
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +6 -0
- .gitignore +2 -0
- MultiTalk_dataset/README.md +96 -0
- MultiTalk_dataset/annotations/arabic.json +0 -0
- MultiTalk_dataset/annotations/catalan.json +0 -0
- MultiTalk_dataset/annotations/croatian.json +0 -0
- MultiTalk_dataset/annotations/czech.json +0 -0
- MultiTalk_dataset/annotations/dutch.json +0 -0
- MultiTalk_dataset/annotations/english.json +0 -0
- MultiTalk_dataset/annotations/french.json +0 -0
- MultiTalk_dataset/annotations/german.json +0 -0
- MultiTalk_dataset/annotations/greek.json +0 -0
- MultiTalk_dataset/annotations/hindi.json +0 -0
- MultiTalk_dataset/annotations/italian.json +0 -0
- MultiTalk_dataset/annotations/japanese.json +0 -0
- MultiTalk_dataset/annotations/mandarin.json +0 -0
- MultiTalk_dataset/annotations/polish.json +0 -0
- MultiTalk_dataset/annotations/portuguese.json +0 -0
- MultiTalk_dataset/annotations/russian.json +0 -0
- MultiTalk_dataset/annotations/spanish.json +0 -0
- MultiTalk_dataset/annotations/thai.json +0 -0
- MultiTalk_dataset/annotations/turkish.json +0 -0
- MultiTalk_dataset/annotations/ukrainian.json +0 -0
- MultiTalk_dataset/dataset.sh +4 -0
- MultiTalk_dataset/download_and_process.py +147 -0
- README.md +140 -0
- RUN/multi/MultiTalk_s2/test-20240707_000247.log +15 -0
- RUN/multi/MultiTalk_s2/test-20240707_000302.log +110 -0
- RUN/multi/MultiTalk_s2/test-20240707_000539.log +107 -0
- RUN/multi/MultiTalk_s2/test-20240707_000731.log +93 -0
- RUN/vocaset/MultiTalk_s2/test-20240707_000820.log +90 -0
- assets/statistic.png +0 -0
- assets/teaser.png +3 -0
- base/__init__.py +1 -0
- base/__pycache__/__init__.cpython-38.pyc +0 -0
- base/__pycache__/baseTrainer.cpython-38.pyc +0 -0
- base/__pycache__/base_model.cpython-38.pyc +0 -0
- base/__pycache__/config.cpython-38.pyc +0 -0
- base/__pycache__/utilities.cpython-38.pyc +0 -0
- base/baseTrainer.py +66 -0
- base/base_model.py +30 -0
- base/config.py +165 -0
- base/utilities.py +66 -0
- checkpoints/FLAME_sample.ply +0 -0
- checkpoints/stage1.pth.tar +3 -0
- checkpoints/stage2.pth.tar +3 -0
- checkpoints/templates.pkl +3 -0
- config/multi/demo.yaml +47 -0
- config/multi/stage1.yaml +79 -0
- config/multi/stage2.yaml +97 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,9 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/teaser.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
demo/input/English_WTT5UTZQ9K8_8.wav filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
demo/input/French_JATq1mUhfiA_8.wav filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
demo/input/Italian_72pdx3tZwto_4.wav filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
sample_dataset/wav/Greek_0_38_FbWPEz8NFS8.wav filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
sample_dataset/wav/Spanish_xyVZDmzt6HY_6.wav filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/MultiTalk_dataset/raw_video
|
| 2 |
+
/MultiTalk_dataset/multitalk_dataset
|
MultiTalk_dataset/README.md
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Overview
|
| 2 |
+
MultiTalk dataset is a new multilingual 2D video dataset featuring over 420 hours of talking videos across 20 languages.
|
| 3 |
+
It contains 293,812 clips with a resolution of 512x512, a frame rate of 25 fps, and an average duration of 5.19 seconds per clip.
|
| 4 |
+
The dataset shows a balanced distribution across languages, with each language representing between 2.0% and 9.7% of the total.
|
| 5 |
+
|
| 6 |
+
<img alt="statistic" src="../assets/statistic.png" width=560>
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
<details><summary><b>Detailed statistics</b></summary><p>
|
| 10 |
+
|
| 11 |
+
| Language | Total Duration(h) | #Clips | Avg. Duration(s) | Annotation |
|
| 12 |
+
|:---:|:---:|:---:|:---:|:-------------------------------------------------------------------------------------------------------------------:|
|
| 13 |
+
| Arabic | 10.32 | 9048 | 4.11 | [arabic.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/arabic.json) |
|
| 14 |
+
| Catalan | 41.0 | 29232 | 5.05 | [catalan.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/catalan.json) |
|
| 15 |
+
| Croatian | 41.0 | 25465 | 5.80 | [croatian.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/croatian.json) |
|
| 16 |
+
| Czech | 18.9 | 11228 | 6.06 | [czech.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/czech.json) |
|
| 17 |
+
| Dutch | 17.05 | 14187 | 4.33 | [dutch.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/dutch.json) |
|
| 18 |
+
| English | 15.49 | 11082 | 5.03 | [english.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/english.json) |
|
| 19 |
+
| French | 13.17 | 11576 | 4.10 | [french.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/french.json) |
|
| 20 |
+
| German | 16.25 | 10856 | 5.39 | [german.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/german.json) |
|
| 21 |
+
| Greek | 17.53 | 12698 | 4.97 | [greek.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/greek.json) |
|
| 22 |
+
| Hindi | 24.41 | 16120 | 5.45 | [hindi.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/hindi.json) |
|
| 23 |
+
| Italian | 13.59 | 9753 | 5.02 | [italian.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/italian.json) |
|
| 24 |
+
| Japanese | 8.36 | 5990 | 5.03 | [japanese.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/japanese.json) |
|
| 25 |
+
| Mandarin | 8.73 | 6096 | 5.15 | [mandarin.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/mandarin.json) |
|
| 26 |
+
| Polish | 21.58 | 15181 | 5.12 | [polish.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/polish.json) |
|
| 27 |
+
| Portuguese | 41.0 | 25321 | 5.83 | [portuguese.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/portuguese.json) |
|
| 28 |
+
| Russian | 26.32 | 17811 | 5.32 | [russian.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/russian.json) |
|
| 29 |
+
| Spanish | 23.65 | 18758 | 4.54 | [spanish.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/spanish.json) |
|
| 30 |
+
| Thai | 10.95 | 7595 | 5.19 | [thai.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/thai.json) |
|
| 31 |
+
| Turkish | 12.9 | 11165 | 4.16 | [turkish.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/turkish.json) |
|
| 32 |
+
| Ukrainian | 41.0 | 24650 | 5.99 | [ukrainian.json](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/annotations/ukrainian.json) |
|
| 33 |
+
</p></details>
|
| 34 |
+
|
| 35 |
+
## Download
|
| 36 |
+
|
| 37 |
+
### Usage
|
| 38 |
+
**Prepare the environment:**
|
| 39 |
+
```bash
|
| 40 |
+
pip install pytube
|
| 41 |
+
pip install opencv-python
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
**Run script:**
|
| 45 |
+
```bash
|
| 46 |
+
cd MultiTalk_Dataset
|
| 47 |
+
```
|
| 48 |
+
You can pass the languages you want to download as arguments to the script. If you want to download all 20 languages, run the following script.
|
| 49 |
+
```bash
|
| 50 |
+
sh dataset.sh arabic catalan croatian czech dutch english french german greek hindi italian japanese mandarin polish portuguese russian spanish thai turkish ukrainian
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
After downloading, the folder structure will be as below. Each language folder contains the .mp4 videos.
|
| 54 |
+
You can change the ${ROOT} folder in the [code](https://github.com/postech-ami/MultiTalk/tree/main/MultiTalk_dataset/download_and_process.py).
|
| 55 |
+
```
|
| 56 |
+
${ROOT}
|
| 57 |
+
├── multitalk_dataset # MultiTalk Dataset
|
| 58 |
+
│ ├── arabic
|
| 59 |
+
│ │ ├── O-VJXuHb390_0.mp4
|
| 60 |
+
│ │ ├── O-VJXuHb390_1.mp4
|
| 61 |
+
│ │ ├── ...
|
| 62 |
+
│ │ └── ...
|
| 63 |
+
│ ├── catalan
|
| 64 |
+
│ ├── ...
|
| 65 |
+
│ └── ...
|
| 66 |
+
└── raw_video # Original videos (you can remove this directory after downloading)
|
| 67 |
+
├── arabic
|
| 68 |
+
├── catalan
|
| 69 |
+
├── ...
|
| 70 |
+
└── ...
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
### JSON File Structure
|
| 74 |
+
```javascript
|
| 75 |
+
{
|
| 76 |
+
"QrDZjUeiUwc_0": // clip 1
|
| 77 |
+
{
|
| 78 |
+
"youtube_id": "QrDZjUeiUwc", // youtube id
|
| 79 |
+
"duration": {"start_sec": 302.0, "end_sec": 305.56}, // start and end times in the original video
|
| 80 |
+
"bbox": {"top": 0.0, "bottom": 0.8167, "left": 0.4484, "right": 0.9453}, // bounding box
|
| 81 |
+
"language": "czech", // language
|
| 82 |
+
"transcript": "já jsem v podstatě obnovil svůj list z minulého roku" // transcript
|
| 83 |
+
},
|
| 84 |
+
"QrDZjUeiUwc_1": // clip 2
|
| 85 |
+
{
|
| 86 |
+
"youtube_id": "QrDZjUeiUwc",
|
| 87 |
+
"duration": {"start_sec": 0.12, "end_sec": 4.12},
|
| 88 |
+
"bbox": {"top": 0.0097, "bottom": 0.55, "left": 0.3406, "right": 0.6398},
|
| 89 |
+
"language": "czech",
|
| 90 |
+
"transcript": "ahoj tady anička a vítejte u dalšího easycheck videa"
|
| 91 |
+
}
|
| 92 |
+
"..."
|
| 93 |
+
"..."
