Spaces:
Runtime error

Runtime error
Commit
·
14091f2
1
Parent(s):
bd4066b
Upload folder using huggingface_hub
Browse files- .gitignore +19 -0
- LICENSE +674 -0
- README.md +244 -8
- assets/demo/demo.png +0 -0
- assets/demo/demo07.jpeg +0 -0
- assets/demo/example-01.jpeg +0 -0
- assets/demo/example-02.jpeg +0 -0
- assets/demo/example-03.jpeg +0 -0
- assets/demo/example-04.jpeg +0 -0
- assets/demo/example-05.jpeg +0 -0
- assets/demo/example-06.jpeg +0 -0
- assets/logo/lamda.png +0 -0
- assets/logo/lawgpt.jpeg +0 -0
- data/.gitkeep +0 -0
- finetune.py +283 -0
- infer.py +136 -0
- merge.py +74 -0
- models/base_models/.gitkeep +0 -0
- models/lora_weights/.gitkeep +0 -0
- outputs/.gitkeep +0 -0
- requirements.txt +14 -0
- resources/criminal_charges.json +0 -0
- resources/example_infer_data.json +5 -0
- resources/example_instruction_train.json +8 -0
- resources/example_instruction_tune.json +12 -0
- resources/legal_vocab.txt +0 -0
- scripts/finetune.sh +56 -0
- scripts/infer.sh +7 -0
- scripts/merge.sh +4 -0
- scripts/train_clm.sh +20 -0
- scripts/webui.sh +28 -0
- templates/alpaca.json +6 -0
- templates/law_template.json +6 -0
- tools/clear_law.py +78 -0
- tools/merge_vocabulary.py +63 -0
- train_clm.py +259 -0
- utils/__init__.py +0 -0
- utils/__pycache__/__init__.cpython-38.pyc +0 -0
- utils/__pycache__/callbacks.cpython-38.pyc +0 -0
- utils/__pycache__/prompter.cpython-38.pyc +0 -0
- utils/callbacks.py +75 -0
- utils/evaluate.py +196 -0
- utils/merge.py +51 -0
- utils/prompter.py +51 -0
- webui.py +191 -0
.gitignore
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
__pycache__/
|
| 2 |
+
*.npy
|
| 3 |
+
*.npz
|
| 4 |
+
*.pyc
|
| 5 |
+
*.pyd
|
| 6 |
+
*.so
|
| 7 |
+
*.ipynb
|
| 8 |
+
.ipynb_checkpoints
|
| 9 |
+
models/base_models/*
|
| 10 |
+
!models/base_models/.gitkeep
|
| 11 |
+
models/lora_weights/*
|
| 12 |
+
!models/lora_weights/.gitkeep
|
| 13 |
+
outputs/*
|
| 14 |
+
!outputs/.gitkeep
|
| 15 |
+
data/*
|
| 16 |
+
!data/.gitkeep
|
| 17 |
+
wandb/
|
| 18 |
+
flagged/
|
| 19 |
+
.DS_Store
|
LICENSE
ADDED
|
@@ -0,0 +1,674 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
GNU GENERAL PUBLIC LICENSE
|
| 2 |
+
Version 3, 29 June 2007
|
| 3 |
+
|
| 4 |
+
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
| 5 |
+
Everyone is permitted to copy and distribute verbatim copies
|
| 6 |
+
of this license document, but changing it is not allowed.
|
| 7 |
+
|
| 8 |
+
Preamble
|
| 9 |
+
|
| 10 |
+
The GNU General Public License is a free, copyleft license for
|
| 11 |
+
software and other kinds of works.
|
| 12 |
+
|
| 13 |
+
The licenses for most software and other practical works are designed
|
| 14 |
+
to take away your freedom to share and change the works. By contrast,
|
| 15 |
+
the GNU General Public License is intended to guarantee your freedom to
|
| 16 |
+
share and change all versions of a program--to make sure it remains free
|
| 17 |
+
software for all its users. We, the Free Software Foundation, use the
|
| 18 |
+
GNU General Public License for most of our software; it applies also to
|
| 19 |
+
any other work released this way by its authors. You can apply it to
|
| 20 |
+
your programs, too.
|
| 21 |
+
|
| 22 |
+
When we speak of free software, we are referring to freedom, not
|
| 23 |
+
price. Our General Public Licenses are designed to make sure that you
|
| 24 |
+
have the freedom to distribute copies of free software (and charge for
|
| 25 |
+
them if you wish), that you receive source code or can get it if you
|
| 26 |
+
want it, that you can change the software or use pieces of it in new
|
| 27 |
+
free programs, and that you know you can do these things.
|
| 28 |
+
|
| 29 |
+
To protect your rights, we need to prevent others from denying you
|
| 30 |
+
these rights or asking you to surrender the rights. Therefore, you have
|
| 31 |
+
certain responsibilities if you distribute copies of the software, or if
|
| 32 |
+
you modify it: responsibilities to respect the freedom of others.
|
| 33 |
+
|
| 34 |
+
For example, if you distribute copies of such a program, whether
|
| 35 |
+
gratis or for a fee, you must pass on to the recipients the same
|
| 36 |
+
freedoms that you received. You must make sure that they, too, receive
|
| 37 |
+
or can get the source code. And you must show them these terms so they
|
| 38 |
+
know their rights.
|
| 39 |
+
|
| 40 |
+
Developers that use the GNU GPL protect your rights with two steps:
|
| 41 |
+
(1) assert copyright on the software, and (2) offer you this License
|
| 42 |
+
giving you legal permission to copy, distribute and/or modify it.
|
| 43 |
+
|
| 44 |
+
For the developers' and authors' protection, the GPL clearly explains
|
| 45 |
+
that there is no warranty for this free software. For both users' and
|
| 46 |
+
authors' sake, the GPL requires that modified versions be marked as
|
| 47 |
+
changed, so that their problems will not be attributed erroneously to
|
| 48 |
+
authors of previous versions.
|
| 49 |
+
|
| 50 |
+
Some devices are designed to deny users access to install or run
|
| 51 |
+
modified versions of the software inside them, although the manufacturer
|
| 52 |
+
can do so. This is fundamentally incompatible with the aim of
|
| 53 |
+
protecting users' freedom to change the software. The systematic
|
| 54 |
+
pattern of such abuse occurs in the area of products for individuals to
|
| 55 |
+
use, which is precisely where it is most unacceptable. Therefore, we
|
| 56 |
+
have designed this version of the GPL to prohibit the practice for those
|
| 57 |
+
products. If such problems arise substantially in other domains, we
|
| 58 |
+
stand ready to extend this provision to those domains in future versions
|
| 59 |
+
of the GPL, as needed to protect the freedom of users.
|
| 60 |
+
|
| 61 |
+
Finally, every program is threatened constantly by software patents.
|
| 62 |
+
States should not allow patents to restrict development and use of
|
| 63 |
+
software on general-purpose computers, but in those that do, we wish to
|
| 64 |
+
avoid the special danger that patents applied to a free program could
|
| 65 |
+
make it effectively proprietary. To prevent this, the GPL assures that
|
| 66 |
+
patents cannot be used to render the program non-free.
|
| 67 |
+
|
| 68 |
+
The precise terms and conditions for copying, distribution and
|
| 69 |
+
modification follow.
|
| 70 |
+
|
| 71 |
+
TERMS AND CONDITIONS
|
| 72 |
+
|
| 73 |
+
0. Definitions.
|
| 74 |
+
|
| 75 |
+
"This License" refers to version 3 of the GNU General Public License.
|
| 76 |
+
|
| 77 |
+
"Copyright" also means copyright-like laws that apply to other kinds of
|
| 78 |
+
works, such as semiconductor masks.
|
| 79 |
+
|
| 80 |
+
"The Program" refers to any copyrightable work licensed under this
|
| 81 |
+
License. Each licensee is addressed as "you". "Licensees" and
|
| 82 |
+
"recipients" may be individuals or organizations.
|
| 83 |
+
|
| 84 |
+
To "modify" a work means to copy from or adapt all or part of the work
|
| 85 |
+
in a fashion requiring copyright permission, other than the making of an
|
| 86 |
+
exact copy. The resulting work is called a "modified version" of the
|
| 87 |
+
earlier work or a work "based on" the earlier work.
|
| 88 |
+
|
| 89 |
+
A "covered work" means either the unmodified Program or a work based
|
| 90 |
+
on the Program.
|
| 91 |
+
|
| 92 |
+
To "propagate" a work means to do anything with it that, without
|
| 93 |
+
permission, would make you directly or secondarily liable for
|
| 94 |
+
infringement under applicable copyright law, except executing it on a
|
| 95 |
+
computer or modifying a private copy. Propagation includes copying,
|
| 96 |
+
distribution (with or without modification), making available to the
|
| 97 |
+
public, and in some countries other activities as well.
|
| 98 |
+
|
| 99 |
+
To "convey" a work means any kind of propagation that enables other
|
| 100 |
+
parties to make or receive copies. Mere interaction with a user through
|
| 101 |
+
a computer network, with no transfer of a copy, is not conveying.
|
| 102 |
+
|
| 103 |
+
An interactive user interface displays "Appropriate Legal Notices"
|
| 104 |
+
to the extent that it includes a convenient and prominently visible
|
| 105 |
+
feature that (1) displays an appropriate copyright notice, and (2)
|
| 106 |
+
tells the user that there is no warranty for the work (except to the
|
| 107 |
+
extent that warranties are provided), that licensees may convey the
|
| 108 |
+
work under this License, and how to view a copy of this License. If
|
| 109 |
+
the interface presents a list of user commands or options, such as a
|
| 110 |
+
menu, a prominent item in the list meets this criterion.
|
| 111 |
+
|
| 112 |
+
1. Source Code.
|
| 113 |
+
|
| 114 |
+
The "source code" for a work means the preferred form of the work
|
| 115 |
+
for making modifications to it. "Object code" means any non-source
|
| 116 |
+
form of a work.
|
| 117 |
+
|
| 118 |
+
A "Standard Interface" means an interface that either is an official
|
| 119 |
+
standard defined by a recognized standards body, or, in the case of
|
| 120 |
+
interfaces specified for a particular programming language, one that
|
| 121 |
+
is widely used among developers working in that language.
|
| 122 |
+
|
| 123 |
+
The "System Libraries" of an executable work include anything, other
|
| 124 |
+
than the work as a whole, that (a) is included in the normal form of
|
| 125 |
+
packaging a Major Component, but which is not part of that Major
|
| 126 |
+
Component, and (b) serves only to enable use of the work with that
|
| 127 |
+
Major Component, or to implement a Standard Interface for which an
|
| 128 |
+
implementation is available to the public in source code form. A
|
| 129 |
+
"Major Component", in this context, means a major essential component
|
| 130 |
+
(kernel, window system, and so on) of the specific operating system
|
| 131 |
+
(if any) on which the executable work runs, or a compiler used to
|
| 132 |
+
produce the work, or an object code interpreter used to run it.
|
| 133 |
+
|
| 134 |
+
The "Corresponding Source" for a work in object code form means all
|
| 135 |
+
the source code needed to generate, install, and (for an executable
|
| 136 |
+
work) run the object code and to modify the work, including scripts to
|
| 137 |
+
control those activities. However, it does not include the work's
|
| 138 |
+
System Libraries, or general-purpose tools or generally available free
|
| 139 |
+
programs which are used unmodified in performing those activities but
|
| 140 |
+
which are not part of the work. For example, Corresponding Source
|
| 141 |
+
includes interface definition files associated with source files for
|
| 142 |
+
the work, and the source code for shared libraries and dynamically
|
| 143 |
+
linked subprograms that the work is specifically designed to require,
|
| 144 |
+
such as by intimate data communication or control flow between those
|
| 145 |
+
subprograms and other parts of the work.
|
| 146 |
+
|
| 147 |
+
The Corresponding Source need not include anything that users
|
| 148 |
+
can regenerate automatically from other parts of the Corresponding
|
| 149 |
+
Source.
|
| 150 |
+
|
| 151 |
+
The Corresponding Source for a work in source code form is that
|
| 152 |
+
same work.
|
| 153 |
+
|
| 154 |
+
2. Basic Permissions.
|
| 155 |
+
|
| 156 |
+
All rights granted under this License are granted for the term of
|
| 157 |
+
copyright on the Program, and are irrevocable provided the stated
|
| 158 |
+
conditions are met. This License explicitly affirms your unlimited
|
| 159 |
+
permission to run the unmodified Program. The output from running a
|
| 160 |
+
covered work is covered by this License only if the output, given its
|
| 161 |
+
content, constitutes a covered work. This License acknowledges your
|
| 162 |
+
rights of fair use or other equivalent, as provided by copyright law.
|
| 163 |
+
|
| 164 |
+
You may make, run and propagate covered works that you do not
|
| 165 |
+
convey, without conditions so long as your license otherwise remains
|
| 166 |
+
in force. You may convey covered works to others for the sole purpose
|
| 167 |
+
of having them make modifications exclusively for you, or provide you
|
| 168 |
+
with facilities for running those works, provided that you comply with
|
| 169 |
+
the terms of this License in conveying all material for which you do
|
| 170 |
+
not control copyright. Those thus making or running the covered works
|
| 171 |
+
for you must do so exclusively on your behalf, under your direction
|
| 172 |
+
and control, on terms that prohibit them from making any copies of
|
| 173 |
+
your copyrighted material outside their relationship with you.
|
| 174 |
+
|
| 175 |
+
Conveying under any other circumstances is permitted solely under
|
| 176 |
+
the conditions stated below. Sublicensing is not allowed; section 10
|
| 177 |
+
makes it unnecessary.
|
| 178 |
+
|
| 179 |
+
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
| 180 |
+
|
| 181 |
+
No covered work shall be deemed part of an effective technological
|
| 182 |
+
measure under any applicable law fulfilling obligations under article
|
| 183 |
+
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
| 184 |
+
similar laws prohibiting or restricting circumvention of such
|
| 185 |
+
measures.
|
| 186 |
+
|
| 187 |
+
When you convey a covered work, you waive any legal power to forbid
|
| 188 |
+
circumvention of technological measures to the extent such circumvention
|
| 189 |
+
is effected by exercising rights under this License with respect to
|
| 190 |
+
the covered work, and you disclaim any intention to limit operation or
|
| 191 |
+
modification of the work as a means of enforcing, against the work's
|
| 192 |
+
users, your or third parties' legal rights to forbid circumvention of
|
| 193 |
+
technological measures.
|
| 194 |
+
|
| 195 |
+
4. Conveying Verbatim Copies.
|
| 196 |
+
|
| 197 |
+
You may convey verbatim copies of the Program's source code as you
|
| 198 |
+
receive it, in any medium, provided that you conspicuously and
|
| 199 |
+
appropriately publish on each copy an appropriate copyright notice;
|
| 200 |
+
keep intact all notices stating that this License and any
|
| 201 |
+
non-permissive terms added in accord with section 7 apply to the code;
|
| 202 |
+
keep intact all notices of the absence of any warranty; and give all
|
| 203 |
+
recipients a copy of this License along with the Program.
|
| 204 |
+
|
| 205 |
+
You may charge any price or no price for each copy that you convey,
|
| 206 |
+
and you may offer support or warranty protection for a fee.
|
| 207 |
+
|
| 208 |
+
5. Conveying Modified Source Versions.
|
| 209 |
+
|
| 210 |
+
You may convey a work based on the Program, or the modifications to
|
| 211 |
+
produce it from the Program, in the form of source code under the
|
| 212 |
+
terms of section 4, provided that you also meet all of these conditions:
|
| 213 |
+
|
| 214 |
+
a) The work must carry prominent notices stating that you modified
|
| 215 |
+
it, and giving a relevant date.
|
| 216 |
+
|
| 217 |
+
b) The work must carry prominent notices stating that it is
|
| 218 |
+
released under this License and any conditions added under section
|
| 219 |
+
7. This requirement modifies the requirement in section 4 to
|
| 220 |
+
"keep intact all notices".
|
| 221 |
+
|
| 222 |
+
c) You must license the entire work, as a whole, under this
|
| 223 |
+
License to anyone who comes into possession of a copy. This
|
| 224 |
+
License will therefore apply, along with any applicable section 7
|
| 225 |
+
additional terms, to the whole of the work, and all its parts,
|
| 226 |
+
regardless of how they are packaged. This License gives no
|
| 227 |
+
permission to license the work in any other way, but it does not
|
| 228 |
+
invalidate such permission if you have separately received it.
|
| 229 |
+
|
| 230 |
+
d) If the work has interactive user interfaces, each must display
|
| 231 |
+
Appropriate Legal Notices; however, if the Program has interactive
|
| 232 |
+
interfaces that do not display Appropriate Legal Notices, your
|
| 233 |
+
work need not make them do so.
|
| 234 |
+
|
| 235 |
+
A compilation of a covered work with other separate and independent
|
| 236 |
+
works, which are not by their nature extensions of the covered work,
|
| 237 |
+
and which are not combined with it such as to form a larger program,
|
| 238 |
+
in or on a volume of a storage or distribution medium, is called an
|
| 239 |
+
"aggregate" if the compilation and its resulting copyright are not
|
| 240 |
+
used to limit the access or legal rights of the compilation's users
|
| 241 |
+
beyond what the individual works permit. Inclusion of a covered work
|
| 242 |
+
in an aggregate does not cause this License to apply to the other
|
| 243 |
+
parts of the aggregate.
|
| 244 |
+
|
| 245 |
+
6. Conveying Non-Source Forms.
|
| 246 |
+
|
| 247 |
+
You may convey a covered work in object code form under the terms
|
| 248 |
+
of sections 4 and 5, provided that you also convey the
|
| 249 |
+
machine-readable Corresponding Source under the terms of this License,
|
| 250 |
+
in one of these ways:
|
| 251 |
+
|
| 252 |
+
a) Convey the object code in, or embodied in, a physical product
|
| 253 |
+
(including a physical distribution medium), accompanied by the
|
| 254 |
+
Corresponding Source fixed on a durable physical medium
|
| 255 |
+
customarily used for software interchange.
|
| 256 |
+
|
| 257 |
+
b) Convey the object code in, or embodied in, a physical product
|
| 258 |
+
(including a physical distribution medium), accompanied by a
|
| 259 |
+
written offer, valid for at least three years and valid for as
|
| 260 |
+
long as you offer spare parts or customer support for that product
|
| 261 |
+
model, to give anyone who possesses the object code either (1) a
|
| 262 |
+
copy of the Corresponding Source for all the software in the
|
| 263 |
+
product that is covered by this License, on a durable physical
|
| 264 |
+
medium customarily used for software interchange, for a price no
|
| 265 |
+
more than your reasonable cost of physically performing this
|
| 266 |
+
conveying of source, or (2) access to copy the
|
| 267 |
+
Corresponding Source from a network server at no charge.
|
| 268 |
+
|
| 269 |
+
c) Convey individual copies of the object code with a copy of the
|
| 270 |
+
written offer to provide the Corresponding Source. This
|
| 271 |
+
alternative is allowed only occasionally and noncommercially, and
|
| 272 |
+
only if you received the object code with such an offer, in accord
|
| 273 |
+
with subsection 6b.
|
| 274 |
+
|
| 275 |
+
d) Convey the object code by offering access from a designated
|
| 276 |
+
place (gratis or for a charge), and offer equivalent access to the
|
| 277 |
+
Corresponding Source in the same way through the same place at no
|
| 278 |
+
further charge. You need not require recipients to copy the
|
| 279 |
+
Corresponding Source along with the object code. If the place to
|
| 280 |
+
copy the object code is a network server, the Corresponding Source
|
| 281 |
+
may be on a different server (operated by you or a third party)
|
| 282 |
+
that supports equivalent copying facilities, provided you maintain
|
| 283 |
+
clear directions next to the object code saying where to find the
|
| 284 |
+
Corresponding Source. Regardless of what server hosts the
|
| 285 |
+
Corresponding Source, you remain obligated to ensure that it is
|
| 286 |
+
available for as long as needed to satisfy these requirements.
|
| 287 |
+
|
| 288 |
+
e) Convey the object code using peer-to-peer transmission, provided
|
| 289 |
+
you inform other peers where the object code and Corresponding
|
| 290 |
+
Source of the work are being offered to the general public at no
|
| 291 |
+
charge under subsection 6d.
|
| 292 |
+
|
| 293 |
+
A separable portion of the object code, whose source code is excluded
|
| 294 |
+
from the Corresponding Source as a System Library, need not be
|
| 295 |
+
included in conveying the object code work.
|
| 296 |
+
|
| 297 |
+
A "User Product" is either (1) a "consumer product", which means any
|
| 298 |
+
tangible personal property which is normally used for personal, family,
|
| 299 |
+
or household purposes, or (2) anything designed or sold for incorporation
|
| 300 |
+
into a dwelling. In determining whether a product is a consumer product,
|
| 301 |
+
doubtful cases shall be resolved in favor of coverage. For a particular
|
| 302 |
+
product received by a particular user, "normally used" refers to a
|
| 303 |
+
typical or common use of that class of product, regardless of the status
|
| 304 |
+
of the particular user or of the way in which the particular user
|
| 305 |
+
actually uses, or expects or is expected to use, the product. A product
|
| 306 |
+
is a consumer product regardless of whether the product has substantial
|
| 307 |
+
commercial, industrial or non-consumer uses, unless such uses represent
|
| 308 |
+
the only significant mode of use of the product.
