---
license: mit
base_model:
- numind/NuExtract-1.5-tiny
pipeline_tag: text-generation
tags:
- openvino
library_name: OpenVINO
language:
- multilingual
---

# NuExtract-tiny-v1.5 by NuMind 🔥 OpenVINO
NuExtract-tiny-v1.5 is a fine-tuning of [Qwen/Qwen2.5-0.5B](https://huggingface.co/Qwen/Qwen2.5-0.5B), trained on a private high-quality dataset for structured information extraction. It supports long documents and several languages (English, French, Spanish, German, Portuguese, and Italian).
To use the model, provide an input text and a JSON template describing the information you need to extract.
Note: This model is trained to prioritize pure extraction, so in most cases all text generated by the model is present as is in the original text.
We also provide a 3.8B version which is based on Phi-3.5-mini-instruct: [NuExtract-v1.5](https://huggingface.co/numind/NuExtract-v1.5)
Check out the [blog post](https://numind.ai/blog/nuextract-1-5---multilingual-infinite-context-still-small-and-better-than-gpt-4o).
Try the 3.8B model here: [Playground](https://huggingface.co/spaces/numind/NuExtract-v1.5)
⚠️ We recommend using NuExtract with a temperature at or very close to 0. Some inference frameworks, such as Ollama, use a default of 0.7 which is not well suited to pure extraction tasks.
## This is the OpenVINO IR format of the model, quantized in int8
The model was created with the Optimum-Intel libray cli-command
#### Dependencies required to create the model
There is an open clash in dependencies versions between optiumum-intel and openvino-genai
> ⚠️ Exporting tokenizers to OpenVINO is not supported for tokenizers version > 0.19 and openvino version <= 2024.4. Please downgrade to tokenizers version <= 0.19 to export tokenizers to OpenVINO.
So for the model conversion the only dependency you need is
```
pip install -U "openvino>=2024.3.0" "openvino-genai"
pip install "torch>=2.1" "nncf>=2.7" "transformers>=4.40.0" "onnx<1.16.2" "optimum>=1.16.1" "accelerate" "datasets>=2.14.6" "git+https://github.com/huggingface/optimum-intel.git" --extra-index-url https://download.pytorch.org/whl/cpu
```
The instructions are from the amazing [OpenVINO notebooks](https://docs.openvino.ai/2024/notebooks/llm-question-answering-with-output.html#prerequisites)
vanilla pip install will create clashes among dependencies/versions
This command will install, among others:
```
tokenizers==0.20.3
torch==2.5.1+cpu
transformers==4.46.3
nncf==2.14.0
numpy==2.1.3
onnx==1.16.1
openvino==2024.5.0
openvino-genai==2024.5.0.0
openvino-telemetry==2024.5.0
openvino-tokenizers==2024.5.0.0
optimum==1.23.3
optimum-intel @ git+https://github.com/huggingface/optimum-intel.git@c454b0000279ac9801302d726fbbbc1152733315
```
#### How to quantized the original model
After the previous step you are enabled to run the following command (considering that you downloaded all the model weights and files into a subfolder called `NuExtract-1.5-tiny` from the [official model repository](https://huggingface.co/numind/NuExtract-v1.5))
```bash
optimum-cli export openvino --model NuExtract-1.5-tiny --task text-generation-with-past --trust-remote-code --weight-format int8 ov_NuExtract-1.5-tiny
```
this will start the process and produce the following messages, without any fatal error

#### Dependencies required to run the model with `openvino-genai`
If you simply need to run already converted models into OpenVINO IR format, you need to install only openvino-genai
```
pip install openvino-genai==2024.5.0
```
## How to use the model with openvino-genai
considering you also have python-rich installed (that is coming together with optimum-intel... otherwise `pip install rich`)
```python
"""
followed official tutorial
https://docs.openvino.ai/2024/notebooks/llm-question-answering-with-output.html
"""
# MAIN IMPORTS
import warnings
warnings.filterwarnings(action='ignore')
import datetime
from rich.console import Console
from rich.panel import Panel
import openvino_genai as ov_genai
# SETTING CONSOLE WIDTH
console = Console(width=80)
# LOADING THE MODEL
console.print('Loading the model...', end='')
model_dir = 'ov_NuExtract-1.5-tiny'
pipe = ov_genai.LLMPipeline(model_dir, 'CPU')
console.print('✅ done')
console.print('Ready for generation')
# PROMPT FORMATTING
jsontemplate = """{
"Model": {
"Name": "",
"Number of parameters": "",
"Number of max token": "",
"Architecture": []
},
"Usage": {
"Use case": [],
"Licence": ""
}
}"""
text = """We introduce Mistral 7B, a 7–billion-parameter language model engineered for
superior performance and efficiency. Mistral 7B outperforms the best open 13B
model (Llama 2) across all evaluated benchmarks, and the best released 34B
model (Llama 1) in reasoning, mathematics, and code generation. Our model
leverages grouped-query attention (GQA) for faster inference, coupled with sliding
window attention (SWA) to effectively handle sequences of arbitrary length with a
reduced inference cost. We also provide a model fine-tuned to follow instructions,
Mistral 7B – Instruct, that surpasses Llama 2 13B – chat model both on human and
automated benchmarks. Our models are released under the Apache 2.0 license.
