
adding an app
Browse files- .gitattributes +1 -0
- .gitignore +160 -0
- LICENSE +21 -0
- README.md +1 -1
- agents.py +117 -0
- app.py +118 -0
- data/sales_data.csv +0 -0
- images/.DS_Store +0 -0
- images/chinook.png +0 -0
- images/plugins.png +0 -0
- images/salesforce.png +0 -0
- models.py +90 -0
- requirements.txt +15 -0
- sandbox/flant5.py +16 -0
- sandbox/google.py +16 -0
- sandbox/test.py +61 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*.sqlite filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
share/python-wheels/
|
| 24 |
+
*.egg-info/
|
| 25 |
+
.installed.cfg
|
| 26 |
+
*.egg
|
| 27 |
+
MANIFEST
|
| 28 |
+
|
| 29 |
+
# PyInstaller
|
| 30 |
+
# Usually these files are written by a python script from a template
|
| 31 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 32 |
+
*.manifest
|
| 33 |
+
*.spec
|
| 34 |
+
|
| 35 |
+
# Installer logs
|
| 36 |
+
pip-log.txt
|
| 37 |
+
pip-delete-this-directory.txt
|
| 38 |
+
|
| 39 |
+
# Unit test / coverage reports
|
| 40 |
+
htmlcov/
|
| 41 |
+
.tox/
|
| 42 |
+
.nox/
|
| 43 |
+
.coverage
|
| 44 |
+
.coverage.*
|
| 45 |
+
.cache
|
| 46 |
+
nosetests.xml
|
| 47 |
+
coverage.xml
|
| 48 |
+
*.cover
|
| 49 |
+
*.py,cover
|
| 50 |
+
.hypothesis/
|
| 51 |
+
.pytest_cache/
|
| 52 |
+
cover/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
.pybuilder/
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 87 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 88 |
+
# .python-version
|
| 89 |
+
|
| 90 |
+
# pipenv
|
| 91 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 92 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 93 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 94 |
+
# install all needed dependencies.
|
| 95 |
+
#Pipfile.lock
|
| 96 |
+
|
| 97 |
+
# poetry
|
| 98 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 99 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 100 |
+
# commonly ignored for libraries.
|
| 101 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 102 |
+
#poetry.lock
|
| 103 |
+
|
| 104 |
+
# pdm
|
| 105 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 106 |
+
#pdm.lock
|
| 107 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 108 |
+
# in version control.
|
| 109 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 110 |
+
.pdm.toml
|
| 111 |
+
|
| 112 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 113 |
+
__pypackages__/
|
| 114 |
+
|
| 115 |
+
# Celery stuff
|
| 116 |
+
celerybeat-schedule
|
| 117 |
+
celerybeat.pid
|
| 118 |
+
|
| 119 |
+
# SageMath parsed files
|
| 120 |
+
*.sage.py
|
| 121 |
+
|
| 122 |
+
# Environments
|
| 123 |
+
.env
|
| 124 |
+
.venv
|
| 125 |
+
env/
|
| 126 |
+
venv/
|
| 127 |
+
ENV/
|
| 128 |
+
env.bak/
|
| 129 |
+
venv.bak/
|
| 130 |
+
|
| 131 |
+
# Spyder project settings
|
| 132 |
+
.spyderproject
|
| 133 |
+
.spyproject
|
| 134 |
+
|
| 135 |
+
# Rope project settings
|
| 136 |
+
.ropeproject
|
| 137 |
+
|
| 138 |
+
# mkdocs documentation
|
| 139 |
+
/site
|
| 140 |
+
|
| 141 |
+
# mypy
|
| 142 |
+
.mypy_cache/
|
| 143 |
+
.dmypy.json
|
| 144 |
+
dmypy.json
|
| 145 |
+
|
| 146 |
+
# Pyre type checker
|
| 147 |
+
.pyre/
|
| 148 |
+
|
| 149 |
+
# pytype static type analyzer
|
| 150 |
+
.pytype/
|
| 151 |
+
|
| 152 |
+
# Cython debug symbols
|
| 153 |
+
cython_debug/
|
| 154 |
+
|
| 155 |
+
# PyCharm
|
