Spaces:
Sleeping

Sleeping

Upload 8 files
Browse files- Building_a_Safety_Agent.ipynb +316 -0
- README.md +3 -3
- app.py +80 -4
- data_list.py +1 -1
- model_list.py +79 -0
- nist.png +0 -0
- requirements.txt +4 -0
Building_a_Safety_Agent.ipynb
ADDED
|
@@ -0,0 +1,316 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"nbformat": 4,
|
| 3 |
+
"nbformat_minor": 0,
|
| 4 |
+
"metadata": {
|
| 5 |
+
"colab": {
|
| 6 |
+
"provenance": []
|
| 7 |
+
},
|
| 8 |
+
"kernelspec": {
|
| 9 |
+
"name": "python3",
|
| 10 |
+
"display_name": "Python 3"
|
| 11 |
+
},
|
| 12 |
+
"language_info": {
|
| 13 |
+
"name": "python"
|
| 14 |
+
}
|
| 15 |
+
},
|
| 16 |
+
"cells": [
|
| 17 |
+
{
|
| 18 |
+
"cell_type": "code",
|
| 19 |
+
"execution_count": null,
|
| 20 |
+
"metadata": {
|
| 21 |
+
"id": "bdp9fSdWKBhp",
|
| 22 |
+
"collapsed": true
|
| 23 |
+
},
|
| 24 |
+
"outputs": [],
|
| 25 |
+
"source": [
|
| 26 |
+
"# Install the Libraries used in this notebook.\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"!pip install -qU langchain openai transformers selfcheckgpt profanityfilter\n",
|
| 29 |
+
"! python -m spacy download en"
|
| 30 |
+
]
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"cell_type": "markdown",
|
| 34 |
+
"source": [
|
| 35 |
+
"##Safety Agent"
|
| 36 |
+
],
|
| 37 |
+
"metadata": {
|
| 38 |
+
"id": "6wj7wxo9aTe5"
|
| 39 |
+
}
|
| 40 |
+
},
|
| 41 |
+
{
|
| 42 |
+
"cell_type": "code",
|
| 43 |
+
"source": [
|
| 44 |
+
"from langchain.chat_models import ChatOpenAI\n",
|
| 45 |
+
"from langchain.chains.conversation.memory import ConversationBufferWindowMemory\n",
|
| 46 |
+
"import openai\n",
|
| 47 |
+
"import os\n",
|
| 48 |
+
"os.environ['OPENAI_API_KEY'] = openai.api_key= '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' #platform.openai.com api key\n",
|
| 49 |
+
"\n",
|
| 50 |
+
"# initialize LLM\n",
|
| 51 |
+
"llm = ChatOpenAI(\n",
|
| 52 |
+
" temperature=0,\n",
|
| 53 |
+
" model_name='gpt-3.5-turbo'\n",
|
| 54 |
+
")\n",
|
| 55 |
+
"\n",
|
| 56 |
+
"# initialize conversational memory\n",
|
| 57 |
+
"conversational_memory = ConversationBufferWindowMemory(\n",
|
| 58 |
+
" memory_key='chat_history',\n",
|
| 59 |
+
" k=5,\n",
|
| 60 |
+
" return_messages=True\n",
|
| 61 |
+
")"
|
| 62 |
+
],
|
| 63 |
+
"metadata": {
|
| 64 |
+
"id": "OIKitpN-fPSF"
|
| 65 |
+
},
|
| 66 |
+
"execution_count": null,
|
| 67 |
+
"outputs": []
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"cell_type": "markdown",
|
| 71 |
+
"source": [
|
| 72 |
+
"### Profanity Detection Tool"
|
| 73 |
+
],
|
| 74 |
+
"metadata": {
|
| 75 |
+
"id": "O6BLtKefgSxZ"
|
| 76 |
+
}
|
| 77 |
+
},
|
| 78 |
+
{
|
| 79 |
+
"cell_type": "code",
|
| 80 |
+
"source": [
|
| 81 |
+
