Spaces:
Running

Running
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .github/workflows/update_space.yml +28 -0
- README.MD +54 -0
- README.MD:Zone.Identifier +0 -0
- README.md +3 -9
- app.py +45 -0
- app.py:Zone.Identifier +0 -0
- flagged/Upload PDF/25c86abfddeab2eb868a/Will_smith_web_developer.pdf +0 -0
- flagged/Upload PDF/25c86abfddeab2eb868a/Will_smith_web_developer.pdf:Zone.Identifier +0 -0
- flagged/Upload PDF/f3f1fafbe5840bb7f01e/Niharika_ResumeOct.docx 2.pdf +0 -0
- flagged/Upload PDF/f3f1fafbe5840bb7f01e/Niharika_ResumeOct.docx 2.pdf:Zone.Identifier +0 -0
- flagged/log.csv +7 -0
- flagged/log.csv:Zone.Identifier +0 -0
- images/demo.png +0 -0
- images/demo.png:Zone.Identifier +0 -0
- label_encoder.pkl +3 -0
- label_encoder.pkl:Zone.Identifier +0 -0
- modules/RandomForest.py +81 -0
- modules/RandomForest.py:Zone.Identifier +0 -0
- modules/SVM.py +66 -0
- modules/SVM.py:Zone.Identifier +0 -0
- modules/__init__.py +0 -0
- modules/__init__.py:Zone.Identifier +0 -0
- modules/__pycache__/RandomForest.cpython-38.pyc +0 -0
- modules/__pycache__/RandomForest.cpython-38.pyc:Zone.Identifier +0 -0
- modules/__pycache__/RandomForest_Multi.cpython-38.pyc +0 -0
- modules/__pycache__/RandomForest_Multi.cpython-38.pyc:Zone.Identifier +0 -0
- modules/__pycache__/SVM.cpython-38.pyc +0 -0
- modules/__pycache__/SVM.cpython-38.pyc:Zone.Identifier +0 -0
- modules/__pycache__/__init__.cpython-38.pyc +0 -0
- modules/__pycache__/__init__.cpython-38.pyc:Zone.Identifier +0 -0
- modules/__pycache__/classify.cpython-38.pyc +0 -0
- modules/__pycache__/classify.cpython-38.pyc:Zone.Identifier +0 -0
- modules/__pycache__/classify_text.cpython-38.pyc +0 -0
- modules/__pycache__/classify_text.cpython-38.pyc:Zone.Identifier +0 -0
- modules/__pycache__/parse_pdf.cpython-38.pyc +0 -0
- modules/__pycache__/parse_pdf.cpython-38.pyc:Zone.Identifier +0 -0
- modules/classify.py +44 -0
- modules/classify.py:Zone.Identifier +0 -0
- modules/classify_text.py +17 -0
- modules/classify_text.py:Zone.Identifier +0 -0
- modules/install_stop_words.py +5 -0
- modules/install_stop_words.py:Zone.Identifier +0 -0
- modules/parse_pdf.py +61 -0
- modules/parse_pdf.py:Zone.Identifier +0 -0
- random_forest_model.pkl +3 -0
- random_forest_model.pkl:Zone.Identifier +0 -0
- random_forest_multi_model.pkl +3 -0
- random_forest_multi_model.pkl:Zone.Identifier +0 -0
- requirements.txt +11 -0
- requirements.txt:Zone.Identifier +0 -0
.github/workflows/update_space.yml
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Run Python script
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
push:
|
| 5 |
+
branches:
|
| 6 |
+
- i
|
| 7 |
+
|
| 8 |
+
jobs:
|
| 9 |
+
build:
|
| 10 |
+
runs-on: ubuntu-latest
|
| 11 |
+
|
| 12 |
+
steps:
|
| 13 |
+
- name: Checkout
|
| 14 |
+
uses: actions/checkout@v2
|
| 15 |
+
|
| 16 |
+
- name: Set up Python
|
| 17 |
+
uses: actions/setup-python@v2
|
| 18 |
+
with:
|
| 19 |
+
python-version: '3.9'
|
| 20 |
+
|
| 21 |
+
- name: Install Gradio
|
| 22 |
+
run: python -m pip install gradio
|
| 23 |
+
|
| 24 |
+
- name: Log in to Hugging Face
|
| 25 |
+
run: python -c 'import huggingface_hub; huggingface_hub.login(token="${{ secrets.hf_token }}")'
|
| 26 |
+
|
| 27 |
+
- name: Deploy to Spaces
|
| 28 |
+
run: gradio deploy
|
README.MD
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Web browser using python
|
| 2 |
+
|
| 3 |
+
## Description
|
| 4 |
+
|
| 5 |
+
Demo app for Resume classification
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
## Usage
|
| 9 |
+
|
| 10 |
+
### Step 1: Create a Virtual Python Environment
|
| 11 |
+
|
| 12 |
+
First, create a new virtual environment to ensure all dependencies are isolated from your main Python installation.