|
| 309 |
+
|
| 310 |
+
"Installation Information" for a User Product means any methods,
|
| 311 |
+
procedures, authorization keys, or other information required to install
|
| 312 |
+
and execute modified versions of a covered work in that User Product from
|
| 313 |
+
a modified version of its Corresponding Source. The information must
|
| 314 |
+
suffice to ensure that the continued functioning of the modified object
|
| 315 |
+
code is in no case prevented or interfered with solely because
|
| 316 |
+
modification has been made.
|
| 317 |
+
|
| 318 |
+
If you convey an object code work under this section in, or with, or
|
| 319 |
+
specifically for use in, a User Product, and the conveying occurs as
|
| 320 |
+
part of a transaction in which the right of possession and use of the
|
| 321 |
+
User Product is transferred to the recipient in perpetuity or for a
|
| 322 |
+
fixed term (regardless of how the transaction is characterized), the
|
| 323 |
+
Corresponding Source conveyed under this section must be accompanied
|
| 324 |
+
by the Installation Information. But this requirement does not apply
|
| 325 |
+
if neither you nor any third party retains the ability to install
|
| 326 |
+
modified object code on the User Product (for example, the work has
|
| 327 |
+
been installed in ROM).
|
| 328 |
+
|
| 329 |
+
The requirement to provide Installation Information does not include a
|
| 330 |
+
requirement to continue to provide support service, warranty, or updates
|
| 331 |
+
for a work that has been modified or installed by the recipient, or for
|
| 332 |
+
the User Product in which it has been modified or installed. Access to a
|
| 333 |
+
network may be denied when the modification itself materially and
|
| 334 |
+
adversely affects the operation of the network or violates the rules and
|
| 335 |
+
protocols for communication across the network.
|
| 336 |
+
|
| 337 |
+
Corresponding Source conveyed, and Installation Information provided,
|
| 338 |
+
in accord with this section must be in a format that is publicly
|
| 339 |
+
documented (and with an implementation available to the public in
|
| 340 |
+
source code form), and must require no special password or key for
|
| 341 |
+
unpacking, reading or copying.
|
| 342 |
+
|
| 343 |
+
7. Additional Terms.
|
| 344 |
+
|
| 345 |
+
"Additional permissions" are terms that supplement the terms of this
|
| 346 |
+
License by making exceptions from one or more of its conditions.
|
| 347 |
+
Additional permissions that are applicable to the entire Program shall
|
| 348 |
+
be treated as though they were included in this License, to the extent
|
| 349 |
+
that they are valid under applicable law. If additional permissions
|
| 350 |
+
apply only to part of the Program, that part may be used separately
|
| 351 |
+
under those permissions, but the entire Program remains governed by
|
| 352 |
+
this License without regard to the additional permissions.
|
| 353 |
+
|
| 354 |
+
When you convey a copy of a covered work, you may at your option
|
| 355 |
+
remove any additional permissions from that copy, or from any part of
|
| 356 |
+
it. (Additional permissions may be written to require their own
|
| 357 |
+
removal in certain cases when you modify the work.) You may place
|
| 358 |
+
additional permissions on material, added by you to a covered work,
|
| 359 |
+
for which you have or can give appropriate copyright permission.
|
| 360 |
+
|
| 361 |
+
Notwithstanding any other provision of this License, for material you
|
| 362 |
+
add to a covered work, you may (if authorized by the copyright holders of
|
| 363 |
+
that material) supplement the terms of this License with terms:
|
| 364 |
+
|
| 365 |
+
a) Disclaiming warranty or limiting liability differently from the
|
| 366 |
+
terms of sections 15 and 16 of this License; or
|
| 367 |
+
|
| 368 |
+
b) Requiring preservation of specified reasonable legal notices or
|
| 369 |
+
author attributions in that material or in the Appropriate Legal
|
| 370 |
+
Notices displayed by works containing it; or
|
| 371 |
+
|
| 372 |
+
c) Prohibiting misrepresentation of the origin of that material, or
|
| 373 |
+
requiring that modified versions of such material be marked in
|
| 374 |
+
reasonable ways as different from the original version; or
|
| 375 |
+
|
| 376 |
+
d) Limiting the use for publicity purposes of names of licensors or
|
| 377 |
+
authors of the material; or
|
| 378 |
+
|
| 379 |
+
e) Declining to grant rights under trademark law for use of some
|
| 380 |
+
trade names, trademarks, or service marks; or
|
| 381 |
+
|
| 382 |
+
f) Requiring indemnification of licensors and authors of that
|
| 383 |
+
material by anyone who conveys the material (or modified versions of
|
| 384 |
+
it) with contractual assumptions of liability to the recipient, for
|
| 385 |
+
any liability that these contractual assumptions directly impose on
|
| 386 |
+
those licensors and authors.
|
| 387 |
+
|
| 388 |
+
All other non-permissive additional terms are considered "further
|
| 389 |
+
restrictions" within the meaning of section 10. If the Program as you
|
| 390 |
+
received it, or any part of it, contains a notice stating that it is
|
| 391 |
+
governed by this License along with a term that is a further
|
| 392 |
+
restriction, you may remove that term. If a license document contains
|
| 393 |
+
a further restriction but permits relicensing or conveying under this
|
| 394 |
+
License, you may add to a covered work material governed by the terms
|
| 395 |
+
of that license document, provided that the further restriction does
|
| 396 |
+
not survive such relicensing or conveying.
|
| 397 |
+
|
| 398 |
+
If you add terms to a covered work in accord with this section, you
|
| 399 |
+
must place, in the relevant source files, a statement of the
|
| 400 |
+
additional terms that apply to those files, or a notice indicating
|
| 401 |
+
where to find the applicable terms.
|
| 402 |
+
|
| 403 |
+
Additional terms, permissive or non-permissive, may be stated in the
|
| 404 |
+
form of a separately written license, or stated as exceptions;
|
| 405 |
+
the above requirements apply either way.
|
| 406 |
+
|
| 407 |
+
8. Termination.
|
| 408 |
+
|
| 409 |
+
You may not propagate or modify a covered work except as expressly
|
| 410 |
+
provided under this License. Any attempt otherwise to propagate or
|
| 411 |
+
modify it is void, and will automatically terminate your rights under
|
| 412 |
+
this License (including any patent licenses granted under the third
|
| 413 |
+
paragraph of section 11).
|
| 414 |
+
|
| 415 |
+
However, if you cease all violation of this License, then your
|
| 416 |
+
license from a particular copyright holder is reinstated (a)
|
| 417 |
+
provisionally, unless and until the copyright holder explicitly and
|
| 418 |
+
finally terminates your license, and (b) permanently, if the copyright
|
| 419 |
+
holder fails to notify you of the violation by some reasonable means
|
| 420 |
+
prior to 60 days after the cessation.
|
| 421 |
+
|
| 422 |
+
Moreover, your license from a particular copyright holder is
|
| 423 |
+
reinstated permanently if the copyright holder notifies you of the
|
| 424 |
+
violation by some reasonable means, this is the first time you have
|
| 425 |
+
received notice of violation of this License (for any work) from that
|
| 426 |
+
copyright holder, and you cure the violation prior to 30 days after
|
| 427 |
+
your receipt of the notice.
|
| 428 |
+
|
| 429 |
+
Termination of your rights under this section does not terminate the
|
| 430 |
+
licenses of parties who have received copies or rights from you under
|
| 431 |
+
this License. If your rights have been terminated and not permanently
|
| 432 |
+
reinstated, you do not qualify to receive new licenses for the same
|
| 433 |
+
material under section 10.
|
| 434 |
+
|
| 435 |
+
9. Acceptance Not Required for Having Copies.
|
| 436 |
+
|
| 437 |
+
You are not required to accept this License in order to receive or
|
| 438 |
+
run a copy of the Program. Ancillary propagation of a covered work
|
| 439 |
+
occurring solely as a consequence of using peer-to-peer transmission
|
| 440 |
+
to receive a copy likewise does not require acceptance. However,
|
| 441 |
+
nothing other than this License grants you permission to propagate or
|
| 442 |
+
modify any covered work. These actions infringe copyright if you do
|
| 443 |
+
not accept this License. Therefore, by modifying or propagating a
|
| 444 |
+
covered work, you indicate your acceptance of this License to do so.
|
| 445 |
+
|
| 446 |
+
10. Automatic Licensing of Downstream Recipients.
|
| 447 |
+
|
| 448 |
+
Each time you convey a covered work, the recipient automatically
|
| 449 |
+
receives a license from the original licensors, to run, modify and
|
| 450 |
+
propagate that work, subject to this License. You are not responsible
|
| 451 |
+
for enforcing compliance by third parties with this License.
|
| 452 |
+
|
| 453 |
+
An "entity transaction" is a transaction transferring control of an
|
| 454 |
+
organization, or substantially all assets of one, or subdividing an
|
| 455 |
+
organization, or merging organizations. If propagation of a covered
|
| 456 |
+
work results from an entity transaction, each party to that
|
| 457 |
+
transaction who receives a copy of the work also receives whatever
|
| 458 |
+
licenses to the work the party's predecessor in interest had or could
|
| 459 |
+
give under the previous paragraph, plus a right to possession of the
|
| 460 |
+
Corresponding Source of the work from the predecessor in interest, if
|
| 461 |
+
the predecessor has it or can get it with reasonable efforts.
|
| 462 |
+
|
| 463 |
+
You may not impose any further restrictions on the exercise of the
|
| 464 |
+
rights granted or affirmed under this License. For example, you may
|
| 465 |
+
not impose a license fee, royalty, or other charge for exercise of
|
| 466 |
+
rights granted under this License, and you may not initiate litigation
|
| 467 |
+
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
| 468 |
+
any patent claim is infringed by making, using, selling, offering for
|
| 469 |
+
sale, or importing the Program or any portion of it.
|
| 470 |
+
|
| 471 |
+
11. Patents.
|
| 472 |
+
|
| 473 |
+
A "contributor" is a copyright holder who authorizes use under this
|
| 474 |
+
License of the Program or a work on which the Program is based. The
|
| 475 |
+
work thus licensed is called the contributor's "contributor version".
|
| 476 |
+
|
| 477 |
+
A contributor's "essential patent claims" are all patent claims
|
| 478 |
+
owned or controlled by the contributor, whether already acquired or
|
| 479 |
+
hereafter acquired, that would be infringed by some manner, permitted
|
| 480 |
+
by this License, of making, using, or selling its contributor version,
|
| 481 |
+
but do not include claims that would be infringed only as a
|
| 482 |
+
consequence of further modification of the contributor version. For
|
| 483 |
+
purposes of this definition, "control" includes the right to grant
|
| 484 |
+
patent sublicenses in a manner consistent with the requirements of
|
| 485 |
+
this License.
|
| 486 |
+
|
| 487 |
+
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
| 488 |
+
patent license under the contributor's essential patent claims, to
|
| 489 |
+
make, use, sell, offer for sale, import and otherwise run, modify and
|
| 490 |
+
propagate the contents of its contributor version.
|
| 491 |
+
|
| 492 |
+
In the following three paragraphs, a "patent license" is any express
|
| 493 |
+
agreement or commitment, however denominated, not to enforce a patent
|
| 494 |
+
(such as an express permission to practice a patent or covenant not to
|
| 495 |
+
sue for patent infringement). To "grant" such a patent license to a
|
| 496 |
+
party means to make such an agreement or commitment not to enforce a
|
| 497 |
+
patent against the party.
|
| 498 |
+
|
| 499 |
+
If you convey a covered work, knowingly relying on a patent license,
|
| 500 |
+
and the Corresponding Source of the work is not available for anyone
|
| 501 |
+
to copy, free of charge and under the terms of this License, through a
|
| 502 |
+
publicly available network server or other readily accessible means,
|
| 503 |
+
then you must either (1) cause the Corresponding Source to be so
|
| 504 |
+
available, or (2) arrange to deprive yourself of the benefit of the
|
| 505 |
+
patent license for this particular work, or (3) arrange, in a manner
|
| 506 |
+
consistent with the requirements of this License, to extend the patent
|
| 507 |
+
license to downstream recipients. "Knowingly relying" means you have
|
| 508 |
+
actual knowledge that, but for the patent license, your conveying the
|
| 509 |
+
covered work in a country, or your recipient's use of the covered work
|
| 510 |
+
in a country, would infringe one or more identifiable patents in that
|
| 511 |
+
country that you have reason to believe are valid.
|
| 512 |
+
|
| 513 |
+
If, pursuant to or in connection with a single transaction or
|
| 514 |
+
arrangement, you convey, or propagate by procuring conveyance of, a
|
| 515 |
+
covered work, and grant a patent license to some of the parties
|
| 516 |
+
receiving the covered work authorizing them to use, propagate, modify
|
| 517 |
+
or convey a specific copy of the covered work, then the patent license
|
| 518 |
+
you grant is automatically extended to all recipients of the covered
|
| 519 |
+
work and works based on it.
|
| 520 |
+
|
| 521 |
+
A patent license is "discriminatory" if it does not include within
|
| 522 |
+
the scope of its coverage, prohibits the exercise of, or is
|
| 523 |
+
conditioned on the non-exercise of one or more of the rights that are
|
| 524 |
+
specifically granted under this License. You may not convey a covered
|
| 525 |
+
work if you are a party to an arrangement with a third party that is
|
| 526 |
+
in the business of distributing software, under which you make payment
|
| 527 |
+
to the third party based on the extent of your activity of conveying
|
| 528 |
+
the work, and under which the third party grants, to any of the
|
| 529 |
+
parties who would receive the covered work from you, a discriminatory
|
| 530 |
+
patent license (a) in connection with copies of the covered work
|
| 531 |
+
conveyed by you (or copies made from those copies), or (b) primarily
|
| 532 |
+
for and in connection with specific products or compilations that
|
| 533 |
+
contain the covered work, unless you entered into that arrangement,
|
| 534 |
+
or that patent license was granted, prior to 28 March 2007.
|
| 535 |
+
|
| 536 |
+
Nothing in this License shall be construed as excluding or limiting
|
| 537 |
+
any implied license or other defenses to infringement that may
|
| 538 |
+
otherwise be available to you under applicable patent law.
|
| 539 |
+
|
| 540 |
+
12. No Surrender of Others' Freedom.
|
| 541 |
+
|
| 542 |
+
If conditions are imposed on you (whether by court order, agreement or
|
| 543 |
+
otherwise) that contradict the conditions of this License, they do not
|
| 544 |
+
excuse you from the conditions of this License. If you cannot convey a
|
| 545 |
+
covered work so as to satisfy simultaneously your obligations under this
|
| 546 |
+
License and any other pertinent obligations, then as a consequence you may
|
| 547 |
+
not convey it at all. For example, if you agree to terms that obligate you
|
| 548 |
+
to collect a royalty for further conveying from those to whom you convey
|
| 549 |
+
the Program, the only way you could satisfy both those terms and this
|
| 550 |
+
License would be to refrain entirely from conveying the Program.
|
| 551 |
+
|
| 552 |
+
13. Use with the GNU Affero General Public License.
|
| 553 |
+
|
| 554 |
+
Notwithstanding any other provision of this License, you have
|
| 555 |
+
permission to link or combine any covered work with a work licensed
|
| 556 |
+
under version 3 of the GNU Affero General Public License into a single
|
| 557 |
+
combined work, and to convey the resulting work. The terms of this
|
| 558 |
+
License will continue to apply to the part which is the covered work,
|
| 559 |
+
but the special requirements of the GNU Affero General Public License,
|
| 560 |
+
section 13, concerning interaction through a network will apply to the
|
| 561 |
+
combination as such.
|
| 562 |
+
|
| 563 |
+
14. Revised Versions of this License.
|
| 564 |
+
|
| 565 |
+
The Free Software Foundation may publish revised and/or new versions of
|
| 566 |
+
the GNU General Public License from time to time. Such new versions will
|
| 567 |
+
be similar in spirit to the present version, but may differ in detail to
|
| 568 |
+
address new problems or concerns.
|
| 569 |
+
|
| 570 |
+
Each version is given a distinguishing version number. If the
|
| 571 |
+
Program specifies that a certain numbered version of the GNU General
|
| 572 |
+
Public License "or any later version" applies to it, you have the
|
| 573 |
+
option of following the terms and conditions either of that numbered
|
| 574 |
+
version or of any later version published by the Free Software
|
| 575 |
+
Foundation. If the Program does not specify a version number of the
|
| 576 |
+
GNU General Public License, you may choose any version ever published
|
| 577 |
+
by the Free Software Foundation.
|
| 578 |
+
|
| 579 |
+
If the Program specifies that a proxy can decide which future
|
| 580 |
+
versions of the GNU General Public License can be used, that proxy's
|
| 581 |
+
public statement of acceptance of a version permanently authorizes you
|
| 582 |
+
to choose that version for the Program.
|
| 583 |
+
|
| 584 |
+
Later license versions may give you additional or different
|
| 585 |
+
permissions. However, no additional obligations are imposed on any
|
| 586 |
+
author or copyright holder as a result of your choosing to follow a
|
| 587 |
+
later version.
|
| 588 |
+
|
| 589 |
+
15. Disclaimer of Warranty.
|
| 590 |
+
|
| 591 |
+
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
| 592 |
+
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
| 593 |
+
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
| 594 |
+
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
| 595 |
+
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 596 |
+
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
| 597 |
+
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
| 598 |
+
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
| 599 |
+
|
| 600 |
+
16. Limitation of Liability.
|
| 601 |
+
|
| 602 |
+
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
| 603 |
+
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
| 604 |
+
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
| 605 |
+
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
| 606 |
+
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
| 607 |
+
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
| 608 |
+
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
| 609 |
+
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
| 610 |
+
SUCH DAMAGES.
|
| 611 |
+
|
| 612 |
+
17. Interpretation of Sections 15 and 16.
|
| 613 |
+
|
| 614 |
+
If the disclaimer of warranty and limitation of liability provided
|
| 615 |
+
above cannot be given local legal effect according to their terms,
|
| 616 |
+
reviewing courts shall apply local law that most closely approximates
|
| 617 |
+
an absolute waiver of all civil liability in connection with the
|
| 618 |
+
Program, unless a warranty or assumption of liability accompanies a
|
| 619 |
+
copy of the Program in return for a fee.
|
| 620 |
+
|
| 621 |
+
END OF TERMS AND CONDITIONS
|
| 622 |
+
|
| 623 |
+
How to Apply These Terms to Your New Programs
|
| 624 |
+
|
| 625 |
+
If you develop a new program, and you want it to be of the greatest
|
| 626 |
+
possible use to the public, the best way to achieve this is to make it
|
| 627 |
+
free software which everyone can redistribute and change under these terms.
|
| 628 |
+
|
| 629 |
+
To do so, attach the following notices to the program. It is safest
|
| 630 |
+
to attach them to the start of each source file to most effectively
|
| 631 |
+
state the exclusion of warranty; and each file should have at least
|
| 632 |
+
the "copyright" line and a pointer to where the full notice is found.
|
| 633 |
+
|
| 634 |
+
<one line to give the program's name and a brief idea of what it does.>
|
| 635 |
+
Copyright (C) <year> <name of author>
|
| 636 |
+
|
| 637 |
+
This program is free software: you can redistribute it and/or modify
|
| 638 |
+
it under the terms of the GNU General Public License as published by
|
| 639 |
+
the Free Software Foundation, either version 3 of the License, or
|
| 640 |
+
(at your option) any later version.
|
| 641 |
+
|
| 642 |
+
This program is distributed in the hope that it will be useful,
|
| 643 |
+
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
| 644 |
+
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
| 645 |
+
GNU General Public License for more details.
|
| 646 |
+
|
| 647 |
+
You should have received a copy of the GNU General Public License
|
| 648 |
+
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
| 649 |
+
|
| 650 |
+
Also add information on how to contact you by electronic and paper mail.
|
| 651 |
+
|
| 652 |
+
If the program does terminal interaction, make it output a short
|
| 653 |
+
notice like this when it starts in an interactive mode:
|
| 654 |
+
|
| 655 |
+
<program> Copyright (C) <year> <name of author>
|
| 656 |
+
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
|
| 657 |
+
This is free software, and you are welcome to redistribute it
|
| 658 |
+
under certain conditions; type `show c' for details.
|
| 659 |
+
|
| 660 |
+
The hypothetical commands `show w' and `show c' should show the appropriate
|
| 661 |
+
parts of the General Public License. Of course, your program's commands
|
| 662 |
+
might be different; for a GUI interface, you would use an "about box".
|
| 663 |
+
|
| 664 |
+
You should also get your employer (if you work as a programmer) or school,
|
| 665 |
+
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
| 666 |
+
For more information on this, and how to apply and follow the GNU GPL, see
|
| 667 |
+
<https://www.gnu.org/licenses/>.
|
| 668 |
+
|
| 669 |
+
The GNU General Public License does not permit incorporating your program
|
| 670 |
+
into proprietary programs. If your program is a subroutine library, you
|
| 671 |
+
may consider it more useful to permit linking proprietary applications with
|
| 672 |
+
the library. If this is what you want to do, use the GNU Lesser General
|
| 673 |
+
Public License instead of this License. But first, please read
|
| 674 |
+
<https://www.gnu.org/licenses/why-not-lgpl.html>.
|
README.md
CHANGED
|
@@ -1,12 +1,248 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
|
| 4 |
-
colorFrom: red
|
| 5 |
-
colorTo: yellow
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 3.
