 20 |
+
% `ieee' from BibTeX standard bibliography style `abbrv'
|
| 21 |
+
% version 0.99a for BibTeX versions 0.99a or later, LaTeX version 2.09.
|
| 22 |
+
% Copyright (C) 1985, all rights reserved.
|
| 23 |
+
% Copying of this file is authorized only if either
|
| 24 |
+
% (1) you make absolutely no changes to your copy, including name, or
|
| 25 |
+
% (2) if you do make changes, you name it something other than
|
| 26 |
+
% btxbst.doc, plain.bst, unsrt.bst, alpha.bst, and abbrv.bst.
|
| 27 |
+
% This restriction helps ensure that all standard styles are identical.
|
| 28 |
+
% The file btxbst.doc has the documentation for this style.
|
| 29 |
+
|
| 30 |
+
ENTRY
|
| 31 |
+
{ address
|
| 32 |
+
author
|
| 33 |
+
booktitle
|
| 34 |
+
chapter
|
| 35 |
+
edition
|
| 36 |
+
editor
|
| 37 |
+
howpublished
|
| 38 |
+
institution
|
| 39 |
+
journal
|
| 40 |
+
key
|
| 41 |
+
month
|
| 42 |
+
note
|
| 43 |
+
number
|
| 44 |
+
organization
|
| 45 |
+
pages
|
| 46 |
+
publisher
|
| 47 |
+
school
|
| 48 |
+
series
|
| 49 |
+
title
|
| 50 |
+
type
|
| 51 |
+
volume
|
| 52 |
+
year
|
| 53 |
+
}
|
| 54 |
+
{}
|
| 55 |
+
{ label }
|
| 56 |
+
|
| 57 |
+
INTEGERS { output.state before.all mid.sentence after.sentence after.block }
|
| 58 |
+
|
| 59 |
+
FUNCTION {init.state.consts}
|
| 60 |
+
{ #0 'before.all :=
|
| 61 |
+
#1 'mid.sentence :=
|
| 62 |
+
#2 'after.sentence :=
|
| 63 |
+
#3 'after.block :=
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
STRINGS { s t }
|
| 67 |
+
|
| 68 |
+
FUNCTION {output.nonnull}
|
| 69 |
+
{ 's :=
|
| 70 |
+
output.state mid.sentence =
|
| 71 |
+
{ ", " * write$ }
|
| 72 |
+
{ output.state after.block =
|
| 73 |
+
{ add.period$ write$
|
| 74 |
+
newline$
|
| 75 |
+
"\newblock " write$
|
| 76 |
+
}
|
| 77 |
+
{ output.state before.all =
|
| 78 |
+
'write$
|
| 79 |
+
{ add.period$ " " * write$ }
|
| 80 |
+
if$
|
| 81 |
+
}
|
| 82 |
+
if$
|
| 83 |
+
mid.sentence 'output.state :=
|
| 84 |
+
}
|
| 85 |
+
if$
|
| 86 |
+
s
|
| 87 |
+
}
|
| 88 |
+
|
| 89 |
+
FUNCTION {output}
|
| 90 |
+
{ duplicate$ empty$
|
| 91 |
+
'pop$
|
| 92 |
+
'output.nonnull
|
| 93 |
+
if$
|
| 94 |
+
}
|
| 95 |
+
|
| 96 |
+
FUNCTION {output.check}
|
| 97 |
+
{ 't :=
|
| 98 |
+
duplicate$ empty$
|
| 99 |
+
{ pop$ "empty " t * " in " * cite$ * warning$ }
|
| 100 |
+
'output.nonnull
|
| 101 |
+
if$
|
| 102 |
+
}
|
| 103 |
+
|
| 104 |
+
FUNCTION {output.bibitem}
|
| 105 |
+
{ newline$
|
| 106 |
+
"\bibitem{" write$
|
| 107 |
+
cite$ write$
|
| 108 |
+
"}" write$
|
| 109 |
+
newline$
|
| 110 |
+
""
|
| 111 |
+
before.all 'output.state :=
|
| 112 |
+
}
|
| 113 |
+
|
| 114 |
+
FUNCTION {fin.entry}
|
| 115 |
+
{ add.period$
|
| 116 |
+
write$
|
| 117 |
+
newline$
|
| 118 |
+
}
|
| 119 |
+
|
| 120 |
+
FUNCTION {new.block}
|
| 121 |
+
{ output.state before.all =
|
| 122 |
+
'skip$
|
| 123 |
+
{ after.block 'output.state := }
|
| 124 |
+
if$
|
| 125 |
+
}
|
| 126 |
+
|
| 127 |
+
FUNCTION {new.sentence}
|
| 128 |
+
{ output.state after.block =
|
| 129 |
+
'skip$
|
| 130 |
+
{ output.state before.all =
|
| 131 |
+
'skip$
|
| 132 |
+
{ after.sentence 'output.state := }
|
| 133 |
+
if$
|
| 134 |
+
}
|
| 135 |
+
if$
|
| 136 |
+
}
|
| 137 |
+
|
| 138 |
+
FUNCTION {not}
|
| 139 |
+
{ { #0 }
|
| 140 |
+
{ #1 }
|
| 141 |
+
if$
|
| 142 |
+
}
|
| 143 |
+
|
| 144 |
+
FUNCTION {and}
|
| 145 |
+
{ 'skip$
|
| 146 |
+
{ pop$ #0 }
|
| 147 |
+
if$
|
| 148 |
+
}
|
| 149 |
+
|
| 150 |
+
FUNCTION {or}
|
| 151 |
+
{ { pop$ #1 }
|
| 152 |
+
'skip$
|
| 153 |
+
if$
|
| 154 |
+
}
|
| 155 |
+
|
| 156 |
+
FUNCTION {new.block.checka}
|
| 157 |
+
{ empty$
|
| 158 |
+
'skip$
|
| 159 |
+
'new.block
|
| 160 |
+
if$
|
| 161 |
+
}
|
| 162 |
+
|
| 163 |
+
FUNCTION {new.block.checkb}
|
| 164 |
+
{ empty$
|
| 165 |
+
swap$ empty$
|
| 166 |
+
and
|
| 167 |
+
'skip$
|
| 168 |
+
'new.block
|
| 169 |
+
if$
|
| 170 |
+
}
|
| 171 |
+
|
| 172 |
+
FUNCTION {new.sentence.checka}
|
| 173 |
+
{ empty$
|
| 174 |
+
'skip$
|
| 175 |
+
'new.sentence
|
| 176 |
+
if$
|
| 177 |
+
}
|
| 178 |
+
|
| 179 |
+
FUNCTION {new.sentence.checkb}
|
| 180 |
+
{ empty$
|
| 181 |
+
swap$ empty$
|
| 182 |
+
and
|
| 183 |
+
'skip$
|
| 184 |
+
'new.sentence
|
| 185 |
+
if$
|
| 186 |
+
}
|
| 187 |
+
|
| 188 |
+
FUNCTION {field.or.null}
|
| 189 |
+
{ duplicate$ empty$
|
| 190 |
+
{ pop$ "" }
|
| 191 |
+
'skip$
|
| 192 |
+
if$
|
| 193 |
+
}
|
| 194 |
+
|
| 195 |
+
FUNCTION {emphasize}
|
| 196 |
+
{ duplicate$ empty$
|
| 197 |
+
{ pop$ "" }
|
| 198 |
+
{ "{\em " swap$ * "}" * }
|
| 199 |
+
if$
|
| 200 |
+
}
|
| 201 |
+
|
| 202 |
+
INTEGERS { nameptr namesleft numnames }
|
| 203 |
+
|
| 204 |
+
FUNCTION {format.names}
|
| 205 |
+
{ 's :=
|
| 206 |
+
#1 'nameptr :=
|
| 207 |
+
s num.names$ 'numnames :=
|
| 208 |
+
numnames 'namesleft :=
|
| 209 |
+
{ namesleft #0 > }
|
| 210 |
+
{ s nameptr "{f.~}{vv~}{ll}{, jj}" format.name$ 't :=
|
| 211 |
+
nameptr #1 >
|
| 212 |
+
{ namesleft #1 >
|
| 213 |
+
{ ", " * t * }
|
| 214 |
+
{ numnames #2 >
|
| 215 |
+
{ "," * }
|
| 216 |
+
'skip$
|
| 217 |
+
if$
|
| 218 |
+
t "others" =
|
| 219 |
+
{ " et~al." * }
|
| 220 |
+
{ " and " * t * }
|
| 221 |
+
if$
|
| 222 |
+
}
|
| 223 |
+
if$
|
| 224 |
+
}
|
| 225 |
+
't
|
| 226 |
+
if$
|
| 227 |
+
nameptr #1 + 'nameptr :=
|
| 228 |
+
|
| 229 |
+
namesleft #1 - 'namesleft :=
|
| 230 |
+
}
|
| 231 |
+
while$
|
| 232 |
+
}
|
| 233 |
+
|
| 234 |
+
FUNCTION {format.authors}
|
| 235 |
+
{ author empty$
|
| 236 |
+
{ "" }
|
| 237 |
+
{ author format.names }
|
| 238 |
+
if$
|
| 239 |
+
}
|
| 240 |
+
|
| 241 |
+
FUNCTION {format.editors}
|
| 242 |
+
{ editor empty$
|
| 243 |
+
{ "" }
|
| 244 |
+
{ editor format.names
|
| 245 |
+
editor num.names$ #1 >
|
| 246 |
+
{ ", editors" * }
|
| 247 |
+
{ ", editor" * }
|
| 248 |
+
if$
|
| 249 |
+
}
|
| 250 |
+
if$
|
| 251 |
+
}
|
| 252 |
+
|
| 253 |
+
FUNCTION {format.title}
|
| 254 |
+
{ title empty$
|
| 255 |
+
{ "" }
|
| 256 |
+
{ title "t" change.case$ }
|
| 257 |
+
if$
|
| 258 |
+
}
|
| 259 |
+
|
| 260 |
+
FUNCTION {n.dashify}
|
| 261 |
+
{ 't :=
|
| 262 |
+
""
|
| 263 |
+
{ t empty$ not }
|
| 264 |
+
{ t #1 #1 substring$ "-" =
|
| 265 |
+
{ t #1 #2 substring$ "--" = not
|
| 266 |
+
{ "--" *
|
| 267 |
+
t #2 global.max$ substring$ 't :=
|
| 268 |
+
}
|
| 269 |
+
{ { t #1 #1 substring$ "-" = }
|
| 270 |
+
{ "-" *
|
| 271 |
+
t #2 global.max$ substring$ 't :=
|
| 272 |
+
}
|
| 273 |
+
while$
|
| 274 |
+
}
|
| 275 |
+
if$
|
| 276 |
+
}
|
| 277 |
+
{ t #1 #1 substring$ *
|
| 278 |
+
t #2 global.max$ substring$ 't :=
|
| 279 |
+
}
|
| 280 |
+
if$
|
| 281 |
+
}
|
| 282 |
+
while$
|
| 283 |
+
}
|
| 284 |
+
|
| 285 |
+
FUNCTION {format.date}
|
| 286 |
+
{ year empty$
|
| 287 |
+
{ month empty$
|
| 288 |
+
{ "" }
|
| 289 |
+
{ "there's a month but no year in " cite$ * warning$
|
| 290 |
+
month
|
| 291 |
+
}
|
| 292 |
+
if$
|
| 293 |
+
}
|
| 294 |
+
{ month empty$
|
| 295 |
+
'year
|
| 296 |
+
{ month " " * year * }
|
| 297 |
+
if$
|
| 298 |
+
}
|
| 299 |
+
if$
|
| 300 |
+
}
|
| 301 |
+
|
| 302 |
+
FUNCTION {format.btitle}
|
| 303 |
+
{ title emphasize
|
| 304 |
+
}
|
| 305 |
+
|
| 306 |
+
FUNCTION {tie.or.space.connect}
|
| 307 |
+
{ duplicate$ text.length$ #3 <
|
| 308 |
+
{ "~" }
|
| 309 |
+
{ " " }
|
| 310 |
+
if$
|
| 311 |
+
swap$ * *
|
| 312 |
+
}
|
| 313 |
+
|
| 314 |
+
FUNCTION {either.or.check}
|
| 315 |
+
{ empty$
|
| 316 |
+
'pop$
|
| 317 |
+
{ "can't use both " swap$ * " fields in " * cite$ * warning$ }
|
| 318 |
+
if$
|
| 319 |
+
}
|
| 320 |
+
|
| 321 |
+
FUNCTION {format.bvolume}
|
| 322 |
+
{ volume empty$
|
| 323 |
+
{ "" }
|
| 324 |
+
{ "volume" volume tie.or.space.connect
|
| 325 |
+
series empty$
|
| 326 |
+
'skip$
|
| 327 |
+
{ " of " * series emphasize * }
|
| 328 |
+
if$
|
| 329 |
+
"volume and number" number either.or.check
|
| 330 |
+
}
|
| 331 |
+
if$
|
| 332 |
+
}
|
| 333 |
+
|
| 334 |
+
FUNCTION {format.number.series}
|
| 335 |
+
{ volume empty$
|
| 336 |
+
{ number empty$
|
| 337 |
+
{ series field.or.null }
|
| 338 |
+
{ output.state mid.sentence =
|
| 339 |
+
{ "number" }
|
| 340 |
+
{ "Number" }
|
| 341 |
+
if$
|
| 342 |
+
number tie.or.space.connect
|
| 343 |
+
series empty$
|
| 344 |
+
{ "there's a number but no series in " cite$ * warning$ }
|
| 345 |
+
{ " in " * series * }
|
| 346 |
+
if$
|
| 347 |
+
}
|
| 348 |
+
if$
|
| 349 |
+
}
|
| 350 |
+
{ "" }
|
| 351 |
+
if$
|
| 352 |
+
}
|
| 353 |
+
|
| 354 |
+
FUNCTION {format.edition}
|
| 355 |
+
{ edition empty$
|
| 356 |
+
{ "" }
|
| 357 |
+
{ output.state mid.sentence =
|
| 358 |
+
{ edition "l" change.case$ " edition" * }
|
| 359 |
+
{ edition "t" change.case$ " edition" * }
|
| 360 |
+
if$
|
| 361 |
+
}
|
| 362 |
+
if$
|
| 363 |
+
}
|
| 364 |
+
|
| 365 |
+
INTEGERS { multiresult }
|
| 366 |
+
|
| 367 |
+
FUNCTION {multi.page.check}
|
| 368 |
+
{ 't :=
|
| 369 |
+
#0 'multiresult :=
|
| 370 |
+
{ multiresult not
|
| 371 |
+
t empty$ not
|
| 372 |
+
and
|
| 373 |
+
}
|
| 374 |
+
{ t #1 #1 substring$
|
| 375 |
+
duplicate$ "-" =
|
| 376 |
+
swap$ duplicate$ "," =
|
| 377 |
+
swap$ "+" =
|
| 378 |
+
or or
|
| 379 |
+
{ #1 'multiresult := }
|
| 380 |
+
{ t #2 global.max$ substring$ 't := }
|
| 381 |
+
if$
|
| 382 |
+
}
|
| 383 |
+
while$
|
| 384 |
+
multiresult
|
| 385 |
+
}
|
| 386 |
+
|
| 387 |
+
FUNCTION {format.pages}
|
| 388 |
+
{ pages empty$
|
| 389 |
+
{ "" }
|
| 390 |
+
{ pages multi.page.check
|
| 391 |
+
{ "pages" pages n.dashify tie.or.space.connect }
|
| 392 |
+
{ "page" pages tie.or.space.connect }
|
| 393 |
+
if$
|
| 394 |
+
}
|
| 395 |
+
if$
|
| 396 |
+
}
|
| 397 |
+
|
| 398 |
+
FUNCTION {format.vol.num.pages}
|
| 399 |
+
{ volume field.or.null
|
| 400 |
+
number empty$
|
| 401 |
+
'skip$
|
| 402 |
+
{ "(" number * ")" * *
|
| 403 |
+
volume empty$
|
| 404 |
+
{ "there's a number but no volume in " cite$ * warning$ }
|
| 405 |
+
'skip$
|
| 406 |
+
if$
|
| 407 |
+
}
|
| 408 |
+
if$
|
| 409 |
+
pages empty$
|
| 410 |
+
'skip$
|
| 411 |
+
{ duplicate$ empty$
|
| 412 |
+
{ pop$ format.pages }
|
| 413 |
+
{ ":" * pages n.dashify * }
|
| 414 |
+
if$
|
| 415 |
+
}
|
| 416 |
+
if$
|
| 417 |
+
}
|
| 418 |
+
|
| 419 |
+
FUNCTION {format.chapter.pages}
|
| 420 |
+
{ chapter empty$
|
| 421 |
+
'format.pages
|
| 422 |
+
{ type empty$
|
| 423 |
+
{ "chapter" }
|
| 424 |
+
{ type "l" change.case$ }
|
| 425 |
+
if$
|
| 426 |
+
chapter tie.or.space.connect
|
| 427 |
+
pages empty$
|
| 428 |
+
'skip$
|
| 429 |
+
{ ", " * format.pages * }
|
| 430 |
+
if$
|
| 431 |
+
}
|
| 432 |
+
if$
|
| 433 |
+
}
|
| 434 |
+
|
| 435 |
+
FUNCTION {format.in.ed.booktitle}
|
| 436 |
+
{ booktitle empty$
|
| 437 |
+
{ "" }
|
| 438 |
+
{ editor empty$
|
| 439 |
+
{ "In " booktitle emphasize * }
|
| 440 |
+
{ "In " format.editors * ", " * booktitle emphasize * }
|
| 441 |
+
if$
|
| 442 |
+
}
|
| 443 |
+
if$
|
| 444 |
+
}
|
| 445 |
+
|
| 446 |
+
FUNCTION {empty.misc.check}
|
| 447 |
+
|
| 448 |
+
{ author empty$ title empty$ howpublished empty$
|
| 449 |
+
month empty$ year empty$ note empty$
|
| 450 |
+
and and and and and
|
| 451 |
+
key empty$ not and
|
| 452 |
+
{ "all relevant fields are empty in " cite$ * warning$ }
|
| 453 |
+
'skip$
|
| 454 |
+
if$
|
| 455 |
+
}
|
| 456 |
+
|
| 457 |
+
FUNCTION {format.thesis.type}
|
| 458 |
+
{ type empty$
|
| 459 |
+
'skip$
|
| 460 |
+
{ pop$
|
| 461 |
+
type "t" change.case$
|
| 462 |
+
}
|
| 463 |
+
if$
|
| 464 |
+
}
|
| 465 |
+
|
| 466 |
+
FUNCTION {format.tr.number}
|
| 467 |
+
{ type empty$
|
| 468 |
+
{ "Technical Report" }
|
| 469 |
+
'type
|
| 470 |
+
if$
|
| 471 |
+
number empty$
|
| 472 |
+
{ "t" change.case$ }
|
| 473 |
+
{ number tie.or.space.connect }
|
| 474 |
+
if$
|
| 475 |
+
}
|
| 476 |
+
|
| 477 |
+
FUNCTION {format.article.crossref}
|
| 478 |
+
{ key empty$
|
| 479 |
+
{ journal empty$
|
| 480 |
+
{ "need key or journal for " cite$ * " to crossref " * crossref *
|
| 481 |
+
warning$
|
| 482 |
+
""
|
| 483 |
+
}
|
| 484 |
+
{ "In {\em " journal * "\/}" * }
|
| 485 |
+
if$
|
| 486 |
+
}
|
| 487 |
+
{ "In " key * }
|
| 488 |
+
if$
|
| 489 |
+
" \cite{" * crossref * "}" *
|
| 490 |
+
}
|
| 491 |
+
|
| 492 |
+
FUNCTION {format.crossref.editor}
|
| 493 |
+
{ editor #1 "{vv~}{ll}" format.name$
|
| 494 |
+
editor num.names$ duplicate$
|
| 495 |
+
#2 >
|
| 496 |
+
{ pop$ " et~al." * }
|
| 497 |
+
{ #2 <
|
| 498 |
+
'skip$
|
| 499 |
+
{ editor #2 "{ff }{vv }{ll}{ jj}" format.name$ "others" =
|
| 500 |
+
{ " et~al." * }
|
| 501 |
+
{ " and " * editor #2 "{vv~}{ll}" format.name$ * }
|
| 502 |
+
if$
|
| 503 |
+
}
|
| 504 |
+
if$
|
| 505 |
+
}
|
| 506 |
+
if$
|
| 507 |
+
}
|
| 508 |
+
|
| 509 |
+
FUNCTION {format.book.crossref}
|
| 510 |
+
{ volume empty$
|
| 511 |
+
{ "empty volume in " cite$ * "'s crossref of " * crossref * warning$
|
| 512 |
+
"In "
|
| 513 |
+
}
|
| 514 |
+
{ "Volume" volume tie.or.space.connect
|
| 515 |
+
" of " *