|
| 94 |
+
|
| 95 |
+
}
|
| 96 |
+
```
|
MultiTalk_dataset/annotations/arabic.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/catalan.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/croatian.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/czech.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/dutch.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/english.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/french.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/german.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/greek.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/hindi.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/italian.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/japanese.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/mandarin.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/polish.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/portuguese.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/russian.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/spanish.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/thai.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/turkish.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/annotations/ukrainian.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MultiTalk_dataset/dataset.sh
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
for language in "$@"
|
| 2 |
+
do
|
| 3 |
+
python download_and_process.py --language "$language"
|
| 4 |
+
done
|
MultiTalk_dataset/download_and_process.py
ADDED
|
@@ -0,0 +1,147 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import cv2
|
| 4 |
+
import argparse
|
| 5 |
+
from pytube import Playlist, YouTube
|
| 6 |
+
from pytube.exceptions import VideoUnavailable
|
| 7 |
+
import os
|
| 8 |
+
import shutil
|
| 9 |
+
import subprocess
|
| 10 |
+
|
| 11 |
+
def downloadYouTube(yt, videourl, path):
|
| 12 |
+
video_stream = yt.streams.filter(progressive=False, file_extension='mp4').order_by('resolution').desc().first()
|
| 13 |
+
audio_stream = yt.streams.filter(only_audio=True).order_by('abr').desc().first()
|
| 14 |
+
if video_stream.fps >= 25:
|
| 15 |
+
video_id = videourl.split('=')[-1]
|
| 16 |
+
video_path = os.path.join(path, f"{video_id}_video.mp4")
|
| 17 |
+
audio_path = os.path.join(path, f"{video_id}_audio.mp4")
|
| 18 |
+
final_path = os.path.join(path, f"{video_id}.mp4")
|
| 19 |
+
|
| 20 |
+
print("Downloading video...")
|
| 21 |
+
video_stream.download(filename=video_path)
|
| 22 |
+
print("Downloading audio...")
|
| 23 |
+
audio_stream.download(filename=audio_path)
|
| 24 |
+
|
| 25 |
+
print("Merging video and audio...")
|
| 26 |
+
subprocess.run([
|
| 27 |
+
'ffmpeg', '-i', video_path, '-i', audio_path, '-r', '25',
|
| 28 |
+
'-c:v', 'copy', '-c:a', 'aac', '-strict', 'experimental',
|
| 29 |
+
final_path, '-y'
|
| 30 |
+
])
|
| 31 |
+
|
| 32 |
+
os.remove(video_path)
|
| 33 |
+
os.remove(audio_path)
|
| 34 |
+
return True
|
| 35 |
+
|
| 36 |
+
else:
|
| 37 |
+
return False
|
| 38 |
+
|
| 39 |
+
def process_ffmpeg(raw_vid_path, save_folder, save_vid_name,
|
| 40 |
+
bbox, time):
|
| 41 |
+
"""
|
| 42 |
+
raw_vid_path:
|
| 43 |
+
save_folder:
|
| 44 |
+
save_vid_name:
|
| 45 |
+
bbox: format: top, bottom, left, right. the values are normalized to 0~1
|
| 46 |
+
time: begin_sec, end_sec
|
| 47 |
+
"""
|
| 48 |
+
|
| 49 |
+
def secs_to_timestr(secs):
|
| 50 |
+
hrs = secs // (60 * 60)
|
| 51 |
+
min = (secs - hrs * 3600) // 60
|
| 52 |
+
sec = secs % 60
|
| 53 |
+
end = (secs - int(secs)) * 100
|
| 54 |
+
return "{:02d}:{:02d}:{:02d}.{:02d}".format(int(hrs), int(min),
|
| 55 |
+
int(sec), int(end))
|
| 56 |
+
|
| 57 |
+
def expand(bbox, ratio):
|
| 58 |
+
top, bottom = max(bbox[0] - ratio, 0), min(bbox[1] + ratio, 1)
|
| 59 |
+
left, right = max(bbox[2] - ratio, 0), min(bbox[3] + ratio, 1)
|
| 60 |
+
|
| 61 |
+
return top, bottom, left, right
|
| 62 |
+
|
| 63 |
+
def to_square(bbox):
|
| 64 |
+
top, bottom, left, right = bbox
|
| 65 |
+
h = bottom - top
|
| 66 |
+
w = right - left
|
| 67 |
+
c = min(h, w) // 2
|
| 68 |
+
c_h = (top + bottom) / 2
|
| 69 |
+
c_w = (left + right) / 2
|
| 70 |
+
|
| 71 |
+
top, bottom = c_h - c, c_h + c
|
| 72 |
+
left, right = c_w - c, c_w + c
|
| 73 |
+
return top, bottom, left, right
|
| 74 |
+
|
| 75 |
+
def denorm(bbox, height, width):
|
| 76 |
+
top, bottom, left, right = \
|
| 77 |
+
round(bbox[0] * height), \
|
| 78 |
+
round(bbox[1] * height), \
|
| 79 |
+
round(bbox[2] * width), \
|
| 80 |
+
round(bbox[3] * width)
|
| 81 |
+
|
| 82 |
+
return top, bottom, left, right
|
| 83 |
+
|
| 84 |
+
out_path = os.path.join(save_folder, save_vid_name)
|
| 85 |
+
|
| 86 |
+
cap = cv2.VideoCapture(raw_vid_path)
|
| 87 |
+
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
|
| 88 |
+
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
|
| 89 |
+
top, bottom, left, right = to_square(
|
| 90 |
+
denorm(expand(bbox, 0.02), height, width))
|
| 91 |
+
start_sec, end_sec = time
|
| 92 |
+
cmd = f"ffmpeg -i {raw_vid_path} -r 25 -vf crop=w={right-left}:h={bottom-top}:x={left}:y={top},scale=512:512 -ss {start_sec} -to {end_sec} -loglevel error {out_path}"
|
| 93 |
+
os.system(cmd)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def load_data(file_path):
|
| 97 |
+
with open(file_path) as f:
|
| 98 |
+
data_dict = json.load(f)
|
| 99 |
+
|
| 100 |
+
for key, val in data_dict.items():
|
| 101 |
+
save_name = key+".mp4"
|
| 102 |
+
ytb_id = val['youtube_id']
|
| 103 |
+
time = val['duration']['start_sec'], val['duration']['end_sec']
|
| 104 |
+
|
| 105 |
+
bbox = [val['bbox']['top'], val['bbox']['bottom'],
|
| 106 |
+
val['bbox']['left'], val['bbox']['right']]
|
| 107 |
+
language = val['language']
|
| 108 |
+
yield ytb_id, save_name, time, bbox, language
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
if __name__ == '__main__':
|
| 112 |
+
parser = argparse.ArgumentParser()
|
| 113 |
+
parser.add_argument('--language', type=str, default="dutch", help='Language')
|
| 114 |
+
args = parser.parse_args()
|
| 115 |
+
|
| 116 |
+
# you can change the root folder
|
| 117 |
+
root = './'
|
| 118 |
+
processed_vid_root = os.path.join(root, 'multitalk_dataset') # processed video path
|
| 119 |
+
raw_vid_root = os.path.join(root, 'raw_video') # downloaded raw video path
|
| 120 |
+
os.makedirs(processed_vid_root, exist_ok=True)
|
| 121 |
+
os.makedirs(raw_vid_root, exist_ok=True)
|
| 122 |
+
|
| 123 |
+
json_path = os.path.join('./annotations', f'{args.language}.json') # json file path
|
| 124 |
+
|
| 125 |
+
for vid_id, save_vid_name, time, bbox, language in load_data(json_path):
|
| 126 |
+
processed_vid_dir = os.path.join(processed_vid_root, language)
|
| 127 |
+
raw_vid_dir = os.path.join(raw_vid_root, language)
|
| 128 |
+
raw_vid_path = os.path.join(raw_vid_dir, vid_id + ".mp4")
|
| 129 |
+
|
| 130 |
+
os.makedirs(processed_vid_dir, exist_ok=True)
|
| 131 |
+
os.makedirs(raw_vid_dir, exist_ok=True)
|
| 132 |
+
|
| 133 |
+
url = 'https://www.youtube.com/watch?v='+vid_id
|
| 134 |
+
success = True
|
| 135 |
+
if not os.path.isfile(raw_vid_path) :
|
| 136 |
+
while True:
|
| 137 |
+
try:
|
| 138 |
+
yt = YouTube(url, use_oauth=True)
|
| 139 |
+
success = downloadYouTube(yt, url, raw_vid_dir)
|
| 140 |
+
break
|
| 141 |
+
except:
|
| 142 |
+
continue
|
| 143 |
+
if success:
|
| 144 |
+
process_ffmpeg(raw_vid_path, processed_vid_dir, save_vid_name, bbox, time)
|
| 145 |
+
|
| 146 |
+
# you can remove this directory after downloading
|
| 147 |
+
# shutil.rmtree(raw_vid_root)
|
README.md
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MultiTalk (INTERSPEECH 2024)
|
| 2 |
+
|
| 3 |
+
### [Project Page](https://multi-talk.github.io/) | [Paper](https://arxiv.org/abs/2406.14272) | [Dataset](https://github.com/postech-ami/MultiTalk/blob/main/MultiTalk_dataset/README.md)
|
| 4 |
+
This repository contains a pytorch implementation for the Interspeech 2024 paper, [MultiTalk: Enhancing 3D Talking Head Generation Across Languages with Multilingual Video Dataset](https://multi-talk.github.io/). MultiTalk generates 3D talking head with enhanced multilingual performance.<br><br>
|
| 5 |
+
|
| 6 |
+
<img width="700" alt="teaser" src="./assets/teaser.png">
|
| 7 |
+
|
| 8 |
+
## Getting started
|
| 9 |
+
This code was developed on Ubuntu 18.04 with Python 3.8, CUDA 11.3 and PyTorch 1.12.0. Later versions should work, but have not been tested.
|
| 10 |
+
|
| 11 |
+
### Installation
|
| 12 |
+
Create and activate a virtual environment to work in:
|
| 13 |
+
```
|
| 14 |
+
conda create --name multitalk python=3.8
|
| 15 |
+
conda activate multitalk
|
| 16 |
+
```
|
| 17 |
+
|
| 18 |
+
Install [PyTorch](https://pytorch.org/). For CUDA 11.3 and ffmpeg, this would look like:
|
| 19 |
+
```
|
| 20 |
+
pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu113
|
| 21 |
+
conda install -c conda-forge ffmpeg
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
Install the remaining requirements with pip:
|
| 25 |
+
```
|
| 26 |
+
pip install -r requirements.txt
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
Compile and install `psbody-mesh` package:
|
| 30 |
+
[MPI-IS/mesh](https://github.com/MPI-IS/mesh)
|
| 31 |
+
```
|
| 32 |
+
BOOST_INCLUDE_DIRS=/usr/lib/x86_64-linux-gnu make all
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
### Download models
|
| 37 |
+
To run MultiTalk, you need to download stage1 and stage2 model, and the template file of mean face in FLAME topology,
|
| 38 |
+
Download [stage1 model](https://drive.google.com/file/d/1jI9feFcUuhXst1pM1_xOMvqE8cgUzP_t/view?usp=sharing | [stage2 model](https://drive.google.com/file/d/1zqhzfF-vO_h_0EpkmBS7nO36TRNV4BCr/view?usp=sharing) | [template](https://drive.google.com/file/d/1WuZ87kljz6EK1bAzEKSyBsZ9IlUmiI-i/view?usp=sharing) and download FLAME_sample.ply from [voca](https://github.com/TimoBolkart/voca/tree/master/template).
