
LiquidAmmonia
commited on
Commit
·
847d5bb
1
Parent(s):
f2aab47
add readme related media
Browse files- README.md +136 -0
- docs/image1.png +3 -0
- docs/image2.png +3 -0
- docs/image3.png +3 -0
- docs/image5.png +3 -0
- docs/tab3.png +3 -0
README.md
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MotionBench: Benchmarking and Improving Fine-grained Video Motion Understanding for Vision Language Models
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+

|
| 5 |
+

|
| 6 |
+
|
| 7 |
+
<font size=7><div align='center' > [[🍎 Project Page](https://motion-bench.github.io/)] [[📖 arXiv Paper](https://arxiv.org/abs/2501.02955)] [[📊 Dataset](https://huggingface.co/datasets/THUDM/MotionBench)][[🏆 Leaderboard](https://motion-bench.github.io/#leaderboard)][[🏆 Huggingface Leaderboard](https://huggingface.co/spaces/THUDM/MotionBench)] </div></font>
|
| 8 |
+
|
| 9 |
+
<p align="center">
|
| 10 |
+
<img src="./docs/image1.png" width="96%" height="50%">
|
| 11 |
+
</p>
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
MotionBench aims to guide and motivate the development of more capable video understanding models, emphasizing the importance of fine-grained motion comprehension.
|
| 15 |
+
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
## 🔥 News
|
| 19 |
+
|
| 20 |
+
* **`2025.01.06`** 🌟 We released MotionBench, a new benchmark for fine-grained motion comprehension!
|
| 21 |
+
|
| 22 |
+
## Introduction
|
| 23 |
+
|
| 24 |
+
In recent years, vision language models (VLMs) have made significant advancements in video understanding. However, a crucial capability — fine-grained motion comprehension — remains under-explored in current benchmarks. To address this gap, we propose MotionBench, a comprehensive evaluation benchmark designed to assess the fine-grained motion comprehension of video understanding models.
|
| 25 |
+
|
| 26 |
+
### Features
|
| 27 |
+
|
| 28 |
+
1. **Core Capabilities**: Six core capabilities for fine-grained motion understanding, enabling the evaluation of motion-level perception.
|
| 29 |
+
2. **Diverse Data**: MotionBench collects diverse video from the web, public datasets, and self-synthetic videos generated via Unity3, capturing a broad distribution of real-world
|
| 30 |
+
application.
|
| 31 |
+
3. **High-Quality Annotations**: Reliable benchmark with meticulous human annotation and multi-stage quality control processes.
|
| 32 |
+
|
| 33 |
+
<p align="center">
|
| 34 |
+
<img src="./docs/image2.png" width="50%" height="20%">
|
| 35 |
+
</p>
|
| 36 |
+
|
| 37 |
+
## Dataset
|
| 38 |
+
|
| 39 |
+
### License
|
| 40 |
+
|
| 41 |
+
Our dataset is under the CC-BY-NC-SA-4.0 license.
|
| 42 |
+
|
| 43 |
+
LVBench is only used for academic research. Commercial use in any form is prohibited. We do not own the copyright of any raw video files.
|
| 44 |
+
|
| 45 |
+
If there is any infringement in MotionBench, please contact [email protected] or directly raise an issue, and we will remove it immediately.
|
| 46 |
+
|
| 47 |
+
### Download
|
| 48 |
+
|
| 49 |
+
Install video2dataset first:
|
| 50 |
+
|
| 51 |
+
```shell
|
| 52 |
+
pip install video2dataset
|
| 53 |
+
pip uninstall transformer-engine
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
Then you should download `video_info.meta.jsonl` from [Huggingface](https://huggingface.co/datasets/THUDM/MotionBench) and
|
| 57 |
+
put it in the `data` directory.
|
| 58 |
+
|
| 59 |
+
Each entry in the `video_info.meta.jsonl` file contains a video sample. Some of the dataset has the ground truth answer (the DEV set) and some not (the TEST set). You could use the DEV set to optimize your dataset and upload the answer file to our [leaderboard](https://huggingface.co/spaces/THUDM/MotionBench) to see your model's performance.
|
| 60 |
+
|
| 61 |
+
#### Caption dataset
|
| 62 |
+
Part of our dataset are derived from our self-annotated detailed video caption. we additionally release a dataset of 5,000 videos with manually annotated fine-grained motion descriptions, which are annotated and double-checked together with the benchmark annotation process. Each video includes dynamic information descriptions with annotation density reaching 12.63 words per second, providing researchers with resources for further development and training to enhance video models’ motion-level comprehension capabilities.
|
| 63 |
+
|
| 64 |
+
#### Self-collected dataset
|
| 65 |
+
We provide the download link for all self-collected data.