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Law_llama
|
| 3 |
+
app_file: webui.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
+
sdk_version: 3.39.0
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
# LaWGPT:基于中文法律知识的大语言模型
|
| 8 |
|
| 9 |
+
<p align="center">
|
| 10 |
+
<a href="assets/logo/lawgpt.jpeg">
|
| 11 |
+
<img src="./assets/logo/lawgpt.jpeg" width="80%" >
|
| 12 |
+
</a>
|
| 13 |
+
</p>
|
| 14 |
+
|
| 15 |
+
<p align="center">
|
| 16 |
+
<a href="https://github.com/pengxiao-song/LaWGPT/wiki"><img src="https://img.shields.io/badge/docs-Wiki-brightgreen"></a>
|
| 17 |
+
<a href="https://huggingface.co/entity303"><img src="https://img.shields.io/badge/Hugging%20Face-entity303-green"></a>
|
| 18 |
+
<a href=""><img src="https://img.shields.io/badge/version-beta1.1-blue"></a>
|
| 19 |
+
<a href=""><img src="https://img.shields.io/badge/os-Linux-9cf"></a>
|
| 20 |
+
<a href=""><img src="https://img.shields.io/github/last-commit/pengxiao-song/lawgpt"></a>
|
| 21 |
+
<a href="https://star-history.com/#pengxiao-song/LaWGPT&Timeline"><img src="https://img.shields.io/github/stars/pengxiao-song/lawgpt?color=yellow"></a>
|
| 22 |
+
<!-- <a href="https://www.lamda.nju.edu.cn/"><img src="https://img.shields.io/badge/support-NJU--LAMDA-9cf.svg"></a> -->
|
| 23 |
+
</p>
|
| 24 |
+
|
| 25 |
+
LaWGPT 是一系列基于中文法律知识的开源大语言模型。
|
| 26 |
+
|
| 27 |
+
该系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM 等)的基础上扩充法律领域专有词表、**大规模中文法律语料预训练**,增强了大模型在法律领域的基础语义理解能力。在此基础上,**构造法律领域对话问答数据集、中国司法考试数据集进行指令精调**,提升了模型对法律内容的理解和执行能力。
|
| 28 |
+
|
| 29 |
+
详细内容请参考[技术报告]()。
|
| 30 |
+
|
| 31 |
+
---
|
| 32 |
+
|
| 33 |
+
本项目持续开展,法律领域数据集及系列模型后续相继开源,敬请关注。
|
| 34 |
+
|
| 35 |
+
## 更新
|
| 36 |
+
|
| 37 |
+
- 🌟 2023/05/30:公开发布
|
| 38 |
+
<a href="https://huggingface.co/entity303/lawgpt-lora-7b-v2"><img src="https://img.shields.io/badge/Model-LaWGPT--7B--beta1.1-yellow"></a>
|
| 39 |
+
|
| 40 |
+
- **LaWGPT-7B-beta1.1**:法律对话模型,构造 35w 高质量法律问答数据集基于 Chinese-alpaca-plus-7B 指令精调
|
| 41 |
+
|
| 42 |
+
- 📣 2023/05/26:开放 [Discussions 讨论区](https://github.com/pengxiao-song/LaWGPT/discussions),欢迎朋友们交流探讨、提出意见、分享观点!
|
| 43 |
+
|
| 44 |
+
- 🛠️ 2023/05/22:项目主分支结构调整,详见[项目结构](https://github.com/pengxiao-song/LaWGPT#项目结构);支持[命令行批量推理](https://github.com/pengxiao-song/LaWGPT/blob/main/scripts/infer.sh)
|
| 45 |
+
|
| 46 |
+
- 🪴 2023/05/15:发布 [中文法律数据源汇总(Awesome Chinese Legal Resources)](https://github.com/pengxiao-song/awesome-chinese-legal-resources) 和 [法律领域词表](https://github.com/pengxiao-song/LaWGPT/blob/main/resources/legal_vocab.txt)
|
| 47 |
+
|
| 48 |
+
- 🌟 2023/05/13:公开发布
|
| 49 |
+
<a href="https://huggingface.co/entity303/legal-lora-7b"><img src="https://img.shields.io/badge/Model-Legal--Base--7B-blue"></a>
|
| 50 |
+
<a href="https://huggingface.co/entity303/lawgpt-legal-lora-7b"><img src="https://img.shields.io/badge/Model-LaWGPT--7B--beta1.0-yellow"></a>
|
| 51 |
+
|
| 52 |
+
- **Legal-Base-7B**:法律基座模型,使用 50w 中文裁判文书数据二次预训练
|
| 53 |
+
|
| 54 |
+
- **LaWGPT-7B-beta1.0**:法律对话模型,构造 30w 高质量法律问答数据集基于 Legal-Base-7B 指令精调
|
| 55 |
+
|
| 56 |
+
- 🌟 2023/04/12:内部测试
|
| 57 |
+
<a href="https://huggingface.co/entity303/lawgpt-lora-7b"><img src="https://img.shields.io/badge/Model-Lawgpt--7B--alpha-yellow"></a>
|
| 58 |
+
- **LaWGPT-7B-alpha**:在 Chinese-LLaMA-7B 的基础上直接构造 30w 法律问答数据集指令精调
|
| 59 |
+
|
| 60 |
+
## 快速开始
|
| 61 |
+
|
| 62 |
+
1. 准备代码,创建环境
|
| 63 |
+
|
| 64 |
+
```bash
|
| 65 |
+
# 下载代码
|
| 66 |
+
git clone [email protected]:pengxiao-song/LaWGPT.git
|
| 67 |
+
cd LaWGPT
|
| 68 |
+
|
| 69 |
+
# 创建环境
|
| 70 |
+
conda create -n lawgpt python=3.10 -y
|
| 71 |
+
conda activate lawgpt
|
| 72 |
+
pip install -r requirements.txt
|
| 73 |
+
```
|
| 74 |
+
2. **启动 web ui(可选,易于调节参数)**
|
| 75 |
+
|
| 76 |
+
- 首先,执行服务启动脚本:`bash scripts/webui.sh`
|
| 77 |
+
|
| 78 |
+
- 其次,访问 http://127.0.0.1:7860 :
|
| 79 |
+
|
| 80 |
+
<p align="center">
|
| 81 |
+
<img style="border-radius: 50%; box-shadow: 0 0 10px rgba(0,0,0,0.5); width: 80%;", src="./assets/demo/example-03.jpeg">
|
| 82 |
+
</p>
|
| 83 |
+
|
| 84 |
+
3. **命令行推理(可选,支持批量测试)**
|
| 85 |
+
|
| 86 |
+
- 首先,参考 `resources/example_infer_data.json` 文件内容构造测试样本集;
|
| 87 |
+
|
| 88 |
+
- 其次,执行推理脚本:`bash scripts/infer.sh`。其中 `--infer_data_path` 参数为测试样本集路径,如果为空或者路径出错,则以交互模式运行。
|
| 89 |
+
|
| 90 |
+
注意,以上步骤的默认模型为 LaWGPT-7B-alpha ,如果您想使用 LaWGPT-7B-beta1.0 模型:
|
| 91 |
+
|
| 92 |
+
- 由于 [LLaMA](https://github.com/facebookresearch/llama) 和 [Chinese-LLaMA](https://github.com/ymcui/Chinese-LLaMA-Alpaca) 均未开源模型权重。根据相应开源许可,**本项目只能发布 LoRA 权重**,无法发布完整的模型权重,请各位谅��。
|
| 93 |
+
|
| 94 |
+
- 本项目给出[合并方式](https://github.com/pengxiao-song/LaWGPT/wiki/%E6%A8%A1%E5%9E%8B%E5%90%88%E5%B9%B6),请各位获取原版权重后自行重构模型。
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
## 项目结构
|
| 98 |
+
|
| 99 |
+
```bash
|
| 100 |
+
LaWGPT
|
| 101 |
+
├── assets # 静态资源
|
| 102 |
+
├── resources # 项目资源
|
| 103 |
+
├── models # 基座模型及 lora 权重
|
| 104 |
+
│ ├── base_models
|
| 105 |
+
│ └── lora_weights
|
| 106 |
+
├── outputs # 指令微调的输出权重
|
| 107 |
+
├── data # 实验数据
|
| 108 |
+
├── scripts # 脚本目录
|
| 109 |
+
│ ├── finetune.sh # 指令微调脚本
|
| 110 |
+
│ └── webui.sh # 启动服务脚本
|
| 111 |
+
├── templates # prompt 模板
|
| 112 |
+
├── tools # 工具包
|
| 113 |
+
├── utils
|
| 114 |
+
├── train_clm.py # 二次训练
|
| 115 |
+
├── finetune.py # 指令微调
|
| 116 |
+
├── webui.py # 启动服务
|
| 117 |
+
├── README.md
|
| 118 |
+
└── requirements.txt
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
## 数据构建
|
| 123 |
+
|
| 124 |
+
本项目基于中文裁判文书网公开法律文书数据、司法考试数据等数据集展开,详情参考[中文法律数据源汇总(Awesome Chinese Legal Resources)](https://github.com/pengxiao-song/awesome-chinese-legal-resources)。
|
| 125 |
+
|
| 126 |
+
1. 初级数据生成:根据 [Stanford_alpaca](https://github.com/tatsu-lab/stanford_alpaca#data-generation-process) 和 [self-instruct](https://github.com/yizhongw/self-instruct) 方式生成对话问答数据
|
| 127 |
+
2. 知识引导的数据生成:通过 Knowledge-based Self-Instruct 方式基于中文法律结构化知识生成数据。
|
| 128 |
+
3. 引入 ChatGPT 清洗数据,辅助构造高质量数据集。
|
| 129 |
+
|
| 130 |
+
## 模型训练
|
| 131 |
+
|
| 132 |
+
LawGPT 系列模型的训练过程分为两个阶段:
|
| 133 |
+
|
| 134 |
+
1. 第一阶段:扩充法律领域词表,在大规模法律文书及法典数据上预训练 Chinese-LLaMA
|
| 135 |
+