|
| 39 |
+
|
| 40 |
+
After downloading the models, place them in `./checkpoints`.
|
| 41 |
+
```
|
| 42 |
+
./checkpoints/stage1.pth.tar
|
| 43 |
+
./checkpoints/stage2.pth.tar
|
| 44 |
+
./checkpoints/FLAME_sample.ply
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
## Demo
|
| 48 |
+
Run below command to train the model.
|
| 49 |
+
We provide sample audios in **./demo/input**.
|
| 50 |
+
```
|
| 51 |
+
sh scripts/demo.sh multi
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
To use wav2vec of `facebook/wav2vec2-large-xlsr-53`, please move to `/path/to/conda_environment/lib/python3.8/site-packages/transformers/models/wav2vec2/processing_wav2vec2.py` and change the code as below.
|
| 55 |
+
```
|
| 56 |
+
L105: tokenizer = Wav2Vec2CTCTokenizer.from_pretrained(pretrained_model_name_or_path, **kwargs)
|
| 57 |
+
to
|
| 58 |
+
L105: tokenizer=Wav2Vec2CTCTokenizer.from_pretrained("facebook/wav2vec2-base-960h",**kwargs)
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
## MultiTalk Dataset
|
| 62 |
+
Please follow the instructions in [MultiTalk_dataset/README.md](https://github.com/postech-ami/MultiTalk/blob/main/MultiTalk_dataset/README.md).
|
| 63 |
+
|
| 64 |
+
## Training and testing
|
| 65 |
+
|
| 66 |
+
### Training for Discrete Motion Prior
|
| 67 |
+
```
|
| 68 |
+
sh scripts/train_multi.sh MultiTalk_s1 config/multi/stage1.yaml multi s1
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
### Training for Speech-Driven Motion Synthesis
|
| 72 |
+
Make sure the paths of pre-trained models are correct, i.e.,`vqvae_pretrained_path` and `wav2vec2model_path` in `config/multi/stage2.yaml`.
|
| 73 |
+
```
|
| 74 |
+
sh scripts/train_multi.sh MultiTalk_s2 config/multi/stage2.yaml multi s2
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
### Testing
|
| 78 |
+
#### Lip Vertex Error (LVE)
|
| 79 |
+
For evaluating the lip vertex error, please run below command.
|
| 80 |
+
|
| 81 |
+
```
|
| 82 |
+
sh scripts/test.sh MultiTalk_s2 config/multi/stage2.yaml vocaset s2
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
#### Audio-Visual Lip Reading (AVLR)
|
| 86 |
+
For evaluating lip readability with a pre-trained Audio-Visual Speech Recognition (AVSR), download language specific checkpoint, dictionary, and tokenizer from [muavic](https://github.com/facebookresearch/muavic).
|
| 87 |
+
Place them in `./avlr/${language}/checkpoints/${language}_avlr`.
|
| 88 |
+
```
|
| 89 |
+
# e.g "Arabic"
|
| 90 |
+
./avlr/ar/checkpoints/ar_avsr/checkpoint_best.pt
|
| 91 |
+
./avlr/ar/checkpoints/ar_avsr/dict.ar.txt
|
| 92 |
+
./avlr/ar/checkpoints/ar_avsr/tokenizer.model
|
| 93 |
+
```
|
| 94 |
+
And place the rendered videos in `./avlr/${language}/inputs/MultiTalk`, corresponding wav files in `./avlr/${language}/inputs/wav`.
|
| 95 |
+
```
|
| 96 |
+
# e.g "Arabic"
|
| 97 |
+
./avlr/ar/inputs/MultiTalk
|
| 98 |
+
./avlr/ar/inputs/wav
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
Run below command to evaluate lip readability.
|
| 102 |
+
```
|
| 103 |
+
python eval_avlr/eval_avlr.py --avhubert-path ./av_hubert/avhubert --work-dir ./avlr --language ${language} --model-name MultiTalk --exp-name ${exp_name}
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
[//]: # (## **Citation**)
|
| 109 |
+
|
| 110 |
+
[//]: # ()
|
| 111 |
+
[//]: # (If you find the code useful for your work, please star this repo and consider citing:)
|
| 112 |
+
|
| 113 |
+
[//]: # ()
|
| 114 |
+
[//]: # (```)
|
| 115 |
+
|
| 116 |
+
[//]: # (@inproceedings{xing2023codetalker,)
|
| 117 |
+
|
| 118 |
+
[//]: # ( title={Codetalker: Speech-driven 3d facial animation with discrete motion prior},)
|
| 119 |
+
|
| 120 |
+
[//]: # ( author={Xing, Jinbo and Xia, Menghan and Zhang, Yuechen and Cun, Xiaodong and Wang, Jue and Wong, Tien-Tsin},)
|
| 121 |
+
|
| 122 |
+
[//]: # ( booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},)
|
| 123 |
+
|
| 124 |
+
[//]: # ( pages={12780--12790},)
|
| 125 |
+
|
| 126 |
+
[//]: # ( year={2023})
|
| 127 |
+
|
| 128 |
+
[//]: # (})
|
| 129 |
+
|
| 130 |
+
[//]: # (```)
|
| 131 |
+
|
| 132 |
+
## **Notes**
|
| 133 |
+
1. Although our codebase allows for training with multi-GPUs, we did not test it and just hardcode the training batch size as one. You may need to change the `data_loader` if needed.
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
## **Acknowledgement**
|
| 137 |
+
We heavily borrow the code from
|
| 138 |
+
[Codetalk](https://doubiiu.github.io/projects/codetalker/).
|
| 139 |
+
We sincerely appreciate those authors.
|
| 140 |
+
|
RUN/multi/MultiTalk_s2/test-20240707_000247.log
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Traceback (most recent call last):
|
| 2 |
+
File "main/test_multi_pred.py", line 12, in <module>
|
| 3 |
+
import librosa
|
| 4 |
+
File "/home/rnd/miniconda3/envs/multitalk/lib/python3.8/site-packages/librosa/__init__.py", line 211, in <module>
|
| 5 |
+
from . import core
|
| 6 |
+
File "/home/rnd/miniconda3/envs/multitalk/lib/python3.8/site-packages/librosa/core/__init__.py", line 9, in <module>
|
| 7 |
+
from .constantq import * # pylint: disable=wildcard-import
|
| 8 |
+
File "/home/rnd/miniconda3/envs/multitalk/lib/python3.8/site-packages/librosa/core/constantq.py", line 1059, in <module>
|
| 9 |
+
dtype=np.complex,
|
| 10 |
+
File "/home/rnd/miniconda3/envs/multitalk/lib/python3.8/site-packages/numpy/__init__.py", line 305, in __getattr__
|
| 11 |
+
raise AttributeError(__former_attrs__[attr])
|
| 12 |
+
AttributeError: module 'numpy' has no attribute 'complex'.
|
| 13 |
+
`np.complex` was a deprecated alias for the builtin `complex`. To avoid this error in existing code, use `complex` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.complex128` here.
|
| 14 |
+
The aliases was originally deprecated in NumPy 1.20; for more details and guidance see the original release note at:
|
| 15 |
+
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
|
RUN/multi/MultiTalk_s2/test-20240707_000302.log
ADDED
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[2024-07-07 00:03:03,357 INFO test_multi_pred.py line 63 3703560]=>INaffine: False
|
| 2 |
+
StepLR: False
|
| 3 |
+
adaptive_lr: False
|
| 4 |
+
arch: stage2
|
| 5 |
+
autoencoder: stage1_vocaset
|
| 6 |
+
base_lr: 0.0001
|
| 7 |
+
batch_size: 1
|
| 8 |
+
batch_size_val: 1
|
| 9 |
+
data_root: sample_dataset
|
| 10 |
+
dataset: multi
|
| 11 |
+
device: cuda
|
| 12 |
+
dist_backend: nccl
|
| 13 |
+
dist_url: tcp://127.0.0.1:6701
|
| 14 |
+
epochs: 100
|
| 15 |
+
eval_freq: 5
|
| 16 |
+
evaluate: True
|
| 17 |
+
face_quan_num: 16
|
| 18 |
+
factor: 0.3
|
| 19 |
+
feature_dim: 1024
|
| 20 |
+
gamma: 0.5
|
| 21 |
+
gt_save_folder: demo/gt
|
| 22 |
+
hidden_size: 1024
|
| 23 |
+
in_dim: 15069
|
| 24 |
+
intermediate_size: 1536
|
| 25 |
+
log_dir: None
|
| 26 |
+
loss: MSE
|
| 27 |
+
manual_seed: 131
|
| 28 |
+
measure_lve: False
|
| 29 |
+
model_path: checkpoints/stage2.pth.tar
|
| 30 |
+
momentum: 0.9
|
| 31 |
+
motion_weight: 1.0
|
| 32 |
+
multiprocessing_distributed: True
|
| 33 |
+
n_embed: 256
|
| 34 |
+
n_head: 4
|
| 35 |
+
neg: 0.2
|
| 36 |
+
num_attention_heads: 8
|
| 37 |
+
num_hidden_layers: 6
|
| 38 |
+
num_layers: 6
|
| 39 |
+
patience: 3
|
| 40 |
+
period: 25
|
| 41 |
+
poly_lr: False
|
| 42 |
+
power: 0.9
|
| 43 |
+
print_freq: 10
|
| 44 |
+
quant_factor: 0
|
| 45 |
+
rank: 0
|
| 46 |
+
read_audio: True
|
| 47 |
+
reg_weight: 1.0
|
| 48 |
+
resume: None
|
| 49 |
+
save: True
|
| 50 |
+
save_folder: demo/output
|
| 51 |
+
save_freq: 1
|
| 52 |
+
save_path: None
|
| 53 |
+
start_epoch: 0
|
| 54 |
+
step_size: 100
|
| 55 |
+
style_emb_method: nnemb
|
| 56 |
+
sync_bn: False
|
| 57 |
+
teacher_forcing: True
|
| 58 |
+
template_file: templates.pkl
|
| 59 |
+
test_batch_size: 1
|
| 60 |
+
test_gpu: [0]
|
| 61 |
+
test_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 62 |
+
test_workers: 0
|
| 63 |
+
threshold: 0.0001
|
| 64 |
+
train_gpu: [0]
|
| 65 |
+
train_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 66 |
+
use_sgd: False
|
| 67 |
+
val_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 68 |
+
vertice_dim: 15069
|
| 69 |
+
vertices_path: npy
|
| 70 |
+
visualize_mesh: True
|
| 71 |
+
vqvae_pretrained_path: checkpoints/stage1.pth.tar
|
| 72 |
+
warmup_steps: 1
|
| 73 |
+
wav2vec2model_path: facebook/wav2vec2-large-xlsr-53
|
| 74 |
+
wav_path: wav
|
| 75 |
+
weight: None
|
| 76 |
+
weight_decay: 0.002
|
| 77 |
+
window_size: 1
|
| 78 |
+
workers: 10
|
| 79 |
+
world_size: 1
|
| 80 |
+
zquant_dim: 64
|
| 81 |
+
[2024-07-07 00:03:03,357 INFO test_multi_pred.py line 64 3703560]=>=> creating model ...
