Open Preference Dataset for Text-to-Image Generation by the 🤗 Community










The Data is Better Together community releases yet another important dataset for open source development. Due to the lack of open preference datasets for text-to-image generation, we set out to release an Apache 2.0 licensed dataset for text-to-image generation. This dataset is focused on text-to-image preference pairs across common image generation categories, while mixing different model families and varying prompt complexities.
TL;DR? All results can be found in this collection on the Hugging Face Hub and code for pre- and post-processing can be found in this GitHub repository. Most importantly, there is a ready-to-go preference dataset and a flux-dev-lora-finetune. If you want to show your support already, don’t forget to like, subscribe and follow us before you continue reading further.
Unfamiliar with the Data is Better Together community?
[Data is Better Together](https://huggingface.co/data-is-better-together) is a collaboration between 🤗 Hugging Face and the Open-Source AI community. We aim to empower the open-source community to build impactful datasets collectively. You can follow the organization to stay up to date with the latest datasets, models, and community sprints.
Similar efforts
There have been several efforts to create an open image preference dataset but our effort is unique due to the varying complexity and categories of the prompts, alongside the openness of the dataset and the code to create it. The following are some of the efforts:
- [yuvalkirstain/pickapic_v2](https://huggingface.co/datasets/yuvalkirstain/pickapic_v2)
- [fal.ai/imgsys](https://imgsys.org/)
- [TIGER-Lab/GenAI-Arena](https://huggingface.co/spaces/TIGER-Lab/GenAI-Arena)
- [artificialanalysis image arena](https://artificialanalysis.ai/text-to-image/arena)
The input dataset
To get a proper input dataset for this sprint, we started with some base prompts, which we cleaned, filtered for toxicity and injected with categories and complexities using synthetic data generation with distilabel. Lastly, we used Flux and Stable Diffusion models to generate the images. This resulted in the open-image-preferences-v1.
Input prompts
Imgsys is a generative image model arena hosted by fal.ai, where people provide prompts and get to choose between two model generations to provide a preference. Sadly, the generated images are not published publicly, however, the associated prompts are hosted on Hugging Face. These prompts represent real-life usage of image generation containing good examples focused on day-to-day generation, but this real-life usage also meant it contained duplicate and toxic prompts, hence we had to look at the data and do some filtering.
Reducing toxicity
We aimed to remove all NSFW prompts and images from the dataset before starting the community. We settled on a multi-model approach where we used two text-based and two image-based classifiers as filters. Post-filtering, we decided to do a manual check of each one of the images to make sure no toxic content was left, luckily we found our approach had worked.
We used the following pipeline:
- Classify images as NSFW
- Remove all positive samples
- Argilla team manually reviews the dataset
- Repeat based on review
Synthetic prompt enhancement
Data diversity is important for data quality, which is why we decided to enhance our dataset by synthetically rewriting prompts based on various categories and complexities. This was done using a distilabel pipeline.
| Type | Prompt | Image |
|---|---|---|
| Default | a harp without any strings |  |
| Stylized | a harp without strings, in an anime style, with intricate details and flowing lines, set against a dreamy, pastel background |  |
| Quality | a harp without strings, in an anime style, with intricate details and flowing lines, set against a dreamy, pastel background, bathed in soft golden hour light, with a serene mood and rich textures, high resolution, photorealistic |  |
Prompt categories
InstructGPT describes foundational task categories for text-to-text generation but there is no clear equivalent of this for text-to-image generation. To alleviate this, we used two main sources as input for our categories: google/sdxl and Microsoft. This led to the following main categories: ["Cinematic", "Photographic", "Anime", "Manga", "Digital art", "Pixel art", "Fantasy art", "Neonpunk", "3D Model", “Painting”, “Animation” “Illustration”]. On top of that we also chose some mutually exclusive, sub-categories to allow us to further diversify the prompts. These categories and sub-categories have been randomly sampled and are therefore roughly equally distributed across the dataset.
Prompt complexities
The Deita paper proved that evolving complexity and diversity of prompts leads to better model generations and fine-tunes, however, humans don’t always take time to write extensive prompts. Therefore we decided to use the same prompt in a complex and simplified manner as two datapoints for different preference generations.
Image generation
The ArtificialAnalysis/Text-to-Image-Leaderboard shows an overview of the best performing image models. We choose two of the best performing models based on their license and their availability on the Hub. Additionally, we made sure that the model would belong to different model families in order to not highlight generations across different categories. Therefore, we chose stabilityai/stable-diffusion-3.5-large and black-forest-labs/FLUX.1-dev. Each of these models was then used to generate an image for both the simplified and complex prompt within the same stylistic categories.

The results
A raw export of all of the annotated data contains responses to a multiple choice, where each annotator chose whether either one of the models was better, both models performed good or both models performed bad. Based on this we got to look at the annotator alignment, the model performance across categories and even do a model-finetune, which you can already play with on the Hub! The following shows the annotated dataset:
Annotator alignment
Annotator agreement is a way to check the validity of a task. Whenever a task is too hard, annotators might not be aligned, and whenever a task is too easy they might be aligned too much. Striking a balance is rare but we managed to get it spot on during this sprint. We did this analysis using the Hugging Face datasets SQL console. Overall, SD3.5-XL was a bit more likely to win within our test setup.
Model performance
Given the annotator alignment, both models proved to perform better within their own right, so we did an additional analysis to see if there were differences across the categories. In short, FLUX-dev works better for anime, and SD3.5-XL works better for art and cinematic scenarios.