2. 第二阶段:构造法律领域对话问答数据集,在预训练模型基础上指令精调
|
| 136 |
+
|
| 137 |
+
### 二次训练流程
|
| 138 |
+
|
| 139 |
+
1. 参考 `resources/example_instruction_train.json` 构造二次训练数据集
|
| 140 |
+
2. 运行 `scripts/train_clm.sh`
|
| 141 |
+
|
| 142 |
+
### 指令精调步骤
|
| 143 |
+
|
| 144 |
+
1. 参考 `resources/example_instruction_tune.json` 构造指令微调数据集
|
| 145 |
+
2. 运行 `scripts/finetune.sh`
|
| 146 |
+
|
| 147 |
+
### 计算资源
|
| 148 |
+
|
| 149 |
+
8 张 Tesla V100-SXM2-32GB :二次训练阶段耗时约 24h / epoch,微调阶段耗时约 12h / epoch
|
| 150 |
+
|
| 151 |
+
## 模型评估
|
| 152 |
+
|
| 153 |
+
### 输出示例
|
| 154 |
+
|
| 155 |
+
<details><summary>问题:酒驾撞人怎么判刑?</summary>
|
| 156 |
+
|
| 157 |
+

|
| 158 |
+
|
| 159 |
+
</details>
|
| 160 |
+
|
| 161 |
+
<details><summary>问题:请给出判决意见。</summary>
|
| 162 |
+
|
| 163 |
+

|
| 164 |
+
|
| 165 |
+
</details>
|
| 166 |
+
|
| 167 |
+
<details><summary>问题:请介绍赌博罪的定义。</summary>
|
| 168 |
+
|
| 169 |
+

|
| 170 |
+
|
| 171 |
+
</details>
|
| 172 |
+
|
| 173 |
+
<details><summary>问题:请问加班工资怎么算?</summary>
|
| 174 |
+
|
| 175 |
+

|
| 176 |
+
|
| 177 |
+
</details>
|
| 178 |
+
|
| 179 |
+
<details><summary>问题:民间借贷受国家保护的合法利息是多少?</summary>
|
| 180 |
+
|
| 181 |
+

|
| 182 |
+
|
| 183 |
+
</details>
|
| 184 |
+
|
| 185 |
+
<details><summary>问题:欠了信用卡的钱还不上要坐牢吗?</summary>
|
| 186 |
+
|
| 187 |
+

|
| 188 |
+
|
| 189 |
+
</details>
|
| 190 |
+
|
| 191 |
+
<details><summary>问题:你能否写一段抢劫罪罪名的案情描述?</summary>
|
| 192 |
+
|
| 193 |
+

|
| 194 |
+
|
| 195 |
+
</details>
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
### 局限性
|
| 199 |
+
|
| 200 |
+
由于计算资源、数据规模等因素限制,当前阶段 LawGPT 存在诸多局限性:
|
| 201 |
+
|
| 202 |
+
1. 数据资源有限、模型容量较小,导致其相对较弱的模型记忆和语言能力。因此,在面对事实性知识任务时,可能会生成不正确的结果。
|
| 203 |
+
2. 该系列模型只进行了初步的人类意图对齐。因此,可能产生不可预测的有害内容以及不符合人类偏好和价值观的内容。
|
| 204 |
+
3. 自我认知能力存在问题,中文理解能力有待增强。
|
| 205 |
+
|
| 206 |
+
请诸君在使用前了解上述问题,以免造成误解和不必要的麻烦。
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
## 协作者
|
| 210 |
+
|
| 211 |
+
如下各位合作开展(按字母序排列):[@cainiao](https://github.com/herobrine19)、[@njuyxw](https://github.com/njuyxw)、[@pengxiao-song](https://github.com/pengxiao-song)
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
## 免责声明
|
| 215 |
+
|
| 216 |
+
请各位严格遵守如下约定:
|
| 217 |
+
|
| 218 |
+
1. 本项目任何资源**仅供学术研究使用,严禁任何商业用途**。
|
| 219 |
+
2. 模型输出受多种不确定性因素影响,本项目当前无法保证其准确性,**严禁用于真实法律场景**。
|
| 220 |
+
3. 本项目不承担任何法律责任,亦不对因使用相关资源和输出结果而可能产生的任何损失承担责任。
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
## 问题反馈
|
| 224 |
+
|
| 225 |
+
如有问题,请在 GitHub Issue 中提交。
|
| 226 |
+
|
| 227 |
+
- 提交问题之前,建议查阅 FAQ 及以往的 issue 看是否能解决您的问题。
|
| 228 |
+
- 请礼貌讨论,构建和谐社区。
|
| 229 |
+
|
| 230 |
+
协作者科研之余推进项目进展,由于人力有限难以实时反馈,给诸君带来不便,敬请谅解!
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
## 致谢
|
| 234 |
+
|
| 235 |
+
本项目基于如下开源项目展开,在此对相关项目和开发人员表示诚挚的感谢:
|
| 236 |
+
|
| 237 |
+
- Chinese-LLaMA-Alpaca: https://github.com/ymcui/Chinese-LLaMA-Alpaca
|
| 238 |
+
- LLaMA: https://github.com/facebookresearch/llama
|
| 239 |
+
- Alpaca: https://github.com/tatsu-lab/stanford_alpaca
|
| 240 |
+
- alpaca-lora: https://github.com/tloen/alpaca-lora
|
| 241 |
+
- ChatGLM-6B: https://github.com/THUDM/ChatGLM-6B
|
| 242 |
+
|
| 243 |
+
此外,本项目基于开放数据资源,详见 [Awesome Chinese Legal Resources](https://github.com/pengxiao-song/awesome-chinese-legal-resources),一并表示感谢。
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
## 引用
|
| 247 |
+
|
| 248 |
+
如果您觉得我们的工作对您有所帮助,请考虑引用该项目
|
assets/demo/demo.png
ADDED
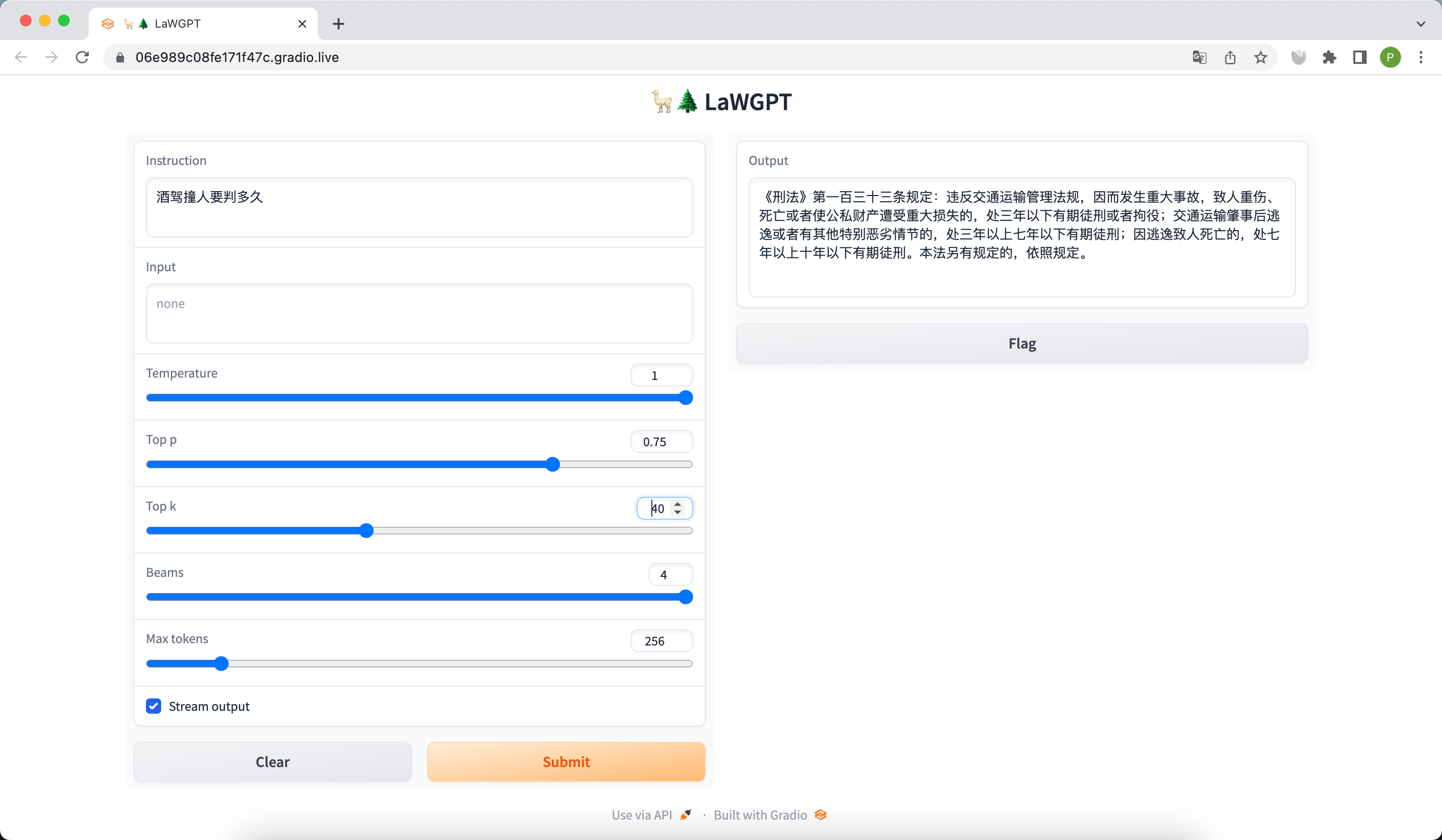
|
assets/demo/demo07.jpeg
ADDED
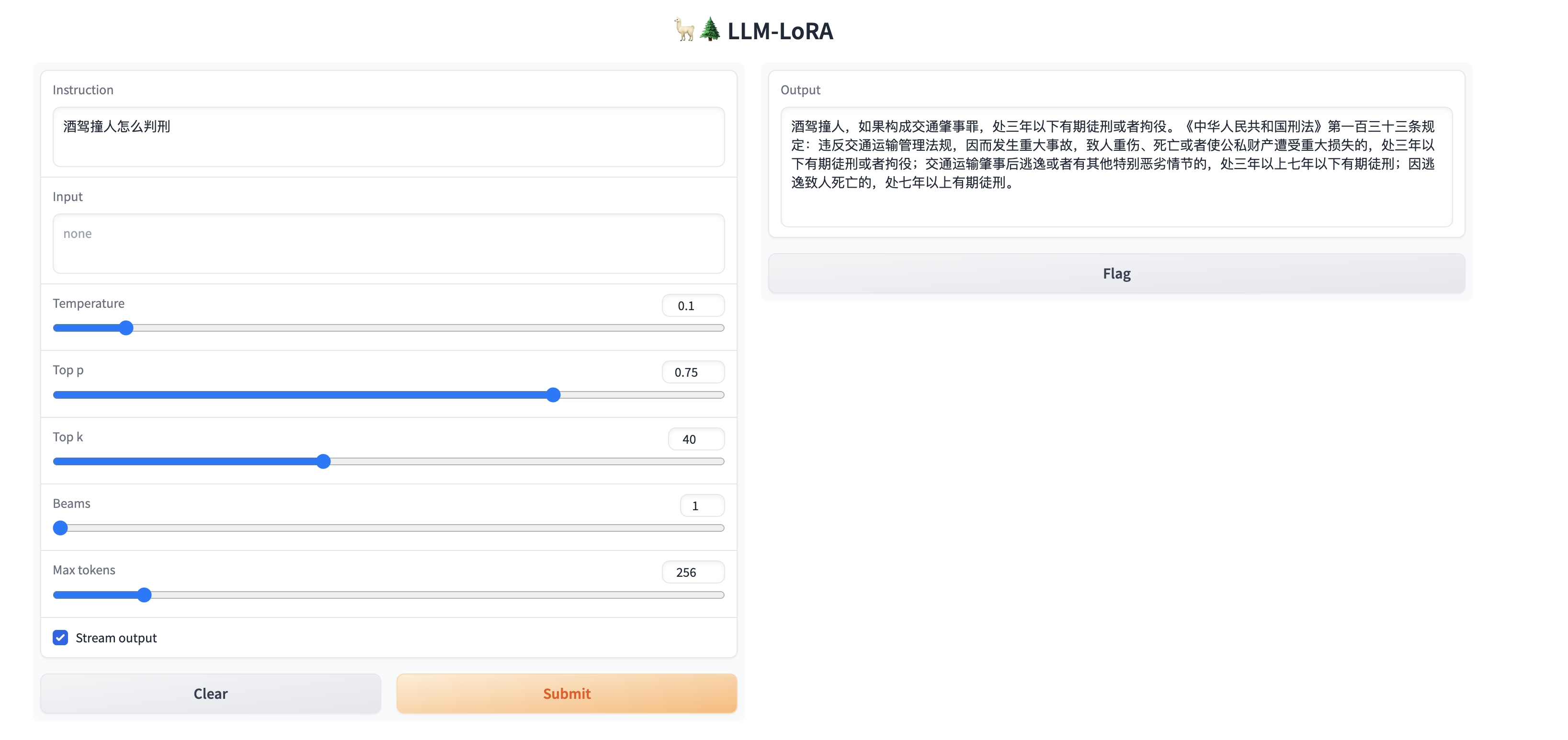
|
assets/demo/example-01.jpeg
ADDED
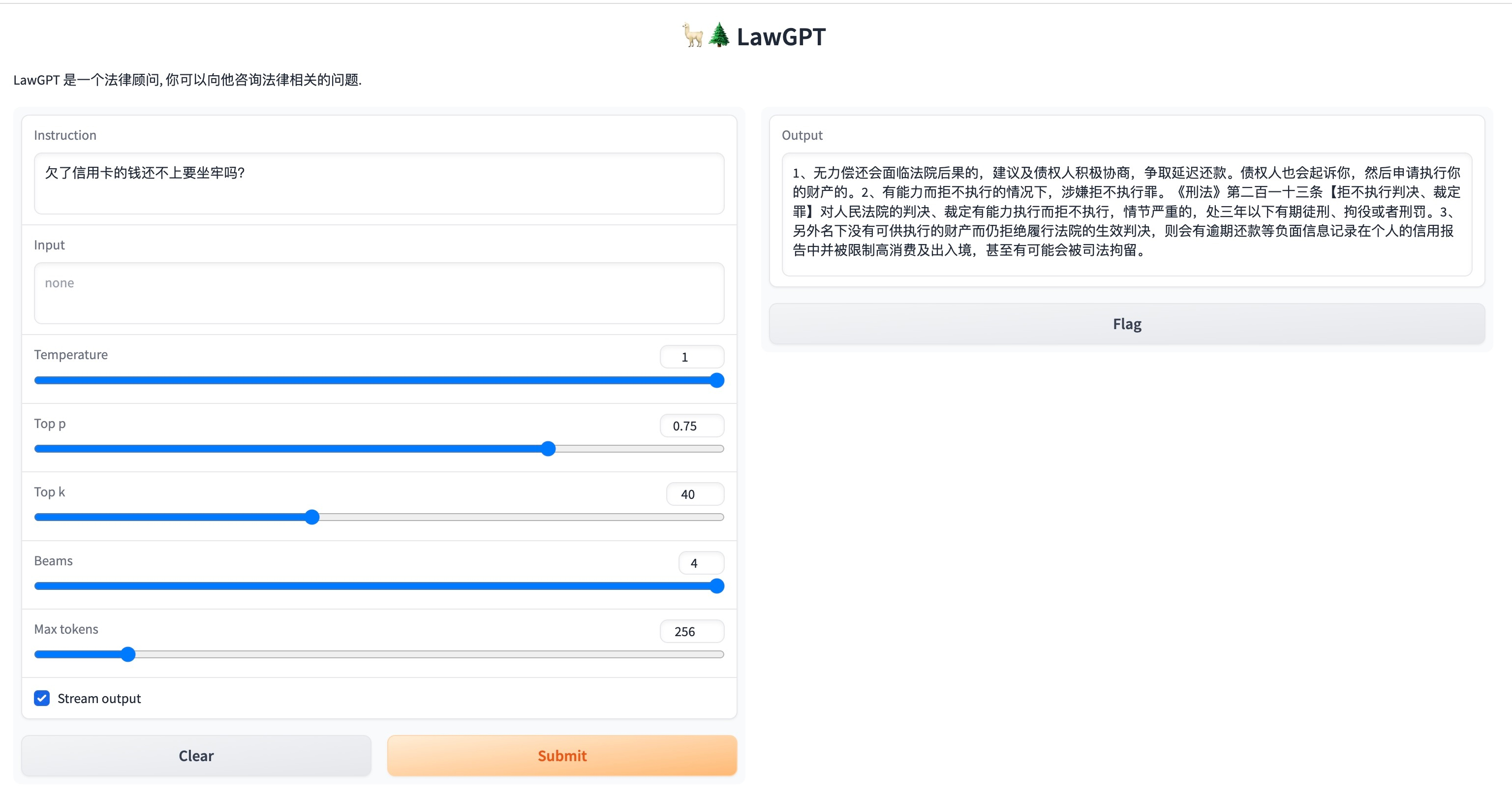
|
assets/demo/example-02.jpeg
ADDED
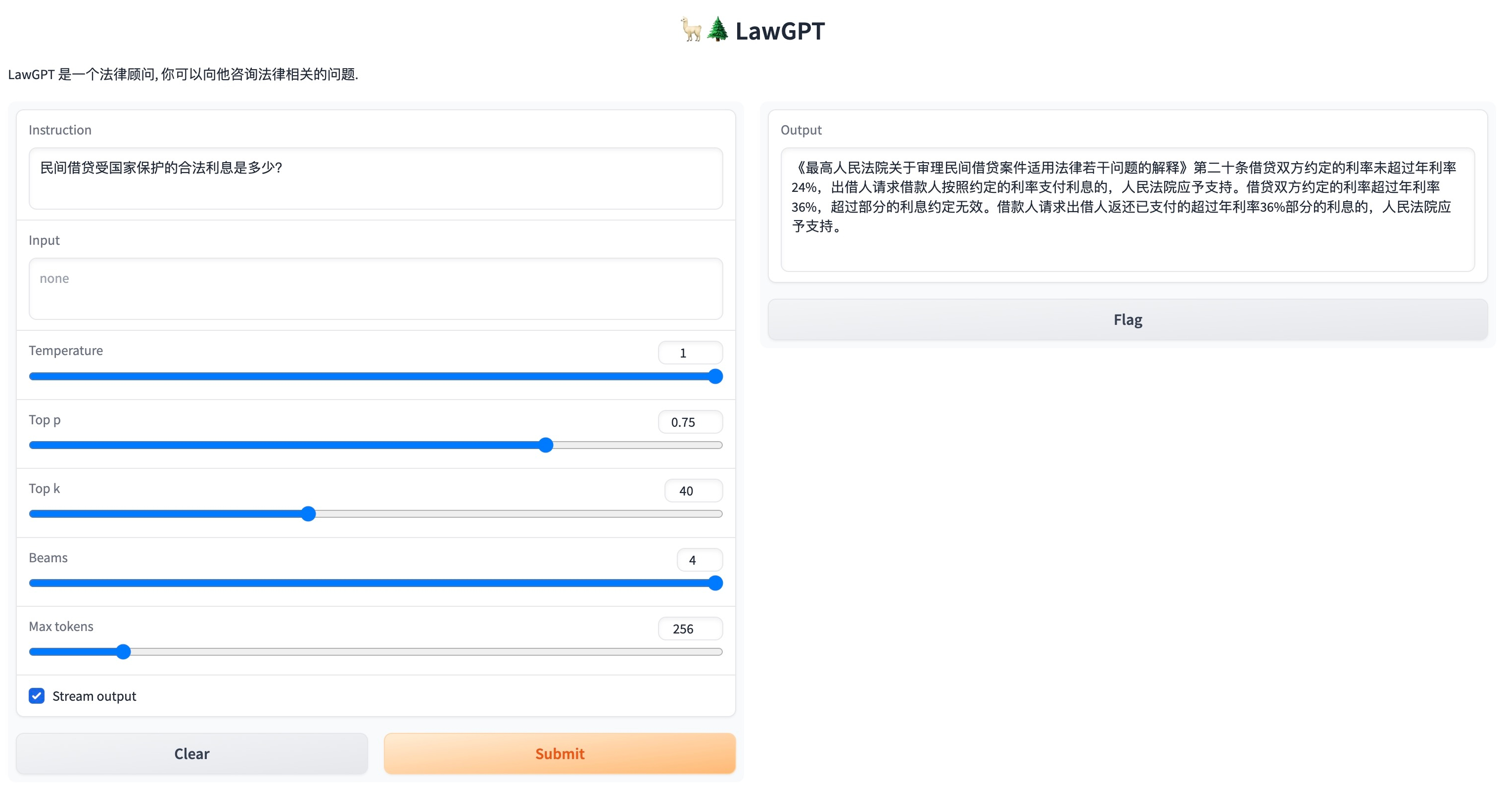
|
assets/demo/example-03.jpeg
ADDED
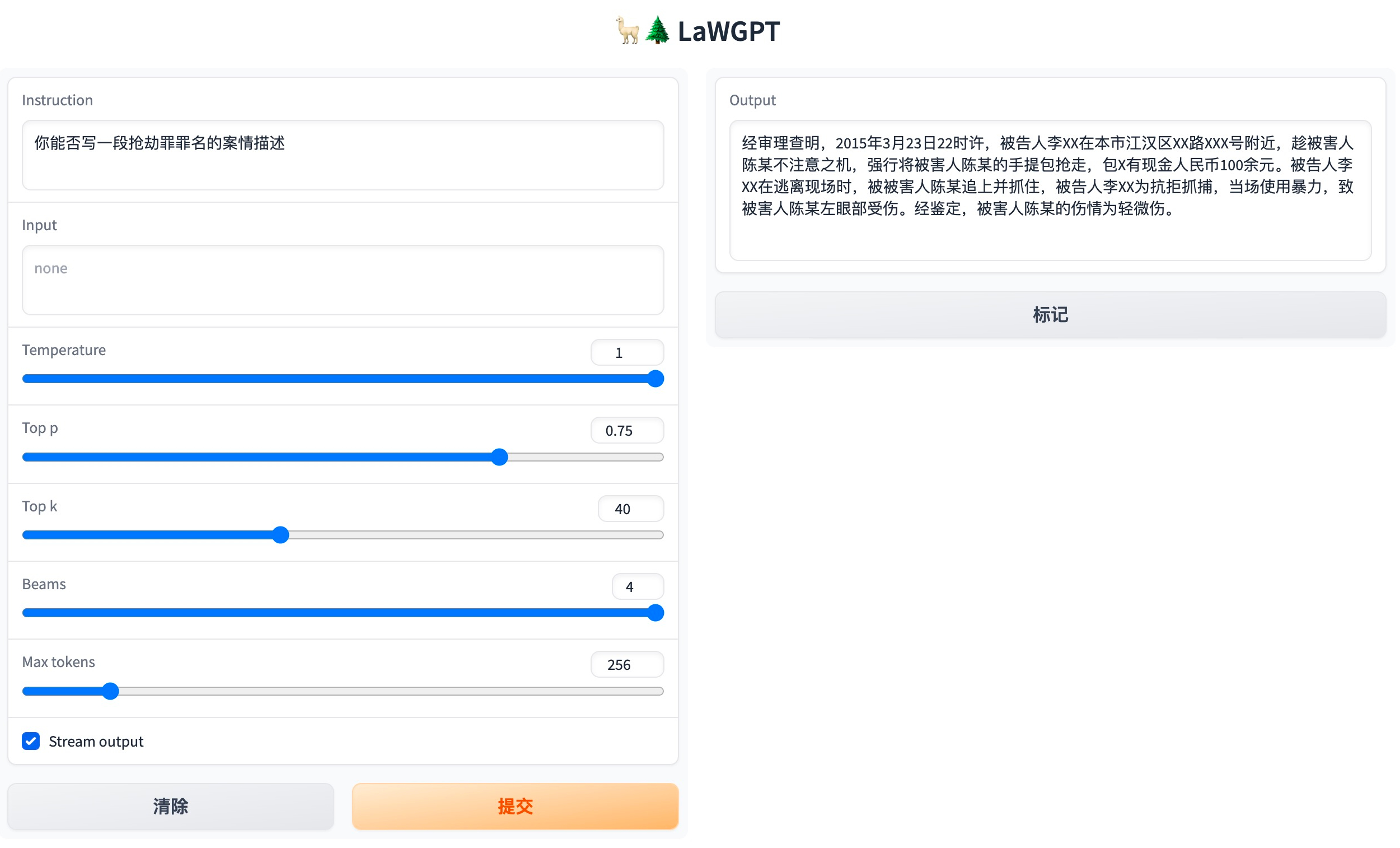
|
assets/demo/example-04.jpeg
ADDED

|
assets/demo/example-05.jpeg
ADDED
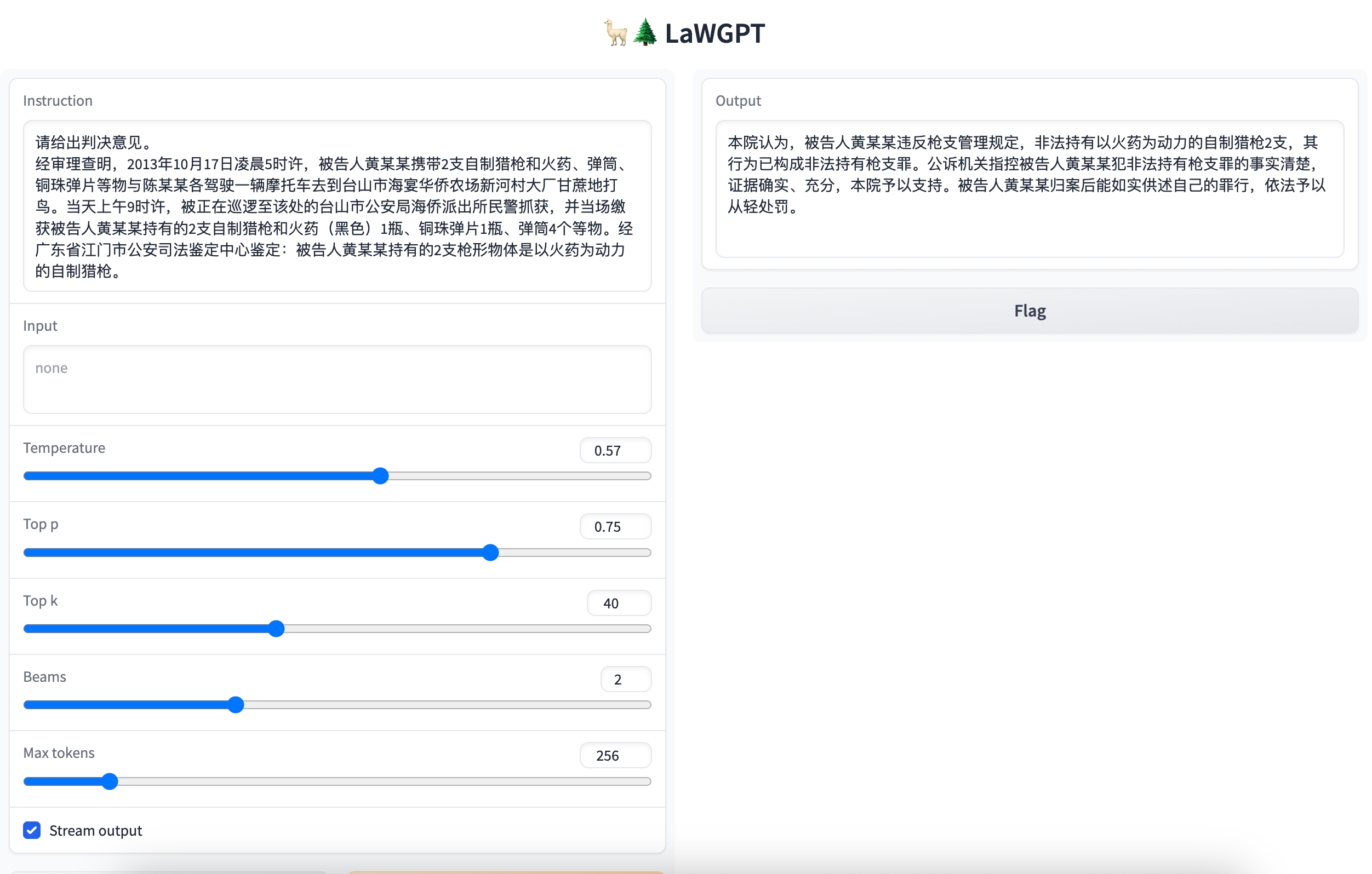
|
assets/demo/example-06.jpeg
ADDED

|
assets/logo/lamda.png
ADDED
|
|
assets/logo/lawgpt.jpeg
ADDED
|
|
data/.gitkeep
ADDED
|
File without changes
|
finetune.py
ADDED
|
@@ -0,0 +1,283 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
from typing import List
|
| 4 |
+
|
| 5 |
+
import fire
|
| 6 |
+
import torch
|
| 7 |
+
import transformers
|
| 8 |
+
from datasets import load_dataset
|
| 9 |
+
|
| 10 |
+
"""
|
| 11 |
+
Unused imports:
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
import bitsandbytes as bnb
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
from peft import (
|
| 17 |
+
LoraConfig,
|
| 18 |
+
get_peft_model,
|
| 19 |
+
get_peft_model_state_dict,
|
| 20 |
+
prepare_model_for_int8_training,
|
| 21 |
+
set_peft_model_state_dict,
|
| 22 |
+
)
|
| 23 |
+
from transformers import LlamaForCausalLM, LlamaTokenizer
|
| 24 |
+
|
| 25 |
+
from utils.prompter import Prompter
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def train(
|
| 29 |
+
# model/data params
|
| 30 |
+
base_model: str = "", # the only required argument
|
| 31 |
+
data_path: str = "yahma/alpaca-cleaned",
|
| 32 |
+
output_dir: str = "./lora-alpaca",
|
| 33 |
+
# training hyperparams
|
| 34 |
+
batch_size: int = 128,
|
| 35 |
+
micro_batch_size: int = 4,
|
| 36 |
+
num_epochs: int = 3,
|
| 37 |
+
learning_rate: float = 3e-4,
|
| 38 |
+
cutoff_len: int = 256,
|
| 39 |
+
val_set_size: int = 2000,
|
| 40 |
+
# lora hyperparams
|
| 41 |
+
lora_r: int = 8,
|
| 42 |
+
lora_alpha: int = 16,
|
| 43 |
+
lora_dropout: float = 0.05,
|
| 44 |
+
lora_target_modules: List[str] = [
|
| 45 |
+
"q_proj",
|
| 46 |
+
"v_proj",
|
| 47 |
+
],
|
| 48 |
+
# llm hyperparams
|
| 49 |
+
train_on_inputs: bool = True, # if False, masks out inputs in loss
|
| 50 |
+
add_eos_token: bool = True,
|
| 51 |
+
group_by_length: bool = False, # faster, but produces an odd training loss curve
|
| 52 |
+
# wandb params
|
| 53 |
+
wandb_project: str = "",
|
| 54 |
+
wandb_run_name: str = "",
|
| 55 |
+
wandb_watch: str = "", # options: false | gradients | all
|
| 56 |
+
wandb_log_model: str = "", # options: false | true
|
| 57 |
+
resume_from_checkpoint: str = None, # either training checkpoint or final adapter
|
| 58 |
+
prompt_template_name: str = "alpaca", # The prompt template to use, will default to alpaca.
