
Update README.md
Browse files
README.md
CHANGED
|
@@ -52,6 +52,8 @@ output = zeroshot_classifier(text, classes_verbalised, hypothesis_template=hypot
|
|
| 52 |
print(output)
|
| 53 |
```
|
| 54 |
|
|
|
|
|
|
|
| 55 |
### Details on data and training
|
| 56 |
|
| 57 |
Reproduction code is available here, in the `v2_synthetic_data` directory: https://github.com/MoritzLaurer/zeroshot-classifier/tree/main
|
|
@@ -59,61 +61,56 @@ Reproduction code is available here, in the `v2_synthetic_data` directory: https
|
|
| 59 |
|
| 60 |
## Metrics
|
| 61 |
|
| 62 |
-
|
| 63 |
-
`
|
| 64 |
-
The
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
|
| 75 |
-
|
|
| 76 |
-
|
|
| 77 |
-
|
|
| 78 |
-
|
|
| 79 |
-
|
|
| 80 |
-
|
|
| 81 |
-
|
|
| 82 |
-
|
|
| 83 |
-
|
|
| 84 |
-
|
|
| 85 |
-
|
|
| 86 |
-
|
|
| 87 |
-
|
|
| 88 |
-
|
|
| 89 |
-
|
|
| 90 |
-
|
|
| 91 |
-
|
|
| 92 |
-
|
|
| 93 |
-
|
|
| 94 |
-
|
|
| 95 |
-
|
|
| 96 |
-
|
|
| 97 |
-
|
|
| 98 |
-
|
|
| 99 |
-
|
|
| 100 |
-
|
|
| 101 |
-
|
|
| 102 |
-
|
|
| 103 |
-
|
| 104 |
-
| fevernli (2) | 89.3 | nan | 89.5 |
|
| 105 |
-
| anli_r1 (2) | 87.9 | nan | 87.3 |
|
| 106 |
-
| anli_r2 (2) | 76.3 | nan | 78 |
|
| 107 |
-
| anli_r3 (2) | 73.6 | nan | 74.1 |
|
| 108 |
-
| wanli (2) | 82.8 | nan | 82.7 |
|
| 109 |
-
| lingnli (2) | 90.2 | nan | 89.6 |
|
| 110 |
|
| 111 |
|
| 112 |
|
| 113 |
## Limitations and bias
|
| 114 |
The model can only do text classification tasks.
|
| 115 |
|
| 116 |
-
|
|
|
|
| 117 |
|
| 118 |
|
| 119 |
## License
|
|
@@ -147,9 +144,7 @@ If you have questions or ideas for cooperation, contact me at moritz{at}huggingf
|
|
| 147 |
|
| 148 |
|
| 149 |
|
| 150 |
-
###
|
| 151 |
-
The hypotheses in the tables below were used to fine-tune the model.
|
| 152 |
-
Inspecting them can help users get a feeling for which type of hypotheses and tasks the model was trained on.
|
| 153 |
You can formulate your own hypotheses by changing the `hypothesis_template` of the zeroshot pipeline. For example:
|
| 154 |
|
| 155 |
```python
|
|
@@ -157,7 +152,7 @@ from transformers import pipeline
|
|
| 157 |
text = "Angela Merkel is a politician in Germany and leader of the CDU"
|
| 158 |
hypothesis_template = "Merkel is the leader of the party: {}"
|
| 159 |
classes_verbalized = ["CDU", "SPD", "Greens"]
|
| 160 |
-
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-
|
| 161 |
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
|
| 162 |
print(output)
|
| 163 |
```
|
|
|
|
| 52 |
print(output)
|
| 53 |
```
|
| 54 |
|
| 55 |
+
`multi_label=False` forces the model to decide on only one class. `multi_label=True` enables the model to choose multiple classes.
|
| 56 |
+
|
| 57 |
### Details on data and training
|
| 58 |
|
| 59 |
Reproduction code is available here, in the `v2_synthetic_data` directory: https://github.com/MoritzLaurer/zeroshot-classifier/tree/main
|
|
|
|
| 61 |
|
| 62 |
## Metrics
|
| 63 |
|
| 64 |
+
The model was evaluated on 28 different text classification tasks with the [balanced_accuracy](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.balanced_accuracy_score.html) metric.
