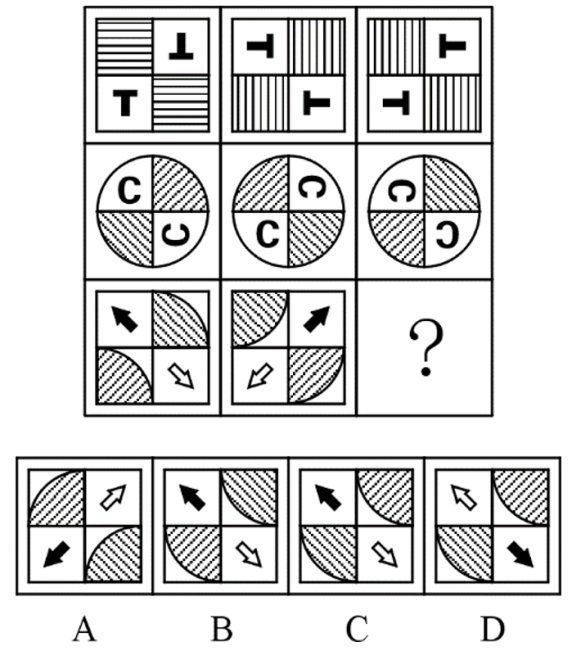
Prompt: Choose the most appropriate option from the given four choices to fill in the question mark, so that it presents a certain regularity:
🔍 Click to expand/collapse more examples
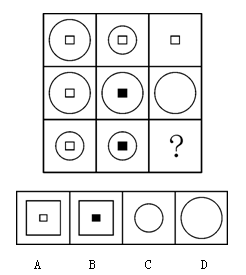
2. Mathematical Reasoning
Prompt1: Choose the most appropriate option from the given four options to present a certain regularity:
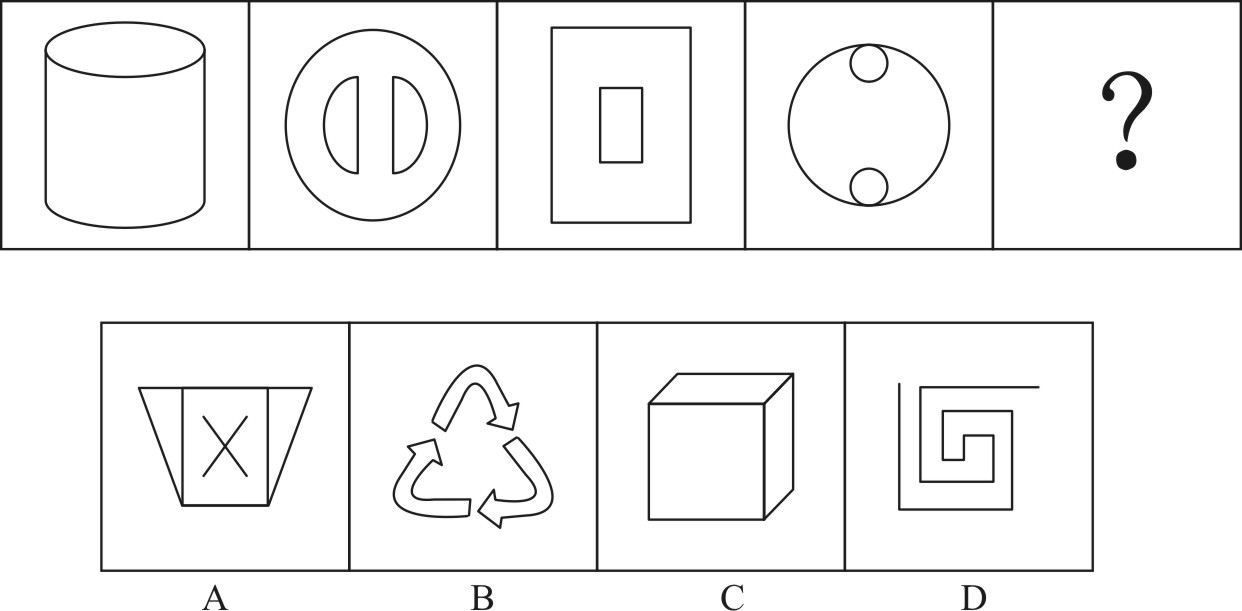
 3. 2D-geometry Reasoning
3. 2D-geometry Reasoning
Prompt: The option that best fits the given pattern of figures is ( ).