"from profanityfilter import ProfanityFilter\n",
|
| 82 |
+
"import spacy\n",
|
| 83 |
+
"from langchain.tools import BaseTool\n",
|
| 84 |
+
"from typing import Optional\n",
|
| 85 |
+
"\n",
|
| 86 |
+
"class Profanity_Check(BaseTool):\n",
|
| 87 |
+
" name = \"Profanity_Checker\"\n",
|
| 88 |
+
" description = (\n",
|
| 89 |
+
" \"use this tool when you need to check for profanity in given text\"\n",
|
| 90 |
+
" )\n",
|
| 91 |
+
" def _run(\n",
|
| 92 |
+
" self,\n",
|
| 93 |
+
" sentence1: Optional[str] = None\n",
|
| 94 |
+
" ):\n",
|
| 95 |
+
" pf = ProfanityFilter()\n",
|
| 96 |
+
" flag = pf.is_profane(sentence1)\n",
|
| 97 |
+
" if flag: return 'Profanity Detected'\n",
|
| 98 |
+
" else: return 'No Profanity found'\n",
|
| 99 |
+
"\n",
|
| 100 |
+
"\n",
|
| 101 |
+
" def _arun(self, sentence1, sentence2):\n",
|
| 102 |
+
" raise NotImplementedError(\"This tool does not support async runs.\")\n"
|
| 103 |
+
],
|
| 104 |
+
"metadata": {
|
| 105 |
+
"id": "_SJa13N5i1kY"
|
| 106 |
+
},
|
| 107 |
+
"execution_count": null,
|
| 108 |
+
"outputs": []
|
| 109 |
+
},
|
| 110 |
+
{
|
| 111 |
+
"cell_type": "markdown",
|
| 112 |
+
"source": [
|
| 113 |
+
"### Hallucination Detection Tool"
|
| 114 |
+
],
|
| 115 |
+
"metadata": {
|
| 116 |
+
"id": "YicTP78lgXlT"
|
| 117 |
+
}
|
| 118 |
+
},
|
| 119 |
+
{
|
| 120 |
+
"cell_type": "code",
|
| 121 |
+
"source": [
|
| 122 |
+
"from selfcheckgpt.modeling_selfcheck import SelfCheckBERTScore\n",
|
| 123 |
+
"\n",
|
| 124 |
+
"class Hallucination_Scorer(BaseTool):\n",
|
| 125 |
+
" name = \"Hallucination_Scorer\"\n",
|
| 126 |
+
" description = (\n",
|
| 127 |
+
" \"use this tool when a you need to give hallucination scores\"\n",
|
| 128 |
+
" )\n",
|
| 129 |
+
" def _run(\n",
|
| 130 |
+
" self,\n",
|
| 131 |
+
" sentence1: Optional[str] = None\n",
|
| 132 |
+
" ):\n",
|
| 133 |
+
" selfcheck_bertscore = SelfCheckBERTScore()\n",
|
| 134 |
+
" nlp = spacy.load('en_core_web_sm')\n",
|
| 135 |
+
" passage = sentence1\n",
|
| 136 |
+
" sentences = [sent.text.strip() for sent in nlp(passage).sents]\n",
|
| 137 |
+
"\n",
|
| 138 |
+
" chat_completion = openai.ChatCompletion.create(model=\"gpt-3.5-turbo\", messages=[{\"role\": \"user\", \"content\": sentence1}])\n",
|
| 139 |
+
" sample1 = chat_completion.choices[0].message.content\n",
|
| 140 |
+
" chat_completion = openai.ChatCompletion.create(model=\"gpt-3.5-turbo\", messages=[{\"role\": \"user\", \"content\": sentence1}])\n",
|
| 141 |
+
" sample2 = chat_completion.choices[0].message.content\n",
|
| 142 |
+
" chat_completion = openai.ChatCompletion.create(model=\"gpt-3.5-turbo\", messages=[{\"role\": \"user\", \"content\": sentence1}])\n",
|
| 143 |
+
" sample3 = chat_completion.choices[0].message.content\n",
