---
configs:
- config_name: Metadata
data_files: pm_info_table.csv
- config_name: Source Data
data_files: pm_source_text.csv
task_categories:
- text-classification
- question-answering
- sentence-similarity
- token-classification
language:
- ta
pretty_name: Project Madurai
size_categories:
- n<1K
license: apache-2.0
---
Project Madurai Books Text Dataset
This dataset card aims to convert the Tamil books available on the Project Madurai website to the HF dataset. It has been scrapped from [Project Madurai Website](https://www.projectmadurai.org/pmworks.html).
## Dataset Details
- You can see a table above called "Meta Data", which is just an info table.
You can't able to preview the "Source Data" table, due to it being about 300MB.
[Don't open the Dataset in Excel It will lead to a crash of the OS instead open it using Python in pandas or datasets]
- "Project Madurai" was a great initiative in 2008, to make the Tamil Language available to everyone on the internet.
- They converted almost 1006 books to the format of PDF and HTML pages.
- By utilizing the website this dataset is created .
- The dataset contains more genres of books from Tamil Literature to Fiction which can be very useful for developing an NLP model for Tamil.
## Dataset Structure
#### First Table Structure
- This Table Contains the Meta Data of the Dataset Which Tells the Index, Work.No[no of the book],Author of the Book,Title of the book, Unicode[The Html Page name which the source of the book is available].
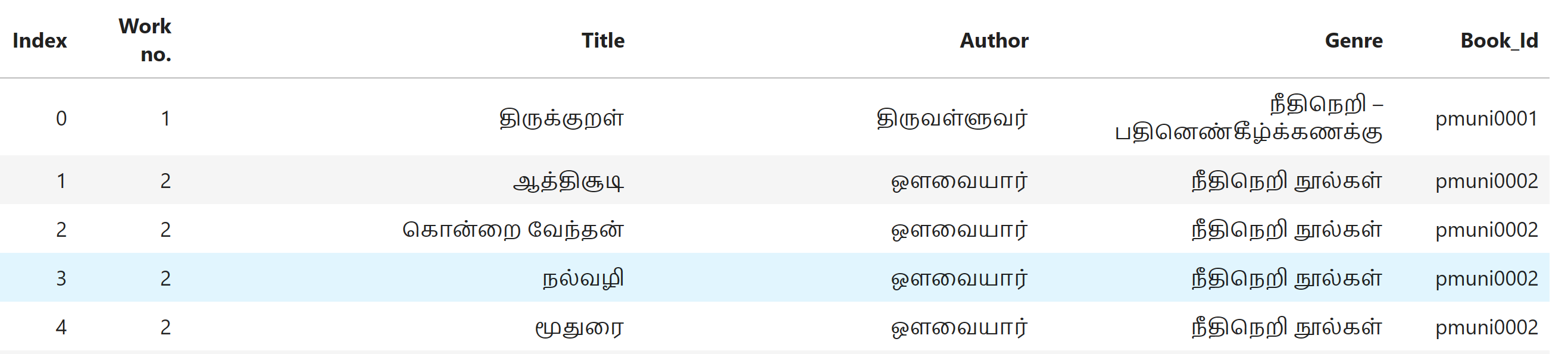
- This Table can be used to find the source of the data in the "Source Data"[second table].
- In one cell there can be 2 or more book id.
#### Second Table Structure
- You can download the second table from "Files and Versions". This can't be preview due to the size.
- This Table Contains the Source Data of the Dataset Which Tells the Index, Book_Id[HTML page name],Link of the Book,tamil_text of the book.
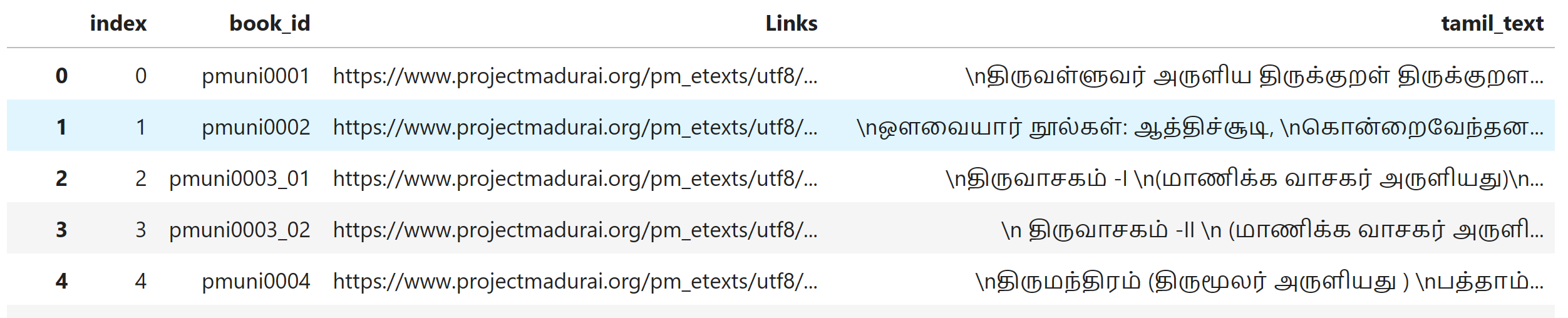
- In this Table, each row contains a single book or half of the book[due to one book in different html pages].
- The 'tamil_text' column contains more than 95% of Tamil text, and others are Roman letters, numerals, and english text. While scarping it the Tamil text and english text both in single tag, it can be cleaned in future.
- The 'tamil_text' column may contain delimeters like ['',.?!/n-] to process the data easier.
- The Table contains more than 1006 rows due to some books split into different parts.
- You can find the book author's name in the first table using the Book_ID
### Special Thanks
- Project Madurai Team.