Spaces:
Running
on
L40S

Running
on
L40S
Migrated from GitHub
Browse files- ORIGINAL_README.md +215 -0
- assert/lq/lq1.mp4 +0 -0
- assert/lq/lq2.mp4 +0 -0
- assert/lq/lq3.mp4 +0 -0
- assert/mask/lq3.png +0 -0
- assert/method.png +0 -0
- config/infer.yaml +21 -0
- infer.py +305 -0
- requirements.txt +10 -0
- src/dataset/dataset.py +50 -0
- src/dataset/face_align/align.py +36 -0
- src/dataset/face_align/yoloface.py +310 -0
- src/models/id_proj.py +20 -0
- src/models/model_insightface_360k.py +203 -0
- src/models/svfr_adapter/attention_processor.py +616 -0
- src/models/svfr_adapter/unet_3d_blocks.py +0 -0
- src/models/svfr_adapter/unet_3d_svd_condition_ip.py +536 -0
- src/pipelines/pipeline.py +812 -0
- src/utils/noise_util.py +25 -0
- src/utils/util.py +64 -0
ORIGINAL_README.md
ADDED
|
@@ -0,0 +1,215 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!-- # SVFR: A Unified Framework for Generalized Video Face Restoration -->
|
| 2 |
+
|
| 3 |
+
<div>
|
| 4 |
+
<h1>SVFR: A Unified Framework for Generalized Video Face Restoration</h1>
|
| 5 |
+
</div>
|
| 6 |
+
|
| 7 |
+
[](https://arxiv.org/pdf/2501.01235)
|
| 8 |
+
[](https://wangzhiyaoo.github.io/SVFR/)
|
| 9 |
+
|
| 10 |
+
## 🔥 Overview
|
| 11 |
+
|
| 12 |
+
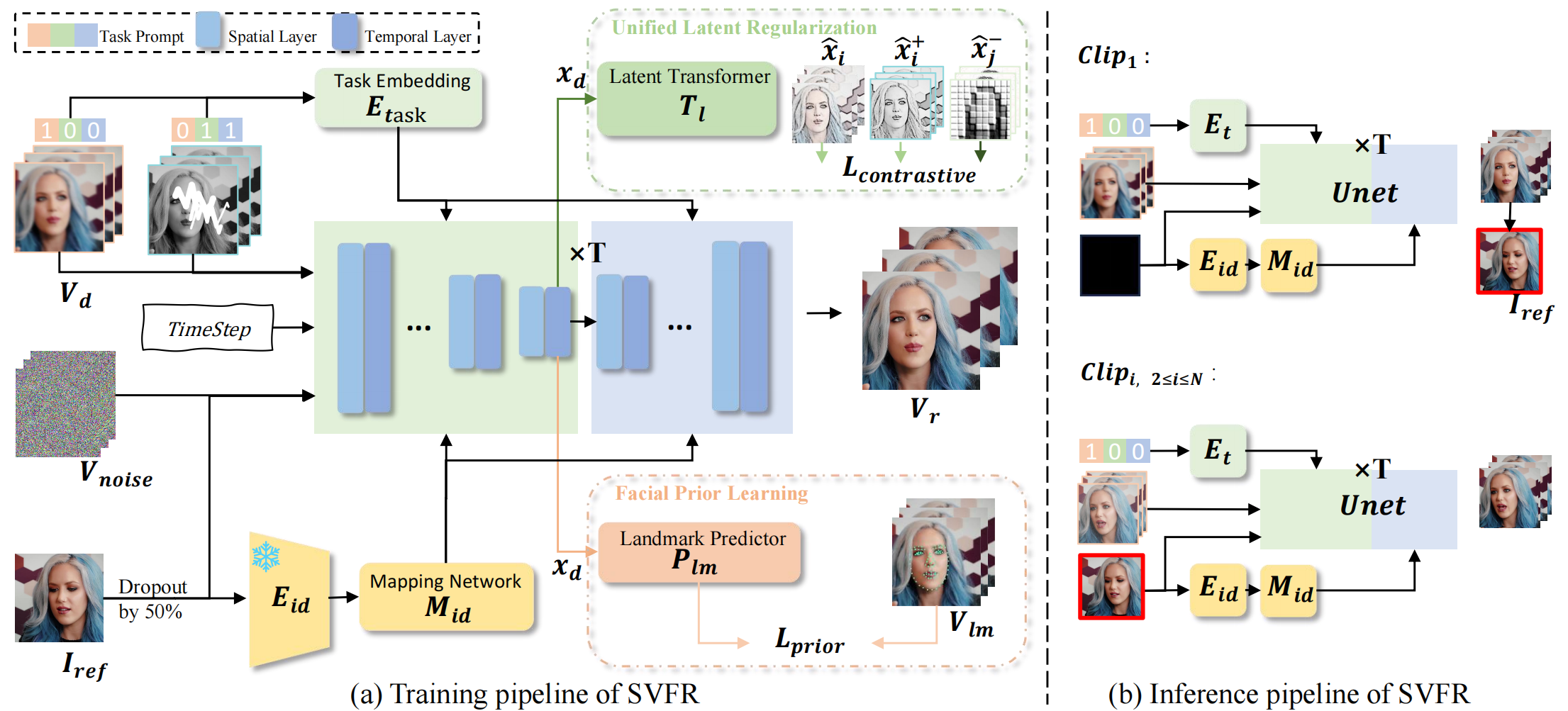
SVFR is a unified framework for face video restoration that supports tasks such as **BFR, Colorization, Inpainting**, and **their combinations** within one cohesive system.
|
| 13 |
+
|
| 14 |
+
<img src="assert/method.png">
|
| 15 |
+
|
| 16 |
+
## 🎬 Demo
|
| 17 |
+
|
| 18 |
+
### BFR
|
| 19 |
+
<!--
|
| 20 |
+
<div style="display: flex; gap: 10px;">
|
| 21 |
+
<video controls width="360">
|
| 22 |
+
<source src="https://wangzhiyaoo.github.io/SVFR/static/videos/wild-test/case1_bfr.mp4" type="video/mp4">
|
| 23 |
+
|
| 24 |
+
</video>
|
| 25 |
+
|
| 26 |
+
<video controls width="360">
|
| 27 |
+
<source src="https://wangzhiyaoo.github.io/SVFR/static/videos/wild-test/case4_bfr.mp4" type="video/mp4">
|
| 28 |
+
|
| 29 |
+
</video>
|
| 30 |
+
</div> -->
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
<!-- <div style="display: flex; gap: 10px;">
|
| 34 |
+
<video src="https://github.com/user-attachments/assets/49f985f3-a2db-4b9f-aed0-e9943bae9c17" controls width=45%></video>
|
| 35 |
+
<video src="https://github.com/user-attachments/assets/8fcd1dd9-79d3-4e57-b98e-a80ae2badfb5" controls width="45%"></video>
|
| 36 |
+
</div> -->
|
| 37 |
+
|
| 38 |
+
| Case1 | Case2 |
|
| 39 |
+
|--------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------|
|
| 40 |
+
|<video src="https://github.com/user-attachments/assets/49f985f3-a2db-4b9f-aed0-e9943bae9c17" /> | <video src="https://github.com/user-attachments/assets/8fcd1dd9-79d3-4e57-b98e-a80ae2badfb5" /> |
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
<!-- <video src="https://wangzhiyaoo.github.io/SVFR/bfr"> -->
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
<!-- https://github.com/user-attachments/assets/49f985f3-a2db-4b9f-aed0-e9943bae9c17
|
| 48 |
+
|
| 49 |
+
https://github.com/user-attachments/assets/8fcd1dd9-79d3-4e57-b98e-a80ae2badfb5 -->
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
### BFR+Colorization
|
| 56 |
+
<!-- <div style="display: flex; gap: 10px;">
|
| 57 |
+
<video controls width="360">
|
| 58 |
+
<source src="https://wangzhiyaoo.github.io/SVFR/static/videos/wild-test/case10_bfr_colorization.mp4" type="video/mp4">
|
| 59 |
+
|
| 60 |
+
</video>
|
| 61 |
+
|
| 62 |
+
<video controls width="360">
|
| 63 |
+
<source src="https://wangzhiyaoo.github.io/SVFR/static/videos/wild-test/case12_bfr_colorization.mp4" type="video/mp4">
|
| 64 |
+
|
| 65 |
+
</video>
|
| 66 |
+
</div> -->
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
<!-- https://github.com/user-attachments/assets/795f4cb1-a7c9-41c5-9486-26e64a96bcf0
|
| 70 |
+
|
| 71 |
+
https://github.com/user-attachments/assets/6ccf2267-30be-4553-9ecc-f3e7e0ca1d6f -->
|
| 72 |
+
|
| 73 |
+
| Case3 | Case4 |
|
| 74 |
+
|--------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------|
|
| 75 |
+
|<video src="https://github.com/user-attachments/assets/795f4cb1-a7c9-41c5-9486-26e64a96bcf0" /> | <video src="https://github.com/user-attachments/assets/6ccf2267-30be-4553-9ecc-f3e7e0ca1d6f" /> |
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
### BFR+Colorization+Inpainting
|
| 79 |
+
<!-- <div style="display: flex; gap: 10px;">
|
| 80 |
+
<video controls width="360">
|
| 81 |
+
<source src="https://wangzhiyaoo.github.io/SVFR/static/videos/wild-test/case14_bfr+colorization+inpainting.mp4" type="video/mp4">
|
| 82 |
+
|
| 83 |
+
</video>
|
| 84 |
+
|
| 85 |
+
<video controls width="360">
|
| 86 |
+
<source src="https://wangzhiyaoo.github.io/SVFR/static/videos/wild-test/case15_bfr+colorization+inpainting.mp4" type="video/mp4">
|
| 87 |
+
|
| 88 |
+
</video>
|
| 89 |
+
</div> -->
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
<!-- https://github.com/user-attachments/assets/6113819f-142b-4faa-b1c3-a2b669fd0786
|
| 94 |
+
|
| 95 |
+
https://github.com/user-attachments/assets/efdac23c-0ba5-4dad-ab8c-48904af5dd89
|
| 96 |
+
-->
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
| Case5 | Case6 |
|
| 100 |
+
|--------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------|
|
| 101 |
+
|<video src="https://github.com/user-attachments/assets/6113819f-142b-4faa-b1c3-a2b669fd0786" /> | <video src="https://github.com/user-attachments/assets/efdac23c-0ba5-4dad-ab8c-48904af5dd89" /> |
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
## 🎙️ News
|
| 105 |
+
|
| 106 |
+
- **[2025.01.02]**: We released the initial version of the [inference code](#inference) and [models](#download-checkpoints). Stay tuned for continuous updates!
|
| 107 |
+
- **[2024.12.17]**: This repo is created!
|
| 108 |
+
|
| 109 |
+
## 🚀 Getting Started
|
| 110 |
+
|
| 111 |
+
## Setup
|
| 112 |
+
|
| 113 |
+
Use the following command to install a conda environment for SVFR from scratch:
|
| 114 |
+
|
| 115 |
+
```bash
|
| 116 |
+
conda create -n svfr python=3.9 -y
|
| 117 |
+
conda activate svfr
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
Install PyTorch: make sure to select the appropriate CUDA version based on your hardware, for example,
|
| 121 |
+
|
| 122 |
+
```bash
|
| 123 |
+
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2
|
| 124 |
+
```
|
| 125 |
+
|
| 126 |
+
Install Dependencies:
|
| 127 |
+
|
| 128 |
+
```bash
|
| 129 |
+
pip install -r requirements.txt
|
| 130 |
+
```
|
| 131 |
+
|
| 132 |
+
## Download checkpoints
|
| 133 |
+
|
| 134 |
+
<li>Download the Stable Video Diffusion</li>
|
| 135 |
+
|
| 136 |
+
```
|
| 137 |
+
conda install git-lfs
|
| 138 |
+
git lfs install
|
| 139 |
+
git clone https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt models/stable-video-diffusion-img2vid-xt
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
<li>Download SVFR</li>
|
| 143 |
+
|
| 144 |
+
You can download checkpoints manually through link on [Google Drive](https://drive.google.com/drive/folders/1nzy9Vk-yA_DwXm1Pm4dyE2o0r7V6_5mn?usp=share_link).
|
| 145 |
+
|
| 146 |
+
Put checkpoints as follows:
|
| 147 |
+
|
| 148 |
+
```
|
| 149 |
+
└── models
|
| 150 |
+
├── face_align
|
| 151 |
+
│ ├── yoloface_v5m.pt
|
| 152 |
+
├── face_restoration
|
| 153 |
+
│ ├── unet.pth
|
| 154 |
+
│ ├── id_linear.pth
|
| 155 |
+
│ ├── insightface_glint360k.pth
|
| 156 |
+
└── stable-video-diffusion-img2vid-xt
|
| 157 |
+
├── vae
|
| 158 |
+
├── scheduler
|
| 159 |
+
└── ...
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
## Inference
|
| 163 |
+
|
| 164 |
+
### Inference single or multi task
|
| 165 |
+
|
| 166 |
+
```
|
| 167 |
+
python3 infer.py \
|
| 168 |
+
--config config/infer.yaml \
|
| 169 |
+
--task_ids 0 \
|
| 170 |
+
--input_path ./assert/lq/lq1.mp4 \
|
| 171 |
+
--output_dir ./results/
|
| 172 |
+
```
|
| 173 |
+
|
| 174 |
+
<li>task_id:</li>
|
| 175 |
+
|
| 176 |
+
> 0 -- bfr
|
| 177 |
+
> 1 -- colorization
|
| 178 |
+
> 2 -- inpainting
|
| 179 |
+
> 0,1 -- bfr and colorization
|
| 180 |
+
> 0,1,2 -- bfr and colorization and inpainting
|
| 181 |
+
> ...
|
| 182 |
+
|
| 183 |
+
### Inference with additional inpainting mask
|
| 184 |
+
|
| 185 |
+
```
|
| 186 |
+
# For Inference with Inpainting
|
| 187 |
+
# Add '--mask_path' if you need to specify the mask file.
|
| 188 |
+
|
| 189 |
+
python3 infer.py \
|
| 190 |
+
--config config/infer.yaml \
|
| 191 |
+
--task_ids 0,1,2 \
|
| 192 |
+
--input_path ./assert/lq/lq3.mp4 \
|
| 193 |
+
--output_dir ./results/
|
| 194 |
+
--mask_path ./assert/mask/lq3.png
|
| 195 |
+
```
|
| 196 |
+
|
| 197 |
+
## License
|
| 198 |
+
|
| 199 |
+
The code of SVFR is released under the MIT License. There is no limitation for both academic and commercial usage.
|
| 200 |
+
|
| 201 |
+
**The pretrained models we provided with this library are available for non-commercial research purposes only, including both auto-downloading models and manual-downloading models.**
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
## BibTex
|
| 205 |
+
```
|
| 206 |
+
@misc{wang2025svfrunifiedframeworkgeneralized,
|
| 207 |
+
title={SVFR: A Unified Framework for Generalized Video Face Restoration},
|
| 208 |
+
author={Zhiyao Wang and Xu Chen and Chengming Xu and Junwei Zhu and Xiaobin Hu and Jiangning Zhang and Chengjie Wang and Yuqi Liu and Yiyi Zhou and Rongrong Ji},
|
| 209 |
+
year={2025},
|
| 210 |
+
eprint={2501.01235},
|
| 211 |
+
archivePrefix={arXiv},
|
| 212 |
+
primaryClass={cs.CV},
|
| 213 |
+
url={https://arxiv.org/abs/2501.01235},
|
| 214 |
+
}
|
| 215 |
+
```
|
assert/lq/lq1.mp4
ADDED
|
Binary file (98.2 kB). View file
|
|
|
assert/lq/lq2.mp4
ADDED
|
Binary file (314 kB). View file
|
|
|
assert/lq/lq3.mp4
ADDED
|
Binary file (687 kB). View file
|
|
|
assert/mask/lq3.png
ADDED

|
assert/method.png
ADDED
|
config/infer.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
data:
|
| 2 |
+
n_sample_frames: 16
|
| 3 |
+
width: 512
|
| 4 |
+
height: 512
|
| 5 |
+
|
| 6 |
+
pretrained_model_name_or_path: "models/stable-video-diffusion-img2vid-xt"
|
| 7 |
+
unet_checkpoint_path: "models/face_restoration/unet.pth"
|
| 8 |
+
id_linear_checkpoint_path: "models/face_restoration/id_linear.pth"
|
| 9 |
+
net_arcface_checkpoint_path: "models/face_restoration/insightface_glint360k.pth"
|
| 10 |
+
# output_dir: 'result'
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
# test config
|
| 14 |
+
weight_dtype: 'fp16'
|
| 15 |
+
num_inference_steps: 30
|
| 16 |
+
decode_chunk_size: 16
|
| 17 |
+
overlap: 3
|
| 18 |
+
noise_aug_strength: 0.00
|
| 19 |
+
min_appearance_guidance_scale: 2.0
|
| 20 |
+
max_appearance_guidance_scale: 2.0
|
| 21 |
+
i2i_noise_strength: 1.0
|
infer.py
ADDED
|
@@ -0,0 +1,305 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import warnings
|
| 3 |
+
import os
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torch.utils.checkpoint
|
| 7 |
+
from PIL import Image
|
| 8 |
+
import random
|
| 9 |
+
|
| 10 |
+
from omegaconf import OmegaConf
|
| 11 |
+
from diffusers import AutoencoderKLTemporalDecoder
|
| 12 |
+
from diffusers.schedulers import EulerDiscreteScheduler
|
| 13 |
+
from transformers import CLIPVisionModelWithProjection
|
| 14 |
+
import torchvision.transforms as transforms
|
| 15 |
+
import torch.nn.functional as F
|
| 16 |
+
from src.models.svfr_adapter.unet_3d_svd_condition_ip import UNet3DConditionSVDModel
|
| 17 |
+
|
| 18 |
+
# pipeline
|
| 19 |
+
from src.pipelines.pipeline import LQ2VideoLongSVDPipeline
|
| 20 |
+
|
| 21 |
+
from src.utils.util import (
|
| 22 |
+
save_videos_grid,
|
| 23 |
+
seed_everything,
|
| 24 |
+
)
|
| 25 |
+
from torchvision.utils import save_image
|
| 26 |
+
|
| 27 |
+
from src.models.id_proj import IDProjConvModel
|
| 28 |
+
from src.models import model_insightface_360k
|
| 29 |
+
|
| 30 |
+
from src.dataset.face_align.align import AlignImage
|
| 31 |
+
|
| 32 |
+
warnings.filterwarnings("ignore")
|
| 33 |
+
|
| 34 |
+
import decord
|
| 35 |
+
import cv2
|
| 36 |
+
from src.dataset.dataset import get_affine_transform, mean_face_lm5p_256
|
| 37 |
+
|
| 38 |
+
BASE_DIR = '.'
|
| 39 |
+
|
| 40 |
+
def main(config,args):
|
| 41 |
+
if 'CUDA_VISIBLE_DEVICES' in os.environ:
|
| 42 |
+
cuda_visible_devices = os.environ['CUDA_VISIBLE_DEVICES']
|
| 43 |
+
print(f"CUDA_VISIBLE_DEVICES is set to: {cuda_visible_devices}")
|
| 44 |
+
else:
|
| 45 |
+
print("CUDA_VISIBLE_DEVICES is not set.")