Code:
Webpage: """
prompt = f"""<|input|>\n### Template:
{jsontemplate}
### Text:
{text}
<|output|>
"""
# START PIPELINE setting eos_token_id = 151643
start = datetime.datetime.now()
with console.status("Generating json reply", spinner='dots8',):
output = pipe.generate(prompt, temperature=0.2,
do_sample=True,
max_new_tokens=500,
repetition_penalty=1.178,
eos_token_id = 151643)
delta = datetime.datetime.now() - start
# PRINT THE OUTPUT
console.print(output)
console.rule()
console.print(f'Generated in {delta}')
```

## An awesome Streamlit+OpenVINO interface
you can find the code in [my official GitHub repository](https://github.com/fabiomatricardi/NuExtract-1.5-openvino)
[](https://github.com/openvinotoolkit/awesome-openvino)
You can clone the repo and use the downloaded files from this Hugging Face Model
Running the streamlit app will give this:

---
## Benchmark
Zero-shot performance (English):
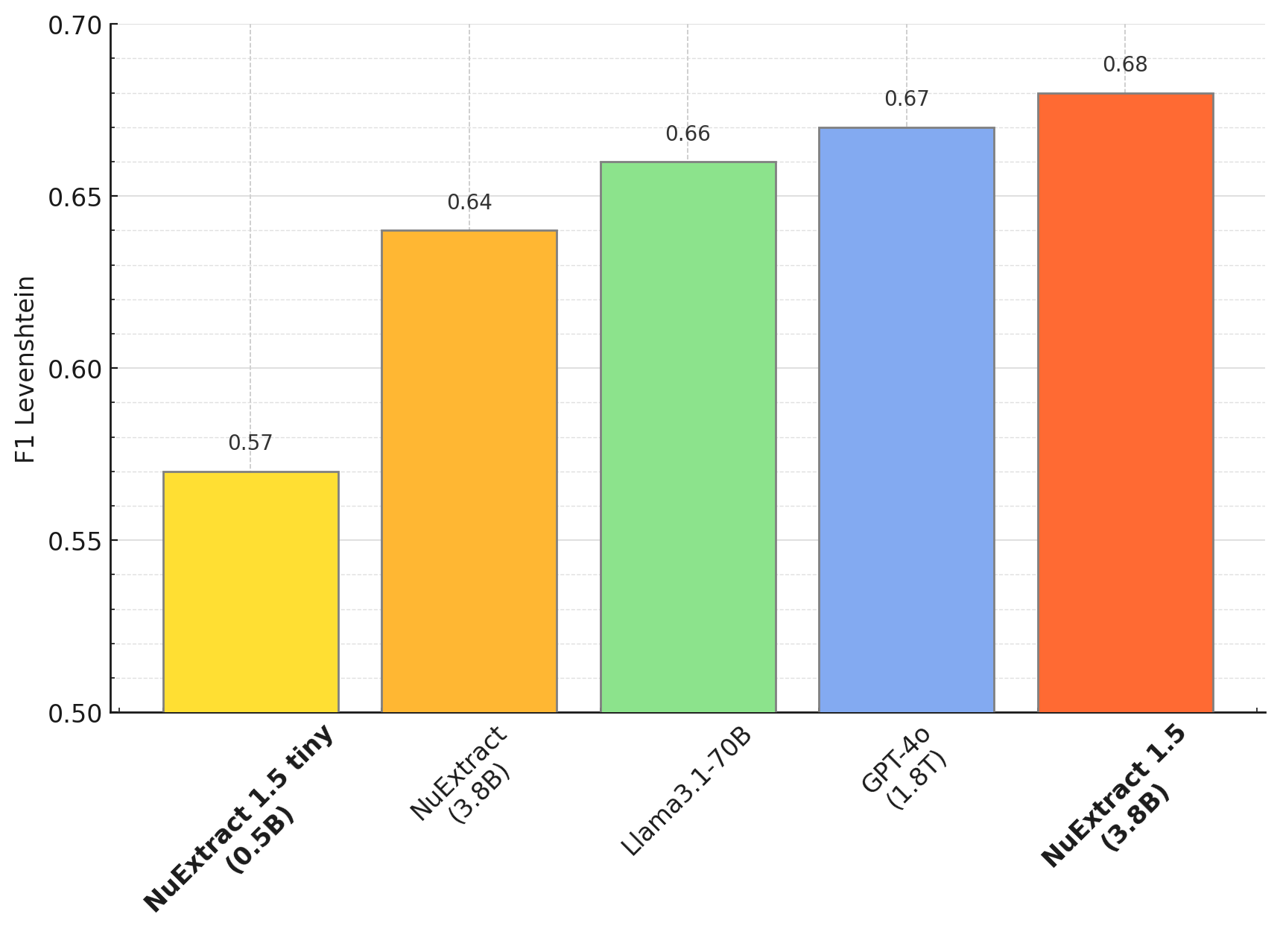
Few-shot fine-tuning:
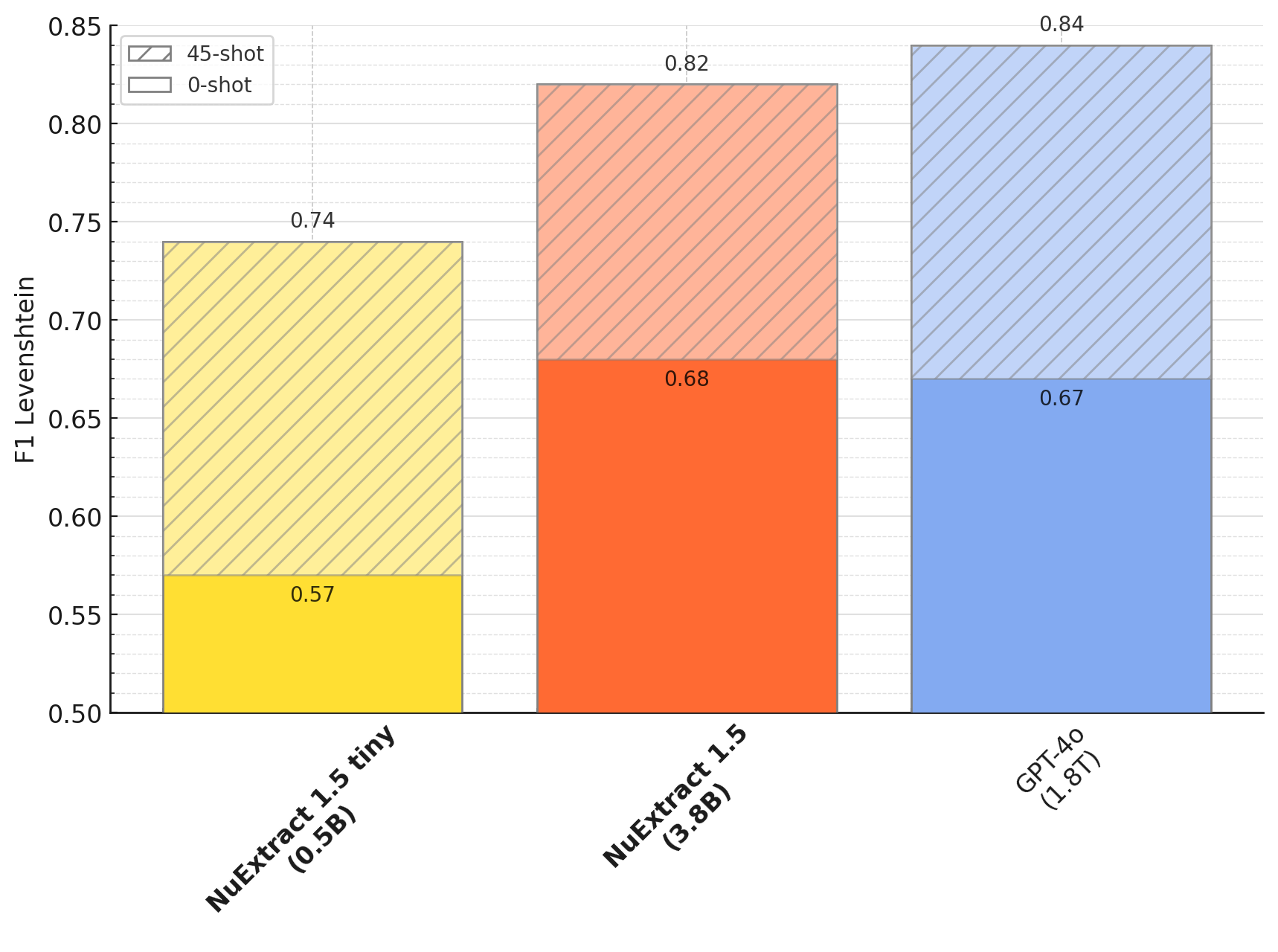
---
## Usage (copied from original model)
To use the model:
```python
import json
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def predict_NuExtract(model, tokenizer, texts, template, batch_size=1, max_length=10_000, max_new_tokens=4_000):
template = json.dumps(json.loads(template), indent=4)
prompts = [f"""<|input|>\n### Template:\n{template}\n### Text:\n{text}\n\n<|output|>""" for text in texts]
outputs = []
with torch.no_grad():
for i in range(0, len(prompts), batch_size):
batch_prompts = prompts[i:i+batch_size]
batch_encodings = tokenizer(batch_prompts, return_tensors="pt", truncation=True, padding=True, max_length=max_length).to(model.device)