|
| 13 |
+
|
| 14 |
+
```bash
|
| 15 |
+
conda create -n resume-atlas python=3.8
|
| 16 |
+
```
|
| 17 |
+
|
| 18 |
+
### Step 2: Activate the Environment
|
| 19 |
+
|
| 20 |
+
```bash
|
| 21 |
+
conda activate resume-atlas
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
### Step 3: Install the Requirements
|
| 25 |
+
|
| 26 |
+
```bash
|
| 27 |
+
pip install -r requirements.txt
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
### step 4: install nltk package
|
| 31 |
+
```bash
|
| 32 |
+
python modules/install_stop_words.py
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
### step 5: Run the app
|
| 36 |
+
```bash
|
| 37 |
+
python app.py
|
| 38 |
+
```
|
| 39 |
+
copy the following URL to your browser
|
| 40 |
+
```bash
|
| 41 |
+
http://127.0.0.1:7860
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
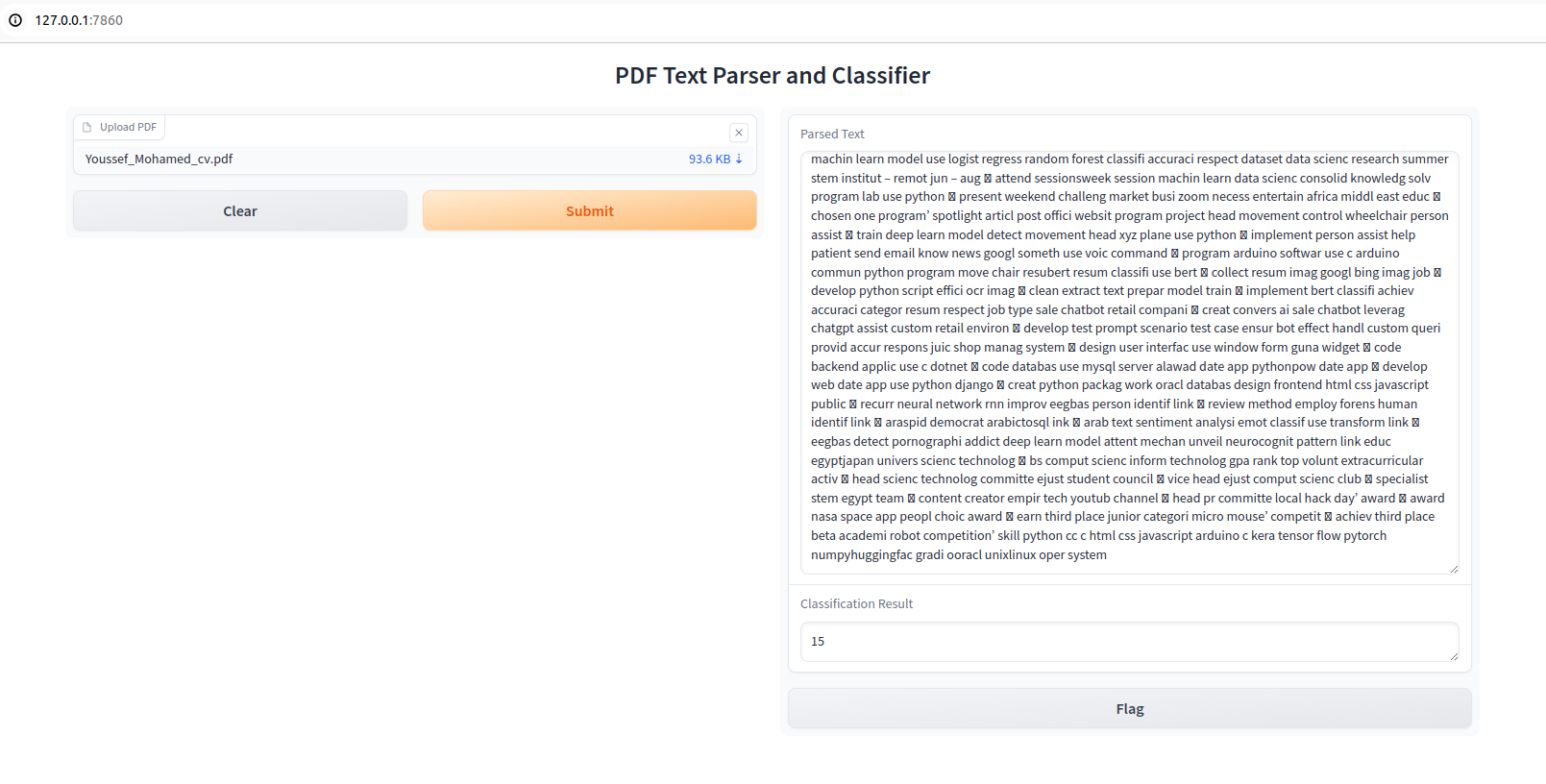
### DEMO
|
| 45 |
+

|
| 46 |
+
|
| 47 |
+
### Notes:
|
| 48 |
+
|
| 49 |
+
- if their is any problem in torch installation please use the following [website](https://pytorch.org/get-started/locally/) for installation
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
## Contribution
|
| 54 |
+
Contributions are welcome! If you find any issues or have suggestions for improvement, please create an issue or submit a pull request on the project's GitHub repository.# Intelligent-Resume-Classification-and-Job-Matching-System
|
README.MD:Zone.Identifier
ADDED
|
File without changes
|
README.md
CHANGED
|
@@ -1,12 +1,6 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji: 📊
|
| 4 |
-
colorFrom: red
|
| 5 |
-
colorTo: green
|
| 6 |
-
sdk: gradio
|
| 7 |
-
sdk_version: 5.4.0
|
| 8 |
app_file: app.py
|
| 9 |
-
|
|
|
|
| 10 |
---
|
| 11 |
-
|
| 12 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: classify
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
app_file: app.py
|
| 4 |
+
sdk: gradio
|
| 5 |
+
sdk_version: 3.35.2
|
| 6 |
---
|
|
|
|
|
|
app.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
from modules.parse_pdf import process_pdf
|
| 3 |
+
from modules.classify import classify_text_multi # Importing BERT model classification
|
| 4 |
+
from modules.RandomForest import classify_text_rf,classify_text_rf_multi #Importing single and multi-label classification
|
| 5 |
+
from modules.SVM import classify_text_svm,classify_text_svm_multi #Importing single and multi-label classification
|
| 6 |
+
|
| 7 |
+
# Function to process and classify PDF using both BERT and Random Forest models
|
| 8 |
+
def process_and_classify_pdf(file):
|
| 9 |
+
# Step 1: Process the PDF to extract and clean the text
|
| 10 |
+
parsed_text = process_pdf(file)
|
| 11 |
+
|
| 12 |
+
# Step 2: Classify using the existing BERT model
|
| 13 |
+
classification_bert = classify_text_multi(parsed_text) # Assuming this is multi-label BERT model
|
| 14 |
+
|
| 15 |
+
# Step 3: Classify using Random Forest single-label and multi-label
|
| 16 |
+
classification_rf_single = classify_text_rf(parsed_text)
|
| 17 |
+
classification_rf_multi = classify_text_rf_multi(parsed_text)
|
| 18 |
+
classification_svm_single=classify_text_svm(parsed_text)
|
| 19 |
+
classification_svm_multi=classify_text_svm_multi(parsed_text)
|
| 20 |
+
|
| 21 |
+
# Combine the results
|
| 22 |
+
combined_result = (
|
| 23 |
+
f"BERT Classification: {', '.join(classification_bert)}\n"
|
| 24 |
+
f"Random Forest (Single-label): {classification_rf_single}\n"
|
| 25 |
+
f"Random Forest (Multi-label): {', '.join(classification_rf_multi)}\n"
|
| 26 |
+
f"SVM (Single-label):{classification_svm_single}\n"
|
| 27 |
+
f"SVM (multi-label):{', '.join(classification_svm_multi)}"
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
# Step 4: Return parsed text and combined classification results
|
| 31 |
+
return parsed_text, combined_result
|
| 32 |
+
|
| 33 |
+
# Define Gradio interface
|
| 34 |
+
input_file = gr.File(label="Upload PDF")
