

Update README.md
Browse files
README.md
CHANGED
|
@@ -4049,12 +4049,13 @@ language:
|
|
| 4049 |
It is pre-trained on over 1 million hours of publicly available speech datasets.
|
| 4050 |
It requires fine-tuning to be used in downstream tasks such as Speech Recognition or Translation.
|
| 4051 |
Its hidden states can also be used with k-means for semantic Speech Tokenization.
|
| 4052 |
-
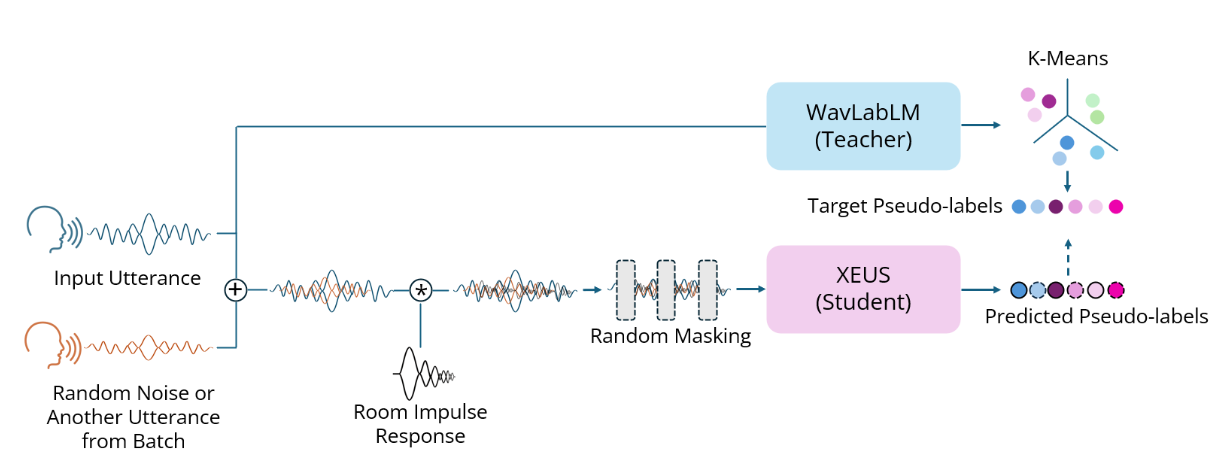
XEUS uses the [E-Branchformer]() architecture and is trained using [HuBERT]()-style masked prediction of discrete speech tokens extracted from [WavLabLM]().
|
| 4053 |
During training, the input speech is also augmented with acoustic noise and reverberation, making XEUS more robust. The total model size is 577M parameters.
|
| 4054 |
|
| 4055 |
|
| 4056 |
|
| 4057 |
-
XEUS tops the [ML-SUPERB](https://arxiv.org/abs/2305.10615) multilingual speech recognition leaderboard, outperforming [MMS](https://arxiv.org/abs/2305.13516), [w2v-BERT 2.0](https://arxiv.org/abs/2312.05187), and [XLS-R](https://arxiv.org/abs/2111.09296).
|
|
|
|
| 4058 |
|
| 4059 |
More information about XEUS, including ***download links for our crawled 4000-language dataset***, can be found in the [project page](https://www.wavlab.org/activities/2024/xeus/) and [paper](https://wanchichen.github.io/pdf/xeus.pdf).
|
| 4060 |
|
|
|
|
| 4049 |
It is pre-trained on over 1 million hours of publicly available speech datasets.
|
| 4050 |
It requires fine-tuning to be used in downstream tasks such as Speech Recognition or Translation.
|
| 4051 |
Its hidden states can also be used with k-means for semantic Speech Tokenization.
|
| 4052 |
+
XEUS uses the [E-Branchformer](https://arxiv.org/abs/2210.00077) architecture and is trained using [HuBERT](https://arxiv.org/pdf/2106.07447)-style masked prediction of discrete speech tokens extracted from [WavLabLM](https://arxiv.org/abs/2309.15317).
|
| 4053 |
During training, the input speech is also augmented with acoustic noise and reverberation, making XEUS more robust. The total model size is 577M parameters.
|
| 4054 |
|
| 4055 |

|
| 4056 |
|
| 4057 |
+
XEUS tops the [ML-SUPERB](https://arxiv.org/abs/2305.10615) multilingual speech recognition leaderboard, outperforming [MMS](https://arxiv.org/abs/2305.13516), [w2v-BERT 2.0](https://arxiv.org/abs/2312.05187), and [XLS-R](https://arxiv.org/abs/2111.09296).
|
| 4058 |
+
XEUS also sets a new state-of-the-art on 4 tasks in the monolingual [SUPERB](https://superbbenchmark.org/) benchmark.
|
| 4059 |
|
| 4060 |
More information about XEUS, including ***download links for our crawled 4000-language dataset***, can be found in the [project page](https://www.wavlab.org/activities/2024/xeus/) and [paper](https://wanchichen.github.io/pdf/xeus.pdf).
|
| 4061 |
|