Spaces:
Runtime error

Runtime error
application
Browse files- .gitignore +9 -0
- README.md +129 -1
- app.py +90 -0
- config.py +33 -0
- model.png +0 -0
- model/counter.pkl +3 -0
- model/full_model.h5 +3 -0
- model/model_weights.h5 +3 -0
- model/text_vectorizer.pkl +3 -0
- predict.py +45 -0
- requirements.txt +6 -0
- src/__init__.py +1 -0
- src/data_preprocessing.py +68 -0
- src/make_dataset.py +60 -0
- src/me.jpg +0 -0
- src/model.py +16 -0
- src/utils.py +77 -0
- train.py +120 -0
.gitignore
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dataset/
|
| 2 |
+
*/__pycache__/
|
| 3 |
+
__pycache__
|
| 4 |
+
src/__pycache__
|
| 5 |
+
logs/
|
| 6 |
+
src/__pycache__/*
|
| 7 |
+
**/__pycache__/
|
| 8 |
+
notebook/__pycache__/*
|
| 9 |
+
|
README.md
CHANGED
|
@@ -10,4 +10,132 @@ pinned: false
|
|
| 10 |
license: openrail
|
| 11 |
---
|
| 12 |
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
license: openrail
|
| 11 |
---
|
| 12 |
|
| 13 |
+
# Amazon review sentiment analysis
|
| 14 |
+

|
| 15 |
+
|
| 16 |
+
Welcome to the Amazon Review Sentiment Analysis project! This repository contains code for training a sentiment analysis model on a large dataset of Amazon reviews using Long Short-Term Memory (LSTM) neural networks. The trained model can predict the sentiment (positive or negative) of Amazon reviews. The dataset used for training consists of over 2 million reviews, totaling 2.6 GB of data.
|
| 17 |
+
|
| 18 |
+
<img src='https://img.shields.io/badge/TensorFlow-FF6F00?style=for-the-badge&logo=tensorflow&logoColor=white'>
|
| 19 |
+
|
| 20 |
+
<img src='https://img.shields.io/badge/scikit--learn-%23F7931E.svg?style=for-the-badge&logo=scikit-learn&logoColor=white'>
|
| 21 |
+
|
| 22 |
+
<img src='https://img.shields.io/badge/Polars-CD792C.svg?style=for-the-badge&logo=Polars&logoColor=white'>
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
## Table of Contents
|
| 26 |
+
* Introduction
|
| 27 |
+
* Dataset
|
| 28 |
+
* Model
|
| 29 |
+
* Getting Started
|
| 30 |
+
* Prerequisites
|
| 31 |
+
* Training
|
| 32 |
+
* Prediction
|
| 33 |
+
* Running the Streamlit App
|
| 34 |
+
* Contributing
|
| 35 |
+
* Acknowledgements
|
| 36 |
+
|
| 37 |
+
## Introduction
|
| 38 |
+
Sentiment analysis is the process of determining the sentiment or emotion expressed in a piece of text. In this project, we focus on predicting whether Amazon reviews are positive or negative based on their text content. We use LSTM neural networks, a type of recurrent neural network (RNN), to capture the sequential patterns in the text data and make accurate sentiment predictions.
|
| 39 |
+
|
| 40 |
+
## Dataset
|
| 41 |
+
The dataset used for this project is a massive collection of Amazon reviews, comprising more than 2 million reviews with a total size of 2.6 GB. The dataset is [ here](https://www.kaggle.com/datasets/kritanjalijain/amazon-reviews). It contains both positive and negative reviews, making it suitable for training a sentiment analysis model.
|
| 42 |
+
|
| 43 |
+
### Challenges
|
| 44 |
+
* Dataset is very larget (2.6 GB) with 2.6 Million Reviews
|
| 45 |
+
* Machine's resources are limiting as loading multiple variables with processed data is eating up RAM
|
| 46 |
+
|
| 47 |
+
### Work Arounds
|
| 48 |
+
* Used polars for data manipulation and Preprocessings ( Uses Parallel computation, Doesn't load data on memory)
|
| 49 |
+
|
| 50 |
+
## Model
|
| 51 |
+
The sentiment analysis model is built using TensorFlow and Keras libraries. We employ LSTM layers to effectively capture the sequential nature of text data. The model is trained on the labeled Amazon reviews dataset, and its performance is evaluated using various metrics such as accuracy, precision, recall, and F1-score.
