

Commit
·
8fea09c
1
Parent(s):
15dffa4
Add more information about training dataset
Browse files
README.md
CHANGED
|
@@ -125,24 +125,37 @@ model = transformers.AutoModelForCausalLM.from_pretrained(model_name,
|
|
| 125 |
...
|
| 126 |
)
|
| 127 |
```
|
| 128 |
-
where `revision` can be one of:
|
|
|
|
|
|
|
|
|
|
| 129 |
|
| 130 |
## Training Details
|
| 131 |
|
| 132 |
### Training Data
|
| 133 |
|
| 134 |
-
The training dataset
|
| 135 |
-
|
| 136 |
-
and described in ["The Lucie Training Dataset" (2024/
|
| 137 |
|
| 138 |
-
|
|
|
|
|
|
|
| 139 |
|
| 140 |
-
|
| 141 |
-
|
|
|
|
|
|
|
|
|
|
| 142 |
|
| 143 |
Lucie-7B is a causal decoder-only model trained on a causal language modeling task (i.e., predict the next token).
|
| 144 |
|
| 145 |
-
It was trained on 512 H100 80GB GPUs for about
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 146 |
|
| 147 |
#### Neural Network Architecture
|
| 148 |
|
|
|
|
| 125 |
...
|
| 126 |
)
|
| 127 |
```
|
| 128 |
+
where `revision` can be one of:
|
| 129 |
+
* ["`step0005000`"](https://huggingface.co/OpenLLM-France/Lucie-7B/tree/step0005000), ["`step0010000`"](https://huggingface.co/OpenLLM-France/Lucie-7B/tree/step0010000), ["`step0015000`"](https://huggingface.co/OpenLLM-France/Lucie-7B/tree/step0015000), ["`step0020000`"](https://huggingface.co/OpenLLM-France/Lucie-7B/tree/step0020000): each 5000 steps for the first pre-training steps.
|
| 130 |
+
* ["`step0025000`"](https://huggingface.co/OpenLLM-France/Lucie-7B/tree/step0025000), ["`step0050000`"](https://huggingface.co/OpenLLM-France/Lucie-7B/tree/step0050000), ["`step0075000`"](https://huggingface.co/OpenLLM-France/Lucie-7B/tree/step0075000), ["`step0100000`"](https://huggingface.co/OpenLLM-France/Lucie-7B/tree/step0100000), ..., ["`step0750000`"](https://huggingface.co/OpenLLM-France/Lucie-7B/tree/step0750000): each 25000 steps from 25k to 750k steps.
|
| 131 |
+
* ["`step0753851`"](https://huggingface.co/OpenLLM-France/Lucie-7B/tree/step0753851): last pre-training step before context extension and annealing.
|
| 132 |
|
| 133 |
## Training Details
|
| 134 |
|
| 135 |
### Training Data
|
| 136 |
|
| 137 |
+
The training dataset used for the pretraining of Lucie-7B is available
|
| 138 |
+
at [OpenLLM-France/Lucie-Training-Dataset](https://huggingface.co/datasets/OpenLLM-France/Lucie-Training-Dataset).