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
Some weights of the model checkpoint at facebook/wav2vec2-large-xlsr-53 were not used when initializing Wav2Vec2Model: ['quantizer.weight_proj.bias', 'project_hid.bias', 'project_q.bias', 'quantizer.weight_proj.weight', 'project_q.weight', 'quantizer.codevectors', 'project_hid.weight']
|
| 85 |
+
- This IS expected if you are initializing Wav2Vec2Model from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
|
| 86 |
+
- This IS NOT expected if you are initializing Wav2Vec2Model from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
|
| 87 |
+
[2024-07-07 00:04:21,701 INFO test_multi_pred.py line 69 3703560]=>=> loading checkpoint 'checkpoints/stage2.pth.tar'
|
| 88 |
+
[2024-07-07 00:04:22,268 INFO test_multi_pred.py line 72 3703560]=>=> loaded checkpoint 'checkpoints/stage2.pth.tar'
|
| 89 |
+
Loading data...
|
| 90 |
+
|
| 91 |
+
Traceback (most recent call last):
|
| 92 |
+
File "main/test_multi_pred.py", line 144, in <module>
|
| 93 |
+
main()
|
| 94 |
+
File "main/test_multi_pred.py", line 78, in main
|
| 95 |
+
dataset = get_dataloaders(cfg, test_config=True)
|
| 96 |
+
File "/home/rnd/Documents/Ameer/Dream/MultiTalk/dataset/data_loader_multi.py", line 142, in get_dataloaders
|
| 97 |
+
train_data, valid_data, test_data, subjects_dict = read_data(args, test_config)
|
| 98 |
+
File "/home/rnd/Documents/Ameer/Dream/MultiTalk/dataset/data_loader_multi.py", line 66, in read_data
|
| 99 |
+
processor = Wav2Vec2Processor.from_pretrained(args.wav2vec2model_path)
|
| 100 |
+
File "/home/rnd/miniconda3/envs/multitalk/lib/python3.8/site-packages/transformers/models/wav2vec2/processing_wav2vec2.py", line 105, in from_pretrained
|
| 101 |
+
tokenizer = Wav2Vec2CTCTokenizer.from_pretrained(pretrained_model_name_or_path, **kwargs)
|
| 102 |
+
File "/home/rnd/miniconda3/envs/multitalk/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 1708, in from_pretrained
|
| 103 |
+
raise EnvironmentError(msg)
|
| 104 |
+
OSError: Can't load tokenizer for 'facebook/wav2vec2-large-xlsr-53'. Make sure that:
|
| 105 |
+
|
| 106 |
+
- 'facebook/wav2vec2-large-xlsr-53' is a correct model identifier listed on 'https://huggingface.co/models'
|
| 107 |
+
|
| 108 |
+
- or 'facebook/wav2vec2-large-xlsr-53' is the correct path to a directory containing relevant tokenizer files
|
| 109 |
+
|
| 110 |
+
|
RUN/multi/MultiTalk_s2/test-20240707_000539.log
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[2024-07-07 00:05:39,843 INFO test_multi_pred.py line 63 3704273]=>INaffine: False
|
| 2 |
+
StepLR: False
|
| 3 |
+
adaptive_lr: False
|
| 4 |
+
arch: stage2
|
| 5 |
+
autoencoder: stage1_vocaset
|
| 6 |
+
base_lr: 0.0001
|
| 7 |
+
batch_size: 1
|
| 8 |
+
batch_size_val: 1
|
| 9 |
+
data_root: sample_dataset
|
| 10 |
+
dataset: multi
|
| 11 |
+
device: cuda
|
| 12 |
+
dist_backend: nccl
|
| 13 |
+
dist_url: tcp://127.0.0.1:6701
|
| 14 |
+
epochs: 100
|
| 15 |
+
eval_freq: 5
|
| 16 |
+
evaluate: True
|
| 17 |
+
face_quan_num: 16
|
| 18 |
+
factor: 0.3
|
| 19 |
+
feature_dim: 1024
|
| 20 |
+
gamma: 0.5
|
| 21 |
+
gt_save_folder: demo/gt
|
| 22 |
+
hidden_size: 1024
|
| 23 |
+
in_dim: 15069
|
| 24 |
+
intermediate_size: 1536
|
| 25 |
+
log_dir: None
|
| 26 |
+
loss: MSE
|
| 27 |
+
manual_seed: 131
|
| 28 |
+
measure_lve: False
|
| 29 |
+
model_path: checkpoints/stage2.pth.tar
|
| 30 |
+
momentum: 0.9
|
| 31 |
+
motion_weight: 1.0
|
| 32 |
+
multiprocessing_distributed: True
|
| 33 |
+
n_embed: 256
|
| 34 |
+
n_head: 4
|
| 35 |
+
neg: 0.2
|
| 36 |
+
num_attention_heads: 8
|
| 37 |
+
num_hidden_layers: 6
|
| 38 |
+
num_layers: 6
|
| 39 |
+
patience: 3
|
| 40 |
+
period: 25
|
| 41 |
+
poly_lr: False
|
| 42 |
+
power: 0.9
|
| 43 |
+
print_freq: 10
|
| 44 |
+
quant_factor: 0
|
| 45 |
+
rank: 0
|
| 46 |
+
read_audio: True
|
| 47 |
+
reg_weight: 1.0
|
| 48 |
+
resume: None
|
| 49 |
+
save: True
|
| 50 |
+
save_folder: demo/output
|
| 51 |
+
save_freq: 1
|
| 52 |
+
save_path: None
|
| 53 |
+
start_epoch: 0
|
| 54 |
+
step_size: 100
|
| 55 |
+
style_emb_method: nnemb
|
| 56 |
+
sync_bn: False
|
| 57 |
+
teacher_forcing: True
|
| 58 |
+
template_file: templates.pkl
|
| 59 |
+
test_batch_size: 1
|
| 60 |
+
test_gpu: [0]
|
| 61 |
+
test_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 62 |
+
test_workers: 0
|
| 63 |
+
threshold: 0.0001
|
| 64 |
+
train_gpu: [0]
|
| 65 |
+
train_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 66 |
+
use_sgd: False
|
| 67 |
+
val_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 68 |
+
vertice_dim: 15069
|
| 69 |
+
vertices_path: npy
|
| 70 |
+
visualize_mesh: True
|
| 71 |
+
vqvae_pretrained_path: checkpoints/stage1.pth.tar
|
| 72 |
+
warmup_steps: 1
|
| 73 |
+
wav2vec2model_path: facebook/wav2vec2-large-xlsr-53
|
| 74 |
+
wav_path: wav
|
| 75 |
+
weight: None
|
| 76 |
+
weight_decay: 0.002
|
| 77 |
+
window_size: 1
|
| 78 |
+
workers: 10
|
| 79 |
+
world_size: 1
|
| 80 |
+
zquant_dim: 64
|
| 81 |
+
[2024-07-07 00:05:39,843 INFO test_multi_pred.py line 64 3704273]=>=> creating model ...
|
| 82 |
+
Some weights of the model checkpoint at facebook/wav2vec2-large-xlsr-53 were not used when initializing Wav2Vec2Model: ['quantizer.codevectors', 'project_q.weight', 'project_hid.bias', 'project_hid.weight', 'project_q.bias', 'quantizer.weight_proj.weight', 'quantizer.weight_proj.bias']
|
| 83 |
+
- This IS expected if you are initializing Wav2Vec2Model from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
|
| 84 |
+
- This IS NOT expected if you are initializing Wav2Vec2Model from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
|
| 85 |
+
[2024-07-07 00:05:43,925 INFO test_multi_pred.py line 69 3704273]=>=> loading checkpoint 'checkpoints/stage2.pth.tar'
|
| 86 |
+
[2024-07-07 00:05:44,516 INFO test_multi_pred.py line 72 3704273]=>=> loaded checkpoint 'checkpoints/stage2.pth.tar'
|
| 87 |
+
Loading data...