|
| 52 |
+
|
| 53 |
+
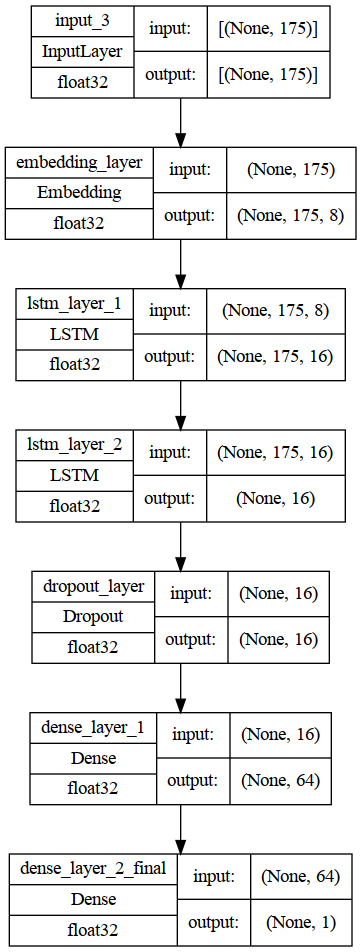
## Model architectures
|
| 54 |
+
```
|
| 55 |
+
Model: "model_lstm"
|
| 56 |
+
_________________________________________________________________
|
| 57 |
+
Layer (type) Output Shape Param #
|
| 58 |
+
=================================================================
|
| 59 |
+
input_3 (InputLayer) [(None, 175)] 0
|
| 60 |
+
|
| 61 |
+
embedding_layer (Embedding) (None, 175, 8) 2400000
|
| 62 |
+
|
| 63 |
+
lstm_layer_1 (LSTM) (None, 175, 16) 1600
|
| 64 |
+
|
| 65 |
+
lstm_layer_2 (LSTM) (None, 16) 2112
|
| 66 |
+
|
| 67 |
+
dropout_layer (Dropout) (None, 16) 0
|
| 68 |
+
|
| 69 |
+
dense_layer_1 (Dense) (None, 64) 1088
|
| 70 |
+
|
| 71 |
+
dense_layer_2_final (Dense) (None, 1) 65
|
| 72 |
+
|
| 73 |
+
=================================================================
|
| 74 |
+
Total params: 2,404,865
|
| 75 |
+
Trainable params: 2,404,865
|
| 76 |
+
Non-trainable params: 0
|
| 77 |
+
_________________________________________________________________
|
| 78 |
+
```
|
| 79 |
+
## Model Performance
|
| 80 |
+
|
| 81 |
+
| Model | Accuracy | Precision | Recall | F1 | Description |
|
| 82 |
+
|-------------------|--------------------|--------------------|--------------------|--------------------|--------------------------------------------------|
|
| 83 |
+
| model0: Naive Bayes | 84.79% | 84.82% | 84.79% | 84.79% | |
|
| 84 |
+
| model1: **LSTM**(in use) | 94.06% | 94.06% | 94.06% | 94.06% | small lstm model with vectorizer and embedding layer |
|
| 85 |
+
|
| 86 |
+
## Getting Started
|
| 87 |
+
Follow these steps to get started with the project:
|
| 88 |
+
|
| 89 |
+
### Prerequisites
|
| 90 |
+
* Python 3.x
|
| 91 |
+
* TensorFlow
|
| 92 |
+
* Keras
|
| 93 |
+
* Polars
|
| 94 |
+
* Streamlit
|
| 95 |
+
|
| 96 |
+
You can install the required dependencies using the following command:
|
| 97 |
+
|
| 98 |
+
```
|
| 99 |
+
pip install -r requirements.txt
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
### Training
|
| 103 |
+
To train the LSTM model, run the train.py script:
|
| 104 |
+
|
| 105 |
+
```
|
| 106 |
+
python3 train.py
|
| 107 |
+
```
|
| 108 |
+
This script will preprocess the dataset, train the model, and save the trained weights to disk.
|
| 109 |
+
|
| 110 |
+
### Prediction
|
| 111 |
+
|
| 112 |
+
To use the trained model for making predictions on new reviews, run the predict.py script:
|
| 113 |
+
|
| 114 |
+
```
|
| 115 |
+
python3 predict.py
|
| 116 |
+
```
|
| 117 |
+
### Running the Streamlit App
|
| 118 |
+
We've also provided a user-friendly Streamlit app to interact with the trained
|
| 119 |
+
Model. Run the app using the following command:
|
| 120 |
+
```
|
| 121 |
+
streamlit run app.py
|
| 122 |
+
```
|
| 123 |
+
This will launch a local web app where you can input your own Amazon review and see the model's sentiment prediction.
|
| 124 |
+
|
| 125 |
+
## Contributing
|
| 126 |
+
Contributions are welcome! If you find any issues or have suggestions for improvements, please feel free to open an issue or create a pull request.