|
| 144 |
+
"# SelfCheck-BERTScore: Score for each sentence where value is in [0.0, 1.0] and high value means non-factual\n",
|
| 145 |
+
" sent_scores_bertscore = selfcheck_bertscore.predict(\n",
|
| 146 |
+
" sentences = sentences, # list of sentences\n",
|
| 147 |
+
" sampled_passages = [sample1, sample2, sample3], # list of sampled passages\n",
|
| 148 |
+
" )\n",
|
| 149 |
+
" return sent_scores_bertscore\n",
|
| 150 |
+
"\n",
|
| 151 |
+
"\n",
|
| 152 |
+
" def _arun(self, sentence1, sentence2):\n",
|
| 153 |
+
" raise NotImplementedError(\"This tool does not support async runs.\")\n"
|
| 154 |
+
],
|
| 155 |
+
"metadata": {
|
| 156 |
+
"id": "1CA0tBsWYC6K"
|
| 157 |
+
},
|
| 158 |
+
"execution_count": null,
|
| 159 |
+
"outputs": []
|
| 160 |
+
},
|
| 161 |
+
{
|
| 162 |
+
"cell_type": "markdown",
|
| 163 |
+
"source": [
|
| 164 |
+
"### Initializing Safety Agent\n"
|
| 165 |
+
],
|
| 166 |
+
"metadata": {
|
| 167 |
+
"id": "6wqgeEvKgex7"
|
| 168 |
+
}
|
| 169 |
+
},
|
| 170 |
+
{
|
| 171 |
+
"cell_type": "code",
|
| 172 |
+
"source": [
|
| 173 |
+
"from langchain.agents import initialize_agent\n",
|
| 174 |
+
"\n",
|
| 175 |
+
"# Pass the tools\n",
|
| 176 |
+
"tools = [Hallucination_Scorer(),Profanity_Check()]\n",
|
| 177 |
+
"\n",
|
| 178 |
+
"# initialize agent with tools\n",
|
| 179 |
+
"agent = initialize_agent(\n",
|
| 180 |
+
" agent='chat-conversational-react-description',\n",
|
| 181 |
+
" tools=tools, # Point each smaller sized agent towards the test we use\n",
|
| 182 |
+
" llm=llm, # Can be buiult over any LLM\n",
|
| 183 |
+
" verbose=True, ## Temperature for responses is set to zero for determinsitc test score// change to 1 when generating reports.\n",
|
| 184 |
+
" max_iterations=3, # Avoid Looping\n",
|
| 185 |
+
" early_stopping_method='generate', # Stop and generate a score\n",
|
| 186 |
+
" memory=conversational_memory # Chat Memory\n",
|
| 187 |
+
"\n",
|
| 188 |
+
")"
|
| 189 |
+
],
|
| 190 |
+
"metadata": {
|
| 191 |
+
"id": "4hI5kL3I10sM"
|
| 192 |
+
},
|
| 193 |
+
"execution_count": null,
|
| 194 |
+
"outputs": []
|
| 195 |
+
},
|
| 196 |
+
{
|
| 197 |
+
"cell_type": "markdown",
|
| 198 |
+
"source": [
|
| 199 |
+
"##### Loading generated policy"
|
| 200 |
+
],
|
| 201 |
+
"metadata": {
|
| 202 |
+
"id": "RNxBUVOsjXpr"
|
| 203 |
+
}
|
| 204 |
+
},
|
| 205 |
+
{
|
| 206 |
+
"cell_type": "code",
|
| 207 |
+
"source": [
|
| 208 |
+
"with open(\"/content/Generated_Policy.txt\", \"r\") as file1:\n",
|
| 209 |
+
" text = file1.read()\n",
|
| 210 |
+
" generated_policy = ' '.join(text.split('\\n'))\n",
|
| 211 |
+
"file1.close()"
|
| 212 |
+
],
|
| 213 |
+
"metadata": {
|
| 214 |
+
"id": "exp-mK78gbUG",
|
| 215 |
+
"collapsed": true