|
| 516 |
+
}
|
| 517 |
+
if$
|
| 518 |
+
editor empty$
|
| 519 |
+
editor field.or.null author field.or.null =
|
| 520 |
+
or
|
| 521 |
+
{ key empty$
|
| 522 |
+
{ series empty$
|
| 523 |
+
{ "need editor, key, or series for " cite$ * " to crossref " *
|
| 524 |
+
crossref * warning$
|
| 525 |
+
"" *
|
| 526 |
+
}
|
| 527 |
+
{ "{\em " * series * "\/}" * }
|
| 528 |
+
if$
|
| 529 |
+
}
|
| 530 |
+
{ key * }
|
| 531 |
+
if$
|
| 532 |
+
}
|
| 533 |
+
{ format.crossref.editor * }
|
| 534 |
+
if$
|
| 535 |
+
" \cite{" * crossref * "}" *
|
| 536 |
+
}
|
| 537 |
+
|
| 538 |
+
FUNCTION {format.incoll.inproc.crossref}
|
| 539 |
+
{ editor empty$
|
| 540 |
+
editor field.or.null author field.or.null =
|
| 541 |
+
or
|
| 542 |
+
{ key empty$
|
| 543 |
+
{ booktitle empty$
|
| 544 |
+
{ "need editor, key, or booktitle for " cite$ * " to crossref " *
|
| 545 |
+
crossref * warning$
|
| 546 |
+
""
|
| 547 |
+
}
|
| 548 |
+
{ "In {\em " booktitle * "\/}" * }
|
| 549 |
+
if$
|
| 550 |
+
}
|
| 551 |
+
{ "In " key * }
|
| 552 |
+
if$
|
| 553 |
+
}
|
| 554 |
+
{ "In " format.crossref.editor * }
|
| 555 |
+
if$
|
| 556 |
+
" \cite{" * crossref * "}" *
|
| 557 |
+
}
|
| 558 |
+
|
| 559 |
+
FUNCTION {article}
|
| 560 |
+
{ output.bibitem
|
| 561 |
+
format.authors "author" output.check
|
| 562 |
+
new.block
|
| 563 |
+
format.title "title" output.check
|
| 564 |
+
new.block
|
| 565 |
+
crossref missing$
|
| 566 |
+
{ journal emphasize "journal" output.check
|
| 567 |
+
format.vol.num.pages output
|
| 568 |
+
format.date "year" output.check
|
| 569 |
+
}
|
| 570 |
+
{ format.article.crossref output.nonnull
|
| 571 |
+
format.pages output
|
| 572 |
+
}
|
| 573 |
+
if$
|
| 574 |
+
new.block
|
| 575 |
+
note output
|
| 576 |
+
fin.entry
|
| 577 |
+
}
|
| 578 |
+
|
| 579 |
+
FUNCTION {book}
|
| 580 |
+
{ output.bibitem
|
| 581 |
+
author empty$
|
| 582 |
+
{ format.editors "author and editor" output.check }
|
| 583 |
+
{ format.authors output.nonnull
|
| 584 |
+
crossref missing$
|
| 585 |
+
{ "author and editor" editor either.or.check }
|
| 586 |
+
'skip$
|
| 587 |
+
if$
|
| 588 |
+
}
|
| 589 |
+
if$
|
| 590 |
+
new.block
|
| 591 |
+
format.btitle "title" output.check
|
| 592 |
+
crossref missing$
|
| 593 |
+
{ format.bvolume output
|
| 594 |
+
new.block
|
| 595 |
+
format.number.series output
|
| 596 |
+
new.sentence
|
| 597 |
+
publisher "publisher" output.check
|
| 598 |
+
address output
|
| 599 |
+
}
|
| 600 |
+
{ new.block
|
| 601 |
+
format.book.crossref output.nonnull
|
| 602 |
+
}
|
| 603 |
+
if$
|
| 604 |
+
format.edition output
|
| 605 |
+
format.date "year" output.check
|
| 606 |
+
new.block
|
| 607 |
+
note output
|
| 608 |
+
fin.entry
|
| 609 |
+
}
|
| 610 |
+
|
| 611 |
+
FUNCTION {booklet}
|
| 612 |
+
{ output.bibitem
|
| 613 |
+
format.authors output
|
| 614 |
+
new.block
|
| 615 |
+
format.title "title" output.check
|
| 616 |
+
howpublished address new.block.checkb
|
| 617 |
+
howpublished output
|
| 618 |
+
address output
|
| 619 |
+
format.date output
|
| 620 |
+
new.block
|
| 621 |
+
note output
|
| 622 |
+
fin.entry
|
| 623 |
+
}
|
| 624 |
+
|
| 625 |
+
FUNCTION {inbook}
|
| 626 |
+
{ output.bibitem
|
| 627 |
+
author empty$
|
| 628 |
+
{ format.editors "author and editor" output.check }
|
| 629 |
+
{ format.authors output.nonnull
|
| 630 |
+
|
| 631 |
+
crossref missing$
|
| 632 |
+
{ "author and editor" editor either.or.check }
|
| 633 |
+
'skip$
|
| 634 |
+
if$
|
| 635 |
+
}
|
| 636 |
+
if$
|
| 637 |
+
new.block
|
| 638 |
+
format.btitle "title" output.check
|
| 639 |
+
crossref missing$
|
| 640 |
+
{ format.bvolume output
|
| 641 |
+
format.chapter.pages "chapter and pages" output.check
|
| 642 |
+
new.block
|
| 643 |
+
format.number.series output
|
| 644 |
+
new.sentence
|
| 645 |
+
publisher "publisher" output.check
|
| 646 |
+
address output
|
| 647 |
+
}
|
| 648 |
+
{ format.chapter.pages "chapter and pages" output.check
|
| 649 |
+
new.block
|
| 650 |
+
format.book.crossref output.nonnull
|
| 651 |
+
}
|
| 652 |
+
if$
|
| 653 |
+
format.edition output
|
| 654 |
+
format.date "year" output.check
|
| 655 |
+
new.block
|
| 656 |
+
note output
|
| 657 |
+
fin.entry
|
| 658 |
+
}
|
| 659 |
+
|
| 660 |
+
FUNCTION {incollection}
|
| 661 |
+
{ output.bibitem
|
| 662 |
+
format.authors "author" output.check
|
| 663 |
+
new.block
|
| 664 |
+
format.title "title" output.check
|
| 665 |
+
new.block
|
| 666 |
+
crossref missing$
|
| 667 |
+
{ format.in.ed.booktitle "booktitle" output.check
|
| 668 |
+
format.bvolume output
|
| 669 |
+
format.number.series output
|
| 670 |
+
format.chapter.pages output
|
| 671 |
+
new.sentence
|
| 672 |
+
publisher "publisher" output.check
|
| 673 |
+
address output
|
| 674 |
+
format.edition output
|
| 675 |
+
format.date "year" output.check
|
| 676 |
+
}
|
| 677 |
+
{ format.incoll.inproc.crossref output.nonnull
|
| 678 |
+
format.chapter.pages output
|
| 679 |
+
}
|
| 680 |
+
if$
|
| 681 |
+
new.block
|
| 682 |
+
note output
|
| 683 |
+
fin.entry
|
| 684 |
+
}
|
| 685 |
+
|
| 686 |
+
FUNCTION {inproceedings}
|
| 687 |
+
{ output.bibitem
|
| 688 |
+
format.authors "author" output.check
|
| 689 |
+
new.block
|
| 690 |
+
format.title "title" output.check
|
| 691 |
+
new.block
|
| 692 |
+
crossref missing$
|
| 693 |
+
{ format.in.ed.booktitle "booktitle" output.check
|
| 694 |
+
format.bvolume output
|
| 695 |
+
format.number.series output
|
| 696 |
+
format.pages output
|
| 697 |
+
address empty$
|
| 698 |
+
{ organization publisher new.sentence.checkb
|
| 699 |
+
organization output
|
| 700 |
+
publisher output
|
| 701 |
+
format.date "year" output.check
|
| 702 |
+
}
|
| 703 |
+
{ address output.nonnull
|
| 704 |
+
format.date "year" output.check
|
| 705 |
+
new.sentence
|
| 706 |
+
organization output
|
| 707 |
+
publisher output
|
| 708 |
+
}
|
| 709 |
+
if$
|
| 710 |
+
}
|
| 711 |
+
{ format.incoll.inproc.crossref output.nonnull
|
| 712 |
+
format.pages output
|
| 713 |
+
}
|
| 714 |
+
if$
|
| 715 |
+
new.block
|
| 716 |
+
note output
|
| 717 |
+
fin.entry
|
| 718 |
+
}
|
| 719 |
+
|
| 720 |
+
FUNCTION {conference} { inproceedings }
|
| 721 |
+
|
| 722 |
+
FUNCTION {manual}
|
| 723 |
+
{ output.bibitem
|
| 724 |
+
author empty$
|
| 725 |
+
{ organization empty$
|
| 726 |
+
'skip$
|
| 727 |
+
{ organization output.nonnull
|
| 728 |
+
address output
|
| 729 |
+
}
|
| 730 |
+
if$
|
| 731 |
+
}
|
| 732 |
+
{ format.authors output.nonnull }
|
| 733 |
+
if$
|
| 734 |
+
new.block
|
| 735 |
+
format.btitle "title" output.check
|
| 736 |
+
author empty$
|
| 737 |
+
{ organization empty$
|
| 738 |
+
{ address new.block.checka
|
| 739 |
+
address output
|
| 740 |
+
}
|
| 741 |
+
'skip$
|
| 742 |
+
if$
|
| 743 |
+
}
|
| 744 |
+
{ organization address new.block.checkb
|
| 745 |
+
organization output
|
| 746 |
+
address output
|
| 747 |
+
}
|
| 748 |
+
if$
|
| 749 |
+
format.edition output
|
| 750 |
+
format.date output
|
| 751 |
+
new.block
|
| 752 |
+
note output
|
| 753 |
+
fin.entry
|
| 754 |
+
}
|
| 755 |
+
|
| 756 |
+
FUNCTION {mastersthesis}
|
| 757 |
+
{ output.bibitem
|
| 758 |
+
format.authors "author" output.check
|
| 759 |
+
new.block
|
| 760 |
+
format.title "title" output.check
|
| 761 |
+
new.block
|
| 762 |
+
"Master's thesis" format.thesis.type output.nonnull
|
| 763 |
+
school "school" output.check
|
| 764 |
+
address output
|
| 765 |
+
format.date "year" output.check
|
| 766 |
+
new.block
|
| 767 |
+
note output
|
| 768 |
+
fin.entry
|
| 769 |
+
}
|
| 770 |
+
|
| 771 |
+
FUNCTION {misc}
|
| 772 |
+
{ output.bibitem
|
| 773 |
+
format.authors output
|
| 774 |
+
title howpublished new.block.checkb
|
| 775 |
+
format.title output
|
| 776 |
+
howpublished new.block.checka
|
| 777 |
+
howpublished output
|
| 778 |
+
format.date output
|
| 779 |
+
new.block
|
| 780 |
+
note output
|
| 781 |
+
fin.entry
|
| 782 |
+
empty.misc.check
|
| 783 |
+
}
|
| 784 |
+
|
| 785 |
+
FUNCTION {phdthesis}
|
| 786 |
+
{ output.bibitem
|
| 787 |
+
format.authors "author" output.check
|
| 788 |
+
new.block
|
| 789 |
+
format.btitle "title" output.check
|
| 790 |
+
new.block
|
| 791 |
+
"PhD thesis" format.thesis.type output.nonnull
|
| 792 |
+
school "school" output.check
|
| 793 |
+
address output
|
| 794 |
+
format.date "year" output.check
|
| 795 |
+
new.block
|
| 796 |
+
note output
|
| 797 |
+
fin.entry
|
| 798 |
+
}
|
| 799 |
+
|
| 800 |
+
FUNCTION {proceedings}
|
| 801 |
+
{ output.bibitem
|
| 802 |
+
editor empty$
|
| 803 |
+
{ organization output }
|
| 804 |
+
{ format.editors output.nonnull }
|
| 805 |
+
|
| 806 |
+
if$
|
| 807 |
+
new.block
|
| 808 |
+
format.btitle "title" output.check
|
| 809 |
+
format.bvolume output
|
| 810 |
+
format.number.series output
|
| 811 |
+
address empty$
|
| 812 |
+
{ editor empty$
|
| 813 |
+
{ publisher new.sentence.checka }
|
| 814 |
+
{ organization publisher new.sentence.checkb
|
| 815 |
+
organization output
|
| 816 |
+
}
|
| 817 |
+
if$
|
| 818 |
+
publisher output
|
| 819 |
+
format.date "year" output.check
|
| 820 |
+
}
|
| 821 |
+
{ address output.nonnull
|
| 822 |
+
format.date "year" output.check
|
| 823 |
+
new.sentence
|
| 824 |
+
editor empty$
|
| 825 |
+
'skip$
|
| 826 |
+
{ organization output }
|
| 827 |
+
if$
|
| 828 |
+
publisher output
|
| 829 |
+
}
|
| 830 |
+
if$
|
| 831 |
+
new.block
|
| 832 |
+
note output
|
| 833 |
+
fin.entry
|
| 834 |
+
}
|
| 835 |
+
|
| 836 |
+
FUNCTION {techreport}
|
| 837 |
+
{ output.bibitem
|
| 838 |
+
format.authors "author" output.check
|
| 839 |
+
new.block
|
| 840 |
+
format.title "title" output.check
|
| 841 |
+
new.block
|
| 842 |
+
format.tr.number output.nonnull
|
| 843 |
+
institution "institution" output.check
|
| 844 |
+
address output
|
| 845 |
+
format.date "year" output.check
|
| 846 |
+
new.block
|
| 847 |
+
note output
|
| 848 |
+
fin.entry
|
| 849 |
+
}
|
| 850 |
+
|
| 851 |
+
FUNCTION {unpublished}
|
| 852 |
+
{ output.bibitem
|
| 853 |
+
format.authors "author" output.check
|
| 854 |
+
new.block
|
| 855 |
+
format.title "title" output.check
|
| 856 |
+
new.block
|
| 857 |
+
note "note" output.check
|
| 858 |
+
format.date output
|
| 859 |
+
fin.entry
|
| 860 |
+
}
|
| 861 |
+
|
| 862 |
+
FUNCTION {default.type} { misc }
|
| 863 |
+
|
| 864 |
+
MACRO {jan} {"Jan."}
|
| 865 |
+
|
| 866 |
+
MACRO {feb} {"Feb."}
|
| 867 |
+
|
| 868 |
+
MACRO {mar} {"Mar."}
|
| 869 |
+
|
| 870 |
+
MACRO {apr} {"Apr."}
|
| 871 |
+
|
| 872 |
+
MACRO {may} {"May"}
|
| 873 |
+
|
| 874 |
+
MACRO {jun} {"June"}
|
| 875 |
+
|
| 876 |
+
MACRO {jul} {"July"}
|
| 877 |
+
|
| 878 |
+
MACRO {aug} {"Aug."}
|
| 879 |
+
|
| 880 |
+
MACRO {sep} {"Sept."}
|
| 881 |
+
|
| 882 |
+
MACRO {oct} {"Oct."}
|
| 883 |
+
|
| 884 |
+
MACRO {nov} {"Nov."}
|
| 885 |
+
|
| 886 |
+
MACRO {dec} {"Dec."}
|
| 887 |
+
|
| 888 |
+
MACRO {acmcs} {"ACM Comput. Surv."}
|
| 889 |
+
|
| 890 |
+
MACRO {acta} {"Acta Inf."}
|
| 891 |
+
|
| 892 |
+
MACRO {cacm} {"Commun. ACM"}
|
| 893 |
+
|
| 894 |
+
MACRO {ibmjrd} {"IBM J. Res. Dev."}
|
| 895 |
+
|
| 896 |
+
MACRO {ibmsj} {"IBM Syst.~J."}
|
| 897 |
+
|
| 898 |
+
MACRO {ieeese} {"IEEE Trans. Softw. Eng."}
|
| 899 |
+
|
| 900 |
+
MACRO {ieeetc} {"IEEE Trans. Comput."}
|
| 901 |
+
|
| 902 |
+
MACRO {ieeetcad}
|
| 903 |
+
{"IEEE Trans. Comput.-Aided Design Integrated Circuits"}
|
| 904 |
+
|
| 905 |
+
MACRO {ipl} {"Inf. Process. Lett."}
|
| 906 |
+
|
| 907 |
+
MACRO {jacm} {"J.~ACM"}
|
| 908 |
+
|
| 909 |
+
MACRO {jcss} {"J.~Comput. Syst. Sci."}
|
| 910 |
+
|
| 911 |
+
MACRO {scp} {"Sci. Comput. Programming"}
|
| 912 |
+
|
| 913 |
+
MACRO {sicomp} {"SIAM J. Comput."}
|
| 914 |
+
|
| 915 |
+
MACRO {tocs} {"ACM Trans. Comput. Syst."}
|
| 916 |
+
|
| 917 |
+
MACRO {tods} {"ACM Trans. Database Syst."}
|
| 918 |
+
|
| 919 |
+
MACRO {tog} {"ACM Trans. Gr."}
|
| 920 |
+
|
| 921 |
+
MACRO {toms} {"ACM Trans. Math. Softw."}
|
| 922 |
+
|
| 923 |
+
MACRO {toois} {"ACM Trans. Office Inf. Syst."}
|
| 924 |
+
|
| 925 |
+
MACRO {toplas} {"ACM Trans. Prog. Lang. Syst."}
|
| 926 |
+
|
| 927 |
+
MACRO {tcs} {"Theoretical Comput. Sci."}
|
| 928 |
+
|
| 929 |
+
READ
|
| 930 |
+
|
| 931 |
+
FUNCTION {sortify}
|
| 932 |
+
{ purify$
|
| 933 |
+
"l" change.case$
|
| 934 |
+
}
|
| 935 |
+
|
| 936 |
+
INTEGERS { len }
|
| 937 |
+
|
| 938 |
+
FUNCTION {chop.word}
|
| 939 |
+
{ 's :=
|
| 940 |
+
'len :=
|
| 941 |
+
s #1 len substring$ =
|
| 942 |
+
{ s len #1 + global.max$ substring$ }
|
| 943 |
+
's
|
| 944 |
+
if$
|
| 945 |
+
}
|
| 946 |
+
|
| 947 |
+
FUNCTION {sort.format.names}
|
| 948 |
+
{ 's :=
|
| 949 |
+
#1 'nameptr :=
|
| 950 |
+
""
|
| 951 |
+
s num.names$ 'numnames :=
|
| 952 |
+
numnames 'namesleft :=
|
| 953 |
+
{ namesleft #0 > }
|
| 954 |
+
{ nameptr #1 >
|
| 955 |
+
{ " " * }
|
| 956 |
+
'skip$
|
| 957 |
+
if$
|
| 958 |
+