|
| 59 |
+
):
|
| 60 |
+
if int(os.environ.get("LOCAL_RANK", 0)) == 0:
|
| 61 |
+
print(
|
| 62 |
+
f"Training Alpaca-LoRA model with params:\n"
|
| 63 |
+
f"base_model: {base_model}\n"
|
| 64 |
+
f"data_path: {data_path}\n"
|
| 65 |
+
f"output_dir: {output_dir}\n"
|
| 66 |
+
f"batch_size: {batch_size}\n"
|
| 67 |
+
f"micro_batch_size: {micro_batch_size}\n"
|
| 68 |
+
f"num_epochs: {num_epochs}\n"
|
| 69 |
+
f"learning_rate: {learning_rate}\n"
|
| 70 |
+
f"cutoff_len: {cutoff_len}\n"
|
| 71 |
+
f"val_set_size: {val_set_size}\n"
|
| 72 |
+
f"lora_r: {lora_r}\n"
|
| 73 |
+
f"lora_alpha: {lora_alpha}\n"
|
| 74 |
+
f"lora_dropout: {lora_dropout}\n"
|
| 75 |
+
f"lora_target_modules: {lora_target_modules}\n"
|
| 76 |
+
f"train_on_inputs: {train_on_inputs}\n"
|
| 77 |
+
f"add_eos_token: {add_eos_token}\n"
|
| 78 |
+
f"group_by_length: {group_by_length}\n"
|
| 79 |
+
f"wandb_project: {wandb_project}\n"
|
| 80 |
+
f"wandb_run_name: {wandb_run_name}\n"
|
| 81 |
+
f"wandb_watch: {wandb_watch}\n"
|
| 82 |
+
f"wandb_log_model: {wandb_log_model}\n"
|
| 83 |
+
f"resume_from_checkpoint: {resume_from_checkpoint or False}\n"
|
| 84 |
+
f"prompt template: {prompt_template_name}\n"
|
| 85 |
+
)
|
| 86 |
+
assert (
|
| 87 |
+
base_model
|
| 88 |
+
), "Please specify a --base_model, e.g. --base_model='huggyllama/llama-7b'"
|
| 89 |
+
gradient_accumulation_steps = batch_size // micro_batch_size
|
| 90 |
+
|
| 91 |
+
prompter = Prompter(prompt_template_name)
|
| 92 |
+
|
| 93 |
+
device_map = "auto"
|
| 94 |
+
world_size = int(os.environ.get("WORLD_SIZE", 1))
|
| 95 |
+
ddp = world_size != 1
|
| 96 |
+
if ddp:
|
| 97 |
+
device_map = {"": int(os.environ.get("LOCAL_RANK") or 0)}
|
| 98 |
+
gradient_accumulation_steps = gradient_accumulation_steps // world_size
|
| 99 |
+
|
| 100 |
+
# Check if parameter passed or if set within environ
|
| 101 |
+
use_wandb = len(wandb_project) > 0 or (
|
| 102 |
+
"WANDB_PROJECT" in os.environ and len(os.environ["WANDB_PROJECT"]) > 0
|
| 103 |
+
)
|
| 104 |
+
# Only overwrite environ if wandb param passed
|
| 105 |
+
if len(wandb_project) > 0:
|
| 106 |
+
os.environ["WANDB_PROJECT"] = wandb_project
|
| 107 |
+
if len(wandb_watch) > 0:
|
| 108 |
+
os.environ["WANDB_WATCH"] = wandb_watch
|
| 109 |
+
if len(wandb_log_model) > 0:
|
| 110 |
+
os.environ["WANDB_LOG_MODEL"] = wandb_log_model
|
| 111 |
+
|
| 112 |
+
model = LlamaForCausalLM.from_pretrained(
|
| 113 |
+
base_model,
|
| 114 |
+
load_in_8bit=True,
|
| 115 |
+
torch_dtype=torch.float16,
|
| 116 |
+
device_map=device_map,
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
tokenizer = LlamaTokenizer.from_pretrained(base_model)
|
| 120 |
+
|
| 121 |
+
tokenizer.pad_token_id = (
|
| 122 |
+
0 # unk. we want this to be different from the eos token
|
| 123 |
+
)
|
| 124 |
+
tokenizer.padding_side = "left" # Allow batched inference
|
| 125 |
+
|
| 126 |
+
def tokenize(prompt, add_eos_token=True):
|
| 127 |
+
# there's probably a way to do this with the tokenizer settings
|
| 128 |
+
# but again, gotta move fast
|
| 129 |
+
result = tokenizer(
|
| 130 |
+
prompt,
|
| 131 |
+
truncation=True,
|
| 132 |
+
max_length=cutoff_len,
|
| 133 |
+
padding=False,
|
| 134 |
+
return_tensors=None,
|
| 135 |
+
)
|
| 136 |
+
if (
|
| 137 |
+
result["input_ids"][-1] != tokenizer.eos_token_id
|
| 138 |
+
and len(result["input_ids"]) < cutoff_len
|
| 139 |
+
and add_eos_token
|
| 140 |
+
):
|
| 141 |
+
result["input_ids"].append(tokenizer.eos_token_id)
|
| 142 |
+
result["attention_mask"].append(1)
|
| 143 |
+
|
| 144 |
+
result["labels"] = result["input_ids"].copy()
|
| 145 |
+
|
| 146 |
+
return result
|
| 147 |
+
|
| 148 |
+
def generate_and_tokenize_prompt(data_point):
|
| 149 |
+
full_prompt = prompter.generate_prompt(
|
| 150 |
+
data_point["instruction"],
|
| 151 |
+
data_point["input"],
|
| 152 |
+
data_point["output"],
|
| 153 |
+
)
|
| 154 |
+
tokenized_full_prompt = tokenize(full_prompt)
|
| 155 |
+
if not train_on_inputs:
|
| 156 |
+
user_prompt = prompter.generate_prompt(
|
| 157 |
+
data_point["instruction"], data_point["input"]
|
| 158 |
+
)
|
| 159 |
+
tokenized_user_prompt = tokenize(
|
| 160 |
+
user_prompt, add_eos_token=add_eos_token
|
| 161 |
+
)
|
| 162 |
+
user_prompt_len = len(tokenized_user_prompt["input_ids"])
|
| 163 |
+
|
| 164 |
+
if add_eos_token:
|
| 165 |
+
user_prompt_len -= 1
|
| 166 |
+
|
| 167 |
+
tokenized_full_prompt["labels"] = [
|
| 168 |
+
-100
|
| 169 |
+
] * user_prompt_len + tokenized_full_prompt["labels"][
|
| 170 |
+
user_prompt_len:
|
| 171 |
+
] # could be sped up, probably
|
| 172 |
+
return tokenized_full_prompt
|
| 173 |
+
|
| 174 |
+
model = prepare_model_for_int8_training(model)
|
| 175 |
+
|
| 176 |
+
config = LoraConfig(
|
| 177 |
+
r=lora_r,
|
| 178 |
+
lora_alpha=lora_alpha,
|
| 179 |
+
target_modules=lora_target_modules,
|
| 180 |
+
lora_dropout=lora_dropout,
|
| 181 |
+
bias="none",
|
| 182 |
+
task_type="CAUSAL_LM",
|
| 183 |
+
)
|
| 184 |
+
model = get_peft_model(model, config)
|
| 185 |
+
|
| 186 |
+
if data_path.endswith(".json") or data_path.endswith(".jsonl"):
|
| 187 |
+
data = load_dataset("json", data_files=data_path)
|
| 188 |
+
else:
|
| 189 |
+
data = load_dataset(data_path)
|
| 190 |
+
|
| 191 |
+
if resume_from_checkpoint:
|
| 192 |
+
# Check the available weights and load them
|
| 193 |
+
checkpoint_name = os.path.join(
|
| 194 |
+
resume_from_checkpoint, "pytorch_model.bin"
|
| 195 |
+
) # Full checkpoint
|
| 196 |
+
if not os.path.exists(checkpoint_name):
|
| 197 |
+
checkpoint_name = os.path.join(
|
| 198 |
+
resume_from_checkpoint, "adapter_model.bin"
|
| 199 |
+
) # only LoRA model - LoRA config above has to fit
|
| 200 |
+
resume_from_checkpoint = (
|
| 201 |
+
False # So the trainer won't try loading its state
|
| 202 |
+
)
|
| 203 |
+
# The two files above have a different name depending on how they were saved, but are actually the same.
|
| 204 |
+
if os.path.exists(checkpoint_name):
|
| 205 |
+
print(f"Restarting from {checkpoint_name}")
|
| 206 |
+
adapters_weights = torch.load(checkpoint_name)
|
| 207 |
+
set_peft_model_state_dict(model, adapters_weights)
|
| 208 |
+
else:
|
| 209 |
+
print(f"Checkpoint {checkpoint_name} not found")
|
| 210 |
+
|
| 211 |
+
model.print_trainable_parameters() # Be more transparent about the % of trainable params.
|
| 212 |
+
|
| 213 |
+
if val_set_size > 0:
|
| 214 |
+
train_val = data["train"].train_test_split(
|
| 215 |
+
test_size=val_set_size, shuffle=True, seed=42
|
| 216 |
+
)
|
| 217 |
+
train_data = (
|
| 218 |
+
train_val["train"].shuffle().map(generate_and_tokenize_prompt)
|
| 219 |
+
)
|
| 220 |
+
val_data = (
|
| 221 |
+
train_val["test"].shuffle().map(generate_and_tokenize_prompt)
|
| 222 |
+
)
|
| 223 |
+
else:
|
| 224 |
+
train_data = data["train"].shuffle().map(generate_and_tokenize_prompt)
|
| 225 |
+
val_data = None
|
| 226 |
+
|
| 227 |
+
if not ddp and torch.cuda.device_count() > 1:
|
| 228 |
+
# keeps Trainer from trying its own DataParallelism when more than 1 gpu is available
|
| 229 |
+
model.is_parallelizable = True
|
| 230 |
+
model.model_parallel = True
|
| 231 |
+
|
| 232 |
+
trainer = transformers.Trainer(
|
| 233 |
+
model=model,
|
| 234 |
+
train_dataset=train_data,
|
| 235 |
+
eval_dataset=val_data,
|
| 236 |
+
args=transformers.TrainingArguments(
|
| 237 |
+
per_device_train_batch_size=micro_batch_size,
|
| 238 |
+
gradient_accumulation_steps=gradient_accumulation_steps,
|
| 239 |
+
warmup_ratio=0.1,
|
| 240 |
+
num_train_epochs=num_epochs,
|
| 241 |
+
learning_rate=learning_rate,
|
| 242 |
+
fp16=True,
|
| 243 |
+
logging_steps=10,
|
| 244 |
+
optim="adamw_torch",
|
| 245 |
+
evaluation_strategy="steps" if val_set_size > 0 else "no",
|
| 246 |
+
save_strategy="steps",
|
| 247 |
+
eval_steps=50 if val_set_size > 0 else None,
|
| 248 |
+
save_steps=50,
|
| 249 |
+
output_dir=output_dir,
|
| 250 |
+
save_total_limit=5,
|
| 251 |
+
load_best_model_at_end=True if val_set_size > 0 else False,
|
| 252 |
+
ddp_find_unused_parameters=False if ddp else None,
|
| 253 |
+
group_by_length=group_by_length,
|
| 254 |
+
report_to="wandb" if use_wandb else None,
|
| 255 |
+
run_name=wandb_run_name if use_wandb else None,
|
| 256 |
+
),
|
| 257 |
+
data_collator=transformers.DataCollatorForSeq2Seq(
|
| 258 |
+
tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True
|
| 259 |
+
),
|
| 260 |
+
)
|
| 261 |
+
model.config.use_cache = False
|
| 262 |
+
|
| 263 |
+
old_state_dict = model.state_dict
|
| 264 |
+
model.state_dict = (
|
| 265 |
+
lambda self, *_, **__: get_peft_model_state_dict(
|
| 266 |
+
self, old_state_dict()
|
| 267 |
+
)
|
| 268 |
+
).__get__(model, type(model))
|
| 269 |
+
|
| 270 |
+
if torch.__version__ >= "2" and sys.platform != "win32":
|
| 271 |
+
model = torch.compile(model)
|
| 272 |
+
|
| 273 |
+
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
|
| 274 |
+
|
| 275 |
+
model.save_pretrained(output_dir)
|
| 276 |
+
|
| 277 |
+
print(
|
| 278 |
+
"\n If there's a warning about missing keys above, please disregard :)"
|
| 279 |
+
)
|
| 280 |
+
|
| 281 |
+
|
| 282 |
+
if __name__ == "__main__":
|
| 283 |
+
fire.Fire(train)
|
infer.py
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import json
|
| 3 |
+
|
| 4 |
+
import fire
|
| 5 |
+
import torch
|
| 6 |
+
from peft import PeftModel
|
| 7 |
+
from transformers import GenerationConfig, LlamaForCausalLM, LlamaTokenizer
|
| 8 |
+
|
| 9 |
+
from utils.prompter import Prompter
|
| 10 |
+
|
| 11 |
+
if torch.cuda.is_available():
|
| 12 |
+
device = "cuda"
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class Infer():
|
| 16 |
+
def __init__(
|
| 17 |
+
self,
|
| 18 |
+
load_8bit: bool = False,
|
| 19 |
+
base_model: str = "",
|
| 20 |
+
lora_weights: str = "",
|
| 21 |
+
prompt_template: str = "", # The prompt template to use, will default to alpaca.
|
| 22 |
+
):
|
| 23 |
+
prompter = Prompter(prompt_template)
|
| 24 |
+
tokenizer = LlamaTokenizer.from_pretrained(base_model)
|
| 25 |
+
model = LlamaForCausalLM.from_pretrained(
|
| 26 |
+
base_model,
|
| 27 |
+
load_in_8bit=load_8bit,
|
| 28 |
+
torch_dtype=torch.float16,
|
| 29 |
+
device_map="auto",
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
try:
|
| 33 |
+
print(f"Using lora {lora_weights}")
|
| 34 |
+
model = PeftModel.from_pretrained(
|
| 35 |
+
model,
|
| 36 |
+
lora_weights,
|
| 37 |
+
torch_dtype=torch.float16,
|
| 38 |
+
)
|
| 39 |
+
except:
|
| 40 |
+
print("*"*50, "\n Attention! No Lora Weights \n", "*"*50)
|
| 41 |
+
|
| 42 |
+
# unwind broken decapoda-research config
|
| 43 |
+
model.config.pad_token_id = tokenizer.pad_token_id = 0 # unk
|
| 44 |
+
model.config.bos_token_id = 1
|
| 45 |
+
model.config.eos_token_id = 2
|
| 46 |
+
if not load_8bit:
|
| 47 |
+
model.half() # seems to fix bugs for some users.
|
| 48 |
+
|
| 49 |
+
model.eval()
|
| 50 |
+
|
| 51 |
+
if torch.__version__ >= "2" and sys.platform != "win32":
|
| 52 |
+
model = torch.compile(model)
|
| 53 |
+
|
| 54 |
+
self.base_model = base_model
|
| 55 |
+
self.lora_weights = lora_weights
|
| 56 |
+
self.model = model
|
| 57 |
+
self.prompter = prompter
|
| 58 |
+
self.tokenizer = tokenizer
|
| 59 |
+
|
| 60 |
+
def generate_output(
|
| 61 |
+
self,
|
| 62 |
+
instruction,
|
| 63 |
+
input=None,
|
| 64 |
+
temperature=0.1,
|
| 65 |
+
top_p=0.75,
|
| 66 |
+
top_k=40,
|
| 67 |
+
num_beams=1,
|
| 68 |
+
max_new_tokens=256,
|
| 69 |
+
**kwargs,
|
| 70 |
+
):
|
| 71 |
+
prompt = self.prompter.generate_prompt(instruction, input)
|
| 72 |
+
inputs = self.tokenizer(prompt, return_tensors="pt")
|
| 73 |
+
input_ids = inputs["input_ids"].to(device)
|
| 74 |
+
generation_config = GenerationConfig(
|
| 75 |
+
temperature=temperature,
|
| 76 |
+
top_p=top_p,
|
| 77 |
+
top_k=top_k,
|
| 78 |
+
num_beams=num_beams,
|
| 79 |
+
# repetition_penalty=10.0,
|
| 80 |
+
**kwargs,
|
| 81 |
+
)
|
| 82 |
+
with torch.no_grad():
|
| 83 |
+
generation_output = self.model.generate(
|
| 84 |
+
input_ids=input_ids,
|
| 85 |
+
generation_config=generation_config,
|
| 86 |
+
return_dict_in_generate=True,
|
| 87 |
+
output_scores=True,
|
| 88 |
+
max_new_tokens=max_new_tokens,
|
| 89 |
+
)
|
| 90 |
+
s = generation_output.sequences[0]
|
| 91 |
+
output = self.tokenizer.decode(s)
|
| 92 |
+
return self.prompter.get_response(output)
|
| 93 |
+
|
| 94 |
+
def infer_from_file(self, infer_data_path):
|
| 95 |
+
with open(infer_data_path) as f:
|
| 96 |
+
for line in f:
|
| 97 |
+
data = json.loads(line)
|
| 98 |
+
instruction = data["instruction"]
|
| 99 |
+
output = data["output"]
|
| 100 |
+
print('=' * 100)
|
| 101 |
+
print(f"Base Model: {self.base_model} Lora Weights: {self.lora_weights}")
|
| 102 |
+
print("Instruction:\n", instruction)
|
| 103 |
+
model_output = self.generate_output(instruction)
|
| 104 |
+
print("Model Output:\n", model_output)
|
| 105 |
+
print("Ground Truth:\n", output)
|
| 106 |
+
print('=' * 100)
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def main(
|
| 110 |
+
load_8bit: bool = False,
|
| 111 |
+
base_model: str = "",
|
| 112 |
+
lora_weights: str = "",
|
| 113 |
+
prompt_template: str = "", # The prompt template to use, will default to alpaca.
|
| 114 |
+
infer_data_path: str = "",
|
| 115 |
+
):
|
| 116 |
+
infer = Infer(
|
| 117 |
+
load_8bit=load_8bit,
|
| 118 |
+
base_model=base_model,
|
| 119 |
+
lora_weights=lora_weights,
|
| 120 |
+
prompt_template=prompt_template
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
try:
|
| 124 |
+
infer.infer_from_file(infer_data_path)
|
| 125 |
+
except Exception as e:
|
| 126 |
+
print(e, "Read infer_data_path Failed! Now Interactive Mode: ")
|
| 127 |
+
while True:
|
| 128 |
+
print('=' * 100)
|
| 129 |
+
instruction = input("请输入您的问题: ")
|
| 130 |
+
print("LaWGPT:")
|
| 131 |
+
print(infer.generate_output(instruction))
|
| 132 |
+
print('=' * 100)
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
if __name__ == "__main__":
|
| 136 |
+
fire.Fire(main)
|
merge.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import transformers
|
| 5 |
+
from peft import PeftModel
|
| 6 |
+
from transformers import LlamaForCausalLM, LlamaTokenizer # noqa: F402
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
import argparse
|
| 10 |
+
parser = argparse.ArgumentParser(description='Merge Base Model and Lora')
|
| 11 |
+
parser.add_argument('--base_model', type=str, default="minlik/chinese-llama-7b-merged", help='base model path')
|
| 12 |
+
parser.add_argument('--lora_model', type=str, default="entity303/legal-lora-7b", help='lora model path')
|
| 13 |
+
parser.add_argument('--output_dir', type=str, default="./models/base_models/llama-7b-legal-lora-merged", help='output model path')
|
| 14 |
+
args = parser.parse_args()
|
| 15 |
+
|
| 16 |
+
BASE_MODEL = args.base_model
|
| 17 |
+
LORA_MODEL = args.lora_model
|
| 18 |
+
OUTPUT_DIR = args.output_dir
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
assert (
|
| 22 |
+
BASE_MODEL
|
| 23 |
+
), "Please specify a value for BASE_MODEL environment variable, e.g. `export BASE_MODEL=huggyllama/llama-7b`" # noqa: E501
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
print(f"{'*'*20} Using base model: {BASE_MODEL} {'*'*20}")
|
| 27 |
+
print(f"{'*'*20} Using lora model: {LORA_MODEL} {'*'*20}")
|
| 28 |
+
print(f"{'*'*20} Saving to: {OUTPUT_DIR} {'*'*20}")
|
| 29 |
+
|
| 30 |
+
tokenizer = LlamaTokenizer.from_pretrained(BASE_MODEL)
|
| 31 |
+
|
| 32 |
+
base_model = LlamaForCausalLM.from_pretrained(
|
| 33 |
+
BASE_MODEL,
|
| 34 |
+
load_in_8bit=False,
|
| 35 |
+
torch_dtype=torch.float16,
|
| 36 |
+
device_map={"": "cpu"},
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
first_weight = base_model.model.layers[0].self_attn.q_proj.weight
|
| 40 |
+
first_weight_old = first_weight.clone()
|
| 41 |
+
|
| 42 |
+
lora_model = PeftModel.from_pretrained(
|
| 43 |
+
base_model,
|
| 44 |
+
LORA_MODEL,
|
| 45 |
+
device_map={"": "cpu"},
|
| 46 |
+
torch_dtype=torch.float16,
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
lora_weight = lora_model.base_model.model.model.layers[
|
| 50 |
+
0
|
| 51 |
+
].self_attn.q_proj.weight
|
| 52 |
+
|
| 53 |
+
assert torch.allclose(first_weight_old, first_weight)
|
| 54 |
+
|
| 55 |
+
# merge weights - new merging method from peft
|
| 56 |
+
lora_model = lora_model.merge_and_unload()
|
| 57 |
+
|
| 58 |
+
lora_model.train(False)