| 156 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 157 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 158 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 159 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 160 |
+
#.idea/
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 Phil Mui
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
---
|
| 2 |
title: Globe
|
| 3 |
-
emoji:
|
| 4 |
colorFrom: blue
|
| 5 |
colorTo: indigo
|
| 6 |
sdk: streamlit
|
|
|
|
| 1 |
---
|
| 2 |
title: Globe
|
| 3 |
+
emoji: 🌎
|
| 4 |
colorFrom: blue
|
| 5 |
colorTo: indigo
|
| 6 |
sdk: streamlit
|
agents.py
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
##############################################################################
|
| 2 |
+
# Agent interfaces that bridges private capability agents (pandas,
|
| 3 |
+
# sql, ...), 3rd party plugin agents (search, weather, movie, ...),
|
| 4 |
+
# and 3rd party LLMs
|
| 5 |
+
#
|
| 6 |
+
# @philmui
|
| 7 |
+
# Mon May 1 18:34:45 PDT 2023
|
| 8 |
+
##############################################################################
|
| 9 |
+
|
| 10 |
+
from langchain.schema import HumanMessage
|
| 11 |
+
from langchain.prompts import PromptTemplate, ChatPromptTemplate, \
|
| 12 |
+
HumanMessagePromptTemplate
|
| 13 |
+
from models import load_chat_agent, load_chained_agent, load_sales_agent, \
|
| 14 |
+
load_sqlite_agent
|
| 15 |
+
|
| 16 |
+
import logging
|
| 17 |
+
|
| 18 |
+
logger = logging.getLogger(__name__)
|
| 19 |
+
|
| 20 |
+
# To parse outputs and get structured data back
|
| 21 |
+
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
|
| 22 |
+
|
| 23 |
+
instruct_template = """
|
| 24 |
+
Please answer this question clearly with easy to follow reasoning:
|
| 25 |
+
{query}
|
| 26 |
+
|
| 27 |
+
If you don't know the answer, just reply: not available.
|
| 28 |
+
"""
|
| 29 |
+
|
| 30 |
+
instruct_prompt = PromptTemplate(
|
| 31 |
+
input_variables=["query"],
|
| 32 |
+
template=instruct_template
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
response_schemas = [
|
| 36 |
+
ResponseSchema(name="artist",
|
| 37 |
+
description="The name of the musical artist"),
|
| 38 |
+
ResponseSchema(name="song",
|
| 39 |
+
description="The name of the song that the artist plays")
|
| 40 |
+
]
|
| 41 |
+
|
| 42 |
+
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
|
| 43 |
+
format_instructions = output_parser.get_format_instructions()
|
| 44 |
+
|
| 45 |
+
LOCAL_MAGIC_TOKENS = ["my company", "for us", "our company", "our sales"]
|
| 46 |
+
DIGITAL_MAGIC_TOKENS = ["digital media", "our database", "our digital"]
|
| 47 |
+
|
| 48 |
+
def is_magic(sentence, magic_tokens):
|
| 49 |
+
return any([t in sentence.lower() for t in magic_tokens])
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
chat_prompt = ChatPromptTemplate(
|
| 53 |
+
messages=[
|
| 54 |
+
HumanMessagePromptTemplate.from_template(
|
| 55 |
+
"Given a command from the user, extract the artist and \
|
| 56 |
+
song names \n{format_instructions}\n{user_prompt}")
|
| 57 |
+
],
|
| 58 |
+
input_variables=["user_prompt"],
|
| 59 |
+
partial_variables={"format_instructions": format_instructions}
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def chatAgent(chat_message):
|
| 64 |
+
try:
|
| 65 |
+
agent = load_chat_agent(verbose=True)
|
| 66 |
+
output = agent([HumanMessage(content=chat_message)])
|
| 67 |
+
except:
|
| 68 |
+
output = "Please rephrase and try chat again."