|
| 65 |
+
The main reference point is `facebook/bart-large-mnli` which is at the time of writing (27.03.24) the most used commercially-friendly 0-shot classifier.
|
| 66 |
+
The different `...zeroshot-v2.0` models were all trained with the same data and the only difference the the underlying foundation model.
|
| 67 |
+
|
| 68 |
+
Note that my `...zeroshot-v1.1` models (e.g. [deberta-v3-base-zeroshot-v1.1-all-33](https://huggingface.co/MoritzLaurer/deberta-v3-base-zeroshot-v1.1-all-33))
|
| 69 |
+
perform better on these 28 datasets, but they are trained on several datasets with non-commercial licenses.
|
| 70 |
+
For commercial users, I therefore recommend using the v2.0 model and non-commercial users might get better performance with the v1.1 models.
|
| 71 |
+
|
| 72 |
+
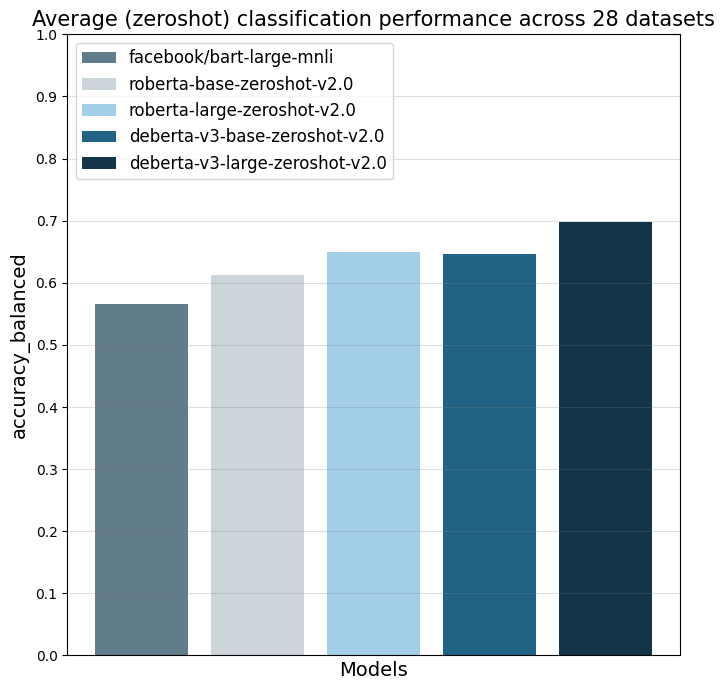
|
| 73 |
+
|
| 74 |
+
| | facebook/bart-large-mnli | roberta-base-zeroshot-v2.0 | roberta-large-zeroshot-v2.0 | deberta-v3-base-zeroshot-v2.0 | deberta-v3-large-zeroshot-v2.0 |
|
| 75 |
+
|:---------------------------|---------------------------:|-----------------------------:|------------------------------:|--------------------------------:|---------------------------------:|
|
| 76 |
+
| all datasets mean | 0.566 | 0.612 | 0.65 | 0.647 | 0.697 |
|
| 77 |
+
| amazonpolarity (2) | 0.937 | 0.924 | 0.951 | 0.937 | 0.952 |
|
| 78 |
+
| imdb (2) | 0.892 | 0.871 | 0.904 | 0.893 | 0.923 |
|
| 79 |
+
| appreviews (2) | 0.934 | 0.913 | 0.937 | 0.938 | 0.943 |
|
| 80 |
+
| yelpreviews (2) | 0.948 | 0.953 | 0.977 | 0.979 | 0.988 |
|
| 81 |
+
| rottentomatoes (2) | 0.831 | 0.803 | 0.841 | 0.841 | 0.87 |
|
| 82 |
+
| emotiondair (6) | 0.495 | 0.523 | 0.514 | 0.487 | 0.495 |
|
| 83 |
+
| emocontext (4) | 0.605 | 0.535 | 0.609 | 0.566 | 0.687 |
|
| 84 |
+
| empathetic (32) | 0.366 | 0.386 | 0.417 | 0.388 | 0.455 |
|
| 85 |
+
| financialphrasebank (3) | 0.673 | 0.521 | 0.445 | 0.678 | 0.656 |
|
| 86 |
+
| banking77 (72) | 0.327 | 0.138 | 0.297 | 0.433 | 0.542 |
|
| 87 |
+
| massive (59) | 0.454 | 0.481 | 0.599 | 0.533 | 0.599 |
|
| 88 |
+
| wikitoxic_toxicaggreg (2) | 0.609 | 0.752 | 0.768 | 0.752 | 0.751 |
|
| 89 |
+