|
| 59 |
+
|
| 60 |
+
# did we do anything?
|
| 61 |
+
assert not torch.allclose(first_weight_old, first_weight)
|
| 62 |
+
|
| 63 |
+
lora_model_sd = lora_model.state_dict()
|
| 64 |
+
deloreanized_sd = {
|
| 65 |
+
k.replace("base_model.model.", ""): v
|
| 66 |
+
for k, v in lora_model_sd.items()
|
| 67 |
+
if "lora" not in k
|
| 68 |
+
}
|
| 69 |
+
|
| 70 |
+
LlamaForCausalLM.save_pretrained(
|
| 71 |
+
base_model, OUTPUT_DIR, state_dict=deloreanized_sd, max_shard_size="2048MB"
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
LlamaTokenizer.save_pretrained(tokenizer, OUTPUT_DIR)
|
models/base_models/.gitkeep
ADDED
|
File without changes
|
models/lora_weights/.gitkeep
ADDED
|
File without changes
|
outputs/.gitkeep
ADDED
|
File without changes
|
requirements.txt
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
accelerate
|
| 2 |
+
appdirs
|
| 3 |
+
bitsandbytes
|
| 4 |
+
black
|
| 5 |
+
black[jupyter]
|
| 6 |
+
datasets
|
| 7 |
+
fire
|
| 8 |
+
git+https://github.com/huggingface/peft.git@e536616888d51b453ed354a6f1e243fecb02ea08
|
| 9 |
+
git+https://github.com/huggingface/transformers.git
|
| 10 |
+
gradio
|
| 11 |
+
sentencepiece
|
| 12 |
+
wandb
|
| 13 |
+
scipy
|
| 14 |
+
socksio
|
resources/criminal_charges.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
resources/example_infer_data.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"instruction":"请介绍赌博罪的定义。","input":"","output":"无"}
|
| 2 |
+
{"instruction":"请问加班工资怎么算?","input":"","output":"无"}
|
| 3 |
+
{"instruction":"民间借贷受国家保护的合法利息是多少?","input":"","output":"无"}
|
| 4 |
+
{"instruction":"欠了信用卡的钱还不上要坐牢吗?","input":"","output":"无"}
|
| 5 |
+
{"instruction":"你能否写一段抢劫罪罪名的案情描述?","input":"","output":"无"}
|
resources/example_instruction_train.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"content": "中华人民共和国最高人民法院 再 审 决 定 书(2022)最高法刑申136号 原审被告人张某某犯挪用资金罪和伪造、变造国家机关公文罪一案,山西省运城市盐湖区人民法院于2012年5月2日以(2012)运盐刑初字第69号刑事判决,认定张克云犯贪污罪,判处有期徒刑十二年,犯伪造、变造国家机关公文罪,判处有期徒刑三年,决定执行有期徒刑十三年。宣判后,张克云不服,提出上诉。山西省运城市中级人民法院于2012年11月12日以(2012)运中刑二终字第125号刑事裁定,驳回上诉,维持原判。裁判生效后,张克云不服,提出申诉。运城市中级人民法院于2013年1月7日以(2013)运中刑申字第3号驳回申诉通知,驳回其申诉。山西省高级人民法院于2017年7月13日以(2013)晋刑监字第8号再审决定,提审本案,并于2019年12月24日以(2017)晋刑再第2号刑事判决,认定张克云犯挪用资金罪,判处有期徒刑七年六个月,与原判伪造、变造国家机关公文罪被判处的有期徒刑三年数罪并罚,决定执行有期徒刑十年。张克云仍不服,以原审认定事实错误,其作为学校董事长、全资投资人有权决定学校相关款项用途,学校仍欠其债务,个人账户用于学校经费开支,没有挪用资金的动机和行为,不构成挪用资金罪等为由,向本院提出申诉。本院经审查认为,原审生效裁判对挪用资金罪定罪量刑的证据不确实、不充分,依法应当予以排除。依照《中华人民共和国刑事诉讼法》第二百五十三条第二项、第二百五十四条第二款、第二百五十五条的规定,决定如下:指令河南省高级人民法院对本案进行再审。二〇二二年十二月二十九日"
|
| 4 |
+
},
|
| 5 |
+
{
|
| 6 |
+
"content":"中华人民共和国最高人民法院 驳 回 申 诉 通 知 书(2022)最高法刑申122号 袁某银、袁某财:你们因原审被告人袁德银故意伤害一案,对江苏省南京市溧水区人民法院(2014)溧刑初字第268号刑事判决、南京市中级人民法院(2015)宁刑终字第433号刑事裁定不服,以被害人朱宽荣住院期间的CT(136678号)报告并未显示其左侧4、5、6、7、8肋骨骨折,出院记录及137470号、143006号CT报告均系伪造,江苏省高级人民法院(2019)苏刑申172号驳回申诉通知书对137470号CT报告的形成时间认定错误为由,向本院提出申诉,请求撤销原判,依法重新审理本案。本院依法组成合议庭认真审查后认为,原审认定原审被告人袁德银因邻里纠纷,殴打被害人朱宽荣致其左胸多发肋骨骨折,构成轻伤二级,其行为构成故意伤害罪,并无不当。关于你们提出的原审认定被害人朱宽荣轻伤二级的证据系伪造的申诉理由。首先,根据你们提供的136678号CT报告,朱宽荣于2015年2月12日入院时经CT检查被诊断为左侧多发肋骨骨折,该份CT报告虽未明确骨折的具体位置,但与出院记录记载的“左侧多发肋骨骨折(4、5、6、7、8)”并不矛盾。根据《人体损伤程度鉴定标准》的规定,肋骨骨折2处以上即构成轻伤二级,故鉴定意见认定朱宽荣的损伤构成轻伤二级并无不当。其次,你们主张出院记录、137470号和143006号CT报告系伪造,但并未提供证据证实。即使排除这两份CT报告,也不影响对本案事实的认定。再次,我院对申诉进行复查的对象是已经发生法律效力的判决、裁定,本案的生效裁判是(2014)溧刑初字第268号刑事判决和(2015)宁刑终字第433号刑事裁定,江苏省高级人民法院作出的驳回申诉通知书不属于我院复查的范围。综上,本院认为,你们的申诉不符合《中华人民共和国刑事诉讼法》第二百五十三条规定的应当重新审判的情形,予以驳回。望你们尊重人民法院的生效裁判,自觉服判息诉。特此通知。二〇二二年十二月十四日"
|
| 7 |
+
}
|
| 8 |
+
]
|
resources/example_instruction_tune.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"instruction": "酒驾撞人要判多久?",
|
| 4 |
+
"input": "",
|
| 5 |
+
"output": "《刑法》第一百三十三条规定:违反交通运输管理法规,因而发生重大事故,致人重伤、死广或者使公私财产遭受重大损失的,处三年以下有期徒刑或者拘役;交通运输肇事后逃逸,致人重伤的,处三年以上七年以下有期徒刑。交通肇事后逃逸致人死亡的,处七年以上有期徒刑。"
|
| 6 |
+
},
|
| 7 |
+
{
|
| 8 |
+
"instruction": "偷狗被派出所抓到,会怎么处理?",
|
| 9 |
+
"input": "",
|
| 10 |
+
"output": "取决于偷盗的狗的价值,可能按盗窃罪的罪名处理。如果价值达到犯罪标准,就构成盗窃罪,要承担刑事责任;如果不到犯罪标准,就是治安处罚、罚款或者拘留治安处罚这会涉嫌构成盗窃。如果不到一千元,则不会构成犯罪。如果超过一千元,则可能会是构成犯罪的。"
|
| 11 |
+
}
|
| 12 |
+
]
|
resources/legal_vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
scripts/finetune.sh
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
export WANDB_MODE=disabled # 禁用wandb
|
| 3 |
+
|
| 4 |
+
# 使用chinese-alpaca-plus-7b-merged模型在law_data.json数据集上finetune
|
| 5 |
+
experiment_name="chinese-alpaca-plus-7b-law-e1"
|
| 6 |
+
|
| 7 |
+
# 单卡或者模型并行
|
| 8 |
+
python finetune.py \
|
| 9 |
+
--base_model "minlik/chinese-alpaca-plus-7b-merged" \
|
| 10 |
+
--data_path "./data/finetune_law_data.json" \
|
| 11 |
+
--output_dir "./outputs/"${experiment_name} \
|
| 12 |
+
--batch_size 64 \
|
| 13 |
+
--micro_batch_size 8 \
|
| 14 |
+
--num_epochs 20 \
|
| 15 |
+
--learning_rate 3e-4 \
|
| 16 |
+
--cutoff_len 256 \
|
| 17 |
+
--val_set_size 0 \
|
| 18 |
+
--lora_r 8 \
|
| 19 |
+
--lora_alpha 16 \
|
| 20 |
+
--lora_dropout 0.05 \
|
| 21 |
+
--lora_target_modules "[q_proj,v_proj]" \
|
| 22 |
+
--train_on_inputs False \
|
| 23 |
+
--add_eos_token True \
|
| 24 |
+
--group_by_length False \
|
| 25 |
+
--wandb_project "" \
|
| 26 |
+
--wandb_run_name "" \
|
| 27 |
+
--wandb_watch "" \
|
| 28 |
+
--wandb_log_model "" \
|
| 29 |
+
--resume_from_checkpoint "./outputs/"${experiment_name} \
|
| 30 |
+
--prompt_template_name "alpaca" \
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
# 多卡数据并行
|
| 34 |
+
# WORLD_SIZE=8 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 torchrun --nproc_per_node=8 --master_port=1234 finetune.py \
|
| 35 |
+
# --base_model "minlik/chinese-alpaca-plus-7b-merged" \
|
| 36 |
+
# --data_path "./data/finetune_law_data.json" \
|
| 37 |
+
# --output_dir "./outputs/"${experiment_name} \
|
| 38 |
+
# --batch_size 64 \
|
| 39 |
+
# --micro_batch_size 8 \
|
| 40 |
+
# --num_epochs 20 \
|
| 41 |
+
# --learning_rate 3e-4 \
|
| 42 |
+
# --cutoff_len 256 \
|
| 43 |
+
# --val_set_size 0 \
|
| 44 |
+
# --lora_r 8 \
|
| 45 |
+
# --lora_alpha 16 \
|
| 46 |
+
# --lora_dropout 0.05 \
|
| 47 |
+
# --lora_target_modules "[q_proj,v_proj]" \
|
| 48 |
+
# --train_on_inputs True \
|
| 49 |
+
# --add_eos_token True \
|
| 50 |
+
# --group_by_length False \
|
| 51 |
+
# --wandb_project \
|
| 52 |
+
# --wandb_run_name \
|
| 53 |
+
# --wandb_watch \
|
| 54 |
+
# --wandb_log_model \
|
| 55 |
+
# --resume_from_checkpoint "./outputs/"${experiment_name} \
|
| 56 |
+
# --prompt_template_name "alpaca" \
|
scripts/infer.sh
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
python infer.py \
|
| 3 |
+
--load_8bit True \
|
| 4 |
+
--base_model 'minlik/chinese-llama-7b-merged' \
|
| 5 |
+
--lora_weights 'entity303/lawgpt-lora-7b' \
|
| 6 |
+
--prompt_template 'law_template' \
|
| 7 |
+
--infer_data_path './resources/example_infer_data.json'
|
scripts/merge.sh
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python merge.py \
|
| 2 |
+
--base_model 'minlik/chinese-llama-7b-merged' \
|
| 3 |
+
--lora_model 'entity303/legal-lora-7b' \
|
| 4 |
+
--output_dir './models/base_models/legal_base-7b' \
|
scripts/train_clm.sh
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
WORLD_SIZE=8 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 torchrun --nproc_per_node=8 --master_port=1235 train_clm.py \
|
| 4 |
+
--base_model './models/base_models/chinese_llama_7b' \
|
| 5 |
+
--data_path './data/train_clm_data.json' \
|
| 6 |
+
--output_dir './outputs/train-clm' \
|
| 7 |
+
--batch_size 128 \
|
| 8 |
+
--micro_batch_size 8 \
|
| 9 |
+
--num_epochs 1 \
|
| 10 |
+
--learning_rate 0.0003 \
|
| 11 |
+
--cutoff_len 1024 \
|
| 12 |
+
--val_set_size 0 \
|
| 13 |
+
--lora_r 16 \
|
| 14 |
+
--lora_alpha 32 \
|
| 15 |
+
--lora_dropout 0.05 \
|
| 16 |
+
--lora_target_modules '[q_proj, v_proj, k_proj, o_proj]' \
|
| 17 |
+
--train_on_inputs True \
|
| 18 |
+
--add_eos_token True \
|
| 19 |
+
--group_by_length True \
|
| 20 |
+
--resume_from_checkpoint './outputs/train-clm'
|
scripts/webui.sh
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
###
|
| 3 |
+
# Copyright (C) Baidu Ltd. All rights reserved.
|
| 4 |
+
# @FilePath: /Law_llama/scripts/webui.sh
|
| 5 |
+
# @Autor: [email protected]
|
| 6 |
+
# @Date: 2023-08-23 10:25:20
|
| 7 |
+
# @Description:
|
| 8 |
+
###
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
# 使用huggingface上已经训练好的模型
|
| 12 |
+
XPU_VISIBLE_DEVICES=4 python3 -m xacc webui.py \
|
| 13 |
+
--load_8bit False \
|
| 14 |
+
--base_model 'ziqingyang/chinese-alpaca-2-7b' \
|
| 15 |
+
--lora_weights 'entity303/lawgpt-lora-7b-v' \
|
| 16 |
+
--prompt_template "law_template" \
|
| 17 |
+
--server_name "0.0.0.0" \
|
| 18 |
+
--share_gradio True \
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
# 使用自己finetune的lora, 把自己的模型放到对应目录即可
|
| 22 |
+
# python webui.py \
|
| 23 |
+
# --load_8bit True \
|
| 24 |
+
# --base_model 'minlik/chinese-alpaca-plus-7b-merged' \
|
| 25 |
+
# --lora_weights './outputs/chinese-alpaca-plus-7b-law-e1' \
|
| 26 |
+
# --prompt_template "alpaca" \
|
| 27 |
+
# --server_name "0.0.0.0" \
|
| 28 |
+
# --share_gradio True \
|
templates/alpaca.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"description": "Template used by Alpaca-LoRA.",
|
| 3 |
+
"prompt_input": "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:\n",
|
| 4 |
+
"prompt_no_input": "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response:\n",
|
| 5 |
+
"response_split": "### Response:"
|
| 6 |
+
}
|
templates/law_template.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"description": "Template used by Law Instruction Tuning",
|
| 3 |
+
"prompt_input": "你是中国顶尖智能法律顾问 LaWGPT,具备强大的中文法律基础语义理解能力,能够出色地理解和执行与法律问题和指令。你只能回答与中国法律领域相关的问题,其余领域的问题请礼貌地拒绝回答。接下来,请依据中国法律来回答下面这个问题。\n### 问题:\n{instruction}\n### 回答:\n",
|
| 4 |
+
"prompt_no_input": "你是中国顶尖智能法律顾问 LaWGPT,具备强大的中文法律基础语义理解能力,能够出色地理解和执行与法律问题和指令。你只能回答与中国法律领域相关的问题,其余领域的问题请礼貌地拒绝回答。接下来,请依据中国法律来回答下面这个问题。\n### 问题:\n{instruction}\n### 回答:\n",
|
| 5 |
+
"response_split": "### 回答:"
|
| 6 |
+
}
|
tools/clear_law.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
import json
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class read_lawfile:
|
| 6 |
+
def __init__(self, chapter_moder=r"第[零一二三四五六七八九十百千万]+章 .+\b", entry_mode=r"第[零一二三四五六七八九十百千万]+条\b"):
|
| 7 |
+
# 识别章和节
|
| 8 |
+
self.chapter_mode = chapter_moder
|
| 9 |
+
self.entry_mode = entry_mode
|
| 10 |
+
|
| 11 |
+
def read_file(self, file_path):
|
| 12 |
+
# 读取文件
|
| 13 |
+
self.law = {}
|
| 14 |
+
f = open(file_path, encoding='utf-8')
|
| 15 |
+
content = f.read()
|
| 16 |
+
content = content.replace("\n\n", "\n")
|
| 17 |
+
content = content.replace("##", "")
|
| 18 |
+
# print(content)
|
| 19 |
+
chapter_p = re.search(self.chapter_mode, content)
|
| 20 |
+
while chapter_p is not None:
|
| 21 |
+
c_start = chapter_p.start()
|
| 22 |
+
c_end = chapter_p.end()
|
| 23 |
+
key = content[c_start:c_end]
|
| 24 |
+
content = content[c_end:]
|
| 25 |
+
|
| 26 |
+
chapter_p = re.search(self.chapter_mode, content)
|
| 27 |
+
if chapter_p is not None:
|
| 28 |
+
end = chapter_p.start()
|
| 29 |
+
c_content = content[:end]
|
| 30 |
+
self.law[key] = self.read_entrys(c_content)
|
| 31 |
+
# print(content[c_start:c_end])
|
| 32 |
+
else:
|
| 33 |
+
self.law[key] = self.read_entrys(content)
|
| 34 |
+
f.close()
|
| 35 |
+
return self.law
|
| 36 |
+
|
| 37 |
+
def read_entrys(self, content):
|
| 38 |
+
entrys = {}
|
| 39 |
+
entry_p = re.search(self.entry_mode, content)
|
| 40 |
+
while entry_p is not None:
|
| 41 |
+
e_start = entry_p.start()
|
| 42 |
+
e_end = entry_p.end()
|
| 43 |
+
key = content[e_start:e_end]
|
| 44 |
+
content = content[e_end+1:]
|
| 45 |
+
|
| 46 |
+
entry_p = re.search(self.entry_mode, content)
|
| 47 |
+
if entry_p is not None:
|
| 48 |
+
end = entry_p.start()
|
| 49 |
+
e_content = content[:end]
|
| 50 |
+
entrys[key] = e_content
|
| 51 |
+
else:
|
| 52 |
+
entrys[key] = content
|
| 53 |
+
return entrys
|
| 54 |
+
# entry_p = re.search(entry_mode, content)
|
| 55 |
+
# while entry_p is not None:
|
| 56 |
+
# start = entry_p.start()
|
| 57 |
+
# end = entry_p.end()
|
| 58 |
+
# # print(content[start:end])
|
| 59 |
+
# content = content[end:]
|
| 60 |
+
# law[content[start:end]] = read_entrys(content)
|
| 61 |
+
# chapter_p = re.search(chapter_mode, content)
|
| 62 |
+
|
| 63 |
+
def show(self):
|
| 64 |
+
for key in self.law:
|
| 65 |
+
print(key, '\n')
|
| 66 |
+
for item in self.law[key]:
|
| 67 |
+
print(item, ' ', self.law[key][item])
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
if __name__ == '__main__':
|
| 71 |
+
file_path = "D:/11496/Documents/project/Laws-master/经济法/价格法(1997-12-29).md"
|
| 72 |
+
r = read_lawfile()
|
| 73 |
+
dict = r.read_file(file_path)
|
| 74 |
+
r.show()
|
| 75 |
+
print(dict)
|
| 76 |
+
with open('./a.json', 'w') as f:
|
| 77 |
+
# json.dumps(dict, f, ensure_ascii=False)
|
| 78 |
+
json.dump(dict, f, ensure_ascii=False)
|
tools/merge_vocabulary.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import LlamaTokenizer
|
| 2 |
+
from sentencepiece import sentencepiece_model_pb2 as model
|
| 3 |
+
import sentencepiece as sp
|
| 4 |
+
import argparse
|
| 5 |
+
import os
|
| 6 |
+
|
| 7 |
+
if __name__ == '__main__':
|
| 8 |
+
# Load arguments
|
| 9 |
+
parser = argparse.ArgumentParser()
|
| 10 |
+
parser.add_argument('--load_path', default='../src/models/base_model/chinese_llama_7b/tokenizer_chinese.model', type=str)
|
| 11 |
+
parser.add_argument('--save_dir', default='../src/models/base_model/save_chinese', type=str)
|
| 12 |
+
parser.add_argument('--voc_path', default='../data/vocabulary/legal_vocab_processed.txt', type=str)
|
| 13 |
+
args = parser.parse_args()
|
| 14 |
+
|
| 15 |
+
LOAD_PATH = args.load_path
|
| 16 |
+
SAVE_DIR = args.save_dir
|
| 17 |
+
VOC_PATH = args.voc_path
|
| 18 |
+
|
| 19 |
+
# Load pre-trained llama tokenizer and sentencepiece model
|
| 20 |
+
llama_spm = model.ModelProto()
|
| 21 |
+
llama_spm.ParseFromString(open(LOAD_PATH, "rb").read())
|
| 22 |
+
|
| 23 |
+
# show size of llama's vocabulary
|
| 24 |
+
llama_spm_tokens_set = set(p.piece for p in llama_spm.pieces)
|
| 25 |
+
print(f"Size of initial llama's vocabulary: {len(llama_spm_tokens_set)}")
|
| 26 |
+
|
| 27 |
+
# Load custom vocabulary
|
| 28 |
+
new_tokens = open(VOC_PATH, "r").read().split("\n")
|
| 29 |
+
for token in new_tokens:
|
| 30 |
+
if token not in llama_spm_tokens_set:
|
| 31 |
+
new_token = model.ModelProto().SentencePiece()
|
| 32 |
+
new_token.piece = token
|
| 33 |
+
new_token.score = 0
|
| 34 |
+
llama_spm.pieces.append(new_token)
|
| 35 |
+
print(f"Size of merged llama's vocabulary: {len(llama_spm.pieces)}")
|
| 36 |
+
|
| 37 |
+
# save
|
| 38 |
+
os.makedirs(SAVE_DIR, exist_ok=True)
|
| 39 |
+
SAVE_MODEL_PATH = os.path.join(SAVE_DIR, 'tokenizer.model')
|
| 40 |
+
SAVE_VOCAB_PATH = os.path.join(SAVE_DIR, 'tokenizer.vocab')
|
| 41 |
+
with open(SAVE_MODEL_PATH, 'wb') as f:
|
| 42 |
+
f.write(llama_spm.SerializeToString())
|
| 43 |
+
with open(SAVE_VOCAB_PATH, 'w') as f:
|
| 44 |
+
f.writelines([f'{token.piece} {token.score}\n' for token in llama_spm.pieces])
|
| 45 |
+
tokenizer = LlamaTokenizer(SAVE_MODEL_PATH)
|
| 46 |
+
tokenizer.save_pretrained(SAVE_DIR)
|
| 47 |
+
print(f'New llama tokenizer and spm has been saved to {SAVE_DIR}')
|
| 48 |
+
|
| 49 |
+
# test
|
| 50 |
+
llama_tokenizer_old = LlamaTokenizer.from_pretrained(LOAD_PATH)
|
| 51 |
+
llama_tokenizer_new = LlamaTokenizer.from_pretrained(SAVE_DIR)
|
| 52 |
+
text = '''登记错误赔偿责任登记等手续登记等手续生效登记机构和登记办法登记机构赔偿后登记机构应当提供登记收费问题'''
|
| 53 |
+
|
| 54 |
+
print(f'Size of old vocabulary: {llama_tokenizer_old.vocab_size}')
|
| 55 |
+
print(f'Size of new vocabulary: {llama_tokenizer_new.vocab_size}')
|
| 56 |
+
print('All special tokens and ids in new llama:')
|
| 57 |
+
print(llama_tokenizer_new.all_special_tokens)
|
| 58 |
+
print(llama_tokenizer_new.all_special_ids)
|
| 59 |
+
print(llama_tokenizer_new.special_tokens_map)
|
| 60 |
+
|
| 61 |
+
print(f'Text:\n{text}')
|
| 62 |
+
print(f'Tokenized by LLaMA tokenizer:\n {llama_tokenizer_old.tokenize(text)}')
|
| 63 |
+
print(f'Tokenized by NEW LLaMA tokenizer:\n {llama_tokenizer_new.tokenize(text)}')
|
train_clm.py
ADDED
|
@@ -0,0 +1,259 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
from typing import List
|
| 4 |
+
|
| 5 |
+
import fire
|
| 6 |
+
import torch
|
| 7 |
+
import transformers
|
| 8 |
+
from datasets import load_dataset
|
| 9 |
+
|
| 10 |
+
from peft import (
|
| 11 |
+
LoraConfig,
|
| 12 |
+
get_peft_model,
|
| 13 |
+
get_peft_model_state_dict,
|
| 14 |
+
prepare_model_for_int8_training,
|
| 15 |
+
set_peft_model_state_dict,
|
| 16 |
+
)