|
| 69 |
+
return output
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def instructAgent(question_text, model_name):
|
| 73 |
+
output = ""
|
| 74 |
+
|
| 75 |
+
if is_magic(question_text, LOCAL_MAGIC_TOKENS):
|
| 76 |
+
output = salesAgent(question_text)
|
| 77 |
+
print(f"🔹 salesAgent")
|
| 78 |
+
elif is_magic(question_text, DIGITAL_MAGIC_TOKENS):
|
| 79 |
+
output = chinookAgent(question_text, model_name)
|
| 80 |
+
print(f"🔹 chinookAgent")
|
| 81 |
+
else:
|
| 82 |
+
try:
|
| 83 |
+
instruction = instruct_prompt.format(query=question_text)
|
| 84 |
+
logger.info(f"instruction: {instruction}")
|
| 85 |
+
agent = load_chained_agent(verbose=True, model_name=model_name)
|
| 86 |
+
response = agent([instruction])
|
| 87 |
+
if response is None or "not available" in response["output"]:
|
| 88 |
+
response = ""
|
| 89 |
+
else:
|
| 90 |
+
output = response['output']
|
| 91 |
+
logger.info(f"🔹 Steps: {response['intermediate_steps']}")
|
| 92 |
+
except Exception as e:
|
| 93 |
+
output = "Please rephrase and try again ..."
|
| 94 |
+
print(f"\t{e}")
|
| 95 |
+
|
| 96 |
+
return output
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def salesAgent(instruction):
|
| 100 |
+
output = ""
|
| 101 |
+
try:
|
| 102 |
+
agent = load_sales_agent(verbose=True)
|
| 103 |
+
output = agent.run(instruction)
|
| 104 |
+
print("panda> " + output)
|
| 105 |
+
except:
|
| 106 |
+
output = "Please rephrase and try again for company sales data"
|
| 107 |
+
return output
|
| 108 |
+
|
| 109 |
+
def chinookAgent(instruction, model_name):
|
| 110 |
+
output = ""
|
| 111 |
+
try:
|
| 112 |
+
agent = load_sqlite_agent(model_name)
|
| 113 |
+
output = agent.run(instruction)
|
| 114 |
+
print("chinook> " + output)
|
| 115 |
+
except:
|
| 116 |
+
output = "Please rephrase and try again for digital media data"
|
| 117 |
+
return output
|
app.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
##############################################################################
|
| 2 |
+
# Main script that builds the UI & connects the logic for an LLM-driven
|
| 3 |
+
# query frontend to a "Global Commerce" demo app.
|
| 4 |
+
#
|
| 5 |
+
# @philmui
|
| 6 |
+
# Mon May 1 18:34:45 PDT 2023
|
| 7 |
+
##############################################################################
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
import streamlit as st
|
| 11 |
+
from agents import instructAgent, salesAgent, chinookAgent, chatAgent
|
| 12 |
+
|
| 13 |
+
##############################################################################
|
| 14 |
+
|
| 15 |
+
st.set_page_config(page_title="Global",
|
| 16 |
+
page_icon=":cart:",
|
| 17 |
+
layout="wide")
|
| 18 |
+
st.header("📦 Global 🛍️")
|
| 19 |
+
|
| 20 |
+
col1, col2 = st.columns([1,1])
|
| 21 |
+
|
| 22 |
+
with col1:
|
| 23 |
+
option_llm = st.selectbox(
|
| 24 |
+
"Model",
|
| 25 |
+
('text-davinci-003',
|
| 26 |
+
'text-babbage-001',
|
| 27 |
+
'text-curie-001',
|
| 28 |
+
'text-ada-001',
|
| 29 |
+
'gpt-4',
|
| 30 |
+
'gpt-3.5-turbo',
|
| 31 |
+
'google/flan-t5-xl',
|
| 32 |
+
'databricks/dolly-v2-3b',
|
| 33 |
+
'bigscience/bloom-1b7')
|
| 34 |
+
)
|
| 35 |
+
