

add viewer + update plots
Browse files- analyze_results.ipynb +0 -0
- comparison_rank.png +3 -0
- individual_plots/comparison_ar.png +2 -2
- individual_plots/comparison_fr.png +2 -2
- individual_plots/comparison_hi.png +2 -2
- individual_plots/comparison_ru.png +2 -2
- individual_plots/comparison_sw.png +2 -2
- individual_plots/comparison_te.png +2 -2
- individual_plots/comparison_th.png +2 -2
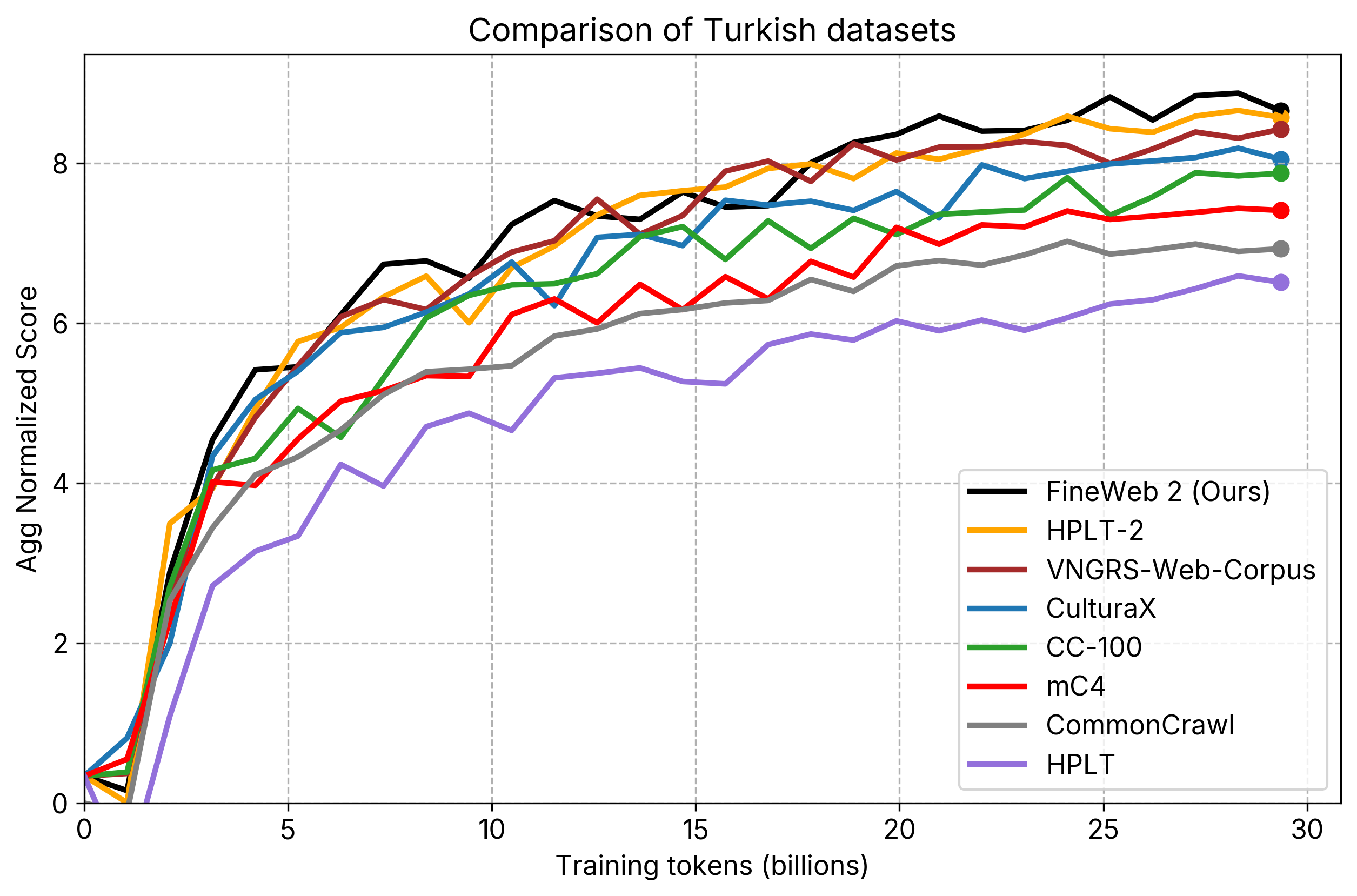
- individual_plots/comparison_tr.png +2 -2
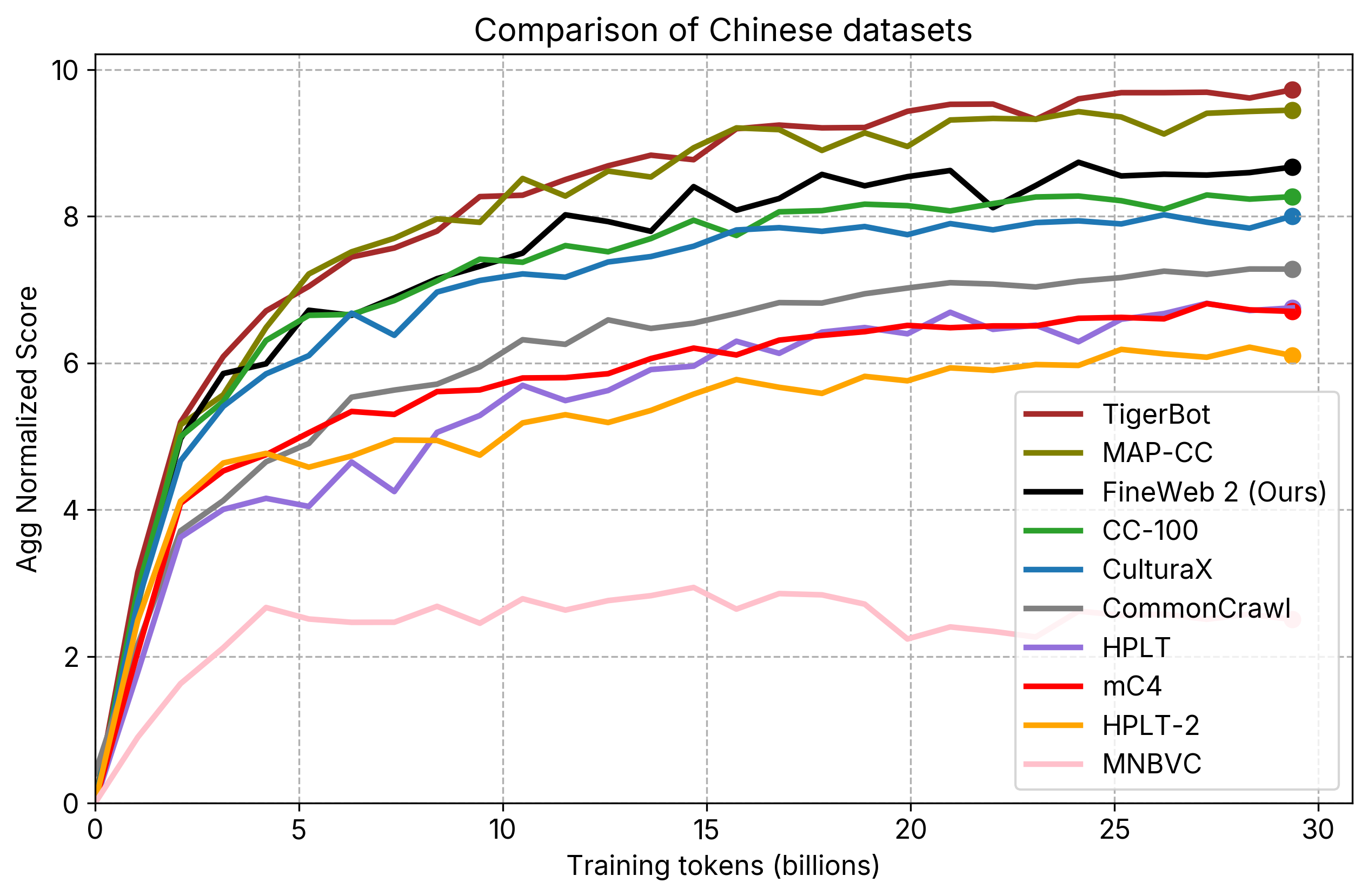
- individual_plots/comparison_zh.png +2 -2
- viewer/__init__.py +0 -0
- viewer/__pycache__/__init__.cpython-310.pyc +0 -0
- viewer/__pycache__/__init__.cpython-312.pyc +0 -0
- viewer/__pycache__/__init__.cpython-313.pyc +0 -0
- viewer/__pycache__/agg_score_metrics.cpython-310.pyc +0 -0
- viewer/__pycache__/agg_score_metrics.cpython-312.pyc +0 -0
- viewer/__pycache__/literals.cpython-310.pyc +0 -0
- viewer/__pycache__/literals.cpython-312.pyc +0 -0
- viewer/__pycache__/literals.cpython-313.pyc +0 -0
- viewer/__pycache__/results.cpython-310.pyc +0 -0
- viewer/__pycache__/results.cpython-312.pyc +0 -0
- viewer/__pycache__/results.cpython-313.pyc +0 -0
- viewer/__pycache__/stats.cpython-310.pyc +0 -0
- viewer/__pycache__/stats.cpython-312.pyc +0 -0
- viewer/__pycache__/stats.cpython-313.pyc +0 -0
- viewer/__pycache__/task_type_mapping.cpython-310.pyc +0 -0
- viewer/__pycache__/task_type_mapping.cpython-312.pyc +0 -0
- viewer/__pycache__/utils.cpython-310.pyc +0 -0
- viewer/__pycache__/utils.cpython-312.pyc +0 -0
- viewer/agg_score_metrics.py +297 -0
- viewer/app.py +277 -0
- viewer/literals.py +9 -0
- viewer/plot.py +131 -0
- viewer/results.py +421 -0
- viewer/stats.py +189 -0
- viewer/task_type_mapping.py +41 -0
- viewer/utils.py +186 -0
analyze_results.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
comparison_rank.png
ADDED
|
|
Git LFS Details
|
individual_plots/comparison_ar.png
CHANGED

|
Git LFS Details
|
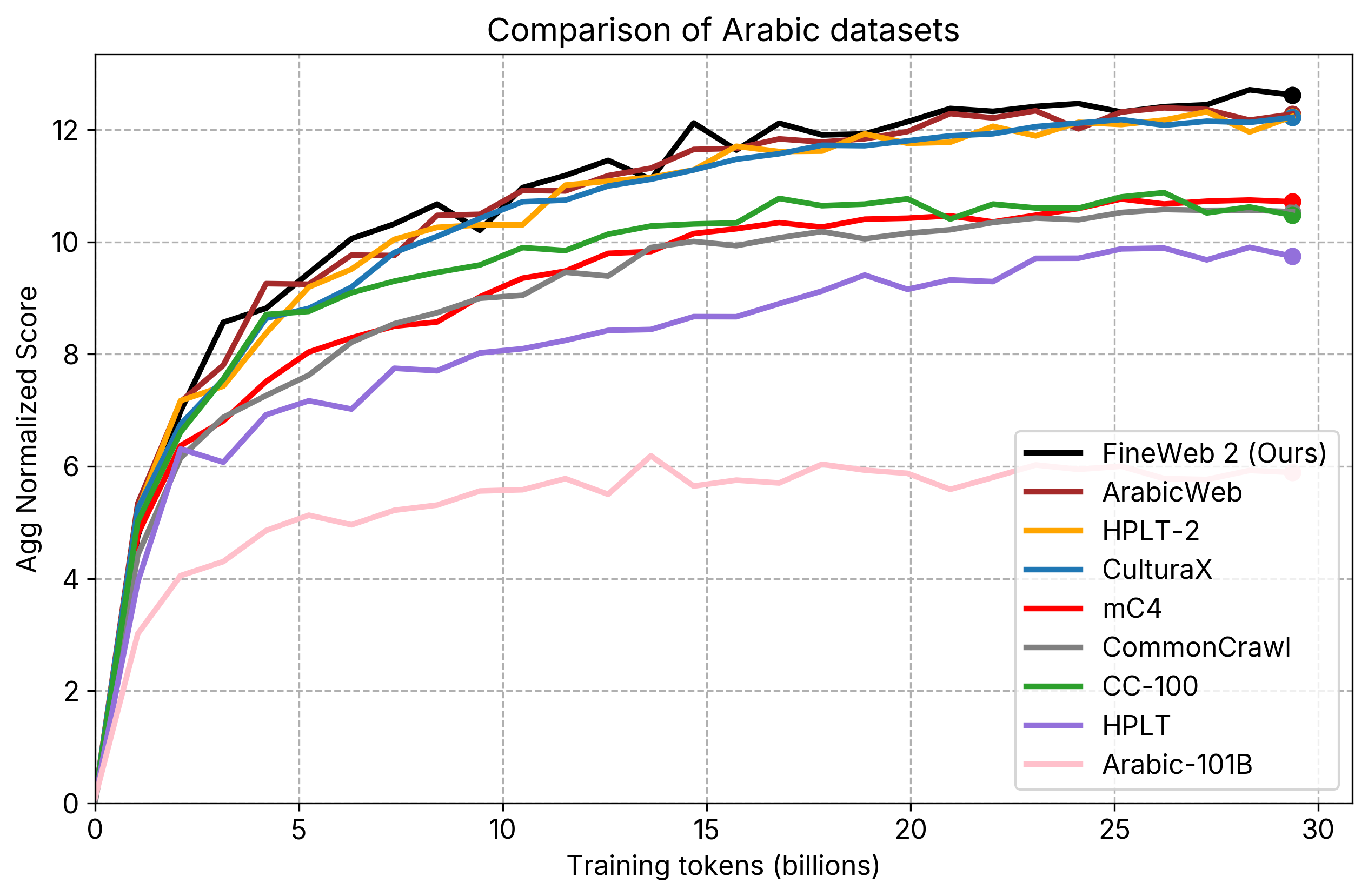
|
Git LFS Details
|
individual_plots/comparison_fr.png
CHANGED

|
Git LFS Details
|
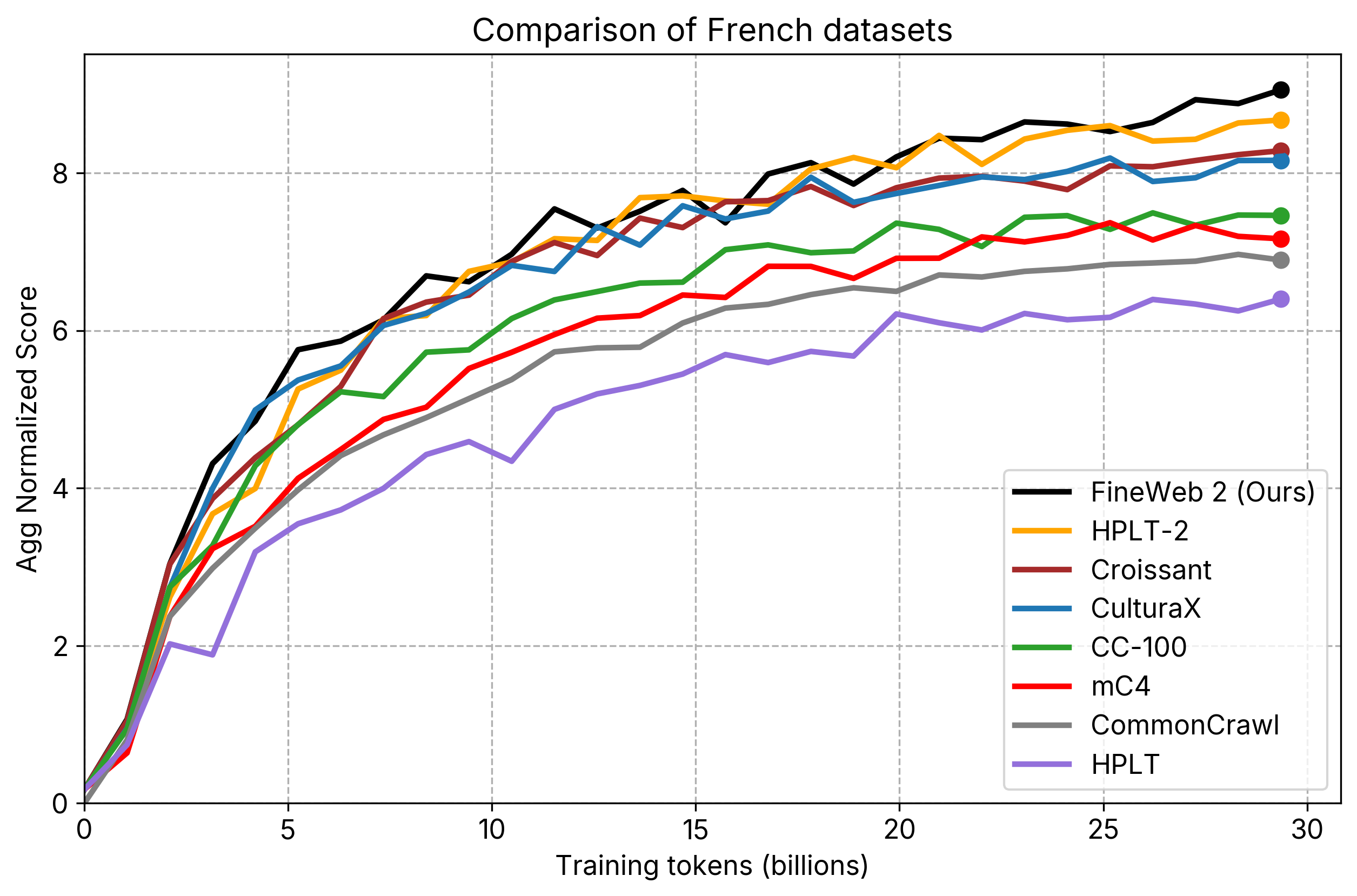
|
Git LFS Details
|
individual_plots/comparison_hi.png
CHANGED
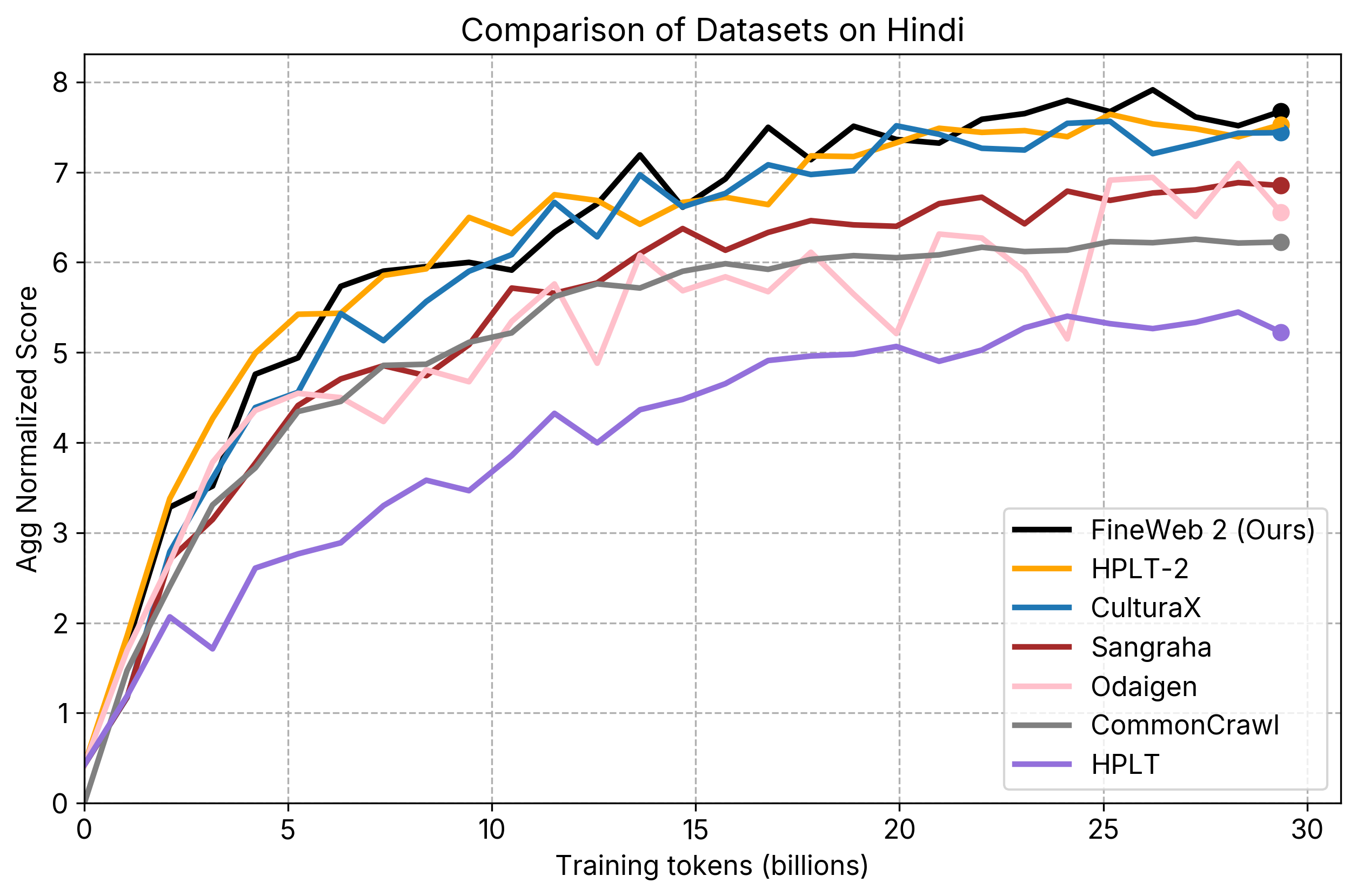
|
Git LFS Details
|
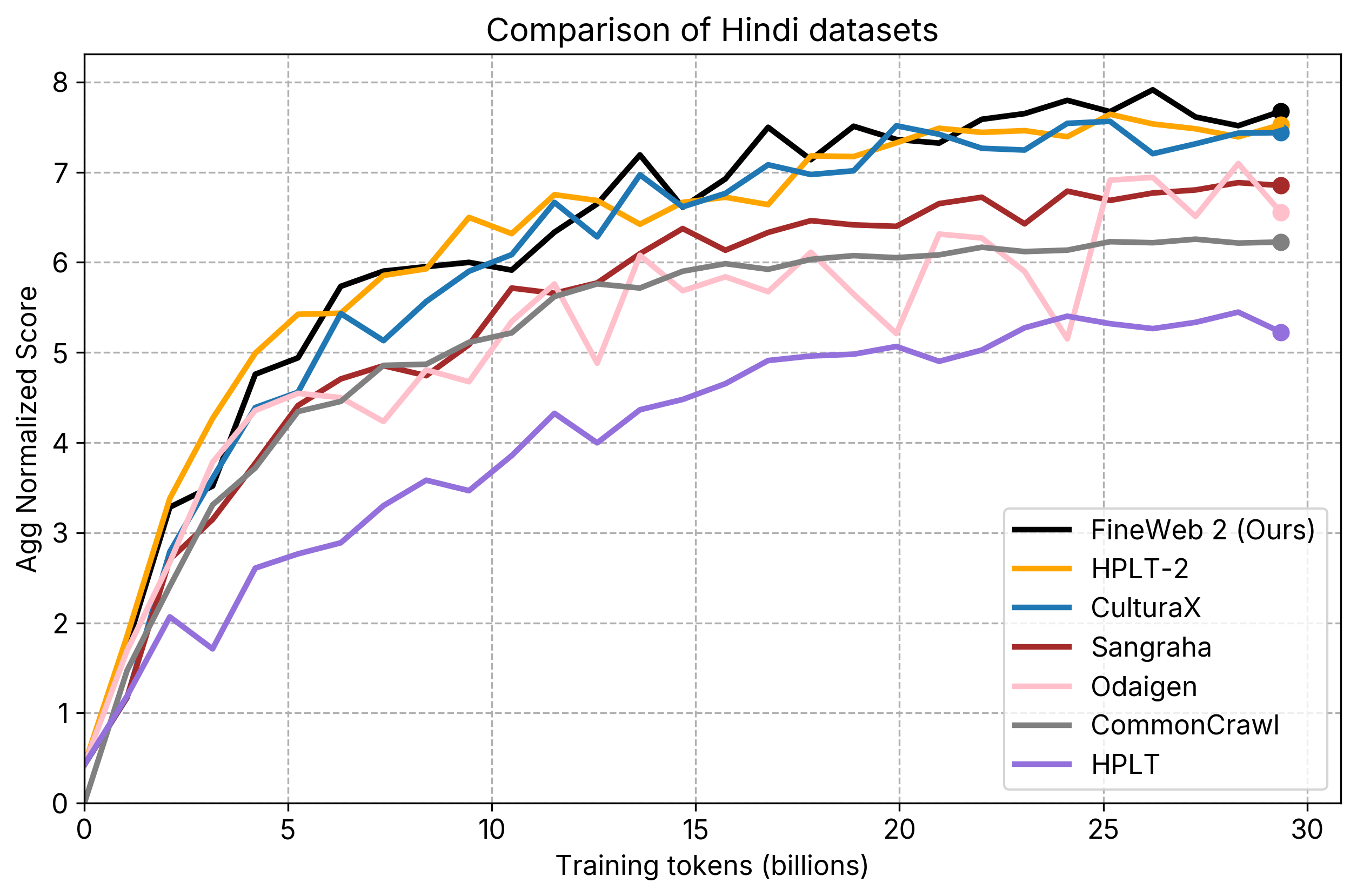
|
Git LFS Details
|
individual_plots/comparison_ru.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
individual_plots/comparison_sw.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
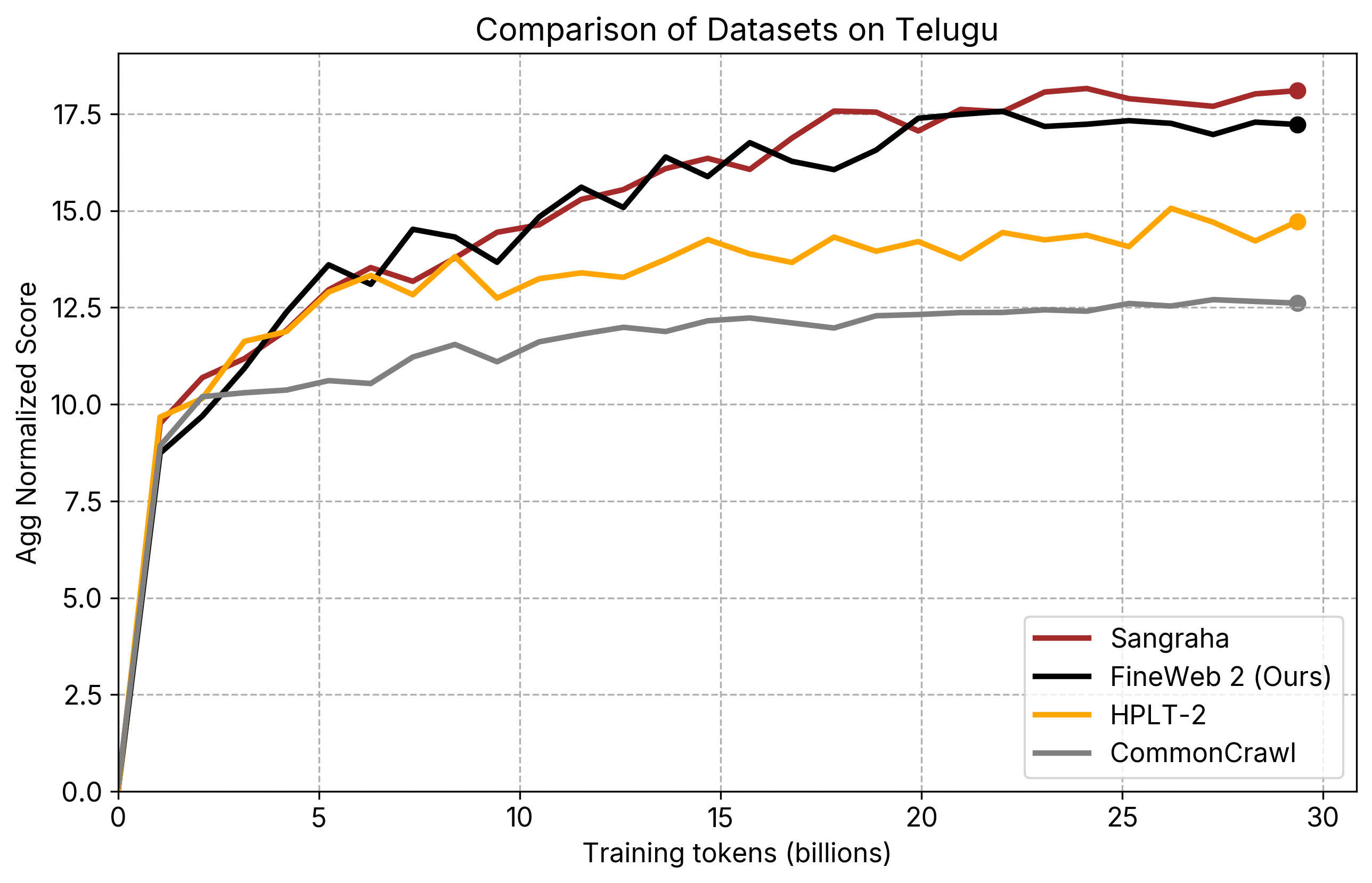
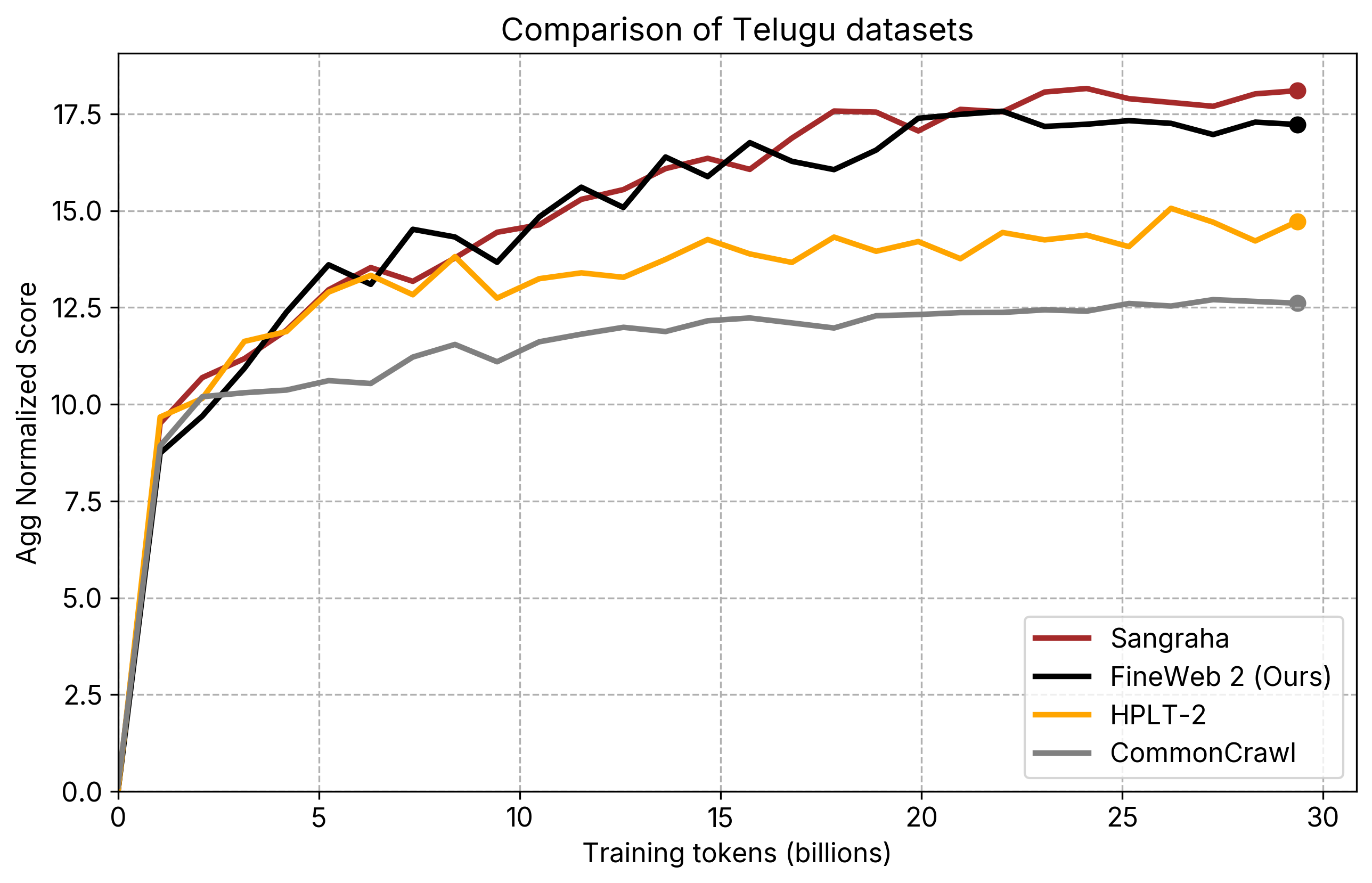
individual_plots/comparison_te.png
CHANGED
|
Git LFS Details
|
|
Git LFS Details
|
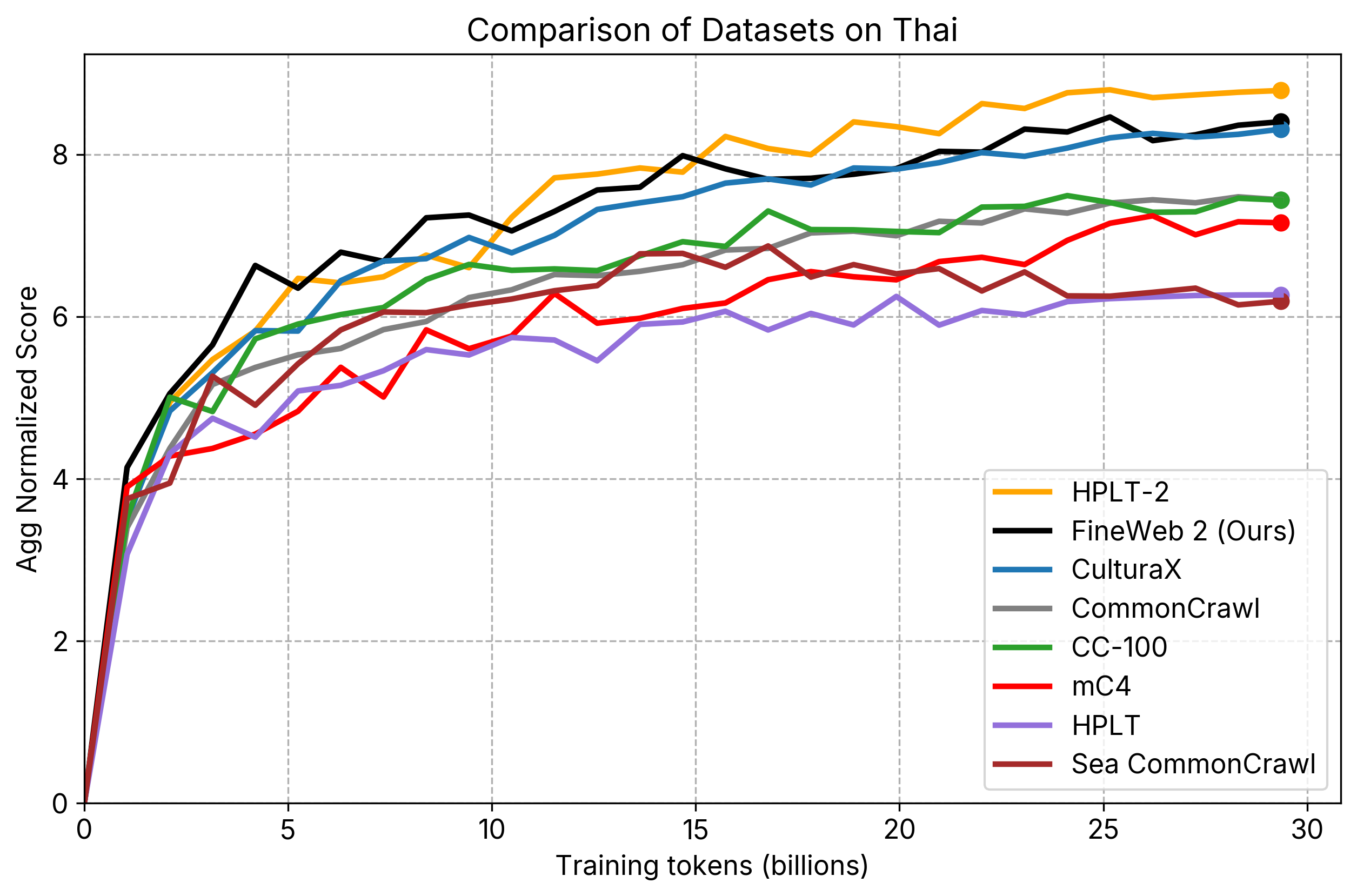
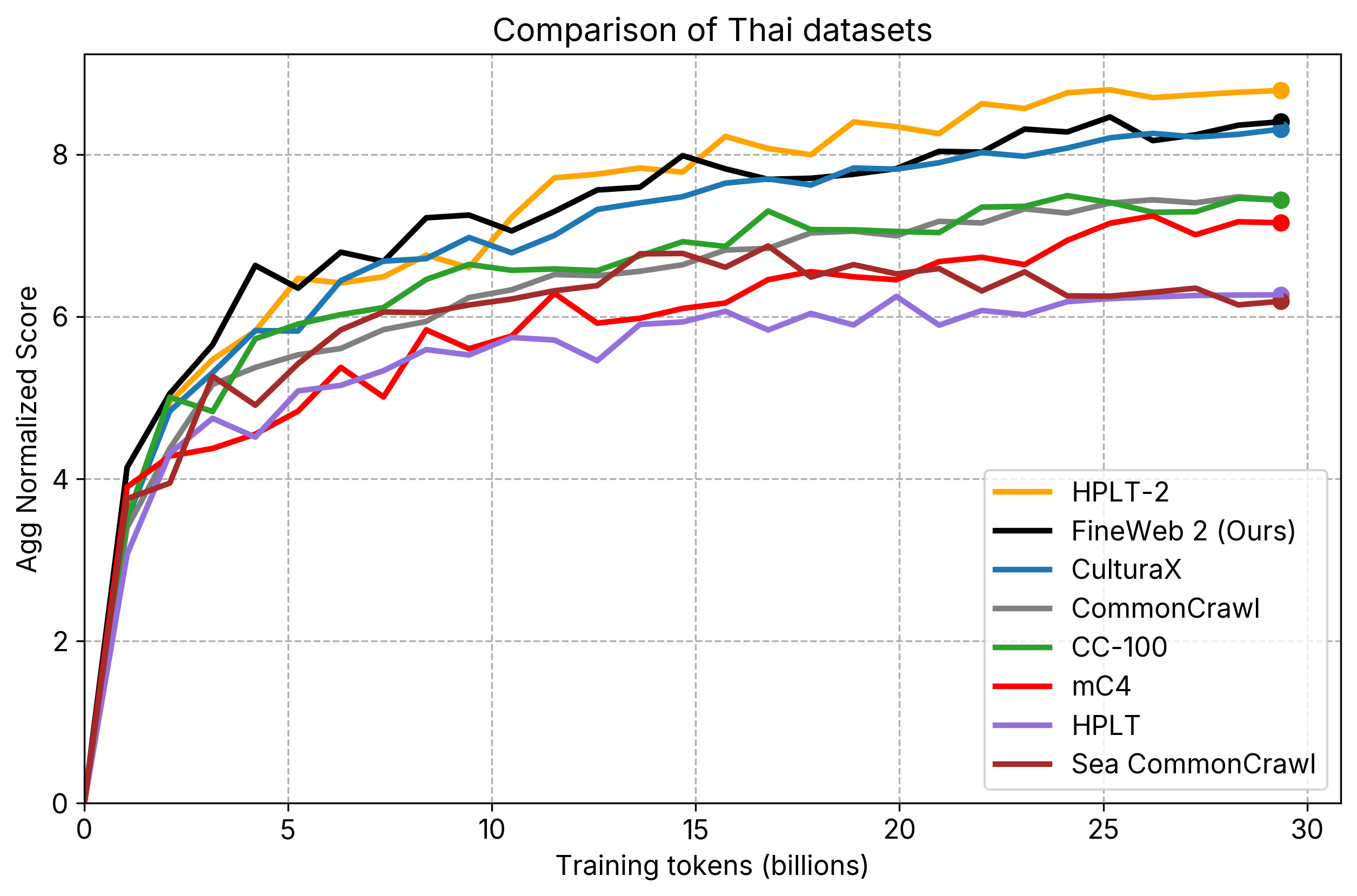
individual_plots/comparison_th.png
CHANGED
|
Git LFS Details
|
|
Git LFS Details
|
individual_plots/comparison_tr.png
CHANGED

|
Git LFS Details
|
|
Git LFS Details
|
individual_plots/comparison_zh.png
CHANGED

|
Git LFS Details
|
|
Git LFS Details
|
viewer/__init__.py
ADDED
|
File without changes
|
viewer/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (171 Bytes). View file
|
|
|
viewer/__pycache__/__init__.cpython-312.pyc
ADDED
|
Binary file (166 Bytes). View file
|
|
|
viewer/__pycache__/__init__.cpython-313.pyc
ADDED
|
Binary file (166 Bytes). View file
|
|
|
viewer/__pycache__/agg_score_metrics.cpython-310.pyc
ADDED
|
Binary file (5.58 kB). View file
|
|
|
viewer/__pycache__/agg_score_metrics.cpython-312.pyc
ADDED
|
Binary file (5.79 kB). View file
|
|
|
viewer/__pycache__/literals.cpython-310.pyc
ADDED
|
Binary file (556 Bytes). View file
|
|
|
viewer/__pycache__/literals.cpython-312.pyc
ADDED
|
Binary file (583 Bytes). View file
|
|
|
viewer/__pycache__/literals.cpython-313.pyc
ADDED
|
Binary file (583 Bytes). View file
|
|
|
viewer/__pycache__/results.cpython-310.pyc
ADDED
|
Binary file (16.4 kB). View file
|
|
|
viewer/__pycache__/results.cpython-312.pyc
ADDED
|
Binary file (25.4 kB). View file
|
|
|
viewer/__pycache__/results.cpython-313.pyc
ADDED
|
Binary file (25.8 kB). View file
|
|
|
viewer/__pycache__/stats.cpython-310.pyc
ADDED
|
Binary file (6.17 kB). View file
|
|
|
viewer/__pycache__/stats.cpython-312.pyc
ADDED
|
Binary file (11 kB). View file
|
|
|
viewer/__pycache__/stats.cpython-313.pyc
ADDED
|
Binary file (11.1 kB). View file
|
|
|
viewer/__pycache__/task_type_mapping.cpython-310.pyc
ADDED
|
Binary file (2.02 kB). View file
|
|
|
viewer/__pycache__/task_type_mapping.cpython-312.pyc
ADDED
|
Binary file (2.47 kB). View file
|
|
|
viewer/__pycache__/utils.cpython-310.pyc
ADDED
|
Binary file (7.1 kB). View file
|
|
|
viewer/__pycache__/utils.cpython-312.pyc
ADDED
|
Binary file (11.2 kB). View file
|
|
|
viewer/agg_score_metrics.py
ADDED
|
@@ -0,0 +1,297 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from typing import Literal
|
| 3 |
+
|
| 4 |
+
AGG_SCORE_METRICS_TYPE = Literal["agg_score_metrics", "agg_score_metrics_prob_raw", "agg_score_metrics_acc"]
|
| 5 |
+
|
| 6 |
+
agg_score_metrics_dict_prob = {
|
| 7 |
+
"ar": [
|
| 8 |
+
'custom|alghafa:mcq_exams_test_ar|0/prob_norm_token',
|
| 9 |
+
'custom|alghafa:meta_ar_msa|0/prob_norm',
|
| 10 |
+
'custom|alghafa:multiple_choice_grounded_statement_soqal_task|0/prob_norm_token',
|
| 11 |
+
'custom|arabic_mmlu_native:_average|0/prob_norm_pmi',
|
| 12 |
+
'custom|arc_easy_ar|0/prob_norm_token',
|
| 13 |
+
'custom|hellaswag-ar|0/prob_norm_token',
|
| 14 |
+
'custom|mlqa-ar|0/qa_ar_f1',
|
| 15 |