|
| 35 |
+
output_text = gr.Textbox(label="Parsed Text")
|
| 36 |
+
output_class = gr.Textbox(label="Job Title Predictions")
|
| 37 |
+
|
| 38 |
+
# Launch Gradio interface
|
| 39 |
+
gr.Interface(
|
| 40 |
+
fn=process_and_classify_pdf,
|
| 41 |
+
inputs=input_file,
|
| 42 |
+
outputs=[output_text, output_class],
|
| 43 |
+
title="Resume Classification and Parsing for Intelligent Applicant Screening",
|
| 44 |
+
theme=gr.themes.Soft()
|
| 45 |
+
).launch(share=True)
|
app.py:Zone.Identifier
ADDED
|
File without changes
|
flagged/Upload PDF/25c86abfddeab2eb868a/Will_smith_web_developer.pdf
ADDED
|
Binary file (71 kB). View file
|
|
|
flagged/Upload PDF/25c86abfddeab2eb868a/Will_smith_web_developer.pdf:Zone.Identifier
ADDED
|
File without changes
|
flagged/Upload PDF/f3f1fafbe5840bb7f01e/Niharika_ResumeOct.docx 2.pdf
ADDED
|
Binary file (146 kB). View file
|
|
|
flagged/Upload PDF/f3f1fafbe5840bb7f01e/Niharika_ResumeOct.docx 2.pdf:Zone.Identifier
ADDED
|
File without changes
|
flagged/log.csv
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Upload PDF,Parsed Text,Job Title Predictions,flag,username,timestamp
|
| 2 |
+
flagged\Upload PDF\25c86abfddeab2eb868a\Will_smith_web_developer.pdf,name smith address react street techville codetown cl phone email willsmithemailcom linkedin linkedincominwillsmith objective dynamic resultsdriven web developer focus frontend development using reactjs dedicated creating interactive engaging user interface seeking opportunity leverage expertise react related technology contribute innovative web project professional experience frontend web developer reactjs tech solution plus techville codetown march present developed responsive interactive web application using reactjs redux frontend technology collaborated uiux designer translate design concept functional react component implemented state management data flow pattern using redux complex web application conducted code review provided feedback ensure adherence best practice coding standard integrated thirdparty apis library enhance functionality feature web application optimized web application performance user experience efficient react component rendering junior web developer codecrafters inc code city techland july february assisted development frontend component feature web application using html cs javascript supported implementation responsive design principle technique ensure cross device compatibility participated agile development sprint contributed planning execution project task conducted testing debugging identify resolve issue web application functionality performance maintained code repository documentation ongoing project codebase management education bachelor science computer science tech university tech city techland graduated may skill proficient reactjs redux html cs javascript experience frontend build tool webpack babel familiarity uiux design principle responsive web design technique strong problemsolving analytical ability excellent communication collaboration skill certification reactjs developer certification udemy redux fundamental certification pluralsight,"BERT Classification: React Developer
|
| 3 |
+
Random Forest (Single-label): Web Designing
|
| 4 |
+
Random Forest (Multi-label): Web Designing, Java Developer, React Developer",,,2024-10-17 16:30:57.077916
|
| 5 |
+