pred_ids = model.generate(**batch_encodings, max_new_tokens=max_new_tokens)
outputs += tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
return [output.split("<|output|>")[1] for output in outputs]
model_name = "numind/NuExtract-tiny-v1.5"
device = "cuda"
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, trust_remote_code=True).to(device).eval()
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
text = """We introduce Mistral 7B, a 7–billion-parameter language model engineered for
superior performance and efficiency. Mistral 7B outperforms the best open 13B
model (Llama 2) across all evaluated benchmarks, and the best released 34B
model (Llama 1) in reasoning, mathematics, and code generation. Our model
leverages grouped-query attention (GQA) for faster inference, coupled with sliding
window attention (SWA) to effectively handle sequences of arbitrary length with a
reduced inference cost. We also provide a model fine-tuned to follow instructions,
Mistral 7B – Instruct, that surpasses Llama 2 13B – chat model both on human and
automated benchmarks. Our models are released under the Apache 2.0 license.
Code:
Webpage: """
template = """{
"Model": {
"Name": "",
"Number of parameters": "",
"Number of max token": "",
"Architecture": []
},
"Usage": {
"Use case": [],
"Licence": ""
}
}"""
prediction = predict_NuExtract(model, tokenizer, [text], template)[0]
print(prediction)
```
Sliding window prompting:
```python
import json
MAX_INPUT_SIZE = 20_000
MAX_NEW_TOKENS = 6000
def clean_json_text(text):
text = text.strip()
text = text.replace("\#", "#").replace("\&", "&")
return text
def predict_chunk(text, template, current, model, tokenizer):