|
| 139 |
+
<!-- and described in ["The Lucie Training Dataset" (2024/12)](https://arxiv.org/abs/xxxx.xxxxx). -->
|
| 140 |
|
| 141 |
+
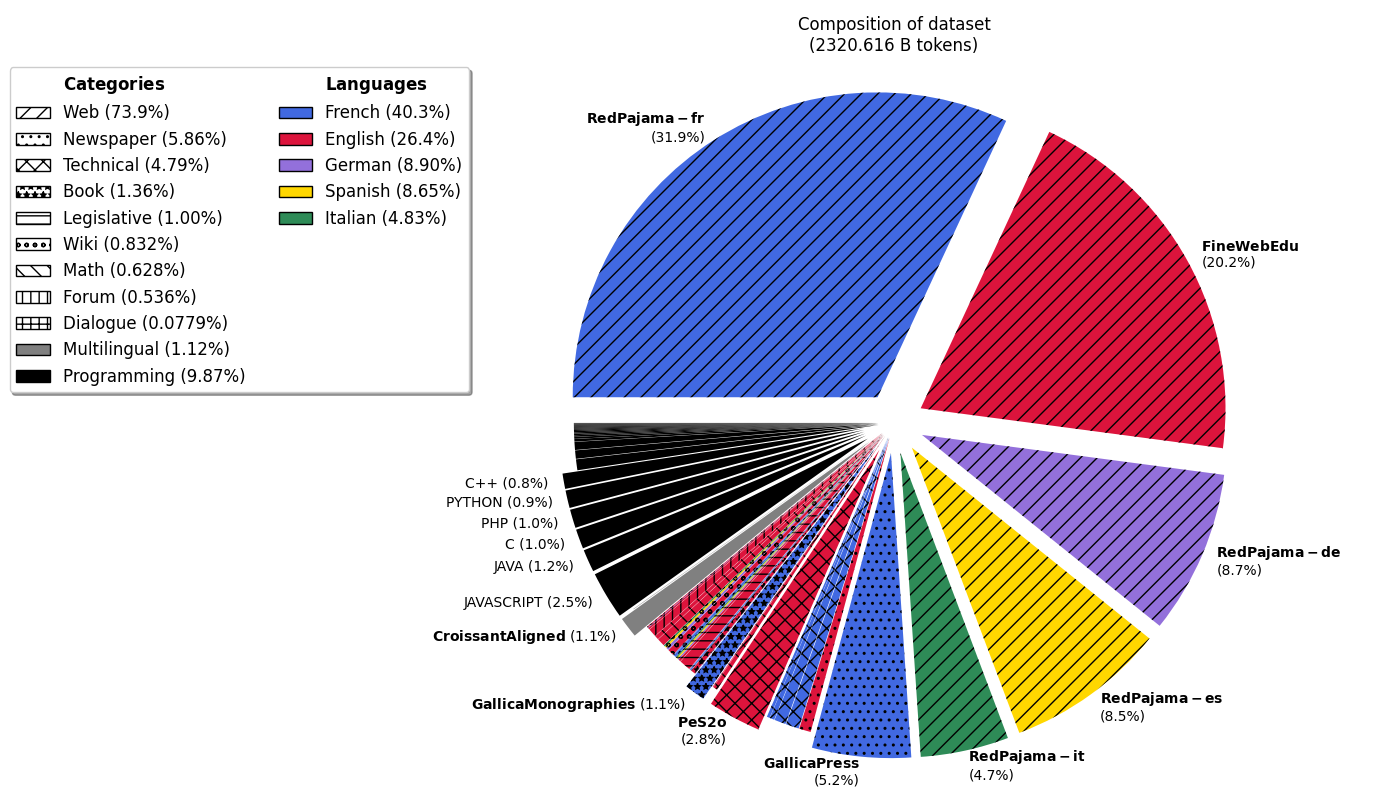
The initial composition of the training data is as follows:
|
| 142 |
+
|
| 143 |
+

|
| 144 |
|
| 145 |
+
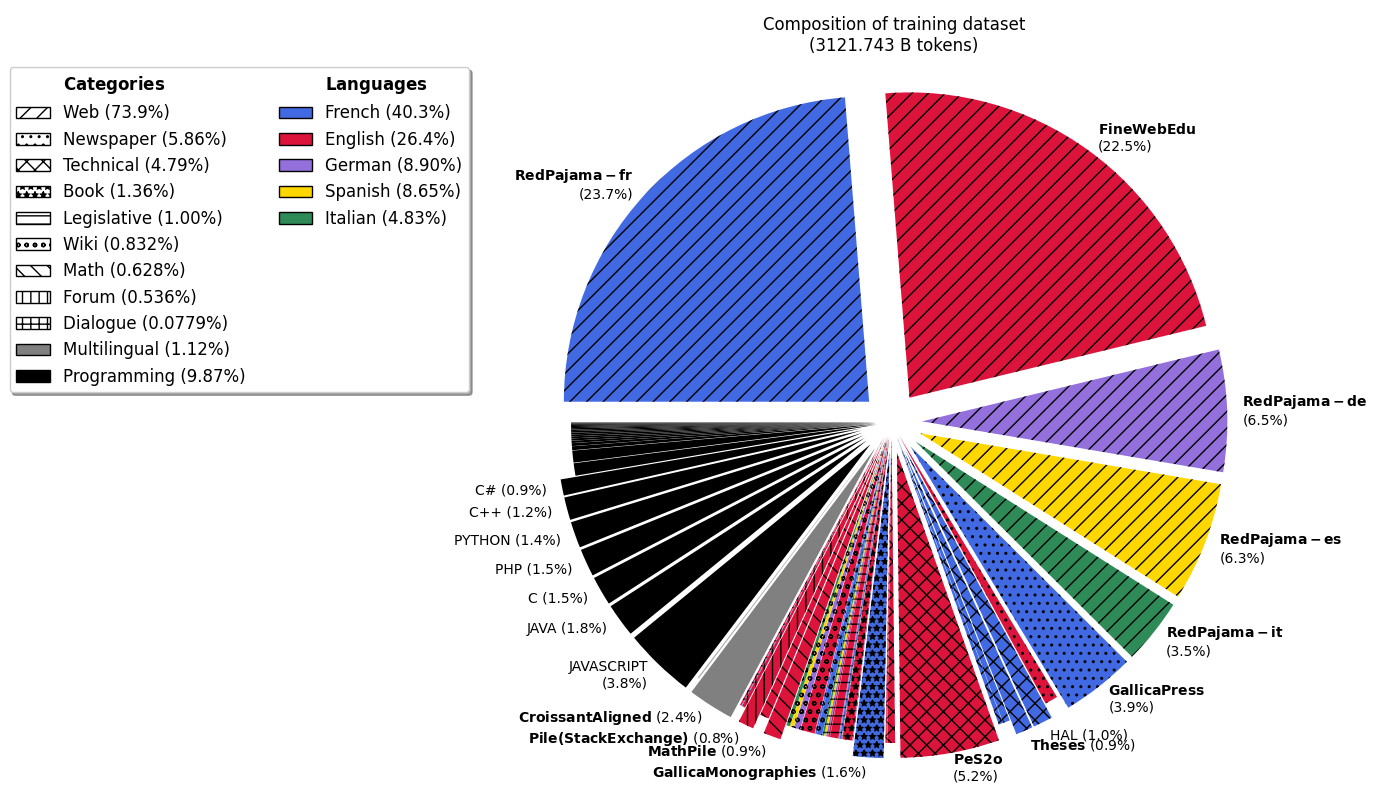
Some of the data was upsampled to balance the training data distribution, and the final composition is as follows:
|
| 146 |
+
|
| 147 |
+

|
| 148 |
+
|
| 149 |
+
### Training Procedure
|
| 150 |
|
| 151 |
Lucie-7B is a causal decoder-only model trained on a causal language modeling task (i.e., predict the next token).
|
| 152 |
|
| 153 |
+
It was pre-trained on 512 H100 80GB GPUs for about 550\,000 GPU hours on [Jean Zay supercomputer](http://www.idris.fr/eng/jean-zay/jean-zay-presentation-eng.html).
|
| 154 |
+
|
| 155 |
+
The training code is available at [https://github.com/OpenLLM-France/Lucie-Training](https://github.com/OpenLLM-France/Lucie-Training).
|
| 156 |
+
It is based on [this fork of Megatron-DeepSpeed](https://github.com/OpenLLM-France/Megatron-DeepSpeed).
|
| 157 |
+
|
| 158 |
+
Optimizer checkpoints are available at [OpenLLM-France/Lucie-7B-optimizer-states](https://huggingface.co/OpenLLM-France/Lucie-7B-optimizer-states).
|
| 159 |
|
| 160 |
#### Neural Network Architecture
|
| 161 |
|
figures/fig_dataset_composition.png
ADDED
|
figures/fig_dataset_composition_training.png
ADDED
|