s nameptr "{vv{ } }{ll{ }}{ f{ }}{ jj{ }}" format.name$ 't :=
|
| 959 |
+
nameptr numnames = t "others" = and
|
| 960 |
+
{ "et al" * }
|
| 961 |
+
{ t sortify * }
|
| 962 |
+
if$
|
| 963 |
+
nameptr #1 + 'nameptr :=
|
| 964 |
+
namesleft #1 - 'namesleft :=
|
| 965 |
+
}
|
| 966 |
+
while$
|
| 967 |
+
}
|
| 968 |
+
|
| 969 |
+
FUNCTION {sort.format.title}
|
| 970 |
+
{ 't :=
|
| 971 |
+
"A " #2
|
| 972 |
+
"An " #3
|
| 973 |
+
"The " #4 t chop.word
|
| 974 |
+
chop.word
|
| 975 |
+
chop.word
|
| 976 |
+
sortify
|
| 977 |
+
#1 global.max$ substring$
|
| 978 |
+
}
|
| 979 |
+
|
| 980 |
+
FUNCTION {author.sort}
|
| 981 |
+
{ author empty$
|
| 982 |
+
{ key empty$
|
| 983 |
+
{ "to sort, need author or key in " cite$ * warning$
|
| 984 |
+
""
|
| 985 |
+
}
|
| 986 |
+
{ key sortify }
|
| 987 |
+
if$
|
| 988 |
+
}
|
| 989 |
+
{ author sort.format.names }
|
| 990 |
+
if$
|
| 991 |
+
}
|
| 992 |
+
|
| 993 |
+
FUNCTION {author.editor.sort}
|
| 994 |
+
{ author empty$
|
| 995 |
+
{ editor empty$
|
| 996 |
+
{ key empty$
|
| 997 |
+
{ "to sort, need author, editor, or key in " cite$ * warning$
|
| 998 |
+
""
|
| 999 |
+
}
|
| 1000 |
+
{ key sortify }
|
| 1001 |
+
if$
|
| 1002 |
+
}
|
| 1003 |
+
{ editor sort.format.names }
|
| 1004 |
+
if$
|
| 1005 |
+
}
|
| 1006 |
+
{ author sort.format.names }
|
| 1007 |
+
if$
|
| 1008 |
+
}
|
| 1009 |
+
|
| 1010 |
+
FUNCTION {author.organization.sort}
|
| 1011 |
+
{ author empty$
|
| 1012 |
+
|
| 1013 |
+
{ organization empty$
|
| 1014 |
+
{ key empty$
|
| 1015 |
+
{ "to sort, need author, organization, or key in " cite$ * warning$
|
| 1016 |
+
""
|
| 1017 |
+
}
|
| 1018 |
+
{ key sortify }
|
| 1019 |
+
if$
|
| 1020 |
+
}
|
| 1021 |
+
{ "The " #4 organization chop.word sortify }
|
| 1022 |
+
if$
|
| 1023 |
+
}
|
| 1024 |
+
{ author sort.format.names }
|
| 1025 |
+
if$
|
| 1026 |
+
}
|
| 1027 |
+
|
| 1028 |
+
FUNCTION {editor.organization.sort}
|
| 1029 |
+
{ editor empty$
|
| 1030 |
+
{ organization empty$
|
| 1031 |
+
{ key empty$
|
| 1032 |
+
{ "to sort, need editor, organization, or key in " cite$ * warning$
|
| 1033 |
+
""
|
| 1034 |
+
}
|
| 1035 |
+
{ key sortify }
|
| 1036 |
+
if$
|
| 1037 |
+
}
|
| 1038 |
+
{ "The " #4 organization chop.word sortify }
|
| 1039 |
+
if$
|
| 1040 |
+
}
|
| 1041 |
+
{ editor sort.format.names }
|
| 1042 |
+
if$
|
| 1043 |
+
}
|
| 1044 |
+
|
| 1045 |
+
FUNCTION {presort}
|
| 1046 |
+
{ type$ "book" =
|
| 1047 |
+
type$ "inbook" =
|
| 1048 |
+
or
|
| 1049 |
+
'author.editor.sort
|
| 1050 |
+
{ type$ "proceedings" =
|
| 1051 |
+
'editor.organization.sort
|
| 1052 |
+
{ type$ "manual" =
|
| 1053 |
+
'author.organization.sort
|
| 1054 |
+
'author.sort
|
| 1055 |
+
if$
|
| 1056 |
+
}
|
| 1057 |
+
if$
|
| 1058 |
+
}
|
| 1059 |
+
if$
|
| 1060 |
+
" "
|
| 1061 |
+
*
|
| 1062 |
+
year field.or.null sortify
|
| 1063 |
+
*
|
| 1064 |
+
" "
|
| 1065 |
+
*
|
| 1066 |
+
title field.or.null
|
| 1067 |
+
sort.format.title
|
| 1068 |
+
*
|
| 1069 |
+
#1 entry.max$ substring$
|
| 1070 |
+
'sort.key$ :=
|
| 1071 |
+
}
|
| 1072 |
+
|
| 1073 |
+
ITERATE {presort}
|
| 1074 |
+
|
| 1075 |
+
SORT
|
| 1076 |
+
|
| 1077 |
+
STRINGS { longest.label }
|
| 1078 |
+
|
| 1079 |
+
INTEGERS { number.label longest.label.width }
|
| 1080 |
+
|
| 1081 |
+
FUNCTION {initialize.longest.label}
|
| 1082 |
+
{ "" 'longest.label :=
|
| 1083 |
+
#1 'number.label :=
|
| 1084 |
+
#0 'longest.label.width :=
|
| 1085 |
+
}
|
| 1086 |
+
|
| 1087 |
+
FUNCTION {longest.label.pass}
|
| 1088 |
+
{ number.label int.to.str$ 'label :=
|
| 1089 |
+
number.label #1 + 'number.label :=
|
| 1090 |
+
label width$ longest.label.width >
|
| 1091 |
+
{ label 'longest.label :=
|
| 1092 |
+
label width$ 'longest.label.width :=
|
| 1093 |
+
}
|
| 1094 |
+
'skip$
|
| 1095 |
+
if$
|
| 1096 |
+
}
|
| 1097 |
+
|
| 1098 |
+
EXECUTE {initialize.longest.label}
|
| 1099 |
+
|
| 1100 |
+
ITERATE {longest.label.pass}
|
| 1101 |
+
|
| 1102 |
+
FUNCTION {begin.bib}
|
| 1103 |
+
{ preamble$ empty$
|
| 1104 |
+
'skip$
|
| 1105 |
+
{ preamble$ write$ newline$ }
|
| 1106 |
+
if$
|
| 1107 |
+
"\begin{thebibliography}{" longest.label * "}" *
|
| 1108 |
+
"\itemsep=-1pt" * % Compact the entries a little.
|
| 1109 |
+
write$ newline$
|
| 1110 |
+
}
|
| 1111 |
+
|
| 1112 |
+
EXECUTE {begin.bib}
|
| 1113 |
+
|
| 1114 |
+
EXECUTE {init.state.consts}
|
| 1115 |
+
|
| 1116 |
+
ITERATE {call.type$}
|
| 1117 |
+
|
| 1118 |
+
FUNCTION {end.bib}
|
| 1119 |
+
{ newline$
|
| 1120 |
+
"\end{thebibliography}" write$ newline$
|
| 1121 |
+
}
|
| 1122 |
+
|
| 1123 |
+
EXECUTE {end.bib}
|
| 1124 |
+
|
| 1125 |
+
% end of file ieee.bst
|
| 1126 |
+
% ---------------------------------------------------------------
|
| 1127 |
+
|
| 1128 |
+
|
| 1129 |
+
|
download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/residual_v1_arxiv_release.bbl
ADDED
|
@@ -0,0 +1,273 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
\begin{thebibliography}{10}\itemsep=-1pt
|
| 2 |
+
|
| 3 |
+
\bibitem{Bengio1994}
|
| 4 |
+
Y.~Bengio, P.~Simard, and P.~Frasconi.
|
| 5 |
+
\newblock Learning long-term dependencies with gradient descent is difficult.
|
| 6 |
+
\newblock {\em IEEE Transactions on Neural Networks}, 5(2):157--166, 1994.
|
| 7 |
+
|
| 8 |
+
\bibitem{Bishop1995}
|
| 9 |
+
C.~M. Bishop.
|
| 10 |
+
\newblock {\em Neural networks for pattern recognition}.
|
| 11 |
+
\newblock Oxford university press, 1995.
|
| 12 |
+
|
| 13 |
+
\bibitem{Briggs2000}
|
| 14 |
+
W.~L. Briggs, S.~F. McCormick, et~al.
|
| 15 |
+
\newblock {\em {A Multigrid Tutorial}}.
|
| 16 |
+
\newblock Siam, 2000.
|
| 17 |
+
|
| 18 |
+
\bibitem{Chatfield2011}
|
| 19 |
+
K.~Chatfield, V.~Lempitsky, A.~Vedaldi, and A.~Zisserman.
|
| 20 |
+
\newblock The devil is in the details: an evaluation of recent feature encoding
|
| 21 |
+
methods.
|
| 22 |
+
\newblock In {\em BMVC}, 2011.
|
| 23 |
+
|
| 24 |
+
\bibitem{Everingham2010}
|
| 25 |
+
M.~Everingham, L.~Van~Gool, C.~K. Williams, J.~Winn, and A.~Zisserman.
|
| 26 |
+
\newblock {The Pascal Visual Object Classes (VOC) Challenge}.
|
| 27 |
+
\newblock {\em IJCV}, pages 303--338, 2010.
|
| 28 |
+
|
| 29 |
+
\bibitem{Gidaris2015}
|
| 30 |
+
S.~Gidaris and N.~Komodakis.
|
| 31 |
+
\newblock Object detection via a multi-region \& semantic segmentation-aware
|
| 32 |
+
cnn model.
|
| 33 |
+
\newblock In {\em ICCV}, 2015.
|
| 34 |
+
|
| 35 |
+
\bibitem{Girshick2015}
|
| 36 |
+
R.~Girshick.
|
| 37 |
+
\newblock {Fast R-CNN}.
|
| 38 |
+
\newblock In {\em ICCV}, 2015.
|
| 39 |
+
|
| 40 |
+
\bibitem{Girshick2014}
|
| 41 |
+
R.~Girshick, J.~Donahue, T.~Darrell, and J.~Malik.
|
| 42 |
+
\newblock Rich feature hierarchies for accurate object detection and semantic
|
| 43 |
+
segmentation.
|
| 44 |
+
\newblock In {\em CVPR}, 2014.
|
| 45 |
+
|
| 46 |
+
\bibitem{Glorot2010}
|
| 47 |
+
X.~Glorot and Y.~Bengio.
|
| 48 |
+
\newblock Understanding the difficulty of training deep feedforward neural
|
| 49 |
+
networks.
|
| 50 |
+
\newblock In {\em AISTATS}, 2010.
|
| 51 |
+
|
| 52 |
+
\bibitem{Goodfellow2013}
|
| 53 |
+
I.~J. Goodfellow, D.~Warde-Farley, M.~Mirza, A.~Courville, and Y.~Bengio.
|
| 54 |
+
\newblock Maxout networks.
|
| 55 |
+
\newblock {\em arXiv:1302.4389}, 2013.
|
| 56 |
+
|
| 57 |
+
\bibitem{He2015a}
|
| 58 |
+
K.~He and J.~Sun.
|
| 59 |
+
\newblock Convolutional neural networks at constrained time cost.
|
| 60 |
+
\newblock In {\em CVPR}, 2015.
|
| 61 |
+
|
| 62 |
+
\bibitem{He2014}
|
| 63 |
+
K.~He, X.~Zhang, S.~Ren, and J.~Sun.
|
| 64 |
+
\newblock Spatial pyramid pooling in deep convolutional networks for visual
|
| 65 |
+
recognition.
|
| 66 |
+
\newblock In {\em ECCV}, 2014.
|
| 67 |
+
|
| 68 |
+
\bibitem{He2015}
|
| 69 |
+
K.~He, X.~Zhang, S.~Ren, and J.~Sun.
|
| 70 |
+
\newblock Delving deep into rectifiers: Surpassing human-level performance on
|
| 71 |
+
imagenet classification.
|
| 72 |
+
\newblock In {\em ICCV}, 2015.
|
| 73 |
+
|
| 74 |
+
\bibitem{Hinton2012}
|
| 75 |
+
G.~E. Hinton, N.~Srivastava, A.~Krizhevsky, I.~Sutskever, and R.~R.
|
| 76 |
+
Salakhutdinov.
|
| 77 |
+
\newblock Improving neural networks by preventing co-adaptation of feature
|
| 78 |
+
detectors.
|
| 79 |
+
\newblock {\em arXiv:1207.0580}, 2012.
|
| 80 |
+
|
| 81 |
+
\bibitem{Hochreiter1997}
|
| 82 |
+
S.~Hochreiter and J.~Schmidhuber.
|
| 83 |
+
\newblock Long short-term memory.
|
| 84 |
+
\newblock {\em Neural computation}, 9(8):1735--1780, 1997.
|
| 85 |
+
|
| 86 |
+
\bibitem{Ioffe2015}
|
| 87 |
+
S.~Ioffe and C.~Szegedy.
|
| 88 |
+
\newblock Batch normalization: Accelerating deep network training by reducing
|
| 89 |
+
internal covariate shift.
|
| 90 |
+
\newblock In {\em ICML}, 2015.
|
| 91 |
+
|
| 92 |
+
\bibitem{Jegou2011}
|
| 93 |
+
H.~Jegou, M.~Douze, and C.~Schmid.
|
| 94 |
+
\newblock Product quantization for nearest neighbor search.
|
| 95 |
+
\newblock {\em TPAMI}, 33, 2011.
|
| 96 |
+
|
| 97 |
+
\bibitem{Jegou2012}
|
| 98 |
+
H.~Jegou, F.~Perronnin, M.~Douze, J.~Sanchez, P.~Perez, and C.~Schmid.
|
| 99 |
+
\newblock Aggregating local image descriptors into compact codes.
|
| 100 |
+
\newblock {\em TPAMI}, 2012.
|
| 101 |
+
|
| 102 |
+
\bibitem{Jia2014}
|
| 103 |
+
Y.~Jia, E.~Shelhamer, J.~Donahue, S.~Karayev, J.~Long, R.~Girshick,
|
| 104 |
+
S.~Guadarrama, and T.~Darrell.
|
| 105 |
+
\newblock Caffe: Convolutional architecture for fast feature embedding.
|
| 106 |
+
\newblock {\em arXiv:1408.5093}, 2014.
|
| 107 |
+
|
| 108 |
+
\bibitem{Krizhevsky2009}
|
| 109 |
+
A.~Krizhevsky.
|
| 110 |
+
\newblock Learning multiple layers of features from tiny images.
|
| 111 |
+
\newblock {\em Tech Report}, 2009.
|
| 112 |
+
|
| 113 |
+
\bibitem{Krizhevsky2012}
|
| 114 |
+
A.~Krizhevsky, I.~Sutskever, and G.~Hinton.
|
| 115 |
+
\newblock Imagenet classification with deep convolutional neural networks.
|
| 116 |
+
\newblock In {\em NIPS}, 2012.
|
| 117 |
+
|
| 118 |
+
\bibitem{LeCun1989}
|
| 119 |
+
Y.~LeCun, B.~Boser, J.~S. Denker, D.~Henderson, R.~E. Howard, W.~Hubbard, and
|
| 120 |
+
L.~D. Jackel.
|
| 121 |
+
\newblock Backpropagation applied to handwritten zip code recognition.
|
| 122 |
+
\newblock {\em Neural computation}, 1989.
|
| 123 |
+
|
| 124 |
+
\bibitem{LeCun1998}
|
| 125 |
+
Y.~LeCun, L.~Bottou, G.~B. Orr, and K.-R. M{\"u}ller.
|
| 126 |
+
\newblock Efficient backprop.
|
| 127 |
+
\newblock In {\em Neural Networks: Tricks of the Trade}, pages 9--50. Springer,
|
| 128 |
+
1998.
|
| 129 |
+
|
| 130 |
+
\bibitem{Lee2014}
|
| 131 |
+
C.-Y. Lee, S.~Xie, P.~Gallagher, Z.~Zhang, and Z.~Tu.
|
| 132 |
+
\newblock Deeply-supervised nets.
|
| 133 |
+
\newblock {\em arXiv:1409.5185}, 2014.
|
| 134 |
+
|
| 135 |
+
\bibitem{Lin2013}
|
| 136 |
+
M.~Lin, Q.~Chen, and S.~Yan.
|
| 137 |
+
\newblock Network in network.
|
| 138 |
+
\newblock {\em arXiv:1312.4400}, 2013.
|
| 139 |
+
|
| 140 |
+
\bibitem{Lin2014}
|
| 141 |
+
T.-Y. Lin, M.~Maire, S.~Belongie, J.~Hays, P.~Perona, D.~Ramanan,
|
| 142 |
+
P.~Doll{\'a}r, and C.~L. Zitnick.
|
| 143 |
+
\newblock {Microsoft COCO: Common objects in context}.
|
| 144 |
+
\newblock In {\em ECCV}. 2014.
|
| 145 |
+
|
| 146 |
+
\bibitem{Long2015}
|
| 147 |
+
J.~Long, E.~Shelhamer, and T.~Darrell.
|
| 148 |
+
\newblock Fully convolutional networks for semantic segmentation.
|
| 149 |
+
\newblock In {\em CVPR}, 2015.
|
| 150 |
+
|
| 151 |
+
\bibitem{Montufar2014}
|
| 152 |
+
G.~Mont{\'u}far, R.~Pascanu, K.~Cho, and Y.~Bengio.
|
| 153 |
+
\newblock On the number of linear regions of deep neural networks.
|
| 154 |
+
\newblock In {\em NIPS}, 2014.
|
| 155 |
+
|
| 156 |
+
\bibitem{Nair2010}
|
| 157 |
+
V.~Nair and G.~E. Hinton.
|
| 158 |
+
\newblock Rectified linear units improve restricted boltzmann machines.
|
| 159 |
+
\newblock In {\em ICML}, 2010.
|
| 160 |
+
|
| 161 |
+
\bibitem{Perronnin2007}
|
| 162 |
+
F.~Perronnin and C.~Dance.
|
| 163 |
+
\newblock Fisher kernels on visual vocabularies for image categorization.
|
| 164 |
+
\newblock In {\em CVPR}, 2007.
|
| 165 |
+
|
| 166 |
+
\bibitem{Raiko2012}
|
| 167 |
+
T.~Raiko, H.~Valpola, and Y.~LeCun.
|
| 168 |
+
\newblock Deep learning made easier by linear transformations in perceptrons.
|
| 169 |
+
\newblock In {\em AISTATS}, 2012.
|
| 170 |
+
|
| 171 |
+
\bibitem{Ren2015}
|
| 172 |
+
S.~Ren, K.~He, R.~Girshick, and J.~Sun.
|
| 173 |
+
\newblock {Faster R-CNN}: Towards real-time object detection with region
|
| 174 |
+
proposal networks.
|
| 175 |
+
\newblock In {\em NIPS}, 2015.
|
| 176 |
+
|
| 177 |
+
\bibitem{Ren2015a}
|
| 178 |
+
S.~Ren, K.~He, R.~Girshick, X.~Zhang, and J.~Sun.
|
| 179 |
+
\newblock Object detection networks on convolutional feature maps.
|
| 180 |
+
\newblock {\em arXiv:1504.06066}, 2015.
|
| 181 |
+
|
| 182 |
+
\bibitem{Ripley1996}
|
| 183 |
+
B.~D. Ripley.
|
| 184 |
+
\newblock {\em Pattern recognition and neural networks}.