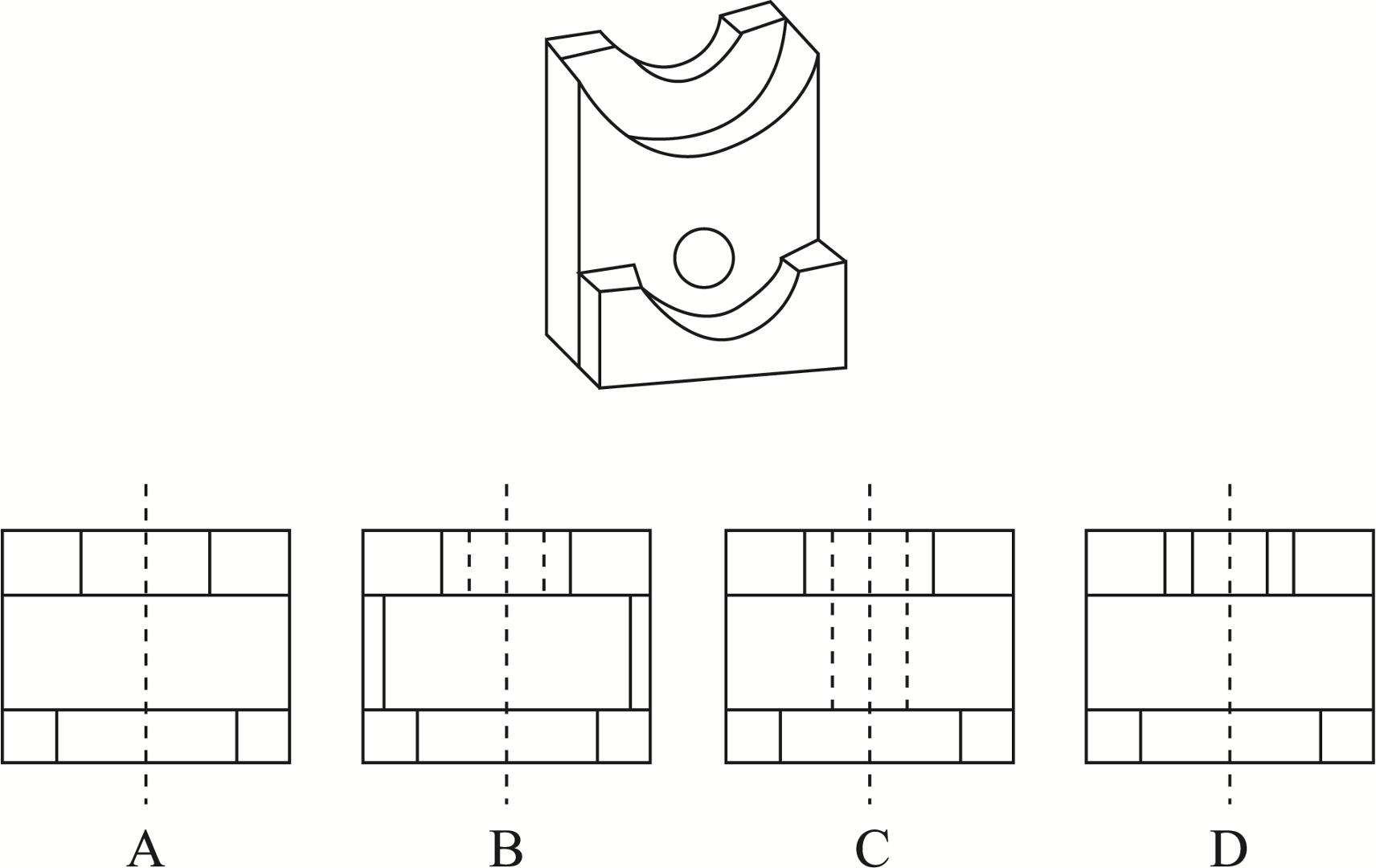
 4. 3D-geometry Reasoning
4. 3D-geometry Reasoning
Prompt: The one that matches the top view is:
 5. visual instruction Reasoning
5. visual instruction Reasoning
Prompt: Choose the most appropriate option from the given four options to present a certain regularity:
 6. Spatial Relationship Reasoning
6. Spatial Relationship Reasoning
Prompt: Choose the most appropriate option from the given four options to present a certain regularity:
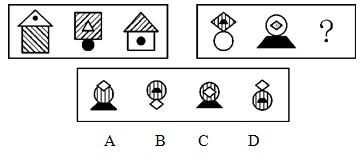 7. Concrete Object Reasoning
7. Concrete Object Reasoning
Prompt: Choose the most appropriate option from the given four choices to fill in the question mark, so that it presents a certain regularity:
 8. Temporal Movement Reasoning
8. Temporal Movement Reasoning
Prompt:Choose the most appropriate option from the given four choices to fill in the question mark, so that it presents a certain regularity:
## Leaderboard
🏆 The leaderboard for the *MMIQ* (2,710 problems) is available [here](https://acechq.github.io/MMIQ-benchmark/#leaderboard).
## Dataset Usage
### Data Downloading
You can download this dataset by the following command (make sure that you have installed [Huggingface Datasets](https://huggingface.co/docs/datasets/quickstart)):
```python
from datasets import load_dataset
dataset = load_dataset("huanqia/MMIQ")
```
Here are some examples of how to access the downloaded dataset:
```python
# print the first example on the MMIQ dataset
print(dataset[0])
print(dataset[0]['data_id']) # print the problem id
print(dataset[0]['question']) # print the question text
print(dataset[0]['answer']) # print the answer
print(dataset[0]['image']) # print the image
```
### Data Format
The dataset is provided in json format and contains the following attributes:
```json
{
"question": [string] The question text,
"image": [string] The image content
"answer": [string] The correct answer for the problem,
"data_id": [int] The problem id
"category": [string] The category of reasoning pattern
}
```
### Automatic Evaluation
🔔 To automatically evaluate a model on the dataset, please refer to our GitHub repository [here](https://github.com/AceCHQ/MMIQ/tree/main/mmiq).
## Citation
If you use the **MMIQ** dataset in your work, please kindly cite the paper using this BibTeX:
```
@misc{cai2025mmiq,
title = {MMIQ: Are Your Multimodal Large Language Models Smart Enough?},
author = {Huanqia, Cai and Yijun Yang and Winston Hu},
month = {January},
year = {2025}
}
```
## Contact
[Huanqia Cai](caihuanqia19@mails.ucas.ac.cn): caihuanqia19@mails.ucas.ac.cn