|
| 46 |
+
|
| 47 |
+
save_dir = f"{BASE_DIR}/{args.output_dir}"
|
| 48 |
+
os.makedirs(save_dir,exist_ok=True)
|
| 49 |
+
|
| 50 |
+
vae = AutoencoderKLTemporalDecoder.from_pretrained(
|
| 51 |
+
f"{BASE_DIR}/{config.pretrained_model_name_or_path}",
|
| 52 |
+
subfolder="vae",
|
| 53 |
+
variant="fp16")
|
| 54 |
+
|
| 55 |
+
val_noise_scheduler = EulerDiscreteScheduler.from_pretrained(
|
| 56 |
+
f"{BASE_DIR}/{config.pretrained_model_name_or_path}",
|
| 57 |
+
subfolder="scheduler")
|
| 58 |
+
|
| 59 |
+
image_encoder = CLIPVisionModelWithProjection.from_pretrained(
|
| 60 |
+
f"{BASE_DIR}/{config.pretrained_model_name_or_path}",
|
| 61 |
+
subfolder="image_encoder",
|
| 62 |
+
variant="fp16")
|
| 63 |
+
unet = UNet3DConditionSVDModel.from_pretrained(
|
| 64 |
+
f"{BASE_DIR}/{config.pretrained_model_name_or_path}",
|
| 65 |
+
subfolder="unet",
|
| 66 |
+
variant="fp16")
|
| 67 |
+
|
| 68 |
+
weight_dir = 'models/face_align'
|
| 69 |
+
det_path = os.path.join(BASE_DIR, weight_dir, 'yoloface_v5m.pt')
|
| 70 |
+
align_instance = AlignImage("cuda", det_path=det_path)
|
| 71 |
+
|
| 72 |
+
to_tensor = transforms.Compose([
|
| 73 |
+
transforms.ToTensor(),
|
| 74 |
+
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
|
| 75 |
+
])
|
| 76 |
+
|
| 77 |
+
import torch.nn as nn
|
| 78 |
+
class InflatedConv3d(nn.Conv2d):
|
| 79 |
+
def forward(self, x):
|
| 80 |
+
x = super().forward(x)
|
| 81 |
+
return x
|
| 82 |
+
# Add ref channel
|
| 83 |
+
old_weights = unet.conv_in.weight
|
| 84 |
+
old_bias = unet.conv_in.bias
|
| 85 |
+
new_conv1 = InflatedConv3d(
|
| 86 |
+
12,
|
| 87 |
+
old_weights.shape[0],
|
| 88 |
+
kernel_size=unet.conv_in.kernel_size,
|
| 89 |
+
stride=unet.conv_in.stride,
|
| 90 |
+
padding=unet.conv_in.padding,
|
| 91 |
+
bias=True if old_bias is not None else False,
|
| 92 |
+
)
|
| 93 |
+
param = torch.zeros((320, 4, 3, 3), requires_grad=True)
|
| 94 |
+
new_conv1.weight = torch.nn.Parameter(torch.cat((old_weights, param), dim=1))
|
| 95 |
+
if old_bias is not None:
|
| 96 |
+
new_conv1.bias = old_bias
|
| 97 |
+
unet.conv_in = new_conv1
|
| 98 |
+
unet.config["in_channels"] = 12
|
| 99 |
+
unet.config.in_channels = 12
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
id_linear = IDProjConvModel(in_channels=512, out_channels=1024).to(device='cuda')
|
| 103 |
+
|
| 104 |
+
# load pretrained weights
|
| 105 |
+
unet_checkpoint_path = os.path.join(BASE_DIR, config.unet_checkpoint_path)
|
| 106 |
+
unet.load_state_dict(
|
| 107 |
+
torch.load(unet_checkpoint_path, map_location="cpu"),
|
| 108 |
+
strict=True,
|
| 109 |
+
)
|
| 110 |
+
|
| 111 |
+
id_linear_checkpoint_path = os.path.join(BASE_DIR, config.id_linear_checkpoint_path)
|
| 112 |
+
id_linear.load_state_dict(
|
| 113 |
+
torch.load(id_linear_checkpoint_path, map_location="cpu"),
|
| 114 |
+
strict=True,
|
| 115 |
+
)
|
| 116 |
+
|
| 117 |
+
net_arcface = model_insightface_360k.getarcface(f'{BASE_DIR}/{config.net_arcface_checkpoint_path}').eval().to(device="cuda")
|
| 118 |
+
|
| 119 |
+
if config.weight_dtype == "fp16":
|
| 120 |
+
weight_dtype = torch.float16
|
| 121 |
+
elif config.weight_dtype == "fp32":
|
| 122 |
+
weight_dtype = torch.float32
|
| 123 |
+
elif config.weight_dtype == "bf16":
|
| 124 |
+
weight_dtype = torch.bfloat16
|
| 125 |
+
else:
|
| 126 |
+
raise ValueError(
|
| 127 |
+
f"Do not support weight dtype: {config.weight_dtype} during training"
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
image_encoder.to(weight_dtype)
|
| 131 |
+
vae.to(weight_dtype)
|
| 132 |
+
unet.to(weight_dtype)
|
| 133 |
+
id_linear.to(weight_dtype)
|
| 134 |
+
net_arcface.requires_grad_(False).to(weight_dtype)
|
| 135 |
+
|
| 136 |
+
pipe = LQ2VideoLongSVDPipeline(
|
| 137 |
+
unet=unet,
|
| 138 |
+
image_encoder=image_encoder,
|
| 139 |
+
vae=vae,
|
| 140 |
+
scheduler=val_noise_scheduler,
|
| 141 |
+
feature_extractor=None
|
| 142 |
+
|
| 143 |
+
)
|
| 144 |
+
pipe = pipe.to("cuda", dtype=unet.dtype)
|
| 145 |
+
|
| 146 |
+
seed_input = args.seed
|
| 147 |
+
seed_everything(seed_input)
|
| 148 |
+
|
| 149 |
+
video_path = args.input_path
|
| 150 |
+
task_ids = args.task_ids
|
| 151 |
+
|
| 152 |
+
if 2 in task_ids and args.mask_path is not None:
|
| 153 |
+
mask_path = args.mask_path
|
| 154 |
+
mask = Image.open(mask_path).convert("L")
|
| 155 |
+
mask_array = np.array(mask)
|
| 156 |
+
|
| 157 |
+
white_positions = mask_array == 255
|
| 158 |
+
|
| 159 |
+
print('task_ids:',task_ids)
|
| 160 |
+
task_prompt = [0,0,0]
|
| 161 |
+
for i in range(3):
|
| 162 |
+
if i in task_ids:
|
| 163 |
+
task_prompt[i] = 1
|
| 164 |
+
print("task_prompt:",task_prompt)
|
| 165 |
+
|
| 166 |
+
video_name = video_path.split('/')[-1]
|
| 167 |
+
# print(video_name)
|
| 168 |
+
|
| 169 |
+
if os.path.exists(os.path.join(save_dir, "result_frames", video_name[:-4])):
|
| 170 |
+
print(os.path.join(save_dir, "result_frames", video_name[:-4]))
|
| 171 |
+
# continue
|
| 172 |
+
|
| 173 |
+
cap = decord.VideoReader(video_path, fault_tol=1)
|
| 174 |
+
total_frames = len(cap)
|
| 175 |
+
T = total_frames #
|
| 176 |
+
print("total_frames:",total_frames)
|
| 177 |
+
step=1
|
| 178 |
+
drive_idx_start = 0
|
| 179 |
+
drive_idx_list = list(range(drive_idx_start, drive_idx_start + T * step, step))
|
| 180 |
+
assert len(drive_idx_list) == T
|
| 181 |
+
|
| 182 |
+
imSameIDs = []
|
| 183 |
+
vid_gt = []
|
| 184 |
+
for i, drive_idx in enumerate(drive_idx_list):
|
| 185 |
+
frame = cap[drive_idx].asnumpy()
|
| 186 |
+
imSameID = Image.fromarray(frame)
|
| 187 |
+
|
| 188 |
+
imSameID = imSameID.resize((512,512))
|
| 189 |
+
image_array = np.array(imSameID)
|
| 190 |
+
if 2 in task_ids and args.mask_path is not None:
|
| 191 |
+
image_array[white_positions] = [255, 255, 255] # mask for inpainting task
|
| 192 |
+
vid_gt.append(np.float32(image_array/255.))
|
| 193 |
+
imSameIDs.append(imSameID)
|
| 194 |
+
|
| 195 |
+
vid_lq = [(torch.from_numpy(frame).permute(2,0,1) - 0.5) / 0.5 for frame in vid_gt]
|
| 196 |
+
|
| 197 |
+
val_data = dict(
|
| 198 |
+
pixel_values_vid_lq = torch.stack(vid_lq,dim=0),
|
| 199 |
+
# pixel_values_ref_img=self.to_tensor(target_image),
|
| 200 |
+
# pixel_values_ref_concat_img=self.to_tensor(imSrc2),
|
| 201 |
+
task_ids=task_ids,
|
| 202 |
+
task_id_input=torch.tensor(task_prompt),
|
| 203 |
+
total_frames=total_frames,
|
| 204 |
+
)
|
| 205 |
+
|
| 206 |
+
window_overlap=0
|
| 207 |
+
inter_frame_list = get_overlap_slide_window_indices(val_data["total_frames"],config.data.n_sample_frames,window_overlap)
|
| 208 |
+
|
| 209 |
+
lq_frames = val_data["pixel_values_vid_lq"]
|
| 210 |
+
task_ids = val_data["task_ids"]
|
| 211 |
+
task_id_input = val_data["task_id_input"]
|
| 212 |
+
height, width = val_data["pixel_values_vid_lq"].shape[-2:]
|
| 213 |
+
|
| 214 |
+
print("Generating the first clip...")
|
| 215 |
+
output = pipe(
|
| 216 |
+
lq_frames[inter_frame_list[0]].to("cuda").to(weight_dtype), # lq
|
| 217 |
+
None, # ref concat
|
| 218 |
+
torch.zeros((1, len(inter_frame_list[0]), 49, 1024)).to("cuda").to(weight_dtype),# encoder_hidden_states
|
| 219 |
+
task_id_input.to("cuda").to(weight_dtype),
|
| 220 |
+
height=height,
|
| 221 |
+
width=width,
|
| 222 |
+
num_frames=len(inter_frame_list[0]),
|
| 223 |
+
decode_chunk_size=config.decode_chunk_size,
|
| 224 |
+
noise_aug_strength=config.noise_aug_strength,
|
| 225 |
+
min_guidance_scale=config.min_appearance_guidance_scale,
|
| 226 |
+
max_guidance_scale=config.max_appearance_guidance_scale,
|
| 227 |
+
overlap=config.overlap,
|
| 228 |
+
frames_per_batch=len(inter_frame_list[0]),
|
| 229 |
+
num_inference_steps=50,
|
| 230 |
+
i2i_noise_strength=config.i2i_noise_strength,
|
| 231 |
+
)
|
| 232 |
+
video = output.frames
|
| 233 |
+
|
| 234 |
+
ref_img_tensor = video[0][:,-1]
|
| 235 |
+
ref_img = (video[0][:,-1] *0.5+0.5).clamp(0,1) * 255.
|
| 236 |
+
ref_img = ref_img.permute(1,2,0).cpu().numpy().astype(np.uint8)
|
| 237 |
+
|
| 238 |
+
pts5 = align_instance(ref_img[:,:,[2,1,0]], maxface=True)[0][0]
|
| 239 |
+
|
| 240 |
+
warp_mat = get_affine_transform(pts5, mean_face_lm5p_256 * height/256)
|
| 241 |
+
ref_img = cv2.warpAffine(np.array(Image.fromarray(ref_img)), warp_mat, (height, width), flags=cv2.INTER_CUBIC)
|
| 242 |
+
ref_img = to_tensor(ref_img).to("cuda").to(weight_dtype)
|
| 243 |
+
|
| 244 |
+
save_image(ref_img*0.5 + 0.5,f"{save_dir}/ref_img_align.png")
|
| 245 |
+
|
| 246 |
+
ref_img = F.interpolate(ref_img.unsqueeze(0)[:, :, 0:224, 16:240], size=[112, 112], mode='bilinear')
|
| 247 |
+
_, id_feature_conv = net_arcface(ref_img)
|
| 248 |
+
id_embedding = id_linear(id_feature_conv)
|
| 249 |
+
|
| 250 |
+
print('Generating all video clips...')
|
| 251 |
+
video = pipe(
|
| 252 |
+
lq_frames.to("cuda").to(weight_dtype), # lq
|
| 253 |
+
ref_img_tensor.to("cuda").to(weight_dtype),
|
| 254 |
+
id_embedding.unsqueeze(1).repeat(1, len(lq_frames), 1, 1).to("cuda").to(weight_dtype), # encoder_hidden_states
|
| 255 |
+
task_id_input.to("cuda").to(weight_dtype),
|
| 256 |
+
height=height,
|
| 257 |
+
width=width,
|
| 258 |
+
num_frames=val_data["total_frames"],#frame_num,
|
| 259 |
+
decode_chunk_size=config.decode_chunk_size,
|
| 260 |
+
noise_aug_strength=config.noise_aug_strength,
|
| 261 |
+
min_guidance_scale=config.min_appearance_guidance_scale,
|
| 262 |
+
max_guidance_scale=config.max_appearance_guidance_scale,
|
| 263 |
+
overlap=config.overlap,
|
| 264 |
+
frames_per_batch=config.data.n_sample_frames,
|
| 265 |
+
num_inference_steps=config.num_inference_steps,
|
| 266 |
+
i2i_noise_strength=config.i2i_noise_strength,
|
| 267 |
+
).frames
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
video = (video*0.5 + 0.5).clamp(0, 1)
|
| 271 |
+
video = torch.cat([video.to(device="cuda")], dim=0).cpu()
|
| 272 |
+
|
| 273 |
+
save_videos_grid(video, f"{save_dir}/{video_name[:-4]}_{seed_input}.mp4", n_rows=1, fps=25)
|
| 274 |
+
|
| 275 |
+
if args.restore_frames:
|
| 276 |
+
video = video.squeeze(0)
|
| 277 |
+
os.makedirs(os.path.join(save_dir, "result_frames", f"{video_name[:-4]}_{seed_input}"),exist_ok=True)
|
| 278 |
+
print(os.path.join(save_dir, "result_frames", video_name[:-4]))
|
| 279 |
+
for i in range(video.shape[1]):
|
| 280 |
+
save_frames_path = os.path.join(f"{save_dir}/result_frames", f"{video_name[:-4]}_{seed_input}", f'{i:08d}.png')
|
| 281 |
+
save_image(video[:,i], save_frames_path)
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
def get_overlap_slide_window_indices(video_length, window_size, window_overlap):
|
| 285 |
+
inter_frame_list = []
|
| 286 |
+
for j in range(0, video_length, window_size-window_overlap):
|
| 287 |
+
inter_frame_list.append( [e % video_length for e in range(j, min(j + window_size, video_length))] )
|
| 288 |
+
|
| 289 |
+
return inter_frame_list
|
| 290 |
+
|
| 291 |
+
if __name__ == "__main__":
|
| 292 |
+
def parse_list(value):
|
| 293 |
+
return [int(x) for x in value.split(",")]
|
| 294 |
+
parser = argparse.ArgumentParser()
|
| 295 |
+
parser.add_argument("--config", type=str, default="./configs/infer.yaml")
|
| 296 |
+
parser.add_argument("--output_dir", type=str, default="output")
|
| 297 |
+
parser.add_argument("--seed", type=int, default=77)
|
| 298 |
+
parser.add_argument("--task_ids", type=parse_list, default=[0])
|
| 299 |
+
parser.add_argument("--input_path", type=str, default='./assert/lq/lq3.mp4')
|
| 300 |
+
parser.add_argument("--mask_path", type=str, default=None)
|
| 301 |
+
parser.add_argument("--restore_frames", action='store_true')
|
| 302 |
+
|
| 303 |
+
args = parser.parse_args()
|
| 304 |
+
config = OmegaConf.load(args.config)
|
| 305 |
+
main(config, args)
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
accelerate
|
| 2 |
+
decord
|
| 3 |
+
diffusers
|
| 4 |
+
einops
|
| 5 |
+
moviepy==1.0.3
|
| 6 |
+
numpy<2.0
|
| 7 |
+
omegaconf
|
| 8 |
+
opencv-python
|
| 9 |
+
scikit-video
|
| 10 |
+
transformers
|
src/dataset/dataset.py
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import numpy as np
|
| 3 |
+
import random
|
| 4 |
+
from PIL import Image
|
| 5 |
+
import torch
|
| 6 |
+
from torch.utils.data import Dataset
|
| 7 |
+
import torchvision.transforms as transforms
|
| 8 |
+
from transformers import CLIPImageProcessor
|
| 9 |
+
# import librosa
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import cv2
|
| 13 |
+
|
| 14 |
+
mean_face_lm5p_256 = np.array([
|
| 15 |
+
[(30.2946+8)*2+16, 51.6963*2],
|
| 16 |
+
[(65.5318+8)*2+16, 51.5014*2],
|
| 17 |
+
[(48.0252+8)*2+16, 71.7366*2],
|
| 18 |
+
[(33.5493+8)*2+16, 92.3655*2],
|
| 19 |
+
[(62.7299+8)*2+16, 92.2041*2],
|
| 20 |
+
], dtype=np.float32)
|
| 21 |
+
|
| 22 |
+
def get_affine_transform(target_face_lm5p, mean_lm5p):
|
| 23 |
+
mat_warp = np.zeros((2,3))
|
| 24 |
+
A = np.zeros((4,4))
|
| 25 |
+
B = np.zeros((4))
|
| 26 |
+
for i in range(5):
|
| 27 |
+
A[0][0] += target_face_lm5p[i][0] * target_face_lm5p[i][0] + target_face_lm5p[i][1] * target_face_lm5p[i][1]
|
| 28 |
+
A[0][2] += target_face_lm5p[i][0]
|
| 29 |
+
A[0][3] += target_face_lm5p[i][1]
|
| 30 |
+
|
| 31 |
+
B[0] += target_face_lm5p[i][0] * mean_lm5p[i][0] + target_face_lm5p[i][1] * mean_lm5p[i][1] #sb[1] += a[i].x*b[i].y - a[i].y*b[i].x;
|
| 32 |
+
B[1] += target_face_lm5p[i][0] * mean_lm5p[i][1] - target_face_lm5p[i][1] * mean_lm5p[i][0]
|
| 33 |
+
B[2] += mean_lm5p[i][0]
|
| 34 |
+
B[3] += mean_lm5p[i][1]
|
| 35 |
+
|
| 36 |
+
A[1][1] = A[0][0]
|
| 37 |
+
A[2][1] = A[1][2] = -A[0][3]
|
| 38 |
+
A[3][1] = A[1][3] = A[2][0] = A[0][2]
|
| 39 |
+
A[2][2] = A[3][3] = 5
|
| 40 |
+
A[3][0] = A[0][3]
|
| 41 |
+
|
| 42 |
+
_, mat23 = cv2.solve(A, B, flags=cv2.DECOMP_SVD)
|
| 43 |
+
mat_warp[0][0] = mat23[0]
|
| 44 |
+
mat_warp[1][1] = mat23[0]
|
| 45 |
+
mat_warp[0][1] = -mat23[1]
|
| 46 |
+
mat_warp[1][0] = mat23[1]
|
| 47 |
+
mat_warp[0][2] = mat23[2]
|
| 48 |
+
mat_warp[1][2] = mat23[3]
|
| 49 |
+
|
| 50 |
+
return mat_warp
|
src/dataset/face_align/align.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
|
| 4 |
+
sys.path.append(BASE_DIR)
|
| 5 |
+
import torch
|
| 6 |
+
from src.dataset.face_align.yoloface import YoloFace
|
| 7 |
+
|
| 8 |
+
class AlignImage(object):
|
| 9 |
+
def __init__(self, device='cuda', det_path='checkpoints/yoloface_v5m.pt'):
|
| 10 |
+
self.facedet = YoloFace(pt_path=det_path, confThreshold=0.5, nmsThreshold=0.45, device=device)
|
| 11 |
+
|
| 12 |
+
@torch.no_grad()
|
| 13 |
+
def __call__(self, im, maxface=False):
|
| 14 |
+
bboxes, kpss, scores = self.facedet.detect(im)
|
| 15 |
+
face_num = bboxes.shape[0]
|
| 16 |
+
|
| 17 |
+
five_pts_list = []
|
| 18 |
+
scores_list = []
|
| 19 |
+
bboxes_list = []
|
| 20 |
+
for i in range(face_num):
|
| 21 |
+
five_pts_list.append(kpss[i].reshape(5,2))
|
| 22 |
+
scores_list.append(scores[i])
|
| 23 |
+
bboxes_list.append(bboxes[i])
|
| 24 |
+
|
| 25 |
+
if maxface and face_num>1:
|
| 26 |
+
max_idx = 0
|
| 27 |
+
max_area = (bboxes[0, 2])*(bboxes[0, 3])
|
| 28 |
+
for i in range(1, face_num):
|
| 29 |
+
area = (bboxes[i,2])*(bboxes[i,3])
|
| 30 |
+
if area>max_area:
|
| 31 |
+
max_idx = i
|
| 32 |
+
five_pts_list = [five_pts_list[max_idx]]
|
| 33 |
+
scores_list = [scores_list[max_idx]]
|
| 34 |
+
bboxes_list = [bboxes_list[max_idx]]
|
| 35 |
+
|
| 36 |
+
return five_pts_list, scores_list, bboxes_list
|
src/dataset/face_align/yoloface.py
ADDED
|
@@ -0,0 +1,310 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: UTF-8 -*-
|
| 2 |
+
import os
|
| 3 |
+
import cv2
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torchvision
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def xyxy2xywh(x):
|
| 10 |
+
# Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] where xy1=top-left, xy2=bottom-right
|
| 11 |
+
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
|
| 12 |
+
y[:, 0] = (x[:, 0] + x[:, 2]) / 2 # x center
|
| 13 |
+
y[:, 1] = (x[:, 1] + x[:, 3]) / 2 # y center
|
| 14 |
+
y[:, 2] = x[:, 2] - x[:, 0] # width
|
| 15 |
+
y[:, 3] = x[:, 3] - x[:, 1] # height
|
| 16 |
+
return y
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def xywh2xyxy(x):
|
| 20 |
+
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
|
| 21 |
+
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
|
| 22 |
+
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
|
| 23 |
+
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
|
| 24 |
+
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
|
| 25 |
+
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
|
| 26 |
+
return y
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def box_iou(box1, box2):
|
| 30 |
+
# https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
|
| 31 |
+
"""
|
| 32 |
+
Return intersection-over-union (Jaccard index) of boxes.