|
| 216 |
+
},
|
| 217 |
+
"execution_count": null,
|
| 218 |
+
"outputs": []
|
| 219 |
+
},
|
| 220 |
+
{
|
| 221 |
+
"cell_type": "code",
|
| 222 |
+
"source": [
|
| 223 |
+
"generated_policy"
|
| 224 |
+
],
|
| 225 |
+
"metadata": {
|
| 226 |
+
"id": "KsGtYtrkgpey"
|
| 227 |
+
},
|
| 228 |
+
"execution_count": null,
|
| 229 |
+
"outputs": []
|
| 230 |
+
},
|
| 231 |
+
{
|
| 232 |
+
"cell_type": "markdown",
|
| 233 |
+
"source": [
|
| 234 |
+
"### Hallucination Scoring"
|
| 235 |
+
],
|
| 236 |
+
"metadata": {
|
| 237 |
+
"id": "2_32mHKGjeqt"
|
| 238 |
+
}
|
| 239 |
+
},
|
| 240 |
+
{
|
| 241 |
+
"cell_type": "code",
|
| 242 |
+
"source": [
|
| 243 |
+
"prompt1 = 'Hallucination score for :'+generated_policy"
|
| 244 |
+
],
|
| 245 |
+
"metadata": {
|
| 246 |
+
"id": "VWH3VDo03oHr"
|
| 247 |
+
},
|
| 248 |
+
"execution_count": null,
|
| 249 |
+
"outputs": []
|
| 250 |
+
},
|
| 251 |
+
{
|
| 252 |
+
"cell_type": "code",
|
| 253 |
+
"source": [
|
| 254 |
+
"var1 = agent(prompt1)"
|
| 255 |
+
],
|
| 256 |
+
"metadata": {
|
| 257 |
+
"id": "8aCm3m79hppI"
|
| 258 |
+
},
|
| 259 |
+
"execution_count": null,
|
| 260 |
+
"outputs": []
|
| 261 |
+
},
|
| 262 |
+
{
|
| 263 |
+
"cell_type": "code",
|
| 264 |
+
"source": [
|
| 265 |
+
"var1['output']"
|
| 266 |
+
],
|
| 267 |
+
"metadata": {
|
| 268 |
+
"id": "gum7V3J9QFBv"
|
| 269 |
+
},
|
| 270 |
+
"execution_count": null,
|
| 271 |
+
"outputs": []
|
| 272 |
+
},
|
| 273 |
+
{
|
| 274 |
+
"cell_type": "markdown",
|
| 275 |
+
"source": [
|
| 276 |
+
"### Profanity Detection"
|
| 277 |
+
],
|
| 278 |
+
"metadata": {
|
| 279 |
+
"id": "yjyYQJj0jlxm"
|
| 280 |
+
}
|
| 281 |
+
},
|
| 282 |
+
{
|
| 283 |
+
"cell_type": "code",
|
| 284 |
+
"source": [
|
| 285 |
+
"prompt2 = 'Check for profanity in '+generated_policy\n"
|
| 286 |
+
],
|
| 287 |
+
"metadata": {
|
| 288 |
+
"id": "xoc4nCbr4Im5"
|
| 289 |
+
},
|
| 290 |
+
"execution_count": null,
|
| 291 |
+
"outputs": []
|
| 292 |
+
},
|
| 293 |
+
{
|
| 294 |
+
"cell_type": "code",
|
| 295 |
+
"source": [
|
| 296 |
+
"var2 = agent(prompt2)"
|
| 297 |
+
],
|
| 298 |
+
"metadata": {
|
| 299 |
+
"id": "fBsWajM4lOyo"
|
| 300 |
+
},
|
| 301 |
+
"execution_count": null,
|
| 302 |
+
"outputs": []
|
| 303 |
+
},
|
| 304 |
+
{
|
| 305 |
+
"cell_type": "code",
|
| 306 |
+
"source": [
|
| 307 |
+
"var2['output']"
|
| 308 |
+
],
|
| 309 |
+
"metadata": {
|
| 310 |
+
"id": "Nc6aYJ1eYnpf"
|
| 311 |
+
},
|
| 312 |
+
"execution_count": null,
|
| 313 |
+
"outputs": []
|
| 314 |
+
}
|
| 315 |
+
]
|
| 316 |
+
}
|
README.md
CHANGED
|
@@ -1,10 +1,10 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
emoji: 🚀
|
| 4 |
colorFrom: gray
|
| 5 |
-
colorTo:
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 3.
