
File size: 6,685 Bytes
fcf7073 e5292a9 3ee8777 fcf7073 1fa1c3c fcf7073 961d6e4 2bb1049 9afb5ac 2bb1049 0e7d804 fcf7073 cd66d78 1fa1c3c fcf7073 cd66d78 795027f cd66d78 fcf7073 1fa1c3c fcf7073 1fa1c3c fcf7073 1fa1c3c fcf7073 1fa1c3c fcf7073 1fa1c3c fcf7073 1fa1c3c |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 |
from typing import List, Dict
import httpx
import gradio as gr
import pandas as pd
async def get_splits(dataset_name: str) -> Dict[str, List[Dict]]:
URL = f"/static-proxy?url=https%3A%2F%2Fdatasets-server.huggingface.co%2Fsplits%3Fdataset%3D%3Cspan class="hljs-subst">{dataset_name}"
async with httpx.AsyncClient() as session:
response = await session.get(URL)
return response.json()
async def get_valid_datasets() -> Dict[str, List[str]]:
URL = f"/static-proxy?url=https%3A%2F%2Fdatasets-server.huggingface.co%2Fvalid%26quot%3B%3C%2Fspan%3E
async with httpx.AsyncClient() as session:
response = await session.get(URL)
datasets = response.json()["valid"]
return gr.Dropdown.update(choices=datasets, value="awacke1/ChatbotMemory.csv")
# The one to watch: https://huggingface.co/rungalileo
# rungalileo/medical_transcription_40
async def get_first_rows(dataset: str, config: str, split: str) -> Dict[str, Dict[str, List[Dict]]]:
URL = f"/static-proxy?url=https%3A%2F%2Fdatasets-server.huggingface.co%2Ffirst-rows%3Fdataset%3D%3Cspan class="hljs-subst">{dataset}&config={config}&split={split}"
async with httpx.AsyncClient() as session:
response = await session.get(URL)
print(URL)
gr.Markdown(URL)
return response.json()
def get_df_from_rows(api_output):
dfFromSort = pd.DataFrame([row["row"] for row in api_output["rows"]])
try:
dfFromSort.sort_values(by=0, axis=1, ascending=True, inplace=False, kind='mergesort', na_position='last', ignore_index=False, key=None)
except:
print("Exception sorting due to keyerror?")
return dfFromSort
async def update_configs(dataset_name: str):
splits = await get_splits(dataset_name)
all_configs = sorted(set([s["config"] for s in splits["splits"]]))
return (gr.Dropdown.update(choices=all_configs, value=all_configs[0]),