+
'custom|piqa_ar|0/prob_norm_token',
|
| 16 |
+
'custom|race_ar|0/prob_norm_token',
|
| 17 |
+
'custom|sciq_ar|0/prob_norm_token',
|
| 18 |
+
'custom|tydiqa-ar|0/qa_ar_f1',
|
| 19 |
+
'custom|x-codah-ar|0/prob_norm_token',
|
| 20 |
+
'custom|x-csqa-ar|0/prob_norm_pmi',
|
| 21 |
+
'custom|xnli-2.0-bool-v2-ar|0/prob',
|
| 22 |
+
'custom|arcd|0/qa_ar_f1',
|
| 23 |
+
'custom|xstory_cloze-ar|0/prob_norm_token'
|
| 24 |
+
],
|
| 25 |
+
"fr": [
|
| 26 |
+
'custom|belebele-fr|0/prob_norm_token',
|
| 27 |
+
'custom|fquadv2|0/qa_fr_f1',
|
| 28 |
+
'custom|french-hellaswag|0/prob_norm_token',
|
| 29 |
+
'custom|mintaka-fr|0/qa_fr_f1',
|
| 30 |
+
'custom|meta_mmlu-fr:_average|0/prob_norm_pmi',
|
| 31 |
+
'custom|x-codah-fr|0/prob_norm_token',
|
| 32 |
+
'custom|x-csqa-fr|0/prob_norm_pmi',
|
| 33 |
+
'custom|xnli-2.0-bool-v2-fr|0/prob',
|
| 34 |
+
'custom|arc-fr|0/prob_norm_pmi'
|
| 35 |
+
],
|
| 36 |
+
"hi": [
|
| 37 |
+
'custom|belebele-hi|0/prob_norm_token',
|
| 38 |
+
'custom|hellaswag-hi|0/prob_norm_token',
|
| 39 |
+
'custom|hi-arc:easy|0/arc_norm_token',
|
| 40 |
+
'custom|indicqa.hi|0/qa_hi_f1',
|
| 41 |
+
'custom|meta_mmlu-hi:_average|0/prob_norm_pmi',
|
| 42 |
+
'custom|x-codah-hi|0/prob_norm_token',
|
| 43 |
+
'custom|x-csqa-hi|0/prob_norm_pmi',
|
| 44 |
+
'custom|xcopa-hi|0/prob_norm_token',
|
| 45 |
+
'custom|indicnxnli-hi-bool-v2-hi|0/prob_norm_token',
|
| 46 |
+
'custom|xstory_cloze-hi|0/prob_norm_token'
|
| 47 |
+
],
|
| 48 |
+
"ru": [
|
| 49 |
+
'custom|arc-ru|0/prob_norm_pmi',
|
| 50 |
+
'custom|belebele-ru|0/prob_norm_token',
|
| 51 |
+
'custom|hellaswag-ru|0/prob_norm_token',
|
| 52 |
+
'custom|parus|0/prob_norm_token',
|
| 53 |
+
'custom|rummlu:_average|0/prob_norm_pmi',
|
| 54 |
+
'custom|ruopenbookqa|0/prob_norm_token',
|
| 55 |
+
'custom|tydiqa-ru|0/qa_ru_f1',
|
| 56 |
+
'custom|x-codah-ru|0/prob_norm_token',
|
| 57 |
+
'custom|x-csqa-ru|0/prob_norm_pmi',
|
| 58 |
+
'custom|xnli-2.0-bool-v2-ru|0/prob',
|
| 59 |
+
'custom|sber_squad|0/qa_ru_f1',
|
| 60 |
+
'custom|xstory_cloze-ru|0/prob_norm_token',
|
| 61 |
+
'custom|xquad-ru|0/qa_ru_f1'
|
| 62 |
+
],
|
| 63 |
+
"sw": [
|
| 64 |
+
'custom|belebele-sw|0/prob_norm_token',
|
| 65 |
+
'custom|arc-sw:easy|0/prob_norm_token',
|
| 66 |
+
'custom|kenswquad|0/qa_sw_f1',
|
| 67 |
+
'custom|tydiqa-sw|0/qa_sw_f1',
|
| 68 |
+
'custom|m3exam-sw|0/prob_norm_token',
|
| 69 |
+
'custom|x-csqa-sw|0/prob_norm_pmi',
|
| 70 |
+
'custom|xcopa-sw|0/prob_norm_token',
|
| 71 |
+
'custom|xnli-2.0-bool-v2-sw|0/prob_norm',
|
| 72 |
+
'custom|xstory_cloze-sw|0/prob_norm_token'
|
| 73 |
+
],
|
| 74 |
+
"te": [
|
| 75 |
+
'custom|belebele-te|0/prob_norm_token',
|
| 76 |
+
'custom|custom_hellaswag-te|0/prob_norm_token',
|
| 77 |
+
'custom|indicqa.te|0/qa_te_f1',
|
| 78 |
+
'custom|mmlu-te:_average|0/prob_norm_token',
|
| 79 |
+
'custom|indicnxnli-te-bool-v2-te|0/prob_norm_token',
|
| 80 |
+
'custom|xcopa-te|0/prob_norm_token',
|
| 81 |
+
'custom|xstory_cloze-te|0/prob_norm_token'
|
| 82 |
+
],
|
| 83 |
+
"th": [
|
| 84 |
+
'custom|belebele-th|0/prob_norm_token',
|
| 85 |
+
'custom|m3exam-th|0/prob_norm_token',
|
| 86 |
+
'custom|meta_mmlu-th:_average|0/prob_norm_pmi',
|
| 87 |
+
'custom|xnli-2.0-bool-v2-th|0/prob',
|
| 88 |
+
'custom|custom_hellaswag-th|0/prob_norm_token',
|
| 89 |
+
'custom|thaiqa|0/qa_th_f1',
|
| 90 |
+
'custom|xquad-th|0/qa_th_f1',
|
| 91 |
+
],
|
| 92 |
+
"tr": [
|
| 93 |
+
'custom|arc-v2-tr|0/prob_norm',
|
| 94 |
+
'custom|belebele-tr|0/prob_norm',
|
| 95 |
+
'custom|exams-tr:_average|0/prob_norm',
|
| 96 |
+
'custom|hellaswag-tr|0/prob_norm',
|
| 97 |
+
'custom|mmlu-tr:_average|0/prob_norm_pmi',
|
| 98 |
+
'custom|tqduad2|0/qa_tr_f1',
|
| 99 |
+
'custom|xcopa-tr|0/prob_norm',
|
| 100 |
+
'custom|xnli-2.0-bool-v2-tr|0/prob',
|
| 101 |
+
'custom|xquad-tr|0/qa_tr_f1'
|
| 102 |
+
],
|
| 103 |
+
"zh": [
|
| 104 |
+
'custom|agieval_NEW_LINE:_average|0/prob_norm_pmi',
|
| 105 |
+
'custom|belebele-zh|0/prob_norm_token',
|
| 106 |
+
'custom|c3|0/prob_norm_token',
|
| 107 |
+
'custom|ceval_NEW_LINE:_average|0/prob_norm_token',
|
| 108 |
+
'custom|cmmlu:_average|0/prob_norm_token',
|
| 109 |
+
'custom|cmrc|0/qa_zh_f1',
|
| 110 |
+
'custom|hellaswag-zh|0/prob_norm_token',
|
| 111 |
+
'custom|m3exam-zh|0/prob_norm_token',
|
| 112 |
+
'custom|mlqa-zh|0/qa_zh_f1',
|
| 113 |
+
'custom|x-codah-zh|0/prob_norm_token',
|
| 114 |
+
'custom|x-csqa-zh|0/prob_norm_pmi',
|
| 115 |
+
'custom|xcopa-zh|0/prob_norm_token',
|
| 116 |
+
'custom|ocnli-bool-v2-zh|0/prob',
|
| 117 |
+
'custom|chinese-squad|0/qa_zh_f1',
|
| 118 |
+
'custom|xstory_cloze-zh|0/prob_norm_token',
|
| 119 |
+
'custom|xwinograd-zh|0/prob_norm_token'
|
| 120 |
+
]
|
| 121 |
+
}
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def transform_for_prob_raw(metric: str):
|
| 125 |
+
# The pmi can't be used for unormalized probabilities
|
| 126 |
+
# Secondly the acc_norm_token is better in terms of monotonicity for this evaluation metric
|
| 127 |
+
splitted_metric = metric.split("/")
|
| 128 |
+
|
| 129 |
+
# If it's generative metric we don't do anything
|
| 130 |
+
if not "prob" in splitted_metric[-1]:
|
| 131 |
+
return metric
|
| 132 |
+
return "/".join(splitted_metric[:-1] + ["prob_raw_norm_token"])
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
agg_score_metrics_dict_prob_raw = {
|
| 138 |
+
lang: [transform_for_prob_raw(metric) for metric in metrics]
|
| 139 |
+
for lang, metrics in agg_score_metrics_dict_prob.items()
|
| 140 |
+
}
