
Commit
·
25fb861
1
Parent(s):
f81ed15
up
Browse files
README.md
CHANGED
|
@@ -47,7 +47,7 @@ All evaluation results on the public datasets can be found [here]().
|
|
| 47 |
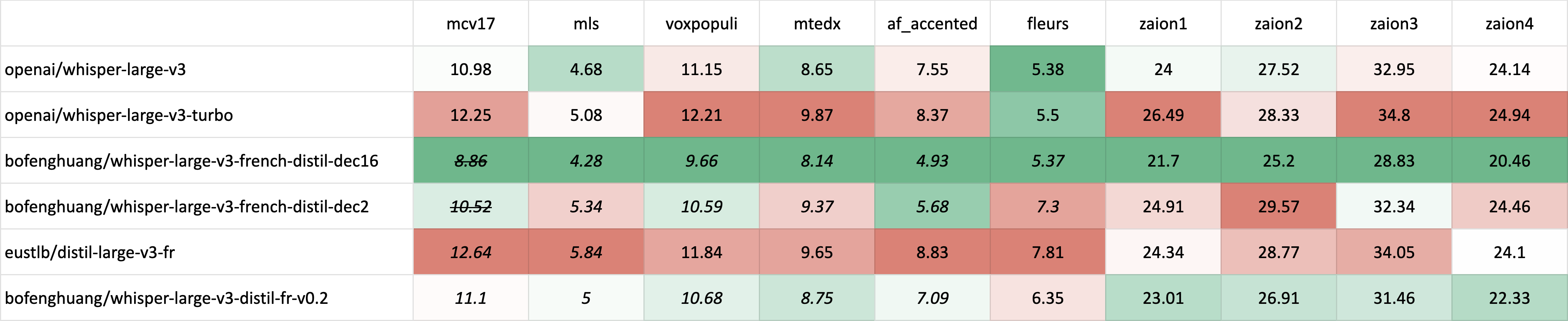
| [distil-large-v3-fr](https://huggingface.co/eustlb/distil-large-v3-fr) | *12.64* | *5.84* | 11.84 | 9.65 | 8.83 | 7.81 | 24.34 | 28.77 | 34.05 | 24.10 |
|
| 48 |
| whisper-large-v3-distil-fr-v0.2 | *11.10* | *5.00* | *10.68* | *8.75* | *7.09* | 6.35 | 23.01 | 26.91 | 31.46 | 22.33 | -->
|
| 49 |
|
| 50 |
-
 evaluation, where test sets correspond to data distributions seen during training, typically yielding higher performance than out-of-distribution (OOD) evaluation. *~~Italic and strikethrough~~* denotes potential test set contamination - for example, when training and evaluation use different versions of Common Voice, raising the possibility of overlapping data.
|
| 53 |
|
|
@@ -57,7 +57,7 @@ Due to the limited availability of out-of-distribution (OOD) and long-form Frenc
|
|
| 57 |
|
| 58 |
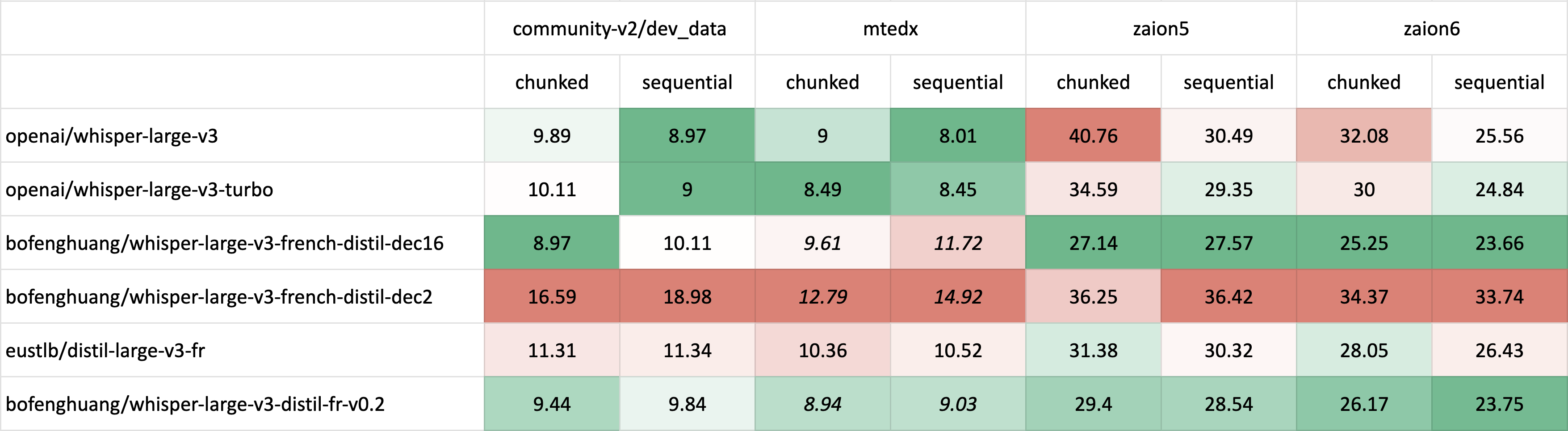
Long-form transcription evaluation used the 🤗 Hugging Face [`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline) with both [chunked](https://huggingface.co/blog/asr-chunking) (chunk_length_s=30) and original sequential decoding methods.
|
| 59 |
|
| 60 |
-
 | | [mtedx](https://www.openslr.org/100/) | | zaion5 | | zaion6 | |
|
| 63 |
|-------|-----------|-----------|---------|-----------|---------|-----------|---------|-----------|
|
|
|
|
| 47 |
| [distil-large-v3-fr](https://huggingface.co/eustlb/distil-large-v3-fr) | *12.64* | *5.84* | 11.84 | 9.65 | 8.83 | 7.81 | 24.34 | 28.77 | 34.05 | 24.10 |
|
| 48 |
| whisper-large-v3-distil-fr-v0.2 | *11.10* | *5.00* | *10.68* | *8.75* | *7.09* | 6.35 | 23.01 | 26.91 | 31.46 | 22.33 | -->
|
| 49 |
|
| 50 |
+
|
| 51 |
|
| 52 |
*Italic* indicates in-distribution (ID) evaluation, where test sets correspond to data distributions seen during training, typically yielding higher performance than out-of-distribution (OOD) evaluation. *~~Italic and strikethrough~~* denotes potential test set contamination - for example, when training and evaluation use different versions of Common Voice, raising the possibility of overlapping data.
|
| 53 |
|
|
|
|
| 57 |
|
| 58 |
Long-form transcription evaluation used the 🤗 Hugging Face [`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline) with both [chunked](https://huggingface.co/blog/asr-chunking) (chunk_length_s=30) and original sequential decoding methods.
|
| 59 |
|
| 60 |
+
|
| 61 |
|
| 62 |
<!-- | Model | [dev_data](https://huggingface.co/datasets/speech-recognition-community-v2/dev_data) | | [mtedx](https://www.openslr.org/100/) | | zaion5 | | zaion6 | |
|
| 63 |
|-------|-----------|-----------|---------|-----------|---------|-----------|---------|-----------|
|