|
| 33 |
+
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
|
| 34 |
+
Arguments:
|
| 35 |
+
box1 (Tensor[N, 4])
|
| 36 |
+
box2 (Tensor[M, 4])
|
| 37 |
+
Returns:
|
| 38 |
+
iou (Tensor[N, M]): the NxM matrix containing the pairwise
|
| 39 |
+
IoU values for every element in boxes1 and boxes2
|
| 40 |
+
"""
|
| 41 |
+
|
| 42 |
+
def box_area(box):
|
| 43 |
+
# box = 4xn
|
| 44 |
+
return (box[2] - box[0]) * (box[3] - box[1])
|
| 45 |
+
|
| 46 |
+
area1 = box_area(box1.T)
|
| 47 |
+
area2 = box_area(box2.T)
|
| 48 |
+
|
| 49 |
+
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
|
| 50 |
+
inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) -
|
| 51 |
+
torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
|
| 52 |
+
# iou = inter / (area1 + area2 - inter)
|
| 53 |
+
return inter / (area1[:, None] + area2 - inter)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def scale_coords(img1_shape, coords, img0_shape, ratio_pad=None):
|
| 57 |
+
# Rescale coords (xyxy) from img1_shape to img0_shape
|
| 58 |
+
if ratio_pad is None: # calculate from img0_shape
|
| 59 |
+
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
|
| 60 |
+
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
|
| 61 |
+
else:
|
| 62 |
+
gain = ratio_pad[0][0]
|
| 63 |
+
pad = ratio_pad[1]
|
| 64 |
+
|
| 65 |
+
coords[:, [0, 2]] -= pad[0] # x padding
|
| 66 |
+
coords[:, [1, 3]] -= pad[1] # y padding
|
| 67 |
+
coords[:, :4] /= gain
|
| 68 |
+
clip_coords(coords, img0_shape)
|
| 69 |
+
return coords
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def clip_coords(boxes, img_shape):
|
| 73 |
+
# Clip bounding xyxy bounding boxes to image shape (height, width)
|
| 74 |
+
boxes[:, 0].clamp_(0, img_shape[1]) # x1
|
| 75 |
+
boxes[:, 1].clamp_(0, img_shape[0]) # y1
|
| 76 |
+
boxes[:, 2].clamp_(0, img_shape[1]) # x2
|
| 77 |
+
boxes[:, 3].clamp_(0, img_shape[0]) # y2
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def scale_coords_landmarks(img1_shape, coords, img0_shape, ratio_pad=None):
|
| 81 |
+
# Rescale coords (xyxy) from img1_shape to img0_shape
|
| 82 |
+
if ratio_pad is None: # calculate from img0_shape
|
| 83 |
+
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
|
| 84 |
+
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
|
| 85 |
+
else:
|
| 86 |
+
gain = ratio_pad[0][0]
|
| 87 |
+
pad = ratio_pad[1]
|
| 88 |
+
|
| 89 |
+
coords[:, [0, 2, 4, 6, 8]] -= pad[0] # x padding
|
| 90 |
+
coords[:, [1, 3, 5, 7, 9]] -= pad[1] # y padding
|
| 91 |
+
coords[:, :10] /= gain
|
| 92 |
+
#clip_coords(coords, img0_shape)
|
| 93 |
+
coords[:, 0].clamp_(0, img0_shape[1]) # x1
|
| 94 |
+
coords[:, 1].clamp_(0, img0_shape[0]) # y1
|
| 95 |
+
coords[:, 2].clamp_(0, img0_shape[1]) # x2
|
| 96 |
+
coords[:, 3].clamp_(0, img0_shape[0]) # y2
|
| 97 |
+
coords[:, 4].clamp_(0, img0_shape[1]) # x3
|
| 98 |
+
coords[:, 5].clamp_(0, img0_shape[0]) # y3
|
| 99 |
+
coords[:, 6].clamp_(0, img0_shape[1]) # x4
|
| 100 |
+
coords[:, 7].clamp_(0, img0_shape[0]) # y4
|
| 101 |
+
coords[:, 8].clamp_(0, img0_shape[1]) # x5
|
| 102 |
+
coords[:, 9].clamp_(0, img0_shape[0]) # y5
|
| 103 |
+
return coords
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def show_results(img, xywh, conf, landmarks, class_num):
|
| 107 |
+
h,w,c = img.shape
|
| 108 |
+
tl = 1 or round(0.002 * (h + w) / 2) + 1 # line/font thickness
|
| 109 |
+
x1 = int(xywh[0] * w - 0.5 * xywh[2] * w)
|
| 110 |
+
y1 = int(xywh[1] * h - 0.5 * xywh[3] * h)
|
| 111 |
+
x2 = int(xywh[0] * w + 0.5 * xywh[2] * w)
|
| 112 |
+
y2 = int(xywh[1] * h + 0.5 * xywh[3] * h)
|
| 113 |
+
cv2.rectangle(img, (x1,y1), (x2, y2), (0,255,0), thickness=tl, lineType=cv2.LINE_AA)
|
| 114 |
+
|
| 115 |
+
clors = [(255,0,0),(0,255,0),(0,0,255),(255,255,0),(0,255,255)]
|
| 116 |
+
|
| 117 |
+
for i in range(5):
|
| 118 |
+
point_x = int(landmarks[2 * i] * w)
|
| 119 |
+
point_y = int(landmarks[2 * i + 1] * h)
|
| 120 |
+
cv2.circle(img, (point_x, point_y), tl+1, clors[i], -1)
|
| 121 |
+
|
| 122 |
+
tf = max(tl - 1, 1) # font thickness
|
| 123 |
+
label = str(conf)[:5]
|
| 124 |
+
cv2.putText(img, label, (x1, y1 - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
|
| 125 |
+
return img
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def make_divisible(x, divisor):
|
| 129 |
+
# Returns x evenly divisible by divisor
|
| 130 |
+
return (x // divisor) * divisor
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def non_max_suppression_face(prediction, conf_thres=0.5, iou_thres=0.45, classes=None, agnostic=False, labels=()):
|
| 134 |
+
"""Performs Non-Maximum Suppression (NMS) on inference results
|
| 135 |
+
Returns:
|
| 136 |
+
detections with shape: nx6 (x1, y1, x2, y2, conf, cls)
|
| 137 |
+
"""
|
| 138 |
+
|
| 139 |
+
nc = prediction.shape[2] - 15 # number of classes
|
| 140 |
+
xc = prediction[..., 4] > conf_thres # candidates
|
| 141 |
+
|
| 142 |
+
# Settings
|
| 143 |
+
min_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and height
|
| 144 |
+
# time_limit = 10.0 # seconds to quit after
|
| 145 |
+
redundant = True # require redundant detections
|
| 146 |
+
multi_label = nc > 1 # multiple labels per box (adds 0.5ms/img)
|
| 147 |
+
merge = False # use merge-NMS
|
| 148 |
+
|
| 149 |
+
# t = time.time()
|
| 150 |
+
output = [torch.zeros((0, 16), device=prediction.device)] * prediction.shape[0]
|
| 151 |
+
for xi, x in enumerate(prediction): # image index, image inference
|
| 152 |
+
# Apply constraints
|
| 153 |
+
# x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
|
| 154 |
+
x = x[xc[xi]] # confidence
|
| 155 |
+
|
| 156 |
+
# Cat apriori labels if autolabelling
|
| 157 |
+
if labels and len(labels[xi]):
|
| 158 |
+
l = labels[xi]
|
| 159 |
+
v = torch.zeros((len(l), nc + 15), device=x.device)
|
| 160 |
+
v[:, :4] = l[:, 1:5] # box
|
| 161 |
+
v[:, 4] = 1.0 # conf
|
| 162 |
+
v[range(len(l)), l[:, 0].long() + 15] = 1.0 # cls
|
| 163 |
+
x = torch.cat((x, v), 0)
|
| 164 |
+
|
| 165 |
+
# If none remain process next image
|
| 166 |
+
if not x.shape[0]:
|
| 167 |
+
continue
|
| 168 |
+
|
| 169 |
+
# Compute conf
|
| 170 |
+
x[:, 15:] *= x[:, 4:5] # conf = obj_conf * cls_conf
|
| 171 |
+
|
| 172 |
+
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
|
| 173 |
+
box = xywh2xyxy(x[:, :4])
|
| 174 |
+
|
| 175 |
+
# Detections matrix nx6 (xyxy, conf, landmarks, cls)
|
| 176 |
+
if multi_label:
|
| 177 |
+
i, j = (x[:, 15:] > conf_thres).nonzero(as_tuple=False).T
|
| 178 |
+
x = torch.cat((box[i], x[i, j + 15, None], x[i, 5:15] ,j[:, None].float()), 1)
|
| 179 |
+
else: # best class only
|
| 180 |
+
conf, j = x[:, 15:].max(1, keepdim=True)
|
| 181 |
+
x = torch.cat((box, conf, x[:, 5:15], j.float()), 1)[conf.view(-1) > conf_thres]
|
| 182 |
+
|
| 183 |
+
# Filter by class
|
| 184 |
+
if classes is not None:
|
| 185 |
+
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
|
| 186 |
+
|
| 187 |
+
# If none remain process next image
|
| 188 |
+
n = x.shape[0] # number of boxes
|
| 189 |
+
if not n:
|
| 190 |
+
continue
|
| 191 |
+
|
| 192 |
+
# Batched NMS
|
| 193 |
+
c = x[:, 15:16] * (0 if agnostic else max_wh) # classes
|
| 194 |
+
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
|
| 195 |
+
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
|
| 196 |
+
#if i.shape[0] > max_det: # limit detections
|
| 197 |
+
# i = i[:max_det]
|
| 198 |
+
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
|
| 199 |
+
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
|
| 200 |
+
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
|
| 201 |
+
weights = iou * scores[None] # box weights
|
| 202 |
+
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
|
| 203 |
+
if redundant:
|
| 204 |
+
i = i[iou.sum(1) > 1] # require redundancy
|
| 205 |
+
|
| 206 |
+
output[xi] = x[i]
|
| 207 |
+
# if (time.time() - t) > time_limit:
|
| 208 |
+
# break # time limit exceeded
|
| 209 |
+
|
| 210 |
+
return output
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
class YoloFace():
|
| 214 |
+
def __init__(self, pt_path='checkpoints/yolov5m-face.pt', confThreshold=0.5, nmsThreshold=0.45, device='cuda'):
|
| 215 |
+
assert os.path.exists(pt_path)
|
| 216 |
+
|
| 217 |
+
self.inpSize = 416
|
| 218 |
+
self.conf_thres = confThreshold
|
| 219 |
+
self.iou_thres = nmsThreshold
|
| 220 |
+
self.test_device = torch.device(device if torch.cuda.is_available() else "cpu")
|
| 221 |
+
self.model = torch.jit.load(pt_path).to(self.test_device)
|
| 222 |
+
self.last_w = 416
|
| 223 |
+
self.last_h = 416
|
| 224 |
+
self.grids = None
|
| 225 |
+
|
| 226 |
+
@torch.no_grad()
|
| 227 |
+
def detect(self, srcimg):
|
| 228 |
+
# t0=time.time()
|
| 229 |
+
|
| 230 |
+
h0, w0 = srcimg.shape[:2] # orig hw
|
| 231 |
+
r = self.inpSize / min(h0, w0) # resize image to img_size
|
| 232 |
+
h1 = int(h0*r+31)//32*32
|
| 233 |
+
w1 = int(w0*r+31)//32*32
|
| 234 |
+
|
| 235 |
+
img = cv2.resize(srcimg, (w1,h1), interpolation=cv2.INTER_LINEAR)
|
| 236 |
+
|
| 237 |
+
# Convert
|
| 238 |
+
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR to RGB
|
| 239 |
+
|
| 240 |
+
# Run inference
|
| 241 |
+
img = torch.from_numpy(img).to(self.test_device).permute(2,0,1)
|
| 242 |
+
img = img.float()/255 # uint8 to fp16/32 0-1
|
| 243 |
+
if img.ndimension() == 3:
|
| 244 |
+
img = img.unsqueeze(0)
|
| 245 |
+
|
| 246 |
+
# Inference
|
| 247 |
+
if h1 != self.last_h or w1 != self.last_w or self.grids is None:
|
| 248 |
+
grids = []
|
| 249 |
+
for scale in [8,16,32]:
|
| 250 |
+
ny = h1//scale
|
| 251 |
+
nx = w1//scale
|
| 252 |
+
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
|
| 253 |
+
grid = torch.stack((xv, yv), 2).view((1,1,ny, nx, 2)).float()
|
| 254 |
+
grids.append(grid.to(self.test_device))
|
| 255 |
+
self.grids = grids
|
| 256 |
+
self.last_w = w1
|
| 257 |
+
self.last_h = h1
|
| 258 |
+
|
| 259 |
+
pred = self.model(img, self.grids).cpu()
|
| 260 |
+
|
| 261 |
+
# Apply NMS
|
| 262 |
+
det = non_max_suppression_face(pred, self.conf_thres, self.iou_thres)[0]
|
| 263 |
+
# Process detections
|
| 264 |
+
# det = pred[0]
|
| 265 |
+
bboxes = np.zeros((det.shape[0], 4))
|
| 266 |
+
kpss = np.zeros((det.shape[0], 5, 2))
|
| 267 |
+
scores = np.zeros((det.shape[0]))
|
| 268 |
+
# gn = torch.tensor([w0, h0, w0, h0]).to(pred) # normalization gain whwh
|
| 269 |
+
# gn_lks = torch.tensor([w0, h0, w0, h0, w0, h0, w0, h0, w0, h0]).to(pred) # normalization gain landmarks
|
| 270 |
+
det = det.cpu().numpy()
|
| 271 |
+
|
| 272 |
+
for j in range(det.shape[0]):
|
| 273 |
+
# xywh = (xyxy2xywh(det[j, :4].view(1, 4)) / gn).view(4).cpu().numpy()
|
| 274 |
+
bboxes[j, 0] = det[j, 0] * w0/w1
|
| 275 |
+
bboxes[j, 1] = det[j, 1] * h0/h1
|
| 276 |
+
bboxes[j, 2] = det[j, 2] * w0/w1 - bboxes[j, 0]
|
| 277 |
+
bboxes[j, 3] = det[j, 3] * h0/h1 - bboxes[j, 1]
|
| 278 |
+
scores[j] = det[j, 4]
|
| 279 |
+
# landmarks = (det[j, 5:15].view(1, 10) / gn_lks).view(5,2).cpu().numpy()
|
| 280 |
+
kpss[j, :, :] = det[j, 5:15].reshape(5, 2) * np.array([[w0/w1,h0/h1]])
|
| 281 |
+
# class_num = det[j, 15].cpu().numpy()
|
| 282 |
+
# orgimg = show_results(orgimg, xywh, conf, landmarks, class_num)
|
| 283 |
+
return bboxes, kpss, scores
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
|
| 287 |
+
if __name__ == '__main__':
|
| 288 |
+
import time
|
| 289 |
+
|
| 290 |
+
imgpath = 'test.png'
|
| 291 |
+
|
| 292 |
+
yoloface = YoloFace(pt_path='../checkpoints/yoloface_v5m.pt')
|
| 293 |
+
srcimg = cv2.imread(imgpath)
|
| 294 |
+
|
| 295 |
+
#warpup
|
| 296 |
+
bboxes, kpss, scores = yoloface.detect(srcimg)
|
| 297 |
+
bboxes, kpss, scores = yoloface.detect(srcimg)
|
| 298 |
+
bboxes, kpss, scores = yoloface.detect(srcimg)
|
| 299 |
+
|
| 300 |
+
t1 = time.time()
|
| 301 |
+
for _ in range(10):
|
| 302 |
+
bboxes, kpss, scores = yoloface.detect(srcimg)
|
| 303 |
+
t2 = time.time()
|
| 304 |
+
print('total time: {} ms'.format((t2 - t1) * 1000))
|
| 305 |
+
for i in range(bboxes.shape[0]):
|
| 306 |
+
xmin, ymin, xamx, ymax = int(bboxes[i, 0]), int(bboxes[i, 1]), int(bboxes[i, 0] + bboxes[i, 2]), int(bboxes[i, 1] + bboxes[i, 3])
|
| 307 |
+
cv2.rectangle(srcimg, (xmin, ymin), (xamx, ymax), (0, 0, 255), thickness=2)
|
| 308 |
+
for j in range(5):
|
| 309 |
+
cv2.circle(srcimg, (int(kpss[i, j, 0]), int(kpss[i, j, 1])), 1, (0, 255, 0), thickness=5)
|
| 310 |
+
cv2.imwrite('test_yoloface.jpg', srcimg)
|
src/models/id_proj.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import torch
|
| 3 |
+
from diffusers import ModelMixin
|
| 4 |
+
from einops import rearrange
|
| 5 |
+
from torch import nn
|
| 6 |
+
|
| 7 |
+
class IDProjConvModel(ModelMixin):
|
| 8 |
+
def __init__(self, in_channels=2048, out_channels=1024):
|
| 9 |
+
super().__init__()
|
| 10 |
+
|
| 11 |
+
self.project1024 = torch.nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, bias=False)
|
| 12 |
+
self.final_norm = torch.nn.LayerNorm(out_channels)
|
| 13 |
+
|
| 14 |
+
def forward(self, src_id_features_7_7_1024):
|
| 15 |
+
c = self.project1024(src_id_features_7_7_1024)
|
| 16 |
+
c = torch.flatten(c, 2)
|
| 17 |
+
c = torch.transpose(c, 2, 1)
|
| 18 |
+
c = self.final_norm(c)
|
| 19 |
+
|
| 20 |
+
return c
|
src/models/model_insightface_360k.py
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
from torch import nn
|
| 4 |
+
|
| 5 |
+
__all__ = ['iresnet18', 'iresnet34', 'iresnet50', 'iresnet100', 'iresnet200', 'getarcface']
|
| 6 |
+
|
| 7 |
+
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
|
| 8 |
+
"""3x3 convolution with padding"""
|
| 9 |
+
return nn.Conv2d(in_planes,
|
| 10 |
+
out_planes,
|
| 11 |
+
kernel_size=3,
|
| 12 |
+
stride=stride,
|
| 13 |
+
padding=dilation,
|
| 14 |
+
groups=groups,
|
| 15 |
+
bias=False,
|
| 16 |
+
dilation=dilation)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def conv1x1(in_planes, out_planes, stride=1):
|
| 20 |
+
"""1x1 convolution"""
|
| 21 |
+
return nn.Conv2d(in_planes,
|
| 22 |
+
out_planes,
|
| 23 |
+
kernel_size=1,
|
| 24 |
+
stride=stride,
|
| 25 |
+
bias=False)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class IBasicBlock(nn.Module):
|
| 29 |
+
expansion = 1
|
| 30 |
+
def __init__(self, inplanes, planes, stride=1, downsample=None,
|
| 31 |
+
groups=1, base_width=64, dilation=1):
|
| 32 |
+
super(IBasicBlock, self).__init__()
|
| 33 |
+
if groups != 1 or base_width != 64:
|
| 34 |
+
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
|
| 35 |
+
if dilation > 1:
|
| 36 |
+
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
|
| 37 |
+
self.bn1 = nn.BatchNorm2d(inplanes, eps=1e-05,)
|
| 38 |
+
self.conv1 = conv3x3(inplanes, planes)
|
| 39 |
+
self.bn2 = nn.BatchNorm2d(planes, eps=1e-05,)
|
| 40 |
+
self.prelu = nn.PReLU(planes)
|
| 41 |
+
self.conv2 = conv3x3(planes, planes, stride)
|
| 42 |
+
self.bn3 = nn.BatchNorm2d(planes, eps=1e-05,)
|
| 43 |
+
self.downsample = downsample
|
| 44 |
+
self.stride = stride
|
| 45 |
+
|
| 46 |
+
def forward(self, x):
|
| 47 |
+
identity = x
|
| 48 |
+
out = self.bn1(x)
|
| 49 |
+
out = self.conv1(out)
|
| 50 |
+
out = self.bn2(out)
|
| 51 |
+
out = self.prelu(out)
|
| 52 |
+
out = self.conv2(out)
|
| 53 |
+
out = self.bn3(out)
|
| 54 |
+
if self.downsample is not None:
|
| 55 |
+
identity = self.downsample(x)
|
| 56 |
+
out += identity
|
| 57 |
+
return out
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class IResNet(nn.Module):
|
| 61 |
+
fc_scale = 7 * 7
|
| 62 |
+
def __init__(self,
|
| 63 |
+
block, layers, dropout=0, num_features=512, zero_init_residual=False,
|
| 64 |
+
groups=1, width_per_group=64, replace_stride_with_dilation=None, fp16=False):
|
| 65 |
+
super(IResNet, self).__init__()
|
| 66 |
+
self.fp16 = fp16
|
| 67 |
+
self.inplanes = 64
|
| 68 |
+
self.dilation = 1
|
| 69 |
+
if replace_stride_with_dilation is None:
|
| 70 |
+
replace_stride_with_dilation = [False, False, False]
|
| 71 |
+
if len(replace_stride_with_dilation) != 3:
|
| 72 |
+
raise ValueError("replace_stride_with_dilation should be None "
|
| 73 |
+
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
|
| 74 |
+
self.groups = groups
|
| 75 |
+
self.base_width = width_per_group
|
| 76 |
+
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)
|
| 77 |
+
self.bn1 = nn.BatchNorm2d(self.inplanes, eps=1e-05)
|
| 78 |
+
self.prelu = nn.PReLU(self.inplanes)
|
| 79 |
+
self.layer1 = self._make_layer(block, 64, layers[0], stride=2)
|
| 80 |
+
self.layer2 = self._make_layer(block,
|
| 81 |
+
128,
|
| 82 |
+
layers[1],
|
| 83 |
+
stride=2,
|
| 84 |
+
dilate=replace_stride_with_dilation[0])
|
| 85 |
+
self.layer3 = self._make_layer(block,
|
| 86 |
+
256,
|
| 87 |
+
layers[2],
|
| 88 |
+
stride=2,
|
| 89 |
+
dilate=replace_stride_with_dilation[1])
|
| 90 |
+
self.layer4 = self._make_layer(block,
|
| 91 |
+
512,
|
| 92 |
+
layers[3],
|
| 93 |
+
stride=2,
|
| 94 |
+
dilate=replace_stride_with_dilation[2])
|
| 95 |
+
self.bn2 = nn.BatchNorm2d(512 * block.expansion, eps=1e-05,)
|
| 96 |
+
self.dropout = nn.Dropout(p=dropout, inplace=True)
|
| 97 |
+
self.fc = nn.Linear(512 * block.expansion * self.fc_scale, num_features)
|
| 98 |
+
self.features = nn.BatchNorm1d(num_features, eps=1e-05)
|
| 99 |
+
nn.init.constant_(self.features.weight, 1.0)
|
| 100 |
+
self.features.weight.requires_grad = False
|
| 101 |
+
|
| 102 |
+
for m in self.modules():
|
| 103 |
+
if isinstance(m, nn.Conv2d):
|
| 104 |
+
nn.init.normal_(m.weight, 0, 0.1)
|
| 105 |
+
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
|
| 106 |
+
nn.init.constant_(m.weight, 1)
|
| 107 |
+
nn.init.constant_(m.bias, 0)
|
| 108 |
+
|
| 109 |
+
if zero_init_residual:
|
| 110 |
+
for m in self.modules():
|
| 111 |
+
if isinstance(m, IBasicBlock):
|
| 112 |
+
nn.init.constant_(m.bn2.weight, 0)
|
| 113 |
+
|
| 114 |
+
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
|
| 115 |
+
downsample = None
|
| 116 |
+
previous_dilation = self.dilation
|
| 117 |
+
if dilate:
|
| 118 |
+
self.dilation *= stride
|
| 119 |
+
stride = 1
|
| 120 |
+
if stride != 1 or self.inplanes != planes * block.expansion:
|
| 121 |
+
downsample = nn.Sequential(
|
| 122 |
+
conv1x1(self.inplanes, planes * block.expansion, stride),
|
| 123 |
+
nn.BatchNorm2d(planes * block.expansion, eps=1e-05, ),
|
| 124 |
+
)
|
| 125 |
+
layers = []
|
| 126 |
+
layers.append(
|
| 127 |
+
block(self.inplanes, planes, stride, downsample, self.groups,
|
| 128 |
+
self.base_width, previous_dilation))
|
| 129 |
+
self.inplanes = planes * block.expansion
|
| 130 |
+
for _ in range(1, blocks):
|
| 131 |
+
layers.append(
|
| 132 |
+
block(self.inplanes,
|
| 133 |
+
planes,
|
| 134 |
+
groups=self.groups,
|
| 135 |
+
base_width=self.base_width,
|
| 136 |
+
dilation=self.dilation))
|
| 137 |
+
|
| 138 |
+
return nn.Sequential(*layers)
|
| 139 |
+
|
| 140 |
+
def forward(self, x):
|
| 141 |
+
# with torch.cuda.amp.autocast(self.fp16):
|
| 142 |
+
x = self.conv1(x)
|
| 143 |
+
x = self.bn1(x)
|
| 144 |
+
x = self.prelu(x)
|
| 145 |
+
x = self.layer1(x)
|
| 146 |
+
x = self.layer2(x)
|
| 147 |
+
x = self.layer3(x)
|
| 148 |
+
x = self.layer4(x)
|
| 149 |
+
layer4_res = x
|
| 150 |
+
x = self.bn2(x)
|
| 151 |
+
x = torch.flatten(x, 1)
|
| 152 |
+
x = self.dropout(x)
|
| 153 |
+
x = self.fc(x.float() if self.fp16 else x)
|
| 154 |
+
y = self.features(x)
|
| 155 |
+
return y,layer4_res
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
def _iresnet(arch, block, layers, pretrained, progress, **kwargs):
|
| 159 |
+
model = IResNet(block, layers, **kwargs)
|
| 160 |
+
if pretrained:
|
| 161 |
+
raise ValueError()
|
| 162 |
+
return model
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
def iresnet18(pretrained=False, progress=True, **kwargs):
|
| 166 |
+
return _iresnet('iresnet18', IBasicBlock, [2, 2, 2, 2], pretrained,
|
| 167 |
+
progress, **kwargs)
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
def iresnet34(pretrained=False, progress=True, **kwargs):
|
| 171 |
+
return _iresnet('iresnet34', IBasicBlock, [3, 4, 6, 3], pretrained,
|
| 172 |
+
progress, **kwargs)
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
def iresnet50(pretrained=False, progress=True, **kwargs):
|
| 176 |
+
return _iresnet('iresnet50', IBasicBlock, [3, 4, 14, 3], pretrained,
|
| 177 |
+
progress, **kwargs)
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
def iresnet100(pretrained=False, progress=True, **kwargs):
|
| 181 |
+
return _iresnet('iresnet100', IBasicBlock, [3, 13, 30, 3], pretrained,
|
| 182 |
+
progress, **kwargs)
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
def iresnet200(pretrained=False, progress=True, **kwargs):
|
| 186 |
+
return _iresnet('iresnet200', IBasicBlock, [6, 26, 60, 6], pretrained,
|
| 187 |
+
progress, **kwargs)
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
def getarcface(pretrained=None):
|
| 191 |
+
model = iresnet100()
|
| 192 |
+
for param in model.parameters():
|
| 193 |
+
param.requires_grad=False
|
| 194 |
+
|
| 195 |
+
if pretrained is not None and os.path.exists(pretrained):
|
| 196 |
+
info = model.load_state_dict(torch.load(pretrained, map_location=lambda storage, loc: storage))
|
| 197 |
+
# print('insightface_glint360k', info)
|
| 198 |
+
return model.eval()
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
if __name__=='__main__':
|
| 202 |
+
ckpt = 'pretrained/insightface_glint360k.pth'
|
| 203 |
+
arcface = getarcface(ckpt)
|
src/models/svfr_adapter/attention_processor.py
ADDED
|
@@ -0,0 +1,616 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import inspect
|
| 2 |
+
import math
|
| 3 |
+
from typing import Callable, List, Optional, Union
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from torch import nn
|
| 8 |
+
|
| 9 |
+
from diffusers.image_processor import IPAdapterMaskProcessor
|
| 10 |
+
from diffusers.utils import deprecate, logging
|
| 11 |
+
from diffusers.utils.import_utils import is_torch_npu_available, is_xformers_available
|
| 12 |
+
from diffusers.utils.torch_utils import maybe_allow_in_graph
|
| 13 |
+
from diffusers.models.attention_processor import Attention
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 17 |
+
|
| 18 |
+
if is_torch_npu_available():
|
| 19 |
+
import torch_npu
|
| 20 |
+
|
| 21 |
+
if is_xformers_available():
|
| 22 |
+
import xformers
|
| 23 |
+
import xformers.ops
|
| 24 |
+
else:
|
| 25 |
+
xformers = None
|
| 26 |
+
|
| 27 |
+
class AttnProcessor:
|
| 28 |
+
r"""
|
| 29 |
+
Default processor for performing attention-related computations.