|
| 141 |
+
|
| 142 |
+
agg_score_metrics_dict_acc = {
|
| 143 |
+
lang: [metric.replace("/prob", "/acc") for metric in metrics]
|
| 144 |
+
for lang, metrics in agg_score_metrics_dict_prob.items()
|
| 145 |
+
}
|
| 146 |
+
|
| 147 |
+
agg_score_metrics_dict_both = {
|
| 148 |
+
lang: agg_score_metrics_dict_prob[lang] + agg_score_metrics_dict_acc[lang]
|
| 149 |
+
for lang in agg_score_metrics_dict_prob.keys()
|
| 150 |
+
}
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
agg_score_metrics = {
|
| 154 |
+
"prob": agg_score_metrics_dict_prob,
|
| 155 |
+
"prob_raw": agg_score_metrics_dict_prob_raw,
|
| 156 |
+
"acc": agg_score_metrics_dict_acc,
|
| 157 |
+
"both": agg_score_metrics_dict_both
|
| 158 |
+
}
|
| 159 |
+
|
| 160 |
+
# Allow to override default groupping behaviour for aggregate tasks
|
| 161 |
+
# The key is the task name and value is the list of tasks to use for the average
|
| 162 |
+
custom_task_aggregate_groups = {
|
| 163 |
+
'custom|agieval_NEW_LINE': [
|
| 164 |
+
'gaokao-biology', 'gaokao-chemistry', 'gaokao-chinese', 'gaokao-geography',
|
| 165 |
+
'gaokao-history', 'gaokao-physics', 'jec-qa-ca',
|
| 166 |
+
'jec-qa-kd', 'logiqa-zh'
|
| 167 |
+
]
|
| 168 |
+
}
|
| 169 |
+
|
| 170 |
+
def is_agg_score_col(col: str, agg_score_type: AGG_SCORE_METRICS_TYPE, lang: str):
|
| 171 |
+
metric_name = col
|
| 172 |
+
if agg_score_type == "agg_score_metrics_prob_raw":
|
| 173 |
+
return metric_name in agg_score_metrics_dict_prob_raw.get(lang, [])
|
| 174 |
+
elif agg_score_type == "agg_score_metrics_acc":
|
| 175 |
+
return metric_name in agg_score_metrics_dict_acc.get(lang, [])
|
| 176 |
+
|
| 177 |
+
return agg_score_metrics_dict_prob.get(lang, [])
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
# agg_score_metrics = {
|
| 181 |
+
# "ar": [
|
| 182 |
+
# 'custom|alghafa:mcq_exams_test_ar|0/acc_norm_token',
|
| 183 |
+
# 'custom|alghafa:meta_ar_msa|0/acc_norm',
|
| 184 |
+
# 'custom|alghafa:multiple_choice_grounded_statement_soqal_task|0/acc_norm_token',
|
| 185 |
+
# 'custom|arabic_mmlu_native:_average|0/acc_norm_pmi',
|
| 186 |
+
# 'custom|arc_easy_ar|0/acc_norm_token',
|
| 187 |
+
# 'custom|hellaswag-ar|0/acc_norm_token',
|
| 188 |
+
# 'custom|mlqa-ar|0/qa_ar_f1',
|
| 189 |
+
# 'custom|piqa_ar|0/acc_norm_token',
|
| 190 |
+
# 'custom|race_ar|0/acc_norm_token',
|
| 191 |
+
# 'custom|sciq_ar|0/acc_norm_token',
|
| 192 |
+
# 'custom|tydiqa-ar|0/qa_ar_f1',
|
| 193 |
+
# 'custom|x-codah-ar|0/acc_norm_token',
|
| 194 |
+
# 'custom|x-csqa-ar|0/acc_norm_pmi',
|
| 195 |
+
# 'custom|xnli-2.0-bool-v2-ar|0/acc',
|
| 196 |
+
# 'custom|arcd|0/qa_ar_f1',
|
| 197 |
+
# 'custom|xstory_cloze-ar|0/acc_norm_token'
|
| 198 |
+
# ],
|
| 199 |
+
# "fr": [
|
| 200 |
+
# 'custom|belebele-fr|0/acc_norm_token',
|
| 201 |
+
# 'custom|fquadv2|0/qa_fr_f1',
|
| 202 |
+
# 'custom|french-hellaswag|0/acc_norm_token',
|
| 203 |
+
# 'custom|mintaka-fr|0/qa_fr_f1',
|
| 204 |
+
# 'custom|meta_mmlu-fr:_average|0/acc_norm_pmi',
|
| 205 |
+
# 'custom|pawns-v2-fr|0/acc',
|
| 206 |
+
# 'custom|x-codah-fr|0/acc_norm_token',
|
| 207 |
+
# 'custom|x-csqa-fr|0/acc_norm_pmi',
|
| 208 |
+
# 'custom|xnli-2.0-bool-v2-fr|0/acc',
|
| 209 |
+
# 'custom|arc-fr|0/acc_norm_pmi'
|
| 210 |
+
# ],
|
| 211 |
+
# "hi": [
|
| 212 |
+
# 'custom|belebele-hi|0/acc_norm_token',
|
| 213 |
+
# 'custom|hellaswag-hi|0/acc_norm_token',
|
| 214 |
+
# 'custom|hi-arc:easy|0/arc_norm_token',
|
| 215 |
+
# 'custom|indicqa.hi|0/qa_hi_f1',
|
| 216 |
+
# 'custom|meta_mmlu-hi:_average|0/acc_norm_pmi',
|
| 217 |
+
# 'custom|x-codah-hi|0/acc_norm_token',
|
| 218 |
+
# 'custom|x-csqa-hi|0/acc_norm_pmi',
|
| 219 |
+
# 'custom|xcopa-hi|0/acc_norm_token',
|
| 220 |
+
# 'custom|indicnxnli-hi-bool-v2-hi|0/acc_norm_token',
|
| 221 |
+
# 'custom|xstory_cloze-hi|0/acc_norm_token'
|
| 222 |
+
# ],
|
| 223 |
+
# "ru": [
|
| 224 |
+
# 'custom|arc-ru|0/acc_norm_pmi',
|
| 225 |
+
# 'custom|belebele-ru|0/acc_norm_token',
|
| 226 |
+
# 'custom|hellaswag-ru|0/acc_norm_token',
|
| 227 |
+
# 'custom|parus|0/acc_norm_token',
|
| 228 |
+
# 'custom|rummlu:_average|0/acc_norm_pmi',
|
| 229 |
+
# 'custom|ruopenbookqa|0/acc_norm_token',
|
| 230 |
+
# 'custom|tydiqa-ru|0/qa_ru_f1',
|
| 231 |
+
# 'custom|x-codah-ru|0/acc_norm_token',
|
| 232 |
+
# 'custom|x-csqa-ru|0/acc_norm_pmi',
|
| 233 |
+
# 'custom|xnli-2.0-bool-v2-ru|0/acc',
|
| 234 |
+
# 'custom|sber_squad|0/qa_ru_f1',
|
| 235 |
+
# 'custom|xstory_cloze-ru|0/acc_norm_token',
|
| 236 |
+
# 'custom|xquad-ru|0/qa_ru_f1'
|
| 237 |
+
# ],
|
| 238 |
+
# "sw": [
|
| 239 |
+
# 'custom|belebele-sw|0/acc_norm_token',
|
| 240 |
+
# 'custom|arc-sw:easy|0/acc_norm_token',
|
| 241 |
+
# 'custom|kenswquad|0/qa_sw_f1',
|
| 242 |
+
# 'custom|tydiqa-sw|0/qa_sw_f1',
|
| 243 |
+
# 'custom|m3exam-sw|0/acc_norm_token',
|
| 244 |
+
# 'custom|x-csqa-sw|0/acc_norm_pmi',
|
| 245 |
+
# 'custom|xcopa-sw|0/acc_norm_token',
|
| 246 |
+
# 'custom|xnli-2.0-bool-v2-sw|0/acc_norm',
|
| 247 |
+
# 'custom|xstory_cloze-sw|0/acc_norm_token'
|
| 248 |
+
# ],
|
| 249 |
+
# "te": [
|
| 250 |
+
# 'custom|belebele-te|0/acc_norm_token',
|
| 251 |
+
# 'custom|custom_hellaswag-te|0/acc_norm_token',
|
| 252 |
+
# 'custom|indicqa.te|0/qa_te_f1',
|
| 253 |
+
# 'custom|mmlu-te:_average|0/acc_norm_token',
|
| 254 |
+
# 'custom|indicnxnli-te-bool-v2-te|0/acc_norm_token',
|
| 255 |
+
# 'custom|xcopa-te|0/acc_norm_token',
|
| 256 |
+
# 'custom|xstory_cloze-te|0/acc_norm_token'
|
| 257 |
+
# ],
|
| 258 |
+
# "th": [
|
| 259 |
