
Upload folder using huggingface_hub
Browse files- README.md +59 -0
- adapter_config.json +31 -0
- adapter_model.safetensors +3 -0
- all_results.json +9 -0
- llamaboard_config.yaml +65 -0
- qwen.tiktoken +0 -0
- running_log.txt +208 -0
- special_tokens_map.json +10 -0
- tokenization_qwen.py +276 -0
- tokenizer_config.json +17 -0
- train_results.json +9 -0
- trainer_log.jsonl +11 -0
- trainer_state.json +123 -0
- training_args.bin +3 -0
- training_args.yaml +33 -0
- training_loss.png +0 -0
README.md
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
base_model: Qwen/Qwen-1_8B-Chat
|
| 3 |
+
library_name: peft
|
| 4 |
+
license: other
|
| 5 |
+
tags:
|
| 6 |
+
- llama-factory
|
| 7 |
+
- lora
|
| 8 |
+
- generated_from_trainer
|
| 9 |
+
model-index:
|
| 10 |
+
- name: train_2024-07-16-18-56-15
|
| 11 |
+
results: []
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 15 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 16 |
+
|
| 17 |
+
# train_2024-07-16-18-56-15
|
| 18 |
+
|
| 19 |
+
This model is a fine-tuned version of [Qwen/Qwen-1_8B-Chat](https://huggingface.co/Qwen/Qwen-1_8B-Chat) on the glaive_toolcall_en_demo dataset.
|
| 20 |
+
|
| 21 |
+
## Model description
|
| 22 |
+
|
| 23 |
+
More information needed
|
| 24 |
+
|
| 25 |
+
## Intended uses & limitations
|
| 26 |
+
|
| 27 |
+
More information needed
|
| 28 |
+
|
| 29 |
+
## Training and evaluation data
|
| 30 |
+
|
| 31 |
+
More information needed
|
| 32 |
+
|
| 33 |
+
## Training procedure
|
| 34 |
+
|
| 35 |
+
### Training hyperparameters
|
| 36 |
+
|
| 37 |
+
The following hyperparameters were used during training:
|
| 38 |
+
- learning_rate: 5e-05
|
| 39 |
+
- train_batch_size: 2
|
| 40 |
+
- eval_batch_size: 8
|
| 41 |
+
- seed: 42
|
| 42 |
+
- gradient_accumulation_steps: 8
|
| 43 |
+
- total_train_batch_size: 16
|
| 44 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 45 |
+
- lr_scheduler_type: cosine
|
| 46 |
+
- num_epochs: 3.0
|
| 47 |
+
- mixed_precision_training: Native AMP
|
| 48 |
+
|
| 49 |
+
### Training results
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
### Framework versions
|
| 54 |
+
|
| 55 |
+
- PEFT 0.11.1
|
| 56 |
+
- Transformers 4.41.2
|
| 57 |
+
- Pytorch 2.3.0+cu121
|
| 58 |
+
- Datasets 2.20.0
|
| 59 |
+
- Tokenizers 0.19.1
|
adapter_config.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "Qwen/Qwen-1_8B-Chat",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"fan_in_fan_out": false,
|
| 7 |
+
"inference_mode": true,
|
| 8 |
+
"init_lora_weights": true,
|
| 9 |
+
"layer_replication": null,
|
| 10 |
+
"layers_pattern": null,
|
| 11 |
+
"layers_to_transform": null,
|
| 12 |
+
"loftq_config": {},
|
| 13 |
+
"lora_alpha": 16,
|
| 14 |
+
"lora_dropout": 0,
|
| 15 |
+
"megatron_config": null,
|
| 16 |
+
"megatron_core": "megatron.core",
|
| 17 |
+
"modules_to_save": null,
|
| 18 |
+
"peft_type": "LORA",
|
| 19 |
+
"r": 8,
|
| 20 |
+
"rank_pattern": {},
|
| 21 |
+
"revision": null,
|
| 22 |
+
"target_modules": [
|
| 23 |
+
"c_attn",
|
| 24 |
+
"c_proj",
|
| 25 |
+
"w1",
|
| 26 |
+
"w2"
|
| 27 |
+
],
|
| 28 |
+
"task_type": "CAUSAL_LM",
|
| 29 |
+
"use_dora": false,
|
| 30 |
+
"use_rslora": false
|
| 31 |
+
}
|
adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:afe14312e77d17e1f123d737ac5109b3156574658b1cecd671446dce7b9722b5
|
| 3 |
+
size 26867400
|
all_results.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.88,
|
| 3 |
+
"num_input_tokens_seen": 530864,
|
| 4 |
+
"total_flos": 4880889936150528.0,
|
| 5 |
+
"train_loss": 0.5967088187182391,
|
| 6 |
+
"train_runtime": 437.0311,
|
| 7 |
+
"train_samples_per_second": 2.059,
|
| 8 |
+
"train_steps_per_second": 0.124
|
| 9 |
+
}
|
llamaboard_config.yaml
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
top.booster: auto
|
| 2 |
+
top.checkpoint_path: []
|
| 3 |
+
top.finetuning_type: lora
|
| 4 |
+
top.model_name: Qwen-1.8B-Chat
|
| 5 |
+
top.quantization_bit: none
|
| 6 |
+
top.quantization_method: bitsandbytes
|
| 7 |
+
top.rope_scaling: none
|
| 8 |
+
top.template: qwen
|
| 9 |
+
top.visual_inputs: false
|
| 10 |
+
train.additional_target: ''
|
| 11 |
+
train.badam_mode: layer
|
| 12 |
+
train.badam_switch_interval: 50
|
| 13 |
+
train.badam_switch_mode: ascending
|
| 14 |
+
train.badam_update_ratio: 0.05
|
| 15 |
+
train.batch_size: 2
|
| 16 |
+
train.compute_type: fp16
|
| 17 |
+
train.create_new_adapter: false
|
| 18 |
+
train.cutoff_len: 1024
|
| 19 |
+
train.dataset:
|
| 20 |
+
- glaive_toolcall_en_demo
|
| 21 |
+
train.dataset_dir: data
|
| 22 |
+
train.ds_offload: false
|
| 23 |
+
train.ds_stage: none
|
| 24 |
+
train.freeze_extra_modules: ''
|
| 25 |
+
train.freeze_trainable_layers: 2
|
| 26 |
+
train.freeze_trainable_modules: all
|
| 27 |
+
train.galore_rank: 16
|
| 28 |
+
train.galore_scale: 0.25
|
| 29 |
+
train.galore_target: all
|
| 30 |
+
train.galore_update_interval: 200
|
| 31 |
+
train.gradient_accumulation_steps: 8
|
| 32 |
+
train.learning_rate: 5e-5
|
| 33 |
+
train.logging_steps: 5
|
| 34 |
+
train.lora_alpha: 16
|
| 35 |
+
train.lora_dropout: 0
|
| 36 |
+
train.lora_rank: 8
|
| 37 |
+
