

End of training
Browse files- README.md +2 -1
- all_results.json +12 -0
- eval_results.json +7 -0
- train_results.json +8 -0
- trainer_state.json +108 -0
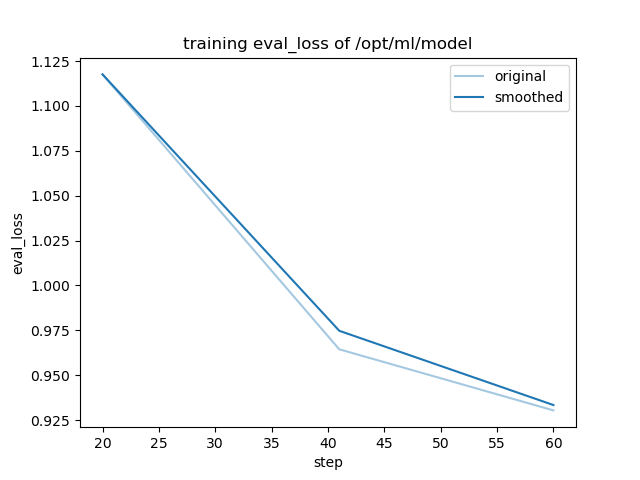
- training_eval_loss.png +0 -0
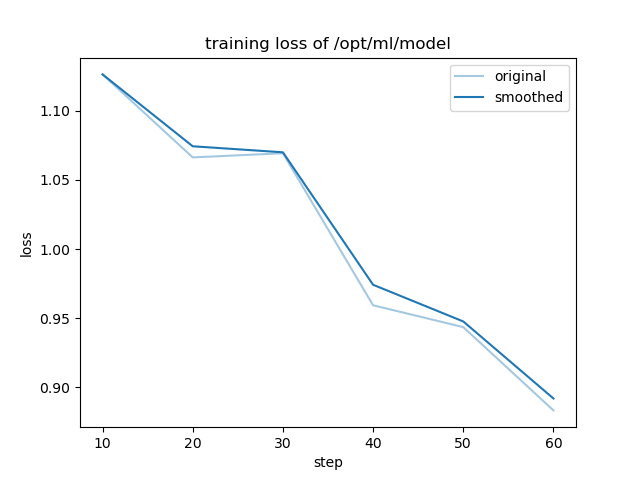
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -4,6 +4,7 @@ license: llama3.1
|
|
| 4 |
base_model: meta-llama/Meta-Llama-3.1-8B
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
|
|
|
| 7 |
- generated_from_trainer
|
| 8 |
model-index:
|
| 9 |
- name: stackexchange_astronomy
|
|
@@ -15,7 +16,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 15 |
|
| 16 |
# stackexchange_astronomy
|
| 17 |
|
| 18 |
-
This model is a fine-tuned version of [meta-llama/Meta-Llama-3.1-8B](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B) on
|
| 19 |
It achieves the following results on the evaluation set:
|
| 20 |
- Loss: 0.9304
|
| 21 |
|
|
|
|
| 4 |
base_model: meta-llama/Meta-Llama-3.1-8B
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
| 7 |
+
- full
|
| 8 |
- generated_from_trainer
|
| 9 |
model-index:
|
| 10 |
- name: stackexchange_astronomy
|
|
|
|
| 16 |
|
| 17 |
# stackexchange_astronomy
|
| 18 |
|
| 19 |
+
This model is a fine-tuned version of [meta-llama/Meta-Llama-3.1-8B](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B) on the mlfoundations-dev/stackexchange_astronomy dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
- Loss: 0.9304
|
| 22 |
|
all_results.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.909090909090909,
|
| 3 |
+
"eval_loss": 0.930383026599884,
|
| 4 |
+
"eval_runtime": 21.5155,
|
| 5 |
+
"eval_samples_per_second": 25.795,
|
| 6 |
+
"eval_steps_per_second": 0.418,
|
| 7 |
+
"total_flos": 100292855070720.0,
|
| 8 |
+
"train_loss": 1.0080458323160808,
|
| 9 |
+
"train_runtime": 3801.2496,
|
| 10 |
+
"train_samples_per_second": 8.313,
|
| 11 |
+
"train_steps_per_second": 0.016
|
| 12 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.909090909090909,
|
| 3 |
+
"eval_loss": 0.930383026599884,
|
| 4 |
+
"eval_runtime": 21.5155,
|
| 5 |
+
"eval_samples_per_second": 25.795,
|
| 6 |
+
"eval_steps_per_second": 0.418
|
| 7 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.909090909090909,
|
| 3 |
+
"total_flos": 100292855070720.0,
|
| 4 |
+
"train_loss": 1.0080458323160808,
|
| 5 |
+
"train_runtime": 3801.2496,
|
| 6 |
+
"train_samples_per_second": 8.313,
|
| 7 |
+
"train_steps_per_second": 0.016
|
| 8 |
+
}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 2.909090909090909,
|
| 5 |
+
"eval_steps": 500,
|
| 6 |
+
"global_step": 60,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.48484848484848486,
|
| 13 |
+
"grad_norm": 4.595314924239334,
|
| 14 |
+
"learning_rate": 5e-06,
|
| 15 |
+
"loss": 1.1263,
|
| 16 |
+
"step": 10
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 0.9696969696969697,