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
## Acknowledgements
|
| 130 |
+
We would like to express our gratitude to the open-source community for providing invaluable resources and tools that made this project possible.
|
| 131 |
+
|
| 132 |
+
Don't Forget to Star!
|
| 133 |
+
If you find this project interesting or useful, please consider starring the repository. Your support is greatly appreciated!
|
| 134 |
+
|
| 135 |
+
Star
|
| 136 |
+
|
| 137 |
+
Happy coding!
|
| 138 |
+
|
| 139 |
+
Your Name
|
| 140 |
+
Your Contact Info
|
| 141 |
+
Date
|
app.py
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import webbrowser
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
import streamlit as st
|
| 6 |
+
import tensorflow as tf
|
| 7 |
+
|
| 8 |
+
import config
|
| 9 |
+
from src import data_preprocessing, utils
|
| 10 |
+
|
| 11 |
+
MODEL_PATH = Path(config.MODEL_DIR) / config.MODEL_FILENAME
|
| 12 |
+
VECTORIZER_PATH = Path(config.MODEL_DIR) / config.TEXT_VECTOR_FILENAME
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def load_model_and_vectorizer(vectorizer_path, model_path):
|
| 19 |
+
try:
|
| 20 |
+
text_vectorizer = utils.load_text_vectorizer(vectorizer_path)
|
| 21 |
+
lstm_model = tf.keras.models.load_model(model_path)
|
| 22 |
+
return text_vectorizer, lstm_model
|
| 23 |
+
except Exception as e:
|
| 24 |
+
return None, None
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def predict_sentiment(title, text, text_vectorizer, lstm_model):
|
| 28 |
+
review = f'{title} {text}' # concatenate the title and text
|
| 29 |
+
clean_review = data_preprocessing.clean_text(review)
|
| 30 |
+
review_sequence = text_vectorizer([clean_review])
|
| 31 |
+
prediction = lstm_model.predict(review_sequence)
|
| 32 |
+
sentiment_score = prediction[0][0]
|
| 33 |
+
sentiment_label = 'Positive' if sentiment_score >= 0.5 else 'Negative'
|
| 34 |
+
return sentiment_label, sentiment_score
|
| 35 |
+
|
| 36 |
+
# Introduction and Project Information
|
| 37 |
+
st.title("Amazon Review Sentiment Analysis")
|
| 38 |
+
st.write("This is a Streamlit app for performing sentiment analysis on Amazon reviews.")
|
| 39 |
+
st.write("Enter the title and text of the review to analyze its sentiment.")
|
| 40 |
+
|
| 41 |
+
# User Inputs
|
| 42 |
+
review_title = st.text_input("Enter the review title:")
|
| 43 |
+
review_text = st.text_area("Enter the review text:(required)")
|
| 44 |
+
|
| 45 |
+
submit = st.button("Analyze Sentiment")
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
text_vectorizer, lstm_model = load_model_and_vectorizer( VECTORIZER_PATH, MODEL_PATH)
|
| 50 |
+
if text_vectorizer is None or lstm_model is None:
|
| 51 |
+
st.error('Could not load text vectorizer and model. Aborting prediction.')
|
| 52 |
+
|
| 53 |
+
# Perform Sentiment Analysis
|
| 54 |
+
if submit:
|
| 55 |
+
with st.spinner():
|
| 56 |
+
sentiment_label, sentiment_score = predict_sentiment(review_title, review_text, text_vectorizer, lstm_model)
|
| 57 |
+
new_sentiment_score= abs(0.5 - sentiment_score)*2
|
| 58 |
+
|
| 59 |
+
if sentiment_score >=0.5:
|
| 60 |
+
st.success(f"Sentiment: {sentiment_label} (Score: {new_sentiment_score:.2f})")
|
| 61 |
+
else:
|
| 62 |
+
st.error(f"Sentiment: {sentiment_label} (Score: {new_sentiment_score:.2f})")
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
# Project Usage and Links
|
| 66 |
+
st.sidebar.write("## Project Usage")
|
| 67 |
+
st.sidebar.write("This project performs sentiment analysis on Amazon reviews to determine whether a review's sentiment is positive or negative.")
|
| 68 |
+
st.sidebar.write("## GitHub Repository")
|
| 69 |
+
st.sidebar.write("Source Code here [GitHub repository](https://github.com/tikendraw/Amazon-review-sentiment-analysis).")
|
| 70 |
+
st.sidebar.write("If you have any feedback or suggestions, feel free to open an issue or a pull request.")
|
| 71 |
+
st.sidebar.write("## Like the Project?")
|
| 72 |
+
st.sidebar.write("If you find this project interesting or useful, don't forget to give it a star on GitHub!")