train.lora_target: ''
|
| 38 |
+
train.loraplus_lr_ratio: 0
|
| 39 |
+
train.lr_scheduler_type: cosine
|
| 40 |
+
train.max_grad_norm: '1.0'
|
| 41 |
+
train.max_samples: '100000'
|
| 42 |
+
train.neat_packing: false
|
| 43 |
+
train.neftune_alpha: 0
|
| 44 |
+
train.num_train_epochs: '3.0'
|
| 45 |
+
train.optim: adamw_torch
|
| 46 |
+
train.packing: false
|
| 47 |
+
train.ppo_score_norm: false
|
| 48 |
+
train.ppo_whiten_rewards: false
|
| 49 |
+
train.pref_beta: 0.1
|
| 50 |
+
train.pref_ftx: 0
|
| 51 |
+
train.pref_loss: sigmoid
|
| 52 |
+
train.report_to: false
|
| 53 |
+
train.resize_vocab: false
|
| 54 |
+
train.reward_model: null
|
| 55 |
+
train.save_steps: 100
|
| 56 |
+
train.shift_attn: false
|
| 57 |
+
train.training_stage: Supervised Fine-Tuning
|
| 58 |
+
train.use_badam: false
|
| 59 |
+
train.use_dora: false
|
| 60 |
+
train.use_galore: false
|
| 61 |
+
train.use_llama_pro: false
|
| 62 |
+
train.use_pissa: false
|
| 63 |
+
train.use_rslora: false
|
| 64 |
+
train.val_size: 0
|
| 65 |
+
train.warmup_steps: 0
|
qwen.tiktoken
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
running_log.txt
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[INFO|parser.py:344] 2024-07-16 19:25:29,726 >> Process rank: 0, device: cuda:0, n_gpu: 1, distributed training: False, compute dtype: torch.float16
|
| 2 |
+
|
| 3 |
+
[INFO|tokenization_utils_base.py:2108] 2024-07-16 19:25:32,413 >> loading file qwen.tiktoken from cache at /root/.cache/huggingface/hub/models--Qwen--Qwen-1_8B-Chat/snapshots/1d0f68de57b88cfde81f3c3e537f24464d889081/qwen.tiktoken
|
| 4 |
+
|
| 5 |
+
[INFO|tokenization_utils_base.py:2108] 2024-07-16 19:25:32,413 >> loading file added_tokens.json from cache at None
|
| 6 |
+
|
| 7 |
+
[INFO|tokenization_utils_base.py:2108] 2024-07-16 19:25:32,413 >> loading file special_tokens_map.json from cache at None
|
| 8 |
+
|
| 9 |
+
[INFO|tokenization_utils_base.py:2108] 2024-07-16 19:25:32,413 >> loading file tokenizer_config.json from cache at /root/.cache/huggingface/hub/models--Qwen--Qwen-1_8B-Chat/snapshots/1d0f68de57b88cfde81f3c3e537f24464d889081/tokenizer_config.json
|
| 10 |
+
|
| 11 |
+
[INFO|tokenization_utils_base.py:2108] 2024-07-16 19:25:32,414 >> loading file tokenizer.json from cache at None
|
| 12 |
+
|
| 13 |
+
[INFO|template.py:268] 2024-07-16 19:25:32,773 >> Add eos token: <|im_end|>
|
| 14 |
+
|
| 15 |
+
[INFO|template.py:372] 2024-07-16 19:25:32,773 >> Add pad token: <|im_end|>
|
| 16 |
+
|
| 17 |
+
[INFO|loader.py:52] 2024-07-16 19:25:32,774 >> Loading dataset glaive_toolcall_en_demo.json...
|
| 18 |
+
|
| 19 |
+
[INFO|configuration_utils.py:733] 2024-07-16 19:26:23,755 >> loading configuration file config.json from cache at /root/.cache/huggingface/hub/models--Qwen--Qwen-1_8B-Chat/snapshots/1d0f68de57b88cfde81f3c3e537f24464d889081/config.json
|
| 20 |
+
|
| 21 |
+
[INFO|configuration_utils.py:733] 2024-07-16 19:26:24,494 >> loading configuration file config.json from cache at /root/.cache/huggingface/hub/models--Qwen--Qwen-1_8B-Chat/snapshots/1d0f68de57b88cfde81f3c3e537f24464d889081/config.json
|
| 22 |
+
|
| 23 |
+
[INFO|configuration_utils.py:796] 2024-07-16 19:26:24,495 >> Model config QWenConfig {
|
| 24 |
+
"_name_or_path": "Qwen/Qwen-1_8B-Chat",
|
| 25 |
+
"architectures": [
|
| 26 |
+
"QWenLMHeadModel"
|
| 27 |
+
],
|
| 28 |
+
"attn_dropout_prob": 0.0,
|
| 29 |
+
"auto_map": {
|
| 30 |
+
"AutoConfig": "Qwen/Qwen-1_8B-Chat--configuration_qwen.QWenConfig",
|
| 31 |
+
"AutoModelForCausalLM": "Qwen/Qwen-1_8B-Chat--modeling_qwen.QWenLMHeadModel"
|
| 32 |
+
},
|
| 33 |
+
"bf16": false,
|
| 34 |
+
"emb_dropout_prob": 0.0,
|
| 35 |
+
"fp16": false,
|
| 36 |
+
"fp32": false,
|
| 37 |
+
"hidden_size": 2048,
|
| 38 |
+
"initializer_range": 0.02,
|
| 39 |
+
"intermediate_size": 11008,
|
| 40 |
+
"kv_channels": 128,
|
| 41 |
+
"layer_norm_epsilon": 1e-06,
|
| 42 |
+
"max_position_embeddings": 8192,
|
| 43 |
+
"model_type": "qwen",
|
| 44 |
+
"no_bias": true,
|
| 45 |
+
"num_attention_heads": 16,
|
| 46 |
+
"num_hidden_layers": 24,
|
| 47 |
+
"onnx_safe": null,
|
| 48 |
+
"rotary_emb_base": 10000,
|
| 49 |
+
"rotary_pct": 1.0,
|
| 50 |
+
"scale_attn_weights": true,
|
| 51 |
+
"seq_length": 8192,
|
| 52 |
+
"softmax_in_fp32": false,
|
| 53 |
+
"tie_word_embeddings": false,
|
| 54 |
+
"tokenizer_class": "QWenTokenizer",
|
| 55 |
+
"transformers_version": "4.41.2",
|
| 56 |
+
"use_cache": true,
|
| 57 |
+
"use_cache_kernel": false,
|
| 58 |
+
"use_cache_quantization": false,
|
| 59 |
+
"use_dynamic_ntk": true,
|
| 60 |
+
"use_flash_attn": "auto",
|
| 61 |
+
"use_logn_attn": true,
|
| 62 |
+
"vocab_size": 151936
|
| 63 |
+
}
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
[INFO|modeling_utils.py:3474] 2024-07-16 19:26:26,974 >> loading weights file model.safetensors from cache at /root/.cache/huggingface/hub/models--Qwen--Qwen-1_8B-Chat/snapshots/1d0f68de57b88cfde81f3c3e537f24464d889081/model.safetensors.index.json
|
| 67 |
+
|
| 68 |
+
[INFO|modeling_utils.py:1519] 2024-07-16 19:26:45,032 >> Instantiating QWenLMHeadModel model under default dtype torch.float16.