- Tie: Photographic, Animation
- FLUX-dev better: 3D Model, Anime, Manga
- SD3.5-XL better: Cinematic, Digital art, Fantasy art, Illustration, Neonpunk, Painting, Pixel art
Model-finetune
To verify the quality of the dataset, while not spending too much time and resources we decided to do a LoRA fine-tune of the black-forest-labs/FLUX.1-dev model based on the diffusers example on GitHub. During this process, we included the chosen sample as expected completions for the FLUX-dev model and left out the rejected samples. Interestingly, the chosen fine-tuned models perform much better in art and cinematic scenarios where it was initially lacking! You can test the fine-tuned adapter here.
| Prompt | Original | Fine-tune |
|---|---|---|
| a boat in the canals of Venice, painted in gouache with soft, flowing brushstrokes and vibrant, translucent colors, capturing the serene reflection on the water under a misty ambiance, with rich textures and a dynamic perspective |  |
 |
| A vibrant orange poppy flower, enclosed in an ornate golden frame, against a black backdrop, rendered in anime style with bold outlines, exaggerated details, and a dramatic chiaroscuro lighting. |  |
 |
| Grainy shot of a robot cooking in the kitchen, with soft shadows and nostalgic film texture. |  |
 |
The community
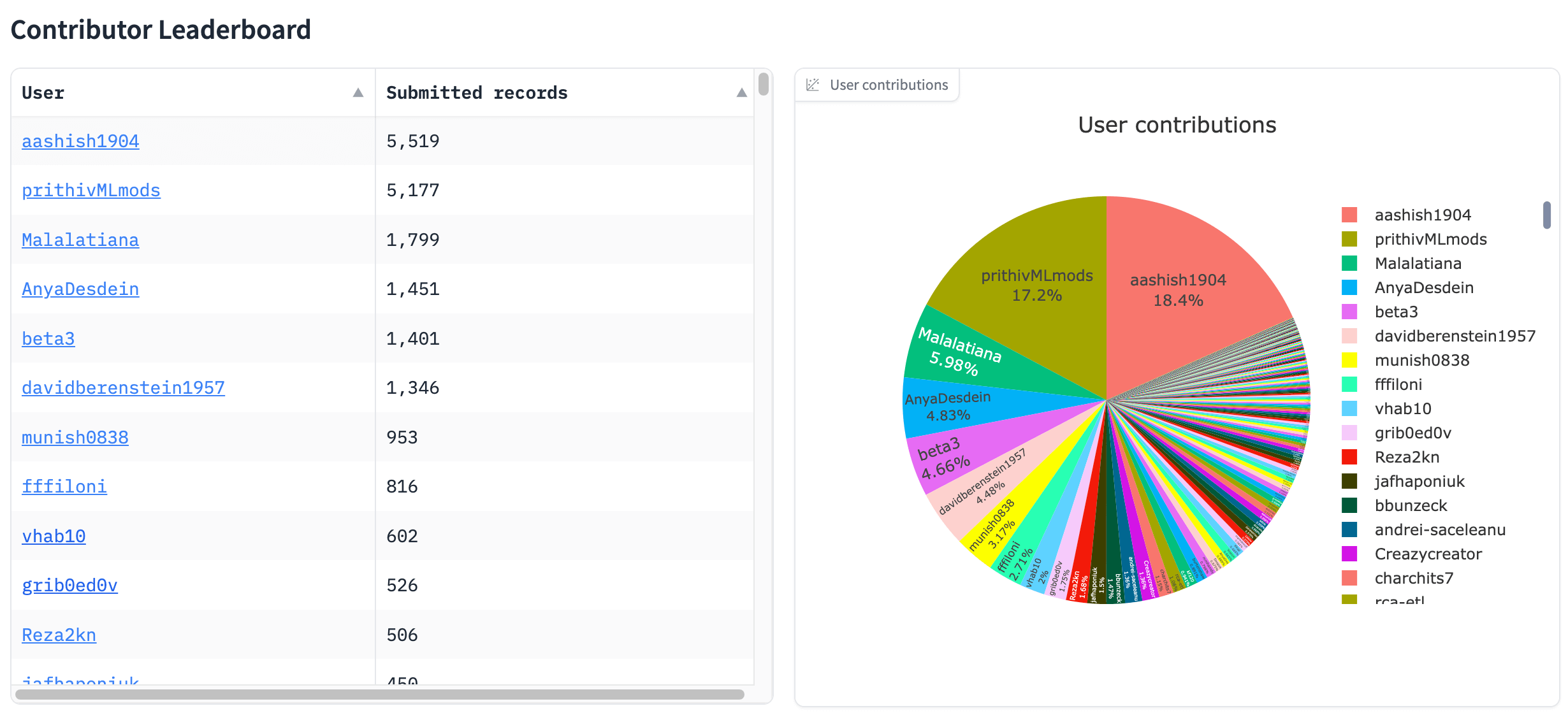
In short, we annotated 10K preference pairs with an annotator overlap of 2 / 3, which resulted in over 30K responses in less than 2 weeks with over 250 community members! The image leaderboard shows some community members even giving more than 5K preferences. We want to thank everyone that participated in this sprint with a special thanks to the top 3 users, who will all get a month of Hugging Face Pro membership. Make sure to follow them on the Hub: aashish1904, prithivMLmods, Malalatiana.
What is next?
After another successful community sprint, we will continue organising them on the Hugging Face Hub. Make sure to follow the Data Is Better Together organisation to stay updated. We also encourage community members to take action themselves and are happy to guide and reshare on socials and within the organisation on the Hub. You can contribute in several ways:
- Join and participate in other sprints.
- Propose your own sprints or requests for high quality datasets.
- Fine-tune models on top of the preference dataset. One idea would be to do a full SFT fine-tune of SDXL or FLUX-schnell. Another idea would be to do a DPO/ORPO fine-tune.
- Evaluate the improved performance of the LoRA adapter compared to the original SD3.5-XL and FLUX-dev models.