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
---
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Explore
|
| 3 |
emoji: 🚀
|
| 4 |
colorFrom: gray
|
| 5 |
+
colorTo: blue
|
| 6 |
sdk: gradio
|
| 7 |
+
sdk_version: 3.43.2
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
---
|
app.py
CHANGED
|
@@ -1,8 +1,43 @@
|
|
| 1 |
import gradio as gr
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
from data_list import DataList
|
| 3 |
|
| 4 |
-
|
| 5 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
with gr.Row():
|
| 7 |
gr.Image(value="RAII.svg",scale=1,show_download_button=False,show_share_button=False,show_label=False,height=100,container=False)
|
| 8 |
gr.Markdown("# Datasets for Healthcare Teams")
|
|
@@ -16,5 +51,46 @@ with gr.Blocks() as demo:
|
|
| 16 |
demo.load(fn=data_list.render, inputs=[search_box, case_sensitive, filter_names, data_types,],outputs=[table,])
|
| 17 |
search_box.submit(fn=data_list.render, inputs=[search_box, case_sensitive, filter_names, data_types,], outputs=[table,])
|
| 18 |
search_button.click(fn=data_list.render, inputs=[search_box, case_sensitive, filter_names, data_types,], outputs=[table,])
|
| 19 |
-
|
| 20 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import gradio as gr
|
| 2 |
+
import IPython
|
| 3 |
+
import nbformat
|
| 4 |
+
from nbconvert import HTMLExporter
|
| 5 |
+
from IPython.display import HTML
|
| 6 |
+
import requests
|
| 7 |
+
from model_list import ModelList
|
| 8 |
from data_list import DataList
|
| 9 |
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def show_notebook(notebook_file):
|
| 13 |
+
with open(notebook_file, 'r', encoding='utf-8') as notebook_file:
|
| 14 |
+
notebook_content = nbformat.read(notebook_file, as_version=4)
|
| 15 |
+
html_expor = HTMLExporter()
|
| 16 |
+
html_output, resources = html_expor.from_notebook_node(notebook_content)
|
| 17 |
+
return html_output
|
| 18 |
+
|
| 19 |
+
def main():
|
| 20 |
+
data_list = DataList()
|
| 21 |
+
model_list = ModelList()
|
| 22 |
+
css = """
|
| 23 |
+
button.svelte-kqij2n{font-weight: bold !important;
|
| 24 |
+
background-color: #ebecf0;
|
| 25 |
+
color: black;
|
| 26 |
+
margin-left: 5px;}
|
| 27 |
+
#tlsnlbs{}
|
| 28 |
+
#mtcs{}
|
| 29 |
+
|
| 30 |
+
#mdls{}
|
| 31 |
+
#dts{}
|
| 32 |
+
.svelte-kqij2n .selected {
|
| 33 |
+
background-color: black;
|
| 34 |
+
color: white;
|
| 35 |
+
}
|
| 36 |
+
span.svelte-s1r2yt{font-weight: bold !important;