| wikitoxic_obscene (2) | 0.728 | 0.818 | 0.854 | 0.853 | 0.884 |
|
| 90 |
+
| wikitoxic_threat (2) | 0.531 | 0.796 | 0.874 | 0.861 | 0.876 |
|
| 91 |
+
| wikitoxic_insult (2) | 0.514 | 0.738 | 0.802 | 0.768 | 0.778 |
|
| 92 |
+
| wikitoxic_identityhate (2) | 0.567 | 0.776 | 0.801 | 0.774 | 0.801 |
|
| 93 |
+
| hateoffensive (3) | 0.41 | 0.497 | 0.484 | 0.539 | 0.634 |
|
| 94 |
+
| hatexplain (3) | 0.373 | 0.423 | 0.385 | 0.441 | 0.446 |
|
| 95 |
+
| biasframes_offensive (2) | 0.499 | 0.571 | 0.587 | 0.546 | 0.648 |
|
| 96 |
+
| biasframes_sex (2) | 0.503 | 0.703 | 0.845 | 0.794 | 0.877 |
|
| 97 |
+
| biasframes_intent (2) | 0.635 | 0.541 | 0.635 | 0.562 | 0.696 |
|
| 98 |
+
| agnews (4) | 0.722 | 0.765 | 0.764 | 0.694 | 0.824 |
|
| 99 |
+
| yahootopics (10) | 0.303 | 0.55 | 0.621 | 0.575 | 0.605 |
|
| 100 |
+
| trueteacher (2) | 0.492 | 0.488 | 0.501 | 0.505 | 0.515 |
|
| 101 |
+
| spam (2) | 0.523 | 0.537 | 0.528 | 0.531 | 0.698 |
|
| 102 |
+
| wellformedquery (2) | 0.528 | 0.5 | 0.5 | 0.5 | 0.476 |
|
| 103 |
+
| manifesto (56) | 0.088 | 0.111 | 0.206 | 0.198 | 0.277 |
|
| 104 |
+
| capsotu (21) | 0.375 | 0.525 | 0.558 | 0.543 | 0.631 |
|
| 105 |
+
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 106 |
|
| 107 |
|
| 108 |
|
| 109 |
## Limitations and bias
|
| 110 |
The model can only do text classification tasks.
|
| 111 |
|
| 112 |
+
Biases can come from the underlying foundation model, the human NLI training data and the synthetic data generated by Mixtral.
|
| 113 |
+
|
| 114 |
|
| 115 |
|
| 116 |
## License
|
|
|
|
| 144 |
|
| 145 |
|
| 146 |
|
| 147 |
+
### Flexible usage and "prompting"
|
|
|
|
|
|
|
| 148 |
You can formulate your own hypotheses by changing the `hypothesis_template` of the zeroshot pipeline. For example:
|
| 149 |
|
| 150 |
```python
|
|
|
|
| 152 |
text = "Angela Merkel is a politician in Germany and leader of the CDU"
|
| 153 |
hypothesis_template = "Merkel is the leader of the party: {}"
|
| 154 |
classes_verbalized = ["CDU", "SPD", "Greens"]
|
| 155 |
+
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-base-zeroshot-v2.0")
|
| 156 |
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
|
| 157 |
print(output)
|
| 158 |
```
|