|
| 69 |
+
|
| 70 |
+
[INFO|configuration_utils.py:962] 2024-07-16 19:26:45,034 >> Generate config GenerationConfig {}
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
[INFO|modeling_utils.py:4280] 2024-07-16 19:26:51,937 >> All model checkpoint weights were used when initializing QWenLMHeadModel.
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
[INFO|modeling_utils.py:4288] 2024-07-16 19:26:51,937 >> All the weights of QWenLMHeadModel were initialized from the model checkpoint at Qwen/Qwen-1_8B-Chat.
|
| 77 |
+
If your task is similar to the task the model of the checkpoint was trained on, you can already use QWenLMHeadModel for predictions without further training.
|
| 78 |
+
|
| 79 |
+
[INFO|configuration_utils.py:917] 2024-07-16 19:26:52,423 >> loading configuration file generation_config.json from cache at /root/.cache/huggingface/hub/models--Qwen--Qwen-1_8B-Chat/snapshots/1d0f68de57b88cfde81f3c3e537f24464d889081/generation_config.json
|
| 80 |
+
|
| 81 |
+
[INFO|configuration_utils.py:962] 2024-07-16 19:26:52,424 >> Generate config GenerationConfig {
|
| 82 |
+
"chat_format": "chatml",
|
| 83 |
+
"do_sample": true,
|
| 84 |
+
"eos_token_id": 151643,
|
| 85 |
+
"max_new_tokens": 512,
|
| 86 |
+
"max_window_size": 6144,
|
| 87 |
+
"pad_token_id": 151643,
|
| 88 |
+
"repetition_penalty": 1.1,
|
| 89 |
+
"top_k": 0,
|
| 90 |
+
"top_p": 0.8
|
| 91 |
+
}
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
[WARNING|checkpointing.py:70] 2024-07-16 19:26:52,440 >> You are using the old GC format, some features (e.g. BAdam) will be invalid.
|
| 95 |
+
|
| 96 |
+
[INFO|checkpointing.py:103] 2024-07-16 19:26:52,440 >> Gradient checkpointing enabled.
|
| 97 |
+
|
| 98 |
+
[INFO|attention.py:86] 2024-07-16 19:26:52,440 >> Using vanilla attention implementation.
|
| 99 |
+
|
| 100 |
+
[INFO|adapter.py:302] 2024-07-16 19:26:52,441 >> Upcasting trainable params to float32.
|
| 101 |
+
|
| 102 |
+
[INFO|adapter.py:158] 2024-07-16 19:26:52,441 >> Fine-tuning method: LoRA
|
| 103 |
+
|
| 104 |
+
[INFO|misc.py:51] 2024-07-16 19:26:52,442 >> Found linear modules: c_attn,c_proj,w1,w2
|
| 105 |
+
|
| 106 |
+
[INFO|loader.py:196] 2024-07-16 19:26:53,145 >> trainable params: 6,709,248 || all params: 1,843,537,920 || trainable%: 0.3639
|
| 107 |
+
|
| 108 |
+
[INFO|trainer.py:641] 2024-07-16 19:26:53,161 >> Using auto half precision backend
|
| 109 |
+
|
| 110 |
+
[INFO|trainer.py:2078] 2024-07-16 19:26:54,481 >> ***** Running training *****
|
| 111 |
+
|
| 112 |
+
[INFO|trainer.py:2079] 2024-07-16 19:26:54,481 >> Num examples = 300
|
| 113 |
+
|
| 114 |
+
[INFO|trainer.py:2080] 2024-07-16 19:26:54,481 >> Num Epochs = 3
|
| 115 |
+
|
| 116 |
+
[INFO|trainer.py:2081] 2024-07-16 19:26:54,481 >> Instantaneous batch size per device = 2
|
| 117 |
+
|
| 118 |
+
[INFO|trainer.py:2084] 2024-07-16 19:26:54,481 >> Total train batch size (w. parallel, distributed & accumulation) = 16
|
| 119 |
+
|
| 120 |
+
[INFO|trainer.py:2085] 2024-07-16 19:26:54,481 >> Gradient Accumulation steps = 8
|
| 121 |
+
|
| 122 |
+
[INFO|trainer.py:2086] 2024-07-16 19:26:54,482 >> Total optimization steps = 54
|
| 123 |
+
|
| 124 |
+
[INFO|trainer.py:2087] 2024-07-16 19:26:54,484 >> Number of trainable parameters = 6,709,248
|
| 125 |
+
|
| 126 |
+
[INFO|callbacks.py:310] 2024-07-16 19:27:37,133 >> {'loss': 0.6756, 'learning_rate': 4.8950e-05, 'epoch': 0.27, 'throughput': 1193.09}
|
| 127 |
+
|
| 128 |
+
[INFO|callbacks.py:310] 2024-07-16 19:28:17,112 >> {'loss': 0.6799, 'learning_rate': 4.5887e-05, 'epoch': 0.53, 'throughput': 1200.41}
|
| 129 |
+
|
| 130 |
+
[INFO|callbacks.py:310] 2024-07-16 19:28:56,484 >> {'loss': 0.6995, 'learning_rate': 4.1070e-05, 'epoch': 0.80, 'throughput': 1208.30}
|
| 131 |
+
|
| 132 |
+
[INFO|callbacks.py:310] 2024-07-16 19:29:36,117 >> {'loss': 0.6313, 'learning_rate': 3.4902e-05, 'epoch': 1.07, 'throughput': 1209.98}
|
| 133 |
+
|
| 134 |
+
[INFO|callbacks.py:310] 2024-07-16 19:30:17,804 >> {'loss': 0.5683, 'learning_rate': 2.7902e-05, 'epoch': 1.33, 'throughput': 1211.98}
|
| 135 |
+
|
| 136 |
+
[INFO|callbacks.py:310] 2024-07-16 19:30:57,971 >> {'loss': 0.4988, 'learning_rate': 2.0659e-05, 'epoch': 1.60, 'throughput': 1214.64}
