

update README.md
Browse files- .gitattributes +1 -0
- README.md +229 -0
- assets/example_image1.jpg +0 -0
- assets/example_image2.jpg +0 -0
- assets/example_video.mp4 +3 -0
- assets/overview.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*.mp4 filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,232 @@
|
|
| 1 |
---
|
| 2 |
license: mit
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
+
base_model:
|
| 4 |
+
- OpenGVLab/InternViT-300M-448px
|
| 5 |
+
- internlm/internlm2_5-7b-chat
|
| 6 |
+
new_version: OpenGVLab/PVC-InternVL-8B
|
| 7 |
+
language:
|
| 8 |
+
- multilingual
|
| 9 |
+
pipeline_tag: image-text-to-text
|
| 10 |
+
library_name: transformers
|
| 11 |
+
tags:
|
| 12 |
+
- internvl
|
| 13 |
+
- video
|
| 14 |
+
- token compression
|
| 15 |
---
|
| 16 |
+
|
| 17 |
+
# PVC-InternVL2-8B
|
| 18 |
+
|
| 19 |
+
[\[📂 GitHub\]](https://github.com/OpenGVLab/PVC)
|
| 20 |
+
|
| 21 |
+
## Introduction
|
| 22 |
+
|
| 23 |
+
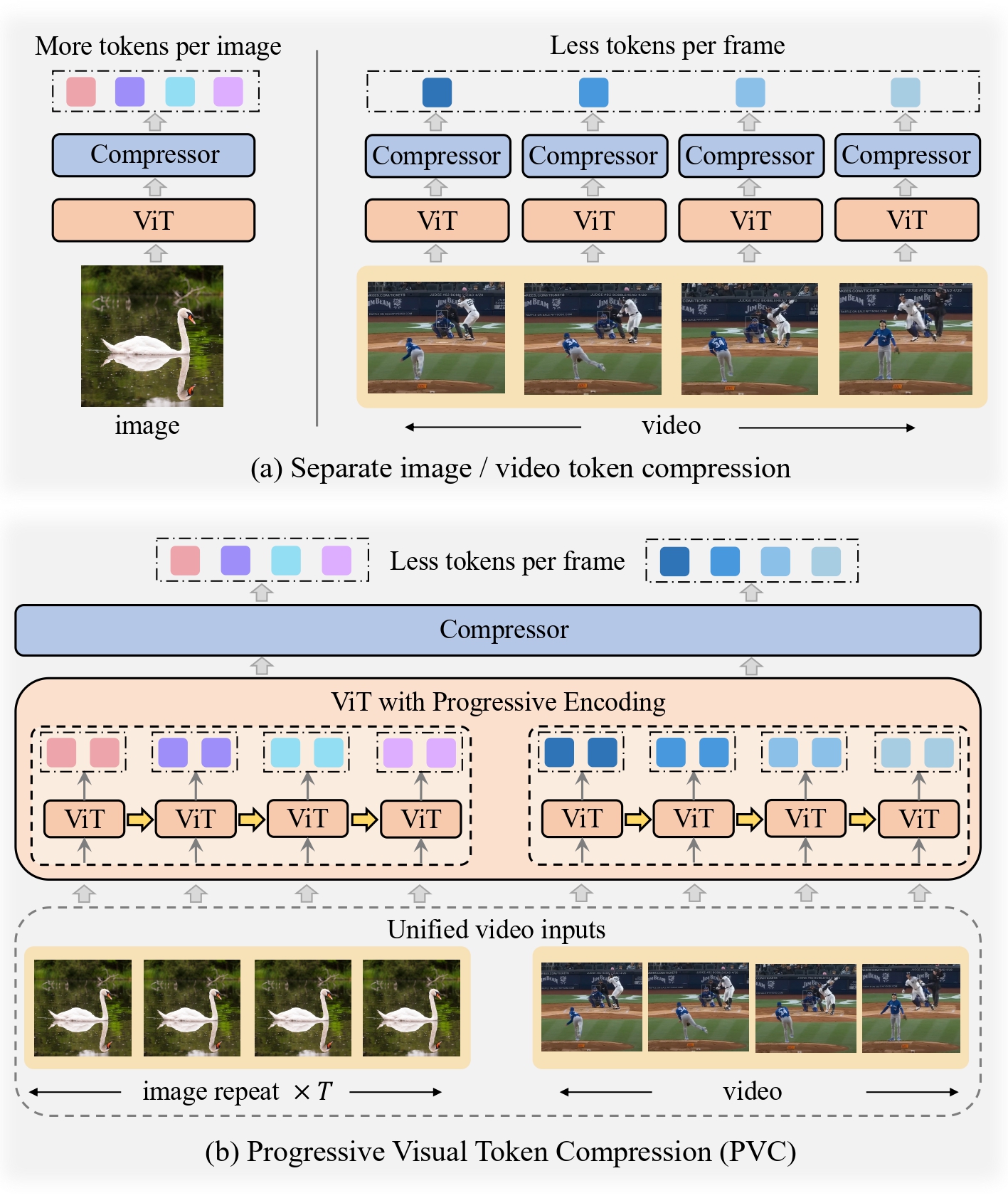
We introduce the **Progressive Visual Token Compression (PVC)** in large vision-language models (VLMs), which unifies the visual inputs as videos and progressively compresses vision tokens across video frames. Our PVC achieves:
|
| 24 |
+
|
| 25 |
+
* Preserve spatial details and temporal dynamics for both images and videos.