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
#### Publically available dataset
|
| 69 |
+
For publically available data. we do not provide the orginal video files. You could download them from the original repo:
|
| 70 |
+
```
|
| 71 |
+
1. MedVid: https://github.com/deepaknlp/MedVidQACL
|
| 72 |
+
2. SportsSloMo: https://cvlab.cse.msu.edu/project-svw.html
|
| 73 |
+
3. HA-ViD: https://iai-hrc.github.io/ha-vid
|
| 74 |
+
```
|
| 75 |
+
After downloading the above mentioned dataset, find the mapping from the downloaded names to the filenames in our benchmark with the mapping file:
|
| 76 |
+
```
|
| 77 |
+
data/mapping.json
|
| 78 |
+
```
|
| 79 |
+
Then, cut the video to clips using the last two integers separated by `_`.
|
| 80 |
+
|
| 81 |
+
e.g., the video file `S10A13I22S1.mp4` is mapped to file `ef476626-3499-40c2-bbd6-5004223d1ada` according to the mapping file. To obtain the final test case `ef476626-3499-40c2-bbd6-5004223d1ada_58_59` in `video_info.meta.jsonl`, you should cut the video clip from `58` second to `59` second, yielding the final video sample for benchmarking.
|
| 82 |
+
|
| 83 |
+