|
| 137 |
+
|
| 138 |
+
[INFO|callbacks.py:310] 2024-07-16 19:31:38,903 >> {'loss': 0.5748, 'learning_rate': 1.3780e-05, 'epoch': 1.87, 'throughput': 1215.63}
|
| 139 |
+
|
| 140 |
+
[INFO|callbacks.py:310] 2024-07-16 19:32:15,869 >> {'loss': 0.5793, 'learning_rate': 7.8440e-06, 'epoch': 2.13, 'throughput': 1214.06}
|
| 141 |
+
|
| 142 |
+
[INFO|callbacks.py:310] 2024-07-16 19:32:55,941 >> {'loss': 0.5500, 'learning_rate': 3.3494e-06, 'epoch': 2.40, 'throughput': 1214.25}
|
| 143 |
+
|
| 144 |
+
[INFO|callbacks.py:310] 2024-07-16 19:33:38,528 >> {'loss': 0.5715, 'learning_rate': 6.7388e-07, 'epoch': 2.67, 'throughput': 1214.09}
|
| 145 |
+
|
| 146 |
+
[INFO|trainer.py:2329] 2024-07-16 19:34:11,515 >>
|
| 147 |
+
|
| 148 |
+
Training completed. Do not forget to share your model on huggingface.co/models =)
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
[INFO|trainer.py:3410] 2024-07-16 19:34:11,517 >> Saving model checkpoint to saves/Qwen-1.8B-Chat/lora/train_2024-07-16-18-56-15
|
| 153 |
+
|
| 154 |
+
[INFO|configuration_utils.py:733] 2024-07-16 19:34:12,032 >> loading configuration file config.json from cache at /root/.cache/huggingface/hub/models--Qwen--Qwen-1_8B-Chat/snapshots/1d0f68de57b88cfde81f3c3e537f24464d889081/config.json
|
| 155 |
+
|
| 156 |
+
[INFO|configuration_utils.py:796] 2024-07-16 19:34:12,033 >> Model config QWenConfig {
|
| 157 |
+
"architectures": [
|
| 158 |
+
"QWenLMHeadModel"
|
| 159 |
+
],
|
| 160 |
+
"attn_dropout_prob": 0.0,
|
| 161 |
+
"auto_map": {
|
| 162 |
+
"AutoConfig": "Qwen/Qwen-1_8B-Chat--configuration_qwen.QWenConfig",
|
| 163 |
+
"AutoModelForCausalLM": "Qwen/Qwen-1_8B-Chat--modeling_qwen.QWenLMHeadModel"
|
| 164 |
+
},
|
| 165 |
+
"bf16": false,
|
| 166 |
+
"emb_dropout_prob": 0.0,
|
| 167 |
+
"fp16": false,
|
| 168 |
+
"fp32": false,
|
| 169 |
+
"hidden_size": 2048,
|
| 170 |
+
"initializer_range": 0.02,
|
| 171 |
+
"intermediate_size": 11008,
|
| 172 |
+
"kv_channels": 128,
|
| 173 |
+
"layer_norm_epsilon": 1e-06,
|
| 174 |
+
"max_position_embeddings": 8192,
|
| 175 |
+
"model_type": "qwen",
|
| 176 |
+
"no_bias": true,
|
| 177 |
+
"num_attention_heads": 16,
|
| 178 |
+
"num_hidden_layers": 24,
|
| 179 |
+
"onnx_safe": null,
|
| 180 |
+
"rotary_emb_base": 10000,
|
| 181 |
+
"rotary_pct": 1.0,
|
| 182 |
+
"scale_attn_weights": true,
|
| 183 |
+
"seq_length": 8192,
|
| 184 |
+
"softmax_in_fp32": false,
|
| 185 |
+
"tie_word_embeddings": false,
|
| 186 |
+
"tokenizer_class": "QWenTokenizer",
|
| 187 |
+
"transformers_version": "4.41.2",
|
| 188 |
+
"use_cache": true,
|
| 189 |
+
"use_cache_kernel": false,
|
| 190 |
+
"use_cache_quantization": false,
|
| 191 |
+
"use_dynamic_ntk": true,
|
| 192 |
+
"use_flash_attn": "auto",
|
| 193 |
+
"use_logn_attn": true,
|
| 194 |
+
"vocab_size": 151936
|
| 195 |
+
}
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
[INFO|tokenization_utils_base.py:2513] 2024-07-16 19:34:12,174 >> tokenizer config file saved in saves/Qwen-1.8B-Chat/lora/train_2024-07-16-18-56-15/tokenizer_config.json
|
| 199 |
+
|
| 200 |
+
[INFO|tokenization_utils_base.py:2522] 2024-07-16 19:34:12,174 >> Special tokens file saved in saves/Qwen-1.8B-Chat/lora/train_2024-07-16-18-56-15/special_tokens_map.json
|
| 201 |
+
|
| 202 |
+
[WARNING|ploting.py:89] 2024-07-16 19:34:12,511 >> No metric eval_loss to plot.
|
| 203 |
+
|
| 204 |
+
[WARNING|ploting.py:89] 2024-07-16 19:34:12,512 >> No metric eval_accuracy to plot.
|
| 205 |
+
|
| 206 |
+
[INFO|modelcard.py:450] 2024-07-16 19:34:12,513 >> Dropping the following result as it does not have all the necessary fields:
|
| 207 |
+
{'task': {'name': 'Causal Language Modeling', 'type': 'text-generation'}}
|
| 208 |
+
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"eos_token": {
|
| 3 |
+
"content": "<|im_end|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"pad_token": "<|im_end|>"
|
| 10 |
+
}
|
tokenization_qwen.py
ADDED
|
@@ -0,0 +1,276 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Alibaba Cloud.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
"""Tokenization classes for QWen."""