|
| 185 |
+
\newblock Cambridge university press, 1996.
|
| 186 |
+
|
| 187 |
+
\bibitem{Romero2015}
|
| 188 |
+
A.~Romero, N.~Ballas, S.~E. Kahou, A.~Chassang, C.~Gatta, and Y.~Bengio.
|
| 189 |
+
\newblock Fitnets: Hints for thin deep nets.
|
| 190 |
+
\newblock In {\em ICLR}, 2015.
|
| 191 |
+
|
| 192 |
+
\bibitem{Russakovsky2014}
|
| 193 |
+
O.~Russakovsky, J.~Deng, H.~Su, J.~Krause, S.~Satheesh, S.~Ma, Z.~Huang,
|
| 194 |
+
A.~Karpathy, A.~Khosla, M.~Bernstein, et~al.
|
| 195 |
+
\newblock Imagenet large scale visual recognition challenge.
|
| 196 |
+
\newblock {\em arXiv:1409.0575}, 2014.
|
| 197 |
+
|
| 198 |
+
\bibitem{Saxe2013}
|
| 199 |
+
A.~M. Saxe, J.~L. McClelland, and S.~Ganguli.
|
| 200 |
+
\newblock Exact solutions to the nonlinear dynamics of learning in deep linear
|
| 201 |
+
neural networks.
|
| 202 |
+
\newblock {\em arXiv:1312.6120}, 2013.
|
| 203 |
+
|
| 204 |
+
\bibitem{Schraudolph1998a}
|
| 205 |
+
N.~N. Schraudolph.
|
| 206 |
+
\newblock Accelerated gradient descent by factor-centering decomposition.
|
| 207 |
+
\newblock Technical report, 1998.
|
| 208 |
+
|
| 209 |
+
\bibitem{Schraudolph1998}
|
| 210 |
+
N.~N. Schraudolph.
|
| 211 |
+
\newblock Centering neural network gradient factors.
|
| 212 |
+
\newblock In {\em Neural Networks: Tricks of the Trade}, pages 207--226.
|
| 213 |
+
Springer, 1998.
|
| 214 |
+
|
| 215 |
+
\bibitem{Sermanet2014}
|
| 216 |
+
P.~Sermanet, D.~Eigen, X.~Zhang, M.~Mathieu, R.~Fergus, and Y.~LeCun.
|
| 217 |
+
\newblock Overfeat: Integrated recognition, localization and detection using
|
| 218 |
+
convolutional networks.
|
| 219 |
+
\newblock In {\em ICLR}, 2014.
|
| 220 |
+
|
| 221 |
+
\bibitem{Simonyan2015}
|
| 222 |
+
K.~Simonyan and A.~Zisserman.
|
| 223 |
+
\newblock Very deep convolutional networks for large-scale image recognition.
|
| 224 |
+
\newblock In {\em ICLR}, 2015.
|
| 225 |
+
|
| 226 |
+
\bibitem{Srivastava2015}
|
| 227 |
+
R.~K. Srivastava, K.~Greff, and J.~Schmidhuber.
|
| 228 |
+
\newblock Highway networks.
|
| 229 |
+
\newblock {\em arXiv:1505.00387}, 2015.
|
| 230 |
+
|
| 231 |
+
\bibitem{Srivastava2015a}
|
| 232 |
+
R.~K. Srivastava, K.~Greff, and J.~Schmidhuber.
|
| 233 |
+
\newblock Training very deep networks.
|
| 234 |
+
\newblock {\em 1507.06228}, 2015.
|
| 235 |
+
|
| 236 |
+
\bibitem{Szegedy2015}
|
| 237 |
+
C.~Szegedy, W.~Liu, Y.~Jia, P.~Sermanet, S.~Reed, D.~Anguelov, D.~Erhan,
|
| 238 |
+
V.~Vanhoucke, and A.~Rabinovich.
|
| 239 |
+
\newblock Going deeper with convolutions.
|
| 240 |
+
\newblock In {\em CVPR}, 2015.
|
| 241 |
+
|
| 242 |
+
\bibitem{Szeliski1990}
|
| 243 |
+
R.~Szeliski.
|
| 244 |
+
\newblock Fast surface interpolation using hierarchical basis functions.
|
| 245 |
+
\newblock {\em TPAMI}, 1990.
|
| 246 |
+
|
| 247 |
+
\bibitem{Szeliski2006}
|
| 248 |
+
R.~Szeliski.
|
| 249 |
+
\newblock Locally adapted hierarchical basis preconditioning.
|
| 250 |
+
\newblock In {\em SIGGRAPH}, 2006.
|
| 251 |
+
|
| 252 |
+
\bibitem{Vatanen2013}
|
| 253 |
+
T.~Vatanen, T.~Raiko, H.~Valpola, and Y.~LeCun.
|
| 254 |
+
\newblock Pushing stochastic gradient towards second-order
|
| 255 |
+
methods--backpropagation learning with transformations in nonlinearities.
|
| 256 |
+
\newblock In {\em Neural Information Processing}, 2013.
|
| 257 |
+
|
| 258 |
+
\bibitem{Vedaldi2008}
|
| 259 |
+
A.~Vedaldi and B.~Fulkerson.
|
| 260 |
+
\newblock {VLFeat}: An open and portable library of computer vision algorithms,
|
| 261 |
+
2008.
|
| 262 |
+
|
| 263 |
+
\bibitem{Venables1999}
|
| 264 |
+
W.~Venables and B.~Ripley.
|
| 265 |
+
\newblock Modern applied statistics with s-plus.
|
| 266 |
+
\newblock 1999.
|
| 267 |
+
|
| 268 |
+
\bibitem{Zeiler2014}
|
| 269 |
+
M.~D. Zeiler and R.~Fergus.
|
| 270 |
+
\newblock Visualizing and understanding convolutional neural networks.
|
| 271 |
+
\newblock In {\em ECCV}, 2014.
|
| 272 |
+
|
| 273 |
+
\end{thebibliography}
|
download/20230719163556/output/Deep-Residual-Learning-for-Image-Recognition/residual_v1_arxiv_release.tex
ADDED
|
@@ -0,0 +1,909 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
\documentclass[10pt,twocolumn,letterpaper]{article}
|
| 2 |
+
|
| 3 |
+
\usepackage{cvpr}
|
| 4 |
+
\usepackage{times}
|
| 5 |
+
\usepackage{epsfig}
|
| 6 |
+
\usepackage{graphicx}
|
| 7 |
+
\usepackage{amsmath}
|
| 8 |
+
\usepackage{amssymb}
|
| 9 |
+
\usepackage{tabulary}
|
| 10 |
+
\usepackage{multirow}
|
| 11 |
+
|
| 12 |
+
\usepackage{soul}
|
| 13 |
+
|
| 14 |
+
% Include other packages here, before hyperref.
|
| 15 |
+
|
| 16 |
+
% If you comment hyperref and then uncomment it, you should delete
|
| 17 |
+
% egpaper.aux before re-running latex. (Or just hit 'q' on the first latex
|
| 18 |
+
% run, let it finish, and you should be clear).
|
| 19 |
+
\usepackage[bookmarks=false,colorlinks=true,linkcolor=black,citecolor=black,filecolor=black,urlcolor=black]{hyperref}
|
| 20 |
+
\usepackage[british,UKenglish,USenglish,english,american]{babel}
|
| 21 |
+
|
| 22 |
+
\cvprfinalcopy % *** Uncomment this line for the final submission
|
| 23 |
+
|
| 24 |
+
\newcommand{\ve}[1]{\mathbf{#1}} % for displaying a vector
|
| 25 |
+
\newcommand{\ma}[1]{\mathrm{#1}} % for displaying a matrix
|
| 26 |
+
|
| 27 |
+
\newcommand{\tabincell}[2]{\begin{tabular}{@{}#1@{}}#2\end{tabular}}
|
| 28 |
+
|
| 29 |
+
\renewcommand\arraystretch{1.2}
|
| 30 |
+
|
| 31 |
+
\def\httilde{\mbox{\tt\raisebox{-.5ex}{\symbol{126}}}}
|
| 32 |
+
|
| 33 |
+
\hyphenation{identity notorious underlying surpasses desired residual doubled}
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
% Pages are numbered in submission mode, and unnumbered in camera-ready
|
| 37 |
+
%\ifcvprfinal\pagestyle{empty}\fi
|
| 38 |
+
\setcounter{page}{1}
|
| 39 |
+
\begin{document}
|
| 40 |
+
|
| 41 |
+
%%%%%%%%% TITLE
|
| 42 |
+
\title{Deep Residual Learning for Image Recognition}
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
\author{Kaiming He \qquad Xiangyu Zhang \qquad Shaoqing Ren \qquad Jian Sun \\
|
| 47 |
+
\large Microsoft Research \vspace{-.2em}\\
|
| 48 |
+
\normalsize
|
| 49 |
+
\{kahe,~v-xiangz,~v-shren,~jiansun\}@microsoft.com
|
| 50 |
+
}
|
| 51 |
+
|
| 52 |
+
\maketitle
|
| 53 |
+
%\thispagestyle{empty}
|
| 54 |
+
|
| 55 |
+
%%%%%%%%% ABSTRACT
|
| 56 |
+
\begin{abstract}
|
| 57 |
+
\vspace{-.5em}
|
| 58 |
+
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth.
|
| 59 |
+
On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8$\times$ deeper than VGG nets \cite{Simonyan2015} but still having lower complexity.
|
| 60 |
+
An ensemble of these residual nets achieves 3.57\% error on the ImageNet \emph{test} set. This result won the 1st place on the ILSVRC 2015 classification task.
|
| 61 |
+
We also present analysis on CIFAR-10 with 100 and 1000 layers.
|
| 62 |
+
|
| 63 |
+
The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28\% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC \& COCO 2015 competitions\footnote{\fontsize{7.6pt}{1em}\selectfont \url{http://image-net.org/challenges/LSVRC/2015/} and \url{http://mscoco.org/dataset/\#detections-challenge2015}.}, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
|
| 64 |
+
\end{abstract}
|
| 65 |
+
|
| 66 |
+
% plain text
|
| 67 |
+
% Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
|
| 68 |
+
|
| 69 |
+
%The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
|
| 70 |
+
|
| 71 |
+
%%%%%%%%% BODY TEXT
|
| 72 |
+
|
| 73 |
+
\vspace{-1em}
|
| 74 |
+
\section{Introduction}
|
| 75 |
+
\label{sec:intro}
|
| 76 |
+
|
| 77 |
+
Deep convolutional neural networks \cite{LeCun1989,Krizhevsky2012} have led to a series of breakthroughs for image classification \cite{Krizhevsky2012,Zeiler2014,Sermanet2014}. Deep networks naturally integrate low/mid/high-level features \cite{Zeiler2014} and classifiers in an end-to-end multi-layer fashion, and the ``levels'' of features can be enriched by the number of stacked layers (depth).
|
| 78 |
+
Recent evidence \cite{Simonyan2015,Szegedy2015} reveals that network depth is of crucial importance, and the leading results \cite{Simonyan2015,Szegedy2015,He2015,Ioffe2015} on the challenging ImageNet dataset \cite{Russakovsky2014} all exploit ``very deep'' \cite{Simonyan2015} models, with a depth of sixteen \cite{Simonyan2015} to thirty \cite{Ioffe2015}. Many other nontrivial visual recognition tasks \cite{Girshick2014,He2014,Girshick2015,Ren2015,Long2015} have also greatly benefited from very deep models.
|
| 79 |
+
|
| 80 |
+
Driven by the significance of depth, a question arises: \emph{Is learning better networks as easy
|
| 81 |
+
as stacking more layers?}
|
| 82 |
+
An obstacle to answering this question was the notorious problem of vanishing/exploding gradients \cite{Bengio1994,Glorot2010}, which hamper convergence from the beginning. This problem, however, has been largely addressed by normalized initialization \cite{LeCun1998,Glorot2010,Saxe2013,He2015} and intermediate normalization layers \cite{Ioffe2015}, which enable networks with tens of layers to start converging for stochastic gradient descent (SGD) with backpropagation \cite{LeCun1989}.
|
| 83 |
+
|
| 84 |
+
\begin{figure}[t]
|
| 85 |
+
\begin{center}
|
| 86 |
+
\includegraphics[width=1.0\linewidth]{eps/teaser}
|
| 87 |
+
\end{center}
|
| 88 |
+
\vspace{-1.2em}
|
| 89 |
+
\caption{Training error (left) and test error (right) on CIFAR-10 with 20-layer and 56-layer ``plain'' networks. The deeper network has higher training error, and thus test error. Similar phenomena on ImageNet is presented in Fig.~\ref{fig:imagenet}.}
|
| 90 |
+
\label{fig:teaser}
|
| 91 |
+
\vspace{-1em}
|
| 92 |
+
\end{figure}
|
| 93 |
+
|
| 94 |
+
When deeper networks are able to start converging, a \emph{degradation} problem has been exposed: with the network depth increasing, accuracy gets saturated (which might be unsurprising) and then degrades rapidly. Unexpectedly, such degradation is \emph{not caused by overfitting}, and adding more layers to a suitably deep model leads to \emph{higher training error}, as reported in \cite{He2015a, Srivastava2015} and thoroughly verified by our experiments. Fig.~\ref{fig:teaser} shows a typical example.
|
| 95 |
+
|
| 96 |
+
The degradation (of training accuracy) indicates that not all systems are similarly easy to optimize. Let us consider a shallower architecture and its deeper counterpart that adds more layers onto it. There exists a solution \emph{by construction} to the deeper model: the added layers are \emph{identity} mapping, and the other layers are copied from the learned shallower model. The existence of this constructed solution indicates that a deeper model should produce no higher training error than its shallower counterpart. But experiments show that our current solvers on hand are unable to find solutions that are comparably good or better than the constructed solution (or unable to do so in feasible time).
|
| 97 |
+
|
| 98 |
+
In this paper, we address the degradation problem by introducing a \emph{deep residual learning} framework.
|
| 99 |
+
Instead of hoping each few stacked layers directly fit a desired underlying mapping, we explicitly let these layers fit a residual mapping. Formally, denoting the desired underlying mapping as $\mathcal{H}(\ve{x})$, we let the stacked nonlinear layers fit another mapping of $\mathcal{F}(\ve{x}):=\mathcal{H}(\ve{x})-\ve{x}$. The original mapping is recast into $\mathcal{F}(\ve{x})+\ve{x}$.
|
| 100 |
+
We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers.
|
| 101 |
+
|
| 102 |
+
The formulation of $\mathcal{F}(\ve{x})+\ve{x}$ can be realized by feedforward neural networks with ``shortcut connections'' (Fig.~\ref{fig:block}). Shortcut connections \cite{Bishop1995,Ripley1996,Venables1999} are those skipping one or more layers. In our case, the shortcut connections simply perform \emph{identity} mapping, and their outputs are added to the outputs of the stacked layers (Fig.~\ref{fig:block}). Identity shortcut connections add neither extra parameter nor computational complexity. The entire network can still be trained end-to-end by SGD with backpropagation, and can be easily implemented using common libraries (\eg, Caffe \cite{Jia2014}) without modifying the solvers.
|
| 103 |
+
|
| 104 |
+
\begin{figure}[t]
|
| 105 |
+
\centering
|
| 106 |
+
\hspace{48pt}
|
| 107 |
+
\includegraphics[width=0.9\linewidth]{eps/block}
|
| 108 |
+
\vspace{-.5em}
|
| 109 |
+
\caption{Residual learning: a building block.}
|
| 110 |
+
\label{fig:block}
|
| 111 |
+
\vspace{-1em}
|
| 112 |
+
\end{figure}
|
| 113 |
+
|
| 114 |
+
We present comprehensive experiments on ImageNet \cite{Russakovsky2014} to show the degradation problem and evaluate our method.
|
| 115 |
+
We show that: 1) Our extremely deep residual nets are easy to optimize, but the counterpart ``plain'' nets (that simply stack layers) exhibit higher training error when the depth increases; 2) Our deep residual nets can easily enjoy accuracy gains from greatly increased depth, producing results substantially better than previous networks.
|
| 116 |
+
|
| 117 |
+
Similar phenomena are also shown on the CIFAR-10 set \cite{Krizhevsky2009}, suggesting that the optimization difficulties and the effects of our method are not just akin to a particular dataset. We present successfully trained models on this dataset with over 100 layers, and explore models with over 1000 layers.
|
| 118 |
+
|
| 119 |
+
On the ImageNet classification dataset \cite{Russakovsky2014}, we obtain excellent results by extremely deep residual nets.
|
| 120 |
+
Our 152-layer residual net is the deepest network ever presented on ImageNet, while still having lower complexity than VGG nets \cite{Simonyan2015}. Our ensemble has \textbf{3.57\%} top-5 error on the ImageNet \emph{test} set, and \emph{won the 1st place in the ILSVRC 2015 classification competition}. The extremely deep representations also have excellent generalization performance on other recognition tasks, and lead us to further \emph{win the 1st places on: ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation} in ILSVRC \& COCO 2015 competitions. This strong evidence shows that the residual learning principle is generic, and we expect that it is applicable in other vision and non-vision problems.
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
\section{Related Work}
|
| 124 |
+
|
| 125 |
+
%\vspace{6pt}
|
| 126 |
+
\noindent\textbf{Residual Representations.}
|
| 127 |
+
In image recognition, VLAD \cite{Jegou2012} is a representation that encodes by the residual vectors with respect to a dictionary, and Fisher Vector \cite{Perronnin2007} can be formulated as a probabilistic version \cite{Jegou2012} of VLAD.
|
| 128 |
+
Both of them are powerful shallow representations for image retrieval and classification \cite{Chatfield2011,Vedaldi2008}.
|
| 129 |
+
For vector quantization, encoding residual vectors \cite{Jegou2011} is shown to be more effective than encoding original vectors.
|
| 130 |
+
|
| 131 |
+
In low-level vision and computer graphics, for solving Partial Differential Equations (PDEs), the widely used Multigrid method \cite{Briggs2000} reformulates the system as subproblems at multiple scales, where each subproblem is responsible for the residual solution between a coarser and a finer scale. An alternative to Multigrid is hierarchical basis preconditioning \cite{Szeliski1990,Szeliski2006}, which relies on variables that represent residual vectors between two scales. It has been shown \cite{Briggs2000,Szeliski1990,Szeliski2006} that these solvers converge much faster than standard solvers that are unaware of the residual nature of the solutions. These methods suggest that a good reformulation or preconditioning can simplify the optimization.
|
| 132 |
+
|
| 133 |
+
\vspace{6pt}
|
| 134 |
+
\noindent\textbf{Shortcut Connections.}
|
| 135 |
+
Practices and theories that lead to shortcut connections \cite{Bishop1995,Ripley1996,Venables1999} have been studied for a long time.
|
| 136 |
+
%The motivations and usages of shortcuts, however, are diversified in the literature.
|
| 137 |
+
An early practice of training multi-layer perceptrons (MLPs) is to add a linear layer connected from the network input to the output \cite{Ripley1996,Venables1999}. In \cite{Szegedy2015,Lee2014}, a few intermediate layers are directly connected to auxiliary classifiers for addressing vanishing/exploding gradients. The papers of \cite{Schraudolph1998,Schraudolph1998a,Raiko2012,Vatanen2013} propose methods for centering layer responses, gradients, and propagated errors, implemented by shortcut connections. In \cite{Szegedy2015}, an ``inception'' layer is composed of a shortcut branch and a few deeper branches.