+
# 'custom|belebele-th|0/acc_norm_token',
|
| 260 |
+
# 'custom|m3exam-th|0/acc_norm_token',
|
| 261 |
+
# 'custom|meta_mmlu-th:_average|0/acc_norm_pmi',
|
| 262 |
+
# 'custom|xnli-2.0-bool-v2-th|0/acc',
|
| 263 |
+
# 'custom|custom_hellaswag-th|0/acc_norm_token',
|
| 264 |
+
# 'custom|thaiqa|0/qa_th_f1',
|
| 265 |
+
# 'custom|xquad-th|0/qa_th_f1',
|
| 266 |
+
# 'custom|thai-exams:tgat|0/acc_norm_token'
|
| 267 |
+
# ],
|
| 268 |
+
# "tr": [
|
| 269 |
+
# 'custom|arc-v2-tr|0/acc_norm',
|
| 270 |
+
# 'custom|belebele-tr|0/acc_norm',
|
| 271 |
+
# 'custom|exams-tr:_average|0/acc_norm',
|
| 272 |
+
# 'custom|hellaswag-tr|0/acc_norm',
|
| 273 |
+
# 'custom|mmlu-tr:_average|0/acc_norm_pmi',
|
| 274 |
+
# 'custom|tqduad2|0/qa_tr_f1',
|
| 275 |
+
# 'custom|xcopa-tr|0/acc_norm',
|
| 276 |
+
# 'custom|xnli-2.0-bool-v2-tr|0/acc',
|
| 277 |
+
# 'custom|xquad-tr|0/qa_tr_f1'
|
| 278 |
+
# ],
|
| 279 |
+
# "zh": [
|
| 280 |
+
# 'custom|agieval_NEW_LINE:_average|0/acc_norm_pmi',
|
| 281 |
+
# 'custom|belebele-zh|0/acc_norm_token',
|
| 282 |
+
# 'custom|c3|0/acc_norm_token',
|
| 283 |
+
# 'custom|ceval_NEW_LINE:_average|0/acc_norm_token',
|
| 284 |
+
# 'custom|cmmlu:_average|0/acc_norm_token',
|
| 285 |
+
# 'custom|cmrc|0/qa_zh_f1',
|
| 286 |
+
# 'custom|hellaswag-zh|0/acc_norm_token',
|
| 287 |
+
# 'custom|m3exam-zh|0/acc_norm_token',
|
| 288 |
+
# 'custom|mlqa-zh|0/qa_zh_f1',
|
| 289 |
+
# 'custom|x-codah-zh|0/acc_norm_token',
|
| 290 |
+
# 'custom|x-csqa-zh|0/acc_norm_pmi',
|
| 291 |
+
# 'custom|xcopa-zh|0/acc_norm_token',
|
| 292 |
+
# 'custom|ocnli-bool-v2-zh|0/acc',
|
| 293 |
+
# 'custom|chinese-squad|0/qa_zh_f1',
|
| 294 |
+
# 'custom|xstory_cloze-zh|0/acc_norm_token',
|
| 295 |
+
# 'custom|xwinograd-zh|0/acc_norm_token'
|
| 296 |
+
# ]
|
| 297 |
+
# }
|
viewer/app.py
ADDED
|
@@ -0,0 +1,277 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import defaultdict
|
| 2 |
+
from typing import get_args
|
| 3 |
+
|
| 4 |
+
import gradio as gr
|
| 5 |
+
import numpy as np
|
| 6 |
+
|
| 7 |
+
from literals import TASK_CONSISTENCY_BUTTON_LABEL, CHECK_MISSING_DATAPOINTS_BUTTON_LABEL
|
| 8 |
+
from plot import prepare_plot_data, plot_metric
|
| 9 |
+
from viewer.results import fetch_run_results, fetch_run_list, init_input_normalization_runs, select_runs_by_regex, \
|
| 10 |
+
select_runs_by_language, \
|
| 11 |
+
init_input_component_values, init_std_dev_runs, render_results_table, export_results_csv, \
|
| 12 |
+
check_missing_datapoints
|
| 13 |
+
from viewer.stats import generate_and_export_stats, format_statistics, calculate_statistics, smooth_tasks
|
| 14 |
+
from viewer.utils import PlotOptions, check_task_hash_consistency, BASELINE_GROUPING_MODE
|
| 15 |
+
|
| 16 |
+
with gr.Blocks() as demo:
|
| 17 |
+
list_of_runs = gr.State([])
|
| 18 |
+
plot_data = gr.State([])
|
| 19 |
+
statistics = gr.State(defaultdict(lambda: np.nan))
|
| 20 |
+
login_button = gr.LoginButton(visible=False)
|
| 21 |
+
run_data = gr.State([])
|
| 22 |
+
gr.Markdown("# FineWeb Multilingual experiments results explorer V2")
|
| 23 |
+
results_uri = gr.Textbox(label="TB HF Repo", value="s3://fineweb-multilingual-v1/evals/results/", visible=True)
|
| 24 |
+
with gr.Column():
|
| 25 |
+
with gr.Row():
|
| 26 |
+
# crop_prefix = gr.Textbox(label="Prefix to crop", value="tb/fineweb-exps-1p82G-")
|
| 27 |
+
steps = gr.Textbox(label="Training steps", value="%500",
|
| 28 |
+
info="Use \",\" to separate. Use \"%32000\" for every 32000 steps. Use \"-\" for ranges. You can also combine them: \"1000-5000%1000\", 1000 to 5000 every 1000 steps.",
|
| 29 |
+
interactive=True)
|
| 30 |
+
with gr.Column():
|
| 31 |
+
select_by_language = gr.Dropdown(choices=["ar", "fr", "ru", "hi", "th", "tr", "zh", "sw", "te"],
|
| 32 |
+
interactive=True, label="Select language",
|
| 33 |
+
info="Choose a language preset")
|
| 34 |
+
mcq_type = gr.Radio(choices=["prob_raw", "prob", "acc"], value="prob", label="MCQ agg metric type")
|
| 35 |
+
with gr.Column():
|
| 36 |
+
select_by_regex_text = gr.Textbox(label="Regex to select runs",
|
| 37 |
+
value="1p46G-gemma-fp-.*-{lang}-.*")
|
| 38 |
+
select_by_regex_button = gr.Button("Select matching runs")
|
| 39 |
+
selected_runs = gr.Dropdown(choices=[], interactive=True, multiselect=True, label="Selected runs")
|
| 40 |
+
fetch_res = gr.Button("Fetch results")
|
| 41 |
+
with gr.Column():
|
| 42 |
+
aggregate_score_cols = gr.Dropdown(
|
| 43 |
+
choices=[], interactive=True, multiselect=True,
|
| 44 |
+
value=[],
|
| 45 |
+
label="Aggregate score columns", allow_custom_value=True,
|
| 46 |
+
info="The values from these columns/metrics will be averaged to produce the \"agg_score\""
|
| 47 |
+
)
|
| 48 |
+
metrics_to_show = gr.Checkboxgroup(
|
| 49 |
+
interactive=True,
|
| 50 |
+
value=["agg_score_metrics"],
|
| 51 |
+
choices=["agg_score_metrics"],
|
| 52 |
+
label="Metrics to display",
|
| 53 |
+
info="Results for these metrics will be shown")
|
| 54 |
+
with gr.Row():
|
| 55 |
+
with gr.Column(scale=1):
|
| 56 |
+
task_averaging = gr.Checkboxgroup(
|
| 57 |
+
interactive=True,
|
| 58 |
+
choices=["show averages", "show expanded"],
|
| 59 |
+
value=["show averages"],
|
| 60 |
+
label="Task averaging",
|
| 61 |
+
info="Behaviour for tasks with subsets")
|
| 62 |
+
|
| 63 |
+
std_dev_run = gr.Dropdown(
|
| 64 |
+
interactive=True,
|
| 65 |
+
choices=[],
|
| 66 |
+
label="Run for std_dev",
|
| 67 |
+
info="Select a run to compute std_devs. Must have multiple seeds."
