Timm ❤️ Transformers: Use any timm model with transformers







Get lightning-fast inference, quick quantization,
torch.compile boosts, and effortless fine-tuning
for any timm model—all within the friendly 🤗 transformers ecosystem.
Enter TimmWrapper—a simple,
yet powerful tool that unlocks this potential.
In this post, we’ll cover:
- How the timm integration works and why it’s a game-changer.
- How to integrate
timmmodels with 🤗transformers. - Practical examples: pipelines, quantization, fine-tuning, and more.
To follow along with this blog post, install the latest version of
transformersandtimmby running:pip install -Uq transformers timm
Check out the full repository for all code examples and notebooks: 🔗 TimmWrapper Examples
What is timm?
The PyTorch Image Models (timm) library
offers a rich collection of state-of-the-art computer vision models,
along with useful layers, utilities, optimizers, and data augmentations.
With more than 32K GitHub stars and more than 200K daily downloads at the time of writing,
it's a go-to resource for image classification and feature extraction for object detection,
segmentation, image search, and other downstream tasks.
With pre-trained models covering a wide range of architectures, timm simplifies the workflow for
computer vision practitioners.
Why Use the timm integration?
While 🤗 transformers supports several vision models, timm offers an even broader collection,
including many mobile-friendly and efficient models not available in transformers.
The timm integration bridges this gap, bringing the best of both worlds:
- ✅ Pipeline API Support: Easily plug any
timmmodel into the high-leveltransformerspipeline for streamlined inference. - 🧩 Compatibility with Auto Classes: While
timmmodels aren’t natively compatible withtransformers, the integration makes them work seamlessly with theAutoclasses API. - ⚡ Quick Quantization: With just ~5 lines of code, you can quantize any
timmmodel for efficient inference. - 🎯 Fine-Tuning with Trainer API: Fine-tune
timmmodels using theTrainerAPI and even integrate with adapters like low rank adaptation (LoRA). - 🔁 Round trip to timm: Use fine-tuned models back in
timm. - 🚀 Torch Compile for Speed: Leverage
torch.compileto optimize inference time.
Pipeline API: Using timm Models for Image Classification
One of the standout features of the timm integration is that it allows you to leverage the 🤗 pipeline API.
The pipeline API abstracts away a lot of complexity, making it easy to load a pre-trained model,
perform inference, and view results with a few lines of code.
Let's see how to use a transformers pipeline with the MobileNetV4. This architecture does not have a native transformers implementation, but can be easily used from timm:
from transformers import pipeline
import requests
# Load the image classification pipeline with a timm model
image_classifier = pipeline(model="timm/mobilenetv4_conv_medium.e500_r256_in1k")
# URL of the image to classify
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/timm/cat.jpg"
# Perform inference
outputs = image_classifier(url)
# Print the results
for output in outputs:
print(f"Label: {output['label'] :20} Score: {output['score'] :0.2f}")
Outputs:
Device set to use cpu
Label: tabby, tabby cat Score: 0.69
Label: tiger cat Score: 0.21
Label: Egyptian cat Score: 0.02
Label: bee Score: 0.00
Label: marmoset Score: 0.00
Gradio Integration: Building a Food Classifier Demo 🍣
Want to quickly create an interactive web app for image classification? Gradio makes it simple
to build a user-friendly interface with minimal code. Let's combine Gradio with the pipeline API
to classify food images using a fine-tuned timm ViT model (we will cover fine tuning in a later section).
Here’s how you can set up a quick demo with a timm model:
import gradio as gr
from transformers import pipeline
# Load the image classification pipeline using a timm model
pipe = pipeline(
"image-classification",
model="ariG23498/vit_base_patch16_224.augreg2_in21k_ft_in1k.ft_food101"
)
def classify(image):
return pipe(image)[0]["label"]
demo = gr.Interface(
fn=classify,
inputs=gr.Image(type="pil"),
outputs="text",
examples=[["./sushi.png", "sushi"]]
)
demo.launch()
Here’s a live example hosted on Hugging Face Spaces. You can test it directly in your browser!
Auto Classes: Simplifying Model Loading
The 🤗 transformers library provides Auto Classes to abstract away the complexity of loading
models and processors. With the TimmWrapper, you can use AutoModelForImageClassification
and AutoImageProcessor to load any timm model effortlessly.
Here’s a quick example:
from transformers import (
AutoModelForImageClassification,
AutoImageProcessor,
)
from transformers.image_utils import load_image
image_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/timm/cat.jpg"
image = load_image(image_url)
# Use Auto classes to load a timm model
checkpoint = "timm/mobilenetv4_conv_medium.e500_r256_in1k"
image_processor = AutoImageProcessor.from_pretrained(checkpoint)
model = AutoModelForImageClassification.from_pretrained(checkpoint).eval()
# Check the types
print(type(image_processor)) # TimmWrapperImageProcessor
print(type(model)) # TimmWrapperForImageClassification
Running quantized timm models
Quantization is a powerful technique to reduce model size and speed up inference,
especially for deployment on resource-constrained devices. With the timm integration,
you can quantize any timm model on the fly with just a few lines of code using
BitsAndBytesConfig from bitsandbytes.