|
| 73 |
+
st.sidebar.markdown('', unsafe_allow_html=True)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
st.sidebar.write('### Created by:')
|
| 77 |
+
c1, c2 = st.sidebar.columns([4,4])
|
| 78 |
+
c1.image('./src/me.jpg', width=150)
|
| 79 |
+
c2.write('### Tikendra Kumar Sahu')
|
| 80 |
+
st.sidebar.write('Data Science Enthusiast')
|
| 81 |
+
|
| 82 |
+
if st.sidebar.button('Github'):
|
| 83 |
+
webbrowser.open('https://github.com/tikendraw')
|
| 84 |
+
|
| 85 |
+
if st.sidebar.button('LinkdIn'):
|
| 86 |
+
webbrowser.open('https://www.linkedin.com/in/tikendraw/')
|
| 87 |
+
|
| 88 |
+
if st.sidebar.button('Instagram'):
|
| 89 |
+
webbrowser.open('https://www.instagram.com/tikendraw/')
|
| 90 |
+
|
config.py
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
|
| 4 |
+
cur_dir= Path(os.getcwd())
|
| 5 |
+
|
| 6 |
+
# Data paths
|
| 7 |
+
DATA_DIR = cur_dir / "dataset"
|
| 8 |
+
PREPROCESSED_DATA_PATH = DATA_DIR / "preprocessed_df.csv"
|
| 9 |
+
|
| 10 |
+
# Paths
|
| 11 |
+
MODEL_DIR = cur_dir / "model"
|
| 12 |
+
LOG_DIR = cur_dir / "logs"
|
| 13 |
+
VECTORIZE_PATH = cur_dir / 'model' / 'text_vectorizer.pkl'
|
| 14 |
+
|
| 15 |
+
TEXT_VECTOR_FILENAME = "text_vectorizer.pkl"
|
| 16 |
+
MODEL_FILENAME = "full_model.h5"
|
| 17 |
+
COUNTER_NAME = "counter.pkl"
|
| 18 |
+
|
| 19 |
+
# Text Vectorizer hyperparameters
|
| 20 |
+
MAX_TOKEN = 100_000 # don't change this
|
| 21 |
+
OUTPUT_SEQUENCE_LENGTH = 175 # don't change this
|
| 22 |
+
|
| 23 |
+
# Model hyperparameters
|
| 24 |
+
BATCH_SIZE = 32
|
| 25 |
+
DIM = 8
|
| 26 |
+
EPOCHS = 10
|
| 27 |
+
TRAIN_SIZE = 0.05
|
| 28 |
+
TEST_SIZE = 0.01
|
| 29 |
+
LEARNING_RATE = 0.002
|
| 30 |
+
RANDOM_STATE = 42
|
| 31 |
+
SEED = 42
|
| 32 |
+
#callback
|
| 33 |
+
EARLY_STOPPING_PATIENCE = 2
|
model.png
ADDED
|
model/counter.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dafbc639b1e553ae24200370ca9f49e1d6779ba72c22573ae9b78ae15aff772e
|
| 3 |
+
size 12171041
|
model/full_model.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:560d2c40c82de35d9238a85dedae6b85a5df85617212c12df67bef32825ff83f
|
| 3 |
+
size 9714960
|
model/model_weights.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b5912bd4d93874c16f8eb4269dd86d1226c8c5d20ddec48aa8d6ce326b3da027
|
| 3 |
+
size 3245400
|
model/text_vectorizer.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:40f64980ca826dde2aeb0d092e7e47ed633ec13eb0a079be4b280c7ad0c7ea3f
|
| 3 |
+
size 1074029
|
predict.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import logging
|
| 3 |
+
import tensorflow as tf
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
from src.utils import configure_logging, load_model_and_vectorizer
|
| 6 |
+
|
| 7 |
+
from src.data_preprocessing import clean_text
|
| 8 |
+
import config
|
| 9 |
+
from tensorflow.keras.layers import TextVectorization
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
# constants
|
| 13 |
+
DATA_DIR = Path(os.getcwd()) / 'dataset'
|
| 14 |
+
DATA_PATH = DATA_DIR / 'preprocessed_df.csv'
|
| 15 |
+
MODEL_PATH = Path(config.MODEL_DIR) / config.MODEL_FILENAME
|
| 16 |
+
VECTORIZER_PATH = Path(config.MODEL_DIR) / config.TEXT_VECTOR_FILENAME
|
| 17 |
+
COUNTER_PATH = Path(config.MODEL_DIR) / config.COUNTER_NAME
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def predict_sentiment(title, text, text_vectorizer, lstm_model):
|
| 21 |
+
review = f'{title} {text}' # concatenate the title and text
|
| 22 |
+
clean_review = clean_text(review)
|
| 23 |
+
review_sequence = text_vectorizer([clean_review])
|
| 24 |
+
prediction = lstm_model.predict(review_sequence)
|
| 25 |
+
sentiment_score = prediction[0][0]
|
| 26 |
+
sentiment_label = 'Positive' if sentiment_score >= 0.5 else 'Negative'
|
| 27 |
+
return sentiment_label, sentiment_score
|
| 28 |
+
|
| 29 |
+
def main():
|
| 30 |
+
configure_logging(config.LOG_DIR, "prediction_log.txt", logging.INFO)
|
| 31 |
+
text_vectorizer, lstm_model = load_model_and_vectorizer(VECTORIZER_PATH, MODEL_PATH)
|
| 32 |
+
|
| 33 |
+
if text_vectorizer is None or lstm_model is None:
|
| 34 |
+
logging.error('Could not load text vectorizer and model. Aborting prediction.')