|
| 68 |
+
)
|
| 69 |
+
with gr.Column(scale=2):
|
| 70 |
+
# includes the seed
|
| 71 |
+
with gr.Row():
|
| 72 |
+
with gr.Column(scale=1):
|
| 73 |
+
normalization_runs = gr.Dropdown(
|
| 74 |
+
interactive=True,
|
| 75 |
+
value=[], choices=[],
|
| 76 |
+
multiselect=True,
|
| 77 |
+
label="Normalization runs",
|
| 78 |
+
info="Select runs to use for normalization"
|
| 79 |
+
)
|
| 80 |
+
normalization_mode = gr.Radio(
|
| 81 |
+
choices=["No norm", "Rescale", "Z-norm"],
|
| 82 |
+
value="Z-norm",
|
| 83 |
+
label="Normalization mode"
|
| 84 |
+
)
|
| 85 |
+
clip_scores_checkbox = gr.Checkbox(value=False, label="Clip Scores")
|
| 86 |
+
with gr.Column(scale=1):
|
| 87 |
+
baseline_runs = gr.Dropdown(
|
| 88 |
+
interactive=True,
|
| 89 |
+
value=[], choices=[],
|
| 90 |
+
multiselect=True,
|
| 91 |
+
label="Baseline runs",
|
| 92 |
+
info="Select runs to use as baseline"
|
| 93 |
+
)
|
| 94 |
+
baseline_groupping_mode = gr.Dropdown(choices=list(get_args(BASELINE_GROUPING_MODE)), value="Mean", label="Baseline grouping mode")
|
| 95 |
+
results_df = gr.Dataframe(interactive=False)
|
| 96 |
+
|
| 97 |
+
with gr.Row():
|
| 98 |
+
with gr.Column():
|
| 99 |
+
export_button = gr.Button("Export Results")
|
| 100 |
+
csv = gr.File(interactive=False, visible=False)
|
| 101 |
+
with gr.Column():
|
| 102 |
+
export_stats_button = gr.Button("Export Stats")
|
| 103 |
+
stats_csv = gr.File(interactive=False, visible=False)
|
| 104 |
+
|
| 105 |
+
check_missing_checkpoints = gr.Button(CHECK_MISSING_DATAPOINTS_BUTTON_LABEL)
|
| 106 |
+
check_task_consistency_button = gr.Button(TASK_CONSISTENCY_BUTTON_LABEL, visible=True)
|
| 107 |
+
|
| 108 |
+
task_consistency_output = gr.Json(label="Task hash consistency", visible=False)
|
| 109 |
+
missing_list = gr.Json(label="Missing datapoints", visible=False)
|
| 110 |
+
with gr.Row():
|
| 111 |
+
column_to_plot = gr.Dropdown(
|
| 112 |
+
choices=[], interactive=True,
|
| 113 |
+
value='agg_score_macro',
|
| 114 |
+
label="Task and metric", allow_custom_value=True)
|
| 115 |
+
score_step = gr.Number(
|
| 116 |
+
value=14000,
|
| 117 |
+
label="Step to use for computing benchmark score",
|
| 118 |
+
)
|
| 119 |
+
baseline_window = gr.Number(
|
| 120 |
+
value=5,
|
| 121 |
+
label="Window size for computing variability and randomness",
|
| 122 |
+
)
|
| 123 |
+
with gr.Row():
|
| 124 |
+
with gr.Column():
|
| 125 |
+
gr.Markdown("### Monotonicity - Spearman Rank Correlation (steps vs score)")
|
| 126 |
+
monotonicity_md = gr.Markdown()
|
| 127 |
+
with gr.Column():
|
| 128 |
+
gr.Markdown("### Variability (Windowed) - std_dev (all steps of std_dev_run) and SNR (last step)")
|
| 129 |
+
variability_md = gr.Markdown()
|
| 130 |
+
with gr.Column():
|
| 131 |
+
gr.Markdown("### Randomness (Windowed) - distance to RB (in std_dev)")
|
| 132 |
+
randomness_md = gr.Markdown()
|
| 133 |
+
with gr.Column():
|
| 134 |
+
gr.Markdown("### Ordering - Kendall Tau (steps vs score)")
|
| 135 |
+
ordering_md = gr.Markdown()
|
| 136 |
+
with gr.Row():
|
| 137 |
+
merge_seeds = gr.Dropdown(
|
| 138 |
+
choices=["none", "min", "max", "mean"],
|
| 139 |
+
value='mean',
|
| 140 |
+
label="Seed merging")
|
| 141 |
+
smoothing_steps = gr.Number(
|
| 142 |
+
value=3,
|
| 143 |
+
label="Smooth every N datapoints (sliding window)",
|
| 144 |
+
)
|
| 145 |
+
stds_to_plot = gr.Number(
|
| 146 |
+
value=0,
|
| 147 |
+
label="plot N stds as error bars",
|
| 148 |
+
)
|
| 149 |
+
with gr.Column():
|
| 150 |
+
interpolate_checkbox = gr.Checkbox(value=False, label="Interpolate missing steps")
|
| 151 |
+
percent_checkbox = gr.Checkbox(value=False, label="%")
|
| 152 |
+
barplot_checkbox = gr.Checkbox(value=False, label="Bar plot")
|
| 153 |
+
plot = gr.Plot()
|
| 154 |
+
|
| 155 |
+
# run selection
|
| 156 |
+
gr.on(
|
| 157 |
+
triggers=[results_uri.change],
|
| 158 |
+
fn=fetch_run_list, inputs=[results_uri], outputs=[list_of_runs, selected_runs]
|
| 159 |
+
)
|
| 160 |
+
gr.on(
|
| 161 |
+
triggers=[select_by_regex_button.click],
|
| 162 |
+
fn=select_runs_by_regex,
|
| 163 |
+
inputs=[list_of_runs, selected_runs, select_by_regex_text, select_by_language], outputs=[selected_runs]
|
| 164 |
+
)
|
| 165 |
+
gr.on(
|
| 166 |
+
triggers=[select_by_language.change, mcq_type.change],
|
| 167 |
+
fn=select_runs_by_language,
|
| 168 |
+
inputs=[list_of_runs, selected_runs, select_by_language, aggregate_score_cols, mcq_type], outputs=[selected_runs, aggregate_score_cols]
|
| 169 |
+
)
|
| 170 |
+
demo.load(fn=fetch_run_list, inputs=[results_uri], outputs=[list_of_runs, selected_runs])
|
| 171 |
+
|
| 172 |
+
gr.on(
|
| 173 |
+
triggers=[selected_runs.change],
|
| 174 |
+
fn=init_std_dev_runs,
|
| 175 |
+
inputs=[selected_runs, std_dev_run],
|
| 176 |
+
outputs=[std_dev_run]
|
| 177 |
+
)
|
| 178 |
+
# fetch result
|
| 179 |
+
gr.on(
|
| 180 |
+
triggers=[fetch_res.click],
|
| 181 |
+
fn=fetch_run_results,
|
| 182 |
+
inputs=[results_uri, selected_runs, steps],
|
| 183 |
+
# We set the plot as output, as state has stae has no loading indicator
|
| 184 |
+
outputs=[run_data, plot]
|
| 185 |
+
).then(
|
| 186 |
+
fn=init_input_component_values, inputs=[run_data, normalization_mode, select_by_language],
|
| 187 |
+
outputs=[metrics_to_show, normalization_runs, baseline_runs]
|
| 188 |
+
).then(
|
| 189 |
+
fn=render_results_table,
|
| 190 |
+
inputs=[run_data, metrics_to_show, task_averaging, normalization_runs, baseline_runs, baseline_groupping_mode, clip_scores_checkbox,
|
| 191 |
+
normalization_mode, aggregate_score_cols, select_by_language, baseline_window, mcq_type],
|
| 192 |
+
outputs=[results_df, aggregate_score_cols, column_to_plot]
|
| 193 |
+
)
|
| 194 |
+
# change results table
|
| 195 |
+
gr.on(
|
| 196 |
+
triggers=[
|
| 197 |
+
metrics_to_show.input,
|
| 198 |
+
task_averaging.input,
|
| 199 |
+
normalization_runs.input,
|
| 200 |
+
baseline_runs.input,
|
| 201 |
+
clip_scores_checkbox.input,
|
| 202 |
+
baseline_groupping_mode.input,
|
| 203 |
+
aggregate_score_cols.input
|
| 204 |
+
],
|
| 205 |
+
fn=render_results_table,
|
| 206 |
+
inputs=[run_data, metrics_to_show, task_averaging, normalization_runs, baseline_runs, baseline_groupping_mode, clip_scores_checkbox,
|
| 207 |
+
normalization_mode, aggregate_score_cols, select_by_language, baseline_window, mcq_type],
|
| 208 |
+
outputs=[results_df, aggregate_score_cols, column_to_plot]
|
| 209 |
+
)
|
| 210 |
+
|
| 211 |
+
# On normalization mode we first have to preinit the compoentntns
|
| 212 |
+
gr.on(
|
| 213 |
+
triggers=[normalization_mode.input],
|
| 214 |
+
fn=init_input_normalization_runs,
|
| 215 |
+
inputs=[run_data, normalization_mode],
|
| 216 |
+
outputs=[normalization_runs]
|
| 217 |
+
).then(
|
| 218 |
+
fn=render_results_table,
|
| 219 |
+
inputs=[run_data, metrics_to_show, task_averaging, normalization_runs, baseline_runs, baseline_groupping_mode, clip_scores_checkbox,
|
| 220 |
+
normalization_mode, aggregate_score_cols, select_by_language, baseline_window, mcq_type],
|
| 221 |
+
outputs=[results_df, aggregate_score_cols, column_to_plot]
|
| 222 |
+
)
|
| 223 |
+
# table actions
|
| 224 |
+
gr.on(
|
| 225 |
+
triggers=[export_button.click],
|
| 226 |
+
fn=export_results_csv, inputs=[results_df], outputs=[csv]
|
| 227 |
+
)
|
| 228 |
+
gr.on(
|
| 229 |
+
triggers=[check_missing_checkpoints.click],
|
| 230 |
+
fn=check_missing_datapoints, inputs=[selected_runs, steps, run_data, check_missing_checkpoints],
|
| 231 |
+
outputs=[missing_list, check_missing_checkpoints]
|
| 232 |
+
)
|
| 233 |
+
|
| 234 |
+
gr.on(
|
| 235 |
+
triggers=[check_task_consistency_button.click],
|
| 236 |
+
fn=check_task_hash_consistency, inputs=[run_data, check_task_consistency_button],
|
| 237 |
+
outputs=[task_consistency_output, check_task_consistency_button]
|
| 238 |
+
)
|
| 239 |
+
# plot
|
| 240 |
+
gr.on(
|
| 241 |
+
triggers=[results_df.change, column_to_plot.input, merge_seeds.input, smoothing_steps.input, stds_to_plot.input,
|
| 242 |
+
interpolate_checkbox.input, percent_checkbox.input, baseline_window.input, barplot_checkbox.input],
|
| 243 |
+
fn=lambda df, col, merge_seeds, smoothing_steps, interpolate_checkbox, percent_checkbox:
|
| 244 |
+
prepare_plot_data(df,
|
| 245 |
+
col,
|
| 246 |
+
merge_seeds,
|
| 247 |
+
PlotOptions(
|
| 248 |
+
smoothing=smoothing_steps,
|
| 249 |
+
interpolate=interpolate_checkbox,
|
| 250 |
+
pct=percent_checkbox,
|
| 251 |
+
merge_seeds=merge_seeds)),
|
| 252 |
+
inputs=[results_df, column_to_plot, merge_seeds, smoothing_steps, interpolate_checkbox, percent_checkbox],
|
| 253 |
+
outputs=[plot_data]
|
| 254 |
+
).then(
|
| 255 |
+
fn=lambda df ,std_dev_run_name, column_name, score_s, variance_window, smoothing_steps:
|
| 256 |
+
calculate_statistics(smooth_tasks(df, smoothing_steps), std_dev_run_name, column_name, score_s, variance_window),
|
| 257 |
+
inputs=[results_df, std_dev_run, column_to_plot, score_step, baseline_window, smoothing_steps],
|
| 258 |
+
outputs=[statistics]
|
| 259 |
+
).then(
|
| 260 |
+
fn=plot_metric,
|
| 261 |
+
inputs=[plot_data, column_to_plot, merge_seeds, percent_checkbox, statistics, stds_to_plot, select_by_language, barplot_checkbox],
|
| 262 |
+
outputs=[plot]
|
| 263 |
+
).then(
|
| 264 |
+
fn=format_statistics,
|
| 265 |
+
inputs=[statistics],
|
| 266 |
+
outputs=[monotonicity_md, variability_md, randomness_md, ordering_md]
|
| 267 |
+
)
|
| 268 |
+
|
| 269 |
+
gr.on(
|
| 270 |
+
triggers=[export_stats_button.click],
|
| 271 |
+
fn=generate_and_export_stats,
|
| 272 |
+
inputs=[run_data, std_dev_run, baseline_runs, baseline_groupping_mode,
|
| 273 |
+
score_step, baseline_window],
|
| 274 |
+
outputs=[stats_csv]
|
| 275 |
+
)
|
| 276 |
+
|
| 277 |
+
demo.launch()
|
viewer/literals.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
TASK_CONSISTENCY_BUTTON_LABEL = "Check task hash consistency"
|
| 2 |
+
TASK_CONSISTENCY_BUTTON_CLOSE_LABEL = "Close results"
|
| 3 |
+
CHECK_MISSING_DATAPOINTS_BUTTON_LABEL = "Check missing datapoints"
|
| 4 |
+
CHECK_MISSING_DATAPOINTS_BUTTON_CLOSE_LABEL = "Close results"
|
| 5 |
+
FALLBACK_TOKEN_NAME = "HF_TOKEN"
|
| 6 |
+
BASLINE_RUN_NAME = "baseline-6-"
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
REFERENCE_RUNS = ["cc-100", "commoncrawl", "culturax", "hplt", "mc4"]
|
viewer/plot.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import pandas as pd
|
| 3 |
+
from plotly import graph_objects as go
|
| 4 |
+
import plotly.express as px
|
| 5 |
+
from viewer.utils import PlotOptions
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def parse_merge_runs_to_plot(df, metric_name, merge_method):
|
| 9 |
+
if merge_method == "none":
|
| 10 |
+
return [
|
| 11 |
+
(group["steps"], group[metric_name], f'{runname}-s{seed}')
|
| 12 |
+
for (runname, seed), group in df.groupby(["runname", "seed"])
|
| 13 |
+
]
|
| 14 |
+
if metric_name not in df.columns:
|
| 15 |
+
return []
|
| 16 |
+
grouped = df.groupby(['runname', 'steps']).agg({metric_name: merge_method}).reset_index()
|
| 17 |
+
return [
|
| 18 |
+
(group["steps"], group[metric_name], runname)
|
| 19 |
+
for (runname,), group in grouped.groupby(["runname"])
|
| 20 |
+
]
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def prepare_plot_data(df: pd.DataFrame, metric_name: str, seed_merge_method: str,
|
| 24 |
+
plot_options: PlotOptions) -> pd.DataFrame:
|
| 25 |
+
if df is None or "steps" not in df or metric_name not in df.columns:
|
| 26 |
+
return pd.DataFrame()
|
| 27 |
+
|
| 28 |
+
df = df.copy().sort_values(by=["steps"])
|
| 29 |
+
plot_data = parse_merge_runs_to_plot(df, metric_name, seed_merge_method)
|
| 30 |
+
|
| 31 |
+
# Create DataFrame with all possible steps as index
|
| 32 |
+
all_steps = sorted(set(step for xs, _, _ in plot_data for step in xs))
|
| 33 |
+
result_df = pd.DataFrame(index=all_steps)
|
| 34 |
+
|
| 35 |
+
# Populate the DataFrame respecting xs for each series
|
| 36 |
+
for xs, ys, runname in plot_data:
|
| 37 |
+
result_df[runname] = pd.Series(index=xs.values, data=ys.values)
|
| 38 |
+
|
| 39 |
+
# Interpolate or keep NaN based on the interpolate flag
|
| 40 |
+
if plot_options.interpolate:
|
| 41 |
+
# this is done per run, as each run is in a diff column
|
| 42 |
+
result_df = result_df.interpolate(method='linear')
|
| 43 |
+
# Apply smoothing if needed
|
| 44 |
+
if plot_options.smoothing > 0:
|
| 45 |
+
result_df = result_df.rolling(window=plot_options.smoothing, min_periods=1).mean()
|
| 46 |
+
if plot_options.pct:
|
| 47 |
+
result_df = result_df * 100
|
| 48 |
+
|
| 49 |
+
return result_df
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def plot_metric(plot_df: pd.DataFrame, metric_name: str, seed_merge_method: str, pct: bool, statistics: dict,
|
| 53 |
+
nb_stds: int, language: str = None, barplot: bool = False) -> go.Figure:
|
| 54 |
+
if barplot:
|
| 55 |
+
return plot_metric_barplot(plot_df, metric_name, seed_merge_method, pct, statistics, nb_stds, language)
|
| 56 |
+
return plot_metric_scatter(plot_df, metric_name, seed_merge_method, pct, statistics, nb_stds, language)
|
| 57 |
+
|
| 58 |
+
def plot_metric_scatter(plot_df: pd.DataFrame, metric_name: str, seed_merge_method: str, pct: bool, statistics: dict,
|
| 59 |
+
nb_stds: int, language: str = None) -> go.Figure:
|
| 60 |
+
fig = go.Figure()
|
| 61 |
+
if not isinstance(plot_df, pd.DataFrame) or plot_df.empty:
|
| 62 |
+
return fig
|
| 63 |
+
show_error_bars = nb_stds > 0 and not np.isnan(statistics["mean_std"])
|
| 64 |
+
error_value = statistics["mean_std"] * nb_stds * (100 if pct else 1) if show_error_bars else 0.0
|
| 65 |
+
|
| 66 |
+
last_y_values = {runname: plot_df[runname].iloc[-1] for runname in plot_df.columns}
|
| 67 |
+
sorted_runnames = sorted(last_y_values, key=last_y_values.get, reverse=True)
|
| 68 |
+
for runname in sorted_runnames:
|
| 69 |
+
fig.add_trace(
|
| 70 |
+
go.Scatter(x=plot_df.index, y=plot_df[runname], mode='lines+markers', name=runname,
|
| 71 |
+
hovertemplate=f'%{{y:.2f}} ({runname})<extra></extra>',
|
| 72 |
+
error_y=dict(
|
| 73 |
+
type='constant', # Use a constant error value
|
| 74 |
+
value=error_value, # Single error value
|
| 75 |
+