|
| 88 |
+
Traceback (most recent call last):
|
| 89 |
+
File "main/test_multi_pred.py", line 144, in <module>
|
| 90 |
+
main()
|
| 91 |
+
File "main/test_multi_pred.py", line 78, in main
|
| 92 |
+
dataset = get_dataloaders(cfg, test_config=True)
|
| 93 |
+
File "/home/rnd/Documents/Ameer/Dream/MultiTalk/dataset/data_loader_multi.py", line 142, in get_dataloaders
|
| 94 |
+
train_data, valid_data, test_data, subjects_dict = read_data(args, test_config)
|
| 95 |
+
File "/home/rnd/Documents/Ameer/Dream/MultiTalk/dataset/data_loader_multi.py", line 66, in read_data
|
| 96 |
+
processor = Wav2Vec2Processor.from_pretrained(args.wav2vec2model_path)
|
| 97 |
+
File "/home/rnd/miniconda3/envs/multitalk/lib/python3.8/site-packages/transformers/models/wav2vec2/processing_wav2vec2.py", line 105, in from_pretrained
|
| 98 |
+
tokenizer = Wav2Vec2CTCTokenizer.from_pretrained(pretrained_model_name_or_path, **kwargs)
|
| 99 |
+
File "/home/rnd/miniconda3/envs/multitalk/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 1708, in from_pretrained
|
| 100 |
+
raise EnvironmentError(msg)
|
| 101 |
+
OSError: Can't load tokenizer for 'facebook/wav2vec2-large-xlsr-53'. Make sure that:
|
| 102 |
+
|
| 103 |
+
- 'facebook/wav2vec2-large-xlsr-53' is a correct model identifier listed on 'https://huggingface.co/models'
|
| 104 |
+
|
| 105 |
+
- or 'facebook/wav2vec2-large-xlsr-53' is the correct path to a directory containing relevant tokenizer files
|
| 106 |
+
|
| 107 |
+
|
RUN/multi/MultiTalk_s2/test-20240707_000731.log
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 0 |
0%| | 0/4 [00:00<?, ?it/s]
|
| 1 |
50%|█████ | 2/4 [00:00<00:00, 7.68it/s]
|
|
|
|
|
|
|
|
|
| 1 |
+
[2024-07-07 00:07:32,456 INFO test_multi_pred.py line 63 3704520]=>INaffine: False
|
| 2 |
+
StepLR: False
|
| 3 |
+
adaptive_lr: False
|
| 4 |
+
arch: stage2
|
| 5 |
+
autoencoder: stage1_vocaset
|
| 6 |
+
base_lr: 0.0001
|
| 7 |
+
batch_size: 1
|
| 8 |
+
batch_size_val: 1
|
| 9 |
+
data_root: sample_dataset
|
| 10 |
+
dataset: multi
|
| 11 |
+
device: cuda
|
| 12 |
+
dist_backend: nccl
|
| 13 |
+
dist_url: tcp://127.0.0.1:6701
|
| 14 |
+
epochs: 100
|
| 15 |
+
eval_freq: 5
|
| 16 |
+
evaluate: True
|
| 17 |
+
face_quan_num: 16
|
| 18 |
+
factor: 0.3
|
| 19 |
+
feature_dim: 1024
|
| 20 |
+
gamma: 0.5
|
| 21 |
+
gt_save_folder: demo/gt
|
| 22 |
+
hidden_size: 1024
|
| 23 |
+
in_dim: 15069
|
| 24 |
+
intermediate_size: 1536
|
| 25 |
+
log_dir: None
|
| 26 |
+
loss: MSE
|
| 27 |
+
manual_seed: 131
|
| 28 |
+
measure_lve: False
|
| 29 |
+
model_path: checkpoints/stage2.pth.tar
|
| 30 |
+
momentum: 0.9
|
| 31 |
+
motion_weight: 1.0
|
| 32 |
+
multiprocessing_distributed: True
|
| 33 |
+
n_embed: 256
|
| 34 |
+
n_head: 4
|
| 35 |
+
neg: 0.2
|
| 36 |
+
num_attention_heads: 8
|
| 37 |
+
num_hidden_layers: 6
|
| 38 |
+
num_layers: 6
|
| 39 |
+
patience: 3
|
| 40 |
+
period: 25
|
| 41 |
+
poly_lr: False
|
| 42 |
+
power: 0.9
|
| 43 |
+
print_freq: 10
|
| 44 |
+
quant_factor: 0
|
| 45 |
+
rank: 0
|
| 46 |
+
read_audio: True
|
| 47 |
+
reg_weight: 1.0
|
| 48 |
+
resume: None
|
| 49 |
+
save: True
|
| 50 |
+
save_folder: demo/output
|
| 51 |
+
save_freq: 1
|
| 52 |
+
save_path: None
|
| 53 |
+
start_epoch: 0
|
| 54 |
+
step_size: 100
|
| 55 |
+
style_emb_method: nnemb
|
| 56 |
+
sync_bn: False
|
| 57 |
+
teacher_forcing: True
|
| 58 |
+
template_file: templates.pkl
|
| 59 |
+
test_batch_size: 1
|
| 60 |
+
test_gpu: [0]
|
| 61 |
+
test_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 62 |
+
test_workers: 0
|
| 63 |
+
threshold: 0.0001
|
| 64 |
+
train_gpu: [0]
|
| 65 |
+
train_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 66 |
+
use_sgd: False
|
| 67 |
+
val_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 68 |
+
vertice_dim: 15069
|
| 69 |
+
vertices_path: npy
|
| 70 |
+
visualize_mesh: True
|
| 71 |
+
vqvae_pretrained_path: checkpoints/stage1.pth.tar
|
| 72 |
+
warmup_steps: 1
|
| 73 |
+
wav2vec2model_path: facebook/wav2vec2-large-xlsr-53
|
| 74 |
+
wav_path: wav
|
| 75 |
+
weight: None
|
| 76 |
+
weight_decay: 0.002
|
| 77 |
+
window_size: 1
|
| 78 |
+
workers: 10
|
| 79 |
+
world_size: 1
|
| 80 |
+
zquant_dim: 64
|
| 81 |
+
[2024-07-07 00:07:32,456 INFO test_multi_pred.py line 64 3704520]=>=> creating model ...
|
| 82 |
+
Some weights of the model checkpoint at facebook/wav2vec2-large-xlsr-53 were not used when initializing Wav2Vec2Model: ['project_hid.bias', 'project_q.weight', 'quantizer.weight_proj.weight', 'project_hid.weight', 'quantizer.codevectors', 'quantizer.weight_proj.bias', 'project_q.bias']
|
| 83 |
+
- This IS expected if you are initializing Wav2Vec2Model from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
|
| 84 |
+
- This IS NOT expected if you are initializing Wav2Vec2Model from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
|
| 85 |
+
[2024-07-07 00:07:36,887 INFO test_multi_pred.py line 69 3704520]=>=> loading checkpoint 'checkpoints/stage2.pth.tar'
|
| 86 |
+
[2024-07-07 00:07:37,452 INFO test_multi_pred.py line 72 3704520]=>=> loaded checkpoint 'checkpoints/stage2.pth.tar'
|
| 87 |
+
Loading data...
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
|
| 92 |
0%| | 0/4 [00:00<?, ?it/s]
|
| 93 |
50%|█████ | 2/4 [00:00<00:00, 7.68it/s]
|
| 94 |
+
Loaded data: Train-0, Val-0, Test-2
|
| 95 |
+
Lip Vertex Error on test set: 9.532534e-06
|
RUN/vocaset/MultiTalk_s2/test-20240707_000820.log
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 0 |
0%| | 0/4 [00:00<?, ?it/s]
|
| 1 |
50%|█████ | 2/4 [00:00<00:00, 7.70it/s]
|
|
|
|
|
|
|
|
|
| 1 |
+
[2024-07-07 00:08:21,269 INFO test_multi_pred.py line 63 3705029]=>INaffine: False
|
| 2 |
+
StepLR: False
|
| 3 |
+
adaptive_lr: False
|
| 4 |
+
arch: stage2
|
| 5 |
+
autoencoder: stage1_vocaset
|
| 6 |
+
base_lr: 0.0001
|
| 7 |
+
batch_size: 1
|
| 8 |
+
batch_size_val: 1
|
| 9 |
+
data_root: sample_dataset
|
| 10 |
+
dataset: multi
|
| 11 |
+
device: cuda
|
| 12 |
+
dist_backend: nccl
|
| 13 |
+
dist_url: tcp://127.0.0.1:6701
|
| 14 |
+
epochs: 100
|
| 15 |
+
eval_freq: 5
|
| 16 |
+
evaluate: True
|
| 17 |
+
face_quan_num: 16
|
| 18 |
+
factor: 0.3
|
| 19 |
+
feature_dim: 1024
|
| 20 |
+
gamma: 0.5
|
| 21 |
+
gt_save_folder: demo/gt
|
| 22 |
+
hidden_size: 1024
|
| 23 |
+
in_dim: 15069
|
| 24 |
+
intermediate_size: 1536
|
| 25 |
+
log_dir: None
|
| 26 |
+
loss: MSE
|
| 27 |
+
manual_seed: 131
|
| 28 |
+
measure_lve: False
|
| 29 |
+
model_path: checkpoints/stage2.pth.tar
|
| 30 |
+
momentum: 0.9
|
| 31 |
+
motion_weight: 1.0
|
| 32 |
+
multiprocessing_distributed: True
|
| 33 |
+
n_embed: 256
|
| 34 |
+
n_head: 4
|
| 35 |
+
neg: 0.2
|
| 36 |
+
num_attention_heads: 8
|
| 37 |
+
num_hidden_layers: 6
|
| 38 |
+
num_layers: 6
|
| 39 |
+
patience: 3
|
| 40 |
+
period: 25
|
| 41 |
+
poly_lr: False
|
| 42 |
+
power: 0.9
|
| 43 |
+
print_freq: 10
|
| 44 |
+
quant_factor: 0
|
| 45 |
+
rank: 0
|
| 46 |
+
read_audio: True
|
| 47 |
+
reg_weight: 1.0
|
| 48 |
+
resume: None
|
| 49 |
+
save: True
|
| 50 |
+
save_folder: demo/output
|
| 51 |
+
save_freq: 1
|
| 52 |
+
save_path: None
|
| 53 |
+
start_epoch: 0
|
| 54 |
+
step_size: 100
|
| 55 |
+
style_emb_method: nnemb
|
| 56 |
+
sync_bn: False
|
| 57 |
+
teacher_forcing: True
|
| 58 |
+
template_file: templates.pkl
|
| 59 |
+
test_batch_size: 1
|
| 60 |
+
test_gpu: [0]
|
| 61 |
+
test_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 62 |
+
test_workers: 0
|
| 63 |
+
threshold: 0.0001
|
| 64 |
+
train_gpu: [0]
|
| 65 |
+
train_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 66 |
+
use_sgd: False
|
| 67 |
+
val_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 68 |
+
vertice_dim: 15069
|
| 69 |
+
vertices_path: npy
|
| 70 |
+
visualize_mesh: True
|
| 71 |
+
vqvae_pretrained_path: checkpoints/stage1.pth.tar
|
| 72 |
+
warmup_steps: 1
|
| 73 |
+
wav2vec2model_path: facebook/wav2vec2-large-xlsr-53
|
| 74 |
+
wav_path: wav
|
| 75 |
+
weight: None
|
| 76 |
+
weight_decay: 0.002
|
| 77 |
+
window_size: 1
|
| 78 |
+
workers: 10
|
| 79 |
+
world_size: 1
|
| 80 |
+
zquant_dim: 64
|
| 81 |
+
[2024-07-07 00:08:21,269 INFO test_multi_pred.py line 64 3705029]=>=> creating model ...