|
| 35 |
+
return
|
| 36 |
+
|
| 37 |
+
title = input("Enter the title of the review: ")
|
| 38 |
+
text = input("Enter the text of the review: ")
|
| 39 |
+
|
| 40 |
+
sentiment_label, sentiment_score = predict_sentiment(title, text, text_vectorizer, lstm_model)
|
| 41 |
+
logging.debug(f'\nReview title: {title} \nReview text: {text}')
|
| 42 |
+
logging.info(f'Review Sentiment: {sentiment_label} (Score: {sentiment_score:.4f})')
|
| 43 |
+
|
| 44 |
+
if __name__ == "__main__":
|
| 45 |
+
main()
|
requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
contractions
|
| 2 |
+
tensorflow
|
| 3 |
+
sklearn
|
| 4 |
+
funcyou
|
| 5 |
+
polars
|
| 6 |
+
scikit-learn
|
src/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
__all__ = ['data_preprocessing','make_dataset','model', 'utils']
|
src/data_preprocessing.py
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import re
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
import polars as pl
|
| 6 |
+
from sklearn.model_selection import train_test_split
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def preprocess_data(data_dir:Path):
|
| 10 |
+
# Read the CSV file using Polars
|
| 11 |
+
df = pl.read_csv(data_dir / 'train.csv', new_columns=['polarity', 'title', 'text'])
|
| 12 |
+
|
| 13 |
+
assert df['polarity'].max()==2
|
| 14 |
+
assert df['polarity'].min()==1
|
| 15 |
+
|
| 16 |
+
# Drop rows with null values
|
| 17 |
+
df.drop_nulls()
|
| 18 |
+
|
| 19 |
+
# Map polarity to binary values (0 for negative, 1 for positive)
|
| 20 |
+
df = df.with_columns([
|
| 21 |
+
pl.col('polarity').apply(lambda x: 0 if x == 1 else 1)
|
| 22 |
+
])
|
| 23 |
+
|
| 24 |
+
# Cast polarity column to Int16
|
| 25 |
+
df = df.with_columns([
|
| 26 |
+
pl.col('polarity').cast(pl.Int16, strict=False)
|
| 27 |
+
])
|
| 28 |
+
|
| 29 |
+
# Combine title and text columns to create the review column
|
| 30 |
+
df = df.with_columns([
|
| 31 |
+
(pl.col('title') + ' ' + pl.col('text')).alias('review')
|
| 32 |
+
])
|
| 33 |
+
|
| 34 |
+
df = df.with_columns([
|
| 35 |
+
(pl.col('review').str().lower())
|
| 36 |
+
])
|
| 37 |
+
|
| 38 |
+
# Select relevant columns
|
| 39 |
+
df = df.select(['review', 'polarity'])
|
| 40 |
+
|
| 41 |
+
# Perform text cleaning using a function
|
| 42 |
+
df = df.with_columns([
|
| 43 |
+
pl.col('review').apply(clean_text)
|
| 44 |
+
])
|
| 45 |
+
|
| 46 |
+
df.write_csv(data_dir/'preprocessed_df.csv')
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
import re
|
| 51 |
+
|
| 52 |
+
import contractions
|
| 53 |
+
|
| 54 |
+
# Compile the regular expressions outside the function for better performance
|
| 55 |
+
PUNCTUATION_REGEX = re.compile(r'[^\w\s]')
|
| 56 |
+
DIGIT_REGEX = re.compile(r'\d')
|
| 57 |
+
SPECIAL_CHARACTERS_REGEX = re.compile(r'[#,@,&]')
|
| 58 |
+
MULTIPLE_SPACES_REGEX = re.compile(r'\s+')
|
| 59 |
+
|
| 60 |
+
def clean_text(x: str) -> str:
|
| 61 |
+
expanded_text = contractions.fix(x) # Expand contractions
|
| 62 |
+
text = PUNCTUATION_REGEX.sub(' ', expanded_text.lower()) # Remove punctuation after lowering
|
| 63 |
+
text = DIGIT_REGEX.sub('', text) # Remove digits
|
| 64 |
+
# Remove special characters (#,@,&)
|
| 65 |
+
text = SPECIAL_CHARACTERS_REGEX.sub('', text)
|
| 66 |
+
# Remove multiple spaces with single space
|
| 67 |
+
text = MULTIPLE_SPACES_REGEX.sub(' ', text)
|
| 68 |
+
return text.strip()