|
| 37 |
+
}
|
| 38 |
+
"""
|
| 39 |
+
with gr.Blocks(css=css) as demo:
|
| 40 |
+
with gr.Tab(label="DATASETS",elem_id="dts"):
|
| 41 |
with gr.Row():
|
| 42 |
gr.Image(value="RAII.svg",scale=1,show_download_button=False,show_share_button=False,show_label=False,height=100,container=False)
|
| 43 |
gr.Markdown("# Datasets for Healthcare Teams")
|
|
|
|
| 51 |
demo.load(fn=data_list.render, inputs=[search_box, case_sensitive, filter_names, data_types,],outputs=[table,])
|
| 52 |
search_box.submit(fn=data_list.render, inputs=[search_box, case_sensitive, filter_names, data_types,], outputs=[table,])
|
| 53 |
search_button.click(fn=data_list.render, inputs=[search_box, case_sensitive, filter_names, data_types,], outputs=[table,])
|
| 54 |
+
|
| 55 |
+
with gr.Tab(label="MODELS",elem_id="mdls"):
|
| 56 |
+
with gr.Row():
|
| 57 |
+
gr.Image(value="RAII.svg",scale=1,show_download_button=False,show_share_button=False,show_label=False,height=100,container=False)
|
| 58 |
+
gr.Markdown("# Models for Healthcare Teams")
|
| 59 |
+
search_box = gr.Textbox(label='Search Name',placeholder='You can search for titles with regular expressions. e.g. (?<!sur)face',max_lines=1)
|
| 60 |
+
case_sensitive = gr.Checkbox(label='Case Sensitive')
|
| 61 |
+
filter_names1 = gr.CheckboxGroup(choices=['NLP','Computer Vision', 'Multi-Model'], value=['NLP','Computer Vision', 'Multi-Model'], label='Task')
|
| 62 |
+
data_type_names1 = ['Biomedical Corpus','Scientific Corpus','Clinical Corpus','Image','Mixed']
|
| 63 |
+
data_types1 = gr.CheckboxGroup(choices=data_type_names1, value=data_type_names1, label='Training Data Type')
|
| 64 |
+
search_button = gr.Button('Search')
|
| 65 |
+
table = gr.HTML(show_label=False)
|
| 66 |
+
demo.load(fn=model_list.render, inputs=[search_box, case_sensitive, filter_names1, data_types1,],outputs=[table,])
|
| 67 |
+
search_box.submit(fn=model_list.render, inputs=[search_box, case_sensitive, filter_names1, data_types1,], outputs=[table,])
|
| 68 |
+
search_button.click(fn=model_list.render, inputs=[search_box, case_sensitive, filter_names1, data_types1,], outputs=[table,])
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
with gr.Tab(label="NOTEBOOKS",elem_id="nbs"):
|
| 73 |
+
with gr.Accordion("Building a Safety Agent using Langchain",open=False):
|
| 74 |
+
notebook='Building_a_Safety_Agent.ipynb'
|
| 75 |
+