|
| 30 |
+
"""
|
| 31 |
+
|
| 32 |
+
def __call__(
|
| 33 |
+
self,
|
| 34 |
+
attn: Attention,
|
| 35 |
+
hidden_states: torch.Tensor,
|
| 36 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 37 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 38 |
+
temb: Optional[torch.Tensor] = None,
|
| 39 |
+
*args,
|
| 40 |
+
**kwargs,
|
| 41 |
+
) -> torch.Tensor:
|
| 42 |
+
if len(args) > 0 or kwargs.get("scale", None) is not None:
|
| 43 |
+
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
|
| 44 |
+
deprecate("scale", "1.0.0", deprecation_message)
|
| 45 |
+
|
| 46 |
+
residual = hidden_states
|
| 47 |
+
|
| 48 |
+
if attn.spatial_norm is not None:
|
| 49 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 50 |
+
|
| 51 |
+
input_ndim = hidden_states.ndim
|
| 52 |
+
|
| 53 |
+
if input_ndim == 4:
|
| 54 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 55 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 56 |
+
|
| 57 |
+
batch_size, sequence_length, _ = (
|
| 58 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 59 |
+
)
|
| 60 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 61 |
+
|
| 62 |
+
if attn.group_norm is not None:
|
| 63 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 64 |
+
|
| 65 |
+
query = attn.to_q(hidden_states)
|
| 66 |
+
|
| 67 |
+
if encoder_hidden_states is None:
|
| 68 |
+
encoder_hidden_states = hidden_states
|
| 69 |
+
elif attn.norm_cross:
|
| 70 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 71 |
+
|
| 72 |
+
key = attn.to_k(encoder_hidden_states)
|
| 73 |
+
value = attn.to_v(encoder_hidden_states)
|
| 74 |
+
|
| 75 |
+
query = attn.head_to_batch_dim(query)
|
| 76 |
+
key = attn.head_to_batch_dim(key)
|
| 77 |
+
value = attn.head_to_batch_dim(value)
|
| 78 |
+
|
| 79 |
+
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
| 80 |
+
hidden_states = torch.bmm(attention_probs, value)
|
| 81 |
+
hidden_states = attn.batch_to_head_dim(hidden_states)
|
| 82 |
+
|
| 83 |
+
# linear proj
|
| 84 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 85 |
+
# dropout
|
| 86 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 87 |
+
|
| 88 |
+
if input_ndim == 4:
|
| 89 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 90 |
+
|
| 91 |
+
if attn.residual_connection:
|
| 92 |
+
hidden_states = hidden_states + residual
|
| 93 |
+
|
| 94 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 95 |
+
|
| 96 |
+
return hidden_states
|
| 97 |
+
|
| 98 |
+
class AttnProcessor2_0(nn.Module):
|
| 99 |
+
r"""
|
| 100 |
+
Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
|
| 101 |
+
"""
|
| 102 |
+
|
| 103 |
+
def __init__(self):
|
| 104 |
+
super().__init__()
|
| 105 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 106 |
+
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
| 107 |
+
|
| 108 |
+
def __call__(
|
| 109 |
+
self,
|
| 110 |
+
attn: Attention,
|
| 111 |
+
hidden_states: torch.Tensor,
|
| 112 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 113 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 114 |
+
temb: Optional[torch.Tensor] = None,
|
| 115 |
+
ip_adapter_masks: Optional[torch.Tensor] = None,
|
| 116 |
+
*args,
|
| 117 |
+
**kwargs,
|
| 118 |
+
) -> torch.Tensor:
|
| 119 |
+
if len(args) > 0 or kwargs.get("scale", None) is not None:
|
| 120 |
+
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
|
| 121 |
+
deprecate("scale", "1.0.0", deprecation_message)
|
| 122 |
+
|
| 123 |
+
residual = hidden_states
|
| 124 |
+
if attn.spatial_norm is not None:
|
| 125 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 126 |
+
|
| 127 |
+
input_ndim = hidden_states.ndim
|
| 128 |
+
|
| 129 |
+
if input_ndim == 4:
|
| 130 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 131 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 132 |
+
|
| 133 |
+
batch_size, sequence_length, _ = (
|
| 134 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
if attention_mask is not None:
|
| 138 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 139 |
+
# scaled_dot_product_attention expects attention_mask shape to be
|
| 140 |
+
# (batch, heads, source_length, target_length)
|
| 141 |
+
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
| 142 |
+
|
| 143 |
+
if attn.group_norm is not None:
|
| 144 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 145 |
+
|
| 146 |
+
query = attn.to_q(hidden_states)
|
| 147 |
+
|
| 148 |
+
if encoder_hidden_states is None:
|
| 149 |
+
encoder_hidden_states = hidden_states
|
| 150 |
+
elif attn.norm_cross:
|
| 151 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 152 |
+
|
| 153 |
+
key = attn.to_k(encoder_hidden_states)
|
| 154 |
+
value = attn.to_v(encoder_hidden_states)
|
| 155 |
+
|
| 156 |
+
inner_dim = key.shape[-1]
|
| 157 |
+
head_dim = inner_dim // attn.heads
|
| 158 |
+
|
| 159 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 160 |
+
|
| 161 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 162 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 163 |
+
|
| 164 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 165 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 166 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 167 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 168 |
+
)
|
| 169 |
+
|
| 170 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 171 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 172 |
+
|
| 173 |
+
# linear proj
|
| 174 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 175 |
+
# dropout
|
| 176 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 177 |
+
|
| 178 |
+
if input_ndim == 4:
|
| 179 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 180 |
+
|
| 181 |
+
if attn.residual_connection:
|
| 182 |
+
hidden_states = hidden_states + residual
|
| 183 |
+
|
| 184 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 185 |
+
|
| 186 |
+
return hidden_states
|
| 187 |
+
|
| 188 |
+
class IPAdapterAttnProcessor(nn.Module):
|
| 189 |
+
r"""
|
| 190 |
+
Attention processor for Multiple IP-Adapters.
|
| 191 |
+
|
| 192 |
+
Args:
|
| 193 |
+
hidden_size (`int`):
|
| 194 |
+
The hidden size of the attention layer.
|
| 195 |
+
cross_attention_dim (`int`):
|
| 196 |
+
The number of channels in the `encoder_hidden_states`.
|
| 197 |
+
num_tokens (`int`, `Tuple[int]` or `List[int]`, defaults to `(4,)`):
|
| 198 |
+
The context length of the image features.
|
| 199 |
+
scale (`float` or List[`float`], defaults to 1.0):
|
| 200 |
+
the weight scale of image prompt.
|
| 201 |
+
"""
|
| 202 |
+
|
| 203 |
+
def __init__(self, hidden_size, cross_attention_dim=None, num_tokens=(4,), scale=1.0):
|
| 204 |
+
super().__init__()
|
| 205 |
+
|
| 206 |
+
self.hidden_size = hidden_size
|
| 207 |
+
self.cross_attention_dim = cross_attention_dim
|
| 208 |
+
|
| 209 |
+
if not isinstance(num_tokens, (tuple, list)):
|
| 210 |
+
num_tokens = [num_tokens]
|
| 211 |
+
self.num_tokens = num_tokens
|
| 212 |
+
|
| 213 |
+
if not isinstance(scale, list):
|
| 214 |
+
scale = [scale] * len(num_tokens)
|
| 215 |
+
if len(scale) != len(num_tokens):
|
| 216 |
+
raise ValueError("`scale` should be a list of integers with the same length as `num_tokens`.")
|
| 217 |
+
self.scale = scale
|
| 218 |
+
|
| 219 |
+
self.to_k_ip = nn.ModuleList(
|
| 220 |
+
[nn.Linear(cross_attention_dim, hidden_size, bias=False) for _ in range(len(num_tokens))]
|
| 221 |
+
)
|
| 222 |
+
self.to_v_ip = nn.ModuleList(
|
| 223 |
+
[nn.Linear(cross_attention_dim, hidden_size, bias=False) for _ in range(len(num_tokens))]
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
def __call__(
|
| 227 |
+
self,
|
| 228 |
+
attn: Attention,
|
| 229 |
+
hidden_states: torch.Tensor,
|
| 230 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 231 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 232 |
+
temb: Optional[torch.Tensor] = None,
|
| 233 |
+
scale: float = 1.0,
|
| 234 |
+
ip_adapter_masks: Optional[torch.Tensor] = None,
|
| 235 |
+
):
|
| 236 |
+
residual = hidden_states
|
| 237 |
+
|
| 238 |
+
# separate ip_hidden_states from encoder_hidden_states
|
| 239 |
+
if encoder_hidden_states is not None:
|
| 240 |
+
if isinstance(encoder_hidden_states, tuple):
|
| 241 |
+
encoder_hidden_states, ip_hidden_states = encoder_hidden_states
|
| 242 |
+
else:
|
| 243 |
+
deprecation_message = (
|
| 244 |
+
"You have passed a tensor as `encoder_hidden_states`. This is deprecated and will be removed in a future release."
|
| 245 |
+
" Please make sure to update your script to pass `encoder_hidden_states` as a tuple to suppress this warning."
|
| 246 |
+
)
|
| 247 |
+
deprecate("encoder_hidden_states not a tuple", "1.0.0", deprecation_message, standard_warn=False)
|
| 248 |
+
end_pos = encoder_hidden_states.shape[1] - self.num_tokens[0]
|
| 249 |
+
encoder_hidden_states, ip_hidden_states = (
|
| 250 |
+
encoder_hidden_states[:, :end_pos, :],
|
| 251 |
+
[encoder_hidden_states[:, end_pos:, :]],
|
| 252 |
+
)
|
| 253 |
+
|
| 254 |
+
if attn.spatial_norm is not None:
|
| 255 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 256 |
+
|
| 257 |
+
input_ndim = hidden_states.ndim
|
| 258 |
+
|
| 259 |
+
if input_ndim == 4:
|
| 260 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 261 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 262 |
+
|
| 263 |
+
batch_size, sequence_length, _ = (
|
| 264 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 265 |
+
)
|
| 266 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 267 |
+
|
| 268 |
+
if attn.group_norm is not None:
|
| 269 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 270 |
+
|
| 271 |
+
query = attn.to_q(hidden_states)
|
| 272 |
+
|
| 273 |
+
if encoder_hidden_states is None:
|
| 274 |
+
encoder_hidden_states = hidden_states
|
| 275 |
+
elif attn.norm_cross:
|
| 276 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 277 |
+
|
| 278 |
+
key = attn.to_k(encoder_hidden_states)
|
| 279 |
+
value = attn.to_v(encoder_hidden_states)
|
| 280 |
+
|
| 281 |
+
query = attn.head_to_batch_dim(query)
|
| 282 |
+
key = attn.head_to_batch_dim(key)
|
| 283 |
+
value = attn.head_to_batch_dim(value)
|
| 284 |
+
|
| 285 |
+
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
| 286 |
+
hidden_states = torch.bmm(attention_probs, value)
|
| 287 |
+
hidden_states = attn.batch_to_head_dim(hidden_states)
|
| 288 |
+
|
| 289 |
+
if ip_adapter_masks is not None:
|
| 290 |
+
if not isinstance(ip_adapter_masks, List):
|
| 291 |
+
# for backward compatibility, we accept `ip_adapter_mask` as a tensor of shape [num_ip_adapter, 1, height, width]
|
| 292 |
+
ip_adapter_masks = list(ip_adapter_masks.unsqueeze(1))
|
| 293 |
+
if not (len(ip_adapter_masks) == len(self.scale) == len(ip_hidden_states)):
|
| 294 |
+
raise ValueError(
|
| 295 |
+
f"Length of ip_adapter_masks array ({len(ip_adapter_masks)}) must match "
|
| 296 |
+
f"length of self.scale array ({len(self.scale)}) and number of ip_hidden_states "
|
| 297 |
+
f"({len(ip_hidden_states)})"
|
| 298 |
+
)
|
| 299 |
+
else:
|
| 300 |
+
for index, (mask, scale, ip_state) in enumerate(zip(ip_adapter_masks, self.scale, ip_hidden_states)):
|
| 301 |
+
if not isinstance(mask, torch.Tensor) or mask.ndim != 4:
|
| 302 |
+
raise ValueError(
|
| 303 |
+
"Each element of the ip_adapter_masks array should be a tensor with shape "
|
| 304 |
+
"[1, num_images_for_ip_adapter, height, width]."
|
| 305 |
+
" Please use `IPAdapterMaskProcessor` to preprocess your mask"
|
| 306 |
+
)
|
| 307 |
+
if mask.shape[1] != ip_state.shape[1]:
|
| 308 |
+
raise ValueError(
|
| 309 |
+
f"Number of masks ({mask.shape[1]}) does not match "
|
| 310 |
+
f"number of ip images ({ip_state.shape[1]}) at index {index}"
|
| 311 |
+
)
|
| 312 |
+
if isinstance(scale, list) and not len(scale) == mask.shape[1]:
|
| 313 |
+
raise ValueError(
|
| 314 |
+
f"Number of masks ({mask.shape[1]}) does not match "
|
| 315 |
+
f"number of scales ({len(scale)}) at index {index}"
|
| 316 |
+
)
|
| 317 |
+
else:
|
| 318 |
+
ip_adapter_masks = [None] * len(self.scale)
|
| 319 |
+
|
| 320 |
+
# for ip-adapter
|
| 321 |
+
for current_ip_hidden_states, scale, to_k_ip, to_v_ip, mask in zip(
|
| 322 |
+
ip_hidden_states, self.scale, self.to_k_ip, self.to_v_ip, ip_adapter_masks
|
| 323 |
+
):
|
| 324 |
+
skip = False
|
| 325 |
+
if isinstance(scale, list):
|
| 326 |
+
if all(s == 0 for s in scale):
|
| 327 |
+
skip = True
|
| 328 |
+
elif scale == 0:
|
| 329 |
+
skip = True
|
| 330 |
+
if not skip:
|
| 331 |
+
if mask is not None:
|
| 332 |
+
if not isinstance(scale, list):
|
| 333 |
+
scale = [scale] * mask.shape[1]
|
| 334 |
+
|
| 335 |
+
current_num_images = mask.shape[1]
|
| 336 |
+
for i in range(current_num_images):
|
| 337 |
+
ip_key = to_k_ip(current_ip_hidden_states[:, i, :, :])
|
| 338 |
+
ip_value = to_v_ip(current_ip_hidden_states[:, i, :, :])
|
| 339 |
+
|
| 340 |
+
ip_key = attn.head_to_batch_dim(ip_key)
|
| 341 |
+
ip_value = attn.head_to_batch_dim(ip_value)
|
| 342 |
+
|
| 343 |
+
ip_attention_probs = attn.get_attention_scores(query, ip_key, None)
|
| 344 |
+
_current_ip_hidden_states = torch.bmm(ip_attention_probs, ip_value)
|
| 345 |
+
_current_ip_hidden_states = attn.batch_to_head_dim(_current_ip_hidden_states)
|
| 346 |
+
|
| 347 |
+
mask_downsample = IPAdapterMaskProcessor.downsample(
|
| 348 |
+
mask[:, i, :, :],
|
| 349 |
+
batch_size,
|
| 350 |
+
_current_ip_hidden_states.shape[1],
|
| 351 |
+
_current_ip_hidden_states.shape[2],
|
| 352 |
+
)
|
| 353 |
+
|
| 354 |
+
mask_downsample = mask_downsample.to(dtype=query.dtype, device=query.device)
|
| 355 |
+
|
| 356 |
+
hidden_states = hidden_states + scale[i] * (_current_ip_hidden_states * mask_downsample)
|
| 357 |
+
else:
|
| 358 |
+
ip_key = to_k_ip(current_ip_hidden_states)
|
| 359 |
+
ip_value = to_v_ip(current_ip_hidden_states)
|
| 360 |
+
|
| 361 |
+
ip_key = attn.head_to_batch_dim(ip_key)
|
| 362 |
+
ip_value = attn.head_to_batch_dim(ip_value)
|
| 363 |
+
|
| 364 |
+
ip_attention_probs = attn.get_attention_scores(query, ip_key, None)
|
| 365 |
+
current_ip_hidden_states = torch.bmm(ip_attention_probs, ip_value)
|
| 366 |
+
current_ip_hidden_states = attn.batch_to_head_dim(current_ip_hidden_states)
|
| 367 |
+
|
| 368 |
+
hidden_states = hidden_states + scale * current_ip_hidden_states
|
| 369 |
+
|
| 370 |
+
# linear proj
|
| 371 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 372 |
+
# dropout
|
| 373 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 374 |
+
|
| 375 |
+
if input_ndim == 4:
|
| 376 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 377 |
+
|
| 378 |
+
if attn.residual_connection:
|
| 379 |
+
hidden_states = hidden_states + residual
|
| 380 |
+
|
| 381 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 382 |
+
|
| 383 |
+
return hidden_states
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
class IPAdapterAttnProcessor2_0(torch.nn.Module):
|
| 387 |
+
r"""
|
| 388 |
+
Attention processor for IP-Adapter for PyTorch 2.0.
|
| 389 |
+
|
| 390 |
+
Args:
|
| 391 |
+
hidden_size (`int`):
|
| 392 |
+
The hidden size of the attention layer.
|
| 393 |
+
cross_attention_dim (`int`):
|
| 394 |
+
The number of channels in the `encoder_hidden_states`.
|
| 395 |
+
num_tokens (`int`, `Tuple[int]` or `List[int]`, defaults to `(4,)`):
|
| 396 |
+
The context length of the image features.
|
| 397 |
+
scale (`float` or `List[float]`, defaults to 1.0):
|
| 398 |
+
the weight scale of image prompt.
|
| 399 |
+
"""
|
| 400 |
+
|
| 401 |
+
def __init__(self, hidden_size, cross_attention_dim=None, num_tokens=(4,), scale=1.0):
|
| 402 |
+
super().__init__()
|
| 403 |
+
|
| 404 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 405 |
+
raise ImportError(
|
| 406 |
+
f"{self.__class__.__name__} requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0."
|
| 407 |
+
)
|
| 408 |
+
|
| 409 |
+
self.hidden_size = hidden_size
|
| 410 |
+
self.cross_attention_dim = cross_attention_dim
|
| 411 |
+
|
| 412 |
+
if not isinstance(num_tokens, (tuple, list)):
|
| 413 |
+
num_tokens = [num_tokens]
|
| 414 |
+
self.num_tokens = num_tokens
|
| 415 |
+
|
| 416 |
+
if not isinstance(scale, list):
|
| 417 |
+
scale = [scale] * len(num_tokens)
|
| 418 |
+
if len(scale) != len(num_tokens):
|
| 419 |
+
raise ValueError("`scale` should be a list of integers with the same length as `num_tokens`.")