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
Concurrent with our work, ``highway networks'' \cite{Srivastava2015,Srivastava2015a} present shortcut connections with gating functions \cite{Hochreiter1997}. These gates are data-dependent and have parameters, in contrast to our identity shortcuts that are parameter-free. When a gated shortcut is ``closed'' (approaching zero), the layers in highway networks represent \emph{non-residual} functions. On the contrary, our formulation always learns residual functions; our identity shortcuts are never closed, and all information is always passed through, with additional residual functions to be learned. In addition, highway networks have not demonstrated accuracy gains with extremely increased depth (\eg, over 100 layers).
|
| 141 |
+
|
| 142 |
+
\section{Deep Residual Learning}
|
| 143 |
+
|
| 144 |
+
\subsection{Residual Learning}
|
| 145 |
+
\label{sec:motivation}
|
| 146 |
+
|
| 147 |
+
Let us consider $\mathcal{H}(\ve{x})$ as an underlying mapping to be fit by a few stacked layers (not necessarily the entire net), with $\ve{x}$ denoting the inputs to the first of these layers. If one hypothesizes that multiple nonlinear layers can asymptotically approximate complicated functions\footnote{This hypothesis, however, is still an open question. See \cite{Montufar2014}.}, then it is equivalent to hypothesize that they can asymptotically approximate the residual functions, \ie, $\mathcal{H}(\ve{x})-\ve{x}$ (assuming that the input and output are of the same dimensions).
|
| 148 |
+
So rather than expect stacked layers to approximate $\mathcal{H}(\ve{x})$, we explicitly let these layers approximate a residual function $\mathcal{F}(\ve{x}):=\mathcal{H}(\ve{x})-\ve{x}$. The original function thus becomes $\mathcal{F}(\ve{x})+\ve{x}$. Although both forms should be able to asymptotically approximate the desired functions (as hypothesized), the ease of learning might be different.
|
| 149 |
+
|
| 150 |
+
This reformulation is motivated by the counterintuitive phenomena about the degradation problem (Fig.~\ref{fig:teaser}, left). As we discussed in the introduction, if the added layers can be constructed as identity mappings, a deeper model should have training error no greater than its shallower counterpart. The degradation problem suggests that the solvers might have difficulties in approximating identity mappings by multiple nonlinear layers. With the residual learning reformulation, if identity mappings are optimal, the solvers may simply drive the weights of the multiple nonlinear layers toward zero to approach identity mappings.
|
| 151 |
+
|
| 152 |
+
In real cases, it is unlikely that identity mappings are optimal, but our reformulation may help to precondition the problem. If the optimal function is closer to an identity mapping than to a zero mapping, it should be easier for the solver to find the perturbations with reference to an identity mapping, than to learn the function as a new one. We show by experiments (Fig.~\ref{fig:std}) that the learned residual functions in general have small responses, suggesting that identity mappings provide reasonable preconditioning.
|
| 153 |
+
|
| 154 |
+
\subsection{Identity Mapping by Shortcuts}
|
| 155 |
+
|
| 156 |
+
We adopt residual learning to every few stacked layers.
|
| 157 |
+
A building block is shown in Fig.~\ref{fig:block}. Formally, in this paper we consider a building block defined as:
|
| 158 |
+
%\vspace{-.5em}
|
| 159 |
+
\begin{equation}\label{eq:identity}
|
| 160 |
+
\ve{y}= \mathcal{F}(\ve{x}, \{W_{i}\}) + \ve{x}.
|
| 161 |
+
\end{equation}
|
| 162 |
+
Here $\ve{x}$ and $\ve{y}$ are the input and output vectors of the layers considered. The function $\mathcal{F}(\ve{x}, \{W_{i}\})$ represents the residual mapping to be learned. For the example in Fig.~\ref{fig:block} that has two layers, $\mathcal{F}=W_{2}\sigma(W_{1}\ve{x})$ in which $\sigma$ denotes ReLU \cite{Nair2010} and the biases are omitted for simplifying notations. The operation $\mathcal{F}+\ve{x}$ is performed by a shortcut connection and element-wise addition. We adopt the second nonlinearity after the addition (\ie, $\sigma(\ve{y})$, see Fig.~\ref{fig:block}).
|
| 163 |
+
|
| 164 |
+
The shortcut connections in Eqn.(\ref{eq:identity}) introduce neither extra parameter nor computation complexity. This is not only attractive in practice but also important in our comparisons between plain and residual networks. We can fairly compare plain/residual networks that simultaneously have the same number of parameters, depth, width, and computational cost (except for the negligible element-wise addition).
|
| 165 |
+
|
| 166 |
+
The dimensions of $\ve{x}$ and $\mathcal{F}$ must be equal in Eqn.(\ref{eq:identity}). If this is not the case (\eg, when changing the input/output channels), we can perform a linear projection $W_{s}$ by the shortcut connections to match the dimensions:
|
| 167 |
+
%\vspace{-.5em}
|
| 168 |
+
\begin{equation}\label{eq:transform}
|
| 169 |
+
\ve{y}= \mathcal{F}(\ve{x}, \{W_{i}\}) + W_{s}\ve{x}.
|
| 170 |
+
\end{equation}
|
| 171 |
+
We can also use a square matrix $W_{s}$ in Eqn.(\ref{eq:identity}). But we will show by experiments that the identity mapping is sufficient for addressing the degradation problem and is economical, and thus $W_{s}$ is only used when matching dimensions.
|
| 172 |
+
|
| 173 |
+
The form of the residual function $\mathcal{F}$ is flexible. Experiments in this paper involve a function $\mathcal{F}$ that has two or three layers (Fig.~\ref{fig:block_deeper}), while more layers are possible. But if $\mathcal{F}$ has only a single layer, Eqn.(\ref{eq:identity}) is similar to a linear layer: $\ve{y}=W_1\ve{x}+\ve{x}$, for which we have not observed advantages.
|
| 174 |
+
|
| 175 |
+
We also note that although the above notations are about fully-connected layers for simplicity, they are applicable to convolutional layers. The function $\mathcal{F}(\ve{x}, \{W_{i}\})$ can represent multiple convolutional layers. The element-wise addition is performed on two feature maps, channel by channel.
|
| 176 |
+
|
| 177 |
+
\begin{figure}[t]
|
| 178 |
+
\begin{center}
|
| 179 |
+
\vspace{.5em}
|
| 180 |
+
\includegraphics[width=1.0\linewidth]{eps/arch}
|
| 181 |
+
\end{center}
|
| 182 |
+
%\vspace{-1em}
|
| 183 |
+
\caption{Example network architectures for ImageNet. \textbf{Left}: the VGG-19 model \cite{Simonyan2015} (19.6 billion FLOPs) as a reference. \textbf{Middle}: a plain network with 34 parameter layers (3.6 billion FLOPs). \textbf{Right}: a residual network with 34 parameter layers (3.6 billion FLOPs). The dotted shortcuts increase dimensions. \textbf{Table~\ref{tab:arch}} shows more details and other variants.}
|
| 184 |
+
\label{fig:arch}
|
| 185 |
+
\vspace{-1em}
|
| 186 |
+
\end{figure}
|
| 187 |
+
|
| 188 |
+
\subsection{Network Architectures}
|
| 189 |
+
|
| 190 |
+
We have tested various plain/residual nets, and have observed consistent phenomena. To provide instances for discussion, we describe two models for ImageNet as follows.
|
| 191 |
+
|
| 192 |
+
\vspace{6pt}
|
| 193 |
+
\noindent\textbf{Plain Network.}
|
| 194 |
+
Our plain baselines (Fig.~\ref{fig:arch}, middle) are mainly inspired by the philosophy of VGG nets \cite{Simonyan2015} (Fig.~\ref{fig:arch}, left).
|
| 195 |
+
The convolutional layers mostly have 3$\times$3 filters and follow two simple design rules: (i) for the same output feature map size, the layers have the same number of filters; and (ii) if the feature map size is halved, the number of filters is doubled so as to preserve the time complexity per layer. We perform downsampling directly by convolutional layers that have a stride of 2.
|
| 196 |
+
The network ends with a global average pooling layer and a 1000-way fully-connected layer with softmax. The total number of weighted layers is 34 in Fig.~\ref{fig:arch} (middle).
|
| 197 |
+
|
| 198 |
+
It is worth noticing that our model has \emph{fewer} filters and \emph{lower} complexity than VGG nets \cite{Simonyan2015} (Fig.~\ref{fig:arch}, left). Our 34-layer baseline has 3.6 billion FLOPs (multiply-adds), which is only 18\% of VGG-19 (19.6 billion FLOPs).
|
| 199 |
+
|
| 200 |
+
\vspace{6pt}
|
| 201 |
+
\noindent\textbf{Residual Network.}
|
| 202 |
+
Based on the above plain network, we insert shortcut connections (Fig.~\ref{fig:arch}, right) which turn the network into its counterpart residual version.
|
| 203 |
+
The identity shortcuts (Eqn.(\ref{eq:identity})) can be directly used when the input and output are of the same dimensions (solid line shortcuts in Fig.~\ref{fig:arch}).
|
| 204 |
+
When the dimensions increase (dotted line shortcuts in Fig.~\ref{fig:arch}), we consider two options:
|
| 205 |
+
(A) The shortcut still performs identity mapping, with extra zero entries padded for increasing dimensions. This option introduces no extra parameter;
|
| 206 |
+
(B) The projection shortcut in Eqn.(\ref{eq:transform}) is used to match dimensions (done by 1$\times$1 convolutions).
|
| 207 |
+
For both options, when the shortcuts go across feature maps of two sizes, they are performed with a stride of 2.
|
| 208 |
+
|
| 209 |
+
\newcommand{\blocka}[2]{\multirow{3}{*}{\(\left[\begin{array}{c}\text{3$\times$3, #1}\\[-.1em] \text{3$\times$3, #1} \end{array}\right]\)$\times$#2}
|
| 210 |
+
}
|
| 211 |
+
\newcommand{\blockb}[3]{\multirow{3}{*}{\(\left[\begin{array}{c}\text{1$\times$1, #2}\\[-.1em] \text{3$\times$3, #2}\\[-.1em] \text{1$\times$1, #1}\end{array}\right]\)$\times$#3}
|
| 212 |
+
}
|
| 213 |
+
\renewcommand\arraystretch{1.1}
|
| 214 |
+
\setlength{\tabcolsep}{3pt}
|
| 215 |
+
\begin{table*}[t]
|
| 216 |
+
\begin{center}
|
| 217 |
+
\resizebox{0.7\linewidth}{!}{
|
| 218 |
+
%\footnotesize
|
| 219 |
+
\begin{tabular}{c|c|c|c|c|c|c}
|
| 220 |
+
\hline
|
| 221 |
+
layer name & output size & 18-layer & 34-layer & 50-layer & 101-layer & 152-layer \\
|
| 222 |
+
\hline
|
| 223 |
+
conv1 & 112$\times$112 & \multicolumn{5}{c}{7$\times$7, 64, stride 2}\\
|
| 224 |
+
\hline
|
| 225 |
+
\multirow{4}{*}{conv2\_x} & \multirow{4}{*}{56$\times$56} & \multicolumn{5}{c}{3$\times$3 max pool, stride 2} \\\cline{3-7}
|
| 226 |
+
& & \blocka{64}{2} & \blocka{64}{3} & \blockb{256}{64}{3} & \blockb{256}{64}{3} & \blockb{256}{64}{3}\\
|
| 227 |
+
& & & & & &\\
|
| 228 |
+
& & & & & &\\
|
| 229 |
+
\hline
|
| 230 |
+
\multirow{3}{*}{conv3\_x} & \multirow{3}{*}{28$\times$28} & \blocka{128}{2} & \blocka{128}{4} & \blockb{512}{128}{4} & \blockb{512}{128}{4} &
|
| 231 |
+
\blockb{512}{128}{8}\\
|
| 232 |
+
& & & & & & \\
|
| 233 |
+
& & & & & & \\
|
| 234 |
+
\hline
|
| 235 |
+
\multirow{3}{*}{conv4\_x} & \multirow{3}{*}{14$\times$14} & \blocka{256}{2} & \blocka{256}{6} & \blockb{1024}{256}{6} & \blockb{1024}{256}{23} & \blockb{1024}{256}{36}\\
|
| 236 |
+
& & & & & \\
|
| 237 |
+
& & & & & \\
|
| 238 |
+
\hline
|
| 239 |
+
\multirow{3}{*}{conv5\_x} & \multirow{3}{*}{7$\times$7} & \blocka{512}{2} & \blocka{512}{3} & \blockb{2048}{512}{3} & \blockb{2048}{512}{3}
|
| 240 |
+
& \blockb{2048}{512}{3}\\
|
| 241 |
+
& & & & & & \\
|
| 242 |
+
& & & & & & \\
|
| 243 |
+
\hline
|
| 244 |
+
& 1$\times$1 & \multicolumn{5}{c}{average pool, 1000-d fc, softmax} \\
|
| 245 |
+
\hline
|
| 246 |
+
\multicolumn{2}{c|}{FLOPs} & 1.8$\times10^9$ & 3.6$\times10^9$ & 3.8$\times10^9$ & 7.6$\times10^9$ & 11.3$\times10^9$ \\
|
| 247 |
+
\hline
|
| 248 |
+
\end{tabular}
|
| 249 |
+
}
|
| 250 |
+
\end{center}
|
| 251 |
+
\vspace{-.5em}
|
| 252 |
+
\caption{Architectures for ImageNet. Building blocks are shown in brackets (see also Fig.~\ref{fig:block_deeper}), with the numbers of blocks stacked. Downsampling is performed by conv3\_1, conv4\_1, and conv5\_1 with a stride of 2.
|
| 253 |
+
}
|
| 254 |
+
\label{tab:arch}
|
| 255 |
+
\vspace{-.5em}
|
| 256 |
+
\end{table*}
|
| 257 |
+
|
| 258 |
+
\begin{figure*}[t]
|
| 259 |
+
\begin{center}
|
| 260 |
+
\includegraphics[width=0.86\linewidth]{eps/imagenet}
|
| 261 |
+
\end{center}
|
| 262 |
+
\vspace{-1.2em}
|
| 263 |
+
\caption{Training on \textbf{ImageNet}. Thin curves denote training error, and bold curves denote validation error of the center crops. Left: plain networks of 18 and 34 layers. Right: ResNets of 18 and 34 layers. In this plot, the residual networks have no extra parameter compared to their plain counterparts.}
|
| 264 |
+
\label{fig:imagenet}
|
| 265 |
+
\end{figure*}
|
| 266 |
+
|
| 267 |
+
\subsection{Implementation}
|
| 268 |
+
\label{sec:impl}
|
| 269 |
+
|
| 270 |
+
Our implementation for ImageNet follows the practice in \cite{Krizhevsky2012,Simonyan2015}. The image is resized with its shorter side randomly sampled in $[256, 480]$ for scale augmentation \cite{Simonyan2015}. A 224$\times$224 crop is randomly sampled from an image or its horizontal flip, with the per-pixel mean subtracted \cite{Krizhevsky2012}. The standard color augmentation in \cite{Krizhevsky2012} is used.
|
| 271 |
+
We adopt batch normalization (BN) \cite{Ioffe2015} right after each convolution and before activation, following \cite{Ioffe2015}.
|
| 272 |
+
We initialize the weights as in \cite{He2015} and train all plain/residual nets from scratch.
|
| 273 |
+
We use SGD with a mini-batch size of 256. The learning rate starts from 0.1 and is divided by 10 when the error plateaus, and the models are trained for up to $60\times10^4$ iterations. We use a weight decay of 0.0001 and a momentum of 0.9. We do not use dropout \cite{Hinton2012}, following the practice in \cite{Ioffe2015}.
|
| 274 |
+
|
| 275 |
+
In testing, for comparison studies we adopt the standard 10-crop testing \cite{Krizhevsky2012}.
|
| 276 |
+
For best results, we adopt the fully-convolutional form as in \cite{Simonyan2015,He2015}, and average the scores at multiple scales (images are resized such that the shorter side is in $\{224, 256, 384, 480, 640\}$).
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
\section{Experiments}
|
| 280 |
+
\label{sec:exp}
|
| 281 |
+
|
| 282 |
+
\subsection{ImageNet Classification}
|
| 283 |
+
\label{sec:imagenet}
|
| 284 |
+
|
| 285 |
+
We evaluate our method on the ImageNet 2012 classification dataset \cite{Russakovsky2014} that consists of 1000 classes. The models are trained on the 1.28 million training images, and evaluated on the 50k validation images. We also obtain a final result on the 100k test images, reported by the test server. We evaluate both top-1 and top-5 error rates.
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
\vspace{6pt}
|
| 289 |
+
\noindent\textbf{Plain Networks.}
|
| 290 |
+
We first evaluate 18-layer and 34-layer plain nets. The 34-layer plain net is in Fig.~\ref{fig:arch} (middle). The 18-layer plain net is of a similar form. See Table~\ref{tab:arch} for detailed architectures.
|
| 291 |
+
|
| 292 |
+
The results in Table~\ref{tab:plain_vs_shortcut} show that the deeper 34-layer plain net has higher validation error than the shallower 18-layer plain net. To reveal the reasons, in Fig.~\ref{fig:imagenet} (left) we compare their training/validation errors during the training procedure. We have observed the degradation problem - the 34-layer plain net has higher \emph{training} error throughout the whole training procedure, even though the solution space of the 18-layer plain network is a subspace of that of the 34-layer one.
|
| 293 |
+
|
| 294 |
+
\newcolumntype{x}[1]{>{\centering}p{#1pt}}
|
| 295 |
+
\renewcommand\arraystretch{1.1}
|
| 296 |
+
\setlength{\tabcolsep}{8pt}
|
| 297 |
+
\begin{table}[t]
|
| 298 |
+
\begin{center}
|
| 299 |
+
\small
|
| 300 |
+
\begin{tabular}{l|x{42}|c}
|
| 301 |
+
\hline
|
| 302 |
+
& plain & ResNet \\
|
| 303 |
+
\hline
|
| 304 |
+
18 layers & 27.94 & 27.88 \\
|
| 305 |
+
34 layers & 28.54 & \textbf{25.03} \\
|
| 306 |
+
\hline
|
| 307 |
+
\end{tabular}
|
| 308 |
+
\end{center}
|
| 309 |
+
\vspace{-.5em}
|
| 310 |
+
\caption{Top-1 error (\%, 10-crop testing) on ImageNet validation. Here the ResNets have no extra parameter compared to their plain counterparts. Fig.~\ref{fig:imagenet} shows the training procedures.}
|
| 311 |
+
\label{tab:plain_vs_shortcut}
|
| 312 |
+
\end{table}
|
| 313 |
+
|
| 314 |
+
We argue that this optimization difficulty is \emph{unlikely} to be caused by vanishing gradients. These plain networks are trained with BN \cite{Ioffe2015}, which ensures forward propagated signals to have non-zero variances. We also verify that the backward propagated gradients exhibit healthy norms with BN. So neither forward nor backward signals vanish.
|
| 315 |
+
In fact, the 34-layer plain net is still able to achieve competitive accuracy (Table~\ref{tab:10crop}), suggesting that the solver works to some extent. We conjecture that the deep plain nets may have exponentially low convergence rates, which impact the reducing of the training error\footnote{We have experimented with more training iterations (3$\times$) and still observed the degradation problem, suggesting that this problem cannot be feasibly addressed by simply using more iterations.}.
|
| 316 |
+
The reason for such optimization difficulties will be studied in the future.
|
| 317 |
+
|
| 318 |
+
\vspace{6pt}
|
| 319 |
+
\noindent\textbf{Residual Networks.}
|
| 320 |
+
Next we evaluate 18-layer and 34-layer residual nets (\emph{ResNets}). The baseline architectures are the same as the above plain nets, expect that a shortcut connection is added to each pair of 3$\times$3 filters as in Fig.~\ref{fig:arch} (right). In the first comparison (Table~\ref{tab:plain_vs_shortcut} and Fig.~\ref{fig:imagenet} right), we use identity mapping for all shortcuts and zero-padding for increasing dimensions (option A). So they have \emph{no extra parameter} compared to the plain counterparts.