|
| 26 |
+
* Effectively reduce the tokens used for each video frame and image tile.
|
| 27 |
+
* SoTA performance on various video benchmarks, including long and fine-grained short video tasks.
|
| 28 |
+
* No performance loss on image benchmarks, especially on detail-sensitive tasks.
|
| 29 |
+
|
| 30 |
+
<div style="text-align: center;">
|
| 31 |
+
<img src="./assets/overview.png" width="70%"/>
|
| 32 |
+
</div>
|
| 33 |
+
|
| 34 |
+
## Results
|
| 35 |
+
|
| 36 |
+
Our implementation is based on the [InternVL2](https://github.com/OpenGVLab/InternVL) model, referred to as **PVC<sub>InternVL2</sub>**
|
| 37 |
+
|
| 38 |
+
### Video Understanding Benckmarks
|
| 39 |
+
|
| 40 |
+
| Model | LLaVA-OneVision-7B | Qwen2-VL-7B | InternVL2-8B | PVC<sub>InternVL2</sub>-8B |
|
| 41 |
+
| :--------------: | :--: | :--: | :--: | :--: |
|
| 42 |
+
| \# token/frame | 196 | - | 256 | 64 |
|
| 43 |
+
| | | | | |
|
| 44 |
+
| MVbench | 56.7 | 67.0 | 66.4 | 73.8 |
|
| 45 |
+
| VideoMME w/o-sub | 58.2 | 63.3 | 54.0 | 64.1 |
|
| 46 |
+
| VideoMME w-sub | 61.5 | 69.0 | 56.9 | 69.7 |
|
| 47 |
+
| MLVU | 64.7 | - | 52.0 | 72.4 |
|
| 48 |
+
| LongVideoBench | 56.5 | - | - | 59.2 |
|
| 49 |
+
| NextQA | 79.4 | - | - | 82.0 |
|
| 50 |
+
| Egoschema | 60.1 | 66.7 | 55.0 | 59.6 |
|
| 51 |
+
| PercepTest | 57.1 | 62.3 | 52.0 | 68.4 |
|
| 52 |
+
| AcNet-QA | 56.6 | - | - | 57.1 |
|
| 53 |
+
|
| 54 |
+
### Image Understanding Benckmarks
|
| 55 |
+
|
| 56 |
+
| Model | LLaVA-OneVision-7B | Qwen2-VL-7B | InternVL2-8B | PVC<sub>InternVL2</sub>-8B |
|
| 57 |
+
| :--------------------: | :--: | :--: | :--: | :--: |
|
| 58 |
+
| \# token/image tile | 729 | - | 256 | 64 |
|
| 59 |
+
| | | | | |
|
| 60 |
+
| AI2D<sub>test</sub> | 81.4 | 83.0 | 83.8 | 83.8 |
|
| 61 |
+
| ChartQA<sub>test</sub> | 80.0 | 83.0 | 83.3 | 84.1 |
|
| 62 |
+
| DocVQA<sub>test</sub> | 87.5 | 94.5 | 91.6 | 92.5 |
|
| 63 |
+
| InfoVQA<sub>test</sub> | 68.8 | 76.5 | 74.8 | 75.0 |
|
| 64 |
+
| SQA<sub>test</sub> | 96.0 | - | 97.1 | 97.7 |
|
| 65 |
+
| TextVQA<sub>val</sub> | - | 84.3 | 77.4 | 80.0 |
|
| 66 |
+
| MMB<sub>en-test</sub> | - | 83.0 | 81.7 | 83.9 |
|
| 67 |
+
| MME<sub>sum</sub> | 1998 | 2327 | 2210 | 2282 |
|
| 68 |
+
| MMMU<sub>val</sub> | 48.8 | 54.1 | 49.3 | 50.9 |
|
| 69 |
+
| SEED<sub>I</sub> | 75.4 | - | 76.2 | 77.2 |
|
| 70 |
+
| OCRBench | - | 866 | 794 | 807 |
|
| 71 |
+
|
| 72 |
+
## Quick Start
|
| 73 |
+
|
| 74 |
+
```python
|
| 75 |
+
import numpy as np
|
| 76 |
+
import torch
|
| 77 |
+
import torchvision.transforms as T
|
| 78 |
+
from decord import VideoReader, cpu
|
| 79 |
+
from PIL import Image
|
| 80 |
+
from torchvision.transforms.functional import InterpolationMode
|
| 81 |
+
from transformers import AutoModel, AutoTokenizer
|
| 82 |
+
|
| 83 |
+
IMAGENET_MEAN = (0.485, 0.456, 0.406)
|
| 84 |
+
IMAGENET_STD = (0.229, 0.224, 0.225)
|
| 85 |
+
|
| 86 |
+
def build_transform(input_size):
|
| 87 |
+
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
|
| 88 |
+
transform = T.Compose([
|
| 89 |
+
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
|
| 90 |
+
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
|
| 91 |
+
T.ToTensor(),
|
| 92 |
+
T.Normalize(mean=MEAN, std=STD)
|
| 93 |
+
])
|
| 94 |
+
return transform
|
| 95 |
+
|
| 96 |
+
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
|
| 97 |
+
best_ratio_diff = float('inf')
|
| 98 |
+
best_ratio = (1, 1)
|
| 99 |
+
area = width * height
|
| 100 |
+
for ratio in target_ratios:
|
| 101 |
+
target_aspect_ratio = ratio[0] / ratio[1]