|
| 420 |
+
self.scale = scale
|
| 421 |
+
|
| 422 |
+
self.to_k_ip = nn.ModuleList(
|
| 423 |
+
[nn.Linear(cross_attention_dim, hidden_size, bias=False) for _ in range(len(num_tokens))]
|
| 424 |
+
)
|
| 425 |
+
self.to_v_ip = nn.ModuleList(
|
| 426 |
+
[nn.Linear(cross_attention_dim, hidden_size, bias=False) for _ in range(len(num_tokens))]
|
| 427 |
+
)
|
| 428 |
+
|
| 429 |
+
def __call__(
|
| 430 |
+
self,
|
| 431 |
+
attn: Attention,
|
| 432 |
+
hidden_states: torch.Tensor,
|
| 433 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 434 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 435 |
+
temb: Optional[torch.Tensor] = None,
|
| 436 |
+
scale: float = 1.0,
|
| 437 |
+
ip_adapter_masks: Optional[torch.Tensor] = None,
|
| 438 |
+
):
|
| 439 |
+
residual = hidden_states
|
| 440 |
+
|
| 441 |
+
# separate ip_hidden_states from encoder_hidden_states
|
| 442 |
+
if encoder_hidden_states is not None:
|
| 443 |
+
if isinstance(encoder_hidden_states, tuple):
|
| 444 |
+
encoder_hidden_states, ip_hidden_states = encoder_hidden_states
|
| 445 |
+
|
| 446 |
+
else:
|
| 447 |
+
deprecation_message = (
|
| 448 |
+
"You have passed a tensor as `encoder_hidden_states`. This is deprecated and will be removed in a future release."
|
| 449 |
+
" Please make sure to update your script to pass `encoder_hidden_states` as a tuple to suppress this warning."
|
| 450 |
+
)
|
| 451 |
+
deprecate("encoder_hidden_states not a tuple", "1.0.0", deprecation_message, standard_warn=False)
|
| 452 |
+
end_pos = encoder_hidden_states.shape[1] - self.num_tokens[0]
|
| 453 |
+
encoder_hidden_states, ip_hidden_states = (
|
| 454 |
+
encoder_hidden_states[:, :end_pos, :],
|
| 455 |
+
[encoder_hidden_states[:, end_pos:, :]],
|
| 456 |
+
)
|
| 457 |
+
|
| 458 |
+
if attn.spatial_norm is not None:
|
| 459 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 460 |
+
|
| 461 |
+
input_ndim = hidden_states.ndim
|
| 462 |
+
|
| 463 |
+
if input_ndim == 4:
|
| 464 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 465 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 466 |
+
|
| 467 |
+
batch_size, sequence_length, _ = (
|
| 468 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 469 |
+
)
|
| 470 |
+
|
| 471 |
+
if attention_mask is not None:
|
| 472 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 473 |
+
# scaled_dot_product_attention expects attention_mask shape to be
|
| 474 |
+
# (batch, heads, source_length, target_length)
|
| 475 |
+
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
| 476 |
+
|
| 477 |
+
if attn.group_norm is not None:
|
| 478 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 479 |
+
|
| 480 |
+
query = attn.to_q(hidden_states)
|
| 481 |
+
|
| 482 |
+
if encoder_hidden_states is None:
|
| 483 |
+
encoder_hidden_states = hidden_states
|
| 484 |
+
elif attn.norm_cross:
|
| 485 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 486 |
+
|
| 487 |
+
key = attn.to_k(encoder_hidden_states)
|
| 488 |
+
value = attn.to_v(encoder_hidden_states)
|
| 489 |
+
|
| 490 |
+
inner_dim = key.shape[-1]
|
| 491 |
+
head_dim = inner_dim // attn.heads
|
| 492 |
+
|
| 493 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 494 |
+
|
| 495 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 496 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 497 |
+
|
| 498 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 499 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 500 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 501 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 502 |
+
)
|
| 503 |
+
|
| 504 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 505 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 506 |
+
|
| 507 |
+
if ip_adapter_masks is not None:
|
| 508 |
+
if not isinstance(ip_adapter_masks, List):
|
| 509 |
+
# for backward compatibility, we accept `ip_adapter_mask` as a tensor of shape [num_ip_adapter, 1, height, width]
|
| 510 |
+
ip_adapter_masks = list(ip_adapter_masks.unsqueeze(1))
|
| 511 |
+
if not (len(ip_adapter_masks) == len(self.scale) == len(ip_hidden_states)):
|
| 512 |
+
raise ValueError(
|
| 513 |
+
f"Length of ip_adapter_masks array ({len(ip_adapter_masks)}) must match "
|
| 514 |
+
f"length of self.scale array ({len(self.scale)}) and number of ip_hidden_states "
|
| 515 |
+
f"({len(ip_hidden_states)})"
|
| 516 |
+
)
|
| 517 |
+
else:
|
| 518 |
+
for index, (mask, scale, ip_state) in enumerate(zip(ip_adapter_masks, self.scale, ip_hidden_states)):
|
| 519 |
+
ip_hidden_states[index] = ip_state = ip_state.unsqueeze(1)
|
| 520 |
+
if not isinstance(mask, torch.Tensor) or mask.ndim != 4:
|
| 521 |
+
raise ValueError(
|
| 522 |
+
"Each element of the ip_adapter_masks array should be a tensor with shape "
|
| 523 |
+
"[1, num_images_for_ip_adapter, height, width]."
|
| 524 |
+
" Please use `IPAdapterMaskProcessor` to preprocess your mask"
|
| 525 |
+
)
|
| 526 |
+
if mask.shape[1] != ip_state.shape[1]:
|
| 527 |
+
raise ValueError(
|
| 528 |
+
f"Number of masks ({mask.shape[1]}) does not match "
|
| 529 |
+
f"number of ip images ({ip_state.shape[1]}) at index {index}"
|
| 530 |
+
)
|
| 531 |
+
if isinstance(scale, list) and not len(scale) == mask.shape[1]:
|
| 532 |
+
raise ValueError(
|
| 533 |
+
f"Number of masks ({mask.shape[1]}) does not match "
|
| 534 |
+
f"number of scales ({len(scale)}) at index {index}"
|
| 535 |
+
)
|
| 536 |
+
else:
|
| 537 |
+
ip_adapter_masks = [None] * len(self.scale)
|
| 538 |
+
|
| 539 |
+
# for ip-adapter
|
| 540 |
+
for current_ip_hidden_states, scale, to_k_ip, to_v_ip, mask in zip(
|
| 541 |
+
ip_hidden_states, self.scale, self.to_k_ip, self.to_v_ip, ip_adapter_masks
|
| 542 |
+
):
|
| 543 |
+
skip = False
|
| 544 |
+
if isinstance(scale, list):
|
| 545 |
+
if all(s == 0 for s in scale):
|
| 546 |
+
skip = True
|
| 547 |
+
elif scale == 0:
|
| 548 |
+
skip = True
|
| 549 |
+
if not skip:
|
| 550 |
+
if mask is not None:
|
| 551 |
+
if not isinstance(scale, list):
|
| 552 |
+
scale = [scale] * mask.shape[1]
|
| 553 |
+
|
| 554 |
+
current_num_images = mask.shape[1]
|
| 555 |
+
for i in range(current_num_images):
|
| 556 |
+
ip_key = to_k_ip(current_ip_hidden_states[:, i, :, :])
|
| 557 |
+
ip_value = to_v_ip(current_ip_hidden_states[:, i, :, :])
|
| 558 |
+
|
| 559 |
+
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 560 |
+
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 561 |
+
|
| 562 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 563 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 564 |
+
_current_ip_hidden_states = F.scaled_dot_product_attention(
|
| 565 |
+
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
|
| 566 |
+
)
|
| 567 |
+
|
| 568 |
+
_current_ip_hidden_states = _current_ip_hidden_states.transpose(1, 2).reshape(
|
| 569 |
+
batch_size, -1, attn.heads * head_dim
|
| 570 |
+
)
|
| 571 |
+
_current_ip_hidden_states = _current_ip_hidden_states.to(query.dtype)
|
| 572 |
+
|
| 573 |
+
mask_downsample = IPAdapterMaskProcessor.downsample(
|
| 574 |
+
mask[:, i, :, :],
|
| 575 |
+
batch_size,
|
| 576 |
+
_current_ip_hidden_states.shape[1],
|
| 577 |
+
_current_ip_hidden_states.shape[2],
|
| 578 |
+
)
|
| 579 |
+
mask_downsample = mask_downsample.to(dtype=query.dtype, device=query.device)
|
| 580 |
+
hidden_states = hidden_states + scale[i] * (_current_ip_hidden_states * mask_downsample)
|
| 581 |
+
|
| 582 |
+
else:
|
| 583 |
+
ip_key = to_k_ip(current_ip_hidden_states)
|
| 584 |
+
ip_value = to_v_ip(current_ip_hidden_states)
|
| 585 |
+
|
| 586 |
+
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 587 |
+
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 588 |
+
|
| 589 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 590 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 591 |
+
current_ip_hidden_states = F.scaled_dot_product_attention(
|
| 592 |
+
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
|
| 593 |
+
)
|
| 594 |
+
|
| 595 |
+
current_ip_hidden_states = current_ip_hidden_states.transpose(1, 2).reshape(
|
| 596 |
+
batch_size, -1, attn.heads * head_dim
|
| 597 |
+
)
|
| 598 |
+
current_ip_hidden_states = current_ip_hidden_states.to(query.dtype)
|
| 599 |
+
|
| 600 |
+
hidden_states = hidden_states + scale * current_ip_hidden_states
|
| 601 |
+
|
| 602 |
+
|
| 603 |
+
# linear proj
|
| 604 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 605 |
+
# dropout
|
| 606 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 607 |
+
|
| 608 |
+
if input_ndim == 4:
|
| 609 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 610 |
+
|
| 611 |
+
if attn.residual_connection:
|
| 612 |
+
hidden_states = hidden_states + residual
|
| 613 |
+
|
| 614 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 615 |
+
|
| 616 |
+
return hidden_states
|
src/models/svfr_adapter/unet_3d_blocks.py
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
src/models/svfr_adapter/unet_3d_svd_condition_ip.py
ADDED
|
@@ -0,0 +1,536 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from typing import Dict, Optional, Tuple, Union, Any
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 9 |
+
from diffusers.loaders import UNet2DConditionLoadersMixin
|
| 10 |
+
from diffusers.utils import BaseOutput, logging
|
| 11 |
+
from diffusers.models.attention_processor import CROSS_ATTENTION_PROCESSORS, AttentionProcessor
|
| 12 |
+
|
| 13 |
+
from diffusers.models.embeddings import TimestepEmbedding, Timesteps
|
| 14 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 15 |
+
from src.models.svfr_adapter.unet_3d_blocks import UNetMidBlockSpatioTemporal, get_down_block, get_up_block
|
| 16 |
+
from src.models.svfr_adapter.attention_processor import AttnProcessor2_0, AttnProcessor, IPAdapterAttnProcessor2_0, IPAdapterAttnProcessor
|
| 17 |
+
|
| 18 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 19 |
+
|
| 20 |
+
@dataclass
|
| 21 |
+
class UNet3DConditionSVDOutput(BaseOutput):
|
| 22 |
+
"""
|
| 23 |
+
The output of [`UNet3DConditionSVDModel`].
|
| 24 |
+
|
| 25 |
+
Args:
|
| 26 |
+
sample (`torch.FloatTensor` of shape `(batch_size, num_frames, num_channels, height, width)`):
|
| 27 |
+
The hidden states output conditioned on `encoder_hidden_states` input. Output of last layer of model.
|
| 28 |
+
"""
|
| 29 |
+
|
| 30 |
+
sample: torch.FloatTensor = None
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class UNet3DConditionSVDModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin):
|
| 34 |
+
r"""
|
| 35 |
+
A conditional Spatio-Temporal UNet model that takes a noisy video frames, conditional state, and a timestep and returns a sample
|
| 36 |
+
shaped output.
|
| 37 |
+
|
| 38 |
+
This model inherits from [`ModelMixin`]. Check the superclass documentation for it's generic methods implemented
|
| 39 |
+
for all models (such as downloading or saving).
|
| 40 |
+
|
| 41 |
+
Parameters:
|
| 42 |
+
sample_size (`int` or `Tuple[int, int]`, *optional*, defaults to `None`):
|
| 43 |
+
Height and width of input/output sample.
|
| 44 |
+
in_channels (`int`, *optional*, defaults to 8): Number of channels in the input sample.
|
| 45 |
+
out_channels (`int`, *optional*, defaults to 4): Number of channels in the output.
|
| 46 |
+
down_block_types (`Tuple[str]`, *optional*, defaults to `("CrossAttnDownBlockSpatioTemporal", "CrossAttnDownBlockSpatioTemporal", "CrossAttnDownBlockSpatioTemporal", "DownBlockSpatioTemporal")`):
|
| 47 |
+
The tuple of downsample blocks to use.
|
| 48 |
+
up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlockSpatioTemporal", "CrossAttnUpBlockSpatioTemporal", "CrossAttnUpBlockSpatioTemporal", "CrossAttnUpBlockSpatioTemporal")`):
|
| 49 |
+
The tuple of upsample blocks to use.
|
| 50 |
+
block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
|
| 51 |
+
The tuple of output channels for each block.
|
| 52 |
+
addition_time_embed_dim: (`int`, defaults to 256):
|
| 53 |
+
Dimension to to encode the additional time ids.
|
| 54 |
+
projection_class_embeddings_input_dim (`int`, defaults to 768):
|
| 55 |
+
The dimension of the projection of encoded `added_time_ids`.
|
| 56 |
+
layers_per_block (`int`, *optional*, defaults to 2): The number of layers per block.
|
| 57 |
+
cross_attention_dim (`int` or `Tuple[int]`, *optional*, defaults to 1280):
|
| 58 |
+
The dimension of the cross attention features.
|
| 59 |
+
transformer_layers_per_block (`int`, `Tuple[int]`, or `Tuple[Tuple]` , *optional*, defaults to 1):
|
| 60 |
+
The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`]. Only relevant for
|
| 61 |
+
[`~models.unet_3d_blocks.CrossAttnDownBlockSpatioTemporal`], [`~models.unet_3d_blocks.CrossAttnUpBlockSpatioTemporal`],
|
| 62 |
+
[`~models.unet_3d_blocks.UNetMidBlockSpatioTemporal`].
|
| 63 |
+
num_attention_heads (`int`, `Tuple[int]`, defaults to `(5, 10, 10, 20)`):
|
| 64 |
+
The number of attention heads.
|
| 65 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 66 |
+
"""
|
| 67 |
+
|
| 68 |
+
_supports_gradient_checkpointing = True
|
| 69 |
+
|
| 70 |
+
@register_to_config
|
| 71 |
+
def __init__(
|
| 72 |
+
self,
|
| 73 |
+
sample_size: Optional[int] = None,
|
| 74 |
+
in_channels: int = 8,
|
| 75 |
+
out_channels: int = 4,
|
| 76 |
+
down_block_types: Tuple[str] = (
|
| 77 |
+
"CrossAttnDownBlockSpatioTemporal",
|
| 78 |
+
"CrossAttnDownBlockSpatioTemporal",
|
| 79 |
+
"CrossAttnDownBlockSpatioTemporal",
|
| 80 |
+
"DownBlockSpatioTemporal",
|
| 81 |
+
),
|
| 82 |
+
up_block_types: Tuple[str] = (
|
| 83 |
+
"UpBlockSpatioTemporal",
|
| 84 |
+
"CrossAttnUpBlockSpatioTemporal",
|
| 85 |
+
"CrossAttnUpBlockSpatioTemporal",
|
| 86 |
+
"CrossAttnUpBlockSpatioTemporal",
|
| 87 |
+
),
|
| 88 |
+
block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
|
| 89 |
+
addition_time_embed_dim: int = 256,
|
| 90 |
+
projection_class_embeddings_input_dim: int = 768,
|
| 91 |
+
layers_per_block: Union[int, Tuple[int]] = 2,
|
| 92 |
+
cross_attention_dim: Union[int, Tuple[int]] = 1024,
|
| 93 |
+
transformer_layers_per_block: Union[int, Tuple[int], Tuple[Tuple]] = 1,
|
| 94 |
+
num_attention_heads: Union[int, Tuple[int]] = (5, 10, 10, 20),
|
| 95 |
+
num_frames: int = 25,
|
| 96 |
+
):
|
| 97 |
+
super().__init__()
|
| 98 |
+
|
| 99 |
+
self.sample_size = sample_size
|
| 100 |
+
|
| 101 |
+
# Check inputs
|
| 102 |
+
if len(down_block_types) != len(up_block_types):
|
| 103 |
+
raise ValueError(
|
| 104 |
+
f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
|
| 105 |
+
)
|
| 106 |
+
|
| 107 |
+
if len(block_out_channels) != len(down_block_types):
|
| 108 |
+
raise ValueError(
|
| 109 |
+
f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
|
| 113 |
+
raise ValueError(
|
| 114 |
+
f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
|
| 115 |
+
)
|
| 116 |
+
|
| 117 |
+
if isinstance(cross_attention_dim, list) and len(cross_attention_dim) != len(down_block_types):
|
| 118 |
+
raise ValueError(
|
| 119 |
+
f"Must provide the same number of `cross_attention_dim` as `down_block_types`. `cross_attention_dim`: {cross_attention_dim}. `down_block_types`: {down_block_types}."
|
| 120 |
+
)
|
| 121 |
+
|
| 122 |
+
if not isinstance(layers_per_block, int) and len(layers_per_block) != len(down_block_types):
|
| 123 |
+
raise ValueError(
|
| 124 |
+
f"Must provide the same number of `layers_per_block` as `down_block_types`. `layers_per_block`: {layers_per_block}. `down_block_types`: {down_block_types}."
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
# input
|
| 128 |
+
self.conv_in = nn.Conv2d(
|
| 129 |
+
in_channels,
|
| 130 |
+
block_out_channels[0],
|
| 131 |
+
kernel_size=3,
|
| 132 |
+
padding=1,
|
| 133 |
+
)
|
| 134 |
+
|
| 135 |
+
# time
|
| 136 |
+
time_embed_dim = block_out_channels[0] * 4
|
| 137 |
+
|
| 138 |
+
self.time_proj = Timesteps(block_out_channels[0], True, downscale_freq_shift=0)
|
| 139 |
+
timestep_input_dim = block_out_channels[0]
|
| 140 |
+
|
| 141 |
+
self.time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
|
| 142 |
+
|
| 143 |
+
self.add_time_proj = Timesteps(addition_time_embed_dim, True, downscale_freq_shift=0)
|
| 144 |
+
self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
|
| 145 |
+
|
| 146 |
+
self.down_blocks = nn.ModuleList([])
|
| 147 |
+
self.up_blocks = nn.ModuleList([])
|
| 148 |
+
|
| 149 |
+
if isinstance(num_attention_heads, int):
|
| 150 |
+
num_attention_heads = (num_attention_heads,) * len(down_block_types)
|
| 151 |
+
|
| 152 |
+
if isinstance(cross_attention_dim, int):
|
| 153 |
+
cross_attention_dim = (cross_attention_dim,) * len(down_block_types)
|
| 154 |
+
|
| 155 |
+
if isinstance(layers_per_block, int):
|
| 156 |
+
layers_per_block = [layers_per_block] * len(down_block_types)
|
| 157 |
+
|
| 158 |
+
if isinstance(transformer_layers_per_block, int):
|
| 159 |
+
transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
|
| 160 |
+
|
| 161 |
+
blocks_time_embed_dim = time_embed_dim
|
| 162 |
+
|
| 163 |
+
# down
|
| 164 |
+
output_channel = block_out_channels[0]
|
| 165 |
+
for i, down_block_type in enumerate(down_block_types):
|
| 166 |
+
input_channel = output_channel
|
| 167 |
+
output_channel = block_out_channels[i]
|
| 168 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 169 |
+
|
| 170 |
+
down_block = get_down_block(
|
| 171 |
+
down_block_type,
|
| 172 |
+
num_layers=layers_per_block[i],
|
| 173 |
+
transformer_layers_per_block=transformer_layers_per_block[i],
|
| 174 |
+
in_channels=input_channel,
|
| 175 |
+
out_channels=output_channel,
|
| 176 |
+
temb_channels=blocks_time_embed_dim,
|
| 177 |
+
add_downsample=not is_final_block,
|
| 178 |
+
resnet_eps=1e-5,
|
| 179 |
+
cross_attention_dim=cross_attention_dim[i],
|
| 180 |
+
num_attention_heads=num_attention_heads[i],
|
| 181 |
+
resnet_act_fn="silu",
|
| 182 |
+
)
|
| 183 |
+
self.down_blocks.append(down_block)
|
| 184 |
+
|
| 185 |
+
# mid
|
| 186 |
+
self.mid_block = UNetMidBlockSpatioTemporal(
|
| 187 |
+
block_out_channels[-1],
|
| 188 |
+
temb_channels=blocks_time_embed_dim,
|
| 189 |
+
transformer_layers_per_block=transformer_layers_per_block[-1],
|
| 190 |
+
cross_attention_dim=cross_attention_dim[-1],
|
| 191 |
+
num_attention_heads=num_attention_heads[-1],
|
| 192 |
+
)
|
| 193 |
+
|
| 194 |
+
# count how many layers upsample the images
|
| 195 |
+
self.num_upsamplers = 0
|
| 196 |
+
|
| 197 |
+
# up
|
| 198 |
+
reversed_block_out_channels = list(reversed(block_out_channels))
|
| 199 |
+
reversed_num_attention_heads = list(reversed(num_attention_heads))
|
| 200 |
+
reversed_layers_per_block = list(reversed(layers_per_block))
|
| 201 |
+
reversed_cross_attention_dim = list(reversed(cross_attention_dim))
|
| 202 |
+
reversed_transformer_layers_per_block = list(reversed(transformer_layers_per_block))
|
| 203 |
+
|
| 204 |
+
output_channel = reversed_block_out_channels[0]
|
| 205 |
+
for i, up_block_type in enumerate(up_block_types):
|
| 206 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 207 |
+
|
| 208 |
+
prev_output_channel = output_channel
|
| 209 |
+
output_channel = reversed_block_out_channels[i]
|
| 210 |
+
input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
|
| 211 |
+
|
| 212 |
+
# add upsample block for all BUT final layer
|
| 213 |
+
if not is_final_block:
|
| 214 |
+
add_upsample = True
|
| 215 |
+
self.num_upsamplers += 1
|
| 216 |
+
else:
|
| 217 |
+
add_upsample = False
|
| 218 |
+
|
| 219 |
+
up_block = get_up_block(
|
| 220 |
+
up_block_type,
|
| 221 |
+
num_layers=reversed_layers_per_block[i] + 1,
|
| 222 |
+
transformer_layers_per_block=reversed_transformer_layers_per_block[i],
|
| 223 |
+
in_channels=input_channel,
|
| 224 |
+
out_channels=output_channel,
|
| 225 |
+
prev_output_channel=prev_output_channel,
|
| 226 |
+
temb_channels=blocks_time_embed_dim,
|
| 227 |
+
add_upsample=add_upsample,
|
| 228 |
+
resnet_eps=1e-5,
|
| 229 |
+
resolution_idx=i,
|
| 230 |
+
cross_attention_dim=reversed_cross_attention_dim[i],
|
| 231 |
+
num_attention_heads=reversed_num_attention_heads[i],
|
| 232 |
+
resnet_act_fn="silu",
|
| 233 |
+
)
|
| 234 |
+
self.up_blocks.append(up_block)
|
| 235 |
+
prev_output_channel = output_channel
|
| 236 |
+
|
| 237 |
+
# out
|
| 238 |
+
self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=32, eps=1e-5)
|
| 239 |
+
self.conv_act = nn.SiLU()
|
| 240 |
+
|
| 241 |
+
self.conv_out = nn.Conv2d(
|
| 242 |
+
block_out_channels[0],
|
| 243 |
+
out_channels,
|
| 244 |
+
kernel_size=3,
|
| 245 |
+
padding=1,
|
| 246 |
+
)
|
| 247 |
+
|
| 248 |
+
@property
|
| 249 |
+
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
| 250 |
+
r"""
|
| 251 |
+
Returns:
|
| 252 |
+
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
| 253 |
+
indexed by its weight name.