|
| 321 |
+
|
| 322 |
+
We have three major observations from Table~\ref{tab:plain_vs_shortcut} and Fig.~\ref{fig:imagenet}. First, the situation is reversed with residual learning -- the 34-layer ResNet is better than the 18-layer ResNet (by 2.8\%). More importantly, the 34-layer ResNet exhibits considerably lower training error and is generalizable to the validation data. This indicates that the degradation problem is well addressed in this setting and we manage to obtain accuracy gains from increased depth.
|
| 323 |
+
|
| 324 |
+
Second, compared to its plain counterpart, the 34-layer ResNet reduces the top-1 error by 3.5\% (Table~\ref{tab:plain_vs_shortcut}), resulting from the successfully reduced training error (Fig.~\ref{fig:imagenet} right \vs left). This comparison verifies the effectiveness of residual learning on extremely deep systems.
|
| 325 |
+
|
| 326 |
+
Last, we also note that the 18-layer plain/residual nets are comparably accurate (Table~\ref{tab:plain_vs_shortcut}), but the 18-layer ResNet converges faster (Fig.~\ref{fig:imagenet} right \vs left).
|
| 327 |
+
When the net is ``not overly deep'' (18 layers here), the current SGD solver is still able to find good solutions to the plain net. In this case, the ResNet eases the optimization by providing faster convergence at the early stage.
|
| 328 |
+
|
| 329 |
+
\begin{table}[t]
|
| 330 |
+
\setlength{\tabcolsep}{8pt}
|
| 331 |
+
\begin{center}
|
| 332 |
+
\small
|
| 333 |
+
\begin{tabular}{l|cc}
|
| 334 |
+
\hline
|
| 335 |
+
\footnotesize model & \footnotesize top-1 err. & \footnotesize top-5 err. \\
|
| 336 |
+
\hline
|
| 337 |
+
%\footnotesize SPP-net \cite{He2014} & 29.68 & 10.95 \\
|
| 338 |
+
\footnotesize VGG-16 \cite{Simonyan2015} & 28.07 & 9.33\\
|
| 339 |
+
\footnotesize GoogLeNet \cite{Szegedy2015} & - & 9.15 \\
|
| 340 |
+
\footnotesize PReLU-net \cite{He2015} & 24.27 & 7.38 \\
|
| 341 |
+
%\footnotesize Deep Neural Decision Forest \cite{Kontschieder2015} & - & 7.08 \\
|
| 342 |
+
\hline
|
| 343 |
+
\hline
|
| 344 |
+
\footnotesize plain-34 & 28.54 & 10.02 \\
|
| 345 |
+
%\hline
|
| 346 |
+
\footnotesize ResNet-34 A & 25.03 & 7.76 \\
|
| 347 |
+
\footnotesize ResNet-34 B & 24.52 & 7.46 \\
|
| 348 |
+
\footnotesize ResNet-34 C & 24.19 & 7.40 \\
|
| 349 |
+
\hline
|
| 350 |
+
\footnotesize ResNet-50 & 22.85 & 6.71 \\
|
| 351 |
+
\footnotesize ResNet-101 & 21.75 & 6.05 \\
|
| 352 |
+
\footnotesize ResNet-152 & \textbf{21.43} & \textbf{5.71} \\
|
| 353 |
+
\hline
|
| 354 |
+
\end{tabular}
|
| 355 |
+
\end{center}
|
| 356 |
+
\vspace{-.5em}
|
| 357 |
+
\caption{Error rates (\%, \textbf{10-crop} testing) on ImageNet validation.
|
| 358 |
+
VGG-16 is based on our test. ResNet-50/101/152 are of option B that only uses projections for increasing dimensions.}
|
| 359 |
+
\label{tab:10crop}
|
| 360 |
+
\vspace{-.5em}
|
| 361 |
+
\end{table}
|
| 362 |
+
|
| 363 |
+
\begin{table}[t]
|
| 364 |
+
\setlength{\tabcolsep}{8pt}
|
| 365 |
+
\small
|
| 366 |
+
\begin{center}
|
| 367 |
+
\begin{tabular}{l|c c}
|
| 368 |
+
\hline
|
| 369 |
+
\footnotesize method & \footnotesize top-1 err. & \footnotesize top-5 err.\\
|
| 370 |
+
\hline
|
| 371 |
+
VGG \cite{Simonyan2015} (ILSVRC'14) & - & 8.43$^{\dag}$\\
|
| 372 |
+
GoogLeNet \cite{Szegedy2015} (ILSVRC'14) & - & 7.89\\
|
| 373 |
+
\hline
|
| 374 |
+
VGG \cite{Simonyan2015} \footnotesize (v5) & 24.4 & 7.1\\
|
| 375 |
+
PReLU-net \cite{He2015} & 21.59 & 5.71 \\
|
| 376 |
+
BN-inception \cite{Ioffe2015} & 21.99 & 5.81 \\\hline
|
| 377 |
+
ResNet-34 B & 21.84 & 5.71 \\
|
| 378 |
+
ResNet-34 C & 21.53 & 5.60 \\
|
| 379 |
+
ResNet-50 & 20.74 & 5.25 \\
|
| 380 |
+
ResNet-101 & 19.87 & 4.60 \\
|
| 381 |
+
ResNet-152 & \textbf{19.38} & \textbf{4.49} \\
|
| 382 |
+
\hline
|
| 383 |
+
\end{tabular}
|
| 384 |
+
\end{center}
|
| 385 |
+
\vspace{-.5em}
|
| 386 |
+
\caption{Error rates (\%) of \textbf{single-model} results on the ImageNet validation set (except $^{\dag}$ reported on the test set).}
|
| 387 |
+
\label{tab:single}
|
| 388 |
+
%\vspace{-.5em}
|
| 389 |
+
%\end{table}
|
| 390 |
+
%\begin{table}[t]
|
| 391 |
+
\setlength{\tabcolsep}{12pt}
|
| 392 |
+
\small
|
| 393 |
+
\begin{center}
|
| 394 |
+
\begin{tabular}{l|c}
|
| 395 |
+
\hline
|
| 396 |
+
\footnotesize method & top-5 err. (\textbf{test}) \\
|
| 397 |
+
\hline
|
| 398 |
+
VGG \cite{Simonyan2015} (ILSVRC'14) & 7.32\\
|
| 399 |
+
GoogLeNet \cite{Szegedy2015} (ILSVRC'14) & 6.66\\
|
| 400 |
+
\hline
|
| 401 |
+
VGG \cite{Simonyan2015} \footnotesize (v5) & 6.8 \\
|
| 402 |
+
PReLU-net \cite{He2015} & 4.94 \\
|
| 403 |
+
BN-inception \cite{Ioffe2015} & 4.82 \\\hline
|
| 404 |
+
\textbf{ResNet (ILSVRC'15)} & \textbf{3.57} \\
|
| 405 |
+
\hline
|
| 406 |
+
\end{tabular}
|
| 407 |
+
\end{center}
|
| 408 |
+
\vspace{-.5em}
|
| 409 |
+
\caption{Error rates (\%) of \textbf{ensembles}. The top-5 error is on the test set of ImageNet and reported by the test server.}
|
| 410 |
+
\label{tab:ensemble}
|
| 411 |
+
%\vspace{-.5em}
|
| 412 |
+
\end{table}
|
| 413 |
+
|
| 414 |
+
\vspace{6pt}
|
| 415 |
+
\noindent\textbf{Identity \vs Projection Shortcuts.}
|
| 416 |
+
We have shown that parameter-free, identity shortcuts help with training. Next we investigate projection shortcuts (Eqn.(\ref{eq:transform})).
|
| 417 |
+
In Table~\ref{tab:10crop} we compare three options: (A) zero-padding shortcuts are used for increasing dimensions, and all shortcuts are parameter-free (the same as Table~\ref{tab:plain_vs_shortcut} and Fig.~\ref{fig:imagenet} right); (B) projection shortcuts are used for increasing dimensions, and other shortcuts are identity; and (C) all shortcuts are projections.
|
| 418 |
+
|
| 419 |
+
Table~\ref{tab:10crop} shows that all three options are considerably better than the plain counterpart.
|
| 420 |
+
B is slightly better than A. We argue that this is because the zero-padded dimensions in A indeed have no residual learning. C is marginally better than B, and we attribute this to the extra parameters introduced by many (thirteen) projection shortcuts. But the small differences among A/B/C indicate that projection shortcuts are not essential for addressing the degradation problem. So we do not use option C in the rest of this paper, to reduce memory/time complexity and model sizes. Identity shortcuts are particularly important for not increasing the complexity of the bottleneck architectures that are introduced below.
|
| 421 |
+
|
| 422 |
+
|
| 423 |
+
\begin{figure}[t]
|
| 424 |
+
\begin{center}
|
| 425 |
+
\hspace{12pt}
|
| 426 |
+
\includegraphics[width=0.85\linewidth]{eps/block_deeper}
|
| 427 |
+
\end{center}
|
| 428 |
+
%\vspace{-1.0em}
|
| 429 |
+
\caption{A deeper residual function $\mathcal{F}$ for ImageNet. Left: a building block (on 56$\times$56 feature maps) as in Fig.~\ref{fig:arch} for ResNet-34. Right: a ``bottleneck'' building block for ResNet-50/101/152.}
|
| 430 |
+
\label{fig:block_deeper}
|
| 431 |
+
\vspace{-.6em}
|
| 432 |
+
\end{figure}
|
| 433 |
+
|
| 434 |
+
\vspace{6pt}
|
| 435 |
+
\noindent\textbf{Deeper Bottleneck Architectures.} Next we describe our deeper nets for ImageNet. Because of concerns on the training time that we can afford, we modify the building block as a \emph{bottleneck} design\footnote{Deeper \emph{non}-bottleneck ResNets (\eg, Fig.~\ref{fig:block_deeper} left) also gain accuracy from increased depth (as shown on CIFAR-10), but are not as economical as the bottleneck ResNets. So the usage of bottleneck designs is mainly due to practical considerations. We further note that the degradation problem of plain nets is also witnessed for the bottleneck designs.}.
|
| 436 |
+
For each residual function $\mathcal{F}$, we use a stack of 3 layers instead of 2 (Fig.~\ref{fig:block_deeper}). The three layers are 1$\times$1, 3$\times$3, and 1$\times$1 convolutions, where the 1$\times$1 layers are responsible for reducing and then increasing (restoring) dimensions, leaving the 3$\times$3 layer a bottleneck with smaller input/output dimensions.
|
| 437 |
+
Fig.~\ref{fig:block_deeper} shows an example, where both designs have similar time complexity.
|
| 438 |
+
|
| 439 |
+
The parameter-free identity shortcuts are particularly important for the bottleneck architectures. If the identity shortcut in Fig.~\ref{fig:block_deeper} (right) is replaced with projection, one can show that the time complexity and model size are doubled, as the shortcut is connected to the two high-dimensional ends. So identity shortcuts lead to more efficient models for the bottleneck designs.
|
| 440 |
+
|
| 441 |
+
\textbf{50-layer ResNet:} We replace each 2-layer block in the 34-layer net with this 3-layer bottleneck block, resulting in a 50-layer ResNet (Table~\ref{tab:arch}). We use option B for increasing dimensions.
|
| 442 |
+
This model has 3.8 billion FLOPs.
|
| 443 |
+
|
| 444 |
+
\textbf{101-layer and 152-layer ResNets:} We construct 101-layer and 152-layer ResNets by using more 3-layer blocks (Table~\ref{tab:arch}).
|
| 445 |
+
Remarkably, although the depth is significantly increased, the 152-layer ResNet (11.3 billion FLOPs) still has \emph{lower complexity} than VGG-16/19 nets (15.3/19.6 billion FLOPs).
|
| 446 |
+
|
| 447 |
+
The 50/101/152-layer ResNets are more accurate than the 34-layer ones by considerable margins (Table~\ref{tab:10crop} and~\ref{tab:single}). We do not observe the degradation problem and thus enjoy significant accuracy gains from considerably increased depth. The benefits of depth are witnessed for all evaluation metrics (Table~\ref{tab:10crop} and~\ref{tab:single}).
|
| 448 |
+
|
| 449 |
+
\begin{figure*}[t]
|
| 450 |
+
\begin{center}
|
| 451 |
+
\includegraphics[width=0.8\linewidth]{eps/cifar}
|
| 452 |
+
\end{center}
|
| 453 |
+
\vspace{-1.5em}
|
| 454 |
+
\caption{Training on \textbf{CIFAR-10}. Dashed lines denote training error, and bold lines denote testing error. \textbf{Left}: plain networks. The error of plain-110 is higher than 60\% and not displayed. \textbf{Middle}: ResNets. \textbf{Right}: ResNets with 110 and 1202 layers.}
|
| 455 |
+
\label{fig:cifar}
|
| 456 |
+
\end{figure*}
|
| 457 |
+
|
| 458 |
+
\vspace{6pt}
|
| 459 |
+
\noindent\textbf{Comparisons with State-of-the-art Methods.}
|
| 460 |
+
In Table~\ref{tab:single} we compare with the previous best single-model results.
|
| 461 |
+
Our baseline 34-layer ResNets have achieved very competitive accuracy.
|
| 462 |
+
Our 152-layer ResNet has a single-model top-5 validation error of 4.49\%. This single-model result outperforms all previous ensemble results (Table~\ref{tab:ensemble}).
|
| 463 |
+
We combine six models of different depth to form an ensemble (only with two 152-layer ones at the time of submitting). This leads to \textbf{3.57\%} top-5 error on the test set (Table~\ref{tab:ensemble}). \emph{This entry won the 1st place in ILSVRC 2015.}
|
| 464 |
+
|
| 465 |
+
|
| 466 |
+
\subsection{CIFAR-10 and Analysis}
|
| 467 |
+
|
| 468 |
+
We conducted more studies on the CIFAR-10 dataset \cite{Krizhevsky2009}, which consists of 50k training images and 10k testing images in 10 classes. We present experiments trained on the training set and evaluated on the test set.
|
| 469 |
+
Our focus is on the behaviors of extremely deep networks, but not on pushing the state-of-the-art results, so we intentionally use simple architectures as follows.
|
| 470 |
+
|
| 471 |
+
The plain/residual architectures follow the form in Fig.~\ref{fig:arch} (middle/right).
|
| 472 |
+
The network inputs are 32$\times$32 images, with the per-pixel mean subtracted. The first layer is 3$\times$3 convolutions. Then we use a stack of $6n$ layers with 3$\times$3 convolutions on the feature maps of sizes $\{32, 16, 8\}$ respectively, with 2$n$ layers for each feature map size. The numbers of filters are $\{16, 32, 64\}$ respectively. The subsampling is performed by convolutions with a stride of 2. The network ends with a global average pooling, a 10-way fully-connected layer, and softmax. There are totally 6$n$+2 stacked weighted layers. The following table summarizes the architecture:
|
| 473 |
+
\renewcommand\arraystretch{1.1}
|
| 474 |
+
\begin{center}
|
| 475 |
+
%\footnotesize
|
| 476 |
+
\small
|
| 477 |
+
\setlength{\tabcolsep}{8pt}
|
| 478 |
+
\begin{tabular}{c|c|c|c}
|
| 479 |
+
\hline
|
| 480 |
+
output map size & 32$\times$32 & 16$\times$16 & 8$\times$8 \\
|
| 481 |
+
\hline
|
| 482 |
+
\# layers & 1+2$n$ & 2$n$ & 2$n$\\
|
| 483 |
+
\# filters & 16 & 32 & 64\\
|
| 484 |
+
\hline
|
| 485 |
+
\end{tabular}
|
| 486 |
+
\end{center}
|
| 487 |
+
When shortcut connections are used, they are connected to the pairs of 3$\times$3 layers (totally $3n$ shortcuts). On this dataset we use identity shortcuts in all cases (\ie, option A), so our residual models have exactly the same depth, width, and number of parameters as the plain counterparts.
|
| 488 |
+
|
| 489 |
+
\renewcommand\arraystretch{1.05}
|
| 490 |
+
\setlength{\tabcolsep}{5pt}
|
| 491 |
+
\begin{table}[t]
|
| 492 |
+
\begin{center}
|
| 493 |
+
\small
|
| 494 |
+
\resizebox{1.0\linewidth}{!}{
|
| 495 |
+
\begin{tabular}{c|c|c|l}
|
| 496 |
+
\hline
|
| 497 |
+
\multicolumn{3}{c|}{method} & error (\%) \\
|
| 498 |
+
\hline
|
| 499 |
+
\multicolumn{3}{c|}{Maxout \cite{Goodfellow2013}} & 9.38 \\
|
| 500 |
+
\multicolumn{3}{c|}{NIN \cite{Lin2013}} & 8.81 \\
|
| 501 |
+
\multicolumn{3}{c|}{DSN \cite{Lee2014}} & 8.22 \\
|
| 502 |
+
\hline
|
| 503 |
+
& \# layers & \# params & \\
|
| 504 |
+
\hline
|
| 505 |
+
FitNet \cite{Romero2015} & 19 & 2.5M & 8.39 \\
|
| 506 |
+
Highway \cite{Srivastava2015,Srivastava2015a} & 19 & 2.3M & 7.54 \footnotesize (7.72$\pm$0.16) \\
|
| 507 |
+
Highway \cite{Srivastava2015,Srivastava2015a} & 32 & 1.25M & 8.80 \\
|
| 508 |
+
\hline
|
| 509 |
+
ResNet & 20 & 0.27M & 8.75 \\
|
| 510 |
+
ResNet & 32 & 0.46M & 7.51 \\
|
| 511 |
+
ResNet & 44 & 0.66M & 7.17 \\
|
| 512 |
+
ResNet & 56 & 0.85M & 6.97 \\
|
| 513 |
+
ResNet & 110 & 1.7M & \textbf{6.43} \footnotesize (6.61$\pm$0.16) \\ % 6.64, 6.43, 6.61, 6.53, 6.86
|
| 514 |
+
ResNet & 1202 & 19.4M & 7.93 \\
|
| 515 |
+
\hline
|
| 516 |
+
\end{tabular}
|
| 517 |
+
}
|
| 518 |
+
\end{center}
|
| 519 |
+
\caption{Classification error on the \textbf{CIFAR-10} test set. All methods are with data augmentation. For ResNet-110, we run it 5 times and show ``best (mean$\pm$std)'' as in \cite{Srivastava2015a}.%, and our 5 results are \{6.64, 6.43, 6.61, 6.53, 6.86\}.
|
| 520 |
+
}
|
| 521 |
+
\label{tab:cifar}
|
| 522 |
+
\end{table}
|
| 523 |
+
|
| 524 |
+
We use a weight decay of 0.0001 and momentum of 0.9, and adopt the weight initialization in \cite{He2015} and BN \cite{Ioffe2015} but with no dropout. These models are trained with a mini-batch size of 128 on two GPUs. We start with a learning rate of 0.1, divide it by 10 at 32k and 48k iterations, and terminate training at 64k iterations, which is determined on a 45k/5k train/val split. We follow the simple data augmentation in \cite{Lee2014} for training: 4 pixels are padded on each side, and a 32$\times$32 crop is randomly sampled from the padded image or its horizontal flip. For testing, we only evaluate the single view of the original 32$\times$32 image.
|
| 525 |
+
|
| 526 |
+
We compare $n=\{3,5,7,9\}$, leading to 20, 32, 44, and 56-layer networks.
|
| 527 |
+
Fig.~\ref{fig:cifar} (left) shows the behaviors of the plain nets. The deep plain nets suffer from increased depth, and exhibit higher training error when going deeper. This phenomenon is similar to that on ImageNet (Fig.~\ref{fig:imagenet}, left) and on MNIST (see \cite{Srivastava2015}), suggesting that such an optimization difficulty is a fundamental problem.