flagged\Upload PDF\f3f1fafbe5840bb7f01e\Niharika_ResumeOct.docx 2.pdf,anumola niharika varma niharikaanumolagmailcom linkedincominanumolaniharikavarmaa finalyear student specializing artificial intelligence machine learning university college engineering osmania university passionate applying aiml technique solve realworld problem handson experience building predictive model natural language processing eager contribute skill innovative project continue expanding expertise aiml research development technical skill programming language pythoncjavasql speciality exploratory data analysisedadata structure algorithmsdsadata miningdatabase management systemsdbmscomputer networksmachine learningnatural language processing library tool pandasmatplotlib seabornscikitlearnnumpyqiskitgit version control web development htmlcssreactjs project intelligent resume classification job matching system developed machine learning model using random forest bert intelligent classification resume based job category implemented multilabel classification system using random forest provide topn job recommendation parsed resume text built gradiobased user interface uploading pdfs parsing resume displaying classified job title parsed resume contentmanaged training evaluation model dataset resume text summarization github demonstrated text summarization using textranktfidflsatpegasusbertbased model evaluated text summarization model including pegasus leveraged machine learning technique analysis demonstrated pegasus delivers superior accuracy coherence summary compared traditional method summarization like tfidftextrank parallelizing sequential cryptography algorithm github implemented rsaaes algorithm cpugpu shors algorithm quantum backend using ibm quantum platform explored rsa aes encryption classical hardware shor’s algorithm break rsa quantum computer demonstrated traditional cryptographic algorithm like rsa vulnerable quantum algorithm emphasizing need quantumresistant encryption additional activity member robotics automation societyras ieee member gdscgoogle developer student club volunteered gamglobal alumnus meetof osmania university successfully organized technical event techtriaithlon infinity knational level technical symposium university college engineeringoucse department education university college engineeringosmania universityhyderabad – bachelor engineering artificial intelligence machine learning cgpa krishnamurthy junior collegevidyanagarhyderabad – intermediate score,"BERT Classification: Data Science, ETL Developer, Python Developer, React Developer
|
| 6 |
+
Random Forest (Single-label): Data Science
|
| 7 |
+
Random Forest (Multi-label): Data Science, Advocate, Information Technology",,,2024-10-23 10:59:34.952562
|
flagged/log.csv:Zone.Identifier
ADDED
|
File without changes
|
images/demo.png
ADDED
|
images/demo.png:Zone.Identifier
ADDED
|
File without changes
|
label_encoder.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1bc4c7cb8492f33077bd8ba17d5b38c61731bf5d7ddf3b941b6e0ffa2d369669
|
| 3 |
+
size 1343
|
label_encoder.pkl:Zone.Identifier
ADDED
|
File without changes
|
modules/RandomForest.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
from sklearn.feature_extraction.text import TfidfVectorizer
|
| 3 |
+
from sklearn.model_selection import train_test_split
|
| 4 |
+
from sklearn.ensemble import RandomForestClassifier
|
| 5 |
+
from sklearn.preprocessing import LabelEncoder
|
| 6 |
+
from datasets import load_dataset
|
| 7 |
+
import joblib
|
| 8 |
+
import os
|
| 9 |
+
import numpy as np
|
| 10 |
+
|
| 11 |
+
# Define paths for the Random Forest model, TF-IDF vectorizer, and label encoder
|
| 12 |
+
rf_model_path = 'random_forest_model.pkl'
|
| 13 |
+
vectorizer_path = "tfidf_vectorizer.pkl"
|
| 14 |
+
label_encoder_path = "label_encoder.pkl"
|
| 15 |
+
multi_rf_model_path= "random_forest_multi_model.pkl"
|
| 16 |
+
|
| 17 |
+
# Check if models and encoder exist
|
| 18 |
+
if os.path.exists(rf_model_path) and os.path.exists(vectorizer_path) and os.path.exists(label_encoder_path) and os.path.exists(multi_rf_model_path):
|
| 19 |
+
# Load the models if they already exist
|
| 20 |
+
rf_single = joblib.load(rf_model_path)
|
| 21 |
+
vectorizer = joblib.load(vectorizer_path)
|
| 22 |
+
le = joblib.load(label_encoder_path)
|
| 23 |
+
rf_multi = joblib.load(multi_rf_model_path)
|
| 24 |
+
print("Random Forest model, vectorizer, and label encoder loaded from disk.")