colab_link="<a href='https://colab.research.google.com/drive/1BoxUprJQ7skeyA88gfGRVVgzsvFUwnqd?usp=sharing'><button style='box-sizing: border-box; border: 1px solid #000; padding: 5px;'>Open in Colab</button></a>"
|
| 76 |
+
gr.HTML(colab_link)
|
| 77 |
+
gr.HTML(show_notebook(notebook))
|
| 78 |
+
with gr.Accordion("LLM Hallucination Detection",open=False):
|
| 79 |
+
gr.HTML("Coming Soon")
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
with gr.Tab(label="METRICS",elem_id="mtcs"):
|
| 83 |
+
gr.HTML(value='<iframe src="https://v2-embednotion.com/Metrics-dbe5d86e2181438fb4eb1e4f01fa3955?pvs=4"></iframe> <style> iframe { width: 100%; height: 10vh; border: 2px solid #ccc; border-radius: 10px; padding: none; text-align: right; } </style>')
|
| 84 |
+
|
| 85 |
+
with gr.Tab(label="NIST-RAI INSTITUTE AI SAFETY RATINGS ",elem_id="nrasr"):
|
| 86 |
+
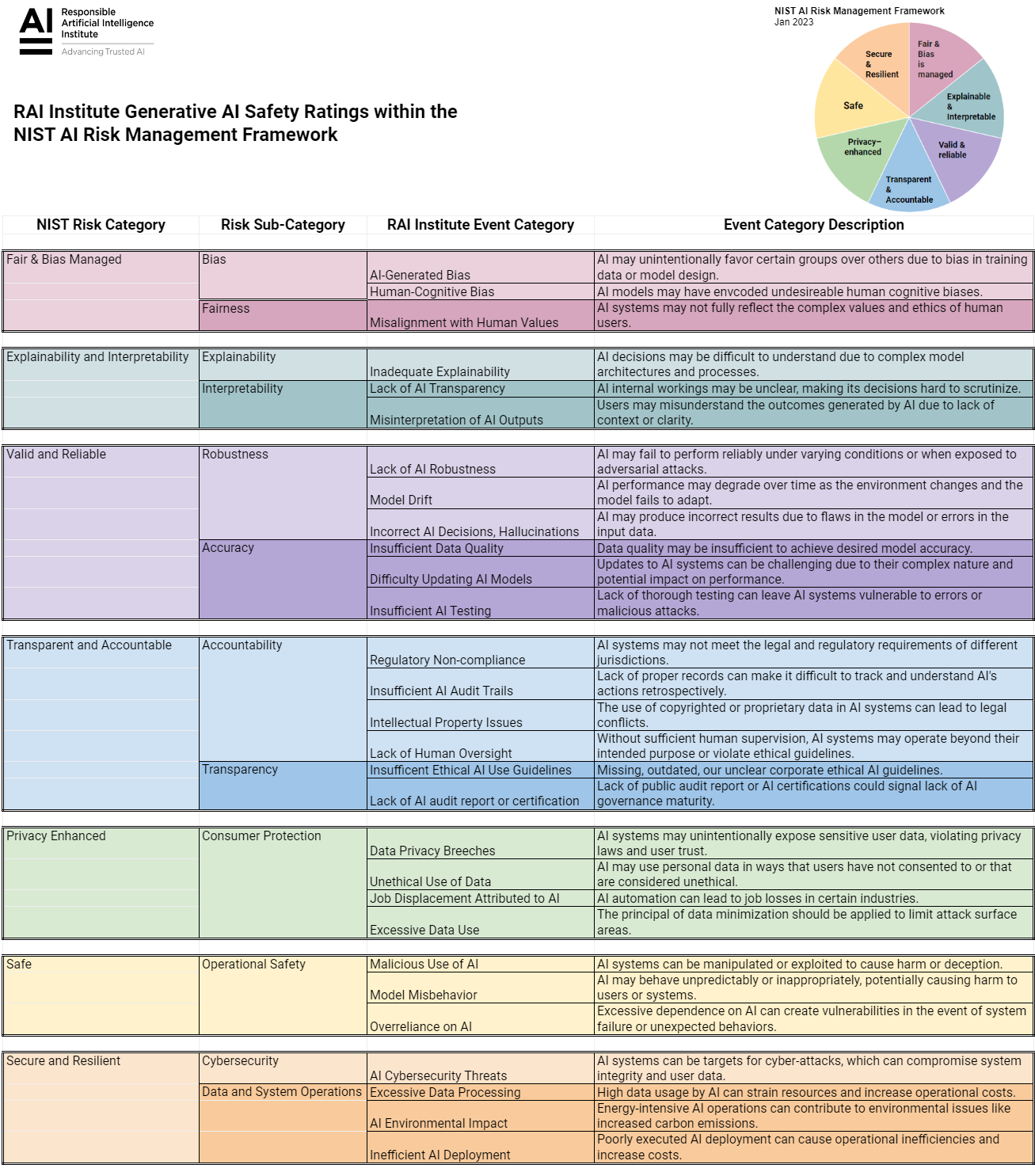
gr.Image(value="nist.png",scale=1,show_download_button=False,show_share_button=False,show_label=False,container=False)
|
| 87 |
+
|
| 88 |
+
with gr.Tab(label="TOOLKITS & LIBRARIES",elem_id="tlsnlbs"):
|
| 89 |
+
gr.HTML(value='<iframe src="https://v2-embednotion.com/Toolkits-Libraries-d5865c7ae5b0499988f5cc5fce711888?pvs=4"></iframe> <style> iframe { width: 100%; height: 10vh; border: 2px solid #ccc; border-radius: 10px; padding: none; } </style>')
|
| 90 |
+
|
| 91 |
+
demo.queue()
|
| 92 |
+
demo.launch(share=False)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
if __name__ == '__main__':
|
| 96 |
+
main()
|
data_list.py
CHANGED
|
@@ -74,4 +74,4 @@ class DataList:
|
|
| 74 |
{table_header}
|
| 75 |
{table_data}
|
| 76 |
</table>'''
|
| 77 |
-
return html
|
|
|
|
| 74 |
{table_header}
|
| 75 |
{table_data}
|
| 76 |
</table>'''
|
| 77 |
+
return html
|
model_list.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import annotations
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import pandas as pd
|
| 5 |
+
import requests
|
| 6 |
+
from huggingface_hub.hf_api import SpaceInfo
|
| 7 |
+
|
| 8 |
+
SHEET_ID = '1L7AHpWMVU_kZVLcsk8H2FTizgzeVxWPDoBxw7K8KHXw'
|
| 9 |
+
SHEET_NAME = 'model'
|
| 10 |
+
csv_url = f'https://docs.google.com/spreadsheets/d/{SHEET_ID}/gviz/tq?tqx=out:csv&sheet={SHEET_NAME}'
|
| 11 |
+
|
| 12 |
+
class ModelList:
|
| 13 |
+
def __init__(self):
|
| 14 |
+
self.table = pd.read_csv(csv_url)
|
| 15 |
+
self.table = self.table.astype({'Year':'string'})
|
| 16 |
+
self._preprocess_table()
|
| 17 |
+
|
| 18 |
+
self.table_header = '''
|
| 19 |
+
<tr>
|