|
| 528 |
+
|
| 529 |
+
Fig.~\ref{fig:cifar} (middle) shows the behaviors of ResNets. Also similar to the ImageNet cases (Fig.~\ref{fig:imagenet}, right), our ResNets manage to overcome the optimization difficulty and demonstrate accuracy gains when the depth increases.
|
| 530 |
+
|
| 531 |
+
We further explore $n=18$ that leads to a 110-layer ResNet. In this case, we find that the initial learning rate of 0.1 is slightly too large to start converging\footnote{With an initial learning rate of 0.1, it starts converging ($<$90\% error) after several epochs, but still reaches similar accuracy.}. So we use 0.01 to warm up the training until the training error is below 80\% (about 400 iterations), and then go back to 0.1 and continue training. The rest of the learning schedule is as done previously. This 110-layer network converges well (Fig.~\ref{fig:cifar}, middle). It has \emph{fewer} parameters than other deep and thin networks such as FitNet \cite{Romero2015} and Highway \cite{Srivastava2015} (Table~\ref{tab:cifar}), yet is among the state-of-the-art results (6.43\%, Table~\ref{tab:cifar}).
|
| 532 |
+
|
| 533 |
+
\begin{figure}[t]
|
| 534 |
+
\begin{center}
|
| 535 |
+
\includegraphics[width=0.9\linewidth]{eps/std}
|
| 536 |
+
\end{center}
|
| 537 |
+
\vspace{-1.5em}
|
| 538 |
+
\caption{Standard deviations (std) of layer responses on CIFAR-10. The responses are the outputs of each 3$\times$3 layer, after BN and before nonlinearity. \textbf{Top}: the layers are shown in their original order. \textbf{Bottom}: the responses are ranked in descending order.}
|
| 539 |
+
\label{fig:std}
|
| 540 |
+
\end{figure}
|
| 541 |
+
|
| 542 |
+
|
| 543 |
+
\vspace{6pt}
|
| 544 |
+
\noindent\textbf{Analysis of Layer Responses.}
|
| 545 |
+
Fig.~\ref{fig:std} shows the standard deviations (std) of the layer responses. The responses are the outputs of each 3$\times$3 layer, after BN and before other nonlinearity (ReLU/addition). For ResNets, this analysis reveals the response strength of the residual functions.
|
| 546 |
+
Fig.~\ref{fig:std} shows that ResNets have generally smaller responses than their plain counterparts. These results support our basic motivation (Sec.\ref{sec:motivation}) that the residual functions might be generally closer to zero than the non-residual functions.
|
| 547 |
+
We also notice that the deeper ResNet has smaller magnitudes of responses, as evidenced by the comparisons among ResNet-20, 56, and 110 in Fig.~\ref{fig:std}. When there are more layers, an individual layer of ResNets tends to modify the signal less.
|
| 548 |
+
|
| 549 |
+
\vspace{6pt}
|
| 550 |
+
\noindent\textbf{Exploring Over 1000 layers.}
|
| 551 |
+
We explore an aggressively deep model of over 1000 layers. We set $n=200$ that leads to a 1202-layer network, which is trained as described above. Our method shows \emph{no optimization difficulty}, and this $10^3$-layer network is able to achieve \emph{training error} $<$0.1\% (Fig.~\ref{fig:cifar}, right). Its test error is still fairly good (7.93\%, Table~\ref{tab:cifar}).
|
| 552 |
+
|
| 553 |
+
But there are still open problems on such aggressively deep models.
|
| 554 |
+
The testing result of this 1202-layer network is worse than that of our 110-layer network, although both have similar training error. We argue that this is because of overfitting.
|
| 555 |
+
The 1202-layer network may be unnecessarily large (19.4M) for this small dataset. Strong regularization such as maxout \cite{Goodfellow2013} or dropout \cite{Hinton2012} is applied to obtain the best results (\cite{Goodfellow2013,Lin2013,Lee2014,Romero2015}) on this dataset.
|
| 556 |
+
In this paper, we use no maxout/dropout and just simply impose regularization via deep and thin architectures by design, without distracting from the focus on the difficulties of optimization. But combining with stronger regularization may improve results, which we will study in the future.
|
| 557 |
+
|
| 558 |
+
\subsection{Object Detection on PASCAL and MS COCO}
|
| 559 |
+
|
| 560 |
+
\renewcommand\arraystretch{1.05}
|
| 561 |
+
\setlength{\tabcolsep}{8pt}
|
| 562 |
+
\begin{table}[t]
|
| 563 |
+
\begin{center}
|
| 564 |
+
\small
|
| 565 |
+
%\resizebox{0.9\linewidth}{!}{
|
| 566 |
+
\begin{tabular}{c|c|c}
|
| 567 |
+
\hline
|
| 568 |
+
training data & 07+12 & 07++12 \\
|
| 569 |
+
\hline
|
| 570 |
+
test data & VOC 07 test & VOC 12 test \\
|
| 571 |
+
\hline
|
| 572 |
+
VGG-16 & 73.2 & 70.4 \\
|
| 573 |
+
ResNet-101 & \textbf{76.4} & \textbf{73.8} \\
|
| 574 |
+
\hline
|
| 575 |
+
\end{tabular}
|
| 576 |
+
%}
|
| 577 |
+
\end{center}
|
| 578 |
+
\vspace{-.5em}
|
| 579 |
+
\caption{Object detection mAP (\%) on the PASCAL VOC 2007/2012 test sets using \textbf{baseline} Faster R-CNN. See also Table~\ref{tab:voc07_all} and \ref{tab:voc12_all} for better results.
|
| 580 |
+
}
|
| 581 |
+
\vspace{-.5em}
|
| 582 |
+
\label{tab:detection_voc}
|
| 583 |
+
%\end{table}
|
| 584 |
+
%\renewcommand\arraystretch{1.05}
|
| 585 |
+
\setlength{\tabcolsep}{5pt}
|
| 586 |
+
%\begin{table}[t]
|
| 587 |
+
\begin{center}
|
| 588 |
+
\small
|
| 589 |
+
%\resizebox{0.9\linewidth}{!}{
|
| 590 |
+
\begin{tabular}{c|c|c}
|
| 591 |
+
\hline
|
| 592 |
+
metric & [email protected]~~~ & mAP@[.5, .95] \\
|
| 593 |
+
\hline
|
| 594 |
+
VGG-16 & 41.5 & 21.2 \\
|
| 595 |
+
ResNet-101 & \textbf{48.4} & \textbf{27.2} \\
|
| 596 |
+
\hline
|
| 597 |
+
\end{tabular}
|
| 598 |
+
%}
|
| 599 |
+
\end{center}
|
| 600 |
+
\vspace{-.5em}
|
| 601 |
+
\caption{Object detection mAP (\%) on the COCO validation set using \textbf{baseline} Faster R-CNN. See also Table~\ref{tab:detection_coco_improve} for better results.
|
| 602 |
+
}
|
| 603 |
+
\vspace{-.5em}
|
| 604 |
+
\label{tab:detection_coco}
|
| 605 |
+
\end{table}
|
| 606 |
+
|
| 607 |
+
Our method has good generalization performance on other recognition tasks. Table~\ref{tab:detection_voc} and ~\ref{tab:detection_coco} show the object detection baseline results on PASCAL VOC 2007 and 2012 \cite{Everingham2010} and COCO \cite{Lin2014}. We adopt \emph{Faster R-CNN} \cite{Ren2015} as the detection method. Here we are interested in the improvements of replacing VGG-16 \cite{Simonyan2015} with ResNet-101. The detection implementation (see appendix) of using both models is the same, so the gains can only be attributed to better networks. Most remarkably, on the challenging COCO dataset we obtain a 6.0\% increase in COCO's standard metric (mAP@[.5, .95]), which is a 28\% relative improvement. This gain is solely due to the learned representations.
|
| 608 |
+
|
| 609 |
+
Based on deep residual nets, we won the 1st places in several tracks in ILSVRC \& COCO 2015 competitions: ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation. The details are in the appendix.
|
| 610 |
+
|
| 611 |
+
|
| 612 |
+
|
| 613 |
+
|
| 614 |
+
|
| 615 |
+
%\renewcommand\arraystretch{1.05}
|
| 616 |
+
%\setlength{\tabcolsep}{4pt}
|
| 617 |
+
%\begin{table}[t]
|
| 618 |
+
%\begin{center}
|
| 619 |
+
%\small
|
| 620 |
+
%\resizebox{1.0\linewidth}{!}{
|
| 621 |
+
%\begin{tabular}{c|c|c|c|c}
|
| 622 |
+
%\hline
|
| 623 |
+
%dataset & VOC 07 & VOC 12 & \multicolumn{2}{c}{MS COCO} \\
|
| 624 |
+
%\hline
|
| 625 |
+
%metric & [email protected] & [email protected] & [email protected] & mAP@[.5, .95] \\
|
| 626 |
+
%\hline
|
| 627 |
+
%VGG-16 & 73.2 & 70.4 & 41.5 & 21.2 \\
|
| 628 |
+
%ResNet-101 & \textbf{76.4} & \textbf{73.8} & \textbf{48.4} & \textbf{27.2} \\
|
| 629 |
+
%\hline
|
| 630 |
+
%\end{tabular}
|
| 631 |
+
%}
|
| 632 |
+
%\end{center}
|
| 633 |
+
%\vspace{-.5em}
|
| 634 |
+
%\caption{\textbf{Object detection} mAP (\%) on the PASCAL VOC 2007/2012 test sets and the MS COCO validation set using Faster R-CNN \cite{Ren2015}. Following \cite{Ren2015}, for the VOC 2007 test, the training data is 2007 trainval and 2012 trainval; for the VOC 2012 test, the training data is 2007 trainval+test and 2012 trainval. For MS COCO, the training data is the 80k COCO training set. ``[email protected]'' means that IoU=0.5 is used for evaluation.
|
| 635 |
+
%}
|
| 636 |
+
%\label{tab:detection}
|
| 637 |
+
%\end{table}
|
| 638 |
+
|
| 639 |
+
{
|
| 640 |
+
%\small
|
| 641 |
+
\footnotesize
|
| 642 |
+
%\fontsize{8.8pt}{9pt}\selectfont
|
| 643 |
+
\bibliographystyle{ieee}
|
| 644 |
+
\bibliography{residual_v1_arxiv_release}
|
| 645 |
+
}
|
| 646 |
+
|
| 647 |
+
\newpage
|
| 648 |
+
|
| 649 |
+
\appendix
|
| 650 |
+
\section{Object Detection Baselines}
|
| 651 |
+
|
| 652 |
+
In this section we introduce our detection method based on the baseline Faster R-CNN \cite{Ren2015} system.
|
| 653 |
+
The models are initialized by the ImageNet classification models, and then fine-tuned on the object detection data. We have experimented with ResNet-50/101 at the time of the ILSVRC \& COCO 2015 detection competitions.
|
| 654 |
+
|
| 655 |
+
Unlike VGG-16 used in \cite{Ren2015}, our ResNet has no hidden fc layers. We adopt the idea of ``Networks on Conv feature maps'' (NoC) \cite{Ren2015a} to address this issue.
|
| 656 |
+
We compute the full-image shared conv feature maps using those layers whose strides on the image are no greater than 16 pixels (\ie, conv1, conv2\_ x, conv3\_x, and conv4\_x, totally 91 conv layers in ResNet-101; Table~\ref{tab:arch}). We consider these layers as analogous to the 13 conv layers in VGG-16, and by doing so, both ResNet and VGG-16 have conv feature maps of the same total stride (16 pixels).
|
| 657 |
+
These layers are shared by a region proposal network (RPN, generating 300 proposals) \cite{Ren2015} and a Fast R-CNN detection network \cite{Girshick2015}.
|
| 658 |
+
RoI pooling \cite{Girshick2015} is performed before conv5\_1. On this RoI-pooled feature, all layers of conv5\_x and up are adopted for each region, playing the roles of VGG-16's fc layers.
|
| 659 |
+
The final classification layer is replaced by two sibling layers (classification and box regression \cite{Girshick2015}).
|
| 660 |
+
|
| 661 |
+
For the usage of BN layers, after pre-training, we compute the BN statistics (means and variances) for each layer on the ImageNet training set. Then the BN layers are fixed during fine-tuning for object detection. As such, the BN layers become linear activations with constant offsets and scales, and BN statistics are not updated by fine-tuning. We fix the BN layers mainly for reducing memory consumption in Faster R-CNN training.
|
| 662 |
+
|
| 663 |
+
|
| 664 |
+
\vspace{.5em}
|
| 665 |
+
\noindent\textbf{PASCAL VOC}
|
| 666 |
+
|
| 667 |
+
Following \cite{Girshick2015,Ren2015}, for the PASCAL VOC 2007 \emph{test} set, we use the 5k \emph{trainval} images in VOC 2007 and 16k \emph{trainval} images in VOC 2012 for training (``07+12''). For the PASCAL VOC 2012 \emph{test} set, we use the 10k \emph{trainval}+\emph{test} images in VOC 2007 and 16k \emph{trainval} images in VOC 2012 for training (``07++12''). The hyper-parameters for training Faster R-CNN are the same as in \cite{Ren2015}.
|
| 668 |
+
Table~\ref{tab:detection_voc} shows the results. ResNet-101 improves the mAP by $>$3\% over VGG-16. This gain is solely because of the improved features learned by ResNet.
|
| 669 |
+
|
| 670 |
+
|
| 671 |
+
|
| 672 |
+
\vspace{.5em}
|
| 673 |
+
\noindent\textbf{MS COCO}
|
| 674 |
+
|
| 675 |
+
The MS COCO dataset \cite{Lin2014} involves 80 object categories. We evaluate the PASCAL VOC metric (mAP @ IoU = 0.5) and the standard COCO metric (mAP @ IoU = .5:.05:.95). We use the 80k images on the train set for training and the 40k images on the val set for evaluation.
|
| 676 |
+
Our detection system for COCO is similar to that for PASCAL VOC.
|
| 677 |
+
We train the COCO models with an 8-GPU implementation, and thus the RPN step has a mini-batch size of 8 images (\ie, 1 per GPU) and the Fast R-CNN step has a mini-batch size of 16 images. The RPN step and Fast R-CNN step are both trained for 240k iterations with a learning rate of 0.001 and then for 80k iterations with 0.0001.
|
| 678 |
+
|
| 679 |
+
|
| 680 |
+
Table~\ref{tab:detection_coco} shows the results on the MS COCO validation set. ResNet-101 has a 6\% increase of mAP@[.5, .95] over VGG-16, which is a 28\% relative improvement, solely contributed by the features learned by the better network. Remarkably, the mAP@[.5, .95]'s absolute increase (6.0\%) is nearly as big as [email protected]'s (6.9\%). This suggests that a deeper network can improve both recognition and localization.
|
| 681 |
+
|
| 682 |
+
|
| 683 |
+
|
| 684 |
+
\section{Object Detection Improvements}
|
| 685 |
+
|
| 686 |
+
For completeness, we report the improvements made for the competitions. These improvements are based on deep features and thus should benefit from residual learning.
|
| 687 |
+
|
| 688 |
+
\renewcommand\arraystretch{1.05}
|
| 689 |
+
\setlength{\tabcolsep}{4pt}
|
| 690 |
+
\begin{table*}[t]
|
| 691 |
+
\begin{center}
|
| 692 |
+
\small
|
| 693 |
+
%\resizebox{0.9\linewidth}{!}{
|
| 694 |
+
\begin{tabular}{l|c|c|c|c}
|
| 695 |
+
\hline
|
| 696 |
+
training data & \multicolumn{2}{c|}{COCO train} & \multicolumn{2}{c}{COCO trainval} \\
|
| 697 |
+
\hline
|
| 698 |
+
test data & \multicolumn{2}{c|}{COCO val} & \multicolumn{2}{c}{COCO test-dev}\\
|
| 699 |
+
\hline
|
| 700 |
+
mAP & [email protected]~~~~ & @[.5, .95] & [email protected]~~~~ & @[.5, .95]\\
|
| 701 |
+
\hline
|
| 702 |
+
baseline Faster R-CNN (VGG-16) & 41.5 & 21.2 & \\
|
| 703 |
+
baseline Faster R-CNN (ResNet-101) & 48.4 & 27.2 & \\
|
| 704 |
+
~+box refinement & 49.9 & 29.9 & \\
|
| 705 |
+
~+context & 51.1 & 30.0 & 53.3 & 32.2 \\
|
| 706 |
+
~+multi-scale testing & 53.8 & 32.5 & \textbf{55.7} & \textbf{34.9} \\
|
| 707 |
+
\hline
|
| 708 |
+
ensemble & & & \textbf{59.0} & \textbf{37.4} \\
|
| 709 |
+
\hline
|
| 710 |
+
\end{tabular}
|
| 711 |
+
%}
|
| 712 |
+
\end{center}
|
| 713 |
+
\vspace{-.5em}
|
| 714 |
+
\caption{Object detection improvements on MS COCO using Faster R-CNN and ResNet-101.}
|
| 715 |
+
\vspace{-.5em}
|
| 716 |
+
\label{tab:detection_coco_improve}
|
| 717 |
+
\end{table*}
|
| 718 |
+
|
| 719 |
+
\newcolumntype{x}[1]{>{\centering}p{#1pt}}
|
| 720 |
+
\newcolumntype{y}{>{\centering}p{16pt}}
|
| 721 |
+
\renewcommand{\hl}[1]{\textbf{#1}}
|
| 722 |
+
\newcommand{\ct}[1]{\fontsize{6pt}{1pt}\selectfont{#1}}
|
| 723 |
+
\renewcommand{\arraystretch}{1.2}
|
| 724 |
+
\setlength{\tabcolsep}{1.5pt}
|
| 725 |
+
\begin{table*}[t]
|
| 726 |
+
\begin{center}
|
| 727 |
+
\footnotesize
|
| 728 |
+
\vspace{1em}
|
| 729 |
+
\resizebox{\linewidth}{!}{
|
| 730 |
+
\begin{tabular}{l|x{40}|x{54}|x{20}|yyyyyyyyyyyyyyyyyyyc}
|
| 731 |
+
\hline
|
| 732 |
+
\ct{system} & net & data & mAP & \ct{areo} & \ct{bike} & \ct{bird} & \ct{boat} & \ct{bottle} & \ct{bus} & \ct{car} & \ct{cat} & \ct{chair} & \ct{cow} & \ct{table} & \ct{dog} & \ct{horse} & \ct{mbike} & \ct{person} & \ct{plant} & \ct{sheep} & \ct{sofa} & \ct{train} & \ct{tv} \\
|
| 733 |
+
\hline
|
| 734 |
+
\footnotesize baseline & \footnotesize VGG-16 & 07+12 & {73.2} & 76.5 & 79.0 & {70.9} & {65.5} & {52.1} & {83.1} & {84.7} & 86.4 & 52.0 & {81.9} & 65.7 & {84.8} & {84.6} & {77.5} & {76.7} & 38.8 & {73.6} & 73.9 & {83.0} & {72.6}\\
|
| 735 |
+
\footnotesize baseline & \footnotesize ResNet-101 & 07+12 & 76.4 & 79.8 & 80.7 & 76.2 & 68.3 & 55.9 & 85.1 & 85.3 & \hl{89.8} & 56.7 & 87.8 & 69.4 & 88.3 & 88.9 & 80.9 & 78.4 & 41.7 & 78.6 & 79.8 & 85.3 & 72.0 \\
|
| 736 |
+
\footnotesize baseline+++ & \footnotesize ResNet-101 & COCO+07+12 & \hl{85.6} & \hl{90.0} & \hl{89.6} & \hl{87.8} & \hl{80.8} & \hl{76.1} & \hl{89.9} & \hl{89.9} & {89.6} & \hl{75.5} & \hl{90.0} & \hl{80.7} & \hl{89.6} & \hl{90.3} & \hl{89.1} & \hl{88.7} & \hl{65.4} & \hl{88.1} & \hl{85.6} & \hl{89.0} & \hl{86.8} \\
|
| 737 |
+
\hline
|
| 738 |
+
\end{tabular}
|
| 739 |
+
}
|
| 740 |
+
\end{center}
|
| 741 |
+
\vspace{-.5em}
|
| 742 |
+
\caption{Detection results on the PASCAL VOC 2007 test set. The baseline is the Faster R-CNN system. The system ``baseline+++'' include box refinement, context, and multi-scale testing in Table~\ref{tab:detection_coco_improve}.}
|
| 743 |
+
\label{tab:voc07_all}
|
| 744 |
+
%\end{table*}
|
| 745 |
+
%\begin{table*}[t]
|
| 746 |
+
\begin{center}
|
| 747 |
+
\footnotesize
|
| 748 |
+
%\vspace{1em}
|
| 749 |
+
\resizebox{\linewidth}{!}{
|
| 750 |
+
\begin{tabular}{l|x{40}|x{54}|x{20}|yyyyyyyyyyyyyyyyyyyc}
|
| 751 |
+
\hline
|
| 752 |
+
\ct{system} & net & data & mAP & \ct{areo} & \ct{bike} & \ct{bird} & \ct{boat} & \ct{bottle} & \ct{bus} & \ct{car} & \ct{cat} & \ct{chair} & \ct{cow} & \ct{table} & \ct{dog} & \ct{horse} & \ct{mbike} & \ct{person} & \ct{plant} & \ct{sheep} & \ct{sofa} & \ct{train} & \ct{tv} \\
|
| 753 |
+
\hline
|
| 754 |
+
\footnotesize baseline & \footnotesize VGG-16 & 07++12 & {70.4} & {84.9} & {79.8} & {74.3} & {53.9} & {49.8} & 77.5 & {75.9} & 88.5 & {45.6} & {77.1} & {55.3} & 86.9 & {81.7} & {80.9} & {79.6} & {40.1} & {72.6} & 60.9 & {81.2} & 61.5\\
|
| 755 |
+
\footnotesize baseline & \footnotesize ResNet-101 & 07++12 & 73.8 & 86.5 & 81.6 & 77.2 & 58.0 & 51.0 & 78.6 & 76.6 & 93.2 & 48.6 & 80.4 & 59.0 & 92.1 & 85.3 & 84.8 & 80.7 & 48.1 & 77.3 & 66.5 & 84.7 & 65.6 \\
|
| 756 |
+
\footnotesize baseline+++ & \footnotesize ResNet-101 & COCO+07++12 & \hl{83.8} & \hl{92.1} & \hl{88.4} & \hl{84.8} & \hl{75.9} & \hl{71.4} & \hl{86.3} & \hl{87.8} & \hl{94.2} & \hl{66.8} & \hl{89.4} & \hl{69.2} & \hl{93.9} & \hl{91.9} & \hl{90.9} & \hl{ 89.6} & \hl{67.9} & \hl{88.2} & \hl{76.8} & \hl{90.3} & \hl{80.0} \\
|
| 757 |
+
\hline
|
| 758 |
+
\end{tabular}
|
| 759 |
+
}
|
| 760 |
+
\end{center}
|
| 761 |
+
\vspace{-.5em}
|
| 762 |
+
\caption{Detection results on the PASCAL VOC 2012 test set (\url{http://host.robots.ox.ac.uk:8080/leaderboard/displaylb.php?challengeid=11&compid=4}). The baseline is the Faster R-CNN system. The system ``baseline+++'' include box refinement, context, and multi-scale testing in Table~\ref{tab:detection_coco_improve}.}
|
| 763 |
+
\label{tab:voc12_all}
|
| 764 |
+
\end{table*}
|
| 765 |
+
|
| 766 |
+
\vspace{.5em}
|
| 767 |
+
\noindent\textbf{MS COCO}
|
| 768 |
+
|
| 769 |
+
%\vspace{.5em}
|
| 770 |
+
\noindent\emph{Box refinement.} Our box refinement partially follows the iterative localization in \cite{Gidaris2015}.