|
| 254 |
+
"""
|
| 255 |
+
# set recursively
|
| 256 |
+
processors = {}
|
| 257 |
+
|
| 258 |
+
def fn_recursive_add_processors(
|
| 259 |
+
name: str,
|
| 260 |
+
module: torch.nn.Module,
|
| 261 |
+
processors: Dict[str, AttentionProcessor],
|
| 262 |
+
):
|
| 263 |
+
if hasattr(module, "get_processor"):
|
| 264 |
+
processors[f"{name}.processor"] = module.get_processor(return_deprecated_lora=True)
|
| 265 |
+
|
| 266 |
+
for sub_name, child in module.named_children():
|
| 267 |
+
fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
|
| 268 |
+
|
| 269 |
+
return processors
|
| 270 |
+
|
| 271 |
+
for name, module in self.named_children():
|
| 272 |
+
fn_recursive_add_processors(name, module, processors)
|
| 273 |
+
|
| 274 |
+
return processors
|
| 275 |
+
|
| 276 |
+
def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
|
| 277 |
+
r"""
|
| 278 |
+
Sets the attention processor to use to compute attention.
|
| 279 |
+
|
| 280 |
+
Parameters:
|
| 281 |
+
processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
|
| 282 |
+
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
| 283 |
+
for **all** `Attention` layers.
|
| 284 |
+
|
| 285 |
+
If `processor` is a dict, the key needs to define the path to the corresponding cross attention
|
| 286 |
+
processor. This is strongly recommended when setting trainable attention processors.
|
| 287 |
+
|
| 288 |
+
"""
|
| 289 |
+
count = len(self.attn_processors.keys())
|
| 290 |
+
|
| 291 |
+
if isinstance(processor, dict) and len(processor) != count:
|
| 292 |
+
raise ValueError(
|
| 293 |
+
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
|
| 294 |
+
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
|
| 295 |
+
)
|
| 296 |
+
|
| 297 |
+
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
|
| 298 |
+
if hasattr(module, "set_processor"):
|
| 299 |
+
if not isinstance(processor, dict):
|
| 300 |
+
module.set_processor(processor)
|
| 301 |
+
else:
|
| 302 |
+
module.set_processor(processor.pop(f"{name}.processor"))
|
| 303 |
+
|
| 304 |
+
for sub_name, child in module.named_children():
|
| 305 |
+
fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
|
| 306 |
+
|
| 307 |
+
for name, module in self.named_children():
|
| 308 |
+
fn_recursive_attn_processor(name, module, processor)
|
| 309 |
+
|
| 310 |
+
def set_default_attn_processor(self):
|
| 311 |
+
"""
|
| 312 |
+
Disables custom attention processors and sets the default attention implementation.
|
| 313 |
+
"""
|
| 314 |
+
if all(proc.__class__ in CROSS_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 315 |
+
processor = AttnProcessor()
|
| 316 |
+
else:
|
| 317 |
+
raise ValueError(
|
| 318 |
+
f"Cannot call `set_default_attn_processor` when attention processors are of type {next(iter(self.attn_processors.values()))}"
|
| 319 |
+
)
|
| 320 |
+
|
| 321 |
+
self.set_attn_processor(processor)
|
| 322 |
+
|
| 323 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 324 |
+
if hasattr(module, "gradient_checkpointing"):
|
| 325 |
+
module.gradient_checkpointing = value
|
| 326 |
+
|
| 327 |
+
# Copied from diffusers.models.unet_3d_condition.UNet3DConditionModel.enable_forward_chunking
|
| 328 |
+
def enable_forward_chunking(self, chunk_size: Optional[int] = None, dim: int = 0) -> None:
|
| 329 |
+
"""
|
| 330 |
+
Sets the attention processor to use [feed forward
|
| 331 |
+
chunking](https://huggingface.co/blog/reformer#2-chunked-feed-forward-layers).
|
| 332 |
+
|
| 333 |
+
Parameters:
|
| 334 |
+
chunk_size (`int`, *optional*):
|
| 335 |
+
The chunk size of the feed-forward layers. If not specified, will run feed-forward layer individually
|
| 336 |
+
over each tensor of dim=`dim`.
|
| 337 |
+
dim (`int`, *optional*, defaults to `0`):
|
| 338 |
+
The dimension over which the feed-forward computation should be chunked. Choose between dim=0 (batch)
|
| 339 |
+
or dim=1 (sequence length).
|
| 340 |
+
"""
|
| 341 |
+
if dim not in [0, 1]:
|
| 342 |
+
raise ValueError(f"Make sure to set `dim` to either 0 or 1, not {dim}")
|
| 343 |
+
|
| 344 |
+
# By default chunk size is 1
|
| 345 |
+
chunk_size = chunk_size or 1
|
| 346 |
+
|
| 347 |
+
def fn_recursive_feed_forward(module: torch.nn.Module, chunk_size: int, dim: int):
|
| 348 |
+
if hasattr(module, "set_chunk_feed_forward"):
|
| 349 |
+
module.set_chunk_feed_forward(chunk_size=chunk_size, dim=dim)
|
| 350 |
+
|
| 351 |
+
for child in module.children():
|
| 352 |
+
fn_recursive_feed_forward(child, chunk_size, dim)
|
| 353 |
+
|
| 354 |
+
for module in self.children():
|
| 355 |
+
fn_recursive_feed_forward(module, chunk_size, dim)
|
| 356 |
+
|
| 357 |
+
def forward(
|
| 358 |
+
self,
|
| 359 |
+
sample: torch.FloatTensor,
|
| 360 |
+
timestep: Union[torch.Tensor, float, int],
|
| 361 |
+
encoder_hidden_states: torch.Tensor,
|
| 362 |
+
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
| 363 |
+
mid_block_additional_residual: Optional[torch.Tensor] = None,
|
| 364 |
+
return_dict: bool = True,
|
| 365 |
+
added_time_ids: torch.Tensor=None,
|
| 366 |
+
pose_cond_fea: Optional[torch.Tensor] = None,
|
| 367 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 368 |
+
) -> Union[UNet3DConditionSVDOutput, Tuple]:
|
| 369 |
+
r"""
|
| 370 |
+
The [`UNetSpatioTemporalConditionModel`] forward method.
|
| 371 |
+
|
| 372 |
+
Args:
|
| 373 |
+
sample (`torch.FloatTensor`):
|
| 374 |
+
The noisy input tensor with the following shape `(batch, num_frames, channel, height, width)`.
|
| 375 |
+
timestep (`torch.FloatTensor` or `float` or `int`): The number of timesteps to denoise an input.
|
| 376 |
+
encoder_hidden_states (`torch.FloatTensor`):
|
| 377 |
+
The encoder hidden states with shape `(batch, sequence_length, cross_attention_dim)`.
|
| 378 |
+
added_time_ids: (`torch.FloatTensor`):
|
| 379 |
+
The additional time ids with shape `(batch, num_additional_ids)`. These are encoded with sinusoidal
|
| 380 |
+
embeddings and added to the time embeddings.
|
| 381 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 382 |
+
Whether or not to return a [`~models.unet_slatio_temporal.UNetSpatioTemporalConditionOutput`] instead of a plain
|
| 383 |
+
tuple.
|
| 384 |
+
Returns:
|
| 385 |
+
[`~models.unet_slatio_temporal.UNetSpatioTemporalConditionOutput`] or `tuple`:
|
| 386 |
+
If `return_dict` is True, an [`~models.unet_slatio_temporal.UNetSpatioTemporalConditionOutput`] is returned, otherwise
|
| 387 |
+
a `tuple` is returned where the first element is the sample tensor.
|
| 388 |
+
"""
|
| 389 |
+
# 1. time
|
| 390 |
+
timesteps = timestep
|
| 391 |
+
if not torch.is_tensor(timesteps):
|
| 392 |
+
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
| 393 |
+
# This would be a good case for the `match` statement (Python 3.10+)
|
| 394 |
+
is_mps = sample.device.type == "mps"
|
| 395 |
+
if isinstance(timestep, float):
|
| 396 |
+
dtype = torch.float32 if is_mps else torch.float64
|
| 397 |
+
else:
|
| 398 |
+
dtype = torch.int32 if is_mps else torch.int64
|
| 399 |
+
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
| 400 |
+
elif len(timesteps.shape) == 0:
|
| 401 |
+
timesteps = timesteps[None].to(sample.device)
|
| 402 |
+
|
| 403 |
+
batch_size, num_frames = sample.shape[:2]
|
| 404 |
+
timesteps = timesteps.expand(batch_size)
|
| 405 |
+
|
| 406 |
+
t_emb = self.time_proj(timesteps)
|
| 407 |
+
t_emb = t_emb.to(dtype=sample.dtype)
|
| 408 |
+
emb = self.time_embedding(t_emb)
|
| 409 |
+
|
| 410 |
+
time_embeds = self.add_time_proj(added_time_ids.flatten())
|
| 411 |
+
time_embeds = time_embeds.reshape((batch_size, -1))
|
| 412 |
+
time_embeds = time_embeds.to(emb.dtype)
|
| 413 |
+
aug_emb = self.add_embedding(time_embeds)
|
| 414 |
+
emb = emb + aug_emb
|
| 415 |
+
|
| 416 |
+
sample = sample.flatten(0, 1)
|
| 417 |
+
emb = emb.repeat_interleave(num_frames, dim=0)
|
| 418 |
+
|
| 419 |
+
# 2. pre-process
|
| 420 |
+
sample = self.conv_in(sample)
|
| 421 |
+
|
| 422 |
+
if pose_cond_fea is not None:
|
| 423 |
+
sample = sample + pose_cond_fea.flatten(0, 1)
|
| 424 |
+
|
| 425 |
+
image_only_indicator = torch.zeros(batch_size, num_frames, dtype=sample.dtype, device=sample.device)
|
| 426 |
+
|
| 427 |
+
down_block_res_samples = (sample,)
|
| 428 |
+
for downsample_block in self.down_blocks:
|
| 429 |
+
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
| 430 |
+
sample, res_samples = downsample_block(
|
| 431 |
+
hidden_states=sample,
|
| 432 |
+
temb=emb,
|
| 433 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 434 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 435 |
+
image_only_indicator=image_only_indicator,
|
| 436 |
+
)
|
| 437 |
+
else:
|
| 438 |
+
sample, res_samples = downsample_block(
|
| 439 |
+
hidden_states=sample,
|
| 440 |
+
temb=emb,
|
| 441 |
+
image_only_indicator=image_only_indicator,
|
| 442 |
+
)
|
| 443 |
+
|
| 444 |
+
down_block_res_samples += res_samples
|
| 445 |
+
|
| 446 |
+
|
| 447 |
+
# 4. mid
|
| 448 |
+
sample = self.mid_block(
|
| 449 |
+
hidden_states=sample,
|
| 450 |
+
temb=emb,
|
| 451 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 452 |
+
image_only_indicator=image_only_indicator,
|
| 453 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 454 |
+
|
| 455 |
+
)
|
| 456 |
+
|
| 457 |
+
|
| 458 |
+
# 5. up
|
| 459 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 460 |
+
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
| 461 |
+
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
| 462 |
+
|
| 463 |
+
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
|
| 464 |
+
sample = upsample_block(
|
| 465 |
+
hidden_states=sample,
|
| 466 |
+
temb=emb,
|
| 467 |
+
res_hidden_states_tuple=res_samples,
|
| 468 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 469 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 470 |
+
image_only_indicator=image_only_indicator,
|
| 471 |
+
)
|
| 472 |
+
else:
|
| 473 |
+
sample = upsample_block(
|
| 474 |
+
hidden_states=sample,
|
| 475 |
+
temb=emb,
|
| 476 |
+
res_hidden_states_tuple=res_samples,
|
| 477 |
+
image_only_indicator=image_only_indicator,
|
| 478 |
+
)
|
| 479 |
+
|
| 480 |
+
# 6. post-process
|
| 481 |
+
sample = self.conv_norm_out(sample)
|
| 482 |
+
sample = self.conv_act(sample)
|
| 483 |
+
sample = self.conv_out(sample)
|
| 484 |
+
|
| 485 |
+
# 7. Reshape back to original shape
|
| 486 |
+
sample = sample.reshape(batch_size, num_frames, *sample.shape[1:])
|
| 487 |
+
|
| 488 |
+
if not return_dict:
|
| 489 |
+
return (sample,)
|
| 490 |
+
|
| 491 |
+
return UNet3DConditionSVDOutput(sample=sample)
|
| 492 |
+
|
| 493 |
+
|
| 494 |
+
|
| 495 |
+
def init_ip_adapters(unet, num_adapter_embeds=[], scale=1.0):
|
| 496 |
+
# init adapter modules
|
| 497 |
+
attn_procs = {}
|
| 498 |
+
unet_sd = unet.state_dict()
|
| 499 |
+
for name in unet.attn_processors.keys():
|
| 500 |
+
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
|
| 501 |
+
if name.startswith("mid_block"):
|
| 502 |
+
hidden_size = unet.config.block_out_channels[-1]
|
| 503 |
+
elif name.startswith("up_blocks"):
|
| 504 |
+
block_id = int(name[len("up_blocks.")])
|
| 505 |
+
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
|
| 506 |
+
elif name.startswith("down_blocks"):
|
| 507 |
+
block_id = int(name[len("down_blocks.")])
|
| 508 |
+
hidden_size = unet.config.block_out_channels[block_id]
|
| 509 |
+
# if cross_attention_dim is None or "temporal_transformer_blocks" in name:
|
| 510 |
+
if cross_attention_dim is None:
|
| 511 |
+
attn_processor_class = (
|
| 512 |
+
AttnProcessor2_0 if hasattr(F, "scaled_dot_product_attention") else AttnProcessor
|
| 513 |
+
)
|
| 514 |
+
attn_procs[name] = attn_processor_class()
|
| 515 |
+
else:
|
| 516 |
+
attn_processor_class = (
|
| 517 |
+
IPAdapterAttnProcessor2_0 if hasattr(F, "scaled_dot_product_attention") else IPAdapterAttnProcessor
|
| 518 |
+
)
|
| 519 |
+
|
| 520 |
+
attn_procs[name] = attn_processor_class(
|
| 521 |
+
hidden_size=hidden_size,
|
| 522 |
+
cross_attention_dim=cross_attention_dim,
|
| 523 |
+
num_tokens=num_adapter_embeds,
|
| 524 |
+
scale=scale
|
| 525 |
+
)
|
| 526 |
+
|
| 527 |
+
layer_name = name.split(".processor")[0]
|
| 528 |
+
weights = {}
|
| 529 |
+
for i in range(len(num_adapter_embeds)):
|
| 530 |
+
weights.update({f"to_k_ip.{i}.weight": unet_sd[layer_name + ".to_k.weight"]})
|
| 531 |
+
weights.update({f"to_v_ip.{i}.weight": unet_sd[layer_name + ".to_v.weight"]})
|
| 532 |
+
|
| 533 |
+
attn_procs[name].load_state_dict(weights)
|
| 534 |
+
unet.set_attn_processor(attn_procs)
|
| 535 |
+
adapter_modules = torch.nn.ModuleList(unet.attn_processors.values())
|
| 536 |
+
return adapter_modules
|
src/pipelines/pipeline.py
ADDED
|
@@ -0,0 +1,812 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import inspect
|
| 2 |
+
from dataclasses import dataclass
|
| 3 |
+
from typing import Callable, Dict, List, Optional, Union
|
| 4 |
+
|
| 5 |
+
from einops import rearrange
|
| 6 |
+
import numpy as np
|
| 7 |
+
import PIL.Image
|
| 8 |
+
import torch
|
| 9 |
+
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
| 10 |
+
|
| 11 |
+
from diffusers.image_processor import VaeImageProcessor
|
| 12 |
+
# from diffusers.models import UNetSpatioTemporalConditionModel
|
| 13 |
+
from diffusers.utils import BaseOutput, logging
|
| 14 |
+
from diffusers.utils.torch_utils import randn_tensor, is_compiled_module
|
| 15 |
+
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
|
| 16 |
+
from diffusers import (
|
| 17 |
+
AutoencoderKLTemporalDecoder,
|
| 18 |
+
EulerDiscreteScheduler,
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
# from src.models.base.unet_spatio_temporal_condition import UNetSpatioTemporalConditionModel
|
| 22 |
+
from src.models.svfr_adapter.unet_3d_svd_condition_ip import UNet3DConditionSVDModel
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
logger = logging.get_logger(__name__)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def _append_dims(x, target_dims):
|
| 31 |
+
"""Appends dimensions to the end of a tensor until it has target_dims dimensions."""
|
| 32 |
+
dims_to_append = target_dims - x.ndim
|
| 33 |
+
if dims_to_append < 0:
|
| 34 |
+
raise ValueError(f"input has {x.ndim} dims but target_dims is {target_dims}, which is less")
|
| 35 |
+
return x[(...,) + (None,) * dims_to_append]
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def tensor2vid(video: torch.Tensor, processor: VaeImageProcessor, output_type: str = "np"):
|
| 39 |
+
batch_size, channels, num_frames, height, width = video.shape
|
| 40 |
+
outputs = []
|
| 41 |
+
for batch_idx in range(batch_size):
|
| 42 |
+
batch_vid = video[batch_idx].permute(1, 0, 2, 3)
|
| 43 |
+
batch_output = processor.postprocess(batch_vid, output_type)
|
| 44 |
+
|
| 45 |
+
outputs.append(batch_output)
|
| 46 |
+
|
| 47 |
+
if output_type == "np":
|
| 48 |
+
outputs = np.stack(outputs)
|
| 49 |
+
|
| 50 |
+
elif output_type == "pt":
|
| 51 |
+
outputs = torch.stack(outputs)
|
| 52 |
+
|
| 53 |
+
elif not output_type == "pil":
|
| 54 |
+
raise ValueError(f"{output_type} does not exist. Please choose one of ['np', 'pt', 'pil']")
|
| 55 |
+
|
| 56 |
+
return outputs
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
@dataclass
|
| 60 |
+
class LQ2VideoSVDPipelineOutput(BaseOutput):
|
| 61 |
+
r"""
|
| 62 |
+
Output class for zero-shot text-to-video pipeline.
|
| 63 |
+
|
| 64 |
+
Args:
|
| 65 |
+
frames (`[List[PIL.Image.Image]`, `np.ndarray`]):
|
| 66 |
+
List of denoised PIL images of length `batch_size` or NumPy array of shape `(batch_size, height, width,
|
| 67 |
+
num_channels)`.
|
| 68 |
+
"""
|
| 69 |
+
|
| 70 |
+
frames: Union[List[PIL.Image.Image], np.ndarray]
|
| 71 |
+
latents: Union[torch.Tensor, np.ndarray]
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
class LQ2VideoLongSVDPipeline(DiffusionPipeline):
|
| 75 |
+
r"""
|
| 76 |
+
Pipeline to generate video from an input image using Stable Video Diffusion.
|
| 77 |
+
|
| 78 |
+
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
|
| 79 |
+
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
|
| 80 |
+
|
| 81 |
+
Args:
|
| 82 |
+
vae ([`AutoencoderKL`]):
|
| 83 |
+
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
|
| 84 |
+
image_encoder ([`~transformers.CLIPVisionModelWithProjection`]):
|
| 85 |
+
Frozen CLIP image-encoder ([laion/CLIP-ViT-H-14-laion2B-s32B-b79K](https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K)).
|
| 86 |
+
unet ([`UNetSpatioTemporalConditionModel`]):
|
| 87 |
+
A `UNetSpatioTemporalConditionModel` to denoise the encoded image latents.
|
| 88 |
+
scheduler ([`EulerDiscreteScheduler`]):
|
| 89 |
+
A scheduler to be used in combination with `unet` to denoise the encoded image latents.
|
| 90 |
+
feature_extractor ([`~transformers.CLIPImageProcessor`]):
|
| 91 |
+
A `CLIPImageProcessor` to extract features from generated images.