splits)
async def update_splits(config_name: str, state: gr.State):
splits_for_config = sorted(set([s["split"] for s in state["splits"] if s["config"] == config_name]))
dataset_name = state["splits"][0]["dataset"]
dataset = await update_dataset(splits_for_config[0], config_name, dataset_name)
return (gr.Dropdown.update(choices=splits_for_config, value=splits_for_config[0]), dataset)
async def update_dataset(split_name: str, config_name: str, dataset_name: str):
rows = await get_first_rows(dataset_name, config_name, split_name)
df = get_df_from_rows(rows)
return df
# Guido von Roissum: https://www.youtube.com/watch?v=-DVyjdw4t9I
async def update_URL(dataset: str, config: str, split: str) -> str:
URL = f"/static-proxy?url=https%3A%2F%2Fdatasets-server.huggingface.co%2Ffirst-rows%3Fdataset%3D%3Cspan class="hljs-subst">{dataset}&config={config}&split={split}"
URL = f"https://huggingface.co/datasets/{split}"
return (URL)
async def openurl(URL: str) -> str:
html = f"<a href={URL} target=_blank>{URL}</a>"
return (html)
with gr.Blocks() as demo:
gr.Markdown("<h1><center>🥫Datasets🎨</center></h1>")
gr.Markdown("""<div align="center">Curated Datasets: <a href = "https://www.kaggle.com/datasets">Kaggle</a>. <a href="https://www.nlm.nih.gov/research/umls/index.html">NLM UMLS</a>. <a href="https://loinc.org/downloads/">LOINC</a>. <a href="https://www.cms.gov/medicare/icd-10/2022-icd-10-cm">ICD10 Diagnosis</a>. <a href="https://icd.who.int/dev11/downloads">ICD11</a>. <a href="https://paperswithcode.com/datasets?q=medical&v=lst&o=newest">Papers,Code,Datasets for SOTA in Medicine</a>. <a href="https://paperswithcode.com/datasets?q=mental&v=lst&o=newest">Mental</a>. <a href="https://paperswithcode.com/datasets?q=behavior&v=lst&o=newest">Behavior</a>. <a href="https://www.cms.gov/medicare-coverage-database/downloads/downloads.aspx">CMS Downloads</a>. <a href="https://www.cms.gov/medicare/fraud-and-abuse/physicianselfreferral/list_of_codes">CMS CPT and HCPCS Procedures and Services</a> """)
splits_data = gr.State()