|
| 771 |
+
In Faster R-CNN, the final output is a regressed box that is different from its proposal box. So for inference, we pool a new feature from the regressed box and obtain a new classification score and a new regressed box.
|
| 772 |
+
We combine these 300 new predictions with the original 300 predictions. Non-maximum suppression (NMS) is applied on the union set of predicted boxes using an IoU threshold of 0.3 \cite{Girshick2014}, followed by box voting \cite{Gidaris2015}.
|
| 773 |
+
Box refinement improves mAP by about 2 points (Table~\ref{tab:detection_coco_improve}).
|
| 774 |
+
|
| 775 |
+
\vspace{.5em}
|
| 776 |
+
\noindent\emph{Global context.} We combine global context in the Fast R-CNN step. Given the full-image conv feature map, we pool a feature by global Spatial Pyramid Pooling \cite{He2014} (with a ``single-level'' pyramid) which can be implemented as ``RoI'' pooling using the entire image's bounding box as the RoI. This pooled feature is fed into the post-RoI layers to obtain a global context feature. This global feature is concatenated with the original per-region feature, followed by the sibling classification and box regression layers. This new structure is trained end-to-end.
|
| 777 |
+
Global context improves [email protected] by about 1 point (Table~\ref{tab:detection_coco_improve}).
|
| 778 |
+
|
| 779 |
+
\vspace{.5em}
|
| 780 |
+
\noindent\emph{Multi-scale testing.} In the above, all results are obtained by single-scale training/testing as in \cite{Ren2015}, where the image's shorter side is $s=600$ pixels. Multi-scale training/testing has been developed in \cite{He2014,Girshick2015} by selecting a scale from a feature pyramid, and in \cite{Ren2015a} by using maxout layers. In our current implementation, we have performed multi-scale \emph{testing} following \cite{Ren2015a}; we have not performed multi-scale training because of limited time. In addition, we have performed multi-scale testing only for the Fast R-CNN step (but not yet for the RPN step).
|
| 781 |
+
With a trained model, we compute conv feature maps on an image pyramid, where the image's shorter sides are $s\in\{200, 400, 600, 800, 1000\}$. We select two adjacent scales from the pyramid following \cite{Ren2015a}. RoI pooling and subsequent layers are performed on the feature maps of these two scales \cite{Ren2015a}, which are merged by maxout as in \cite{Ren2015a}.
|
| 782 |
+
Multi-scale testing improves the mAP by over 2 points (Table~\ref{tab:detection_coco_improve}).
|
| 783 |
+
|
| 784 |
+
\vspace{.5em}
|
| 785 |
+
\noindent\emph{Using validation data.} Next we use the 80k+40k trainval set for training and the 20k test-dev set for evaluation. The test-dev set has no publicly available ground truth and the result is reported by the evaluation server. Under this setting, the results are an [email protected] of 55.7\% and an mAP@[.5, .95] of 34.9\% (Table~\ref{tab:detection_coco_improve}). This is our single-model result.
|
| 786 |
+
|
| 787 |
+
\vspace{.5em}
|
| 788 |
+
\noindent\emph{Ensemble.} In Faster R-CNN, the system is designed to learn region proposals and also object classifiers, so an ensemble can be used to boost both tasks. We use an ensemble for proposing regions, and the union set of proposals are processed by an ensemble of per-region classifiers.
|
| 789 |
+
Table~\ref{tab:detection_coco_improve} shows our result based on an ensemble of 3 networks. The mAP is 59.0\% and 37.4\% on the test-dev set. \emph{This result won the 1st place in the detection task in COCO 2015.}
|
| 790 |
+
|
| 791 |
+
|
| 792 |
+
\vspace{1em}
|
| 793 |
+
\noindent\textbf{PASCAL VOC}
|
| 794 |
+
|
| 795 |
+
We revisit the PASCAL VOC dataset based on the above model. With the single model on the COCO dataset (55.7\% [email protected] in Table~\ref{tab:detection_coco_improve}), we fine-tune this model on the PASCAL VOC sets. The improvements of box refinement, context, and multi-scale testing are also adopted. By doing so we achieve 85.6\% mAP on PASCAL VOC 2007 (Table~\ref{tab:voc07_all}) and 83.8\% on PASCAL VOC 2012 (Table~\ref{tab:voc12_all})\footnote{\fontsize{6.5pt}{1em}\selectfont\url{http://host.robots.ox.ac.uk:8080/anonymous/3OJ4OJ.html}, submitted on 2015-11-26.}. The result on PASCAL VOC 2012 is 10 points higher than the previous state-of-the-art result \cite{Gidaris2015}.
|
| 796 |
+
|
| 797 |
+
|
| 798 |
+
\vspace{1em}
|
| 799 |
+
\noindent\textbf{ImageNet Detection}
|
| 800 |
+
|
| 801 |
+
\renewcommand\arraystretch{1.2}
|
| 802 |
+
\setlength{\tabcolsep}{10pt}
|
| 803 |
+
\begin{table}[t]
|
| 804 |
+
\begin{center}
|
| 805 |
+
\small
|
| 806 |
+
\begin{tabular}{l|c|c}
|
| 807 |
+
\hline
|
| 808 |
+
& val2 & test \\
|
| 809 |
+
\hline
|
| 810 |
+
GoogLeNet \cite{Szegedy2015} (ILSVRC'14) & - & 43.9 \\
|
| 811 |
+
\hline
|
| 812 |
+
our single model (ILSVRC'15) & 60.5 & 58.8 \\
|
| 813 |
+
our ensemble (ILSVRC'15) & \textbf{63.6} & \textbf{62.1} \\
|
| 814 |
+
\hline
|
| 815 |
+
\end{tabular}
|
| 816 |
+
\end{center}
|
| 817 |
+
\vspace{-.5em}
|
| 818 |
+
\caption{Our results (mAP, \%) on the ImageNet detection dataset. Our detection system is Faster R-CNN \cite{Ren2015} with the improvements in Table~\ref{tab:detection_coco_improve}, using ResNet-101.
|
| 819 |
+
}
|
| 820 |
+
\vspace{-.5em}
|
| 821 |
+
\label{tab:imagenet_det}
|
| 822 |
+
\end{table}
|
| 823 |
+
|
| 824 |
+
The ImageNet Detection (DET) task involves 200 object categories. The accuracy is evaluated by [email protected].
|
| 825 |
+
Our object detection algorithm for ImageNet DET is the same as that for MS COCO in Table~\ref{tab:detection_coco_improve}. The networks are pre-trained on the 1000-class ImageNet classification set, and are fine-tuned on the DET data. We split the validation set into two parts (val1/val2) following \cite{Girshick2014}. We fine-tune the detection models using the DET training set and the val1 set. The val2 set is used for validation. We do not use other ILSVRC 2015 data. Our single model with ResNet-101 has 58.8\% mAP and our ensemble of 3 models has 62.1\% mAP on the DET test set (Table~\ref{tab:imagenet_det}). \emph{This result won the 1st place in the ImageNet detection task in ILSVRC 2015}, surpassing the second place by \textbf{8.5 points} (absolute).
|
| 826 |
+
|
| 827 |
+
%\end{document}
|
| 828 |
+
|
| 829 |
+
\section{ImageNet Localization}
|
| 830 |
+
\label{sec:appendix_localization}
|
| 831 |
+
|
| 832 |
+
\renewcommand\arraystretch{1.05}
|
| 833 |
+
\setlength{\tabcolsep}{2pt}
|
| 834 |
+
\begin{table}[t]
|
| 835 |
+
\begin{center}
|
| 836 |
+
\small
|
| 837 |
+
\resizebox{1.0\linewidth}{!}{
|
| 838 |
+
\begin{tabular}{c|c|c|c|c|c}
|
| 839 |
+
\hline
|
| 840 |
+
\tabincell{c}{LOC \\ method} & \tabincell{c}{LOC \\ network} & testing & \tabincell{c}{LOC error \\on GT CLS} & \tabincell{c}{classification\\ network} & \tabincell{c}{top-5 LOC error \\ on predicted CLS} \\
|
| 841 |
+
\hline
|
| 842 |
+
VGG's \cite{Simonyan2015} & VGG-16 & 1-crop & 33.1 \cite{Simonyan2015} & & \\
|
| 843 |
+
RPN & ResNet-101 & 1-crop & 13.3 & & \\
|
| 844 |
+
RPN & ResNet-101 & dense & 11.7 & & \\
|
| 845 |
+
\hline
|
| 846 |
+
RPN & ResNet-101 & dense & & ResNet-101 & 14.4 \\
|
| 847 |
+
RPN+RCNN & ResNet-101 & dense & & ResNet-101 & \textbf{10.6} \\
|
| 848 |
+
RPN+RCNN & ensemble & dense & & ensemble & \textbf{8.9} \\
|
| 849 |
+
\hline
|
| 850 |
+
\end{tabular}
|
| 851 |
+
}
|
| 852 |
+
\end{center}
|
| 853 |
+
\vspace{-.5em}
|
| 854 |
+
\caption{Localization error (\%) on the ImageNet validation. In the column of ``LOC error on GT class'' (\cite{Simonyan2015}), the ground truth class is used.
|
| 855 |
+
In the ``testing'' column, ``1-crop'' denotes testing on a center crop of 224$\times$224 pixels, ``dense'' denotes dense (fully convolutional) and multi-scale testing.
|
| 856 |
+
}
|
| 857 |
+
\vspace{-.5em}
|
| 858 |
+
\label{tab:localization}
|
| 859 |
+
\end{table}
|
| 860 |
+
|
| 861 |
+
The ImageNet Localization (LOC) task \cite{Russakovsky2014} requires to classify and localize the objects.
|
| 862 |
+
Following \cite{Sermanet2014,Simonyan2015}, we assume that the image-level classifiers are first adopted for predicting the class labels of an image, and the localization algorithm only accounts for predicting bounding boxes based on the predicted classes. We adopt the ``per-class regression'' (PCR) strategy \cite{Sermanet2014,Simonyan2015}, learning a bounding box regressor for each class. We pre-train the networks for ImageNet classification and then fine-tune them for localization.
|
| 863 |
+
We train networks on the provided 1000-class ImageNet training set.
|
| 864 |
+
|
| 865 |
+
Our localization algorithm is based on the RPN framework of \cite{Ren2015} with a few modifications.
|
| 866 |
+
Unlike the way in \cite{Ren2015} that is category-agnostic, our RPN for localization is designed in a \emph{per-class} form. This RPN ends with two sibling 1$\times$1 convolutional layers for binary classification (\emph{cls}) and box regression (\emph{reg}), as in \cite{Ren2015}. The \emph{cls} and \emph{reg} layers are both in a \emph{per-class} from, in contrast to \cite{Ren2015}. Specifically, the \emph{cls} layer has a 1000-d output, and each dimension is \emph{binary logistic regression} for predicting being or not being an object class; the \emph{reg} layer has a 1000$\times$4-d output consisting of box regressors for 1000 classes.
|
| 867 |
+
As in \cite{Ren2015}, our bounding box regression is with reference to multiple translation-invariant ``anchor'' boxes at each position.
|
| 868 |
+
|
| 869 |
+
As in our ImageNet classification training (Sec.~\ref{sec:impl}), we randomly sample 224$\times$224 crops for data augmentation. We use a mini-batch size of 256 images for fine-tuning.
|
| 870 |
+
To avoid negative samples being dominate, 8 anchors are randomly sampled for each image, where the sampled positive and negative anchors have a ratio of 1:1 \cite{Ren2015}. For testing, the network is applied on the image fully-convolutionally.
|
| 871 |
+
|
| 872 |
+
\renewcommand\arraystretch{1.05}
|
| 873 |
+
\setlength{\tabcolsep}{10pt}
|
| 874 |
+
\begin{table}[t]
|
| 875 |
+
\begin{center}
|
| 876 |
+
\small
|
| 877 |
+
\begin{tabular}{l|c|c}
|
| 878 |
+
\hline
|
| 879 |
+
\multicolumn{1}{c|}{\multirow{2}{*}{method}} & \multicolumn{2}{c}{top-5 localization err} \\\cline{2-3}
|
| 880 |
+
& val & test \\
|
| 881 |
+
\hline
|
| 882 |
+
OverFeat \cite{Sermanet2014} (ILSVRC'13) & 30.0 & 29.9 \\
|
| 883 |
+
GoogLeNet \cite{Szegedy2015} (ILSVRC'14) & - & 26.7 \\
|
| 884 |
+
VGG \cite{Simonyan2015} (ILSVRC'14) & 26.9 & 25.3 \\
|
| 885 |
+
\hline
|
| 886 |
+
ours (ILSVRC'15) & \textbf{8.9} & \textbf{9.0} \\
|
| 887 |
+
\hline
|
| 888 |
+
\end{tabular}
|
| 889 |
+
\end{center}
|
| 890 |
+
\vspace{-.5em}
|
| 891 |
+
\caption{Comparisons of localization error (\%) on the ImageNet dataset with state-of-the-art methods.
|
| 892 |
+
}
|
| 893 |
+
\vspace{-.5em}
|
| 894 |
+
\label{tab:localization_all}
|
| 895 |
+
\end{table}
|
| 896 |
+
|
| 897 |
+
Table~\ref{tab:localization} compares the localization results. Following \cite{Simonyan2015}, we first perform ``oracle'' testing using the ground truth class as the classification prediction. VGG's paper \cite{Simonyan2015} reports a center-crop error of 33.1\% (Table~\ref{tab:localization}) using ground truth classes. Under the same setting, our RPN method using ResNet-101 net significantly reduces the center-crop error to 13.3\%. This comparison demonstrates the excellent performance of our framework.
|
| 898 |
+
With dense (fully convolutional) and multi-scale testing, our ResNet-101 has an error of 11.7\% using ground truth classes. Using ResNet-101 for predicting classes (4.6\% top-5 classification error, Table~\ref{tab:single}), the top-5 localization error is 14.4\%.
|
| 899 |
+
|
| 900 |
+
The above results are only based on the \emph{proposal network} (RPN) in Faster R-CNN \cite{Ren2015}. One may use the \emph{detection network} (Fast R-CNN \cite{Girshick2015}) in Faster R-CNN to improve the results. But we notice that on this dataset, one image usually contains a single dominate object, and the proposal regions highly overlap with each other and thus have very similar RoI-pooled features. As a result, the image-centric training of Fast R-CNN \cite{Girshick2015} generates samples of small variations, which may not be desired for stochastic training. Motivated by this, in our current experiment we use the original R-CNN \cite{Girshick2014} that is RoI-centric, in place of Fast R-CNN.
|
| 901 |
+
|
| 902 |
+
Our R-CNN implementation is as follows. We apply the per-class RPN trained as above on the training images to predict bounding boxes for the ground truth class. These predicted boxes play a role of class-dependent proposals.
|
| 903 |
+
For each training image, the highest scored 200 proposals are extracted as training samples to train an R-CNN classifier. The image region is cropped from a proposal, warped to 224$\times$224 pixels, and fed into the classification network as in R-CNN \cite{Girshick2014}. The outputs of this network consist of two sibling fc layers for \emph{cls} and \emph{reg}, also in a per-class form.
|
| 904 |
+
This R-CNN network is fine-tuned on the training set using a mini-batch size of 256 in the RoI-centric fashion. For testing, the RPN generates the highest scored 200 proposals for each predicted class, and the R-CNN network is used to update these proposals' scores and box positions.
|
| 905 |
+
|
| 906 |
+
This method reduces the top-5 localization error to 10.6\% (Table~\ref{tab:localization}). This is our single-model result on the validation set. Using an ensemble of networks for both classification and localization, we achieve a top-5 localization error of 9.0\% on the test set. This number significantly outperforms the ILSVRC 14 results (Table~\ref{tab:localization_all}), showing a 64\% relative reduction of error. \emph{This result won the 1st place in the ImageNet localization task in ILSVRC 2015.}
|
| 907 |
+
|
| 908 |
+
|
| 909 |
+
\end{document}
|