|
| 92 |
+
"""
|
| 93 |
+
|
| 94 |
+
model_cpu_offload_seq = "image_encoder->unet->vae"
|
| 95 |
+
_callback_tensor_inputs = ["latents"]
|
| 96 |
+
|
| 97 |
+
def __init__(
|
| 98 |
+
self,
|
| 99 |
+
vae: AutoencoderKLTemporalDecoder,
|
| 100 |
+
image_encoder: CLIPVisionModelWithProjection,
|
| 101 |
+
unet: UNet3DConditionSVDModel,
|
| 102 |
+
scheduler: EulerDiscreteScheduler,
|
| 103 |
+
feature_extractor: CLIPImageProcessor,
|
| 104 |
+
):
|
| 105 |
+
super().__init__()
|
| 106 |
+
self.register_modules(
|
| 107 |
+
vae=vae,
|
| 108 |
+
image_encoder=image_encoder,
|
| 109 |
+
unet=unet,
|
| 110 |
+
scheduler=scheduler,
|
| 111 |
+
feature_extractor=feature_extractor,
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
|
| 115 |
+
|
| 116 |
+
# print("vae:", self.vae_scale_factor)
|
| 117 |
+
|
| 118 |
+
self.image_processor = VaeImageProcessor(
|
| 119 |
+
vae_scale_factor=self.vae_scale_factor,
|
| 120 |
+
do_convert_rgb=True)
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def _clip_encode_image(self, image, num_frames, device, num_videos_per_prompt, do_classifier_free_guidance):
|
| 124 |
+
dtype = next(self.image_encoder.parameters()).dtype
|
| 125 |
+
|
| 126 |
+
if not isinstance(image, torch.Tensor):
|
| 127 |
+
image = self.image_processor.pil_to_numpy(image)
|
| 128 |
+
image = self.image_processor.numpy_to_pt(image)
|
| 129 |
+
|
| 130 |
+
image = image * 2.0 - 1.0
|
| 131 |
+
image = _resize_with_antialiasing(image, (224, 224))
|
| 132 |
+
image = (image + 1.0) / 2.0
|
| 133 |
+
|
| 134 |
+
# Normalize the image with for CLIP input
|
| 135 |
+
image = self.feature_extractor(
|
| 136 |
+
images=image,
|
| 137 |
+
do_normalize=True,
|
| 138 |
+
do_center_crop=False,
|
| 139 |
+
do_resize=False,
|
| 140 |
+
do_rescale=False,
|
| 141 |
+
return_tensors="pt",
|
| 142 |
+
).pixel_values
|
| 143 |
+
|
| 144 |
+
image = image.to(device=device, dtype=dtype, non_blocking=True,).unsqueeze(0) # 3,224,224
|
| 145 |
+
image_embeddings = self.image_encoder(image).image_embeds
|
| 146 |
+
image_embeddings = image_embeddings.unsqueeze(1)
|
| 147 |
+
|
| 148 |
+
# duplicate image embeddings for each generation per prompt, using mps friendly method
|
| 149 |
+
bs_embed, seq_len, _ = image_embeddings.shape
|
| 150 |
+
image_embeddings = image_embeddings.repeat(1, num_videos_per_prompt, 1)
|
| 151 |
+
image_embeddings = image_embeddings.view(bs_embed * num_videos_per_prompt, seq_len, -1)
|
| 152 |
+
|
| 153 |
+
if do_classifier_free_guidance:
|
| 154 |
+
negative_image_embeddings = torch.zeros_like(image_embeddings)
|
| 155 |
+
image_embeddings = torch.cat([negative_image_embeddings, image_embeddings])
|
| 156 |
+
# image_embeddings = torch.cat([image_embeddings, image_embeddings])
|
| 157 |
+
|
| 158 |
+
return image_embeddings
|
| 159 |
+
|
| 160 |
+
def _encode_vae_image(
|
| 161 |
+
self,
|
| 162 |
+
image: torch.Tensor,
|
| 163 |
+
device,
|
| 164 |
+
num_videos_per_prompt,
|
| 165 |
+
do_classifier_free_guidance,
|
| 166 |
+
):
|
| 167 |
+
image = image.to(device=device)
|
| 168 |
+
image_latents = self.vae.encode(image).latent_dist.mode()
|
| 169 |
+
# image_latents = image_latents * 0.18215
|
| 170 |
+
image_latents = image_latents.unsqueeze(0)
|
| 171 |
+
|
| 172 |
+
if do_classifier_free_guidance:
|
| 173 |
+
negative_image_latents = torch.zeros_like(image_latents)
|
| 174 |
+
|
| 175 |
+
# For classifier free guidance, we need to do two forward passes.
|
| 176 |
+
# Here we concatenate the unconditional and text embeddings into a single batch
|
| 177 |
+
# to avoid doing two forward passes
|
| 178 |
+
# image_latents = torch.cat([negative_image_latents, image_latents])
|
| 179 |
+
image_latents = torch.cat([image_latents, image_latents])
|
| 180 |
+
|
| 181 |
+
# duplicate image_latents for each generation per prompt, using mps friendly method
|
| 182 |
+
image_latents = image_latents.repeat(num_videos_per_prompt, 1, 1, 1, 1)
|
| 183 |
+
|
| 184 |
+
return image_latents
|
| 185 |
+
|
| 186 |
+
def _get_add_time_ids(
|
| 187 |
+
self,
|
| 188 |
+
task_id_input,
|
| 189 |
+
dtype,
|
| 190 |
+
batch_size,
|
| 191 |
+
num_videos_per_prompt,
|
| 192 |
+
do_classifier_free_guidance,
|
| 193 |
+
):
|
| 194 |
+
|
| 195 |
+
passed_add_embed_dim = self.unet.config.addition_time_embed_dim * len(task_id_input)
|
| 196 |
+
expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
|
| 197 |
+
|
| 198 |
+
if expected_add_embed_dim != passed_add_embed_dim:
|
| 199 |
+
raise ValueError(
|
| 200 |
+
f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
|
| 201 |
+
)
|
| 202 |
+
|
| 203 |
+
# add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
|
| 204 |
+
# add_time_ids = add_time_ids.repeat(batch_size * num_videos_per_prompt, 1)
|
| 205 |
+
add_time_ids = task_id_input.to(dtype)
|
| 206 |
+
add_time_ids = add_time_ids.repeat(batch_size * num_videos_per_prompt, 1)
|
| 207 |
+
|
| 208 |
+
if do_classifier_free_guidance:
|
| 209 |
+
add_time_ids = torch.cat([add_time_ids, add_time_ids])
|
| 210 |
+
|
| 211 |
+
return add_time_ids
|
| 212 |
+
|
| 213 |
+
def decode_latents(self, latents, num_frames, decode_chunk_size=14):
|
| 214 |
+
# [batch, frames, channels, height, width] -> [batch*frames, channels, height, width]
|
| 215 |
+
latents = latents.flatten(0, 1)
|
| 216 |
+
|
| 217 |
+
latents = 1 / self.vae.config.scaling_factor * latents
|
| 218 |
+
|
| 219 |
+
forward_vae_fn = self.vae._orig_mod.forward if is_compiled_module(self.vae) else self.vae.forward
|
| 220 |
+
accepts_num_frames = "num_frames" in set(inspect.signature(forward_vae_fn).parameters.keys())
|
| 221 |
+
|
| 222 |
+
# decode decode_chunk_size frames at a time to avoid OOM
|
| 223 |
+
frames = []
|
| 224 |
+
for i in range(0, latents.shape[0], decode_chunk_size):
|
| 225 |
+
num_frames_in = latents[i : i + decode_chunk_size].shape[0]
|
| 226 |
+
decode_kwargs = {}
|
| 227 |
+
if accepts_num_frames:
|
| 228 |
+
# we only pass num_frames_in if it's expected
|
| 229 |
+
decode_kwargs["num_frames"] = num_frames_in
|
| 230 |
+
|
| 231 |
+
frame = self.vae.decode(latents[i : i + decode_chunk_size], **decode_kwargs).sample
|
| 232 |
+
frames.append(frame)
|
| 233 |
+
frames = torch.cat(frames, dim=0)
|
| 234 |
+
|
| 235 |
+
# [batch*frames, channels, height, width] -> [batch, channels, frames, height, width]
|
| 236 |
+
frames = frames.reshape(-1, num_frames, *frames.shape[1:]).permute(0, 2, 1, 3, 4)
|
| 237 |
+
|
| 238 |
+
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
|
| 239 |
+
frames = frames.float()
|
| 240 |
+
return frames
|
| 241 |
+
|
| 242 |
+
def check_inputs(self, image, height, width):
|
| 243 |
+
if (
|
| 244 |
+
not isinstance(image, torch.Tensor)
|
| 245 |
+
and not isinstance(image, PIL.Image.Image)
|
| 246 |
+
and not isinstance(image, list)
|
| 247 |
+
):
|
| 248 |
+
raise ValueError(
|
| 249 |
+
"`image` has to be of type `torch.FloatTensor` or `PIL.Image.Image` or `List[PIL.Image.Image]` but is"
|
| 250 |
+
f" {type(image)}"
|
| 251 |
+
)
|
| 252 |
+
|
| 253 |
+
if height % 8 != 0 or width % 8 != 0:
|
| 254 |
+
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
|
| 255 |
+
|
| 256 |
+
def prepare_latents(
|
| 257 |
+
self,
|
| 258 |
+
batch_size,
|
| 259 |
+
num_frames,
|
| 260 |
+
num_channels_latents,
|
| 261 |
+
height,
|
| 262 |
+
width,
|
| 263 |
+
dtype,
|
| 264 |
+
device,
|
| 265 |
+
generator,
|
| 266 |
+
latents=None,
|
| 267 |
+
ref_image_latents=None,
|
| 268 |
+
timestep=None
|
| 269 |
+
):
|
| 270 |
+
from src.utils.noise_util import random_noise
|
| 271 |
+
shape = (
|
| 272 |
+
batch_size,
|
| 273 |
+
num_frames,
|
| 274 |
+
num_channels_latents // 3,
|
| 275 |
+
height // self.vae_scale_factor,
|
| 276 |
+
width // self.vae_scale_factor,
|
| 277 |
+
)
|
| 278 |
+
if isinstance(generator, list) and len(generator) != batch_size:
|
| 279 |
+
raise ValueError(
|
| 280 |
+
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
| 281 |
+
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
| 282 |
+
)
|
| 283 |
+
|
| 284 |
+
if latents is None:
|
| 285 |
+
# noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
| 286 |
+
# noise = video_fusion_noise(shape=shape, generator=generator, device=device, dtype=dtype)
|
| 287 |
+
# noise = video_fusion_noise_repeat(shape=shape, generator=generator, device=device, dtype=dtype)
|
| 288 |
+
noise = random_noise(shape=shape, generator=generator, device=device, dtype=dtype)
|
| 289 |
+
# noise = video_fusion_noise_repeat_0830(shape=shape, generator=generator, device=device, dtype=dtype)
|
| 290 |
+
else:
|
| 291 |
+
noise = latents.to(device)
|
| 292 |
+
|
| 293 |
+
# scale the initial noise by the standard deviation required by the scheduler
|
| 294 |
+
if timestep is not None:
|
| 295 |
+
init_latents = ref_image_latents.unsqueeze(0)
|
| 296 |
+
# init_latents = ref_image_latents.unsqueeze(1)
|
| 297 |
+
latents = self.scheduler.add_noise(init_latents, noise, timestep)
|
| 298 |
+
else:
|
| 299 |
+
latents = noise * self.scheduler.init_noise_sigma
|
| 300 |
+
|
| 301 |
+
return latents
|
| 302 |
+
|
| 303 |
+
def get_timesteps(self, num_inference_steps, strength, device):
|
| 304 |
+
# get the original timestep using init_timestep
|
| 305 |
+
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
|
| 306 |
+
|
| 307 |
+
t_start = max(num_inference_steps - init_timestep, 0)
|
| 308 |
+
timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
|
| 309 |
+
|
| 310 |
+
return timesteps, num_inference_steps - t_start
|
| 311 |
+
|
| 312 |
+
@property
|
| 313 |
+
def guidance_scale1(self):
|
| 314 |
+
return self._guidance_scale1
|
| 315 |
+
|
| 316 |
+
@property
|
| 317 |
+
def guidance_scale2(self):
|
| 318 |
+
return self._guidance_scale2
|
| 319 |
+
|
| 320 |
+
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
| 321 |
+
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
| 322 |
+
# corresponds to doing no classifier free guidance.
|
| 323 |
+
# @property
|
| 324 |
+
# def do_classifier_free_guidance(self):
|
| 325 |
+
# return True
|
| 326 |
+
|
| 327 |
+
@property
|
| 328 |
+
def num_timesteps(self):
|
| 329 |
+
return self._num_timesteps
|
| 330 |
+
|
| 331 |
+
@torch.no_grad()
|
| 332 |
+
def __call__(
|
| 333 |
+
self,
|
| 334 |
+
ref_image: Union[PIL.Image.Image, List[PIL.Image.Image], torch.FloatTensor], # lq
|
| 335 |
+
ref_concat_image: Union[PIL.Image.Image, List[PIL.Image.Image], torch.FloatTensor], # last concat ref img
|
| 336 |
+
id_prompts: Union[PIL.Image.Image, List[PIL.Image.Image], torch.FloatTensor], # id encode_hidden_state
|
| 337 |
+
# task_id: int = 0,
|
| 338 |
+
task_id_input: torch.Tensor = None,
|
| 339 |
+
height: int = 512,
|
| 340 |
+
width: int = 512,
|
| 341 |
+
num_frames: Optional[int] = None,
|
| 342 |
+
num_inference_steps: int = 25,
|
| 343 |
+
min_guidance_scale=1.0, # 1.0,
|
| 344 |
+
max_guidance_scale=3.0,
|
| 345 |
+
noise_aug_strength: int = 0.02,
|
| 346 |
+
decode_chunk_size: Optional[int] = None,
|
| 347 |
+
num_videos_per_prompt: Optional[int] = 1,
|
| 348 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 349 |
+
latents: Optional[torch.FloatTensor] = None,
|
| 350 |
+
output_type: Optional[str] = "pil",
|
| 351 |
+
callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
|
| 352 |
+
callback_on_step_end_tensor_inputs: List[str] = ["latents"],
|
| 353 |
+
return_dict: bool = True,
|
| 354 |
+
do_classifier_free_guidance: bool = True,
|
| 355 |
+
overlap=7,
|
| 356 |
+
frames_per_batch=14,
|
| 357 |
+
i2i_noise_strength=1.0,
|
| 358 |
+
):
|
| 359 |
+
r"""
|
| 360 |
+
The call function to the pipeline for generation.
|
| 361 |
+
|
| 362 |
+
Args:
|
| 363 |
+
image (`PIL.Image.Image` or `List[PIL.Image.Image]` or `torch.FloatTensor`):
|
| 364 |
+
Image or images to guide image generation. If you provide a tensor, it needs to be compatible with
|
| 365 |
+
[`CLIPImageProcessor`](https://huggingface.co/lambdalabs/sd-image-variations-diffusers/blob/main/feature_extractor/preprocessor_config.json).
|
| 366 |
+
height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
|
| 367 |
+
The height in pixels of the generated image.
|
| 368 |
+
width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
|
| 369 |
+
The width in pixels of the generated image.
|
| 370 |
+
num_frames (`int`, *optional*):
|
| 371 |
+
The number of video frames to generate. Defaults to 14 for `stable-video-diffusion-img2vid` and to 25 for `stable-video-diffusion-img2vid-xt`
|
| 372 |
+
num_inference_steps (`int`, *optional*, defaults to 25):
|
| 373 |
+
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
| 374 |
+
expense of slower inference. This parameter is modulated by `strength`.
|
| 375 |
+
min_guidance_scale (`float`, *optional*, defaults to 1.0):
|
| 376 |
+
The minimum guidance scale. Used for the classifier free guidance with first frame.
|
| 377 |
+
max_guidance_scale (`float`, *optional*, defaults to 3.0):
|
| 378 |
+
The maximum guidance scale. Used for the classifier free guidance with last frame.
|
| 379 |
+
noise_aug_strength (`int`, *optional*, defaults to 0.02):
|
| 380 |
+
The amount of noise added to the init image, the higher it is the less the video will look like the init image. Increase it for more motion.
|
| 381 |
+
decode_chunk_size (`int`, *optional*):
|
| 382 |
+
The number of frames to decode at a time. The higher the chunk size, the higher the temporal consistency
|
| 383 |
+
between frames, but also the higher the memory consumption. By default, the decoder will decode all frames at once
|
| 384 |
+
for maximal quality. Reduce `decode_chunk_size` to reduce memory usage.
|
| 385 |
+
num_videos_per_prompt (`int`, *optional*, defaults to 1):
|
| 386 |
+
The number of images to generate per prompt.
|
| 387 |
+
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
| 388 |
+
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
|
| 389 |
+
generation deterministic.
|
| 390 |
+
latents (`torch.FloatTensor`, *optional*):
|
| 391 |
+
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
|
| 392 |
+
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
| 393 |
+
tensor is generated by sampling using the supplied random `generator`.
|
| 394 |
+
output_type (`str`, *optional*, defaults to `"pil"`):
|
| 395 |
+
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
|
| 396 |
+
callback_on_step_end (`Callable`, *optional*):
|
| 397 |
+
A function that calls at the end of each denoising steps during the inference. The function is called
|
| 398 |
+
with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
|
| 399 |
+
callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
|
| 400 |
+
`callback_on_step_end_tensor_inputs`.
|
| 401 |
+
callback_on_step_end_tensor_inputs (`List`, *optional*):
|
| 402 |
+
The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
|
| 403 |
+
will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
|
| 404 |
+
`._callback_tensor_inputs` attribute of your pipeline class.
|
| 405 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 406 |
+
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
|
| 407 |
+
plain tuple.
|
| 408 |
+
|
| 409 |
+
Returns:
|
| 410 |
+
[`~pipelines.stable_diffusion.StableVideoDiffusionPipelineOutput`] or `tuple`:
|
| 411 |
+
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableVideoDiffusionPipelineOutput`] is returned,
|
| 412 |
+
otherwise a `tuple` is returned where the first element is a list of list with the generated frames.
|
| 413 |
+
|
| 414 |
+
Examples:
|
| 415 |
+
|
| 416 |
+
```py
|
| 417 |
+
from diffusers import StableVideoDiffusionPipeline
|
| 418 |
+
from diffusers.utils import load_image, export_to_video
|
| 419 |
+
|
| 420 |
+
pipe = StableVideoDiffusionPipeline.from_pretrained("stabilityai/stable-video-diffusion-img2vid-xt", torch_dtype=torch.float16, variant="fp16")
|
| 421 |
+
pipe.to("cuda")
|
| 422 |
+
|
| 423 |
+
image = load_image("https://lh3.googleusercontent.com/y-iFOHfLTwkuQSUegpwDdgKmOjRSTvPxat63dQLB25xkTs4lhIbRUFeNBWZzYf370g=s1200")
|
| 424 |
+
image = image.resize((1024, 576))
|
| 425 |
+
|
| 426 |
+
frames = pipe(image, num_frames=25, decode_chunk_size=8).frames[0]
|
| 427 |
+
export_to_video(frames, "generated.mp4", fps=7)
|
| 428 |
+
```
|
| 429 |
+
"""
|
| 430 |
+
# 0. Default height and width to unet
|
| 431 |
+
height = height or self.unet.config.sample_size * self.vae_scale_factor
|
| 432 |
+
width = width or self.unet.config.sample_size * self.vae_scale_factor
|
| 433 |
+
|
| 434 |
+
# print(min_guidance_scale, max_guidance_scale)
|
| 435 |
+
|
| 436 |
+
num_frames = num_frames if num_frames is not None else self.unet.config.num_frames
|
| 437 |
+
decode_chunk_size = decode_chunk_size if decode_chunk_size is not None else num_frames
|
| 438 |
+
|
| 439 |
+
# 1. Check inputs. Raise error if not correct
|
| 440 |
+
self.check_inputs(ref_image, height, width)
|
| 441 |
+
|
| 442 |
+
# 2. Define call parameters
|
| 443 |
+
if isinstance(ref_image, PIL.Image.Image):
|
| 444 |
+
batch_size = 1
|
| 445 |
+
elif isinstance(ref_image, list):
|
| 446 |
+
batch_size = len(ref_image)
|
| 447 |
+
else:
|
| 448 |
+
if len(ref_image.shape)==4:
|
| 449 |
+
batch_size = 1
|
| 450 |
+
else:
|
| 451 |
+
batch_size = ref_image.shape[0]
|
| 452 |
+
|
| 453 |
+
device = self._execution_device
|
| 454 |
+
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
| 455 |
+
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
| 456 |
+
# corresponds to doing no classifier free guidance.
|
| 457 |
+
# do_classifier_free_guidance = True #True
|
| 458 |
+
|
| 459 |
+
# 3. Prepare clip image embeds
|
| 460 |
+
# image_embeddings = torch.zeros([2,1,1024],dtype=self.vae.dtype).to(device)
|
| 461 |
+
# image_embeddings = self._clip_encode_image(
|
| 462 |
+
# clip_image,
|
| 463 |
+
# num_frames,
|
| 464 |
+
# device,
|
| 465 |
+
# num_videos_per_prompt,
|
| 466 |
+
# do_classifier_free_guidance,)
|
| 467 |
+
# print(image_embeddings)
|
| 468 |
+
image_embeddings = torch.cat([torch.zeros_like(id_prompts),id_prompts], dim=0) if do_classifier_free_guidance else id_prompts
|
| 469 |
+
# image_embeddings = torch.cat([torch.zeros_like(id_prompts),id_prompts,id_prompts], dim=0)
|
| 470 |
+
# image_embeddings = torch.cat([id_prompts,id_prompts,id_prompts], dim=0)
|
| 471 |
+
# image_embeddings = torch.cat([torch.zeros_like(id_prompts),torch.zeros_like(id_prompts),torch.zeros_like(id_prompts)], dim=0)