|
| 20 |
+
"grad_norm": 15.5166261384021,
|
| 21 |
+
"learning_rate": 5e-06,
|
| 22 |
+
"loss": 1.0663,
|
| 23 |
+
"step": 20
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"epoch": 0.9696969696969697,
|
| 27 |
+
"eval_loss": 1.1175479888916016,
|
| 28 |
+
"eval_runtime": 22.4342,
|
| 29 |
+
"eval_samples_per_second": 24.739,
|
| 30 |
+
"eval_steps_per_second": 0.401,
|
| 31 |
+
"step": 20
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"epoch": 1.4545454545454546,
|
| 35 |
+
"grad_norm": 9.76010359551301,
|
| 36 |
+
"learning_rate": 5e-06,
|
| 37 |
+
"loss": 1.0693,
|
| 38 |
+
"step": 30
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"epoch": 1.9393939393939394,
|
| 42 |
+
"grad_norm": 1.992807964625793,
|
| 43 |
+
"learning_rate": 5e-06,
|
| 44 |
+
"loss": 0.9594,
|
| 45 |
+
"step": 40
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"epoch": 1.9878787878787878,
|
| 49 |
+
"eval_loss": 0.9644138813018799,
|
| 50 |
+
"eval_runtime": 22.5564,
|
| 51 |
+
"eval_samples_per_second": 24.605,
|
| 52 |
+
"eval_steps_per_second": 0.399,
|
| 53 |
+
"step": 41
|
| 54 |
+
},
|
| 55 |
+
{
|
| 56 |
+
"epoch": 2.4242424242424243,
|
| 57 |
+
"grad_norm": 1.0886748547587948,
|
| 58 |
+
"learning_rate": 5e-06,
|
| 59 |
+
"loss": 0.9436,
|
| 60 |
+
"step": 50
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
"epoch": 2.909090909090909,
|
| 64 |
+
"grad_norm": 1.2145602359017604,
|
| 65 |
+
"learning_rate": 5e-06,
|
| 66 |
+
"loss": 0.8834,
|
| 67 |
+
"step": 60
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"epoch": 2.909090909090909,
|
| 71 |
+
"eval_loss": 0.930383026599884,
|
| 72 |
+
"eval_runtime": 21.7398,
|
| 73 |
+
"eval_samples_per_second": 25.529,
|
| 74 |
+
"eval_steps_per_second": 0.414,
|
| 75 |
+
"step": 60
|
| 76 |
+
},
|
| 77 |
+
{
|
| 78 |
+
"epoch": 2.909090909090909,
|
| 79 |
+
"step": 60,
|
| 80 |
+
"total_flos": 100292855070720.0,
|
| 81 |
+
"train_loss": 1.0080458323160808,
|
| 82 |
+
"train_runtime": 3801.2496,
|
| 83 |
+
"train_samples_per_second": 8.313,
|
| 84 |
+
"train_steps_per_second": 0.016
|
| 85 |
+
}
|
| 86 |
+
],
|
| 87 |
+
"logging_steps": 10,
|
| 88 |
+
"max_steps": 60,
|
| 89 |
+
"num_input_tokens_seen": 0,
|
| 90 |
+
"num_train_epochs": 3,
|
| 91 |
+
"save_steps": 500,
|
| 92 |
+
"stateful_callbacks": {
|
| 93 |
+
"TrainerControl": {
|
| 94 |
+
"args": {
|
| 95 |
+
"should_epoch_stop": false,
|
| 96 |
+
"should_evaluate": false,
|
| 97 |
+
"should_log": false,
|
| 98 |
+
"should_save": true,
|
| 99 |
+
"should_training_stop": true
|
| 100 |
+
},
|
| 101 |
+
"attributes": {}
|
| 102 |
+
}
|
| 103 |
+
},
|
| 104 |
+
"total_flos": 100292855070720.0,
|
| 105 |
+
"train_batch_size": 8,
|
| 106 |
+
"trial_name": null,
|
| 107 |
+
"trial_params": null
|
| 108 |
+
}
|
training_eval_loss.png
ADDED
|
training_loss.png
ADDED
|