visible=show_error_bars # Show error bars
|
| 76 |
+
))
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
lang_string = f" ({language})" if language else ""
|
| 80 |
+
|
| 81 |
+
fig.update_layout(
|
| 82 |
+
title=f"Run comparisons{lang_string}: {metric_name}" +
|
| 83 |
+
(f" ({seed_merge_method} over seeds)" if seed_merge_method != "none" else "") + (f" [%]" if pct else ""),
|
| 84 |
+
xaxis_title="Training steps",
|
| 85 |
+
yaxis_title=metric_name,
|
| 86 |
+
hovermode="x unified"
|
| 87 |
+
)
|
| 88 |
+
return fig
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def plot_metric_barplot(plot_df: pd.DataFrame, metric_name: str, seed_merge_method: str, pct: bool, statistics: dict,
|
| 92 |
+
nb_stds: int, language: str = None) -> go.Figure:
|
| 93 |
+
fig = go.Figure()
|
| 94 |
+
if not isinstance(plot_df, pd.DataFrame) or plot_df.empty:
|
| 95 |
+
return fig
|
| 96 |
+
|
| 97 |
+
show_error_bars = nb_stds > 0 and not np.isnan(statistics["mean_std"])
|
| 98 |
+
error_value = statistics["mean_std"] * nb_stds * (100 if pct else 1) if show_error_bars else 0.0
|
| 99 |
+
|
| 100 |
+
last_values = {runname: plot_df[runname].iloc[-1] for runname in plot_df.columns}
|
| 101 |
+
sorted_runnames = sorted(last_values, key=last_values.get, reverse=True)
|
| 102 |
+
|
| 103 |
+
# Create color map for consistent colors
|
| 104 |
+
colors = px.colors.qualitative.Set1
|
| 105 |
+
color_map = {run: colors[i % len(colors)] for i, run in enumerate(plot_df.columns)}
|
| 106 |
+
|
| 107 |
+
fig.add_trace(
|
| 108 |
+
go.Bar(
|
| 109 |
+
x=sorted_runnames,
|
| 110 |
+
y=[last_values[run] for run in sorted_runnames],
|
| 111 |
+
marker_color=[color_map[run] for run in sorted_runnames],
|
| 112 |
+
error_y=dict(
|
| 113 |
+
type='constant',
|
| 114 |
+
value=error_value,
|
| 115 |
+
visible=show_error_bars
|
| 116 |
+
),
|
| 117 |
+
hovertemplate='%{y:.2f}<extra></extra>'
|
| 118 |
+
)
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
lang_string = f" ({language})" if language else ""
|
| 122 |
+
|
| 123 |
+
fig.update_layout(
|
| 124 |
+
title=f"Run comparisons{lang_string}: {metric_name}" +
|
| 125 |
+
(f" ({seed_merge_method} over seeds)" if seed_merge_method != "none" else "") + (
|
| 126 |
+
f" [%]" if pct else ""),
|
| 127 |
+
xaxis_title="Runs",
|
| 128 |
+
yaxis_title=metric_name,
|
| 129 |
+
hovermode="x"
|
| 130 |
+
)
|
| 131 |
+
return fig
|
viewer/results.py
ADDED
|
@@ -0,0 +1,421 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
|
| 3 |
+
import itertools
|
| 4 |
+
import json
|
| 5 |
+
import os
|
| 6 |
+
from concurrent.futures import ThreadPoolExecutor
|
| 7 |
+
from typing import get_args, Literal, List
|
| 8 |
+
|
| 9 |
+
import pandas as pd
|
| 10 |
+
import time
|
| 11 |
+
from collections import defaultdict, Counter
|
| 12 |
+
from datetime import datetime
|
| 13 |
+
|
| 14 |
+
import gradio as gr
|
| 15 |
+
from huggingface_hub import cached_assets_path
|
| 16 |
+
|
| 17 |
+
from viewer.agg_score_metrics import agg_score_metrics_dict_prob, custom_task_aggregate_groups, agg_score_metrics
|
| 18 |
+
from viewer.literals import BASLINE_RUN_NAME, CHECK_MISSING_DATAPOINTS_BUTTON_CLOSE_LABEL, \
|
| 19 |
+
CHECK_MISSING_DATAPOINTS_BUTTON_LABEL, \
|
| 20 |
+
FALLBACK_TOKEN_NAME, REFERENCE_RUNS
|
| 21 |
+
from viewer.utils import BASELINE_GROUPING_MODE, create_df_from_run_data, get_run_name_seed, RunInfo, TaskInfo, get_groupped_score, RunData, is_aggregate_column, is_baseline_run, is_reference_run, is_task_column, rescale_scores, select_runs, z_score_normalize
|
| 22 |
+
from datatrove.io import DataFolder
|
| 23 |
+
from viewer.task_type_mapping import get_task_type, TASK_TYPE
|
| 24 |
+
import tqdm as progress
|
| 25 |
+
|
| 26 |
+
NormalizationMode = Literal["No adjustment", "Rescale", "Z-norm"]
|
| 27 |
+
|
| 28 |
+
def fetch_run_results(results_uri, runs_to_fetch, steps_to_fetch,
|
| 29 |
+
oauth_token: gr.OAuthToken | None = None):
|
| 30 |
+
token = os.environ.get(FALLBACK_TOKEN_NAME)
|
| 31 |
+
if oauth_token:
|
| 32 |
+
token = oauth_token.token
|
| 33 |
+
if not runs_to_fetch:
|
| 34 |
+
return None, None
|
| 35 |
+
|
| 36 |
+
steps_to_fetch_list = steps_to_fetch.split(",")
|
| 37 |
+
data_folder = DataFolder(results_uri, token=token)
|
| 38 |
+
|
| 39 |
+
def fetch_run_files(run_to_fetch):
|
| 40 |
+
def filename_to_steps_timestamp(fn):
|
| 41 |
+
step, ts = fn.split("/results_")
|
| 42 |
+
dt = datetime.strptime(ts.split(".")[0], "%Y-%m-%dT%H-%M-%S")
|
| 43 |
+
return int(step), dt
|
| 44 |
+
|
| 45 |
+
run_path = f"results/{run_to_fetch}"
|
| 46 |
+
|
| 47 |
+
try:
|
| 48 |
+
eval_files = [f for f in data_folder.list_files(run_path, recursive=True)]
|
| 49 |
+
except FileNotFoundError:
|
| 50 |
+
return []
|
| 51 |
+
|
| 52 |
+
# Group files by step
|
| 53 |
+
step_files = defaultdict(list)
|
| 54 |
+
for fn in eval_files:
|
| 55 |
+
steps, ts = filename_to_steps_timestamp(os.path.relpath(fn, run_path))
|
| 56 |
+
step_files[steps].append((ts, fn))
|
| 57 |
+
|
| 58 |
+
# Sort files within each step by timestamp (newest first)
|
| 59 |
+
for step in step_files:
|
| 60 |
+
step_files[step].sort(reverse=True) # tuples are sorted element by element by default
|
| 61 |
+
|
| 62 |
+
# (run, steps, file_paths_in_repo)
|
| 63 |
+
results = []
|
| 64 |
+
for step, files in step_files.items():
|
| 65 |
+
if any(step_element_match(step, step_el) for step_el in steps_to_fetch_list):
|
| 66 |
+
results.append((run_to_fetch, step, files))
|
| 67 |
+
return results
|
| 68 |
+
|
| 69 |
+
def get_file_with_retry(data_folder: DataFolder, filename: str):
|
| 70 |
+
save_path = os.path.join(cached_assets_path(library_name="results-viewer",
|
| 71 |
+
namespace=data_folder.path), filename)
|
| 72 |
+
if os.path.exists(save_path):
|
| 73 |
+
with open(save_path, "rb") as f:
|
| 74 |
+
return f.read()
|
| 75 |
+
|
| 76 |
+
wait = 1.5
|
| 77 |
+
max_retries = 20
|
| 78 |
+
for attempt in range(max_retries):
|
| 79 |
+
try:
|
| 80 |
+
with data_folder.open(filename, "rb") as f:
|
| 81 |
+
data = f.read()
|
| 82 |
+
os.makedirs(os.path.dirname(save_path), exist_ok=True)
|
| 83 |
+
with open(save_path, "wb") as f:
|
| 84 |
+
f.write(data)
|
| 85 |
+
return data
|
| 86 |
+
except Exception as e:
|
| 87 |
+
print(f"Error downloading (attempt {attempt + 1}/{max_retries}): {e}")
|
| 88 |
+
if attempt == max_retries - 1:
|
| 89 |
+
raise e
|
| 90 |
+
time.sleep(max(wait ** attempt, 40))
|
| 91 |
+
|
| 92 |
+
return None
|
| 93 |
+
|
| 94 |
+
def hot_fix_task_name(task_name: str):
|
| 95 |
+
"""
|
| 96 |
+
This is a hot fix as Hynek inocrrectly named the average collumns
|
| 97 |
+
"""
|
| 98 |
+
|
| 99 |
+
if task_name.endswith(":_average"):
|
| 100 |
+
return task_name.replace(":_average", ":_average|0")
|
| 101 |
+
return task_name
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def load_run_file(run_info: tuple[str, str, list[tuple[datetime, str]]]):
|
| 107 |
+
run_to_fetch, step, file_data = run_info
|
| 108 |
+
aggregated_data = {}
|
| 109 |
+
latest_timestamps = {}
|
| 110 |
+
|
| 111 |
+
for timestamp, result_file in file_data:
|
| 112 |
+
file_data = get_file_with_retry(data_folder, result_file)
|
| 113 |
+
if not file_data:
|
| 114 |
+
raise Exception(f"File {result_file} not found")
|
| 115 |
+
json_data = json.loads(file_data)
|
| 116 |
+
for task, res in json_data["results"].items():
|
| 117 |
+
if task not in latest_timestamps or timestamp > latest_timestamps[task]:
|
| 118 |
+
latest_timestamps[task] = timestamp
|
| 119 |
+
# The aggregated tassks don't contain hashes, we thus use dummy values not to cause conflict
|
| 120 |
+
hashes = json_data["summary_tasks"].get(task, {}).get("hashes") or {
|
| 121 |
+
"hash_examples": "",
|
| 122 |
+
"hash_full_prompts": "",
|
| 123 |
+
"hash_input_tokens": "",
|
| 124 |
+
"hash_cont_tokens": ""
|
| 125 |
+
}
|
| 126 |
+
aggregated_data[task] = {
|
| 127 |
+
"metrics": res,
|
| 128 |
+
"hashes": hashes,
|
| 129 |
+
"filename": result_file
|
| 130 |
+
}
|
| 131 |
+
|
| 132 |
+
runname, seed = get_run_name_seed(run_to_fetch)
|
| 133 |
+
return RunInfo(runname, seed, int(step),
|
| 134 |
+
[TaskInfo(res["filename"], hot_fix_task_name(task), res["metrics"], res["hashes"]) for task, res in
|
| 135 |
+
aggregated_data.items()])
|
| 136 |
+
|
| 137 |
+
with ThreadPoolExecutor() as pool:
|
| 138 |
+
run_files = list(itertools.chain.from_iterable(
|
| 139 |
+
progress.tqdm(pool.map(fetch_run_files, runs_to_fetch), total=len(runs_to_fetch),
|
| 140 |
+
desc="Fetching datafiles...")))
|
| 141 |
+
run_data = list(
|
| 142 |
+
progress.tqdm(pool.map(load_run_file, run_files), total=len(run_files), desc="Loading evals data..."))
|
| 143 |
+
|
| 144 |
+
return run_data, None
|
| 145 |
+
|
| 146 |
+
def filter_run_list_for_language(all_runs, language):
|
| 147 |
+
if not language:
|
| 148 |
+
return []
|
| 149 |
+
return [
|
| 150 |
+
x for x in all_runs if f"-{language}-" in x
|
| 151 |
+
]
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def fetch_run_list(results_uri, oauth_token: gr.OAuthToken | None = None, language=None):
|
| 155 |
+
token = os.environ.get(FALLBACK_TOKEN_NAME)
|
| 156 |
+
if oauth_token:
|
| 157 |
+
token = oauth_token.token
|
| 158 |
+
|
| 159 |
+
data_folder = DataFolder(results_uri, token=token)
|
| 160 |
+
# Ignore the root directory
|
| 161 |
+
list_of_runs = [f.removeprefix("results/") for f in
|
| 162 |
+
data_folder.list_files(subdirectory="results", recursive=False, include_directories=True)
|
| 163 |
+
if f != "results"]
|
| 164 |
+
return list_of_runs, gr.update(choices=filter_run_list_for_language(list_of_runs, language), value=None)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def select_runs_by_regex(runs, current_selected, regex_to_select, lang=None):
|
| 168 |
+
if lang and "{lang}" in regex_to_select:
|
| 169 |
+
regex_to_select = regex_to_select.replace("{lang}", lang)
|
| 170 |
+
comp_re = re.compile(regex_to_select)
|
| 171 |
+
return list(sorted(set((current_selected if current_selected else []) +
|
| 172 |
+
[run for run in runs if comp_re.fullmatch(run)])))
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
def add_baseline_rows(df: pd.DataFrame, baseline_runs: list[str], grouping_mode: BASELINE_GROUPING_MODE, baseline_name: str = BASLINE_RUN_NAME) -> pd.DataFrame:
|
| 176 |
+
if len(baseline_runs) == 0:
|
| 177 |
+
return df
|
| 178 |
+
|
| 179 |
+
baseline_df = select_runs(df, runs_to_include=baseline_runs)
|
| 180 |
+
baseline_values = get_groupped_score(baseline_df, baseline_runs, grouping_mode)
|
| 181 |
+
|
| 182 |
+
# If baseline values doesn't contain all available steps, we interpolate the baseline values
|
| 183 |
+
unique_steps = df["steps"].unique()
|
| 184 |
+
baseline_values = baseline_values.set_index("steps").reindex(index=unique_steps).interpolate().reset_index()
|
| 185 |
+
runname, seed = get_run_name_seed(baseline_name)
|
| 186 |
+
|
| 187 |
+
baseline_values['runname'] = runname
|
| 188 |
+
baseline_values['seed'] = seed
|
| 189 |
+
|
| 190 |
+
# Add the baseline values to the dataframe
|
| 191 |
+
df = pd.concat([df, baseline_values], ignore_index=True)
|
| 192 |
+
|
| 193 |
+
return df
|
| 194 |
+
|
| 195 |
+
def normalize_scores(df: pd.DataFrame, normalization_runs: list[str], clip_scores: bool, normalization_mode: NormalizationMode, variability_window: int = 1):
|
| 196 |
+
if not normalization_runs or len(normalization_runs) == 0:
|
| 197 |
+
return df
|
| 198 |
+
|
| 199 |
+
cols_to_process = [col for col in df.columns if is_task_column(col) and not col.endswith('_stderr') and ":_average|" not in col]
|
| 200 |
+
|
| 201 |
+
if normalization_mode == "Z-norm":
|
| 202 |
+
df = z_score_normalize(df, normalization_runs, cols_to_process, variability_window)
|
| 203 |
+
elif normalization_mode == "Rescale":
|
| 204 |
+
df = rescale_scores(df, normalization_runs, cols_to_process)
|
| 205 |
+
|
| 206 |
+
if clip_scores:
|
| 207 |
+
df[cols_to_process] = df[cols_to_process].clip(lower=0)
|
| 208 |
+
return df
|
| 209 |
+
|
| 210 |
+
def recompute_averages(df: pd.DataFrame) -> pd.DataFrame:
|
| 211 |
+
average_columns = [col for col in df.columns if ":_average|" in col]
|
| 212 |
+
tasks_with_averages = set(x.split(":_average|")[0] for x in average_columns)
|
| 213 |
+
values_to_average = defaultdict(list)
|
| 214 |
+
for col in df.columns:
|
| 215 |
+
if (task := col.split(":")[0]) in tasks_with_averages and (task_subset := col.split(":")[1].split("|")[0]) and task_subset != "_average":
|
| 216 |
+
task_group = custom_task_aggregate_groups.get(task)
|
| 217 |
+
# Only add the task to average is it exists in the task group
|
| 218 |
+
if not task_group or task_subset in task_group:
|
| 219 |
+
values_to_average[(task, col.split("|")[-1])].append(col) # task name and metric
|
| 220 |
+
|
| 221 |
+
for (task, metric), cols in values_to_average.items():
|
| 222 |
+
df[f"{task}:_average|{metric}"] = df[cols].mean(axis=1)
|
| 223 |
+
|
| 224 |
+
return df
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
def select_runs_by_language(runs, current_selected, language, selected_cols, mcq_type):
|
| 228 |
+
new_runs = current_selected
|
| 229 |
+
if language:
|
| 230 |
+
if language in agg_score_metrics[mcq_type]:
|
| 231 |
+
selected_cols = agg_score_metrics[mcq_type][language]
|
| 232 |
+
new_runs = select_runs_by_regex(runs, current_selected, ".*gemma.*-(" + "|".join(REFERENCE_RUNS) + ")-{lang}-.*", language)
|
| 233 |
+
return gr.update(value=new_runs, choices=filter_run_list_for_language(runs, language)), gr.update(value=selected_cols if selected_cols else [], choices=selected_cols if selected_cols else [])
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
def step_element_match(step_to_check, step_element):
|
| 237 |
+
step_element = step_element.strip().replace(" ", "")
|
| 238 |
+
if "-" in step_element:
|
| 239 |
+
a, b = step_element.split("-")
|
| 240 |
+
c = None
|
| 241 |
+
if "%" in b:
|
| 242 |
+
b, c = b.split("%")
|
| 243 |
+
return (int(a) <= step_to_check <= int(b) and
|
| 244 |
+
(c is None or (step_to_check - int(a)) % int(c) == 0))
|
| 245 |
+
elif "%" in step_element:
|
| 246 |
+
