

Update README.md
Browse files
README.md
CHANGED
|
@@ -17,9 +17,13 @@ pipeline_tag: visual-question-answering
|
|
| 17 |
|
| 18 |
|
| 19 |
## Introduction
|
| 20 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 21 |
and trained on [VideoFeedback](https://huggingface.co/datasets/TIGER-Lab/VideoFeedback),
|
| 22 |
-
a large video evaluation dataset with multi-aspect human scores.
|
| 23 |
|
| 24 |
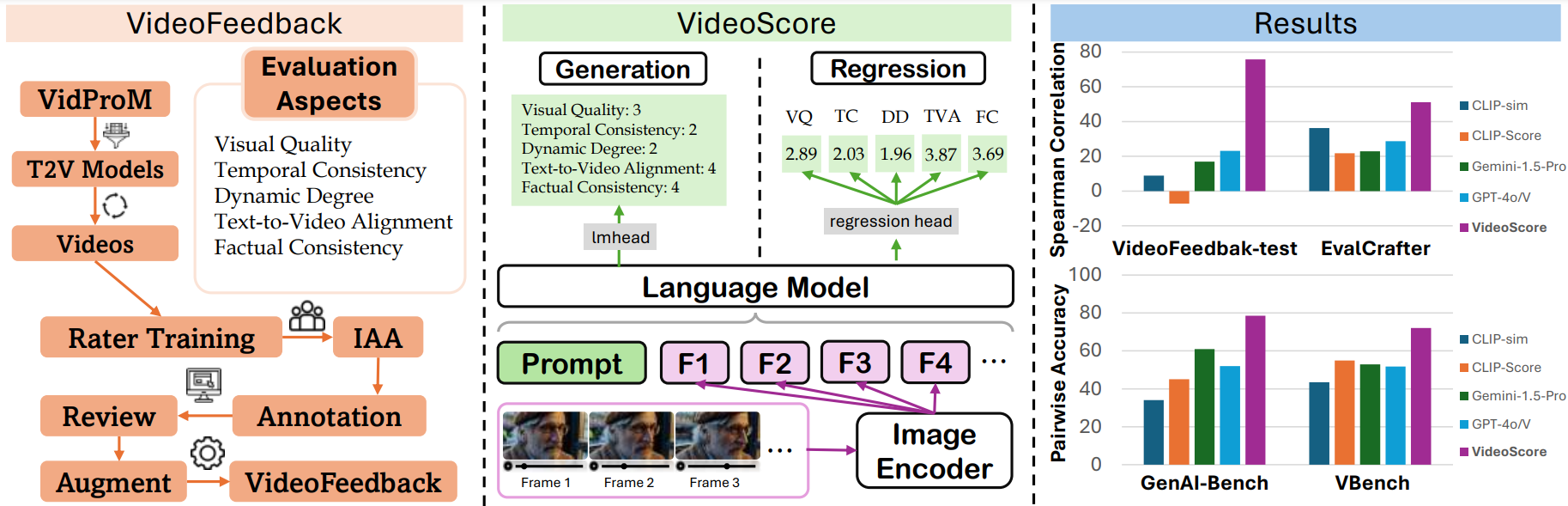
- VideoScore can reach 75+ Spearman correlation with humans on VideoFeedback-test, surpassing all the MLLM-prompting methods and feature-based metrics.
|
| 25 |
VideoScore also beat the best baselines on other three benchmarks EvalCrafter, GenAI-Bench and VBench, showing high alignment with human evaluations.
|
|
|
|
| 17 |

|
| 18 |
|
| 19 |
## Introduction
|
| 20 |
+
|
| 21 |
+
- 🤯🤯Try on the new version [VideoScore-v1.1](https://huggingface.co/TIGER-Lab/VideoScore-v1.1), which is a variant from [VideoScore](https://huggingface.co/TIGER-Lab/VideoScore) with better performance in "text-to-video alignment" subscore!
|
| 22 |
+
See more details about this new version [here](https://huggingface.co/TIGER-Lab/VideoScore-v1.1).
|
| 23 |
+
|
| 24 |
+
- [VideoScore](https://huggingface.co/TIGER-Lab/VideoScore) series is a video quality evaluation model series, taking [Mantis-8B-Idefics2](https://huggingface.co/TIGER-Lab/Mantis-8B-Idefics2) as base-model
|
| 25 |
and trained on [VideoFeedback](https://huggingface.co/datasets/TIGER-Lab/VideoFeedback),
|
| 26 |
+
a large video evaluation dataset with multi-aspect human scores.
|
| 27 |
|
| 28 |
- VideoScore can reach 75+ Spearman correlation with humans on VideoFeedback-test, surpassing all the MLLM-prompting methods and feature-based metrics.
|
| 29 |
VideoScore also beat the best baselines on other three benchmarks EvalCrafter, GenAI-Bench and VBench, showing high alignment with human evaluations.
|