with col2:
|
| 36 |
+
option_mode = st.selectbox(
|
| 37 |
+
"LLM mode",
|
| 38 |
+
("Instruct (all)",
|
| 39 |
+
"Chat (high temperature)",
|
| 40 |
+
"Wolfram-Alpha",
|
| 41 |
+
"Internal-Sales",
|
| 42 |
+
"Internal-Merchant"
|
| 43 |
+
)
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
def get_question():
|
| 47 |
+
input_text = st.text_area(label="Your question ...",
|
| 48 |
+
placeholder="Ask me anything ...",
|
| 49 |
+
key="question_text", label_visibility="collapsed")
|
| 50 |
+
return input_text
|
| 51 |
+
|
| 52 |
+
question_text = get_question()
|
| 53 |
+
if question_text and len(question_text) > 1:
|
| 54 |
+
output=""
|
| 55 |
+
if option_mode == "Internal-Sales":
|
| 56 |
+
output = salesAgent(question_text)
|
| 57 |
+
elif option_mode == "Internal-Merchant":
|
| 58 |
+
output = chinookAgent(question_text, option_llm)
|
| 59 |
+
elif option_mode.startswith("Chat"):
|
| 60 |
+
response = chatAgent(question_text)
|
| 61 |
+
if response and response.content:
|
| 62 |
+
output = response.content
|
| 63 |
+
else:
|
| 64 |
+
output = response
|
| 65 |
+
else:
|
| 66 |
+
output = instructAgent(question_text, option_llm)
|
| 67 |
+
|
| 68 |
+
height = min(2*len(output), 280)
|
| 69 |
+
st.text_area(label="In response ...",
|
| 70 |
+
value=output, height=height)
|
| 71 |
+
|
| 72 |
+
##############################################################################
|
| 73 |
+
|
| 74 |
+
st.markdown(
|
| 75 |
+
"""
|
| 76 |
+
<style>
|
| 77 |
+
textarea[aria-label^="ex"] {
|
| 78 |
+
font-size: 0.8em !important;
|
| 79 |
+
font-family: Arial, sans-serif !important;
|
| 80 |
+
color: gray !important;
|
| 81 |
+
}
|
| 82 |
+
</style>
|
| 83 |
+
""",
|
| 84 |
+
unsafe_allow_html=True,
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
st.markdown("#### 3 types of reasoning:")
|
| 88 |
+
col1, col2, col3 = st.columns([1,1,1])
|
| 89 |
+
|
| 90 |
+
with col1:
|
| 91 |
+
st.markdown("__Common sense reasoning__")
|
| 92 |
+
st.text_area(label="ex1", label_visibility="collapsed", height=120,
|
| 93 |
+
value="🔹 Why is the sky blue?\n" +
|
| 94 |
+
"🔹 How to avoid touching a hot stove?\n" +
|
| 95 |
+
"🔹 Please give tips to win a 3200m track race?\n" +
|
| 96 |
+
"🔹 Please advise on how best to prepare for retirement?"
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
with col2:
|
| 100 |
+
st.markdown("__Local ('secure') reasoning__")
|
| 101 |
+
st.text_area(label="ex2", label_visibility="collapsed", height=120,
|
| 102 |
+
value="🔹 For my company, what is the total sales " +
|
| 103 |
+
"broken down by month?\n" +
|
| 104 |
+
"🔹 How many total artists are there in each "+
|
| 105 |
+
"genres in our digital media database?")
|
| 106 |
+
|
| 107 |
+
with col3:
|
| 108 |
+
st.markdown("__Enhanced reasoning__ [🎵](https://www.youtube.com/watch?v=hTTUaImgCyU&t=62s)")
|
| 109 |
+
st.text_area(label="ex3", label_visibility="collapsed", height=120,
|
| 110 |
+
value="🔹 Who is the president of South Korea? " +
|
| 111 |
+
"What is his favorite song? How old is he? " +
|
| 112 |
+
"What is the smallest prime greater than his age?\n" +
|
| 113 |
+
"🔹 What is the derivative of f(x)=3*log(x)*sin(x)?")