return step_to_check % int(step_element[1:]) == 0
|
| 247 |
+
else:
|
| 248 |
+
return step_to_check == int(step_element)
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
def init_input_component_values(run_data: RunData, normalization_mode: NormalizationMode, language: str | None = None):
|
| 252 |
+
task_metrics = set(metric for run in run_data for task in run.tasks for metric in task.metrics.keys())
|
| 253 |
+
initial_value = "agg_score_metrics" if language and language in agg_score_metrics_dict_prob else \
|
| 254 |
+
("acc_norm" if "acc_norm" in task_metrics else next(iter(task_metrics), None))
|
| 255 |
+
runs = set(run.full_name for run in run_data)
|
| 256 |
+
baseline_runs = [run for run in runs if is_baseline_run(run)]
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
return (gr.update(choices=["agg_score_metrics"] + sorted(task_metrics, key=lambda m: (m.endswith("_stderr"), m)), value=[initial_value]),
|
| 262 |
+
init_input_normalization_runs(run_data, normalization_mode),
|
| 263 |
+
gr.update(value=[] if not baseline_runs else [baseline_runs[0]], choices=sorted(runs)))
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
def init_input_normalization_runs(runs: RunData, normalization_mode: NormalizationMode):
|
| 267 |
+
run_names = set([run.full_name for run in runs])
|
| 268 |
+
if normalization_mode == "Z-norm":
|
| 269 |
+
referene_runs = [run for run in run_names if is_reference_run(run)]
|
| 270 |
+
return gr.update(value=referene_runs, choices=sorted(run_names))
|
| 271 |
+
|
| 272 |
+
elif normalization_mode == "Rescale":
|
| 273 |
+
baseline_runs = [run for run in run_names if is_baseline_run(run)]
|
| 274 |
+
return gr.update(value=baseline_runs, choices=sorted(run_names))
|
| 275 |
+
|
| 276 |
+
else:
|
| 277 |
+
return gr.update(value=[], choices=[])
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
def init_std_dev_runs(runs, current_val):
|
| 282 |
+
# sets to the run with the highest count of seeds, that has at least 2 seeds. name does not include the seed
|
| 283 |
+
value = current_val or "-"
|
| 284 |
+
seed_counter = Counter()
|
| 285 |
+
for run in runs or []:
|
| 286 |
+
seed_counter[run.split("-seed-")[0]] += 1
|
| 287 |
+
|
| 288 |
+
if seed_counter[value] <= 1: # can only select runs with at least 2 seeds
|
| 289 |
+
top_val, top_count = seed_counter.most_common(n=1)[0] if seed_counter else (None, 0)
|
| 290 |
+
value = top_val if top_count > 1 else "-"
|
| 291 |
+
return gr.update(value=value, choices=["-"] + sorted([val for val, count in seed_counter.items() if count > 1]))
|
| 292 |
+
|
| 293 |
+
|
| 294 |
+
def update_dropdown_choices(selected_choices, possible_choices):
|
| 295 |
+
selected_choices = [choice for choice in selected_choices if choice in possible_choices]
|
| 296 |
+
return gr.update(choices=possible_choices, value=selected_choices)
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
def render_results_table(df: pd.DataFrame, metrics, task_avg, normalization_runs: list[str], baseline_runs: list[str], baseline_mode: BASELINE_GROUPING_MODE, clip_scores: bool,
|
| 300 |
+
normalization_mode: NormalizationMode, aggregate_score_cols: list[str], language: str, variability_window: int = 1, mcq_type = "prob"):
|
| 301 |
+
# if not run_data:
|
| 302 |
+
# return None, gr.update(), gr.update()
|
| 303 |
+
# df = create_df_from_run_data(run_data)
|
| 304 |
+
|
| 305 |
+
# Create baseline rows
|
| 306 |
+
df = add_baseline_rows(df, baseline_runs, baseline_mode)
|
| 307 |
+
|
| 308 |
+
# it's important to first normalize scores, so that the _averages can be recomputed
|
| 309 |
+
df = normalize_scores(df, normalization_runs=normalization_runs, clip_scores=clip_scores, normalization_mode=normalization_mode, variability_window=variability_window)
|
| 310 |
+
|
| 311 |
+
df = recompute_averages(df)
|
| 312 |
+
|
| 313 |
+
# Remove baseline runs from the main DataFrame
|
| 314 |
+
df = select_runs(df, runs_to_exclude=baseline_runs)
|
| 315 |
+
|
| 316 |
+
to_drop = []
|
| 317 |
+
for col in df.columns:
|
| 318 |
+
if is_task_column(col):
|
| 319 |
+
# part of the agg score metrics
|
| 320 |
+
if "agg_score_metrics" in metrics and language in agg_score_metrics[mcq_type] and col in agg_score_metrics[mcq_type][language]:
|
| 321 |
+
continue
|
| 322 |
+
task, metric = col.split("/")
|
| 323 |
+
# If no metrics are selected, show all metrics
|
| 324 |
+
if ((metric not in metrics and len(metrics) > 0) or
|
| 325 |
+
(":_average|" in task and "show averages" not in task_avg) or
|
| 326 |
+
("|" in task and ":_average|" not in task and ":" in task.split("|")[
|
| 327 |
+
1] and "show expanded" not in task_avg)):
|
| 328 |
+
to_drop.append(col)
|
| 329 |
+
if to_drop:
|
| 330 |
+
df = df.drop(columns=to_drop)
|
| 331 |
+
|
| 332 |
+
|
| 333 |
+
df.sort_values(by=["runname", "seed", "steps"], inplace=True)
|
| 334 |
+
df = update_agg_score(df, aggregate_score_cols)
|
| 335 |
+
|
| 336 |
+
aggregate_columns = [col for col in df.columns if is_aggregate_column(col)]
|
| 337 |
+
# All task metrics contains /metric
|
| 338 |
+
task_columns = [col for col in df.columns if is_task_column(col)]
|
| 339 |
+
return df, update_dropdown_choices(aggregate_score_cols, task_columns), gr.update(aggregate_columns[0], choices=aggregate_columns + task_columns)
|
| 340 |
+
|
| 341 |
+
|
| 342 |
+
def get_type_tasks_dict(tasks: list[str]) -> dict[TASK_TYPE, list[str]]:
|
| 343 |
+
"""
|
| 344 |
+
Creates a dictionary mapping task types to lists of task names.
|
| 345 |
+
|
| 346 |
+
Args:
|
| 347 |
+
tasks (list[str]): List of task names.
|
| 348 |
+
|
| 349 |
+
Returns:
|
| 350 |
+
dict[TASK_TYPE, list[str]]: Dictionary with task types as keys and lists of task names as values.
|
| 351 |
+
"""
|
| 352 |
+
task_type_dict: dict[TASK_TYPE, list[str]] = defaultdict(list)
|
| 353 |
+
|
| 354 |
+
for task in tasks:
|
| 355 |
+
task_type = get_task_type(task)
|
| 356 |
+
if not task_type:
|
| 357 |
+
raise ValueError(f"Task {task} has no task type")
|
| 358 |
+
task_type_dict[task_type].append(task)
|
| 359 |
+
|
| 360 |
+
return task_type_dict
|
| 361 |
+
|
| 362 |
+
def update_agg_score(df: pd.DataFrame, agg_score_columns: list[str]) -> pd.DataFrame:
|
| 363 |
+
if not agg_score_columns or df is None or "steps" not in df:
|
| 364 |
+
return df
|
| 365 |
+
|
| 366 |
+
new_df = df.copy()
|
| 367 |
+
cols_to_avg = [col for col in agg_score_columns if col in new_df.columns]
|
| 368 |
+
|
| 369 |
+
if cols_to_avg:
|
| 370 |
+
# Calculate task type aggregates
|
| 371 |
+
task_type_dict = get_type_tasks_dict(cols_to_avg)
|
| 372 |
+
# Create a dict from task_type_list
|
| 373 |
+
for task_type, tasks in task_type_dict.items():
|
| 374 |
+
new_df[f'agg_score_{task_type}'] = new_df[tasks].mean(axis=1)
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
# Calculate agg_score_task_macro
|
| 378 |
+
new_df['agg_score_macro'] = new_df[[f'agg_score_{task_type}' for task_type in task_type_dict.keys()]].mean(axis=1)
|
| 379 |
+
|
| 380 |
+
# Update agg_score
|
| 381 |
+
new_df['agg_score_micro'] = new_df[cols_to_avg].mean(axis=1)
|
| 382 |
+
|
| 383 |
+
return new_df
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
def export_results_csv(df):
|
| 387 |
+
df.to_csv("output.csv", index=False)
|
| 388 |
+
return gr.update(value="output.csv", visible=True)
|
| 389 |
+
|
| 390 |
+
|
| 391 |
+
def check_missing_datapoints(runs, steps_to_check, run_data: RunData, check_missing_checkpoints):
|
| 392 |
+
if not runs or check_missing_checkpoints == CHECK_MISSING_DATAPOINTS_BUTTON_CLOSE_LABEL or not run_data or not steps_to_check:
|
| 393 |
+
return gr.Json(value={}, visible=False), gr.Button(value=CHECK_MISSING_DATAPOINTS_BUTTON_LABEL)
|
| 394 |
+
|
| 395 |
+
max_step = max(run.step for run in run_data)
|
| 396 |
+
steps_set = set()
|
| 397 |
+
for step_elem in steps_to_check.split(","):
|
| 398 |
+
step_element = step_elem.strip().replace(" ", "")
|
| 399 |
+
if "-" in step_element:
|
| 400 |
+
a, b = step_element.split("-")
|
| 401 |
+
c = None
|
| 402 |
+
if "%" in b:
|
| 403 |
+
b, c = b.split("%")
|
| 404 |
+
steps_set.update(range(int(a), int(b) + 1, int(c) if c else 1))
|
| 405 |
+
elif "%" in step_element:
|
| 406 |
+
steps_set.update(range(0, max_step + 1, int(step_element[1:])))
|
| 407 |
+
else:
|
| 408 |
+
steps_set.add(int(step_element))
|
| 409 |
+
|
| 410 |
+
existing_evals = {(run.name, run.seed, run.step) for run in run_data}
|
| 411 |
+
|
| 412 |
+
missing_evals = defaultdict(dict)
|
| 413 |
+
for run in runs:
|
| 414 |
+
runname, seed = get_run_name_seed(run)
|
| 415 |
+
missing_steps = [
|
| 416 |
+
step for step in sorted(steps_set) if (runname, seed, step) not in existing_evals
|
| 417 |
+
]
|
| 418 |
+
if missing_steps:
|
| 419 |
+
missing_evals[runname][str(seed)] = missing_steps
|
| 420 |
+
|
| 421 |
+
return gr.Json(value=missing_evals, visible=True), gr.Button(value=CHECK_MISSING_DATAPOINTS_BUTTON_CLOSE_LABEL)
|
viewer/stats.py
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import defaultdict
|
| 2 |
+
|
| 3 |
+
import gradio as gr
|
| 4 |
+
import numpy as np
|
| 5 |
+
import pandas as pd
|
| 6 |
+
from scipy import stats
|
| 7 |
+
from viewer.literals import BASLINE_RUN_NAME
|
| 8 |
+
import tqdm as progress
|
| 9 |
+
from viewer.results import NormalizationMode, add_baseline_rows
|
| 10 |
+
|
| 11 |
+
from viewer.utils import BASELINE_GROUPING_MODE, create_df_from_run_data, get_groupped_score, get_run_name_seed, RunData, is_aggregate_column, is_task_column, select_runs
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def fast_kendall_tau_a(x, y):
|
| 15 |
+
x = np.array(x)
|
| 16 |
+
y = np.array(y)
|
| 17 |
+
n = len(x)
|
| 18 |
+
if n <= 1:
|
| 19 |
+
return 0.0
|
| 20 |
+
|
| 21 |
+
# Create matrices of pairwise differences
|
| 22 |
+
x_diff = x[:, np.newaxis] - x
|
| 23 |
+
y_diff = y[:, np.newaxis] - y
|
| 24 |
+
|
| 25 |
+
# Calculate concordant and discordant pairs
|
| 26 |
+
concordant = np.sum((x_diff * y_diff > 0) & (np.triu(np.ones((n, n)), k=1) == 1))
|
| 27 |
+
discordant = np.sum((x_diff * y_diff <= 0) & (np.triu(np.ones((n, n)), k=1) == 1))
|
| 28 |
+
|
| 29 |
+
# Calculate tau-a
|
| 30 |
+
tau_a = (concordant - discordant) / (n * (n - 1) / 2)
|
| 31 |
+
|
| 32 |
+
return tau_a
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def calculate_statistics(df: pd.DataFrame, std_dev_run_name: str, column_name: str,
|
| 36 |
+
score_s: int, score_window: int, baseline_run: str = BASLINE_RUN_NAME) -> dict[str, float]:
|
| 37 |
+
if len(df) == 0 or not (is_task_column(column_name) or is_aggregate_column(column_name)) or column_name not in df.columns:
|
| 38 |
+
return defaultdict(lambda: np.nan)
|
| 39 |
+
|
| 40 |
+
# drop baseline_score and other columns
|
| 41 |
+
baseline_df = select_runs(df, runs_to_include=[baseline_run])
|
| 42 |
+
|
| 43 |
+
df = select_runs(df, runs_to_exclude=[baseline_run])
|
| 44 |
+
df = df[['runname', 'seed', 'steps', column_name]]
|
| 45 |
+
|
| 46 |
+
# mean over seeds
|
| 47 |
+
mean_over_seeds = df.groupby(['runname', 'steps'], as_index=False)[column_name].mean()
|
| 48 |
+
pivot_df = mean_over_seeds.pivot(index='steps', columns='runname', values=column_name).interpolate(method='linear')
|
| 49 |
+
|
| 50 |
+
# 1. monotonicity: Spearman Correlation
|
| 51 |
+
spearman_corrs = [stats.spearmanr(pivot_df[col].index, pivot_df[col], nan_policy="omit")[0] for col in
|
| 52 |
+
pivot_df.columns if len(np.unique(pivot_df[col])) > 1]
|
| 53 |
+
avg_spearman = np.mean([c for c in spearman_corrs if not np.isnan(c)]) if not all(
|
| 54 |
+
map(np.isnan, spearman_corrs)) else np.nan
|
| 55 |
+
|
| 56 |
+
# 2. ordering consistency: Average Kendall Tau-a
|
| 57 |
+
last_half = int(len(pivot_df.index) / 2)
|
| 58 |
+
step_pairs = list(zip(pivot_df.index[:-1], pivot_df.index[1:]))[last_half:]
|
| 59 |
+
kendall_tau_a_values = [fast_kendall_tau_a(pivot_df.loc[s1], pivot_df.loc[s2]) for s1, s2 in step_pairs]
|
| 60 |
+
avg_kendall_tau_a = np.mean(kendall_tau_a_values) if kendall_tau_a_values else np.nan
|
| 61 |
+
|
| 62 |
+
# 3. variability: Std dev
|
| 63 |
+
mean_std, min_std, min_std_step, max_std, max_std_step, snr, max_n_std = (
|
| 64 |
+
np.nan, np.nan, np.nan, np.nan, np.nan, np.nan, np.nan)
|
| 65 |
+
if std_dev_run_name and std_dev_run_name != "-":
|
| 66 |
+
grouped_std_runs = df[(df['runname'] == std_dev_run_name) & (df['steps'] != 0)] \
|
| 67 |
+
.groupby('steps')[column_name]
|
| 68 |
+
|
| 69 |
+
means = grouped_std_runs.mean()
|
| 70 |
+
stds = grouped_std_runs.std()
|
| 71 |
+
|
| 72 |
+
window_steps = means.index[means.index <= score_s][-score_window:]
|
| 73 |
+
pivot_df_window = pivot_df.loc[window_steps]
|
| 74 |
+
|
| 75 |
+
stds_window = stds[window_steps]
|
| 76 |
+
|
| 77 |
+
if not stds_window.empty:
|
| 78 |
+
max_std, max_std_step = stds_window.max(), stds_window.index[stds_window.argmax()]
|
| 79 |
+
min_std, min_std_step = stds_window.min(), stds_window.index[stds_window.argmin()]
|
| 80 |
+
mean_std = stds_window.mean()
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
score = pivot_df_window.loc[score_s]
|
| 85 |
+
|
| 86 |
+
full_mean_std = stds.mean()
|
| 87 |
+
if full_mean_std != 0.0 and full_mean_std != np.nan:
|
| 88 |
+
snr = score.mean() / full_mean_std
|
| 89 |
+
|
| 90 |
+
if not baseline_df.empty and mean_std != np.nan and mean_std != 0:
|
| 91 |
+
# 4. randomness
|
| 92 |
+
random_baseline_scores = baseline_df.set_index("steps")[column_name].reindex(
|
| 93 |
+
pd.concat([baseline_df["steps"], pivot_df_window.index.to_series()]).unique().sort()
|
| 94 |
+
).interpolate(method='linear')
|
| 95 |
+
|
| 96 |
+
baseline_score = random_baseline_scores.loc[score_s]
|
| 97 |
+
max_n_std = (score - baseline_score).max() / mean_std
|
| 98 |
+
|
| 99 |
+
# # 2. Standard Error, Mean, and Max
|
| 100 |
+
# summary_stats = [(df[col].std() / np.sqrt(df[col].count()),
|
| 101 |
+
# df[col].mean(),
|
| 102 |
+
# df[col].max()) for col in df.columns if df[col].count() > 1]
|
| 103 |
+
# avg_stderr, avg_mean, max_max = np.nan, np.nan, np.nan
|
| 104 |
+
# if summary_stats:
|
| 105 |
+
# avg_stderr = np.mean([s for s, _, _ in summary_stats])
|