|
| 82 |
+
Some weights of the model checkpoint at facebook/wav2vec2-large-xlsr-53 were not used when initializing Wav2Vec2Model: ['project_q.weight', 'project_hid.bias', 'quantizer.weight_proj.weight', 'quantizer.weight_proj.bias', 'project_q.bias', 'quantizer.codevectors', 'project_hid.weight']
|
| 83 |
+
- This IS expected if you are initializing Wav2Vec2Model from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
|
| 84 |
+
- This IS NOT expected if you are initializing Wav2Vec2Model from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
|
| 85 |
+
[2024-07-07 00:08:25,356 INFO test_multi_pred.py line 69 3705029]=>=> loading checkpoint 'checkpoints/stage2.pth.tar'
|
| 86 |
+
[2024-07-07 00:08:25,922 INFO test_multi_pred.py line 72 3705029]=>=> loaded checkpoint 'checkpoints/stage2.pth.tar'
|
| 87 |
+
Loading data...
|
| 88 |
+
|
| 89 |
0%| | 0/4 [00:00<?, ?it/s]
|
| 90 |
50%|█████ | 2/4 [00:00<00:00, 7.70it/s]
|
| 91 |
+
Loaded data: Train-0, Val-0, Test-2
|
| 92 |
+
Lip Vertex Error on test set: 9.532534e-06
|
assets/statistic.png
ADDED
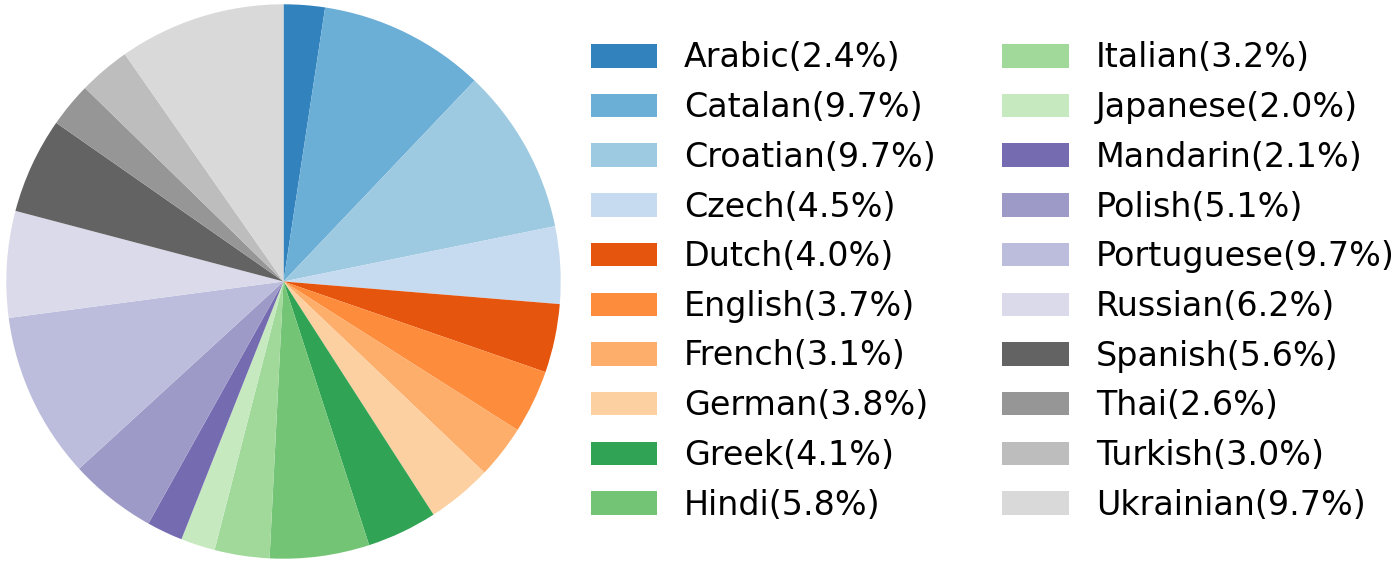
|
assets/teaser.png
ADDED

|
Git LFS Details
|
base/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .base_model import *
|
base/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (176 Bytes). View file
|
|
|
base/__pycache__/baseTrainer.cpython-38.pyc
ADDED
|
Binary file (2.23 kB). View file
|
|
|
base/__pycache__/base_model.cpython-38.pyc
ADDED
|
Binary file (1.53 kB). View file
|
|
|
base/__pycache__/config.cpython-38.pyc
ADDED
|
Binary file (4.58 kB). View file
|
|
|
base/__pycache__/utilities.cpython-38.pyc
ADDED
|
Binary file (2.43 kB). View file
|
|
|
base/baseTrainer.py
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
import torch
|
| 3 |
+
from os.path import join
|
| 4 |
+
import torch.distributed as dist
|
| 5 |
+
from .utilities import check_makedirs
|
| 6 |
+
from collections import OrderedDict
|
| 7 |
+
from torch.nn.parallel import DataParallel, DistributedDataParallel
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def step_learning_rate(base_lr, epoch, step_epoch, multiplier=0.1):
|
| 11 |
+
lr = base_lr * (multiplier ** (epoch // step_epoch))
|
| 12 |
+
return lr
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def poly_learning_rate(base_lr, curr_iter, max_iter, power=0.9):
|
| 16 |
+
"""poly learning rate policy"""
|
| 17 |
+
lr = base_lr * (1 - float(curr_iter) / max_iter) ** power
|
| 18 |
+
return lr
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def adjust_learning_rate(optimizer, lr):
|
| 22 |
+
for param_group in optimizer.param_groups:
|
| 23 |
+
param_group['lr'] = lr
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def save_checkpoint(model, other_state={}, sav_path='', filename='model.pth.tar', stage=1):
|
| 27 |
+
if isinstance(model, (DistributedDataParallel, DataParallel)):
|
| 28 |
+
weight = model.module.state_dict()
|
| 29 |
+
elif isinstance(model, torch.nn.Module):
|
| 30 |
+
weight = model.state_dict()
|
| 31 |
+
else:
|
| 32 |
+
raise ValueError('model must be nn.Module or nn.DataParallel!')
|
| 33 |
+
check_makedirs(sav_path)
|
| 34 |
+
|
| 35 |
+
if stage == 2: # remove vqvae part
|
| 36 |
+
for k in list(weight.keys()):
|
| 37 |
+
if 'autoencoder' in k:
|
| 38 |
+
weight.pop(k)
|
| 39 |
+
|
| 40 |
+
other_state['state_dict'] = weight
|
| 41 |
+
filename = join(sav_path, filename)
|
| 42 |
+
torch.save(other_state, filename)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def load_state_dict(model, state_dict, strict=True):
|
| 47 |
+
if isinstance(model, (DistributedDataParallel, DataParallel)):
|
| 48 |
+
model.module.load_state_dict(state_dict, strict=strict)
|
| 49 |
+
else:
|
| 50 |
+
model.load_state_dict(state_dict, strict=strict)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def state_dict_remove_module(state_dict):
|
| 54 |
+
new_state_dict = OrderedDict()
|
| 55 |
+
for k, v in state_dict.items():
|
| 56 |
+
# name = k[7:] # remove 'module.' of dataparallel
|
| 57 |
+
name = k.replace('module.', '')
|
| 58 |
+
new_state_dict[name] = v
|
| 59 |
+
return new_state_dict
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def reduce_tensor(tensor, args):
|
| 63 |
+
rt = tensor.clone()
|
| 64 |
+
dist.all_reduce(rt, op=dist.ReduceOp.SUM)
|
| 65 |
+
rt /= args.world_size
|
| 66 |
+
return rt
|
base/base_model.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
import numpy as np
|
| 3 |
+
|
| 4 |
+
class BaseModel(nn.Module):
|
| 5 |
+
"""
|
| 6 |
+
Base class for all models
|
| 7 |
+
"""
|
| 8 |
+
|
| 9 |
+
def __init__(self):
|
| 10 |
+
super(BaseModel, self).__init__()
|
| 11 |
+
# self.logger = logging.getLogger(self.__class__.__name__)
|
| 12 |
+
|
| 13 |
+
def forward(self, *x):
|
| 14 |
+
"""
|
| 15 |
+
Forward pass logic
|
| 16 |
+
|
| 17 |
+
:return: Model output
|
| 18 |
+
"""
|
| 19 |
+
raise NotImplementedError
|
| 20 |
+
|
| 21 |
+
def summary(self, logger, writer):
|
| 22 |
+
"""
|
| 23 |
+
Model summary
|
| 24 |
+
"""
|
| 25 |
+
model_parameters = filter(lambda p: p.requires_grad, self.parameters())
|
| 26 |
+
params = sum([np.prod(p.size()) for p in model_parameters]) / 1e6 # Unit is Mega
|
| 27 |
+
logger.info(self)
|
| 28 |
+
logger.info('===>Trainable parameters: %.3f M' % params)
|
| 29 |
+
if writer is not None:
|
| 30 |
+
writer.add_text('Model Summary', 'Trainable parameters: %.3f M' % params)
|
base/config.py
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -----------------------------------------------------------------------------
|
| 2 |
+
# Functions for parsing args
|
| 3 |
+
# -----------------------------------------------------------------------------
|
| 4 |
+
import yaml
|
| 5 |
+
import os
|
| 6 |
+
from ast import literal_eval
|
| 7 |
+
import copy
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class CfgNode(dict):
|
| 11 |
+
"""
|
| 12 |
+
CfgNode represents an internal node in the configuration tree. It's a simple
|
| 13 |
+
dict-like container that allows for attribute-based access to keys.