|
| 114 |
+
|
| 115 |
+
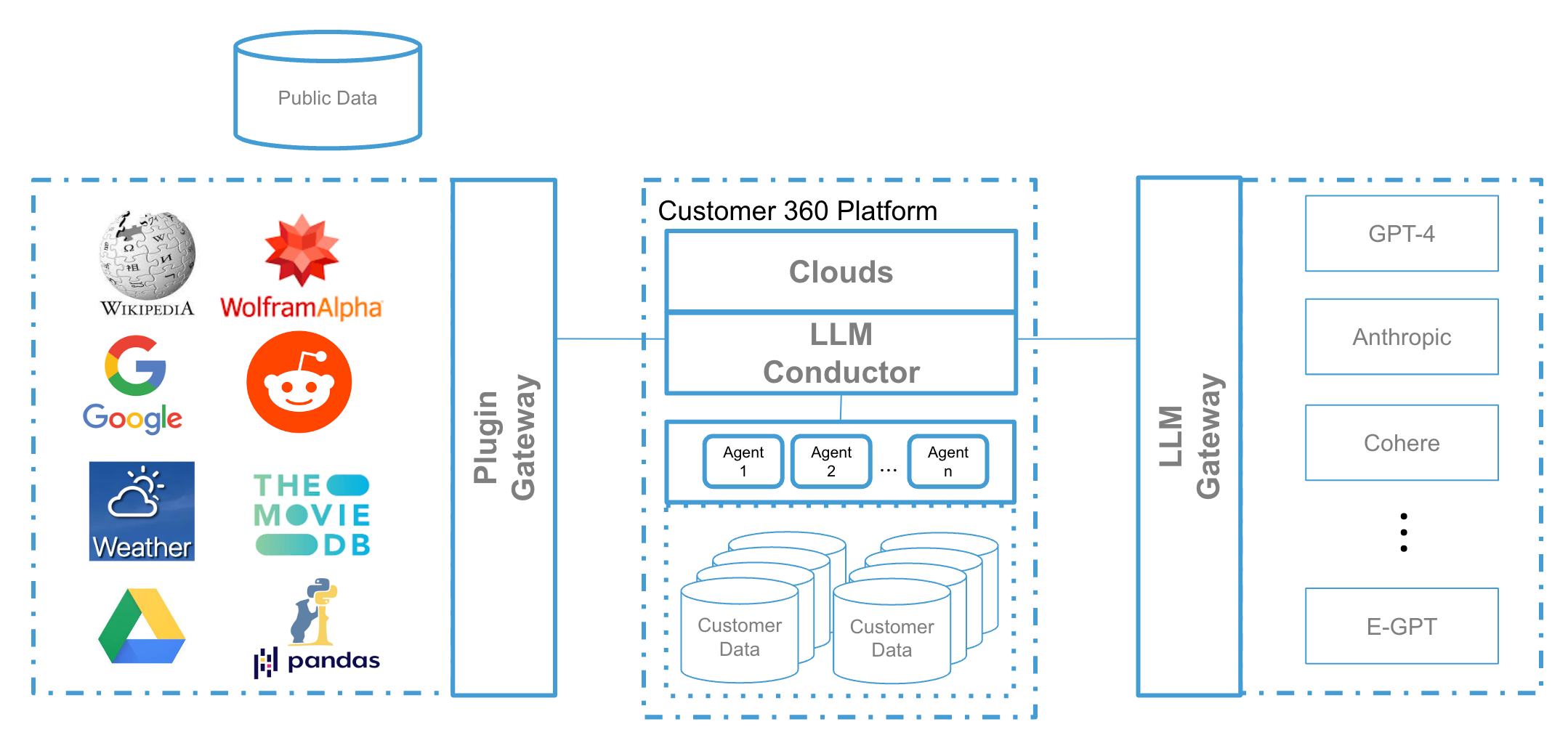
st.image(image="images/plugins.png", width=700, caption="salesforce.com")
|
| 116 |
+
st.image(image="images/chinook.png", width=420, caption="Digital Media Schema")
|
| 117 |
+
|
| 118 |
+
##############################################################################
|
data/sales_data.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
images/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
images/chinook.png
ADDED

|
images/plugins.png
ADDED
|
images/salesforce.png
ADDED

|
models.py
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
##############################################################################
|
| 2 |
+
# Utility methods for building LLMs and agent models
|
| 3 |
+
#
|
| 4 |
+
# @philmui
|
| 5 |
+
# Mon May 1 18:34:45 PDT 2023
|
| 6 |
+
##############################################################################
|
| 7 |
+
|
| 8 |
+
import os
|
| 9 |
+
import pandas as pd
|
| 10 |
+
|
| 11 |
+
from langchain.agents import AgentType, load_tools, initialize_agent,\
|
| 12 |
+
create_pandas_dataframe_agent
|
| 13 |
+
from langchain.chat_models import ChatOpenAI
|
| 14 |
+
from langchain.llms import OpenAI
|
| 15 |
+
from langchain import SQLDatabase, SQLDatabaseChain, HuggingFaceHub
|
| 16 |
+
|
| 17 |
+
OPENAI_LLMS = [
|
| 18 |
+
'text-davinci-003',
|
| 19 |
+
'text-babbage-001',
|
| 20 |
+
'text-curie-001',
|
| 21 |
+
'text-ada-001'
|
| 22 |
+
]
|
| 23 |
+
|
| 24 |
+
OPENAI_CHAT_LLMS = [
|
| 25 |
+
'gpt-3.5-turbo',
|
| 26 |
+
'gpt-4',
|
| 27 |
+
]
|
| 28 |
+
|
| 29 |
+
HUGGINGFACE_LLMS = [
|
| 30 |
+
'google/flan-t5-xl',
|
| 31 |
+
'databricks/dolly-v2-3b',
|
| 32 |
+
'bigscience/bloom-1b7'
|
| 33 |
+
]
|
| 34 |
+
|
| 35 |
+
HUGGINGFACEHUB_API_TOKEN = os.getenv("HUGGINGFACEHUB_API_TOKEN")