Here’s how simple it is to quantize a timm model:
from transformers import TimmWrapperForImageClassification, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
checkpoint = "timm/vit_base_patch16_224.augreg2_in21k_ft_in1k"
model = TimmWrapperForImageClassification.from_pretrained(checkpoint).to("cuda")
model_8bit = TimmWrapperForImageClassification.from_pretrained(
checkpoint,
quantization_config=quantization_config,
low_cpu_mem_usage=True,
)
original_footprint = model.get_memory_footprint()
quantized_footprint = model_8bit.get_memory_footprint()
print(f"Original model size: {original_footprint / 1e6:.2f} MB")
print(f"Quantized model size: {quantized_footprint / 1e6:.2f} MB")
print(f"Reduction: {(original_footprint - quantized_footprint) / original_footprint * 100:.2f}%")
Output:
Original model size: 346.27 MB
Quantized model size: 88.20 MB
Reduction: 74.53%
Quantized models perform almost identically to full-precision models during inference:
| Model | Label | Accuracy |
|---|---|---|
| Original Model | remote control, remote | 0.35% |
| Quantized Model | remote control, remote | 0.33% |
Supervised Fine-Tuning of timm models
Fine-tuning a timm model with the Trainer API from 🤗 transformers is straightforward and highly flexible.
You can fine-tune your model on custom datasets using the Trainer class, which handles the training loop,
logging, and evaluation. Additionally, you can fine-tune using LoRA (Low-Rank Adaptation) to train efficiently with fewer parameters.
This section gives a quick overview of both standard fine-tuning and LoRA fine-tuning, with links to the complete code.
Standard Fine-Tuning with the Trainer API
The Trainer API makes it easy to set up training with minimal code. Here's an outline of what a fine-tuning setup looks like:
from transformers import TrainingArguments, Trainer
# Define training arguments
training_args = TrainingArguments(
output_dir="my_model_output",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=5e-5,
per_device_train_batch_size=16,
num_train_epochs=3,
load_best_model_at_end=True,
push_to_hub=True,
)
# Initialize the Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_ds,
eval_dataset=val_ds,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
# Start training
trainer.train()
What's remarkable about this approach is that it mirrors the exact workflow used for native transformers models,
maintaining consistency across different model types.
This means you can use the familiar Trainer API to fine-tune not just Transformers models, but
also any timm model—bringing powerful models from the timm library into the Hugging Face
ecosystem with minimal adjustments. This significantly broadens the scope of models you can fine-tune
using the same trusted tools and workflows.
Model Example:
Fine-tuned ViT on Food-101: vit_base_patch16_224.augreg2_in21k_ft_in1k.ft_food101
LoRA Fine-Tuning for Efficient Training
LoRA (Low-Rank Adaptation) allows you to fine-tune large models efficiently by training only a
few additional parameters, rather than the full set of model weights. This makes fine-tuning faster,
and allows the use of consumer hardware. You can fine-tune a timm model using
LoRA with the PEFT library.
Here’s how you can set it up:
from peft import LoraConfig, get_peft_model
model = AutoModelForImageClassification.from_pretrained(checkpoint, num_labels=num_labels)
lora_config = LoraConfig(
r=16,
lora_alpha=16,
target_modules=["qkv"],
lora_dropout=0.1,
bias="none",
modules_to_save=["head"],
)
# Wrap the model with PEFT
lora_model = get_peft_model(model, lora_config)
lora_model.print_trainable_parameters()
Trainable Parameters with LoRA:
trainable params: 667,493 || all params: 86,543,818 || trainable%: 0.77%
Model Example:
LoRA Fine-Tuned ViT on Food-101: vit_base_patch16_224.augreg2_in21k_ft_in1k.lora_ft_food101
LoRA is just one example of efficient adapter-based fine-tuning methods you can apply to timm models.
The integration of timm with the 🤗 ecosystem opens up a wide variety of parameter-efficient fine-tuning (PEFT) techniques,
allowing you to choose the method that best fits your use case.
Inference with LoRA Fine-Tuned Model
Once the model is LoRA fine-tuned, we only push the adapter weights to the Hugging Face Hub. This section helps you to download the adapter weights, merge the adapter weights with the base model, and then perform inference.
from peft import PeftModel, PeftConfig
repo_name = "ariG23498/vit_base_patch16_224.augreg2_in21k_ft_in1k.lora_ft_food101"
config = PeftConfig.from_pretrained(repo_name)
model = AutoModelForImageClassification.from_pretrained(
config.base_model_name_or_path,
label2id=label2id,
num_labels=num_labels,
id2label=id2label,
ignore_mismatched_sizes=True,
)
inference_model = PeftModel.from_pretrained(model, repo_name)
# Make prediction with the model

Round trip integration
One of Ross' (creator of timm) favourite features is that this integration maintains
full 'round-trip' compatibility. Namely, using the wrapper one can fine-tune a timm model on a new dataset using transformer's Trainer, publish the resulting model to the Hugging Face hub, and then load the fine-tuned model in timm again using timm.create_model('hf-hub:my_org/my_fine_tuned_model', pretrained=True).