|
| 7 |
+
|
| 8 |
+
import base64
|
| 9 |
+
import logging
|
| 10 |
+
import os
|
| 11 |
+
import unicodedata
|
| 12 |
+
from typing import Collection, Dict, List, Set, Tuple, Union
|
| 13 |
+
|
| 14 |
+
import tiktoken
|
| 15 |
+
from transformers import PreTrainedTokenizer, AddedToken
|
| 16 |
+
|
| 17 |
+
logger = logging.getLogger(__name__)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
VOCAB_FILES_NAMES = {"vocab_file": "qwen.tiktoken"}
|
| 21 |
+
|
| 22 |
+
PAT_STR = r"""(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+"""
|
| 23 |
+
ENDOFTEXT = "<|endoftext|>"
|
| 24 |
+
IMSTART = "<|im_start|>"
|
| 25 |
+
IMEND = "<|im_end|>"
|
| 26 |
+
# as the default behavior is changed to allow special tokens in
|
| 27 |
+
# regular texts, the surface forms of special tokens need to be
|
| 28 |
+
# as different as possible to minimize the impact
|
| 29 |
+
EXTRAS = tuple((f"<|extra_{i}|>" for i in range(205)))
|
| 30 |
+
# changed to use actual index to avoid misconfiguration with vocabulary expansion
|
| 31 |
+
SPECIAL_START_ID = 151643
|
| 32 |
+
SPECIAL_TOKENS = tuple(
|
| 33 |
+
enumerate(
|
| 34 |
+
(
|
| 35 |
+
(
|
| 36 |
+
ENDOFTEXT,
|
| 37 |
+
IMSTART,
|
| 38 |
+
IMEND,
|
| 39 |
+
)
|
| 40 |
+
+ EXTRAS
|
| 41 |
+
),
|
| 42 |
+
start=SPECIAL_START_ID,
|
| 43 |
+
)
|
| 44 |
+
)
|
| 45 |
+
SPECIAL_TOKENS_SET = set(t for i, t in SPECIAL_TOKENS)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def _load_tiktoken_bpe(tiktoken_bpe_file: str) -> Dict[bytes, int]:
|
| 49 |
+
with open(tiktoken_bpe_file, "rb") as f:
|
| 50 |
+
contents = f.read()
|
| 51 |
+
return {
|
| 52 |
+
base64.b64decode(token): int(rank)
|
| 53 |
+
for token, rank in (line.split() for line in contents.splitlines() if line)
|
| 54 |
+
}
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class QWenTokenizer(PreTrainedTokenizer):
|
| 58 |
+
"""QWen tokenizer."""
|
| 59 |
+
|
| 60 |
+
vocab_files_names = VOCAB_FILES_NAMES
|
| 61 |
+
|
| 62 |
+
def __init__(
|
| 63 |
+
self,
|
| 64 |
+
vocab_file,
|
| 65 |
+
errors="replace",
|
| 66 |
+
extra_vocab_file=None,
|
| 67 |
+
**kwargs,
|
| 68 |
+
):
|
| 69 |
+
super().__init__(**kwargs)
|
| 70 |
+
|
| 71 |
+
# how to handle errors in decoding UTF-8 byte sequences
|
| 72 |
+
# use ignore if you are in streaming inference
|
| 73 |
+
self.errors = errors
|
| 74 |
+
|
| 75 |
+
self.mergeable_ranks = _load_tiktoken_bpe(vocab_file) # type: Dict[bytes, int]
|
| 76 |
+
self.special_tokens = {
|
| 77 |
+
token: index
|
| 78 |
+
for index, token in SPECIAL_TOKENS
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
# try load extra vocab from file
|
| 82 |
+
if extra_vocab_file is not None:
|
| 83 |
+
used_ids = set(self.mergeable_ranks.values()) | set(self.special_tokens.values())
|
| 84 |
+
extra_mergeable_ranks = _load_tiktoken_bpe(extra_vocab_file)
|
| 85 |
+
for token, index in extra_mergeable_ranks.items():
|
| 86 |
+
if token in self.mergeable_ranks:
|
| 87 |
+
logger.info(f"extra token {token} exists, skipping")
|
| 88 |
+
continue
|
| 89 |
+
if index in used_ids:
|
| 90 |
+
logger.info(f'the index {index} for extra token {token} exists, skipping')
|
| 91 |
+
continue
|
| 92 |
+
self.mergeable_ranks[token] = index
|
| 93 |
+
# the index may be sparse after this, but don't worry tiktoken.Encoding will handle this
|
| 94 |
+
|
| 95 |
+
enc = tiktoken.Encoding(
|
| 96 |
+
"Qwen",
|
| 97 |
+
pat_str=PAT_STR,
|
| 98 |
+
mergeable_ranks=self.mergeable_ranks,
|
| 99 |
+
special_tokens=self.special_tokens,
|
| 100 |
+
)
|
| 101 |
+
assert (
|
| 102 |
+
len(self.mergeable_ranks) + len(self.special_tokens) == enc.n_vocab
|
| 103 |
+
), f"{len(self.mergeable_ranks) + len(self.special_tokens)} != {enc.n_vocab} in encoding"
|
| 104 |
+
|
| 105 |
+
self.decoder = {
|
| 106 |
+
v: k for k, v in self.mergeable_ranks.items()
|
| 107 |
+
} # type: dict[int, bytes|str]
|
| 108 |
+
self.decoder.update({v: k for k, v in self.special_tokens.items()})
|
| 109 |
+
|
| 110 |
+
self.tokenizer = enc # type: tiktoken.Encoding
|
| 111 |
+
|
| 112 |
+
self.eod_id = self.tokenizer.eot_token
|
| 113 |
+
self.im_start_id = self.special_tokens[IMSTART]
|
| 114 |
+
self.im_end_id = self.special_tokens[IMEND]
|
| 115 |
+
|
| 116 |
+
def __getstate__(self):
|
| 117 |
+
# for pickle lovers
|
| 118 |
+
state = self.__dict__.copy()
|
| 119 |
+
del state["tokenizer"]
|
| 120 |
+
return state
|
| 121 |
+
|
| 122 |
+
def __setstate__(self, state):
|
| 123 |
+
# tokenizer is not python native; don't pass it; rebuild it
|
| 124 |
+
self.__dict__.update(state)
|
| 125 |
+
enc = tiktoken.Encoding(
|
| 126 |
+
"Qwen",
|
| 127 |
+
pat_str=PAT_STR,
|
| 128 |
+
mergeable_ranks=self.mergeable_ranks,
|
| 129 |
+
special_tokens=self.special_tokens,
|
| 130 |
+
)
|
| 131 |
+
self.tokenizer = enc
|
| 132 |
+
|
| 133 |
+
def __len__(self) -> int:
|
| 134 |
+
return self.tokenizer.n_vocab
|
| 135 |
+
|
| 136 |
+
def get_vocab(self) -> Dict[bytes, int]:
|
| 137 |
+
return self.mergeable_ranks
|
| 138 |
+
|
| 139 |
+
def convert_tokens_to_ids(
|
| 140 |
+
self, tokens: Union[bytes, str, List[Union[bytes, str]]]
|
| 141 |
+
) -> List[int]:
|
| 142 |
+
ids = []
|
| 143 |
+
if isinstance(tokens, (str, bytes)):
|
| 144 |
+
if tokens in self.special_tokens:
|
| 145 |
+
return self.special_tokens[tokens]
|
| 146 |
+
else:
|
| 147 |
+
return self.mergeable_ranks.get(tokens)
|
| 148 |
+
for token in tokens:
|
| 149 |
+
if token in self.special_tokens:
|
| 150 |
+
ids.append(self.special_tokens[token])
|
| 151 |
+
else:
|
| 152 |
+
ids.append(self.mergeable_ranks.get(token))
|
| 153 |
+
return ids
|
| 154 |
+
|
| 155 |
+
def _add_tokens(
|
| 156 |
+
self,
|
| 157 |
+
new_tokens: Union[List[str], List[AddedToken]],
|
| 158 |
+
special_tokens: bool = False,
|
| 159 |
+
) -> int:
|
| 160 |
+
if not special_tokens and new_tokens:
|
| 161 |
+
raise ValueError("Adding regular tokens is not supported")
|
| 162 |
+
for token in new_tokens:
|
| 163 |
+
surface_form = token.content if isinstance(token, AddedToken) else token
|
| 164 |
+
if surface_form not in SPECIAL_TOKENS_SET:
|
| 165 |
+
raise ValueError("Adding unknown special tokens is not supported")
|
| 166 |
+
return 0
|
| 167 |
+
|
| 168 |
+
def save_vocabulary(self, save_directory: str, **kwargs) -> Tuple[str]:
|
| 169 |
+
"""
|
| 170 |
+
Save only the vocabulary of the tokenizer (vocabulary).