| 106 |
+
# avg_mean = np.mean([m for _, m, _ in summary_stats])
|
| 107 |
+
# max_max = np.max([mx for _, _, mx in summary_stats])
|
| 108 |
+
|
| 109 |
+
return {
|
| 110 |
+
"avg_spearman": float(avg_spearman),
|
| 111 |
+
"avg_kendall_tau_a": float(avg_kendall_tau_a),
|
| 112 |
+
"max_std": float(max_std),
|
| 113 |
+
"max_std_step": float(max_std_step),
|
| 114 |
+
"min_std": float(min_std),
|
| 115 |
+
"min_std_step": float(min_std_step),
|
| 116 |
+
"mean_std": float(mean_std),
|
| 117 |
+
"avg_snr": float(snr),
|
| 118 |
+
"max_n_std": float(max_n_std)
|
| 119 |
+
}
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def format_statistics(stats: dict[str, float]) -> tuple[str, str, str, str]:
|
| 123 |
+
if not stats:
|
| 124 |
+
stats = defaultdict(lambda: np.nan)
|
| 125 |
+
monotonicity_md_text = f"Average=**{stats['avg_spearman']:.3f}**"
|
| 126 |
+
variability_md_text = f"""SNR=**{stats['avg_snr']:.2f}**; Mean std_dev=**{stats['mean_std']:.5f}**;
|
| 127 |
+
Min std_dev=**{stats['min_std']:.3f} (step {stats['min_std_step']})**;
|
| 128 |
+
Max std_dev=**{stats['max_std']:.3f} (step {stats['max_std_step']})**"""
|
| 129 |
+
randomness_md_text = (f"Maximum distance of final checkpoint to random baseline="
|
| 130 |
+
f"**{stats['max_n_std']:.2f}** std_devs")
|
| 131 |
+
ordering_md_text = (f"Average Kendall-A Tau between second half of consecutive steps="
|
| 132 |
+
f"**{stats['avg_kendall_tau_a']:.3f}**")
|
| 133 |
+
|
| 134 |
+
return monotonicity_md_text, variability_md_text, randomness_md_text, ordering_md_text
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
def smooth_tasks(df: pd.DataFrame, rolling_window: int) -> pd.DataFrame:
|
| 138 |
+
if df.empty or "steps" not in df.columns:
|
| 139 |
+
return df
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
task_or_agg_columns = [c for c in df.columns if is_aggregate_column(c) or is_task_column(c)]
|
| 143 |
+
if rolling_window > 0:
|
| 144 |
+
smoothed_df = df.sort_values(by=["runname", "seed", "steps"])
|
| 145 |
+
smoothed_df = smoothed_df.groupby(['runname', 'seed'])[task_or_agg_columns].rolling(rolling_window, min_periods=1).mean().reset_index(level=[0,1])
|
| 146 |
+
smoothed_df["steps"] = df["steps"]
|
| 147 |
+
df = smoothed_df
|
| 148 |
+
return df
|
| 149 |
+
|
| 150 |
+
def generate_and_export_stats(run_data: RunData, std_dev_run_name: str, baseline_runs: list[str], baseline_mode: BASELINE_GROUPING_MODE, score_s: int, baseline_window: int) -> gr.File:
|
| 151 |
+
if not run_data:
|
| 152 |
+
return gr.File(value=None, visible=False)
|
| 153 |
+
|
| 154 |
+
stats_data: list[dict] = []
|
| 155 |
+
|
| 156 |
+
task_metrics = set(f"{task_info.name}/{metric}" for run in run_data for task_info in run.tasks
|
| 157 |
+
for metric, value in task_info.metrics.items())
|
| 158 |
+
|
| 159 |
+
df = create_df_from_run_data(run_data)
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
df = add_baseline_rows(df, baseline_runs, baseline_mode)
|
| 163 |
+
|
| 164 |
+
df = select_runs(df, runs_to_exclude=baseline_runs)
|
| 165 |
+
|
| 166 |
+
df = smooth_tasks(df, 3)
|
| 167 |
+
|
| 168 |
+
for column in list(progress.tqdm(task_metrics)):
|
| 169 |
+
if not is_task_column(column):
|
| 170 |
+
continue
|
| 171 |
+
|
| 172 |
+
# Calculate statistics
|
| 173 |
+
task_stats = calculate_statistics(df, std_dev_run_name, column, score_s, baseline_window)
|
| 174 |
+
|
| 175 |
+
task, metric = column.split("/")
|
| 176 |
+
|
| 177 |
+
# Add to stats_data
|
| 178 |
+
stats_data.append({
|
| 179 |
+
"task": task,
|
| 180 |
+
"metric": metric.removesuffix("|0/"),
|
| 181 |
+
**task_stats
|
| 182 |
+
})
|
| 183 |
+
|
| 184 |
+
# Create DataFrame and export to CSV
|
| 185 |
+
stats_df = pd.DataFrame(stats_data)
|
| 186 |
+
stats_df.to_csv("statistics.csv", index=False)
|
| 187 |
+
|
| 188 |
+
return gr.File(value="statistics.csv", visible=True)
|
| 189 |
+
|
viewer/task_type_mapping.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
from functools import lru_cache
|
| 3 |
+
from typing import Literal, Dict, Optional
|
| 4 |
+
|
| 5 |
+
TASK_TYPE = Literal['GK', 'RC', 'RES', 'NLU', 'TOXICITY', 'MATH', 'SEMANTIC']
|
| 6 |
+
|
| 7 |
+
task_mapping: dict[TASK_TYPE, list[str]] = {
|
| 8 |
+
'GK': ['arc', 'hi-arc', '.*mmlu', 'mkqa', '.*exams', "mintaka", "m3exam", 'acva', 'agieval', 'ceval', 'x-csqa', 'sciq', 'ruworldtree', 'truthfulqa'],
|
| 9 |
+
'RC': ['belebele', 'tydiqa', 'xquad', 'fquad', ".*meta_ar", 'indicqa', 'cmrc', 'thaiqa', 'tqduad2', 'mlqa', 'race', 'arcd', 'chai', '.*boolq', 'lambada', 'kenswquad', 'chinese-squad', 'sber_squad', '.*soqal', 'c3'],
|
| 10 |
+
'RES': ['x-codah', 'xcopa', 'math-logic-qa', 'parus', 'ruopenbookqa', 'openbook_qa', 'piqa'],
|
| 11 |
+
'NLU': ['.*xnli', '.*hellaswag', 'xstory_cloze', 'xwinograd', 'pawns', 'rcb', 'ocnli'],
|
| 12 |
+
'TOXICITY': ['toxigen'],
|
| 13 |
+
'MATH': ['cmath'],
|
| 14 |
+
'SEMANTIC': ['.*sentiment'],
|
| 15 |
+
}
|
| 16 |
+
|
| 17 |
+
def get_regex_from_strs(strs: list[str]) -> str:
|
| 18 |
+
return r'|'.join(strs)
|
| 19 |
+
|
| 20 |
+
@lru_cache(maxsize=1)
|
| 21 |
+
def create_task_type_retriever() -> Dict[str, TASK_TYPE]:
|
| 22 |
+
return {
|
| 23 |
+
get_regex_from_strs(tasks): task_type
|
| 24 |
+
for task_type, tasks in task_mapping.items()
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
def get_task_type(task_name: str) -> Optional[TASK_TYPE]:
|
| 28 |
+
"""
|
| 29 |
+
Given a task name in format of 'suite|task_name|...', returns the type of task
|
| 30 |
+
"""
|
| 31 |
+
# Ensure we don't put too much into cache
|
| 32 |
+
real_task_name = task_name.split('|')[1]
|
| 33 |
+
return _get_task_type(real_task_name)
|
| 34 |
+
|
| 35 |
+
@lru_cache(maxsize=10_000)
|
| 36 |
+
def _get_task_type(task_name: str) -> Optional[TASK_TYPE]:
|
| 37 |
+
task_type_mapping = create_task_type_retriever()
|
| 38 |
+
for pattern, task_type in task_type_mapping.items():
|
| 39 |
+
if re.match(pattern, task_name):
|
| 40 |
+
return task_type
|
| 41 |
+
return None
|
viewer/utils.py
ADDED
|
@@ -0,0 +1,186 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import defaultdict
|
| 2 |
+
from dataclasses import dataclass
|
| 3 |
+
from typing import Literal, Type
|
| 4 |
+
|
| 5 |
+
import pandas as pd
|
| 6 |
+
from typing import List
|
| 7 |
+
|
| 8 |
+
import gradio as gr
|
| 9 |
+
import numpy as np
|
| 10 |
+
import pandas as pd
|
| 11 |
+
|
| 12 |
+
from viewer.literals import REFERENCE_RUNS, TASK_CONSISTENCY_BUTTON_CLOSE_LABEL, TASK_CONSISTENCY_BUTTON_LABEL
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
@dataclass
|
| 16 |
+
class PlotOptions:
|
| 17 |
+
smoothing: int
|
| 18 |
+
interpolate: bool
|
| 19 |
+
pct: bool
|
| 20 |
+
merge_seeds: str
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
@dataclass(frozen=True)
|
| 24 |
+
class TaskInfo:
|
| 25 |
+
# Source file from which the task was fetched
|
| 26 |
+
filename: str
|
| 27 |
+
name: str
|
| 28 |
+
metrics: dict[str, float]
|
| 29 |
+
hashes: dict[str, str]
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
@dataclass(frozen=True)
|
| 33 |
+
class RunInfo:
|
| 34 |
+
name: str
|
| 35 |
+
seed: int
|
| 36 |
+
step: int
|
| 37 |
+
tasks: list[TaskInfo]
|
| 38 |
+
|
| 39 |
+
@property
|
| 40 |
+
def full_name(self):
|
| 41 |
+
return f"{self.name}-seed-{self.seed}" if not self.name.endswith("-") else self.name
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
RunData = list[RunInfo]
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def get_run_name_seed(run_name):
|
| 48 |
+
if "-seed-" not in run_name:
|
| 49 |
+
return run_name, 42
|
| 50 |
+
run_name, seed = run_name.split("-seed-")
|
| 51 |
+
return run_name, int(seed)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def select_runs(df: pd.DataFrame, runs_to_include: list[str] | None = None, runs_to_exclude: list[str] | None = None):
|
| 55 |
+
conditions = pd.Series(True, index=df.index)
|
| 56 |
+
|
| 57 |
+
if runs_to_include:
|
| 58 |
+
conditions_include = [(df['runname'] == get_run_name_seed(run)[0]) & (df['seed'] == get_run_name_seed(run)[1]) for run in runs_to_include]
|
| 59 |
+
conditions = pd.concat(conditions_include, axis=1).any(axis=1)
|
| 60 |
+
if runs_to_exclude:
|
| 61 |
+
conditions_exclude = [(df['runname'] == get_run_name_seed(run)[0]) & (df['seed'] == get_run_name_seed(run)[1]) for run in runs_to_exclude]
|
| 62 |
+
conditions = ~pd.concat(conditions_exclude, axis=1).any(axis=1)
|
| 63 |
+
|
| 64 |
+
return df[conditions]
|
| 65 |
+
|
| 66 |
+
BASELINE_GROUPING_MODE = Literal["Mean", "Median", "Min", "Max"]
|
| 67 |
+
def get_groupped_score(df: pd.DataFrame, runs: list[str], groupping_mode: BASELINE_GROUPING_MODE):
|
| 68 |
+
if len(runs) == 0:
|
| 69 |
+
return pd.DataFrame(columns=df.columns)
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
tasks_or_agg = [col for col in df.columns if is_task_column(col) or is_aggregate_column(col)]
|
| 73 |
+
|
| 74 |
+
res = select_runs(df, runs_to_include=runs)
|
| 75 |
+
|
| 76 |
+
if groupping_mode == "Mean":
|
| 77 |
+
return res.groupby("steps")[tasks_or_agg].mean().reset_index()
|
| 78 |
+
elif groupping_mode == "Median":
|
| 79 |
+
return res.groupby("steps")[tasks_or_agg].median().reset_index()
|
| 80 |
+
elif groupping_mode == "Min":
|
| 81 |
+
return res.groupby("steps")[tasks_or_agg].min().reset_index()
|
| 82 |
+
elif groupping_mode == "Max":
|
| 83 |
+
return res.groupby("steps")[tasks_or_agg].max().reset_index()
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def check_task_hash_consistency(run_data: RunData, check_task_consistency_button):
|
| 88 |
+
if not run_data or check_task_consistency_button == TASK_CONSISTENCY_BUTTON_CLOSE_LABEL:
|
| 89 |
+
return gr.update(value={}, visible=False), gr.update(value=TASK_CONSISTENCY_BUTTON_LABEL)
|
| 90 |
+
# Ignore the continuation tokens, as they vary with generative tasks
|
| 91 |
+
hash_keys = ["hash_examples", "hash_full_prompts"]
|
| 92 |
+
task_hashes = defaultdict(lambda: defaultdict(list))
|
| 93 |
+
|
| 94 |
+
for run in run_data:
|
| 95 |
+
for task_info in run.tasks:
|
| 96 |
+
hashes = task_info.hashes
|
| 97 |
+
hash_values = tuple(hashes.get(k) for k in hash_keys)
|
| 98 |
+
task_hashes[task_info.name][hash_values].append({
|
| 99 |
+
"name": run.name,
|
| 100 |
+
"step": run.step,
|
| 101 |
+
"filename": task_info.filename
|
| 102 |
+
})
|
| 103 |
+
|
| 104 |
+
conflicts = {}
|
| 105 |
+
for task, hash_groups in task_hashes.items():
|
| 106 |
+
if len(hash_groups) > 1:
|
| 107 |
+
conflicts[task] = [
|
| 108 |
+
{
|
| 109 |
+
"runs": runs,
|
| 110 |
+
"hashes": dict(zip(hash_keys, hash_values))
|
| 111 |
+
}
|
| 112 |
+
for hash_values, runs in hash_groups.items()
|
| 113 |
+
]
|
| 114 |
+
|
| 115 |
+
return gr.Json(value={"conflicts": conflicts}, visible=True), gr.Button(value=TASK_CONSISTENCY_BUTTON_CLOSE_LABEL)
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def create_df_from_run_data(run_data: RunData):
|
| 119 |
+
df = pd.DataFrame([
|
| 120 |
+
{
|
| 121 |
+
"runname": run.name,
|
| 122 |
+
"seed": run.seed,
|
| 123 |
+
"steps": run.step,
|
| 124 |
+
"agg_score_micro": 0,
|
| 125 |
+
**{
|
| 126 |
+
f"{task_info.name}/{metric}": value
|
| 127 |
+
for task_info in run.tasks
|
| 128 |
+
for metric, value in task_info.metrics.items()
|
| 129 |
+
}
|
| 130 |
+
} for run in run_data
|
| 131 |
+
])
|
| 132 |
+
df = df.fillna(0)
|
| 133 |
+
return df
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def is_task_column(column: str):
|
| 137 |
+
return "/" in column
|
| 138 |
+
|
| 139 |
+
def is_aggregate_column(column: str):
|
| 140 |
+
return column.startswith("agg_score")
|
| 141 |
+
|
| 142 |
+
def is_baseline_run(run: str):
|
| 143 |
+
return any(run.startswith(prefix) for prefix in ["random", "dummy", "baseline"])
|
| 144 |
+
|
| 145 |
+
def is_reference_run(run: str):
|
| 146 |
+
return any([ref_run + "-" in run for ref_run in REFERENCE_RUNS])
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def z_score_normalize(df: pd.DataFrame, normalization_runs: List[str], columns: List[str], variability_window: int = 1) -> pd.DataFrame:
|
| 150 |
+
# without 2 runs we can't estimate the std
|
| 151 |
+
if len(normalization_runs) <= 1:
|
| 152 |
+
return df
|
| 153 |
+
|
| 154 |
+
normalization_df = select_runs(df, runs_to_include=normalization_runs)
|
| 155 |
+
|
| 156 |
+
# Group by steps and calculate mean and std for all columns at once
|
| 157 |
+
grouped = normalization_df.groupby('steps')[columns]
|
| 158 |
+
means = grouped.mean()
|
| 159 |
+
stds = grouped.std()
|
| 160 |
+
|
| 161 |
+
# Ensure we don't divide by zero
|
| 162 |
+
stds = stds.replace(0, 1)
|
| 163 |
+
|
| 164 |
+
# fetch values at the highest step
|
| 165 |
+
last_means = means.loc[means.index.max()]
|
| 166 |
+
# fetch and average the last N steps defined by the window size
|
| 167 |
+
last_window_stds = stds.sort_index(ascending=False).head(variability_window).mean()
|
| 168 |
+
|
| 169 |
+
df[columns] = (df[columns].sub(last_means[columns], axis=1)
|
| 170 |
+
.div(last_window_stds[columns], axis=1))
|
| 171 |
+
|
| 172 |
+
return df
|
| 173 |
+
|
| 174 |
+
def rescale_scores(df: pd.DataFrame, normalization_runs: List[str], columns: List[str]) -> pd.DataFrame:
|
| 175 |
+
baseline = get_groupped_score(df, normalization_runs, "Mean")
|
| 176 |
+
|
| 177 |
+
# Prepare baseline values and df for vectorized operation
|
| 178 |
+
baseline = baseline.set_index("steps").reindex(df["steps"].unique()).interpolate().reset_index()
|
| 179 |
+
|
| 180 |
+
rescaled_cols = baseline.columns[~((baseline <= 0.0).all() | (baseline == 1.0).all())]
|
| 181 |
+
rescaled_cols = rescaled_cols[(rescaled_cols != 'steps') & rescaled_cols.isin(columns)]
|
| 182 |
+
|
| 183 |
+
df_with_baseline = df.merge(baseline[list(rescaled_cols) + ['steps']], on=["steps"], how="left", suffixes=("", "_baseline")).fillna(0)
|
| 184 |
+
df[rescaled_cols] = df[rescaled_cols].sub(df_with_baseline[rescaled_cols + '_baseline'].values)
|
| 185 |
+
df[rescaled_cols] = df[rescaled_cols].div(1 - df_with_baseline[rescaled_cols + '_baseline'].values)
|
| 186 |
+
return df
|