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
def __init__(self, init_dict=None, key_list=None, new_allowed=False):
|
| 17 |
+
# Recursively convert nested dictionaries in init_dict into CfgNodes
|
| 18 |
+
init_dict = {} if init_dict is None else init_dict
|
| 19 |
+
key_list = [] if key_list is None else key_list
|
| 20 |
+
for k, v in init_dict.items():
|
| 21 |
+
if type(v) is dict:
|
| 22 |
+
# Convert dict to CfgNode
|
| 23 |
+
init_dict[k] = CfgNode(v, key_list=key_list + [k])
|
| 24 |
+
super(CfgNode, self).__init__(init_dict)
|
| 25 |
+
|
| 26 |
+
def __getattr__(self, name):
|
| 27 |
+
if name in self:
|
| 28 |
+
return self[name]
|
| 29 |
+
else:
|
| 30 |
+
raise AttributeError(name)
|
| 31 |
+
|
| 32 |
+
def __setattr__(self, name, value):
|
| 33 |
+
self[name] = value
|
| 34 |
+
|
| 35 |
+
def __str__(self):
|
| 36 |
+
def _indent(s_, num_spaces):
|
| 37 |
+
s = s_.split("\n")
|
| 38 |
+
if len(s) == 1:
|
| 39 |
+
return s_
|
| 40 |
+
first = s.pop(0)
|
| 41 |
+
s = [(num_spaces * " ") + line for line in s]
|
| 42 |
+
s = "\n".join(s)
|
| 43 |
+
s = first + "\n" + s
|
| 44 |
+
return s
|
| 45 |
+
|
| 46 |
+
r = ""
|
| 47 |
+
s = []
|
| 48 |
+
for k, v in sorted(self.items()):
|
| 49 |
+
seperator = "\n" if isinstance(v, CfgNode) else " "
|
| 50 |
+
attr_str = "{}:{}{}".format(str(k), seperator, str(v))
|
| 51 |
+
attr_str = _indent(attr_str, 2)
|
| 52 |
+
s.append(attr_str)
|
| 53 |
+
r += "\n".join(s)
|
| 54 |
+
return r
|
| 55 |
+
|
| 56 |
+
def __repr__(self):
|
| 57 |
+
return "{}({})".format(self.__class__.__name__, super(CfgNode, self).__repr__())
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def load_cfg_from_cfg_file(file):
|
| 61 |
+
cfg = {}
|
| 62 |
+
assert os.path.isfile(file) and file.endswith('.yaml'), \
|
| 63 |
+
'{} is not a yaml file'.format(file)
|
| 64 |
+
|
| 65 |
+
with open(file, 'r') as f:
|
| 66 |
+
cfg_from_file = yaml.safe_load(f)
|
| 67 |
+
|
| 68 |
+
for key in cfg_from_file:
|
| 69 |
+
for k, v in cfg_from_file[key].items():
|
| 70 |
+
cfg[k] = v
|
| 71 |
+
|
| 72 |
+
cfg = CfgNode(cfg)
|
| 73 |
+
return cfg
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def merge_cfg_from_list(cfg, cfg_list):
|
| 77 |
+
new_cfg = copy.deepcopy(cfg)
|
| 78 |
+
assert len(cfg_list) % 2 == 0
|
| 79 |
+
for full_key, v in zip(cfg_list[0::2], cfg_list[1::2]):
|
| 80 |
+
subkey = full_key.split('.')[-1]
|
| 81 |
+
assert subkey in cfg, 'Non-existent key: {}'.format(full_key)
|
| 82 |
+
value = _decode_cfg_value(v)
|
| 83 |
+
value = _check_and_coerce_cfg_value_type(
|
| 84 |
+
value, cfg[subkey], subkey, full_key
|
| 85 |
+
)
|
| 86 |
+
setattr(new_cfg, subkey, value)
|
| 87 |
+
|
| 88 |
+
return new_cfg
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def _decode_cfg_value(v):
|
| 92 |
+
"""Decodes a raw config value (e.g., from a yaml config files or command
|
| 93 |
+
line argument) into a Python object.
|
| 94 |
+
"""
|
| 95 |
+
# All remaining processing is only applied to strings
|
| 96 |
+
if not isinstance(v, str):
|
| 97 |
+
return v
|
| 98 |
+
# Try to interpret `v` as a:
|
| 99 |
+
# string, number, tuple, list, dict, boolean, or None
|
| 100 |
+
try:
|
| 101 |
+
v = literal_eval(v)
|
| 102 |
+
# The following two excepts allow v to pass through when it represents a
|
| 103 |
+
# string.
|
| 104 |
+
#
|
| 105 |
+
# Longer explanation:
|
| 106 |
+
# The type of v is always a string (before calling literal_eval), but
|
| 107 |
+
# sometimes it *represents* a string and other times a data structure, like
|
| 108 |
+
# a list. In the case that v represents a string, what we got back from the
|
| 109 |
+
# yaml parser is 'foo' *without quotes* (so, not '"foo"'). literal_eval is
|
| 110 |
+
# ok with '"foo"', but will raise a ValueError if given 'foo'. In other
|
| 111 |
+
# cases, like paths (v = 'foo/bar' and not v = '"foo/bar"'), literal_eval
|
| 112 |
+
# will raise a SyntaxError.
|
| 113 |
+
except ValueError:
|
| 114 |
+
pass
|
| 115 |
+
except SyntaxError:
|
| 116 |
+
pass
|
| 117 |
+
return v
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def _check_and_coerce_cfg_value_type(replacement, original, key, full_key):
|
| 121 |
+
"""Checks that `replacement`, which is intended to replace `original` is of
|
| 122 |
+
the right type. The type is correct if it matches exactly or is one of a few
|
| 123 |
+
cases in which the type can be easily coerced.
|
| 124 |
+
"""
|
| 125 |
+
original_type = type(original)
|
| 126 |
+
replacement_type = type(replacement)
|
| 127 |
+
|
| 128 |
+
# The types must match (with some exceptions)
|
| 129 |
+
if replacement_type == original_type or original is None:
|
| 130 |
+
return replacement
|
| 131 |
+
|
| 132 |
+
# Cast replacement from from_type to to_type if the replacement and original
|
| 133 |
+
# types match from_type and to_type
|
| 134 |
+
def conditional_cast(from_type, to_type):
|
| 135 |
+
if replacement_type == from_type and original_type == to_type:
|
| 136 |
+
return True, to_type(replacement)
|
| 137 |
+
else:
|
| 138 |
+
return False, None
|
| 139 |
+
|
| 140 |
+
# Conditionally casts
|
| 141 |
+
# list <-> tuple
|
| 142 |
+
casts = [(tuple, list), (list, tuple)]
|
| 143 |
+
# For py2: allow converting from str (bytes) to a unicode string
|
| 144 |
+
try:
|
| 145 |
+
casts.append((str, unicode)) # noqa: F821
|
| 146 |
+
except Exception:
|
| 147 |
+
pass
|
| 148 |
+
|
| 149 |
+
for (from_type, to_type) in casts:
|
| 150 |
+
converted, converted_value = conditional_cast(from_type, to_type)
|
| 151 |
+
if converted:
|
| 152 |
+
return converted_value
|
| 153 |
+
|
| 154 |
+
raise ValueError(
|
| 155 |
+
"Type mismatch ({} vs. {}) with values ({} vs. {}) for config "
|
| 156 |
+
"key: {}".format(
|
| 157 |
+
original_type, replacement_type, original, replacement, full_key
|
| 158 |
+
)
|
| 159 |
+
)
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def _assert_with_logging(cond, msg):
|
| 163 |
+
if not cond:
|
| 164 |
+
logger.debug(msg)
|
| 165 |
+
assert cond, msg
|
base/utilities.py
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
import argparse
|
| 3 |
+
import os
|
| 4 |
+
import random
|
| 5 |
+
import time
|
| 6 |
+
import logging
|
| 7 |
+
import numpy as np
|
| 8 |
+
from base import config
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get_parser():
|
| 12 |
+
parser = argparse.ArgumentParser(description=' ')
|
| 13 |
+
parser.add_argument('--config', type=str, default='**.yaml', help='config file')
|
| 14 |
+
parser.add_argument('opts', help=' ', default=None,
|
| 15 |
+
nargs=argparse.REMAINDER)
|
| 16 |
+
args = parser.parse_args()
|
| 17 |
+
assert args.config is not None
|
| 18 |
+
cfg = config.load_cfg_from_cfg_file(args.config)
|
| 19 |
+
if args.opts is not None:
|
| 20 |
+
cfg = config.merge_cfg_from_list(cfg, args.opts)
|
| 21 |
+
return cfg
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def get_logger():
|
| 25 |
+
logger_name = "main-logger"
|
| 26 |
+
logger = logging.getLogger(logger_name)
|
| 27 |
+
logger.setLevel(logging.INFO)
|
| 28 |
+
handler = logging.StreamHandler()
|
| 29 |
+
fmt = "[%(asctime)s %(levelname)s %(filename)s line %(lineno)d %(process)d]=>%(message)s"
|
| 30 |
+
handler.setFormatter(logging.Formatter(fmt))
|
| 31 |
+
logger.addHandler(handler)
|
| 32 |
+
return logger
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class AverageMeter(object):
|
| 36 |
+
"""Computes and stores the average and current value"""
|
| 37 |
+
|
| 38 |
+
def __init__(self):
|
| 39 |
+
self.reset()
|
| 40 |
+
|
| 41 |
+
def reset(self):
|
| 42 |
+
self.val = 0
|
| 43 |
+
self.avg = 0
|
| 44 |
+
self.sum = 0
|
| 45 |
+
self.count = 0
|
| 46 |
+
|
| 47 |
+
def update(self, val, n=1):
|
| 48 |
+
self.val = val
|
| 49 |
+
self.sum += val * n
|
| 50 |
+
self.count += n
|
| 51 |
+
self.avg = self.sum / self.count
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def check_mkdir(dir_name):
|
| 55 |
+
if not os.path.exists(dir_name):
|
| 56 |
+