|
| 171 |
+
|
| 172 |
+
Returns:
|
| 173 |
+
`Tuple(str)`: Paths to the files saved.
|
| 174 |
+
"""
|
| 175 |
+
file_path = os.path.join(save_directory, "qwen.tiktoken")
|
| 176 |
+
with open(file_path, "w", encoding="utf8") as w:
|
| 177 |
+
for k, v in self.mergeable_ranks.items():
|
| 178 |
+
line = base64.b64encode(k).decode("utf8") + " " + str(v) + "\n"
|
| 179 |
+
w.write(line)
|
| 180 |
+
return (file_path,)
|
| 181 |
+
|
| 182 |
+
def tokenize(
|
| 183 |
+
self,
|
| 184 |
+
text: str,
|
| 185 |
+
allowed_special: Union[Set, str] = "all",
|
| 186 |
+
disallowed_special: Union[Collection, str] = (),
|
| 187 |
+
**kwargs,
|
| 188 |
+
) -> List[Union[bytes, str]]:
|
| 189 |
+
"""
|
| 190 |
+
Converts a string in a sequence of tokens.
|
| 191 |
+
|
| 192 |
+
Args:
|
| 193 |
+
text (`str`):
|
| 194 |
+
The sequence to be encoded.
|
| 195 |
+
allowed_special (`Literal["all"]` or `set`):
|
| 196 |
+
The surface forms of the tokens to be encoded as special tokens in regular texts.
|
| 197 |
+
Default to "all".
|
| 198 |
+
disallowed_special (`Literal["all"]` or `Collection`):
|
| 199 |
+
The surface forms of the tokens that should not be in regular texts and trigger errors.
|
| 200 |
+
Default to an empty tuple.
|
| 201 |
+
|
| 202 |
+
kwargs (additional keyword arguments, *optional*):
|
| 203 |
+
Will be passed to the underlying model specific encode method.
|
| 204 |
+
|
| 205 |
+
Returns:
|
| 206 |
+
`List[bytes|str]`: The list of tokens.
|
| 207 |
+
"""
|
| 208 |
+
tokens = []
|
| 209 |
+
text = unicodedata.normalize("NFC", text)
|
| 210 |
+
|
| 211 |
+
# this implementation takes a detour: text -> token id -> token surface forms
|
| 212 |
+
for t in self.tokenizer.encode(
|
| 213 |
+
text, allowed_special=allowed_special, disallowed_special=disallowed_special
|
| 214 |
+
):
|
| 215 |
+
tokens.append(self.decoder[t])
|
| 216 |
+
return tokens
|
| 217 |
+
|
| 218 |
+
def convert_tokens_to_string(self, tokens: List[Union[bytes, str]]) -> str:
|
| 219 |
+
"""
|
| 220 |
+
Converts a sequence of tokens in a single string.
|
| 221 |
+
"""
|
| 222 |
+
text = ""
|
| 223 |
+
temp = b""
|
| 224 |
+
for t in tokens:
|
| 225 |
+
if isinstance(t, str):
|
| 226 |
+
if temp:
|
| 227 |
+
text += temp.decode("utf-8", errors=self.errors)
|
| 228 |
+
temp = b""
|
| 229 |
+
text += t
|
| 230 |
+
elif isinstance(t, bytes):
|
| 231 |
+
temp += t
|
| 232 |
+
else:
|
| 233 |
+
raise TypeError("token should only be of type types or str")
|
| 234 |
+
if temp:
|
| 235 |
+
text += temp.decode("utf-8", errors=self.errors)
|
| 236 |
+
return text
|
| 237 |
+
|
| 238 |
+
@property
|
| 239 |
+
def vocab_size(self):
|
| 240 |
+
return self.tokenizer.n_vocab
|
| 241 |
+
|
| 242 |
+
def _convert_id_to_token(self, index: int) -> Union[bytes, str]:
|
| 243 |
+
"""Converts an id to a token, special tokens included"""
|
| 244 |
+
if index in self.decoder:
|
| 245 |
+
return self.decoder[index]
|
| 246 |
+
raise ValueError("unknown ids")
|
| 247 |
+
|
| 248 |
+
def _convert_token_to_id(self, token: Union[bytes, str]) -> int:
|
| 249 |
+
"""Converts a token to an id using the vocab, special tokens included"""
|
| 250 |
+
if token in self.special_tokens:
|
| 251 |
+
return self.special_tokens[token]
|
| 252 |
+
if token in self.mergeable_ranks:
|
| 253 |
+
return self.mergeable_ranks[token]
|
| 254 |
+
raise ValueError("unknown token")
|
| 255 |
+
|
| 256 |
+
def _tokenize(self, text: str, **kwargs):
|
| 257 |
+
"""
|
| 258 |
+
Converts a string in a sequence of tokens (string), using the tokenizer. Split in words for word-based
|
| 259 |
+
vocabulary or sub-words for sub-word-based vocabularies (BPE/SentencePieces/WordPieces).
|
| 260 |
+
|
| 261 |
+
Do NOT take care of added tokens.