|
src/make_dataset.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# train.py
|
| 2 |
+
import sys
|
| 3 |
+
|
| 4 |
+
import tensorflow as tf
|
| 5 |
+
|
| 6 |
+
# def create_datasets(x_train, y_train, text_vectorizer, batch_size):
|
| 7 |
+
# print('Building slices...')
|
| 8 |
+
# train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(batch_size)
|
| 9 |
+
# print('Mapping...')
|
| 10 |
+
# train_dataset = train_dataset.map(lambda x, y: (text_vectorizer(x), y), tf.data.AUTOTUNE)
|
| 11 |
+
# print('Prefetching...')
|
| 12 |
+
# train_dataset = train_dataset.prefetch(tf.data.AUTOTUNE)
|
| 13 |
+
# return train_dataset
|
| 14 |
+
|
| 15 |
+
def sizeof_fmt(num, suffix='B'):
|
| 16 |
+
''' by Fred Cirera, https://stackoverflow.com/a/1094933/1870254, modified'''
|
| 17 |
+
for unit in ['','Ki','Mi','Gi','Ti','Pi','Ei','Zi']:
|
| 18 |
+
if abs(num) < 1024.0:
|
| 19 |
+
return "%3.1f %s%s" % (num, unit, suffix)
|
| 20 |
+
num /= 1024.0
|
| 21 |
+
return "%.1f %s%s" % (num, 'Yi', suffix)
|
| 22 |
+
|
| 23 |
+
for name, size in sorted(((name, sys.getsizeof(value)) for name, value in list(
|
| 24 |
+
locals().items())), key= lambda x: -x[1], reverse = False)[:10]:
|
| 25 |
+
print("{:>30}: {:>8}".format(name, sizeof_fmt(size)))
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def data_generator(x, y):
|
| 30 |
+
num_samples = len(x)
|
| 31 |
+
for i in range(num_samples):
|
| 32 |
+
yield x[i], y[i]
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def create_datasets(x, y, text_vectorizer, batch_size:int = 32, shuffle:bool=False, n_repeat:int = 0, buffer_size:int=1_000_000):
|
| 36 |
+
|
| 37 |
+
generator = data_generator(x, y)
|
| 38 |
+
print('Generating...')
|
| 39 |
+
train_dataset = tf.data.Dataset.from_generator(
|
| 40 |
+
lambda: generator,
|
| 41 |
+
output_signature=(
|
| 42 |
+
tf.TensorSpec(shape=(None, x.shape[1]), dtype=tf.string),
|
| 43 |
+
tf.TensorSpec(shape=(None, y.shape[1]), dtype=tf.int32)
|
| 44 |
+
)
|
| 45 |
+
)
|
| 46 |
+
print('Mapping...')
|
| 47 |
+
train_dataset = train_dataset.map(lambda x, y: (tf.cast(text_vectorizer(x), tf.int32)[0], y[0]), tf.data.AUTOTUNE)
|
| 48 |
+
train_dataset = train_dataset.batch(batch_size)
|
| 49 |
+
|
| 50 |
+
if shuffle:
|
| 51 |
+
train_dataset = train_dataset.shuffle(buffer_size)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
if n_repeat > 0:
|
| 55 |
+
return train_dataset.cache().repeat(n_repeat).prefetch(tf.data.AUTOTUNE)
|
| 56 |
+
elif n_repeat == -1:
|
| 57 |
+
return train_dataset.cache().repeat().prefetch(tf.data.AUTOTUNE)
|
| 58 |
+
elif n_repeat == 0:
|
| 59 |
+
return train_dataset.cache().prefetch(tf.data.AUTOTUNE)
|
| 60 |
+
|
src/me.jpg
ADDED

|
src/model.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# model.py
|
| 2 |
+
from tensorflow import keras
|
| 3 |
+
from tensorflow.keras.layers import (LSTM, Dense, Dropout, Embedding,
|
| 4 |
+
TextVectorization)
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def create_lstm_model(input_shape, max_tokens, dim):
|
| 8 |
+
inputs = keras.Input(shape=(input_shape))
|
| 9 |
+
embedding_layer = Embedding(input_dim=max_tokens, output_dim=dim, mask_zero=True, input_length=input_shape, name='embedding_layer')(inputs)
|
| 10 |
+
x = LSTM(16, return_sequences=True, name = 'lstm_layer_1')(embedding_layer)
|
| 11 |
+
x = LSTM(16, name = 'lstm_layer_2')(x)
|
| 12 |
+
x = Dropout(0.4, name ='dropout_layer')(x)
|
| 13 |
+
x = Dense(64, activation='relu', name = 'dense_layer_1')(x)
|
| 14 |
+
outputs = Dense(1, activation='sigmoid', name = 'dense_layer_2_final')(x)
|
| 15 |
+
return keras.Model(inputs=inputs, outputs=outputs, name='model_lstm')
|
| 16 |
+
|
src/utils.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
import pickle
|
| 4 |
+
import re
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
|
| 7 |
+
import tensorflow as tf
|
| 8 |
+
from tensorflow.keras.layers import TextVectorization
|
| 9 |
+
|
| 10 |
+
from .data_preprocessing import clean_text
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
# Configure logging
|
| 14 |
+
def configure_logging(log_dir, log_filename, log_level=logging.INFO):
|
| 15 |
+
|
| 16 |
+
log_dir = Path(log_dir)
|
| 17 |
+
log_dir.mkdir(exist_ok=True)
|
| 18 |
+
log_file = log_dir / log_filename
|
| 19 |
+
|
| 20 |
+
# Configure logging to both console and file
|
| 21 |
+
logging.basicConfig(level=log_level,
|
| 22 |
+
format='%(asctime)s - %(levelname)s - %(message)s',
|
| 23 |
+
handlers=[
|
| 24 |
+
logging.StreamHandler(),
|
| 25 |
+
logging.FileHandler(log_file)
|
| 26 |
+
])
|
| 27 |
+
return
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def save_text_vectorizer(text_vectorizer, filename):
|
| 31 |
+
config = text_vectorizer.get_config()
|
| 32 |
+
with open(filename, 'wb') as f:
|
| 33 |
+
pickle.dump({'config': config}, f)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def load_counter(filename):
|
| 37 |
+
with open (filename,'rb') as counter :
|
| 38 |
+
return pickle.load(counter)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def load_model(model, model_dir):
|
| 42 |
+
"""Load the model from disk."""