current = clean_json_text(current)
input_llm = f"<|input|>\n### Template:\n{template}\n### Current:\n{current}\n### Text:\n{text}\n\n<|output|>" + "{"
input_ids = tokenizer(input_llm, return_tensors="pt", truncation=True, max_length=MAX_INPUT_SIZE).to("cuda")
output = tokenizer.decode(model.generate(**input_ids, max_new_tokens=MAX_NEW_TOKENS)[0], skip_special_tokens=True)
return clean_json_text(output.split("<|output|>")[1])
def split_document(document, window_size, overlap):
tokens = tokenizer.tokenize(document)
print(f"\tLength of document: {len(tokens)} tokens")
chunks = []
if len(tokens) > window_size:
for i in range(0, len(tokens), window_size-overlap):
print(f"\t{i} to {i + len(tokens[i:i + window_size])}")
chunk = tokenizer.convert_tokens_to_string(tokens[i:i + window_size])
chunks.append(chunk)
if i + len(tokens[i:i + window_size]) >= len(tokens):
break
else:
chunks.append(document)
print(f"\tSplit into {len(chunks)} chunks")
return chunks
def handle_broken_output(pred, prev):
try:
if all([(v in ["", []]) for v in json.loads(pred).values()]):
# if empty json, return previous
pred = prev
except:
# if broken json, return previous
pred = prev
return pred
def sliding_window_prediction(text, template, model, tokenizer, window_size=4000, overlap=128):
# split text into chunks of n tokens
tokens = tokenizer.tokenize(text)
chunks = split_document(text, window_size, overlap)
# iterate over text chunks
prev = template
for i, chunk in enumerate(chunks):
print(f"Processing chunk {i}...")
pred = predict_chunk(chunk, template, prev, model, tokenizer)
# handle broken output
pred = handle_broken_output(pred, prev)
# iterate
prev = pred
return pred
```