|
| 36 |
+
|
| 37 |
+
def createLLM(model_name="text-davinci-003", temperature=0):
|
| 38 |
+
llm = None
|
| 39 |
+
if model_name in OPENAI_LLMS:
|
| 40 |
+
llm = OpenAI(model_name=model_name, temperature=temperature)
|
| 41 |
+
elif model_name in OPENAI_CHAT_LLMS:
|
| 42 |
+
llm = ChatOpenAI(model_name=model_name, temperature=temperature)
|
| 43 |
+
elif model_name in HUGGINGFACE_LLMS:
|
| 44 |
+
llm = HuggingFaceHub(repo_id=model_name,
|
| 45 |
+
model_kwargs={"temperature":1e-10})
|
| 46 |
+
return llm
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def load_chat_agent(verbose=True):
|
| 50 |
+
return createLLM(OPENAI_CHAT_LLMS[0], temperature=0.5)
|
| 51 |
+
|
| 52 |
+
def load_sales_agent(verbose=True):
|
| 53 |
+
'''
|
| 54 |
+
Hard-coded agent that gates an internal sales CSV file for demo
|
| 55 |
+
'''
|
| 56 |
+
chat = createLLM(OPENAI_CHAT_LLMS[0], temperature=0.5)
|
| 57 |
+
df = pd.read_csv("data/sales_data.csv")
|
| 58 |
+
agent = create_pandas_dataframe_agent(chat, df, verbose=verbose)
|
| 59 |
+
return agent
|
| 60 |
+
|
| 61 |
+
def load_sqlite_agent(model_name="text-davinci-003"):
|
| 62 |
+
'''
|
| 63 |
+
Hard-coded agent that gates a sqlite DB of digital media for demo
|
| 64 |
+
'''
|
| 65 |
+
llm = createLLM(OPENAI_LLMS[0])
|
| 66 |
+
sqlite_db_path = "./data/Chinook_Sqlite.sqlite"
|
| 67 |
+
db = SQLDatabase.from_uri(f"sqlite:///{sqlite_db_path}")
|
| 68 |
+
db_chain = SQLDatabaseChain(llm=llm, database=db, verbose=True)
|
| 69 |
+
return db_chain
|
| 70 |
+
|
| 71 |
+
from langchain.tools import DuckDuckGoSearchRun, GoogleSearchRun
|
| 72 |
+
from langchain.utilities import GoogleSearchAPIWrapper
|
| 73 |
+
def load_chained_agent(verbose=True, model_name="text-davinci-003"):
|
| 74 |
+
llm = createLLM(model_name)
|
| 75 |
+