|
| 102 |
+
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
|
| 103 |
+
if ratio_diff < best_ratio_diff:
|
| 104 |
+
best_ratio_diff = ratio_diff
|
| 105 |
+
best_ratio = ratio
|
| 106 |
+
elif ratio_diff == best_ratio_diff:
|
| 107 |
+
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
|
| 108 |
+
best_ratio = ratio
|
| 109 |
+
return best_ratio
|
| 110 |
+
|
| 111 |
+
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
|
| 112 |
+
orig_width, orig_height = image.size
|
| 113 |
+
aspect_ratio = orig_width / orig_height
|
| 114 |
+
|
| 115 |
+
# calculate the existing image aspect ratio
|
| 116 |
+
target_ratios = set(
|
| 117 |
+
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
|
| 118 |
+
i * j <= max_num and i * j >= min_num)
|
| 119 |
+
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
|
| 120 |
+
|
| 121 |
+
# find the closest aspect ratio to the target
|
| 122 |
+
target_aspect_ratio = find_closest_aspect_ratio(
|
| 123 |
+
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
|
| 124 |
+
|
| 125 |
+
# calculate the target width and height
|
| 126 |
+
target_width = image_size * target_aspect_ratio[0]
|
| 127 |
+
target_height = image_size * target_aspect_ratio[1]
|
| 128 |
+
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
|
| 129 |
+
|
| 130 |
+
# resize the image
|
| 131 |
+
resized_img = image.resize((target_width, target_height))
|
| 132 |
+
processed_images = []
|
| 133 |
+
for i in range(blocks):
|
| 134 |
+
box = (
|
| 135 |
+
(i % (target_width // image_size)) * image_size,
|
| 136 |
+
(i // (target_width // image_size)) * image_size,
|
| 137 |
+
((i % (target_width // image_size)) + 1) * image_size,
|
| 138 |
+
((i // (target_width // image_size)) + 1) * image_size
|
| 139 |
+
)
|
| 140 |
+
# split the image
|
| 141 |
+
split_img = resized_img.crop(box)
|
| 142 |
+
processed_images.append(split_img)
|
| 143 |
+
assert len(processed_images) == blocks
|
| 144 |
+
if use_thumbnail and len(processed_images) != 1:
|
| 145 |
+
thumbnail_img = image.resize((image_size, image_size))
|
| 146 |
+
processed_images.append(thumbnail_img)
|
| 147 |
+
return processed_images
|
| 148 |
+
|
| 149 |
+
def load_image(image_file, input_size=448, max_num=12):
|
| 150 |
+
image = Image.open(image_file).convert('RGB')
|
| 151 |
+
transform = build_transform(input_size=input_size)
|
| 152 |
+
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
|
| 153 |
+
pixel_values = [transform(image) for image in images]
|
| 154 |
+
pixel_values = torch.stack(pixel_values)
|
| 155 |
+
return pixel_values
|
| 156 |
+
|
| 157 |
+
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
|
| 158 |
+
if bound:
|
| 159 |
+
start, end = bound[0], bound[1]
|
| 160 |
+
else:
|
| 161 |
+
start, end = -100000, 100000
|
| 162 |
+
start_idx = max(first_idx, round(start * fps))
|
| 163 |
+
end_idx = min(round(end * fps), max_frame)
|
| 164 |
+
seg_size = float(end_idx - start_idx) / num_segments
|
| 165 |
+
frame_indices = np.array([
|
| 166 |
+
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
|
| 167 |
+
for idx in range(num_segments)
|
| 168 |
+
])
|
| 169 |
+
return frame_indices
|
| 170 |
+
|
| 171 |
+
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
|
| 172 |
+
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
|
| 173 |
+
max_frame = len(vr) - 1
|
| 174 |
+
fps = float(vr.get_avg_fps())
|
| 175 |
+
|
| 176 |
+
pixel_values_list, num_patches_list = [], []
|
| 177 |
+
transform = build_transform(input_size=input_size)
|
| 178 |