|
| 25 |
+
else:
|
| 26 |
+
# Load the dataset
|
| 27 |
+
ds = load_dataset('ahmedheakl/resume-atlas', cache_dir="C:/Users/dell/.cache/huggingface/datasets")
|
| 28 |
+
|
| 29 |
+
# Create a DataFrame from the 'train' split
|
| 30 |
+
df_train = pd.DataFrame(ds['train'])
|
| 31 |
+
|
| 32 |
+
# Initialize the Label Encoder and encode the 'Category' labels
|
| 33 |
+
le = LabelEncoder()
|
| 34 |
+
df_train['Category_encoded'] = le.fit_transform(df_train['Category'])
|
| 35 |
+
|
| 36 |
+
# Split the dataset into training and test sets
|
| 37 |
+
X_train, X_test, y_train, y_test = train_test_split(
|
| 38 |
+
df_train['Text'], df_train['Category_encoded'], test_size=0.2, random_state=42)
|
| 39 |
+
|
| 40 |
+
# Initialize TF-IDF Vectorizer and transform the text data
|
| 41 |
+
vectorizer = TfidfVectorizer(max_features=1000)
|
| 42 |
+
X_train_tfidf = vectorizer.fit_transform(X_train)
|
| 43 |
+
X_test_tfidf = vectorizer.transform(X_test)
|
| 44 |
+
|
| 45 |
+
# Initialize and train the Random Forest models
|
| 46 |
+
rf_single = RandomForestClassifier(n_estimators=100, random_state=42)
|
| 47 |
+
rf_single.fit(X_train_tfidf, y_train)
|
| 48 |
+
|
| 49 |
+
rf_multi = RandomForestClassifier(n_estimators=100, random_state=42)
|
| 50 |
+
rf_multi.fit(X_train_tfidf, y_train)
|
| 51 |
+
|
| 52 |
+
# Save the Random Forest models, TF-IDF vectorizer, and label encoder
|
| 53 |
+
joblib.dump(rf_single, rf_model_path)
|
| 54 |
+
joblib.dump(rf_multi, multi_rf_model_path)
|
| 55 |
+
joblib.dump(vectorizer, vectorizer_path)
|
| 56 |
+
joblib.dump(le, label_encoder_path)
|
| 57 |
+
print("Random Forest model, vectorizer, and label encoder trained and saved to disk.")