os.mkdir(dir_name)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def check_makedirs(dir_name):
|
| 60 |
+
if not os.path.exists(dir_name):
|
| 61 |
+
os.makedirs(dir_name)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def main_process(args):
|
| 65 |
+
return not args.multiprocessing_distributed or (
|
| 66 |
+
args.multiprocessing_distributed and args.rank % args.ngpus_per_node == 0)
|
checkpoints/FLAME_sample.ply
ADDED
|
Binary file (190 kB). View file
|
|
|
checkpoints/stage1.pth.tar
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:204f79b355080035e05ef25b2a69d46a9404aa66ed70c9fc0064eeac4ad95fa2
|
| 3 |
+
size 567634587
|
checkpoints/stage2.pth.tar
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0777b00137c88384d72c48f58b5f5e929aca7fdbee3c32e08b45aaa099379693
|
| 3 |
+
size 1703000029
|
checkpoints/templates.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8c9fff77287b68808ce18a76e31dfc2d793a6746abbb7620eb4424d1d73919fa
|
| 3 |
+
size 60437
|
config/multi/demo.yaml
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
DATA:
|
| 2 |
+
dataset: multi
|
| 3 |
+
data_root: sample_dataset
|
| 4 |
+
wav_path: wav
|
| 5 |
+
vertices_path: npy
|
| 6 |
+
template_file: templates.pkl
|
| 7 |
+
train_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 8 |
+
|
| 9 |
+
NETWORK:
|
| 10 |
+
arch: stage2
|
| 11 |
+
in_dim: 15069
|
| 12 |
+
hidden_size: 1024
|
| 13 |
+
num_hidden_layers: 6
|
| 14 |
+
num_attention_heads: 8
|
| 15 |
+
intermediate_size: 1536
|
| 16 |
+
window_size: 1
|
| 17 |
+
quant_factor: 0
|
| 18 |
+
face_quan_num: 16
|
| 19 |
+
neg: 0.2
|
| 20 |
+
autoencoder: stage1_vocaset
|
| 21 |
+
INaffine: False
|
| 22 |
+
style_emb_method: nnemb # onehot or nnemb
|
| 23 |
+
|
| 24 |
+
VQuantizer:
|
| 25 |
+
n_embed: 256
|
| 26 |
+
zquant_dim: 64
|
| 27 |
+
|
| 28 |
+
PREDICTOR:
|
| 29 |
+
feature_dim: 1024
|
| 30 |
+
vertice_dim: 15069
|
| 31 |
+
device: cuda
|
| 32 |
+
period: 25
|
| 33 |
+
vqvae_pretrained_path: checkpoints/stage1.pth.tar
|
| 34 |
+
wav2vec2model_path: facebook/wav2vec2-large-xlsr-53
|
| 35 |
+
teacher_forcing: True
|
| 36 |
+
num_layers: 6
|
| 37 |
+
n_head: 4 # not used
|
| 38 |
+
|
| 39 |
+
DEMO:
|
| 40 |
+
model_path: checkpoints/stage2.pth.tar
|
| 41 |
+
#condition: False #if false, the waveform file has the cue for the type of language
|
| 42 |
+
condition: English
|
| 43 |
+
subject: id
|
| 44 |
+
demo_wav_dir_path: demo/input/
|
| 45 |
+
demo_output_path: demo/output/
|
| 46 |
+
fps: 25
|
| 47 |
+
background_black: True # chose the background color of your rendered video
|
config/multi/stage1.yaml
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
DATA:
|
| 2 |
+
dataset: multi
|
| 3 |
+
data_root: sample_dataset
|
| 4 |
+
wav_path: wav
|
| 5 |
+
vertices_path: npy
|
| 6 |
+
template_file: templates.pkl
|
| 7 |
+
read_audio: False
|
| 8 |
+
train_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 9 |
+
val_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 10 |
+
test_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
LOSS:
|
| 14 |
+
quant_loss_weight: 1.0
|
| 15 |
+
|
| 16 |
+
NETWORK:
|
| 17 |
+
arch: stage1_vocaset
|
| 18 |
+
in_dim: 15069
|
| 19 |
+
hidden_size: 1024
|
| 20 |
+
num_hidden_layers: 6
|
| 21 |
+
num_attention_heads: 8
|
| 22 |
+
intermediate_size: 1536
|
| 23 |
+
window_size: 1
|
| 24 |
+
quant_factor: 0
|
| 25 |
+
face_quan_num: 16
|
| 26 |
+
neg: 0.2
|
| 27 |
+
INaffine: False
|
| 28 |
+
|
| 29 |
+
VQuantizer:
|
| 30 |
+
n_embed: 256
|
| 31 |
+
zquant_dim: 64
|
| 32 |
+
|
| 33 |
+
TRAIN:
|
| 34 |
+
use_sgd: False
|
| 35 |
+
sync_bn: False # adopt sync_bn or not
|
| 36 |
+
train_gpu: [0]
|
| 37 |
+
workers: 10 # data loader workers
|
| 38 |
+
batch_size: 1 # batch size for training
|
| 39 |
+
batch_size_val: 1 # batch size for validation during training, memory and speed tradeoff
|
| 40 |
+
base_lr: 0.0001
|
| 41 |
+
StepLR: True
|
| 42 |
+
warmup_steps: 1
|
| 43 |
+
adaptive_lr: False
|
| 44 |
+
factor: 0.3
|
| 45 |
+
patience: 3
|
| 46 |
+
threshold: 0.0001
|
| 47 |
+
poly_lr: False
|
| 48 |
+
epochs: 200
|
| 49 |
+
step_size: 20
|
| 50 |
+
gamma: 0.5
|
| 51 |
+
start_epoch: 0
|
| 52 |
+
power: 0.9
|
| 53 |
+
momentum: 0.9
|
| 54 |
+
weight_decay: 0.002
|
| 55 |
+
manual_seed: 131
|
| 56 |
+
print_freq: 10
|
| 57 |
+
save_freq: 1
|
| 58 |
+
save_path:
|
| 59 |
+
# weight:
|
| 60 |
+
weight:
|
| 61 |
+
resume:
|
| 62 |
+
evaluate: True # evaluate on validation set, extra gpu memory needed and small batch_size_val is recommend
|
| 63 |
+
eval_freq: 10
|
| 64 |
+
|
| 65 |
+
Distributed:
|
| 66 |
+
dist_url: tcp://127.0.0.1:6701
|
| 67 |
+
dist_backend: 'nccl'
|
| 68 |
+
multiprocessing_distributed: True
|
| 69 |
+
world_size: 1
|
| 70 |
+
rank: 0
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
TEST:
|
| 74 |
+
test_workers: 0
|
| 75 |
+
test_gpu: [0]
|
| 76 |
+
test_batch_size: 1
|
| 77 |
+
save: True
|
| 78 |
+
model_path:
|
| 79 |
+
save_folder:
|
config/multi/stage2.yaml
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
DATA:
|
| 2 |
+
dataset: multi
|
| 3 |
+
data_root: sample_dataset
|
| 4 |
+
wav_path: wav
|
| 5 |
+
vertices_path: npy
|
| 6 |
+
template_file: templates.pkl
|
| 7 |
+
read_audio: True
|
| 8 |
+
train_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 9 |
+
val_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 10 |
+
test_subjects: Arabic English French German Greek Italian Portuguese Russian Spanish Korean Mandarin Japanese
|
| 11 |
+
log_dir:
|
| 12 |
+
|
| 13 |
+
LOSS:
|
| 14 |
+
loss: MSE
|
| 15 |
+
motion_weight: 1.0
|
| 16 |
+
reg_weight: 1.0
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
NETWORK:
|
| 20 |
+
arch: stage2
|
| 21 |
+
in_dim: 15069
|
| 22 |
+
hidden_size: 1024
|
| 23 |
+
num_hidden_layers: 6
|
| 24 |
+
num_attention_heads: 8
|
| 25 |
+
intermediate_size: 1536
|
| 26 |
+
window_size: 1
|
| 27 |
+
quant_factor: 0
|
| 28 |
+
face_quan_num: 16
|
| 29 |
+
neg: 0.2
|
| 30 |
+
autoencoder: stage1_vocaset
|
| 31 |
+
INaffine: False
|
| 32 |
+
style_emb_method: nnemb # onehot or nnemb
|
| 33 |
+
|
| 34 |
+
VQuantizer:
|
| 35 |
+
n_embed: 256
|
| 36 |
+
zquant_dim: 64
|
| 37 |
+
|
| 38 |
+
PREDICTOR:
|
| 39 |
+
feature_dim: 1024
|
| 40 |
+
vertice_dim: 15069
|
| 41 |
+
device: cuda
|
| 42 |
+
period: 25
|
| 43 |
+
vqvae_pretrained_path: checkpoints/stage1.pth.tar
|
| 44 |
+
wav2vec2model_path: facebook/wav2vec2-large-xlsr-53
|
| 45 |
+
teacher_forcing: True
|
| 46 |
+
num_layers: 6
|
| 47 |
+
n_head: 4 # not used
|
| 48 |
+
|
| 49 |
+
TRAIN:
|
| 50 |
+
use_sgd: False
|
| 51 |
+
sync_bn: False # adopt sync_bn or not
|
| 52 |
+
train_gpu: [0]
|
| 53 |
+
workers: 10 # data loader workers
|
| 54 |
+
batch_size: 1 # batch size for training
|
| 55 |
+
batch_size_val: 1 # batch size for validation during training, memory and speed tradeoff
|
| 56 |
+
base_lr: 0.0001
|
| 57 |
+
StepLR: False
|
| 58 |
+
warmup_steps: 1
|
| 59 |
+
adaptive_lr: False
|
| 60 |
+
factor: 0.3
|
| 61 |
+
patience: 3
|
| 62 |
+
threshold: 0.0001
|
| 63 |
+
poly_lr: False
|
| 64 |
+
epochs: 100
|
| 65 |
+
step_size: 100
|
| 66 |
+
gamma: 0.5
|
| 67 |
+
start_epoch: 0
|
| 68 |
+
power: 0.9
|
| 69 |
+
momentum: 0.9
|
| 70 |
+
weight_decay: 0.002
|
| 71 |
+
manual_seed: 131
|
| 72 |
+
print_freq: 10
|
| 73 |
+
save_freq: 1
|
| 74 |
+
save_path:
|
| 75 |
+
# weight:
|
| 76 |
+
weight:
|
| 77 |
+
resume:
|
| 78 |
+
evaluate: True # evaluate on validation set, extra gpu memory needed and small batch_size_val is recommend
|
| 79 |
+
eval_freq: 5
|
| 80 |
+
|
| 81 |
+
Distributed:
|
| 82 |
+
dist_url: tcp://127.0.0.1:6701
|
| 83 |
+
dist_backend: 'nccl'
|
| 84 |
+
multiprocessing_distributed: True
|
| 85 |
+
world_size: 1
|
| 86 |
+
rank: 0
|
| 87 |
+
|
| 88 |
+
TEST:
|
| 89 |
+
test_workers: 0
|
| 90 |
+
test_gpu: [0]
|
| 91 |
+
test_batch_size: 1
|
| 92 |
+
save: True
|
| 93 |
+
model_path: checkpoints/stage2.pth.tar
|
| 94 |
+
save_folder: demo/output
|
| 95 |
+
gt_save_folder: demo/gt
|
| 96 |
+
measure_lve : False
|
| 97 |
+
visualize_mesh : True
|