## Install MotionBench
|
| 84 |
+
|
| 85 |
+
```shell
|
| 86 |
+
pip install -e .
|
| 87 |
+
```
|
| 88 |
+
|
| 89 |
+
## Get Evaluation Results and Submit to Leaderboard
|
| 90 |
+
|
| 91 |
+
(Note: if you want to try the evaluation quickly, you can use the `scripts/construct_random_answers.py` to prepare a
|
| 92 |
+
random answer file.)
|
| 93 |
+
|
| 94 |
+
```shell
|
| 95 |
+
cd scripts
|
| 96 |
+
python test_acc.py
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
After the execution, you will get an evaluation results file `random_answers.json` in the `scripts` directory. You can submit the
|
| 100 |
+
results to the [leaderboard](https://huggingface.co/spaces/THUDM/MotionBench).
|
| 101 |
+
|
| 102 |
+
## 📈 Results
|
| 103 |
+
|
| 104 |
+
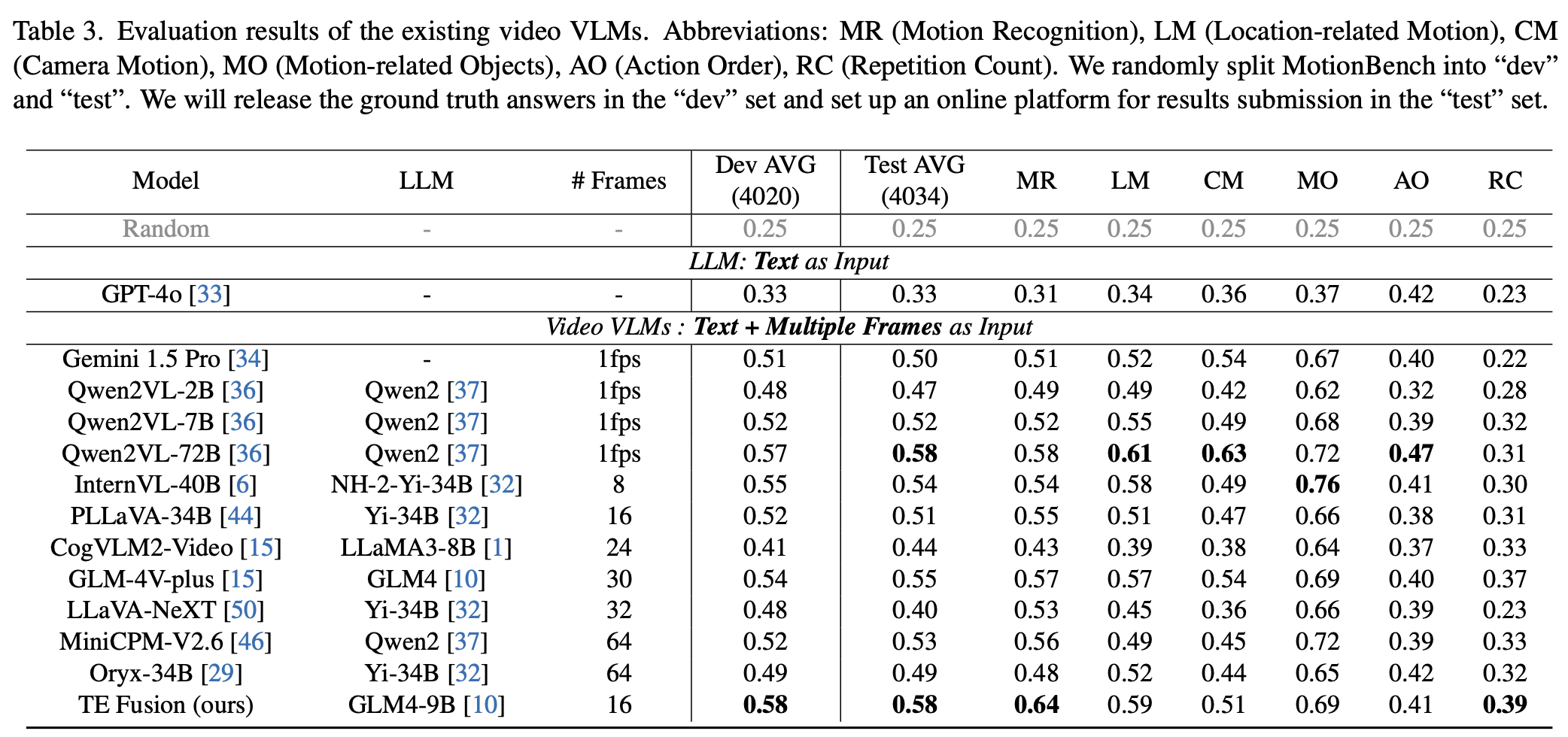
- **Model Comparision:**
|
| 105 |
+
|
| 106 |
+
<p align="center">
|
| 107 |
+
<img src="./docs/tab3.png" width="96%" height="50%">
|
| 108 |
+
</p>
|
| 109 |
+
|
| 110 |
+
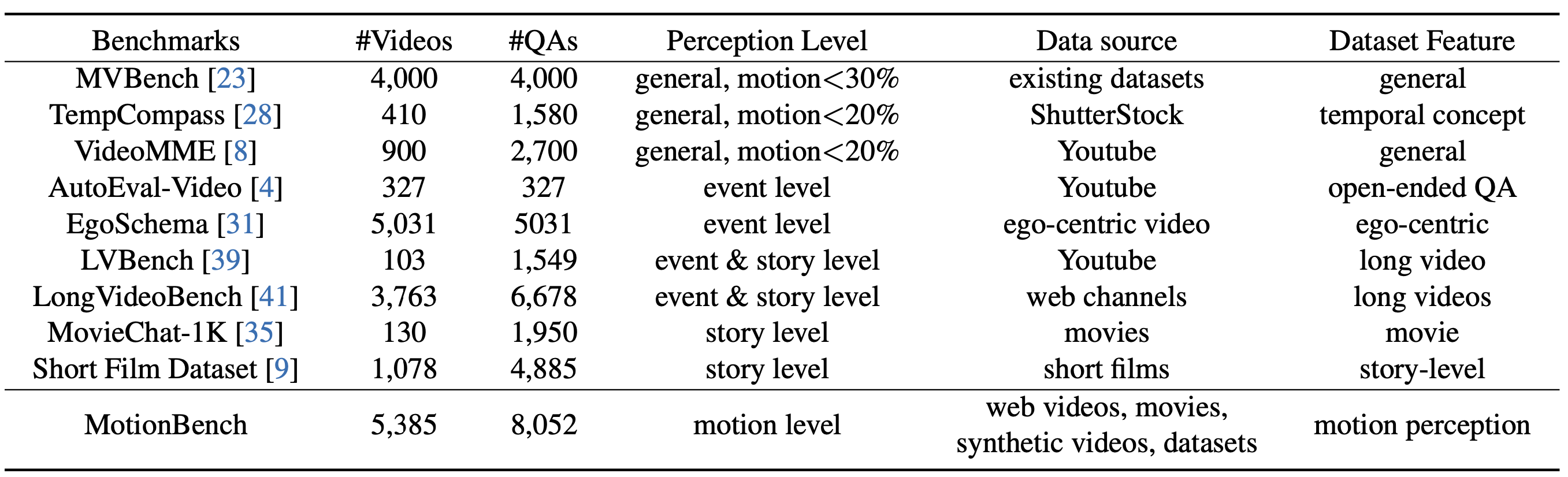
- **Benchmark Comparison:**
|
| 111 |
+
|
| 112 |
+
<p align="center">
|
| 113 |
+
<img src="./docs/image3.png" width="96%" height="50%">