|
| 43 |
+
# Load the Keras model
|
| 44 |
+
return model.load_weights(model_dir)
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
# to load text vectorizer
|
| 48 |
+
def load_text_vectorizer(vectorizer_path):
|
| 49 |
+
from_disk = pickle.load(open(vectorizer_path, "rb"))
|
| 50 |
+
return TextVectorization.from_config(from_disk['config'])
|
| 51 |
+
|
| 52 |
+
# Pickle the config and weights
|
| 53 |
+
def save_text_vectorizer(vectorizer_path):
|
| 54 |
+
pickle.dump({'config': text_vectorizer.get_config()}
|
| 55 |
+
, open(vectorizer_path, "wb"))
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def load_model_and_vectorizer(vectorizer_path, model_path):
|
| 59 |
+
try:
|
| 60 |
+
text_vectorizer = load_text_vectorizer(vectorizer_path)
|
| 61 |
+
lstm_model = tf.keras.models.load_model(model_path)
|
| 62 |
+
return text_vectorizer, lstm_model
|
| 63 |
+
except Exception as e:
|
| 64 |
+
logging.error(f'Error loading vectorizer and model: {e}')
|
| 65 |
+
return None, None
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def predict_sentiment(title, text, text_vectorizer, lstm_model):
|
| 70 |
+
review = f'{title} {text}' # concatenate the title and text
|
| 71 |
+
clean_review = clean_text(review)
|
| 72 |
+
review_sequence = text_vectorizer([clean_review])
|
| 73 |
+
prediction = lstm_model.predict(review_sequence)
|
| 74 |
+
sentiment_score = prediction[0][0]
|
| 75 |
+
sentiment_label = 'Positive' if sentiment_score >= 0.5 else 'Negative'
|
| 76 |
+
return sentiment_label, sentiment_score
|
| 77 |
+
|
train.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import polars as pl
|
| 2 |
+
import tensorflow as tf
|
| 3 |
+
from sklearn.model_selection import train_test_split
|
| 4 |
+
from src import utils, make_dataset, model
|
| 5 |
+
import config
|
| 6 |
+
import pickle
|
| 7 |
+
from tensorflow.keras.layers import TextVectorization
|
| 8 |
+
import os
|
| 9 |
+
import logging
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
import numpy as np
|
| 12 |
+
from sklearn.utils import check_random_state
|
| 13 |
+
|
| 14 |
+
# constants
|
| 15 |
+
DATA_DIR = Path(os.getcwd()) / 'dataset'
|
| 16 |
+
DATA_PATH = DATA_DIR / 'preprocessed_df.csv'
|
| 17 |
+
MODEL_PATH = Path(config.MODEL_DIR) / config.MODEL_FILENAME
|
| 18 |
+
VECTORIZER_PATH = Path(config.MODEL_DIR) / config.TEXT_VECTOR_FILENAME
|
| 19 |
+
COUNTER_PATH = Path(config.MODEL_DIR) / config.COUNTER_NAME
|
| 20 |
+
|
| 21 |
+
def set_global_seed(seed):
|
| 22 |
+
np.random.seed(seed)
|
| 23 |
+
tf.random.set_seed(seed)
|
| 24 |
+
global random_state
|
| 25 |
+
random_state = check_random_state(seed)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def read_data(DATA_PATH, train_size:float = 1.0):
|
| 30 |
+
logging.info('Reading data...')
|
| 31 |
+
df = pl.read_csv(DATA_PATH)
|
| 32 |
+
sample_rate = int(df.shape[0] * train_size)
|
| 33 |
+
df = df.sample(sample_rate, seed=config.SEED)
|
| 34 |
+
logging.info(f'Data shape after sampling: {df.shape}')
|
| 35 |
+
return df
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def main():
|
| 39 |
+
|
| 40 |
+
# Call the function to set the seeds
|
| 41 |
+
set_global_seed(config.SEED)
|
| 42 |
+
|
| 43 |
+
utils.configure_logging(config.LOG_DIR, "training_log.txt", log_level=logging.INFO)
|
| 44 |
+
|
| 45 |
+
df = read_data(DATA_PATH, config.TRAIN_SIZE)
|
| 46 |
+
|
| 47 |
+
logging.info(f'GPU count: {len(tf.config.list_physical_devices("GPU"))}')
|
| 48 |
+
|
| 49 |
+
counter = utils.load_counter(COUNTER_PATH)
|
| 50 |
+
|
| 51 |
+
# Text vectorization
|
| 52 |
+
logging.info('Text Vectorizer loading ...')