|
| 58 |
+
|
| 59 |
+
# Single-label classification function for Random Forest model
|
| 60 |
+
def classify_text_rf(text):
|
| 61 |
+
try:
|
| 62 |
+
text_tfidf = vectorizer.transform([text])
|
| 63 |
+
predicted_class_index = rf_single.predict(text_tfidf)[0]
|
| 64 |
+
predicted_category = le.inverse_transform([predicted_class_index])[0]
|
| 65 |
+
return predicted_category
|
| 66 |
+
except Exception as e:
|
| 67 |
+
print(f"Error in classify_text_rf: {e}")
|
| 68 |
+
return None
|
| 69 |
+
|
| 70 |
+
# Multi-label classification function with top N predictions
|
| 71 |
+
def classify_text_rf_multi(text, top_n=3):
|
| 72 |
+
try:
|
| 73 |
+
text_tfidf = vectorizer.transform([text])
|
| 74 |
+
probabilities = rf_multi.predict_proba(text_tfidf)[0]
|
| 75 |
+
top_n_indices = np.argsort(probabilities)[::-1][:min(top_n, len(probabilities))]
|
| 76 |
+
top_n_categories = le.inverse_transform(top_n_indices)
|
| 77 |
+
return top_n_categories
|
| 78 |
+
except Exception as e:
|
| 79 |
+
print(f"Error in classify_text_rf_multi: {e}")
|
| 80 |
+
return None
|
| 81 |
+
|
modules/RandomForest.py:Zone.Identifier
ADDED
|
File without changes
|
modules/SVM.py
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
from sklearn.feature_extraction.text import TfidfVectorizer
|
| 3 |
+
from sklearn.model_selection import train_test_split
|
| 4 |
+
from sklearn.svm import SVC
|
| 5 |
+
from sklearn.preprocessing import LabelEncoder
|
| 6 |
+
import numpy as np
|
| 7 |
+
from datasets import load_dataset
|
| 8 |
+
import joblib
|
| 9 |
+
import os
|
| 10 |
+
|
| 11 |
+
# Define paths for the model, vectorizer, and label encoder
|
| 12 |
+
svm_model_path = "svm_resume_model.pkl"
|
| 13 |
+
vectorizer_path = "tfidf_vectorizer.pkl"
|
| 14 |
+
label_encoder_path = "label_encoder.pkl"
|
| 15 |
+
|
| 16 |
+
# Check if models exist and load them; otherwise, train and save
|
| 17 |
+
if os.path.exists(svm_model_path) and os.path.exists(vectorizer_path) and os.path.exists(label_encoder_path):
|
| 18 |
+
# Load the models if they already exist
|
| 19 |
+
svm_model = joblib.load(svm_model_path)
|
| 20 |
+
vectorizer = joblib.load(vectorizer_path)
|
| 21 |
+
le = joblib.load(label_encoder_path)
|
| 22 |
+
print("Models loaded from disk.")
|
| 23 |
+
else:
|
| 24 |
+
# Load the dataset
|
| 25 |
+
ds = load_dataset('ahmedheakl/resume-atlas', cache_dir="C:/Users/dell/.cache/huggingface/datasets")
|
| 26 |
+
|
| 27 |
+
# Create a DataFrame from the 'train' split
|
| 28 |
+
df_train = pd.DataFrame(ds['train'])
|
| 29 |
+
|
| 30 |
+
# Initialize the Label Encoder and encode the 'Category' labels
|
| 31 |
+
le = LabelEncoder()
|
| 32 |
+
df_train['Category_encoded'] = le.fit_transform(df_train['Category'])
|
| 33 |
+
|
| 34 |
+
# Split the dataset into training and test sets
|
| 35 |
+
X_train, X_test, y_train, y_test = train_test_split(
|
| 36 |
+
df_train['Text'], df_train['Category_encoded'], test_size=0.2, random_state=42)
|
| 37 |
+
|
| 38 |
+
# Initialize TF-IDF Vectorizer and transform the text data
|
| 39 |
+
vectorizer = TfidfVectorizer(max_features=1000)
|
| 40 |
+
X_train_tfidf = vectorizer.fit_transform(X_train)
|
| 41 |
+
X_test_tfidf = vectorizer.transform(X_test)
|
| 42 |
+
|
| 43 |
+
# Initialize and train the SVM model
|
| 44 |
+
svm_model = SVC(probability=True, random_state=42)
|
| 45 |
+
svm_model.fit(X_train_tfidf, y_train)
|
| 46 |
+
|
| 47 |
+
# Save the SVM model, TF-IDF vectorizer, and label encoder
|
| 48 |
+
joblib.dump(svm_model, svm_model_path)
|
| 49 |
+
joblib.dump(vectorizer, vectorizer_path)
|
| 50 |
+
joblib.dump(le, label_encoder_path)
|
| 51 |
+
print("Models trained and saved to disk.")