|
| 262 |
+
"""
|
| 263 |
+
raise NotImplementedError
|
| 264 |
+
|
| 265 |
+
def _decode(
|
| 266 |
+
self,
|
| 267 |
+
token_ids: Union[int, List[int]],
|
| 268 |
+
skip_special_tokens: bool = False,
|
| 269 |
+
errors: str = None,
|
| 270 |
+
**kwargs,
|
| 271 |
+
) -> str:
|
| 272 |
+
if isinstance(token_ids, int):
|
| 273 |
+
token_ids = [token_ids]
|
| 274 |
+
if skip_special_tokens:
|
| 275 |
+
token_ids = [i for i in token_ids if i < self.eod_id]
|
| 276 |
+
return self.tokenizer.decode(token_ids, errors=errors or self.errors)
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {},
|
| 3 |
+
"auto_map": {
|
| 4 |
+
"AutoTokenizer": [
|
| 5 |
+
"tokenization_qwen.QWenTokenizer",
|
| 6 |
+
null
|
| 7 |
+
]
|
| 8 |
+
},
|
| 9 |
+
"chat_template": "{% set system_message = 'You are a helpful assistant.' %}{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ '<|im_start|>system\n' + system_message + '<|im_end|>\n' }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '<|im_start|>user\n' + content + '<|im_end|>\n<|im_start|>assistant\n' }}{% elif message['role'] == 'assistant' %}{{ content + '<|im_end|>' + '\n' }}{% endif %}{% endfor %}",
|
| 10 |
+
"clean_up_tokenization_spaces": true,
|
| 11 |
+
"eos_token": "<|im_end|>",
|
| 12 |
+
"model_max_length": 8192,
|
| 13 |
+
"pad_token": "<|im_end|>",
|
| 14 |
+
"padding_side": "right",
|
| 15 |
+
"split_special_tokens": false,
|
| 16 |
+
"tokenizer_class": "QWenTokenizer"
|
| 17 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.88,
|
| 3 |
+
"num_input_tokens_seen": 530864,
|
| 4 |
+
"total_flos": 4880889936150528.0,
|
| 5 |
+
"train_loss": 0.5967088187182391,
|
| 6 |
+
"train_runtime": 437.0311,
|
| 7 |
+
"train_samples_per_second": 2.059,
|
| 8 |
+
"train_steps_per_second": 0.124
|
| 9 |
+
}
|
trainer_log.jsonl
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"current_steps": 5, "total_steps": 54, "loss": 0.6756, "learning_rate": 4.894973780788722e-05, "epoch": 0.26666666666666666, "percentage": 9.26, "elapsed_time": "0:00:42", "remaining_time": "0:06:57", "throughput": "1193.09", "total_tokens": 50880}
|
| 2 |
+
{"current_steps": 10, "total_steps": 54, "loss": 0.6799, "learning_rate": 4.588719528532342e-05, "epoch": 0.5333333333333333, "percentage": 18.52, "elapsed_time": "0:01:22", "remaining_time": "0:06:03", "throughput": "1200.41", "total_tokens": 99184}
|
| 3 |
+
{"current_steps": 15, "total_steps": 54, "loss": 0.6995, "learning_rate": 4.1069690242163484e-05, "epoch": 0.8, "percentage": 27.78, "elapsed_time": "0:02:01", "remaining_time": "0:05:17", "throughput": "1208.30", "total_tokens": 147408}
|
| 4 |
+
{"current_steps": 20, "total_steps": 54, "loss": 0.6313, "learning_rate": 3.490199415097892e-05, "epoch": 1.0666666666666667, "percentage": 37.04, "elapsed_time": "0:02:41", "remaining_time": "0:04:34", "throughput": "1209.98", "total_tokens": 195568}
|
| 5 |
+
{"current_steps": 25, "total_steps": 54, "loss": 0.5683, "learning_rate": 2.7902322853130757e-05, "epoch": 1.3333333333333333, "percentage": 46.3, "elapsed_time": "0:03:23", "remaining_time": "0:03:55", "throughput": "1211.98", "total_tokens": 246416}
|
| 6 |
+
{"current_steps": 30, "total_steps": 54, "loss": 0.4988, "learning_rate": 2.0658795558326743e-05, "epoch": 1.6, "percentage": 55.56, "elapsed_time": "0:04:03", "remaining_time": "0:03:14", "throughput": "1214.64", "total_tokens": 295744}
|
| 7 |
+
{"current_steps": 35, "total_steps": 54, "loss": 0.5748, "learning_rate": 1.3780020494988446e-05, "epoch": 1.8666666666666667, "percentage": 64.81, "elapsed_time": "0:04:44", "remaining_time": "0:02:34", "throughput": "1215.63", "total_tokens": 345744}
|
| 8 |
+
{"current_steps": 40, "total_steps": 54, "loss": 0.5793, "learning_rate": 7.843959053281663e-06, "epoch": 2.1333333333333333, "percentage": 74.07, "elapsed_time": "0:05:21", "remaining_time": "0:01:52", "throughput": "1214.06", "total_tokens": 390176}
|
| 9 |
+
{"current_steps": 45, "total_steps": 54, "loss": 0.55, "learning_rate": 3.3493649053890326e-06, "epoch": 2.4, "percentage": 83.33, "elapsed_time": "0:06:01", "remaining_time": "0:01:12", "throughput": "1214.25", "total_tokens": 438896}
|
| 10 |
+
{"current_steps": 50, "total_steps": 54, "loss": 0.5715, "learning_rate": 6.738782355044049e-07, "epoch": 2.6666666666666665, "percentage": 92.59, "elapsed_time": "0:06:44", "remaining_time": "0:00:32", "throughput": "1214.09", "total_tokens": 490544}
|
| 11 |
+
{"current_steps": 54, "total_steps": 54, "epoch": 2.88, "percentage": 100.0, "elapsed_time": "0:07:17", "remaining_time": "0:00:00", "throughput": "1214.71", "total_tokens": 530864}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 2.88,
|
| 5 |
+
"eval_steps": 500,
|
| 6 |
+
"global_step": 54,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.26666666666666666,
|
| 13 |
+
"grad_norm": 0.4435124099254608,
|
| 14 |