|
| 53 |
+
text_vectorizer = TextVectorization(max_tokens=config.MAX_TOKEN, standardize='lower_and_strip_punctuation',
|
| 54 |
+
split='whitespace',
|
| 55 |
+
ngrams= None ,
|
| 56 |
+
output_mode='int',
|
| 57 |
+
output_sequence_length=config.OUTPUT_SEQUENCE_LENGTH,
|
| 58 |
+
pad_to_max_tokens=True,
|
| 59 |
+
vocabulary = list(counter.keys())[:config.MAX_TOKEN-2])
|
| 60 |
+
|
| 61 |
+
logging.info(f"text vectorizer vocab size: {text_vectorizer.vocabulary_size()}")
|
| 62 |
+
|
| 63 |
+
# Create datasets
|
| 64 |
+
logging.info('Preparing dataset...')
|
| 65 |
+
xtrain, xtest, ytrain, ytest = train_test_split(df.select('review'), df.select('polarity'), test_size=config.TEST_SIZE, random_state=config.SEED, stratify=df['polarity'])
|
| 66 |
+
del(df)
|
| 67 |
+
|
| 68 |
+
train_len = xtrain.shape[0]//config.BATCH_SIZE
|
| 69 |
+
test_len = xtest.shape[0]//config.BATCH_SIZE
|
| 70 |
+
|
| 71 |
+
logging.info('Preparing train dataset...')
|
| 72 |
+
train_dataset = make_dataset.create_datasets(xtrain, ytrain, text_vectorizer, batch_size=config.BATCH_SIZE, shuffle=False)
|
| 73 |
+
del(xtrain, ytrain)
|
| 74 |
+
|
| 75 |
+
logging.info('Preparing test dataset...')
|
| 76 |
+
test_dataset = make_dataset.create_datasets(xtest, ytest, text_vectorizer, batch_size=config.BATCH_SIZE, shuffle=False)
|
| 77 |
+
del(xtest, ytest, counter, text_vectorizer )
|
| 78 |
+
|
| 79 |
+
logging.info('Model loading...')
|
| 80 |
+
# Train LSTM model
|
| 81 |
+
lstm_model = model.create_lstm_model(input_shape=(config.OUTPUT_SEQUENCE_LENGTH,), max_tokens=config.MAX_TOKEN, dim=config.DIM)
|
| 82 |
+
lstm_model.compile(optimizer=tf.keras.optimizers.Nadam(learning_rate=config.LEARNING_RATE),
|
| 83 |
+
loss = tf.keras.losses.BinaryCrossentropy(),
|
| 84 |
+
metrics=['Accuracy'])
|
| 85 |
+
|
| 86 |
+
print(lstm_model.summary())
|
| 87 |
+
|
| 88 |
+
# Callbacks
|
| 89 |
+
callbacks = [
|
| 90 |
+
tf.keras.callbacks.EarlyStopping(monitor='loss', patience=config.EARLY_STOPPING_PATIENCE, restore_best_weights=True),
|
| 91 |
+
tf.keras.callbacks.ModelCheckpoint(monitor='loss', filepath=MODEL_PATH, save_best_only=True)
|
| 92 |
+
]
|
| 93 |
+
|
| 94 |
+
# Load model weights if exists
|
| 95 |
+
try:
|
| 96 |
+
lstm_model.load_weights(MODEL_PATH)
|
| 97 |
+
logging.info('Model weights loaded!')
|
| 98 |
+
except Exception as e:
|
| 99 |
+
logging.error(f'Exception occured while loading model weights {e}')
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
# Training
|
| 103 |
+
logging.info('Model training...')
|
| 104 |
+
lstm_history = lstm_model.fit(train_dataset, validation_data=test_dataset, epochs=config.EPOCHS,
|
| 105 |
+
steps_per_epoch=int(1.0*(train_len / config.EPOCHS)),
|
| 106 |
+
validation_steps=int(1.0*(test_len / config.EPOCHS)),
|
| 107 |
+
callbacks=callbacks)
|
| 108 |
+
logging.info('Training Complete!')
|
| 109 |
+
|
| 110 |
+
logging.info('Training history:')
|
| 111 |
+
logging.info(lstm_history.history)
|
| 112 |
+
print(pl.DataFrame(lstm_history.history))
|
| 113 |
+
|
| 114 |
+
# Save text vectorizer and LSTM model
|
| 115 |
+
logging.info('Saving Model')
|
| 116 |
+
lstm_model.save(MODEL_PATH, save_format='h5')
|
| 117 |
+
logging.info('Done')
|
| 118 |
+
|
| 119 |
+
if __name__ == "__main__":
|
| 120 |
+
main()
|