|
| 52 |
+
|
| 53 |
+
# Single-label classification function
|
| 54 |
+
def classify_text_svm(text):
|
| 55 |
+
text_tfidf = vectorizer.transform([text])
|
| 56 |
+
predicted_class_index = svm_model.predict(text_tfidf)[0]
|
| 57 |
+
predicted_category = le.inverse_transform([predicted_class_index])[0]
|
| 58 |
+
return predicted_category
|
| 59 |
+
|
| 60 |
+
# Multi-label classification function (returning top N predictions based on probabilities)
|
| 61 |
+
def classify_text_svm_multi(text, top_n=3):
|
| 62 |
+
text_tfidf = vectorizer.transform([text])
|
| 63 |
+
probabilities = svm_model.predict_proba(text_tfidf)[0]
|
| 64 |
+
top_n_indices = np.argsort(probabilities)[::-1][:top_n] # Get indices of top N predictions
|
| 65 |
+
top_n_categories = le.inverse_transform(top_n_indices)
|
| 66 |
+
return top_n_categories
|
modules/SVM.py:Zone.Identifier
ADDED
|
File without changes
|
modules/__init__.py
ADDED
|
File without changes
|
modules/__init__.py:Zone.Identifier
ADDED
|
File without changes
|
modules/__pycache__/RandomForest.cpython-38.pyc
ADDED
|
Binary file (2.47 kB). View file
|
|
|
modules/__pycache__/RandomForest.cpython-38.pyc:Zone.Identifier
ADDED
|
File without changes
|
modules/__pycache__/RandomForest_Multi.cpython-38.pyc
ADDED
|
Binary file (1.56 kB). View file
|
|
|
modules/__pycache__/RandomForest_Multi.cpython-38.pyc:Zone.Identifier
ADDED
|
File without changes
|
modules/__pycache__/SVM.cpython-38.pyc
ADDED
|
Binary file (1.95 kB). View file
|
|
|
modules/__pycache__/SVM.cpython-38.pyc:Zone.Identifier
ADDED
|
File without changes
|
modules/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (127 Bytes). View file
|
|
|
modules/__pycache__/__init__.cpython-38.pyc:Zone.Identifier
ADDED
|
File without changes
|
modules/__pycache__/classify.cpython-38.pyc
ADDED
|
Binary file (1.65 kB). View file
|
|
|
modules/__pycache__/classify.cpython-38.pyc:Zone.Identifier
ADDED
|
File without changes
|
modules/__pycache__/classify_text.cpython-38.pyc
ADDED
|
Binary file (771 Bytes). View file
|
|
|
modules/__pycache__/classify_text.cpython-38.pyc:Zone.Identifier
ADDED
|
File without changes
|
modules/__pycache__/parse_pdf.cpython-38.pyc
ADDED
|
Binary file (1.69 kB). View file
|
|
|
modules/__pycache__/parse_pdf.cpython-38.pyc:Zone.Identifier
ADDED
|
File without changes
|
modules/classify.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
| 2 |
+
import torch
|
| 3 |
+
import numpy as np
|
| 4 |
+
from sklearn import preprocessing
|
| 5 |
+
|
| 6 |
+
# Load the Hugging Face model and tokenizer
|
| 7 |
+
model_name = "ahmedheakl/bert-resume-classification"
|
| 8 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 9 |
+
model = AutoModelForSequenceClassification.from_pretrained(model_name)
|
| 10 |
+
|
| 11 |
+
# Load the dataset and prepare the label encoder
|
| 12 |
+
dataset_id = 'ahmedheakl/resume-atlas'
|
| 13 |
+
from datasets import load_dataset
|
| 14 |
+
|
| 15 |
+
# Load the dataset
|
| 16 |
+
ds = load_dataset(dataset_id, trust_remote_code=True)
|
| 17 |
+
label_column = "Category"
|
| 18 |
+
|
| 19 |
+
# Initialize Label Encoder and fit it to the categories in the dataset
|
| 20 |
+
le = preprocessing.LabelEncoder()
|
| 21 |
+
le.fit(ds['train'][label_column])
|
| 22 |
+
|
| 23 |
+
def classify_text(text):
|
| 24 |
+
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
|
| 25 |
+
outputs = model(**inputs)
|
| 26 |
+
probabilities = torch.nn.functional.softmax(outputs.logits, dim=-1)
|
| 27 |
+
predicted_class_index = torch.argmax(probabilities).item()
|
| 28 |
+
|
| 29 |
+
# Convert predicted class index to category name
|
| 30 |
+
predicted_category = le.inverse_transform([predicted_class_index])[0]
|
| 31 |
+
return predicted_category
|
| 32 |
+
|
| 33 |
+
#multiclass-classification
|
| 34 |
+
def classify_text_multi(text, threshold=0.95):
|
| 35 |
+
inputs = tokenizer(text, return_tensors="pt",
|
| 36 |
+
truncation=True, padding=True)
|
| 37 |
+
outputs = model(**inputs)
|
| 38 |
+
probabilities = torch.nn.functional.sigmoid(outputs.logits)
|
| 39 |
+
predicted_classes = (probabilities > threshold).int().tolist()[0]
|
| 40 |
+
job_titles = [le.inverse_transform([idx])[0] for idx, val in enumerate(predicted_classes) if val == 1]
|
| 41 |
+
|
| 42 |
+
if not job_titles:
|
| 43 |
+
return ["Uncertain Prediction"]
|
| 44 |
+