|
| 17 |
+
from transformers import LlamaForCausalLM, LlamaTokenizer
|
| 18 |
+
from utils.prompter import Prompter
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def train(
|
| 22 |
+
# model/data params
|
| 23 |
+
base_model: str = "./models/base_models/your_base_model_dir",
|
| 24 |
+
data_path: str = "./data/your_data.json",
|
| 25 |
+
output_dir: str = "./outputs/your_version_dir",
|
| 26 |
+
|
| 27 |
+
# training hyperparams
|
| 28 |
+
batch_size: int = 128,
|
| 29 |
+
micro_batch_size: int = 4,
|
| 30 |
+
num_epochs: int = 10,
|
| 31 |
+
learning_rate: float = 3e-4,
|
| 32 |
+
cutoff_len: int = 512,
|
| 33 |
+
val_set_size: int = 2000,
|
| 34 |
+
|
| 35 |
+
# lora hyperparams
|
| 36 |
+
lora_r: int = 8,
|
| 37 |
+
lora_alpha: int = 16,
|
| 38 |
+
lora_dropout: float = 0.05,
|
| 39 |
+
lora_target_modules: List[str] = ["q_proj", "v_proj",],
|
| 40 |
+
|
| 41 |
+
# llm hyperparams
|
| 42 |
+
train_on_inputs: bool = True, # if False, masks out inputs in loss
|
| 43 |
+
add_eos_token: bool = True,
|
| 44 |
+
group_by_length: bool = False, # faster, but produces an odd training loss curve
|
| 45 |
+
|
| 46 |
+
# wandb params
|
| 47 |
+
wandb_project: str = "",
|
| 48 |
+
wandb_run_name: str = "",
|
| 49 |
+
wandb_watch: str = "", # options: false | gradients | all
|
| 50 |
+
wandb_log_model: str = "", # options: false | true
|
| 51 |
+
|
| 52 |
+
# either training checkpoint or final adapter
|
| 53 |
+
resume_from_checkpoint: str = None,
|
| 54 |
+
|
| 55 |
+
# The prompt template to use, will default to alpaca.
|
| 56 |
+
prompt_template_name: str = "alpaca",
|
| 57 |
+
):
|
| 58 |
+
if int(os.environ.get("LOCAL_RANK", 0)) == 0:
|
| 59 |
+
print(
|
| 60 |
+
f"Training Alpaca-LoRA model with params:\n"
|
| 61 |
+
f"base_model: {base_model}\n"
|
| 62 |
+
f"data_path: {data_path}\n"
|
| 63 |
+
f"output_dir: {output_dir}\n"
|
| 64 |
+
f"batch_size: {batch_size}\n"
|
| 65 |
+
f"micro_batch_size: {micro_batch_size}\n"
|
| 66 |
+
f"num_epochs: {num_epochs}\n"
|
| 67 |
+
f"learning_rate: {learning_rate}\n"
|
| 68 |
+
f"cutoff_len: {cutoff_len}\n"
|
| 69 |
+
f"val_set_size: {val_set_size}\n"
|
| 70 |
+
f"lora_r: {lora_r}\n"
|
| 71 |
+
f"lora_alpha: {lora_alpha}\n"
|
| 72 |
+
f"lora_dropout: {lora_dropout}\n"
|
| 73 |
+
f"lora_target_modules: {lora_target_modules}\n"
|
| 74 |
+
f"train_on_inputs: {train_on_inputs}\n"
|
| 75 |
+
f"add_eos_token: {add_eos_token}\n"
|
| 76 |
+
f"group_by_length: {group_by_length}\n"
|
| 77 |
+
f"wandb_project: {wandb_project}\n"
|
| 78 |
+
f"wandb_run_name: {wandb_run_name}\n"
|
| 79 |
+
f"wandb_watch: {wandb_watch}\n"
|
| 80 |
+
f"wandb_log_model: {wandb_log_model}\n"
|
| 81 |
+
f"resume_from_checkpoint: {resume_from_checkpoint or False}\n"
|
| 82 |
+
f"prompt template: {prompt_template_name}\n"
|
| 83 |
+
)
|
| 84 |
+
gradient_accumulation_steps = batch_size // micro_batch_size
|
| 85 |
+
|
| 86 |
+
prompter = Prompter(prompt_template_name)
|
| 87 |
+
|
| 88 |
+
# Configure device and distributed training
|
| 89 |
+
device_map = "auto"
|
| 90 |
+
world_size = int(os.environ.get("WORLD_SIZE", 1))
|
| 91 |
+
ddp = world_size != 1
|
| 92 |
+
if ddp:
|
| 93 |
+
device_map = {"": int(os.environ.get("LOCAL_RANK") or 0)}
|
| 94 |
+
gradient_accumulation_steps = gradient_accumulation_steps // world_size
|
| 95 |
+
|
| 96 |
+
# Check if parameter passed or if set within environ
|
| 97 |
+
use_wandb = len(wandb_project) > 0 or (
|
| 98 |
+
"WANDB_PROJECT" in os.environ and len(os.environ["WANDB_PROJECT"]) > 0)
|
| 99 |
+
|
| 100 |
+
# Only overwrite environ if wandb param passed
|
| 101 |
+
if len(wandb_project) > 0:
|
| 102 |
+
os.environ["WANDB_PROJECT"] = wandb_project
|
| 103 |
+
if len(wandb_watch) > 0:
|
| 104 |
+
os.environ["WANDB_WATCH"] = wandb_watch
|
| 105 |
+
if len(wandb_log_model) > 0:
|
| 106 |
+
os.environ["WANDB_LOG_MODEL"] = wandb_log_model
|
| 107 |
+
|
| 108 |
+
model = LlamaForCausalLM.from_pretrained(
|
| 109 |
+
base_model,
|
| 110 |
+
load_in_8bit=True,
|
| 111 |
+
torch_dtype=torch.float16,
|
| 112 |
+
device_map=device_map,
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
tokenizer = LlamaTokenizer.from_pretrained(base_model)
|
| 116 |
+
tokenizer.bos_token_id = 1
|
| 117 |
+
tokenizer.eos_token_id = 2
|
| 118 |
+
bos = tokenizer.bos_token_id
|
| 119 |
+
eos = tokenizer.eos_token_id
|
| 120 |
+
pad = tokenizer.pad_token_id
|
| 121 |
+
|
| 122 |
+
print("pre-trained model's BOS EOS and PAD token id:",
|
| 123 |
+
bos, eos, pad, " => It should be 1,2,none")
|
| 124 |
+
|
| 125 |
+
tokenizer.pad_token_id = (
|
| 126 |
+
0 # unk. we want this to be different from the eos token
|
| 127 |
+
)
|
| 128 |
+
tokenizer.padding_side = "left" # Allow batched inference
|
| 129 |
+
|
| 130 |
+
def tokenize(prompt, add_eos_token=True):
|
| 131 |
+
# there's probably a way to do this with the tokenizer settings
|
| 132 |
+
# but again, gotta move fast
|
| 133 |
+
result = tokenizer(
|
| 134 |
+
prompt,
|
| 135 |
+
truncation=True,
|
| 136 |
+
max_length=cutoff_len,
|
| 137 |
+
padding=False,
|
| 138 |
+
return_tensors=None,
|
| 139 |
+
)
|
| 140 |
+
if (
|
| 141 |
+
result["input_ids"][-1] != tokenizer.eos_token_id
|
| 142 |
+
and len(result["input_ids"]) < cutoff_len
|
| 143 |
+
and add_eos_token
|
| 144 |
+
):
|
| 145 |
+
result["input_ids"].append(tokenizer.eos_token_id)
|
| 146 |
+
result["attention_mask"].append(1)
|
| 147 |
+
|
| 148 |
+
result["labels"] = result["input_ids"].copy()
|
| 149 |
+
|
| 150 |
+
return result
|
| 151 |
+
|
| 152 |
+
def generate_and_tokenize_prompt(data_point):
|
| 153 |
+
text = data_point['content']
|
| 154 |
+
tokenized_full_prompt = tokenize(text)
|
| 155 |
+
return tokenized_full_prompt
|
| 156 |
+
|
| 157 |
+
model = prepare_model_for_int8_training(model)
|
| 158 |
+
|
| 159 |
+
config = LoraConfig(
|
| 160 |
+
r=lora_r,
|
| 161 |
+
lora_alpha=lora_alpha,
|
| 162 |
+
target_modules=lora_target_modules,
|
| 163 |
+
lora_dropout=lora_dropout,
|
| 164 |
+
bias="none",
|
| 165 |
+
task_type="CAUSAL_LM",
|
| 166 |
+
)
|
| 167 |
+
model = get_peft_model(model, config)
|
| 168 |
+
|
| 169 |
+
if data_path.endswith(".json") or data_path.endswith(".jsonl"):
|
| 170 |
+
data = load_dataset("json", data_files=data_path)
|
| 171 |
+
else:
|
| 172 |
+
data = load_dataset(data_path)
|
| 173 |
+
|
| 174 |
+
if resume_from_checkpoint:
|
| 175 |
+
# Check the available weights and load them
|
| 176 |
+
checkpoint_name = os.path.join(
|
| 177 |
+
resume_from_checkpoint, "pytorch_model.bin"
|
| 178 |
+
) # Full checkpoint
|
| 179 |
+
if not os.path.exists(checkpoint_name):
|
| 180 |
+
checkpoint_name = os.path.join(
|
| 181 |
+
resume_from_checkpoint, "adapter_model.bin"
|
| 182 |
+
) # only LoRA model - LoRA config above has to fit
|
| 183 |
+
resume_from_checkpoint = (
|
| 184 |
+
False # So the trainer won't try loading its state
|
| 185 |
+
)
|
| 186 |
+
# The two files above have a different name depending on how they were saved, but are actually the same.
|
| 187 |
+
if os.path.exists(checkpoint_name):
|
| 188 |
+
print(f"Restarting from {checkpoint_name}")
|
| 189 |
+
adapters_weights = torch.load(checkpoint_name)
|
| 190 |
+
set_peft_model_state_dict(model, adapters_weights)
|
| 191 |
+
else:
|
| 192 |
+
print(f"Checkpoint {checkpoint_name} not found")
|
| 193 |
+
|
| 194 |
+
# Be more transparent about the % of trainable params.
|
| 195 |
+
model.print_trainable_parameters()
|
| 196 |
+
|
| 197 |
+
if val_set_size > 0:
|
| 198 |
+
train_val = data["train"].train_test_split(test_size=val_set_size, shuffle=True, seed=42)
|
| 199 |
+
train_data = (train_val["train"].shuffle().map(generate_and_tokenize_prompt))
|
| 200 |
+
val_data = (train_val["test"].shuffle().map(generate_and_tokenize_prompt))
|
| 201 |
+
else:
|
| 202 |
+
train_data = data["train"].shuffle().map(generate_and_tokenize_prompt)
|
| 203 |
+
val_data = None
|
| 204 |
+
|
| 205 |
+
if not ddp and torch.cuda.device_count() > 1:
|
| 206 |
+
# keeps Trainer from trying its own DataParallelism when more than 1 gpu is available
|
| 207 |
+
model.is_parallelizable = True
|
| 208 |
+
model.model_parallel = True
|
| 209 |
+
|
| 210 |
+
trainer = transformers.Trainer(
|
| 211 |
+
model=model,
|
| 212 |
+
train_dataset=train_data,
|
| 213 |
+
eval_dataset=val_data,
|
| 214 |
+
args=transformers.TrainingArguments(
|
| 215 |
+
per_device_train_batch_size=micro_batch_size,
|
| 216 |
+
gradient_accumulation_steps=gradient_accumulation_steps,
|
| 217 |
+
warmup_steps=100,
|
| 218 |
+
num_train_epochs=num_epochs,
|
| 219 |
+
learning_rate=learning_rate,
|
| 220 |
+
fp16=True,
|
| 221 |
+
logging_steps=10,
|
| 222 |
+
optim="adamw_torch",
|
| 223 |
+
evaluation_strategy="steps" if val_set_size > 0 else "no",
|
| 224 |
+
save_strategy="steps",
|
| 225 |
+
eval_steps=100 if val_set_size > 0 else None,
|
| 226 |
+
save_steps=100,
|
| 227 |
+
output_dir=output_dir,
|
| 228 |
+
save_total_limit=3,
|
| 229 |
+
load_best_model_at_end=True if val_set_size > 0 else False,
|
| 230 |
+
ddp_find_unused_parameters=False if ddp else None,
|
| 231 |
+
group_by_length=group_by_length,
|
| 232 |
+
report_to="wandb" if use_wandb else None,
|
| 233 |
+
run_name=wandb_run_name if use_wandb else None,
|
| 234 |
+
),
|
| 235 |
+
data_collator=transformers.DataCollatorForSeq2Seq(
|
| 236 |
+
tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True
|
| 237 |
+
),
|
| 238 |
+
)
|
| 239 |
+
model.config.use_cache = False
|
| 240 |
+
|
| 241 |
+
old_state_dict = model.state_dict
|
| 242 |
+
model.state_dict = (
|
| 243 |
+
lambda self, *_, **__: get_peft_model_state_dict(
|
| 244 |
+
self, old_state_dict()
|
| 245 |
+
)
|
| 246 |
+
).__get__(model, type(model))
|
| 247 |
+
|
| 248 |
+
if torch.__version__ >= "2" and sys.platform != "win32":
|
| 249 |
+
model = torch.compile(model)
|
| 250 |
+
|
| 251 |
+
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
|
| 252 |
+
|
| 253 |
+
model.save_pretrained(output_dir)
|
| 254 |
+
|
| 255 |
+
print("\n If there's a warning about missing keys above, please disregard :)")
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
if __name__ == "__main__":
|
| 259 |
+
fire.Fire(train)
|
utils/__init__.py
ADDED
|
File without changes
|
utils/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (131 Bytes). View file
|
|
|
utils/__pycache__/callbacks.cpython-38.pyc
ADDED
|
Binary file (2.65 kB). View file
|
|
|
utils/__pycache__/prompter.cpython-38.pyc
ADDED
|
Binary file (1.61 kB). View file
|
|
|
utils/callbacks.py
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Helpers to support streaming generate output.
|
| 3 |
+
Borrowed from https://github.com/oobabooga/text-generation-webui/blob/ad37f396fc8bcbab90e11ecf17c56c97bfbd4a9c/modules/callbacks.py
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
import gc
|
| 7 |
+
import traceback
|
| 8 |
+
from queue import Queue
|
| 9 |
+
from threading import Thread
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
import transformers
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class Stream(transformers.StoppingCriteria):
|
| 16 |
+
def __init__(self, callback_func=None):
|
| 17 |
+
self.callback_func = callback_func
|
| 18 |
+
|
| 19 |
+
def __call__(self, input_ids, scores) -> bool:
|
| 20 |
+
if self.callback_func is not None:
|
| 21 |
+
self.callback_func(input_ids[0])
|
| 22 |
+
return False
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class Iteratorize:
|
| 26 |
+
|
| 27 |
+
"""
|
| 28 |
+
Transforms a function that takes a callback
|
| 29 |
+
into a lazy iterator (generator).
|
| 30 |
+
"""
|
| 31 |
+
|
| 32 |
+
def __init__(self, func, kwargs={}, callback=None):
|
| 33 |
+
self.mfunc = func
|
| 34 |
+
self.c_callback = callback
|
| 35 |
+
self.q = Queue()
|
| 36 |
+
self.sentinel = object()
|
| 37 |
+
self.kwargs = kwargs
|
| 38 |
+
self.stop_now = False
|
| 39 |
+
|
| 40 |
+
def _callback(val):
|
| 41 |
+
if self.stop_now:
|
| 42 |
+
raise ValueError
|
| 43 |
+
self.q.put(val)
|
| 44 |
+
|
| 45 |
+
def gentask():
|
| 46 |
+
try:
|
| 47 |
+
ret = self.mfunc(callback=_callback, **self.kwargs)
|
| 48 |
+
except ValueError:
|
| 49 |
+
pass
|
| 50 |
+
except:
|
| 51 |
+
traceback.print_exc()
|
| 52 |
+
pass
|
| 53 |
+
|
| 54 |
+
self.q.put(self.sentinel)
|
| 55 |
+
if self.c_callback:
|
| 56 |
+
self.c_callback(ret)
|
| 57 |
+
|
| 58 |
+
self.thread = Thread(target=gentask)
|
| 59 |
+
self.thread.start()
|
| 60 |
+
|
| 61 |
+
def __iter__(self):
|
| 62 |
+
return self
|
| 63 |
+
|
| 64 |
+
def __next__(self):
|
| 65 |
+
obj = self.q.get(True, None)
|
| 66 |
+
if obj is self.sentinel:
|
| 67 |
+
raise StopIteration
|
| 68 |
+
else:
|
| 69 |
+
return obj
|
| 70 |
+
|
| 71 |
+
def __enter__(self):
|
| 72 |
+
return self
|
| 73 |
+
|
| 74 |
+
def __exit__(self, exc_type, exc_val, exc_tb):
|
| 75 |
+
self.stop_now = True
|
utils/evaluate.py
ADDED
|
@@ -0,0 +1,196 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
|
| 5 |
+
import fire
|
| 6 |
+
from tqdm import tqdm
|
| 7 |
+
import pandas as pd
|
| 8 |
+
import torch
|
| 9 |
+
import transformers
|
| 10 |
+
from peft import PeftModel
|
| 11 |
+
import datasets
|
| 12 |
+
from transformers import GenerationConfig, LlamaForCausalLM, LlamaTokenizer
|
| 13 |
+
|
| 14 |
+
from utils.callbacks import Iteratorize, Stream
|
| 15 |
+
from utils.prompter import Prompter
|
| 16 |
+
|
| 17 |
+
device = "cuda"
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def main(
|
| 21 |
+
load_8bit: bool = True,
|
| 22 |
+
base_model: str = "decapoda-research/llama-7b-hf",
|
| 23 |
+
lora_weights: str = "./lora-alpaca",
|
| 24 |
+
data_path: str = "./data",
|
| 25 |
+
output_path: str = "./output",
|
| 26 |
+
eval_rate: float = 0.1,
|
| 27 |
+
batch_size: int = 32,
|
| 28 |
+
# The prompt template to use, will default to alpaca.
|
| 29 |
+
prompt_template: str = "alpaca",
|
| 30 |
+
):
|
| 31 |
+
base_model = base_model or os.environ.get("BASE_MODEL", "")
|
| 32 |
+
assert (base_model), "Please specify a --base_model, e.g. --base_model='huggyllama/llama-7b'"
|
| 33 |
+
|
| 34 |
+
prompter = Prompter(prompt_template)
|
| 35 |
+
tokenizer = LlamaTokenizer.from_pretrained(base_model)
|
| 36 |
+
if device == "cuda":
|
| 37 |
+
model = LlamaForCausalLM.from_pretrained(
|
| 38 |
+
base_model,
|
| 39 |
+
load_in_8bit=load_8bit,
|
| 40 |
+
torch_dtype=torch.float16,
|
| 41 |
+
device_map="auto",
|
| 42 |
+
)
|
| 43 |
+
model = PeftModel.from_pretrained(
|
| 44 |
+
model,
|
| 45 |
+
lora_weights,
|
| 46 |
+
torch_dtype=torch.float16,
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
# unwind broken decapoda-research config
|
| 50 |
+
model.config.pad_token_id = tokenizer.pad_token_id = 0 # unk
|
| 51 |
+
model.config.bos_token_id = 1
|
| 52 |
+
model.config.eos_token_id = 2
|
| 53 |
+
|
| 54 |
+
if not load_8bit:
|
| 55 |
+
model.half() # seems to fix bugs for some users.