|
| 472 |
+
# image_embeddings = torch.cat([id_prompts_neg, id_prompts, id_prompts], dim=0)
|
| 473 |
+
|
| 474 |
+
|
| 475 |
+
# NOTE: Stable Diffusion Video was conditioned on fps - 1, which
|
| 476 |
+
# is why it is reduced here.
|
| 477 |
+
# See: https://github.com/Stability-AI/generative-models/blob/ed0997173f98eaf8f4edf7ba5fe8f15c6b877fd3/scripts/sampling/simple_video_sample.py#L188
|
| 478 |
+
# fps = fps - 1
|
| 479 |
+
|
| 480 |
+
# 4. Encode input image using VAE
|
| 481 |
+
needs_upcasting = (self.vae.dtype == torch.float16 or self.vae.dtype == torch.bfloat16) and self.vae.config.force_upcast
|
| 482 |
+
vae_dtype = self.vae.dtype
|
| 483 |
+
if needs_upcasting:
|
| 484 |
+
self.vae.to(dtype=torch.float32)
|
| 485 |
+
|
| 486 |
+
# Prepare ref image latents
|
| 487 |
+
ref_image_tensor = ref_image.to(
|
| 488 |
+
dtype=self.vae.dtype, device=self.vae.device
|
| 489 |
+
)
|
| 490 |
+
|
| 491 |
+
# bsz = ref_image_tensor.shape[0]
|
| 492 |
+
# ref_image_tensor = rearrange(ref_image_tensor,'b f c h w-> (b f) c h w')
|
| 493 |
+
chunk_size = 20
|
| 494 |
+
ref_image_latents = []
|
| 495 |
+
for chunk_idx in range((ref_image_tensor.shape[0]//chunk_size)+1):
|
| 496 |
+
if chunk_idx*chunk_size>=num_frames: break
|
| 497 |
+
ref_image_latent = self.vae.encode(ref_image_tensor[chunk_idx*chunk_size:(chunk_idx+1)*chunk_size]).latent_dist.mean #TODO
|
| 498 |
+
ref_image_latents.append(ref_image_latent)
|
| 499 |
+
ref_image_latents = torch.cat(ref_image_latents,dim=0)
|
| 500 |
+
# print(ref_image_tensor.shape,ref_image_latents.shape)
|
| 501 |
+
ref_image_latents = ref_image_latents * 0.18215 # (f, 4, h, w)
|
| 502 |
+
# ref_image_latents = rearrange(ref_image_latents, '(b f) c h w-> b f c h w', b=bsz)
|
| 503 |
+
|
| 504 |
+
noise = randn_tensor(
|
| 505 |
+
ref_image_tensor.shape,
|
| 506 |
+
generator=generator,
|
| 507 |
+
device=self.vae.device,
|
| 508 |
+
dtype=self.vae.dtype)
|
| 509 |
+
|
| 510 |
+
ref_image_tensor = ref_image_tensor + noise_aug_strength * noise
|
| 511 |
+
|
| 512 |
+
image_latents = []
|
| 513 |
+
for chunk_idx in range((ref_image_tensor.shape[0]//chunk_size)+1):
|
| 514 |
+
if chunk_idx*chunk_size>=num_frames: break
|
| 515 |
+
image_latent = self._encode_vae_image(
|
| 516 |
+
ref_image_tensor[chunk_idx*chunk_size:(chunk_idx+1)*chunk_size],
|
| 517 |
+
device=device,
|
| 518 |
+
num_videos_per_prompt=num_videos_per_prompt,
|
| 519 |
+
do_classifier_free_guidance=do_classifier_free_guidance,
|
| 520 |
+
)
|
| 521 |
+
image_latents.append(image_latent)
|
| 522 |
+
image_latents = torch.cat(image_latents, dim=1)
|
| 523 |
+
# print(ref_image_tensor.shape,image_latents.shape)
|
| 524 |
+
# print(image_latents.shape)
|
| 525 |
+
image_latents = image_latents.to(image_embeddings.dtype)
|
| 526 |
+
ref_image_latents = ref_image_latents.to(image_embeddings.dtype)
|
| 527 |
+
|
| 528 |
+
# cast back to fp16 if needed
|
| 529 |
+
if needs_upcasting:
|
| 530 |
+
self.vae.to(dtype=vae_dtype)
|
| 531 |
+
|
| 532 |
+
# Repeat the image latents for each frame so we can concatenate them with the noise
|
| 533 |
+
# image_latents [batch, channels, height, width] ->[batch, num_frames, channels, height, width]
|
| 534 |
+
# image_latents = image_latents.unsqueeze(1).repeat(1, num_frames, 1, 1, 1)
|
| 535 |
+
|
| 536 |
+
if ref_concat_image is not None:
|
| 537 |
+
ref_concat_tensor = ref_concat_image.to(
|
| 538 |
+
dtype=self.vae.dtype, device=self.vae.device
|
| 539 |
+
)
|
| 540 |
+
ref_concat_tensor = self.vae.encode(ref_concat_tensor.unsqueeze(0)).latent_dist.mode()
|
| 541 |
+
ref_concat_tensor = ref_concat_tensor.unsqueeze(0).repeat(1,num_frames,1,1,1)
|
| 542 |
+
ref_concat_tensor = torch.cat([torch.zeros_like(ref_concat_tensor), ref_concat_tensor]) if do_classifier_free_guidance else ref_concat_tensor
|
| 543 |
+
ref_concat_tensor = ref_concat_tensor.to(image_embeddings)
|
| 544 |
+
else:
|
| 545 |
+
ref_concat_tensor = torch.zeros_like(image_latents)
|
| 546 |
+
|
| 547 |
+
|
| 548 |
+
# 5. Get Added Time IDs
|
| 549 |
+
added_time_ids = self._get_add_time_ids(
|
| 550 |
+
task_id_input,
|
| 551 |
+
image_embeddings.dtype,
|
| 552 |
+
batch_size,
|
| 553 |
+
num_videos_per_prompt,
|
| 554 |
+
do_classifier_free_guidance,
|
| 555 |
+
)
|
| 556 |
+
added_time_ids = added_time_ids.to(device, dtype=self.unet.dtype)
|
| 557 |
+
|
| 558 |
+
# 4. Prepare timesteps
|
| 559 |
+
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
| 560 |
+
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, i2i_noise_strength, device)
|
| 561 |
+
latent_timestep = timesteps[:1].repeat(batch_size * num_videos_per_prompt)
|
| 562 |
+
|
| 563 |
+
|
| 564 |
+
# 5. Prepare latent variables
|
| 565 |
+
num_channels_latents = self.unet.config.in_channels
|
| 566 |
+
latents = self.prepare_latents(
|
| 567 |
+
batch_size * num_videos_per_prompt,
|
| 568 |
+
num_frames,
|
| 569 |
+
num_channels_latents,
|
| 570 |
+
height,
|
| 571 |
+
width,
|
| 572 |
+
image_embeddings.dtype,
|
| 573 |
+
device,
|
| 574 |
+
generator,
|
| 575 |
+
latents,
|
| 576 |
+
ref_image_latents,
|
| 577 |
+
timestep=latent_timestep
|
| 578 |
+
)
|
| 579 |
+
|
| 580 |
+
# 7. Prepare guidance scale
|
| 581 |
+
guidance_scale = torch.linspace(
|
| 582 |
+
min_guidance_scale,
|
| 583 |
+
max_guidance_scale,
|
| 584 |
+
num_inference_steps)
|
| 585 |
+
guidance_scale1 = guidance_scale.to(device, latents.dtype)
|
| 586 |
+
guidance_scale2 = guidance_scale.to(device, latents.dtype)
|
| 587 |
+
|
| 588 |
+
|
| 589 |
+
self._guidance_scale1 = guidance_scale1
|
| 590 |
+
self._guidance_scale2 = guidance_scale2
|
| 591 |
+
|
| 592 |
+
# 8. Denoising loop
|
| 593 |
+
latents_all = latents # for any-frame generation
|
| 594 |
+
|
| 595 |
+
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
|
| 596 |
+
self._num_timesteps = len(timesteps)
|
| 597 |
+
shift = 0
|
| 598 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 599 |
+
for i, t in enumerate(timesteps):
|
| 600 |
+
|
| 601 |
+
# init
|
| 602 |
+
pred_latents = torch.zeros_like(
|
| 603 |
+
latents_all,
|
| 604 |
+
dtype=self.unet.dtype,
|
| 605 |
+
)
|
| 606 |
+
counter = torch.zeros(
|
| 607 |
+
(latents_all.shape[0], num_frames, 1, 1, 1),
|
| 608 |
+
dtype=self.unet.dtype,
|
| 609 |
+
).to(device=latents_all.device)
|
| 610 |
+
|
| 611 |
+
for batch, index_start in enumerate(range(0, num_frames, frames_per_batch - overlap*(i<3))):
|
| 612 |
+
self.scheduler._step_index = None
|
| 613 |
+
index_start -= shift
|
| 614 |
+
def indice_slice(tensor, idx_list):
|
| 615 |
+
tensor_list = []
|
| 616 |
+
for idx in idx_list:
|
| 617 |
+
idx = idx % tensor.shape[1]
|
| 618 |
+
tensor_list.append(tensor[:,idx])
|
| 619 |
+
return torch.stack(tensor_list, 1)
|
| 620 |
+
idx_list = list(range(index_start, index_start+frames_per_batch))
|
| 621 |
+
latents = indice_slice(latents_all, idx_list)
|
| 622 |
+
image_latents_input = indice_slice(image_latents, idx_list)
|
| 623 |
+
image_embeddings_input = indice_slice(image_embeddings, idx_list)
|
| 624 |
+
ref_concat_tensor_input = indice_slice(ref_concat_tensor, idx_list)
|
| 625 |
+
|
| 626 |
+
|
| 627 |
+
# if index_start + frames_per_batch >= num_frames:
|
| 628 |
+
# index_start = num_frames - frames_per_batch
|
| 629 |
+
|
| 630 |
+
# latents = latents_all[:, index_start:index_start + frames_per_batch]
|
| 631 |
+
# image_latents_input = image_latents[:, index_start:index_start + frames_per_batch]
|
| 632 |
+
|
| 633 |
+
# expand the latents if we are doing classifier free guidance
|
| 634 |
+
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
| 635 |
+
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 636 |
+
|
| 637 |
+
# = torch.cat([torch.zeros_like(image_latents_input),image_latents_input]) if do_classifier_free_guidance else image_latents_input
|
| 638 |
+
# image_latents_input = torch.zeros_like(image_latents_input)
|
| 639 |
+
# image_latents_input = torch.cat([image_latents_input] * 2) if do_classifier_free_guidance else image_latents_input
|
| 640 |
+
|
| 641 |
+
|
| 642 |
+
# Concatenate image_latents over channels dimention
|
| 643 |
+
# print(latent_model_input.shape, image_latents_input.shape)
|
| 644 |
+
latent_model_input = torch.cat([
|
| 645 |
+
latent_model_input,
|
| 646 |
+
image_latents_input,
|
| 647 |
+
ref_concat_tensor_input], dim=2)
|
| 648 |
+
# predict the noise residual
|
| 649 |
+
noise_pred = self.unet(
|
| 650 |
+
latent_model_input,
|
| 651 |
+
t,
|
| 652 |
+
encoder_hidden_states=image_embeddings_input.flatten(0,1),
|
| 653 |
+
added_time_ids=added_time_ids,
|
| 654 |
+
return_dict=False,
|
| 655 |
+
)[0]
|
| 656 |
+
# perform guidance
|
| 657 |
+
if do_classifier_free_guidance:
|
| 658 |
+
noise_pred_uncond, noise_pred_cond = noise_pred.chunk(3)
|
| 659 |
+
noise_pred = noise_pred_uncond + self.guidance_scale1[i] * (noise_pred_cond - noise_pred_uncond) #+ self.guidance_scale2[i] * (noise_pred_cond - noise_pred_drop_id)
|
| 660 |
+
|
| 661 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 662 |
+
latents = self.scheduler.step(noise_pred, t.to(self.unet.dtype), latents).prev_sample
|
| 663 |
+
|
| 664 |
+
if callback_on_step_end is not None:
|
| 665 |
+
callback_kwargs = {}
|
| 666 |
+
for k in callback_on_step_end_tensor_inputs:
|
| 667 |
+
callback_kwargs[k] = locals()[k]
|
| 668 |
+
callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
|
| 669 |
+
|
| 670 |
+
latents = callback_outputs.pop("latents", latents)
|
| 671 |
+
|
| 672 |
+
# if batch == 0:
|
| 673 |
+
for iii in range(frames_per_batch):
|
| 674 |
+
# pred_latents[:, index_start + iii:index_start + iii + 1] += latents[:, iii:iii+1] * min(iii + 1, frames_per_batch-iii)
|
| 675 |
+
# counter[:, index_start + iii:index_start + iii + 1] += min(iii + 1, frames_per_batch-iii)
|
| 676 |
+
p = (index_start + iii) % pred_latents.shape[1]
|
| 677 |
+
pred_latents[:, p] += latents[:, iii] * min(iii + 1, frames_per_batch-iii)
|
| 678 |
+
counter[:, p] += 1 * min(iii + 1, frames_per_batch-iii)
|
| 679 |
+
|
| 680 |
+
|
| 681 |
+
shift += overlap
|
| 682 |
+
shift = shift % frames_per_batch
|
| 683 |
+
|
| 684 |
+
pred_latents = pred_latents / counter
|
| 685 |
+
latents_all = pred_latents
|
| 686 |
+
|
| 687 |
+
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
| 688 |
+
progress_bar.update()
|
| 689 |
+
|
| 690 |
+
latents = latents_all
|
| 691 |
+
if not output_type == "latent":
|
| 692 |
+
# cast back to fp16 if needed
|
| 693 |
+
if needs_upcasting:
|
| 694 |
+
self.vae.to(dtype=vae_dtype)
|
| 695 |
+
frames = self.decode_latents(latents, num_frames, decode_chunk_size)
|
| 696 |
+
else:
|
| 697 |
+
frames = latents
|
| 698 |
+
|
| 699 |
+
self.maybe_free_model_hooks()
|
| 700 |
+
|
| 701 |
+
if not return_dict:
|
| 702 |
+
return frames
|
| 703 |
+
return LQ2VideoSVDPipelineOutput(frames=frames,latents=latents)
|
| 704 |
+
|
| 705 |
+
|
| 706 |
+
# resizing utils
|
| 707 |
+
# TODO: clean up later
|
| 708 |
+
def _resize_with_antialiasing(input, size, interpolation="bicubic", align_corners=True):
|
| 709 |
+
h, w = input.shape[-2:]
|
| 710 |
+
factors = (h / size[0], w / size[1])
|
| 711 |
+
|
| 712 |
+
# First, we have to determine sigma
|
| 713 |
+
# Taken from skimage: https://github.com/scikit-image/scikit-image/blob/v0.19.2/skimage/transform/_warps.py#L171
|
| 714 |
+
sigmas = (
|
| 715 |
+
max((factors[0] - 1.0) / 2.0, 0.001),
|
| 716 |
+
max((factors[1] - 1.0) / 2.0, 0.001),
|
| 717 |
+
)
|
| 718 |
+
|
| 719 |
+
# Now kernel size. Good results are for 3 sigma, but that is kind of slow. Pillow uses 1 sigma
|
| 720 |
+
# https://github.com/python-pillow/Pillow/blob/master/src/libImaging/Resample.c#L206
|
| 721 |
+
# But they do it in the 2 passes, which gives better results. Let's try 2 sigmas for now
|
| 722 |
+
ks = int(max(2.0 * 2 * sigmas[0], 3)), int(max(2.0 * 2 * sigmas[1], 3))
|
| 723 |
+
|
| 724 |
+
# Make sure it is odd
|
| 725 |
+
if (ks[0] % 2) == 0:
|
| 726 |
+
ks = ks[0] + 1, ks[1]
|
| 727 |
+
|
| 728 |
+
if (ks[1] % 2) == 0:
|
| 729 |
+
ks = ks[0], ks[1] + 1
|
| 730 |
+
|
| 731 |
+
input = _gaussian_blur2d(input, ks, sigmas)
|
| 732 |
+
|
| 733 |
+
output = torch.nn.functional.interpolate(input, size=size, mode=interpolation, align_corners=align_corners)
|
| 734 |
+
return output
|
| 735 |
+
|
| 736 |
+
|
| 737 |
+
def _compute_padding(kernel_size):
|
| 738 |
+
"""Compute padding tuple."""
|
| 739 |
+
# 4 or 6 ints: (padding_left, padding_right,padding_top,padding_bottom)
|
| 740 |
+
# https://pytorch.org/docs/stable/nn.html#torch.nn.functional.pad
|
| 741 |
+
if len(kernel_size) < 2:
|
| 742 |
+
raise AssertionError(kernel_size)
|
| 743 |
+
computed = [k - 1 for k in kernel_size]
|
| 744 |
+
|
| 745 |
+
# for even kernels we need to do asymmetric padding :(
|
| 746 |
+
out_padding = 2 * len(kernel_size) * [0]
|
| 747 |
+
|
| 748 |
+
for i in range(len(kernel_size)):
|
| 749 |
+
computed_tmp = computed[-(i + 1)]
|
| 750 |
+
|
| 751 |
+
pad_front = computed_tmp // 2
|
| 752 |
+
pad_rear = computed_tmp - pad_front
|
| 753 |
+
|
| 754 |
+
out_padding[2 * i + 0] = pad_front
|
| 755 |
+
out_padding[2 * i + 1] = pad_rear
|
| 756 |
+
|
| 757 |
+
return out_padding
|
| 758 |
+
|
| 759 |
+
|
| 760 |
+
def _filter2d(input, kernel):
|
| 761 |
+
# prepare kernel
|
| 762 |
+
b, c, h, w = input.shape
|
| 763 |
+
tmp_kernel = kernel[:, None, ...].to(device=input.device, dtype=input.dtype)
|
| 764 |
+
|
| 765 |
+
tmp_kernel = tmp_kernel.expand(-1, c, -1, -1)
|
| 766 |
+
|
| 767 |
+
height, width = tmp_kernel.shape[-2:]
|
| 768 |
+
|
| 769 |
+
padding_shape: list[int] = _compute_padding([height, width])
|
| 770 |
+
input = torch.nn.functional.pad(input, padding_shape, mode="reflect")
|
| 771 |
+
|
| 772 |
+
# kernel and input tensor reshape to align element-wise or batch-wise params
|
| 773 |
+
tmp_kernel = tmp_kernel.reshape(-1, 1, height, width)
|
| 774 |
+
input = input.view(-1, tmp_kernel.size(0), input.size(-2), input.size(-1))
|
| 775 |
+
|
| 776 |
+
# convolve the tensor with the kernel.
|
| 777 |
+
output = torch.nn.functional.conv2d(input, tmp_kernel, groups=tmp_kernel.size(0), padding=0, stride=1)
|
| 778 |
+
|
| 779 |
+
out = output.view(b, c, h, w)
|
| 780 |
+
return out
|
| 781 |
+
|
| 782 |
+
|
| 783 |
+
def _gaussian(window_size: int, sigma):
|
| 784 |
+
if isinstance(sigma, float):
|
| 785 |
+
sigma = torch.tensor([[sigma]])
|
| 786 |
+
|
| 787 |
+
batch_size = sigma.shape[0]
|
| 788 |
+
|
| 789 |
+
x = (torch.arange(window_size, device=sigma.device, dtype=sigma.dtype) - window_size // 2).expand(batch_size, -1)
|
| 790 |
+
|
| 791 |
+
if window_size % 2 == 0:
|
| 792 |
+
x = x + 0.5
|
| 793 |
+
|
| 794 |
+
gauss = torch.exp(-x.pow(2.0) / (2 * sigma.pow(2.0)))
|
| 795 |
+
|
| 796 |
+
return gauss / gauss.sum(-1, keepdim=True)
|
| 797 |
+
|
| 798 |
+
|
| 799 |
+
def _gaussian_blur2d(input, kernel_size, sigma):
|
| 800 |
+
if isinstance(sigma, tuple):
|
| 801 |
+
sigma = torch.tensor([sigma], dtype=input.dtype)
|
| 802 |
+
else:
|
| 803 |
+
sigma = sigma.to(dtype=input.dtype)
|
| 804 |
+
|
| 805 |
+
ky, kx = int(kernel_size[0]), int(kernel_size[1])
|
| 806 |
+
bs = sigma.shape[0]
|
| 807 |
+
kernel_x = _gaussian(kx, sigma[:, 1].view(bs, 1))
|
| 808 |
+
kernel_y = _gaussian(ky, sigma[:, 0].view(bs, 1))
|
| 809 |
+
out_x = _filter2d(input, kernel_x[..., None, :])
|
| 810 |
+
out = _filter2d(out_x, kernel_y[..., None])
|
| 811 |
+
|
| 812 |
+
return out
|
src/utils/noise_util.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Optional, Tuple, Union
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 5 |
+
|
| 6 |
+
def random_noise(
|
| 7 |
+
tensor: torch.Tensor = None,
|
| 8 |
+
shape: Tuple[int] = None,
|
| 9 |
+
dtype: torch.dtype = None,
|
| 10 |
+
device: torch.device = None,
|
| 11 |
+
generator: Optional[Union[List["torch.Generator"], "torch.Generator"]] = None,
|
| 12 |
+
noise_offset: Optional[float] = None, # typical value is 0.1
|
| 13 |
+
) -> torch.Tensor:
|
| 14 |
+
if tensor is not None:
|
| 15 |
+
shape = tensor.shape
|
| 16 |
+
device = tensor.device
|
| 17 |
+
dtype = tensor.dtype
|
| 18 |
+
if isinstance(device, str):
|
| 19 |
+
device = torch.device(device)
|
| 20 |
+
noise = randn_tensor(shape, dtype=dtype, device=device, generator=generator)
|
| 21 |
+
if noise_offset is not None:
|
| 22 |
+
noise += noise_offset * torch.randn(
|
| 23 |
+
(tensor.shape[0], tensor.shape[1], 1, 1, 1), device
|
| 24 |
+
)
|
| 25 |
+
return noise
|
src/utils/util.py
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torchvision
|
| 7 |
+
from einops import rearrange
|
| 8 |
+
from PIL import Image
|
| 9 |
+
|
| 10 |
+
import imageio
|
| 11 |
+
|
| 12 |
+
def seed_everything(seed):
|
| 13 |
+
import random
|
| 14 |
+
|
| 15 |
+
import numpy as np
|
| 16 |
+
|
| 17 |
+
torch.manual_seed(seed)
|
| 18 |
+
torch.cuda.manual_seed_all(seed)
|
| 19 |
+
np.random.seed(seed % (2**32))
|
| 20 |
+
random.seed(seed)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def save_videos_from_pil(pil_images, path, fps=8):
|
| 24 |
+
save_fmt = Path(path).suffix
|
| 25 |
+
os.makedirs(os.path.dirname(path), exist_ok=True)
|
| 26 |
+
|
| 27 |
+
if save_fmt == ".mp4":
|
| 28 |
+
with imageio.get_writer(path, fps=fps) as writer:
|
| 29 |
+
for img in pil_images:
|
| 30 |
+
img_array = np.array(img) # Convert PIL Image to numpy array
|
| 31 |
+
writer.append_data(img_array)
|
| 32 |
+
|
| 33 |
+
elif save_fmt == ".gif":
|
| 34 |
+
pil_images[0].save(
|
| 35 |
+
fp=path,
|
| 36 |
+
format="GIF",
|
| 37 |
+
append_images=pil_images[1:],
|
| 38 |
+
save_all=True,
|
| 39 |
+
duration=(1 / fps * 1000),
|
| 40 |
+
loop=0,
|
| 41 |
+
optimize=False,
|
| 42 |
+
lossless=True
|
| 43 |
+
)
|
| 44 |
+
else:
|
| 45 |
+
raise ValueError("Unsupported file type. Use .mp4 or .gif.")
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def save_videos_grid(videos: torch.Tensor, path: str, rescale=False, n_rows=6, fps=8):
|
| 49 |
+
videos = rearrange(videos, "b c t h w -> t b c h w")
|
| 50 |
+
height, width = videos.shape[-2:]
|
| 51 |
+
outputs = []
|
| 52 |
+
|
| 53 |
+
for i, x in enumerate(videos):
|
| 54 |
+
x = torchvision.utils.make_grid(x, nrow=n_rows) # (c h w)
|
| 55 |
+
x = x.transpose(0, 1).transpose(1, 2).squeeze(-1) # (h w c)
|
| 56 |
+
if rescale:
|
| 57 |
+
x = (x + 1.0) / 2.0 # -1,1 -> 0,1
|
| 58 |
+
x = (x * 255).numpy().astype(np.uint8)
|
| 59 |
+
x = Image.fromarray(x)
|
| 60 |
+
outputs.append(x)
|
| 61 |
+
|
| 62 |
+
os.makedirs(os.path.dirname(path), exist_ok=True)
|
| 63 |
+
|
| 64 |
+
save_videos_from_pil(outputs, path, fps)
|