+
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
|
| 179 |
+
for frame_index in frame_indices:
|
| 180 |
+
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
|
| 181 |
+
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
|
| 182 |
+
pixel_values = [transform(tile) for tile in img]
|
| 183 |
+
pixel_values = torch.stack(pixel_values)
|
| 184 |
+
num_patches_list.append(pixel_values.shape[0])
|
| 185 |
+
pixel_values_list.append(pixel_values)
|
| 186 |
+
pixel_values = torch.cat(pixel_values_list)
|
| 187 |
+
return pixel_values, num_patches_list
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
path = 'OpenGVLab/PVC-InternVL2-8B'
|
| 191 |
+
model = AutoModel.from_pretrained(
|
| 192 |
+
path,
|
| 193 |
+
torch_dtype=torch.bfloat16,
|
| 194 |
+
low_cpu_mem_usage=True,
|
| 195 |
+
trust_remote_code=True).eval().cuda()
|
| 196 |
+
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
|
| 197 |
+
generation_config = dict(max_new_tokens=1024, do_sample=True)
|
| 198 |
+
|
| 199 |
+
# single-image conversation
|
| 200 |
+
pixel_values = load_image('./assets/example_image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 201 |
+
data_flag = torch.tensor([1], dtype=torch.long).cuda()
|
| 202 |
+
|
| 203 |
+
question = '<image>\nWhat is in the image?'
|
| 204 |
+
response = model.chat(tokenizer, pixel_values, question, generation_config, data_flag=data_flag)
|
| 205 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 206 |
+
|
| 207 |
+
# multi-image conversation
|
| 208 |
+
pixel_values1 = load_image('./assets/example_image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 209 |
+
pixel_values2 = load_image('./assets/example_image2.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 210 |
+
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
|
| 211 |
+
data_flag = torch.tensor([2], dtype=torch.long).cuda()
|
| 212 |
+
num_patches_list = [pixel_values1.shape[0], pixel_values2.shape[0]]
|
| 213 |
+
|
| 214 |
+
question = 'Image-1: <image>\nImage-2: <image>\nWhat are the similarities and differences between these two images.'
|
| 215 |
+
response = model.chat(tokenizer, pixel_values, question, generation_config, data_flag=data_flag, num_patches_list=num_patches_list)
|
| 216 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 217 |
+
|
| 218 |
+
# video conversation
|
| 219 |
+
pixel_values, num_patches_list = load_video('./assets/example_video.mp4', num_segments=64, max_num=1)
|
| 220 |
+
pixel_values = pixel_values.to(torch.bfloat16).cuda()
|
| 221 |
+
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
|
| 222 |
+
# Frame1: <image>\nFrame2: <image>\n...\nFrameN: <image>\n{question}
|
| 223 |
+
data_flag = torch.tensor([3], dtype=torch.long).cuda()
|
| 224 |
+
|
| 225 |
+
question = video_prefix + 'Describe this video in detail.'
|
| 226 |
+
response = model.chat(tokenizer, pixel_values, question, generation_config, data_flag=data_flag, num_patches_list=num_patches_list)
|
| 227 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 228 |
+
```
|
| 229 |
+
|
| 230 |
+
## License
|
| 231 |
+
|
| 232 |
+
This project is released under the MIT license. Parts of this project contain code and models from other sources, which are subject to their respective licenses.
|
assets/example_image1.jpg
ADDED

|
assets/example_image2.jpg
ADDED

|
assets/example_video.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d921c07bb97224d65a37801541d246067f0d506f08723ffa1ad85c217907ccb8
|
| 3 |
+
size 1867237
|
assets/overview.png
ADDED
|