|
| 114 |
+
</p>
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
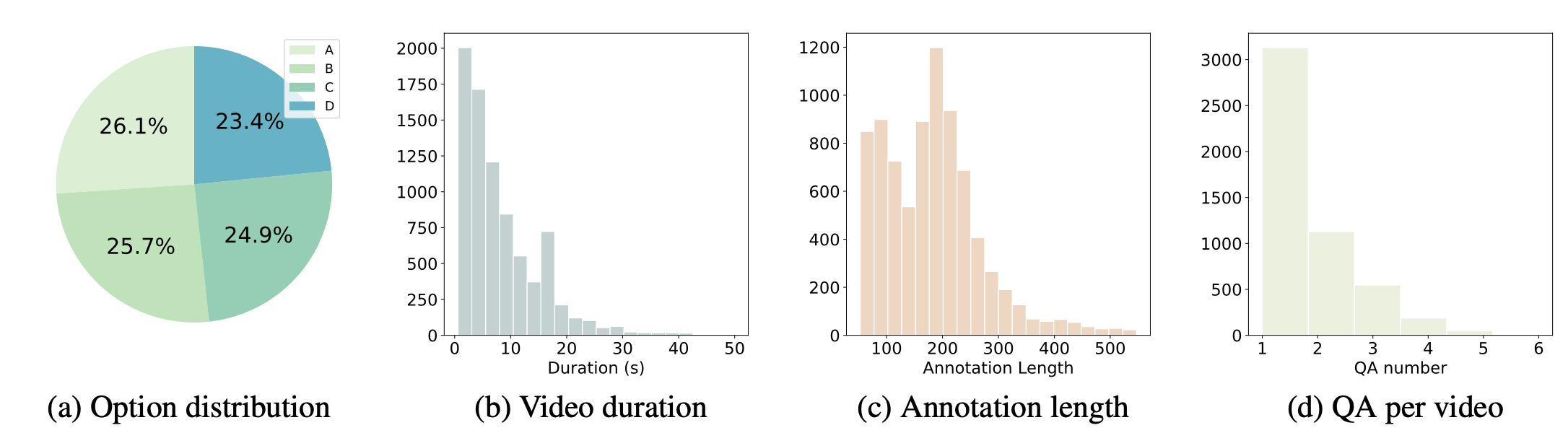
- **Answer Distribution:**
|
| 118 |
+
|
| 119 |
+
<p align="center">
|
| 120 |
+
<img src="./docs/image5.png" width="96%" height="50%">
|
| 121 |
+
</p>
|
| 122 |
+
|
| 123 |
+
## Citation
|
| 124 |
+
|
| 125 |
+
If you find our work helpful for your research, please consider citing our work.
|
| 126 |
+
|
| 127 |
+
```bibtex
|
| 128 |
+
@misc{hong2024motionbench,
|
| 129 |
+
title={MotionBench: Benchmarking and Improving Fine-grained Video Motion Understanding for Vision Language Models},
|
| 130 |
+
author={Wenyi Hong and Yean Cheng and Zhuoyi Yang and Weihan Wang and Lefan Wang and Xiaotao Gu and Shiyu Huang and Yuxiao Dong and Jie Tang},
|
| 131 |
+
year={2024},
|
| 132 |
+
eprint={2501.02955},
|
| 133 |
+
archivePrefix={arXiv},
|
| 134 |
+
primaryClass={cs.CV}
|
| 135 |
+
}
|
| 136 |
+
```
|
docs/image1.png
ADDED

|
Git LFS Details
|
docs/image2.png
ADDED

|
Git LFS Details
|
docs/image3.png
ADDED
|
Git LFS Details
|
docs/image5.png
ADDED
|
Git LFS Details
|
docs/tab3.png
ADDED
|
Git LFS Details
|