| 20 |
+
<td width="15%">Name</td>
|
| 21 |
+
<td width="10%">Year Published</td>
|
| 22 |
+
<td width="10%">Source</td>
|
| 23 |
+
<td width="30%">About</td>
|
| 24 |
+
<td width="10%">Task</td>
|
| 25 |
+
<td width="15%">Training Data Type</td>
|
| 26 |
+
<td width="10%">Publication</td>
|
| 27 |
+
</tr>'''
|
| 28 |
+
|
| 29 |
+
def _preprocess_table(self) -> None:
|
| 30 |
+
self.table['name_lowercase'] = self.table['Name'].str.lower()
|
| 31 |
+
|
| 32 |
+
rows = []
|
| 33 |
+
for row in self.table.itertuples():
|
| 34 |
+
source = f'<a href="{row.Source}" target="_blank">Link</a>' if isinstance(
|
| 35 |
+
row.Source, str) else ''
|
| 36 |
+
paper = f'<a href="{row.Paper}" target="_blank">Link</a>' if isinstance(
|
| 37 |
+
row.Source, str) else ''
|
| 38 |
+
row = f'''
|
| 39 |
+
<tr>
|
| 40 |
+
<td>{row.Name}</td>
|
| 41 |
+
<td>{row.Year}</td>
|
| 42 |
+
<td>{source}</td>
|
| 43 |
+
<td>{row.About}</td>
|
| 44 |
+
<td>{row.task}</td>
|
| 45 |
+
<td>{row.data}</td>
|
| 46 |
+
<td>{paper}</td>
|
| 47 |
+
</tr>'''
|
| 48 |
+
rows.append(row)
|
| 49 |
+
self.table['html_table_content'] = rows
|
| 50 |
+
|
| 51 |
+
def render(self, search_query: str,
|
| 52 |
+
case_sensitive: bool,
|
| 53 |
+
filter_names: list[str],
|
| 54 |
+
data_types: list[str]) -> tuple[int, str]:
|
| 55 |
+
df = self.table
|
| 56 |
+
if search_query:
|
| 57 |
+
if case_sensitive:
|
| 58 |
+
df = df[df.name.str.contains(search_query)]
|
| 59 |
+
else:
|
| 60 |
+
df = df[df.name_lowercase.str.contains(search_query.lower())]
|
| 61 |
+
df = self.filter_table(df, filter_names, data_types)
|
| 62 |
+
result = self.to_html(df, self.table_header)
|
| 63 |
+
return result
|
| 64 |
+
|
| 65 |
+
@staticmethod
|
| 66 |
+
def filter_table(df: pd.DataFrame, filter_names: list[str], data_types: list[str]) -> pd.DataFrame:
|
| 67 |
+
df = df.loc[df.task.isin(set(filter_names))]
|
| 68 |
+
df = df.loc[df.data.isin(set(data_types))]
|
| 69 |
+
return df
|
| 70 |
+
|
| 71 |
+
@staticmethod
|
| 72 |
+
def to_html(df: pd.DataFrame, table_header: str) -> str:
|
| 73 |
+
table_data = ''.join(df.html_table_content)
|
| 74 |
+
html = f'''
|
| 75 |
+
<table>
|
| 76 |
+
{table_header}
|
| 77 |
+
{table_data}
|
| 78 |
+
</table>'''
|
| 79 |
+
return html
|
nist.png
ADDED
|
requirements.txt
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
nbconvert==6.3.0
|
| 2 |
+
ipython==7.28.0
|
| 3 |
+
ipython_genutils==0.1.0
|
| 4 |
+
jinja2==3.1.2
|