with gr.Row():
dataset_name = gr.Dropdown(label="Dataset", interactive=True)
config = gr.Dropdown(label="Subset", interactive=True)
split = gr.Dropdown(label="Split", interactive=True)
with gr.Row():
#filterleft = gr.Textbox(label="First Column Filter",placeholder="Filter Column 1")
URLcenter = gr.Textbox(label="Dataset URL", placeholder="URL")
btn = gr.Button("Use Dataset")
#URLoutput = gr.Textbox(label="Output",placeholder="URL Output")
URLoutput = gr.HTML(label="Output",placeholder="URL Output")
with gr.Row():
dataset = gr.DataFrame(wrap=True, interactive=True)
demo.load(get_valid_datasets, inputs=None, outputs=[dataset_name])
dataset_name.change(update_configs, inputs=[dataset_name], outputs=[config, splits_data])
config.change(update_splits, inputs=[config, splits_data], outputs=[split, dataset])
split.change(update_dataset, inputs=[split, config, dataset_name], outputs=[dataset])
dataset_name.change(update_URL, inputs=[split, config, dataset_name], outputs=[URLcenter])
btn.click(openurl, [URLcenter], URLoutput)
demo.launch(debug=True)
# original: https://huggingface.co/spaces/freddyaboulton/dataset-viewer -- Freddy thanks! Your examples are the best.
# playlist on Gradio and Mermaid: https://www.youtube.com/watch?v=o7kCD4aWMR4&list=PLHgX2IExbFosW7hWNryq8hs2bt2aj91R-
# Link to Mermaid model and code: [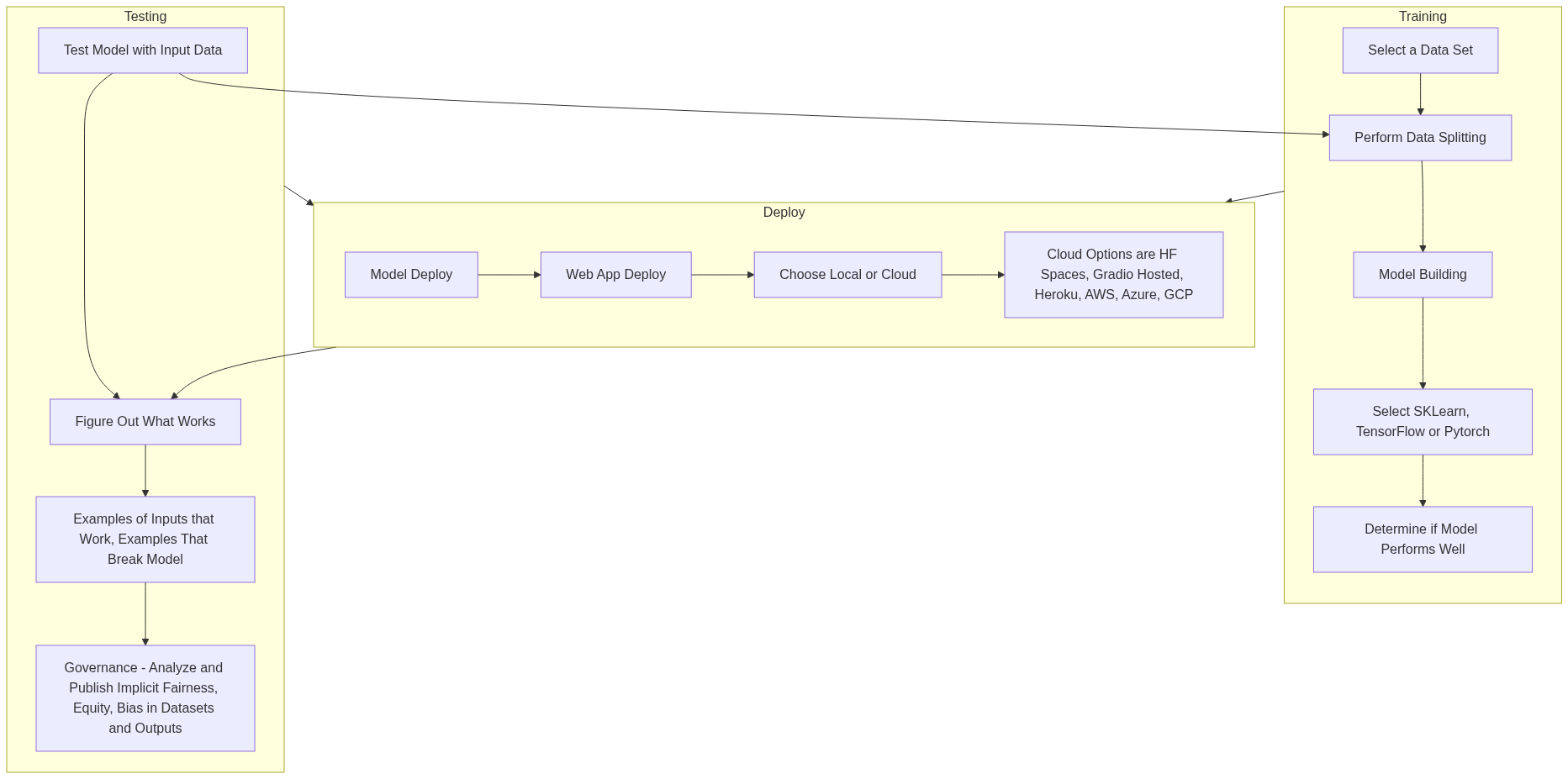](https://mermaid.live/edit#pako:eNp1U8mO2zAM_RXCZ-eQpZccCmSZTIpOMQESIAdnDrRMx0JkydXSNDOYfy_lpUgD1AfBfnx8fCTlj0SYgpJ5UipzFRVaD4flSQM_YjwafcVJ9-FCfrbYVGA0ZQeLUkt9futiOM72pEh4QFijR9iTf2tzsx3Z0ti6hxslvb_Lm0TSNPvBDhQsg1TFXXAag7NBef_9hdDqFA6knbEbdgvGwu7mjRXVkDOLOV-yNXmytdQEsoROvTfi4EhK9XTSxUNz_mo4uVHm1lPyce-uR1k_n2RHymHRNPAvNXaTT7NVZYwjeDECVbS4UiYUAyc2lc-yFoPXxkujHaAl2G54PCjIpfBssZAGtsZ5KlLYkjWXkMLiuOfjPVhiymr3_x4qS7wicneTFuMW6Gdxlb6Cb7oJvt1LbEpMso08sza8MnqskA9jL27Ij72Jafb0G-tGkQNTdgKOy_XcFP5GDxFbWsJLV3FQid2LWfZsfpHVqAXBCBYa1e2dAHUBu5Ar6dgby0ghPWxQWk2Oh_L0M0h_S2Ep0YHUrXFHXD_msefo5XEkfFWBK8atdkA7mgfoalpATJI0qfnWoCz4b_iI0VPiK6rplMz5taASg_Kn5KQ_mYrBm_1Ni2TubaA0CU2BntYSeQl1Mi9ROfr8A8FBGds)
|