return job_titles
|
modules/classify.py:Zone.Identifier
ADDED
|
File without changes
|
modules/classify_text.py
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
# Load the Hugging Face model and tokenizer
|
| 5 |
+
model_name = "ahmedheakl/bert-resume-classification"
|
| 6 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 7 |
+
model = AutoModelForSequenceClassification.from_pretrained(model_name)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def classify_text(text):
|
| 11 |
+
inputs = tokenizer(text, return_tensors="pt",
|
| 12 |
+
truncation=True, padding=True)
|
| 13 |
+
outputs = model(**inputs)
|
| 14 |
+
probabilities = torch.nn.functional.softmax(outputs.logits, dim=-1)
|
| 15 |
+
predicted_class = torch.argmax(probabilities).item()
|
| 16 |
+
return predicted_class
|
| 17 |
+
|
modules/classify_text.py:Zone.Identifier
ADDED
|
File without changes
|
modules/install_stop_words.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import nltk
|
| 2 |
+
|
| 3 |
+
# Download NLTK stopwords and wordnet for lemmatization
|
| 4 |
+
nltk.download('stopwords')
|
| 5 |
+
nltk.download('wordnet')
|
modules/install_stop_words.py:Zone.Identifier
ADDED
|
File without changes
|
modules/parse_pdf.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain_community.document_loaders import PyMuPDFLoader
|
| 2 |
+
from nltk.corpus import stopwords
|
| 3 |
+
from nltk.stem import PorterStemmer
|
| 4 |
+
from nltk.stem import WordNetLemmatizer
|
| 5 |
+
import re
|
| 6 |
+
import string
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def load_pdf(file_path):
|
| 10 |
+
loader = PyMuPDFLoader(file_path)
|
| 11 |
+
data = loader.load()
|
| 12 |
+
return data
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def clean_text(text):
|
| 16 |
+
# Remove special characters (customize as needed)
|
| 17 |
+
special_characters = "○●•◦"
|
| 18 |
+
text = re.sub(f"[{re.escape(special_characters)}]", "", text)
|
| 19 |
+
|
| 20 |
+
# Remove punctuation
|
| 21 |
+
text = text.translate(str.maketrans("", "", string.punctuation))
|
| 22 |
+
|
| 23 |
+
# Remove numbers
|
| 24 |
+
text = re.sub(r'\d+', '', text)
|
| 25 |
+
|
| 26 |
+
# Remove extra whitespace
|
| 27 |
+
text = " ".join(text.split())
|
| 28 |
+
|
| 29 |
+
# Convert text to lowercase
|
| 30 |
+
text = text.lower()
|
| 31 |
+
|
| 32 |
+
# Remove stopwords (optional)
|
| 33 |
+
stop_words = set(stopwords.words('english'))
|
| 34 |
+
text = " ".join(word for word in text.split() if word not in stop_words)
|
| 35 |
+
|
| 36 |
+
# Stemming (optional)
|
| 37 |
+
#ps = PorterStemmer()
|
| 38 |
+
#text = " ".join(ps.stem(word) for word in text.split())
|
| 39 |
+
|
| 40 |
+
#Lemmatization
|
| 41 |
+
lemmatizer = WordNetLemmatizer()
|
| 42 |
+
text= " ".join(lemmatizer.lemmatize(word) for word in text.split())
|
| 43 |
+
|
| 44 |
+
return text
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def get_full_resume_text(file_path):
|
| 48 |
+
resume_pages = load_pdf(file_path)
|
| 49 |
+
resume_text = ""
|
| 50 |
+
|
| 51 |
+
for page in resume_pages:
|
| 52 |
+
resume_text += page.page_content
|
| 53 |
+
resume_text += "\n\n"
|
| 54 |
+
|
| 55 |
+
resume_text = clean_text(resume_text)
|
| 56 |
+
|
| 57 |
+
return resume_text
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def process_pdf(file):
|
| 61 |
+
return get_full_resume_text(file.name)
|
modules/parse_pdf.py:Zone.Identifier
ADDED
|
File without changes
|
random_forest_model.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2150e6cfaf1f7b7fcb65ae956f1b59c7c4c5c6c3024adbd56f79024632c3d29c
|
| 3 |
+
size 212428577
|
random_forest_model.pkl:Zone.Identifier
ADDED
|
File without changes
|
random_forest_multi_model.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2150e6cfaf1f7b7fcb65ae956f1b59c7c4c5c6c3024adbd56f79024632c3d29c
|
| 3 |
+
size 212428577
|
random_forest_multi_model.pkl:Zone.Identifier
ADDED
|
File without changes
|
requirements.txt
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio==4.37.2
|
| 2 |
+
pypdf==4.2.0
|
| 3 |
+
langchain==0.2.3
|
| 4 |
+
langchain-community==0.2.4
|
| 5 |
+
langchain-core==0.2.5
|
| 6 |
+
nltk==3.8.1
|
| 7 |
+
PyMuPDF==1.24.5
|
| 8 |
+
transformers==4.42.3
|
| 9 |
+
torch==2.3.1
|
| 10 |
+
torchvision==0.18.1
|
| 11 |
+
torchaudio==2.3.1
|
requirements.txt:Zone.Identifier
ADDED
|
File without changes
|