

Update README.md
Browse files
README.md
CHANGED
|
@@ -155,7 +155,7 @@ language:
|
|
| 155 |
[XEUS - A Cross-lingual Encoder for Universal Speech]()
|
| 156 |
|
| 157 |
|
| 158 |
-
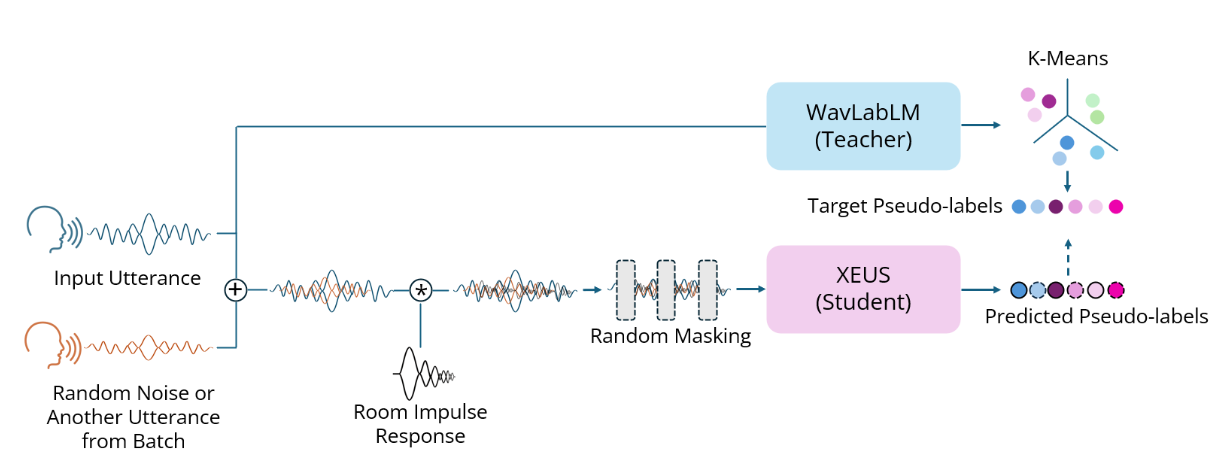
XEUS is a large-scale multilingual speech encoder by Carnegie Mellon University's [WAVLab]() that covers over **4000** languages. It is pre-trained on over 1 million hours of publicly available speech datasets. It
|
| 159 |
|
| 160 |
|
| 161 |
|
|
|
|
| 155 |
[XEUS - A Cross-lingual Encoder for Universal Speech]()
|
| 156 |
|
| 157 |
|
| 158 |
+
XEUS is a large-scale multilingual speech encoder by Carnegie Mellon University's [WAVLab]() that covers over **4000** languages. It is pre-trained on over 1 million hours of publicly available speech datasets. It requires fine-tuning to be used in downstream tasks such as Speech Recognition or Translation. Its hidden states can also be used with k-means for semantic Speech Tokenization. XEUS uses the [E-Branchformer]() architecture and is trained using [HuBERT]()-style masked prediction of discrete speech tokens extracted from [WavLabLM](). During training, the input speech is also augmented with acoustic noise and reverberation, making XEUS more robust. The total model size is 577M parameters.
|
| 159 |
|
| 160 |

|
| 161 |
|