toolkit = [DuckDuckGoSearchRun()]
|
| 76 |
+
toolkit += load_tools(["serpapi", "open-meteo-api", "news-api",
|
| 77 |
+
"python_repl", "wolfram-alpha", "llm-math",
|
| 78 |
+
"pal-math", "pal-colored-objects"],
|
| 79 |
+
llm=llm,
|
| 80 |
+
serpapi_api_key=os.getenv('SERPAPI_API_KEY'),
|
| 81 |
+
news_api_key=os.getenv('NEWS_API_KEY'),
|
| 82 |
+
tmdb_bearer_token=os.getenv('TMDB_BEARER_TOKEN')
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
agent = initialize_agent(toolkit,
|
| 86 |
+
llm,
|
| 87 |
+
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
|
| 88 |
+
verbose=verbose,
|
| 89 |
+
return_intermediate_steps=True)
|
| 90 |
+
return agent
|
requirements.txt
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
charset-normalizer
|
| 2 |
+
chromadb
|
| 3 |
+
fastapi
|
| 4 |
+
duckduckgo-search
|
| 5 |
+
google-api-python-client
|
| 6 |
+
google-search-results
|
| 7 |
+
langchain
|
| 8 |
+
nltk
|
| 9 |
+
numpy
|
| 10 |
+
openai
|
| 11 |
+
pandas
|
| 12 |
+
pdfminer.six
|
| 13 |
+
streamlit
|
| 14 |
+
tabulate
|
| 15 |
+
unstructured
|
sandbox/flant5.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import matplotlib.pyplot as plt
|
| 3 |
+
from transformers import T5Tokenizer, T5ForConditionalGeneration
|
| 4 |
+
|
| 5 |
+
model_path = "/Users/pmui/models/flan-t5-xl"
|
| 6 |
+
tokenizer = T5Tokenizer.from_pretrained(model_path)
|
| 7 |
+
model = T5ForConditionalGeneration.from_pretrained(model_path, device_map="auto")
|
| 8 |
+
|
| 9 |
+
def inference(input_text):
|
| 10 |
+
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
|
| 11 |
+
outputs = model.generate(input_ids, max_length=200, bos_token_id=0)
|
| 12 |
+
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
|
| 13 |
+
print(result)
|
| 14 |
+
|
| 15 |
+
input_text = "What is the tallest building in the world?"
