---
language:
- en
arxiv: 2412.15838
license: cc-by-nc-4.0
tags:
- any-to-any
---
# AnyRewardModel
All-Modality Generation benchmark evaluates a model's ability to follow instructions, automatically select appropriate modalities, and create synergistic outputs across different modalities (text, visual, audio) while avoiding redundancy.
[🏠 Homepage](https://github.com/PKU-Alignment/align-anything) | [👍 Our Official Code Repo](https://github.com/PKU-Alignment/align-anything)
[🤗 All-Modality Understanding Benchmark](https://huggingface.co/datasets/PKU-Alignment/EvalAnything-AMU)
[🤗 All-Modality Generation Benchmark (Instruction Following Part)](https://huggingface.co/datasets/PKU-Alignment/EvalAnything-InstructionFollowing)
[🤗 All-Modality Generation Benchmark (Modality Selection and Synergy Part)](https://huggingface.co/datasets/PKU-Alignment/EvalAnything-Selection_Synergy)
[🤗 All-Modality Generation Reward Model](https://huggingface.co/PKU-Alignment/AnyRewardModel)
## Data Example
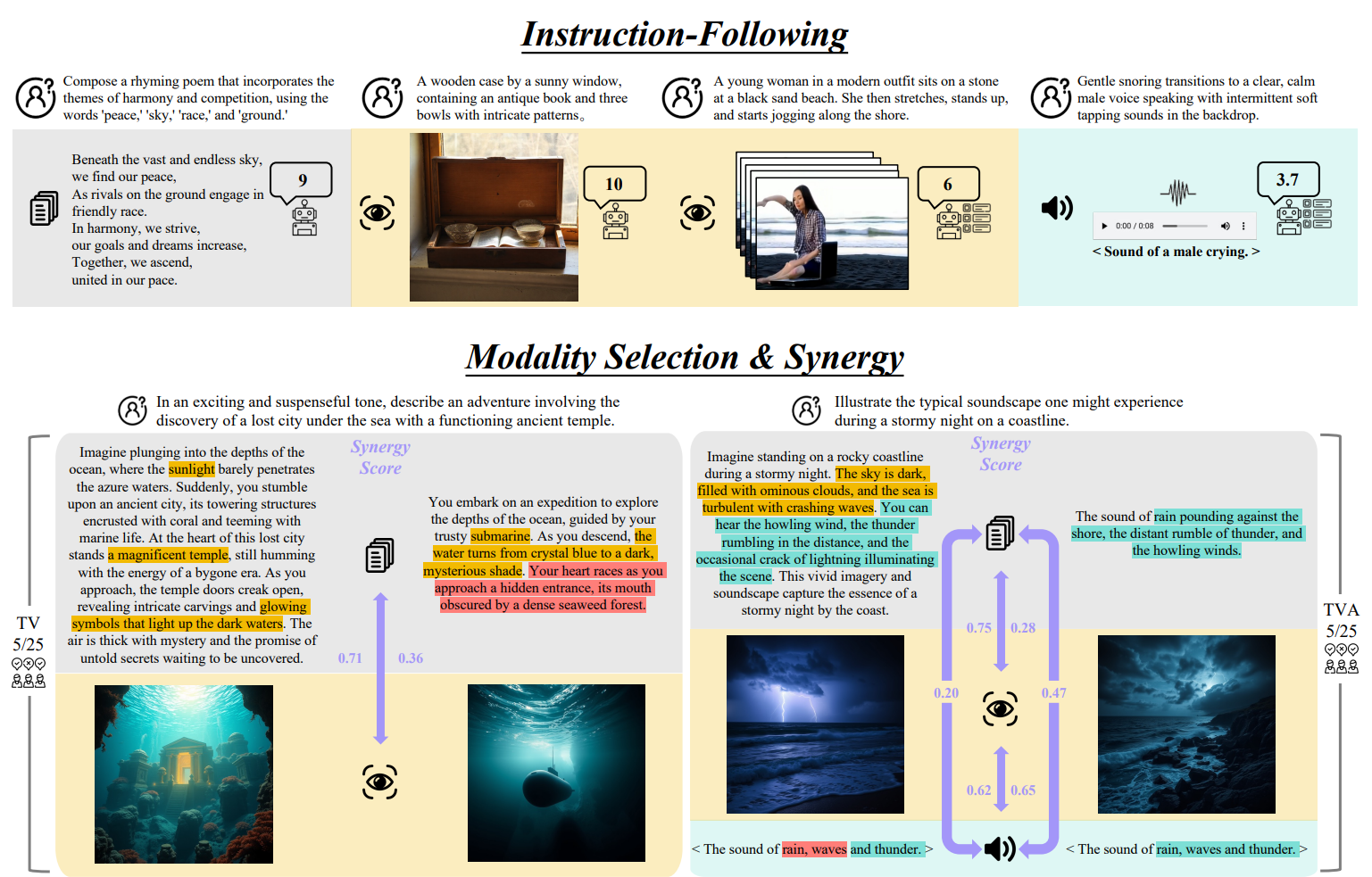
## Usage
```python
from transformers import AutoModel, AutoProcessor
model = AutoModel.from_pretrained("PKU-Alignment/AnyRewardModel", trust_remote_code=True)
processor = AutoProcessor.from_pretrained("PKU-Alignment/AnyRewardModel", trust_remote_code=True)
```
For Image-Audio Modality Synergy scoring:
```python
user_prompt: str = 'USER: {input}'
assistant_prompt: str = '\nASSISTANT:\n{modality}{text_response}'
def sigmoid(x):
return 1 / (1 + math.exp(-x))
def process_ia(prompt, image_path, audio_path):
image_pixel_values = processor(data_paths = image_path, modality="image").pixel_values
audio_pixel_values = processor(data_paths = audio_path, modality="audio").pixel_values
text_input = processor(
text = user_prompt.format(input = prompt) + \
assistant_prompt.format(modality = "