+
"learning_rate": 4.894973780788722e-05,
|
| 15 |
+
"loss": 0.6756,
|
| 16 |
+
"num_input_tokens_seen": 50880,
|
| 17 |
+
"step": 5
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"epoch": 0.5333333333333333,
|
| 21 |
+
"grad_norm": 0.5012878775596619,
|
| 22 |
+
"learning_rate": 4.588719528532342e-05,
|
| 23 |
+
"loss": 0.6799,
|
| 24 |
+
"num_input_tokens_seen": 99184,
|
| 25 |
+
"step": 10
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"epoch": 0.8,
|
| 29 |
+
"grad_norm": 0.31872692704200745,
|
| 30 |
+
"learning_rate": 4.1069690242163484e-05,
|
| 31 |
+
"loss": 0.6995,
|
| 32 |
+
"num_input_tokens_seen": 147408,
|
| 33 |
+
"step": 15
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
"epoch": 1.0666666666666667,
|
| 37 |
+
"grad_norm": 0.3336561322212219,
|
| 38 |
+
"learning_rate": 3.490199415097892e-05,
|
| 39 |
+
"loss": 0.6313,
|
| 40 |
+
"num_input_tokens_seen": 195568,
|
| 41 |
+
"step": 20
|
| 42 |
+
},
|
| 43 |
+
{
|
| 44 |
+
"epoch": 1.3333333333333333,
|
| 45 |
+
"grad_norm": 0.24536238610744476,
|
| 46 |
+
"learning_rate": 2.7902322853130757e-05,
|
| 47 |
+
"loss": 0.5683,
|
| 48 |
+
"num_input_tokens_seen": 246416,
|
| 49 |
+
"step": 25
|
| 50 |
+
},
|
| 51 |
+
{
|
| 52 |
+
"epoch": 1.6,
|
| 53 |
+
"grad_norm": 0.2896718978881836,
|
| 54 |
+
"learning_rate": 2.0658795558326743e-05,
|
| 55 |
+
"loss": 0.4988,
|
| 56 |
+
"num_input_tokens_seen": 295744,
|
| 57 |
+
"step": 30
|
| 58 |
+
},
|
| 59 |
+
{
|
| 60 |
+
"epoch": 1.8666666666666667,
|
| 61 |
+
"grad_norm": 0.2828458249568939,
|
| 62 |
+
"learning_rate": 1.3780020494988446e-05,
|
| 63 |
+
"loss": 0.5748,
|
| 64 |
+
"num_input_tokens_seen": 345744,
|
| 65 |
+
"step": 35
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"epoch": 2.1333333333333333,
|
| 69 |
+
"grad_norm": 0.37326768040657043,
|
| 70 |
+
"learning_rate": 7.843959053281663e-06,
|
| 71 |
+
"loss": 0.5793,
|
| 72 |
+
"num_input_tokens_seen": 390176,
|
| 73 |
+
"step": 40
|
| 74 |
+
},
|
| 75 |
+
{
|
| 76 |
+
"epoch": 2.4,
|
| 77 |
+
"grad_norm": 0.28728172183036804,
|
| 78 |
+
"learning_rate": 3.3493649053890326e-06,
|
| 79 |
+
"loss": 0.55,
|
| 80 |
+
"num_input_tokens_seen": 438896,
|
| 81 |
+
"step": 45
|
| 82 |
+
},
|
| 83 |
+
{
|
| 84 |
+
"epoch": 2.6666666666666665,
|
| 85 |
+
"grad_norm": 0.275715172290802,
|
| 86 |
+
"learning_rate": 6.738782355044049e-07,
|
| 87 |
+
"loss": 0.5715,
|
| 88 |
+
"num_input_tokens_seen": 490544,
|
| 89 |
+
"step": 50
|
| 90 |
+
},
|
| 91 |
+
{
|
| 92 |
+
"epoch": 2.88,
|
| 93 |
+
"num_input_tokens_seen": 530864,
|
| 94 |
+
"step": 54,
|
| 95 |
+
"total_flos": 4880889936150528.0,
|
| 96 |
+
"train_loss": 0.5967088187182391,
|
| 97 |
+
"train_runtime": 437.0311,
|
| 98 |
+
"train_samples_per_second": 2.059,
|
| 99 |
+
"train_steps_per_second": 0.124
|
| 100 |
+
}
|
| 101 |
+
],
|
| 102 |
+
"logging_steps": 5,
|
| 103 |
+
"max_steps": 54,
|
| 104 |
+
"num_input_tokens_seen": 530864,
|
| 105 |
+
"num_train_epochs": 3,
|
| 106 |
+
"save_steps": 100,
|
| 107 |
+
"stateful_callbacks": {
|
| 108 |
+
"TrainerControl": {
|
| 109 |
+
"args": {
|
| 110 |
+
"should_epoch_stop": false,
|
| 111 |
+
"should_evaluate": false,
|
| 112 |
+
"should_log": false,
|
| 113 |
+
"should_save": false,
|
| 114 |
+
"should_training_stop": false
|
| 115 |
+
},
|
| 116 |
+
"attributes": {}
|
| 117 |
+
}
|
| 118 |
+
},
|
| 119 |
+
"total_flos": 4880889936150528.0,
|
| 120 |
+
"train_batch_size": 2,
|
| 121 |
+
"trial_name": null,
|
| 122 |
+
"trial_params": null
|
| 123 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:653a7a5eb95c010e25e2d17462f48539df2aa0b66714044c6de1173e1f47d33d
|
| 3 |
+
size 5304
|
training_args.yaml
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cutoff_len: 1024
|
| 2 |
+
dataset: glaive_toolcall_en_demo
|
| 3 |
+
dataset_dir: data
|
| 4 |
+
ddp_timeout: 180000000
|
| 5 |
+
do_train: true
|
| 6 |
+
finetuning_type: lora
|
| 7 |
+
flash_attn: auto
|
| 8 |
+
fp16: true
|
| 9 |
+
gradient_accumulation_steps: 8
|
| 10 |
+
include_num_input_tokens_seen: true
|
| 11 |
+
learning_rate: 5.0e-05
|
| 12 |
+
logging_steps: 5
|
| 13 |
+
lora_alpha: 16
|
| 14 |
+
lora_dropout: 0
|
| 15 |
+
lora_rank: 8
|
| 16 |
+
lora_target: all
|
| 17 |
+
lr_scheduler_type: cosine
|
| 18 |
+
max_grad_norm: 1.0
|
| 19 |
+
max_samples: 100000
|
| 20 |
+
model_name_or_path: Qwen/Qwen-1_8B-Chat
|
| 21 |
+
num_train_epochs: 3.0
|
| 22 |
+
optim: adamw_torch
|
| 23 |
+
output_dir: saves/Qwen-1.8B-Chat/lora/train_2024-07-16-18-56-15
|
| 24 |
+
packing: false
|
| 25 |
+
per_device_train_batch_size: 2
|
| 26 |
+
plot_loss: true
|
| 27 |
+
preprocessing_num_workers: 16
|
| 28 |
+
quantization_method: bitsandbytes
|
| 29 |
+
report_to: none
|
| 30 |
+
save_steps: 100
|
| 31 |
+
stage: sft
|
| 32 |
+
template: qwen
|
| 33 |
+
warmup_steps: 0
|
training_loss.png
ADDED
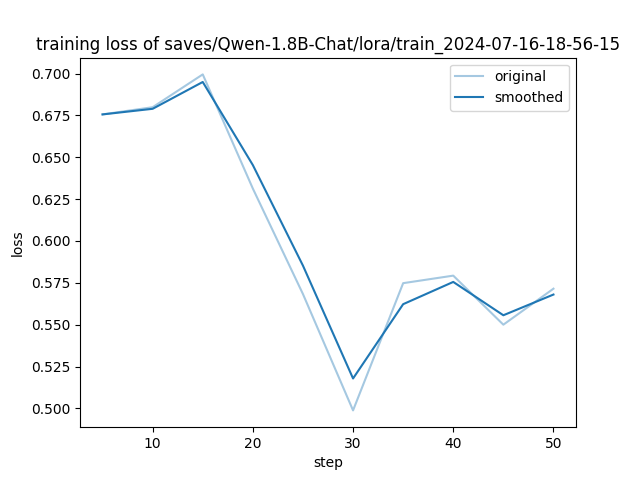
|