|
| 16 |
+
inference(input_text)
|
sandbox/google.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from googleapiclient.discovery import build
|
| 3 |
+
import pprint
|
| 4 |
+
|
| 5 |
+
my_api_key = os.getenv("GOOGLE_API_KEY")
|
| 6 |
+
my_cse_id = os.getenv("GOOGLE_CSE_ID")
|
| 7 |
+
|
| 8 |
+
def google_search(search_term, api_key, cse_id, **kwargs):
|
| 9 |
+
service = build("customsearch", "v1", developerKey=api_key)
|
| 10 |
+
res = service.cse().list(q=search_term, cx=cse_id, **kwargs).execute()
|
| 11 |
+
return res['items']
|
| 12 |
+
|
| 13 |
+
results = google_search(
|
| 14 |
+
'stackoverflow site:en.wikipedia.org', my_api_key, my_cse_id, num=10)
|
| 15 |
+
for result in results:
|
| 16 |
+
pprint.pprint(result)
|
sandbox/test.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from models import load_chained_agent
|
| 3 |
+
from agents import chatAgent
|
| 4 |
+
import langchain
|
| 5 |
+
from langchain.agents import load_tools
|
| 6 |
+
from langchain.agents import initialize_agent
|
| 7 |
+
from langchain.chat_models import ChatOpenAI
|
| 8 |
+
from langchain.llms import OpenAI
|
| 9 |
+
|
| 10 |
+
# print(chatAgent("why is the sky blue?"))
|
| 11 |
+
|
| 12 |
+
# try:
|
| 13 |
+
# prompt_formatted = prompt.format(query="""
|
| 14 |
+
# Who is the president of South Korea? What is his age? What is the digit sum of his age?
|
| 15 |
+
# """)
|
| 16 |
+
# agent = load_chained_agent(verbose=True)
|
| 17 |
+
# response = agent({"input": prompt_formatted})
|
| 18 |
+
# print(response["output"])
|
| 19 |
+
# except Exception as e:
|
| 20 |
+
# print(e)
|
| 21 |
+
|
| 22 |
+
from langchain.tools import DuckDuckGoSearchRun, GoogleSearchRun
|
| 23 |
+
from langchain.utilities import GoogleSearchAPIWrapper
|
| 24 |
+
|
| 25 |
+
def load_chained_agent(verbose=True, model_name="text-davinci-003"):
|
| 26 |
+
llm = OpenAI(model_name=model_name, temperature=0)
|
| 27 |
+
toolkit = [GoogleSearchRun(), DuckDuckGoSearchRun()]
|
| 28 |
+
|
| 29 |
+
toolkit += load_tools(["open-meteo-api", "news-api",
|
| 30 |
+
"python_repl", "wolfram-alpha",
|
| 31 |
+
"pal-math", "pal-colored-objects"],
|
| 32 |
+
llm=llm,
|
| 33 |
+
serpapi_api_key=os.getenv('SERPAPI_API_KEY'),
|
| 34 |
+
news_api_key=os.getenv('NEWS_API_KEY'),
|
| 35 |
+
tmdb_bearer_token=os.getenv('TMDB_BEARER_TOKEN')
|
| 36 |
+
)
|
| 37 |
+
agent = initialize_agent(toolkit,
|
| 38 |
+
llm,
|
| 39 |
+
agent="zero-shot-react-description",
|
| 40 |
+
verbose=verbose,
|
| 41 |
+
return_intermediate_steps=True)
|
| 42 |
+
return agent
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
PROMPT = "Who is the president of South Korea? How old is he? What is the smallest prime greater than his age?"
|
| 46 |
+
|
| 47 |
+
if __name__ == '__main__':
|
| 48 |
+
agent = load_chained_agent()
|
| 49 |
+
response = agent(PROMPT)
|
| 50 |
+
if response is not None:
|
| 51 |
+
"""
|
| 52 |
+
print("Steps: ")
|
| 53 |
+
for action in response['intermediate_steps']:
|
| 54 |
+
print()
|
| 55 |
+
print(f"==> Tool: {action[0].tool}")
|
| 56 |
+
print(f" Input: {action[0].tool_input}")
|
| 57 |
+
print(f" Thought: {action[0].log}")
|
| 58 |
+
print(f" Finding: {action[1]}")
|
| 59 |
+
"""
|
| 60 |
+
print(f"input: {response['input']}")
|
| 61 |
+
print(f"output: {response['output']}")
|