Let us see how we can load our fine tuned model ariG23498/vit_base_patch16_224.augreg2_in21k_ft_in1k.ft_food101 with timm
checkpoint = "ariG23498/vit_base_patch16_224.augreg2_in21k_ft_in1k.ft_food101"
config = AutoConfig.from_pretrained(checkpoint)
model = timm.create_model(f"hf_hub:{checkpoint}", pretrained=True) # Load the model with timm
model = model.eval()
image = load_image("https://cdn.britannica.com/52/128652-050-14AD19CA/Maki-zushi.jpg")
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(image).unsqueeze(0))
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
for prob, idx in zip(top5_probabilities[0], top5_class_indices[0]):
print(f"Label: {config.id2label[idx.item()] :20} Score: {prob/100 :0.2f}%")
Outputs
Label: sushi Score: 0.98%
Label: spring_rolls Score: 0.01%
Label: sashimi Score: 0.00%
Label: club_sandwich Score: 0.00%
Label: cannoli Score: 0.00%
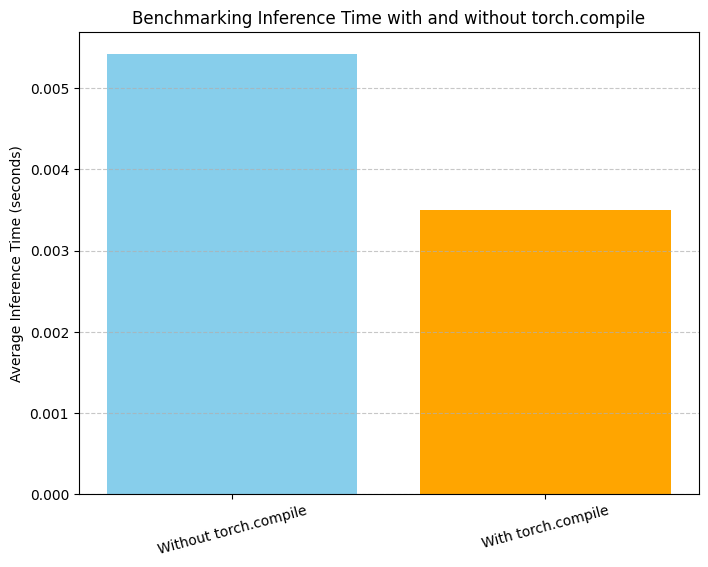
Torch Compile: Instant Speedup
With torch.compile in PyTorch 2.0, you can achieve faster inference by compiling your model
with just one line of code. The timm integration is fully compatible with torch.compile.
Here's a quick benchmark to compare inference time with and without torch.compile using the TimmWrapper.
# Load the model and input
model = TimmWrapperForImageClassification.from_pretrained(checkpoint).to(device)
processed_input = image_processor(image, return_tensors="pt").to(device)
# Benchmark function
def run_benchmark(model, input_data, warmup_runs=5, benchmark_runs=300):
# Warm-up phase
model.eval()
with torch.no_grad():
for _ in range(warmup_runs):
_ = model(**input_data)
# Benchmark phase
times = []
with torch.no_grad():
for _ in range(benchmark_runs):
start_time = time.perf_counter()
_ = model(**input_data)
if device.type == "cuda":
torch.cuda.synchronize(device=device) # Ensure synchronization for CUDA
times.append(time.perf_counter() - start_time)
avg_time = sum(times) / benchmark_runs
return avg_time
# Run benchmarks
time_no_compile = run_benchmark(model, processed_input)
compiled_model = torch.compile(model).to(device)
time_compile = run_benchmark(compiled_model, processed_input)
# Results
print(f"Without torch.compile: {time_no_compile:.4f} s")
print(f"With torch.compile: {time_compile:.4f} s")
Wrapping Up
timm's integration with transformers opens new doors for leveraging state-of-the-art vision models
with minimal effort. Whether you're looking to fine-tune, quantize, or simply run inference, this
integration provides a unified API to streamline your workflow.
Start exploring today and unlock new possibilities in computer vision!
Acknowledgments
We want to give a huge shout-out to the folks who made this integration happen in Transformers PR #34564. In no particular order, a big thanks to Pavel Iakubovskii, Ross Wightman, Lysandre Debut, Pablo Montalvo, Arthur Zucker, and Amy Roberts for all your incredible work. Your combined efforts took this feature from an idea to something everyone can now enjoy!