|
| 56 |
+
|
| 57 |
+
model.eval()
|
| 58 |
+
if torch.__version__ >= "2" and sys.platform != "win32":
|
| 59 |
+
model = torch.compile(model)
|
| 60 |
+
|
| 61 |
+
def evaluate_one(
|
| 62 |
+
instruction,
|
| 63 |
+
input=None,
|
| 64 |
+
temperature=0.1,
|
| 65 |
+
top_p=0.75,
|
| 66 |
+
top_k=40,
|
| 67 |
+
num_beams=2,
|
| 68 |
+
max_new_tokens=128,
|
| 69 |
+
**kwargs,
|
| 70 |
+
):
|
| 71 |
+
prompt = prompter.generate_prompt(instruction, input)
|
| 72 |
+
inputs = tokenizer(prompt, return_tensors="pt")
|
| 73 |
+
input_ids = inputs["input_ids"].to(device)
|
| 74 |
+
generation_config = GenerationConfig(
|
| 75 |
+
temperature=temperature,
|
| 76 |
+
top_p=top_p,
|
| 77 |
+
top_k=top_k,
|
| 78 |
+
num_beams=num_beams,
|
| 79 |
+
**kwargs,
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
# Without streaming
|
| 83 |
+
with torch.no_grad():
|
| 84 |
+
generation_output = model.generate(
|
| 85 |
+
input_ids=input_ids,
|
| 86 |
+
generation_config=generation_config,
|
| 87 |
+
return_dict_in_generate=True,
|
| 88 |
+
output_scores=True,
|
| 89 |
+
max_new_tokens=max_new_tokens,
|
| 90 |
+
)
|
| 91 |
+
s = generation_output.sequences[0]
|
| 92 |
+
output = tokenizer.decode(s, skip_special_tokens=True)
|
| 93 |
+
return prompter.get_response(output)
|
| 94 |
+
|
| 95 |
+
def evaluate_all():
|
| 96 |
+
# data = datasets.load_dataset("json", data_files=data_path)
|
| 97 |
+
# data = data["train"]
|
| 98 |
+
# df = data.to_pandas()
|
| 99 |
+
df = pd.read_json(data_path, orient='records')
|
| 100 |
+
print(df.info())
|
| 101 |
+
# 计算准确率
|
| 102 |
+
correct = 0
|
| 103 |
+
total = 0
|
| 104 |
+
total_step = len(df)
|
| 105 |
+
pbar = tqdm(total=total_step, unit='batch')
|
| 106 |
+
error = []
|
| 107 |
+
for i in range(total_step):
|
| 108 |
+
instruction = df['instruction'].iloc[i]
|
| 109 |
+
input = df['input'].iloc[i]
|
| 110 |
+
label = df['output'].iloc[i]
|
| 111 |
+
pred = evaluate_one(instruction=instruction, input=input)
|
| 112 |
+
if pred == label:
|
| 113 |
+
correct += 1
|
| 114 |
+
else:
|
| 115 |
+
error.append((label, pred))
|
| 116 |
+
total += 1
|
| 117 |
+
acc = correct / total
|
| 118 |
+
# 更新进度条
|
| 119 |
+
# Update the progress bar
|
| 120 |
+
pbar.set_description(
|
| 121 |
+
f"Testing: Sample [{total}/{total_step}] Acc: {acc :.4f}")
|
| 122 |
+
pbar.update(1)
|
| 123 |
+
|
| 124 |
+
for e in error:
|
| 125 |
+
print(e)
|
| 126 |
+
|
| 127 |
+
def evaluate_by_batch(
|
| 128 |
+
temperature=0.1,
|
| 129 |
+
top_p=0.75,
|
| 130 |
+
top_k=40,
|
| 131 |
+
num_beams=1,
|
| 132 |
+
max_new_tokens=32
|
| 133 |
+
):
|
| 134 |
+
df = pd.read_json(data_path, orient='records')
|
| 135 |
+
# df = df.sample(frac=eval_rate).reset_index(drop=True)
|
| 136 |
+
df['prompt'] = df.apply(lambda x: prompter.generate_prompt(
|
| 137 |
+
x['instruction'], x['input']), axis=1)
|
| 138 |
+
tokenizer.padding_side = "left" # Allow batched inference
|
| 139 |
+
|
| 140 |
+
generation_config = GenerationConfig(
|
| 141 |
+
temperature=temperature,
|
| 142 |
+
top_p=top_p,
|
| 143 |
+
top_k=top_k,
|
| 144 |
+
num_beams=num_beams
|
| 145 |
+
)
|
| 146 |
+
|
| 147 |
+
outputs = []
|
| 148 |
+
total = 0
|
| 149 |
+
total_step = math.ceil(len(df) / batch_size)
|
| 150 |
+
pbar = tqdm(total=total_step, unit='batch')
|
| 151 |
+
# 计算准确率
|
| 152 |
+
with torch.no_grad():
|
| 153 |
+
for i in range(total_step):
|
| 154 |
+
batch = df.iloc[i*batch_size:(i+1)*batch_size]
|
| 155 |
+
inputs = tokenizer(batch['prompt'].tolist(), return_tensors="pt", padding=True)[
|
| 156 |
+
'input_ids'].to(device)
|
| 157 |
+
|
| 158 |
+
generation_outputs = model.generate(
|
| 159 |
+
input_ids=inputs,
|
| 160 |
+
generation_config=generation_config,
|
| 161 |
+
max_new_tokens=max_new_tokens,
|
| 162 |
+
pad_token_id=tokenizer.pad_token_id
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
for g in generation_outputs:
|
| 166 |
+
decoded_item = tokenizer.decode(
|
| 167 |
+
g, skip_special_tokens=True)
|
| 168 |
+
try:
|
| 169 |
+
output = prompter.get_response(decoded_item)
|
| 170 |
+
except:
|
| 171 |
+
output = decoded_item
|
| 172 |
+
outputs.append(output)
|
| 173 |
+
total += 1
|
| 174 |
+
|
| 175 |
+
# 更新进度条
|
| 176 |
+
pbar.set_description(f"Testing: Sample [{total}/{len(df)}] ")
|
| 177 |
+
pbar.update(1)
|
| 178 |
+
df['pred'] = outputs
|
| 179 |
+
df['pred'].to_csv(output_path, index=False)
|
| 180 |
+
|
| 181 |
+
evaluate_by_batch()
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
if __name__ == "__main__":
|
| 185 |
+
# fire.Fire(main)
|
| 186 |
+
import yaml
|
| 187 |
+
dataset_param = sys.argv[1]
|
| 188 |
+
with open("./configs/evaluate_params.yaml", "r") as stream:
|
| 189 |
+
# try:
|
| 190 |
+
params = yaml.safe_load(stream)
|
| 191 |
+
print('=' * 80)
|
| 192 |
+
print(params[dataset_param])
|
| 193 |
+
print('=' * 80)
|
| 194 |
+
|
| 195 |
+
# fire.Fire(train)
|
| 196 |
+
main(**params[dataset_param])
|
utils/merge.py
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import transformers
|
| 5 |
+
from peft import PeftModel
|
| 6 |
+
from transformers import LlamaForCausalLM, LlamaTokenizer # noqa: F402
|
| 7 |
+
|
| 8 |
+
BASE_MODEL = os.environ.get("BASE_MODEL", None)
|
| 9 |
+
assert (
|
| 10 |
+
BASE_MODEL
|
| 11 |
+
), "Please specify a value for BASE_MODEL environment variable, e.g. `export BASE_MODEL=huggyllama/llama-7b`" # noqa: E501
|
| 12 |
+
|
| 13 |
+
tokenizer = LlamaTokenizer.from_pretrained(BASE_MODEL)
|
| 14 |
+
|
| 15 |
+
base_model = LlamaForCausalLM.from_pretrained(
|
| 16 |
+
BASE_MODEL,
|
| 17 |
+
load_in_8bit=False,
|
| 18 |
+
torch_dtype=torch.float16,
|
| 19 |
+
device_map={"": "cpu"},
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
first_weight = base_model.model.layers[0].self_attn.q_proj.weight
|
| 23 |
+
first_weight_old = first_weight.clone()
|
| 24 |
+
|
| 25 |
+
lora_model = PeftModel.from_pretrained(
|
| 26 |
+
base_model,
|
| 27 |
+
"../outputs/lora-llama-clm-e2",
|
| 28 |
+
device_map={"": "cpu"},
|
| 29 |
+
torch_dtype=torch.float16,
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
lora_weight = lora_model.base_model.model.model.layers[0].self_attn.q_proj.weight
|
| 33 |
+
|
| 34 |
+
assert torch.allclose(first_weight_old, first_weight)
|
| 35 |
+
|
| 36 |
+
# merge weights - new merging method from peft
|
| 37 |
+
lora_model = lora_model.merge_and_unload()
|
| 38 |
+
|
| 39 |
+
lora_model.train(False)
|
| 40 |
+
|
| 41 |
+
# did we do anything?
|
| 42 |
+
assert not torch.allclose(first_weight_old, first_weight)
|
| 43 |
+
|
| 44 |
+
lora_model_sd = lora_model.state_dict()
|
| 45 |
+
deloreanized_sd = {
|
| 46 |
+
k.replace("base_model.model.", ""): v
|
| 47 |
+
for k, v in lora_model_sd.items()
|
| 48 |
+
if "lora" not in k
|
| 49 |
+
}
|
| 50 |
+
|
| 51 |
+
LlamaForCausalLM.save_pretrained(base_model, '../models/legal-base-7b', state_dict=deloreanized_sd, max_shard_size="400MB")
|
utils/prompter.py
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
A dedicated helper to manage templates and prompt building.
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
import json
|
| 6 |
+
import os.path as osp
|
| 7 |
+
from typing import Union
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class Prompter(object):
|
| 11 |
+
__slots__ = ("template", "_verbose")
|
| 12 |
+
|
| 13 |
+
def __init__(self, template_name: str = "", verbose: bool = False):
|
| 14 |
+
self._verbose = verbose
|
| 15 |
+
if not template_name:
|
| 16 |
+
# Enforce the default here, so the constructor can be called with '' and will not break.
|
| 17 |
+
template_name = "alpaca"
|
| 18 |
+
file_name = osp.join("templates", f"{template_name}.json")
|
| 19 |
+
if not osp.exists(file_name):
|
| 20 |
+
raise ValueError(f"Can't read {file_name}")
|
| 21 |
+
with open(file_name) as fp:
|
| 22 |
+
self.template = json.load(fp)
|
| 23 |
+
if self._verbose:
|
| 24 |
+
print(
|
| 25 |
+
f"Using prompt template {template_name}: {self.template['description']}"
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
def generate_prompt(
|
| 29 |
+
self,
|
| 30 |
+
instruction: str,
|
| 31 |
+
input: Union[None, str] = None,
|
| 32 |
+
label: Union[None, str] = None,
|
| 33 |
+
) -> str:
|
| 34 |
+
# returns the full prompt from instruction and optional input
|
| 35 |
+
# if a label (=response, =output) is provided, it's also appended.
|
| 36 |
+
if input:
|
| 37 |
+
res = self.template["prompt_input"].format(
|
| 38 |
+
instruction=instruction, input=input
|
| 39 |
+
)
|
| 40 |
+
else:
|
| 41 |
+
res = self.template["prompt_no_input"].format(
|
| 42 |
+
instruction=instruction
|
| 43 |
+
)
|
| 44 |
+
if label:
|
| 45 |
+
res = f"{res}{label}"
|
| 46 |
+
if self._verbose:
|
| 47 |
+
print(res)
|
| 48 |
+
return res
|
| 49 |
+
|
| 50 |
+
def get_response(self, output: str) -> str:
|
| 51 |
+
return output.split(self.template["response_split"])[1].strip()
|
webui.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
|
| 4 |
+
import fire
|
| 5 |
+
import gradio as gr
|
| 6 |
+
import torch
|
| 7 |
+
import transformers
|
| 8 |
+
from peft import PeftModel
|
| 9 |
+
from transformers import GenerationConfig, LlamaForCausalLM, LlamaTokenizer, AutoModel, AutoTokenizer, AutoModelForCausalLM,AutoConfig
|
| 10 |
+
|
| 11 |
+
from utils.callbacks import Iteratorize, Stream
|
| 12 |
+
from utils.prompter import Prompter
|
| 13 |
+
|
| 14 |
+
# if torch.cuda.is_available():
|
| 15 |
+
# device = "cuda"
|
| 16 |
+
# else:
|
| 17 |
+
# device = "cpu"
|
| 18 |
+
|
| 19 |
+
# try:
|
| 20 |
+
# if torch.backends.mps.is_available():
|
| 21 |
+
# device = "mps"
|
| 22 |
+
# except:
|
| 23 |
+
# pass
|
| 24 |
+
|
| 25 |
+
device = "xpu"
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def main(
|
| 29 |
+
load_8bit: bool = False,
|
| 30 |
+
base_model: str = "",
|
| 31 |
+
lora_weights: str = "",
|
| 32 |
+
prompt_template: str = "", # The prompt template to use, will default to alpaca.
|
| 33 |
+
server_name: str = "0.0.0.0", # Allows to listen on all interfaces by providing '0.
|
| 34 |
+
share_gradio: bool = False,
|
| 35 |
+
):
|
| 36 |
+
base_model = base_model or os.environ.get("BASE_MODEL", "")
|
| 37 |
+
assert (
|
| 38 |
+
base_model
|
| 39 |
+
), "Please specify a --base_model, e.g. --base_model='huggyllama/llama-7b'"
|
| 40 |
+
|
| 41 |
+
prompter = Prompter(prompt_template)
|
| 42 |
+
tokenizer = LlamaTokenizer.from_pretrained(base_model)
|
| 43 |
+
prompter = Prompter(prompt_template)
|
| 44 |
+
tokenizer = LlamaTokenizer.from_pretrained(base_model)
|
| 45 |
+
config = AutoConfig.from_pretrained(base_model)
|
| 46 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 47 |
+
base_model,
|
| 48 |
+
config=config,
|
| 49 |
+
load_in_8bit=load_8bit,
|
| 50 |
+
torch_dtype=torch.float16,
|
| 51 |
+
device_map="auto",
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
try:
|
| 55 |
+
print(f"Using lora {lora_weights}")
|
| 56 |
+
model = PeftModel.from_pretrained(
|
| 57 |
+
model,
|
| 58 |
+
lora_weights,
|
| 59 |
+
torch_dtype=torch.float16,
|
| 60 |
+
)
|
| 61 |
+
except:
|
| 62 |
+
print("*"*50, "\n Attention! No Lora Weights \n", "*"*50)
|
| 63 |
+
|
| 64 |
+
# unwind broken decapoda-research config
|
| 65 |
+
model.config.pad_token_id = tokenizer.pad_token_id = 0 # unk
|
| 66 |
+
model.config.bos_token_id = 1
|
| 67 |
+
model.config.eos_token_id = 2
|
| 68 |
+
|
| 69 |
+
# if not load_8bit:
|
| 70 |
+
# model.half() # seems to fix bugs for some users.
|
| 71 |
+
|
| 72 |
+
model.eval()
|
| 73 |
+
if torch.__version__ >= "2" and sys.platform != "win32":
|
| 74 |
+
model = torch.compile(model)
|
| 75 |
+
|
| 76 |
+
def evaluate(
|
| 77 |
+
instruction,
|
| 78 |
+
# input=None,
|
| 79 |
+
temperature=0.1,
|
| 80 |
+
top_p=0.75,
|
| 81 |
+
top_k=40,
|
| 82 |
+
num_beams=4,
|
| 83 |
+
max_new_tokens=128,
|
| 84 |
+
stream_output=False,
|
| 85 |
+
**kwargs,
|
| 86 |
+
):
|
| 87 |
+
input=None
|
| 88 |
+
prompt = prompter.generate_prompt(instruction, input)
|
| 89 |
+
inputs = tokenizer(prompt, return_tensors="pt")
|
| 90 |
+
input_ids = inputs["input_ids"].to(device)
|
| 91 |
+
generation_config = GenerationConfig(
|
| 92 |
+
temperature=temperature,
|
| 93 |
+
top_p=top_p,
|
| 94 |
+
top_k=top_k,
|
| 95 |
+
num_beams=num_beams,
|
| 96 |
+
**kwargs,
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
generate_params = {
|
| 100 |
+
"input_ids": input_ids,
|
| 101 |
+
"generation_config": generation_config,
|
| 102 |
+
"return_dict_in_generate": True,
|
| 103 |
+
"output_scores": True,
|
| 104 |
+
"max_new_tokens": max_new_tokens,
|
| 105 |
+
}
|
| 106 |
+
|
| 107 |
+
if stream_output:
|
| 108 |
+
# Stream the reply 1 token at a time.
|
| 109 |
+
# This is based on the trick of using 'stopping_criteria' to create an iterator,
|
| 110 |
+
# from https://github.com/oobabooga/text-generation-webui/blob/ad37f396fc8bcbab90e11ecf17c56c97bfbd4a9c/modules/text_generation.py#L216-L243.
|
| 111 |
+
|
| 112 |
+
def generate_with_callback(callback=None, **kwargs):
|
| 113 |
+
kwargs.setdefault(
|
| 114 |
+
"stopping_criteria", transformers.StoppingCriteriaList()
|
| 115 |
+
)
|
| 116 |
+
kwargs["stopping_criteria"].append(
|
| 117 |
+
Stream(callback_func=callback)
|
| 118 |
+
)
|
| 119 |
+
with torch.no_grad():
|
| 120 |
+
model.generate(**kwargs)
|
| 121 |
+
|
| 122 |
+
def generate_with_streaming(**kwargs):
|
| 123 |
+
return Iteratorize(
|
| 124 |
+
generate_with_callback, kwargs, callback=None
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
with generate_with_streaming(**generate_params) as generator:
|
| 128 |
+
for output in generator:
|
| 129 |
+
# new_tokens = len(output) - len(input_ids[0])
|
| 130 |
+
decoded_output = tokenizer.decode(output)
|
| 131 |
+
|
| 132 |
+
if output[-1] in [tokenizer.eos_token_id]:
|
| 133 |
+
break
|
| 134 |
+
|
| 135 |
+
yield prompter.get_response(decoded_output)
|
| 136 |
+
print(decoded_output)
|
| 137 |
+
return # early return for stream_output
|
| 138 |
+
|
| 139 |
+
# Without streaming
|
| 140 |
+
with torch.no_grad():
|
| 141 |
+
generation_output = model.generate(
|
| 142 |
+
input_ids=input_ids,
|
| 143 |
+
generation_config=generation_config,
|
| 144 |
+
return_dict_in_generate=True,
|
| 145 |
+
output_scores=True,
|
| 146 |
+
max_new_tokens=max_new_tokens,
|
| 147 |
+
)
|
| 148 |
+
s = generation_output.sequences[0]
|
| 149 |
+
output = tokenizer.decode(s)
|
| 150 |
+
print(output)
|
| 151 |
+
yield prompter.get_response(output)
|
| 152 |
+
|
| 153 |
+
gr.Interface(
|
| 154 |
+
fn=evaluate,
|
| 155 |
+
inputs=[
|
| 156 |
+
gr.components.Textbox(
|
| 157 |
+
lines=2,
|
| 158 |
+
label="Instruction",
|
| 159 |
+
placeholder="此处输入法律相关问题",
|
| 160 |
+
),
|
| 161 |
+
# gr.components.Textbox(lines=2, label="Input", placeholder="none"),
|
| 162 |
+
gr.components.Slider(
|
| 163 |
+
minimum=0, maximum=1, value=0.1, label="Temperature"
|
| 164 |
+
),
|
| 165 |
+
gr.components.Slider(
|
| 166 |
+
minimum=0, maximum=1, value=0.75, label="Top p"
|
| 167 |
+
),
|
| 168 |
+
gr.components.Slider(
|
| 169 |
+
minimum=0, maximum=100, step=1, value=40, label="Top k"
|
| 170 |
+
),
|
| 171 |
+
gr.components.Slider(
|
| 172 |
+
minimum=1, maximum=4, step=1, value=1, label="Beams"
|
| 173 |
+
),
|
| 174 |
+
gr.components.Slider(
|
| 175 |
+
minimum=1, maximum=2000, step=1, value=256, label="Max tokens"
|
| 176 |
+
),
|
| 177 |
+
gr.components.Checkbox(label="Stream output", value=True),
|
| 178 |
+
],
|
| 179 |
+
outputs=[
|
| 180 |
+
gr.inputs.Textbox(
|
| 181 |
+
lines=8,
|
| 182 |
+
label="Output",
|
| 183 |
+
)
|
| 184 |
+
],
|
| 185 |
+
title="🦙🌲 LaWGPT",
|
| 186 |
+
description="",
|
| 187 |
+
).queue().launch(server_name="0.0.0.0", share=share_gradio)
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
if __name__ == "__main__":
|
| 191 |
+
fire.Fire(main)
|